GAN对抗生成网络(二)——算法及Python实现
1 算法步骤
上一篇提到的GAN的最优化问题是,本文记录如何求解这一问题。
首先为了表示方便,记,这里让
最大的
可视作常量。
第一步,给定初始的,使用梯度上升找到
,最大化
。关于梯度下降,可以参考笔者另一篇文章《BP神经网络原理-CSDN博客》误差反向传播的部分。
第二步,使用梯度下降法,找到最佳的参数
.其中
为学习率。
得到
之后这两步交替进行。
这里的是有max运算的,可以被微分吗?答案是可以的
引用李宏毅老师的例子,是有max运算的,相当于分段函数,在求微分的时候,根据当前x落在哪个区域决定微分的形式如何。

2 算法与JS散度的关系
上述算法第一步训练时本质是增大JS散度,第二步训练
时看起来是减小JS散度,但实际上不完全等同。
如下图所示,左侧表示算法第一步根据得到了最优的
。当进行到算法第二步,需要根据
找到一个更小的JS散度,如右图所示,
选择了
从而使得
。虽然此时JS散度更小,但是由于
更换成了
,
将更新参数变成
,此时JS散度更大了。只能说不能让
更新得太多,否则不能达到减小JS散度的目标。回到文物造假的例子,造假者收到鉴宝者的反馈后,应该微调技艺,而不是彻底更换技艺,否则只能从头来过。
从快速收敛的角度来说,应该不能更新太过,但是如果太小也忽略了
更好的形式,可能陷入局部最优。

3 实际训练过程
实际训练时,我们是无法计算出真实数据或生成数据实际的期望的,只能通过抽样近似得到期望。因此实际的做法如下:
3.1 第一步,初始化
初始化生成器和判别器
。
3.2 第二步,固定G,训练D
从分布函数(如高斯分布)中随机抽样出m个样本输入给
,输出m个样本
。
本质上概率分布转化器——将高斯分布的噪声转变成样本的分布。从真实数据中随机抽样出m个样本
,将二者输入给
。训练
的参数使其接收
时打出0分,接收
时打出1分,即最大化
建模成分类或回归问题均可。
使用梯度上升法,
实际中需要更新多次,使得V值最大。这一步实际上只找到了一个的下限(lower bound),原因是:(1)训练次数不会非常大,没法训练到收敛;(2)即使能收敛,也可能只是一个局部最优解;(3)推导时假设了
可以是任意的函数,即针对不同的x都给出最高的值,但实际中这个假设不成立。
3.3 第三步,固定D,训练G
从分布函数(如高斯分布)中随机抽样出另外m个样本
更新的参数
使得下式最小:
其中第一项与无关,因此只需要看第二项。
根据上文的讨论,这里一般只训练一次,避免改变过多,无法收敛。
实践中是将和
合在一起作为一个大的神经网络,前几层是
,后几层是
,中间有一个隐含层是
的输出,就是GAN希望得到的输出。第二步和第三步可分别固定神经网络中的某几层参数不动,训练其它层参数。
4 Python实现
关于GAN的代码,参考了https://github.com/junqiangchen/GAN。项目可以产生数字图片和人脸图片,其中人脸图片的生成使用了GAN的变种——WGAN,之后会专门讨论,本文讨论最原始的GAN模型。
4.1 使用新版tensorflow需要修改的地方
原始的代码直接运行是不通的,需要做一些调整;原始代码采用的是旧版Tensorflow(V1),如果安装了新版TensorFlow(V2)也需要做调整;有些包如果安装的新版同样不支持部分API,需要替换。具体如下表所示
| 问题 | 调整方法 | 备注 |
| 部分文件路径不对 | 调整路径,例如 调整为 | 其他几处不再赘述 |
imresize报错 | 例如 调整为 | 最新版本scipy不支持此函数,将 imresize(test_image, (init_width * scale_factor, init_height * scale_factor)) 替换为 resize( Image.fromarray(test_image).resize(init_width * scale_factor, init_height * scale_factor)) |
imsave 报错 | 例如 调整为 | 最新版本scipy不支持此函数,替换成cv2。个人认为最后应该乘255,因为原始数据是0~1的数据,直接存会存成几乎黑白的图片,需要还原 |
| 使用新版tensorflow的问题 | 将 替换为 | 新版tensorflow提供了向下兼容的compat.v1的使用方式,统一替换即可。同时要取消eager_execution模式,新版默认是“即时计算”模式,如果兼容旧版则应取消该模式。 |
4.2 GAN的代码解析
代码位置:gan/GAN/genmnist/mnist_model.py, class名为GANModel
4.2.1 Generator
定义在_GAN_generator函数中,总结为以下要点:
(1)含有五层网络,除最后一层,其他层在进入下一层之前都用batch_normalization归一化+relu激活函数
g4 = tf.contrib.layers.batch_norm(g4, epsilon=1e-5, is_training=self.phase, scope='bn4')
g4 = tf.nn.relu(g4)(2)每一层都定义w和b,使用truncated_normal,即截断异常值的正态分布
tf.truncated_normal_initializer(3)第1~2层使用全连接层,即使用w乘输入,并加上b偏置
tf.matmul(g1, g_w2) + g_b2(4)第3~4层使用反卷积运算。是卷积运算的逆过程,关于反卷积的介绍笔者正在整理
tf.nn.conv2d_transpose(x, W, output_shape, strides=[1, strides, strides, 1], padding='SAME')(5)第5层使用卷积运算,并使用tanh激活函数
g5 = convolution_2d(g4, g_w5)4.2.2 Discriminator
与Generator类似,简述如下:
(1)共4层,其中1、2层使用卷积,3、4层使用全连接
(2)卷积后使用平均池化
d1 = average_pool_2x2(d1)(3)最后一层使用sigmoid将输出控制在0~1之间
out = tf.nn.sigmoid(out_logit)4.2.3 损失函数
Generator的损失函数为
-tf.reduce_mean(tf.log(self.D_fake))对应前文提到的。注意这里是用
,方向是一样的,之后笔者会讨论他们的区别。
Discriminator的损失函数为
-tf.reduce_mean(tf.log(self.D_real) + tf.log(1 - self.D_fake))对应前文提到的
4.2.5 训练
定义D和G的训练函数,使得各自损失函数最小化。
trainD_op = tf.train.AdamOptimizer(learning_rate, beta1).minimize(self.d_loss, var_list=D_vars)
trainG_op = tf.train.AdamOptimizer(learning_rate, beta1).minimize(self.g_loss, var_list=G_vars)先让D预训练30次,然后D和G交替训练。为什么先让D预训练30次?笔者认为D本质上就是个图片分类器,可以不依赖于G,比较好训练,预训练可以加快收敛速度。
训练时使用feed“喂数据”
feed_dict={self.X: batch_xs, self.Z: z_batch, self.phase: 1}其中self.X表示真实的图片,self.Z表示噪声,self.phase表示batchnorm训练阶段还是测试阶段。
4.2.6 预测
生成随机噪声Z之后,喂给G,即可生成图片
outimage = self.Gen.eval(feed_dict={self.Z: z_batch, self.phase: 1}, session=sess)不过笔者对这里的phase有些疑问,是否应该设置为0?恕笔者对Tensorflow不熟,代码解析有些走马观花,没有深究细节以及为什么这么写,等功力提高再回过头来优化。
至此,原始GAN的算法以及Python实现已介绍完毕,下一篇笔者将拓展讨论一些细节并介绍GAN的变种。
相关文章:
GAN对抗生成网络(二)——算法及Python实现
1 算法步骤 上一篇提到的GAN的最优化问题是,本文记录如何求解这一问题。 首先为了表示方便,记,这里让最大的可视作常量。 第一步,给定初始的,使用梯度上升找到 ,最大化。关于梯度下降,可以参考笔者另一篇…...
——线程池)
并发线程(21)——线程池
文章目录 二十一、day211. 线程池实现1.1 完整代码1.2 解释 二十一、day21 我们之前在学习std::future、std::async、std::promise相关的知识时,通过std::promise和packaged_task构建了一个可用的线程池,可参考文章:并发编程(6&a…...

基于32单片机的智能语音家居
一、主要功能介绍 以STM32F103C8T6单片机为控制核心,设计一款智能远程家电控制系统,该系统能实现如下功能: 1、可通过语音命令控制照明灯、空调、加热器、窗户及窗帘的开关; 2、可通过手机显示和控制照明灯、空调、窗户及窗帘的开…...

VScode怎么重启
原文链接:【vscode】vscode重新启动 键盘按下 Ctrl Shift p 打开命令行,如下图: 输入Reload Window,如下图:...

分析服务器 systemctl 启动gozero项目报错的解决方案
### 分析 systemctl start beisen.service 报错 在 Linux 系统中,systemctl 是管理系统和服务的主要工具。当我们尝试重启某个服务时,如果服务启动失败,systemctl 会输出错误信息,帮助我们诊断和解决问题。 本文将通过一个实际的…...

大模型LLM-Prompt-OPTIMAL
1 OPTIMAL OPTIMAL 具体每项内容解释如下: Objective Clarity(目标清晰):明确定义任务的最终目标和预期成果。 Purpose Definition(目的定义):阐述任务的目的和它的重要性。 Information Gat…...

3. 多线程(1) --- 创建线程,Thread类
文章目录 前言1. API2. 创建线程2.1. 继承 Thread类2.2. 实现 Runnable 接口2.3. 匿名内部类2.4. lambda2.5.其他方法 3. Thread类及其常见的方法和属性3.1. Thread 的常见构造方法3.2. Thread 的常见属性3.3. start() --- 启动一个线程3.4. 中断一个线程3.5. 等待线程3.6. 休眠…...

简单的jmeter数据请求学习
简单的jmeter数据请求学习 1.需求 我们的流程服务由原来的workflow-server调用wfms进行了优化,将wfms服务操作并入了workflow-server中,去除了原来的webservice服务调用形式,增加了并发处理,现在想测试模拟一下,在一…...

智能水文:ChatGPT等大语言模型如何提升水资源分析和模型优化的效率
大语言模型与水文水资源领域的融合具有多种具体应用,以下是一些主要的应用实例: 1、时间序列水文数据自动化处理及机器学习模型: ●自动分析流量或降雨量的异常值 ●参数估计,例如PIII型曲线的参数 ●自动分析降雨频率及重现期 ●…...

民宿酒店预订系统小程序+uniapp全开源+搭建教程
一.介绍 一.系统介绍 基于ThinkPHPuniappuView开发的多门店民宿酒店预订管理系统,快速部署属于自己民宿酒店的预订小程序,包含预订、退房、WIFI连接、吐槽、周边信息等功能。提供全部无加密源代码,支持私有化部署。 二.搭建环境 系统环境…...

计算机网络掩码、最小地址、最大地址计算、IP地址个数
一、必备知识 1.无分类地址IPV4地址网络前缀主机号 2.每个IPV4地址由32位二进制数组成 3. /15这个地址表示网络前缀有15位,那么主机号32-1517位。 4.IP地址的个数:2**n (n表示主机号的位数) 5.可用(可分配)IP地址个数&#x…...

Mac中配置vscode(第一期:python开发)
1、终端中安装 xcode-select --install #mac的终端中安装该开发工具 xcode-select -p #显示当前 Xcode 命令行工具的安装路径注意:xcode-select --install是在 macOS 上安装命令行开发工具(Command Line Tools)的关键命令。安装的主要组件包括:C/C 编…...

软件项目体系建设文档,项目开发实施运维,审计,安全体系建设,验收交付,售前资料(word原件)
软件系统实施标准化流程设计至关重要,因为它能确保开发、测试、部署及维护等各阶段高效有序进行。标准化流程能减少人为错误,提升代码质量和系统稳定性。同时,它促进了团队成员间的沟通与协作,确保项目按时交付。此外,…...

计算机网络--路由表的更新
一、方法 【计算机网络习题-RIP路由表更新-哔哩哔哩】 二、举个例子 例1 例2...

CDN防御如何保护我们的网络安全?
在当今数字化时代,网络安全成为了一个至关重要的议题。随着网络攻击的日益频繁和复杂化,企业和个人都面临着前所未有的安全威胁。内容分发网络(CDN)作为一种分布式网络架构,不仅能够提高网站的访问速度和用户体验&…...

matlab离线安装硬件支持包
MATLAB 硬件支持包离线安装 本文章提供matlab硬件支持包离线安装教程,因为我的matlab安装的某种原因(破解),不支持硬件支持包的安装,相信也有很多相同情况的朋友,所以记录一下我是如何离线安装的ÿ…...

使用virtualenv创建虚拟环境
下载 virtualenv pip install virtualenv 创建虚拟环境 先进入想要的目录 一般为 /envs virtualenv 文件名 --python解释器的版本 激活虚拟环境 .\虚拟项目的文件夹名称\Scripts\activate 退出虚拟环境 deactivate...
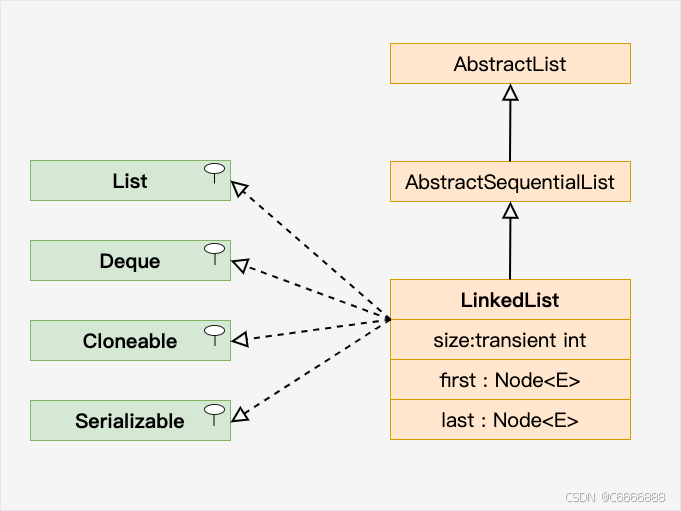
Java链表
链表(Linked List)是一种线性数据结构,它由一系列节点组成,每个节点包含两部分:一部分为用于储存数据元素,另部分是一种引用(指针),指向下一个节点。 这种结构允许动态地添加和删除元素,而不需要像数组那种大规模的数…...

Zero to JupyterHub with Kubernetes 下篇 - Jupyterhub on k8s
前言:纯个人记录使用。 搭建 Zero to JupyterHub with Kubernetes 上篇 - Kubernetes 离线二进制部署。搭建 Zero to JupyterHub with Kubernetes 中篇 - Kubernetes 常规使用记录。搭建 Zero to JupyterHub with Kubernetes 下篇 - Jupyterhub on k8s。 官方文档…...

解决 Tomcat 跨域问题 - Tomcat 配置静态文件和 Java Web 服务(Spring MVC Springboot)同时允许跨域
解决 Tomcat 跨域问题 - Tomcat 配置静态文件和 Java Web 服务(Spring MVC Springboot)同时允许跨域 Tomcat 配置允许跨域Web 项目配置允许跨域Tomcat 同时允许静态文件和 Web 服务跨域 偶尔遇到一个 Tomcat 部署项目跨域问题,因为已经处理…...

AI代码审查工具集成趋势:从“降本”到“提质”的流程重构
摘要:将AI代码审查工具集成到现有流程,关键在于“流程重构”而非“工具替换”。通过精准集成、规则调优与反馈闭环,可实现缺陷率30%以上的系统性降低。趋势判断:AI审查正从“辅助检查”转向“质量内建”为什么许多团队引入AI代码审…...

为什么92%的SITS2026项目在Phase 2失败?——多Agent角色编排、任务分解与状态同步的黄金三角模型,
第一章:SITS2026深度解析:多Agent协作系统设计 2026奇点智能技术大会(https://ml-summit.org) SITS2026(Scalable Intelligent Task Synthesis 2026)是一个面向开放域复杂任务的多Agent协作框架,其核心设计理念是“角…...

200+技术改进实现环世界400%帧率提升的架构解析
200技术改进实现环世界400%帧率提升的架构解析 【免费下载链接】Performance-Fish Performance Mod for RimWorld 项目地址: https://gitcode.com/gh_mirrors/pe/Performance-Fish 随着殖民地规模扩大,《环世界》玩家常面临严重的性能瓶颈问题。游戏在后期处…...

Vite配置文件中process.env与import.meta.env的边界:从Node.js环境到客户端注入的机制解析
1. 为什么Vite配置文件中只能用process.env? 第一次用Vite做项目时,我在vite.config.js里顺手写了import.meta.env,结果控制台直接报错"import.meta is not defined"。当时就纳闷了:明明在组件里用得好好的,…...

【Eviews实战指南】异方差诊断与加权最小二乘法优化
1. 异方差问题初探:为什么你的回归结果不可靠? 第一次用Eviews跑回归时,我发现一个奇怪现象:明明模型R很高,但t检验结果就是不稳定。后来导师指着残差图告诉我:"小伙子,你这是遇到异方差了…...

抖音爬虫避坑实战:从基础requests到进阶DrissionPage,我的踩坑记录与完整代码分享
从requests到DrissionPage:抖音数据采集的进阶实战与避坑指南 第一次尝试用Python爬取抖音视频时,我天真地以为几行requests代码就能搞定。直到实际动手才发现,从接口参数构造到动态加载处理,处处都是坑。这篇文章记录了我从基础r…...

BP神经网络交叉验证算法与确定最佳隐含层节点数Matlab程序(直接运行、数据Excel格式、...
bp神经网络交叉验证算法和确定最佳隐含层节点个数matlab 程序,直接运行即可。 数据excel格式,注释清楚,效果清晰,一步上手。BP 神经网络交叉验证与隐含层节点自寻优工具包功能说明书一、产品定位本工具包面向“零算法背景”的实验…...

基于非对称纳什谈判理论的微网电能共享与P2P交易优化策略:MATLAB复现及隐私保护技术探究
基于非对称纳什谈判的多微网电能共享运行优化策略 MATLAB代码,电网技术文献复现: 关键词:纳什谈判 合作博弈 微网 电转气-碳捕集 P2P电能交易交易 参考文档:《基于非对称纳什谈判的多微网电能共享运行优化策略》完美复现 仿…...
驱动应用程序设计)
基于STM32LXXX的数字电位器(MAX5400EKA+T)驱动应用程序设计
一、简介: MAX5400EKA+T 是 Maxim Integrated(现为 Analog Devices)推出的一款 256抽头、单路、线性变化的数字电位器。 MAX5400 是一款超小封装(SOT-23-8)的数字电位器,非常适合对PCB空间有严格要求的便携式设备。它通过标准的 SPI 接口与 STM32Lxxx 系列 MCU 通信…...

小白也能玩转语音识别:Qwen3-ASR-0.6B镜像部署全攻略
小白也能玩转语音识别:Qwen3-ASR-0.6B镜像部署全攻略 1. 为什么选择Qwen3-ASR-0.6B 语音识别技术正在改变我们与设备交互的方式。想象一下,你可以把会议录音自动转成文字,把语音备忘录变成可搜索的文档,甚至让家里的智能设备听懂…...