C语言数据结构与算法(排序)详细版
大家好,欢迎来到“干货”小仓库!!
很高兴在CSDN这个大家庭与大家相识,希望能在这里与大家共同进步,共同收获更好的自己!!无人扶我青云志,我自踏雪至山巅!!!

1.插入排序
1.1基本思想
直接插入排序是一种简单的插入排序法,其基本思想是:把待排序的记录按其关键码值的大小逐个插入到一个已经排好序的有序序列中,直到所有的记录插入完为止,得到一个新的有序序列 。
生活实例:我们玩扑克牌时,就用了插入排序思想。

1.2直接插入排序
就是将一组已经有序的数组中插入一个新的数据,将其放在数组的正确位置,最终使数组变成有序。
单趟图例:

代码实现及解析:

//插入排序
void InsertSort(int* a, int n)
{for (int i = 1; i < n; i++){int end=i-1;int tmp=a[i];while (end >= 0){if (a[end] > tmp){a[end + 1] = a[end];--end;}elsebreak;}a[end + 1] = tmp;}
}特性总结:
① 元素集合越接近有序,直接插入排序算法的时间效率越高
② 时间复杂度:O(N^2)
③ 空间复杂度:O(1),它是一种稳定的排序算法
④ 稳定性:稳定
2.希尔排序
2.1基本思想
希尔排序法又称缩小增量法。基本思想:①将数据分组(分的组越多,每组数据越少)
②对每组中的数据排好序
③再对整体数据分组,比上次分的组数要少,然后再对每组进行排序,依次循坏进行。
④直到数据分成一组,数据就全部有序了。
2.2实现
代码实现及图解:

//希尔排序
void ShellSort(int* a, int n)
{int gap = n;while (gap > 1){gap = gap / 3 + 1;for (int i = 0; i < n - gap; i++){int end = i;int tmp = a[i + gap];while (end >= 0){if (a[end] > tmp){a[end + gap] = a[end];end -= gap;}elsebreak;}a[end + gap] = tmp;}}
}特性总结:
①希尔排序是对直接插入排序的优化。
② 当gap > 1时都是预排序,目的是让数组更接近于有序。当gap == 1时,数组已经接近有序的了,这样就 会很快。这样整体而言,可以达到优化的效果。我们实现后可以进行性能测试的对比。
③稳定性:不稳定。
3.选择排序
3.1基本思想
每一次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置,直到全部待排序的数据元素排完 。
3.2实现
单趟原理:
①挑选出最大值和最小值
②将挑选出的最大值和最小值分别与最后一个数据和起始数据交换
代码实现及图解:

//交换
void Swap(int* a, int* b)
{int tmp = *a;*a = *b;*b = tmp;
}
//选择排序
void SelectSort(int* a, int left, int right)
{while (left < right){int min=left, max=left;for (int i = left+1; i <= right; i++){if (a[i] < a[min])min=i;if (a[i] > a[max])max=i;}Swap(&a[left], &a[min]);if (max == left)max = min;Swap(&a[right], &a[max]);++left;--right;}
}特性总结:
①直接选择排序思考非常好理解,但是效率不是很好。实际中很少使用
②时间复杂度:O(N^2)
③ 空间复杂度:O(1)
④稳定性:不稳定
4.堆排序
4.1基本思想
堆排序(Heapsort)是指利用堆积树(堆)这种数据结构所设计的一种排序算法,它是选择排序的一种。它是通过堆来进行选择数据。需要注意的是排升序要建大堆,排降序建小堆。
4.2实现
代码实现及解析:

//交换
void Swap(int* a, int* b)
{int tmp = *a;*a = *b;*b = tmp;
}
//向下调整
void AdjustDown(int* a, int n, int parent)
{int child = parent *2 + 1;while (child < n){if (child+1<n && a[child] < a[child + 1])++child;if (a[child] > a[parent]){Swap(&a[child], &a[parent]);parent = child;child = parent * 2 + 1;}elsebreak;}
}
//堆排序
void HeapSort(int* a, int n)
{ //向下调整建堆for (int i = (n - 2) / 2; i >= 0; i--){AdjustDown(a, n, i);}int end = n - 1;while (end > 0){Swap(&a[0], &a[end]);AdjustDown(a, end, 0);--end;}
}特性总结:
①堆排序使用堆来选数,效率就高了很多。(上一篇文章《C语言数据结构与算法(二叉树)》有讲TOPK问题)
②时间复杂度:O(N*logN)
③空间复杂度:O(1)
④稳定性:不稳定
5.冒泡排序
5.1基本思想
所谓交换,就是根据序列中两个记录键值的比较结果来对换这两个记录在序列中的位置,交换排序的特点是:将键值较大的记录向序列的尾部移动,键值较小的记录向序列的前部移动。
5.2实现
代码实现及图解:

//交换
void Swap(int* a, int* b)
{int tmp = *a;*a = *b;*b = tmp;
}//冒泡排序
void BubbleSort(int* a, int n)
{for (int j = 0; j < n; j++){for (int i = 1; i < n-j; i++){if (a[i - 1] > a[i])Swap(&a[i], &a[i - 1]);}}}特性总结:
①冒泡排序是一种非常容易理解的排序
②时间复杂度:O(N^2)
③空间复杂度:O(1)
④稳定性:稳定
6.快速排序
基本思想:任取待排序元素序列中的某元素作为基准值,按照该排序码将待排序集合分割成两子序列,左子序列中所有元素均小于基准值,右子序列中所有元素均大于基准值,然后最左右子序列重复该过程,直到所有元素都排列在相应位置上为止。
6.1hoare版本
①选出一个基准值,一般选最左边或者最右边的那个数据,也可以选中间的数据,然后交换到最左边或者最右边即可。
②左边做基准值,右边先开始移动,找到比基准值小就停下来,然后左边找比基准值大的。
③将左右两边找的值进行交换,然后继续移动右边,左边,直到左边大于或大于右边则停下来,将基准值和停下来的那个位置进行交换,到此单趟就完成了。
④利用递归继续执行上面步骤。
代码解析图解:

//交换
void Swap(int* a, int* b)
{int tmp = *a;*a = *b;*b = tmp;
}//horea版本
int Part1(int* a, int left, int right)
{int keyi = left;while (left < right){while (left < right && a[right] >= a[keyi])--right;while (left < right && a[left] <= a[keyi])++left;Swap(&a[left], &a[right]);}Swap(&a[left], &a[keyi]);keyi = left;return keyi;
}
//快排
void QuickSort(int* a, int left, int right)
{if (left >= right)return;int keyi = Part1(a, left, right);QuickSort(a, left, keyi - 1);QuickSort(a, keyi + 1, right);
}
6.2挖坑法
代码解析图解:

int Part2(int* a, int left, int right)
{int key = a[left];int hole = left;while (left < right){while (left < right && a[right] >= key)--right;a[hole] = a[right];hole = right;while (left < right && a[left] <= key)++left;a[hole] = a[left];hole = left;}a[hole] = key;return hole;
}void QuickSort(int* a, int left, int right)
{if (left >= right)return;int keyi = Part1(a, left, right);QuickSort(a, left, keyi - 1);QuickSort(a, keyi + 1, right);
}
6.3前后指针法
代码解析图解:

//交换
void Swap(int* a, int* b)
{int tmp = *a;*a = *b;*b = tmp;
}//前后指针法
int Part3(int* a, int left, int right)
{int keyi = left;int prev = left;int cur = left+1;while (cur<=right){if (a[cur] >= a[keyi])++cur;else{++prev;if (prev != cur){Swap(&a[prev], &a[cur]);++cur;}else++cur;}}Swap(&a[keyi], &a[prev]);keyi = prev;return keyi;
}
void QuickSort(int* a, int left, int right)
{if (left >= right)return;int keyi = Part1(a, left, right);QuickSort(a, left, keyi - 1);QuickSort(a, keyi + 1, right);
}6.4快速排序优化
当上面的三种快速排序方法遇到接近有序的数据的时候,效率会大大降低,可做如下优化:
①三数取中(选基准值)。上面三种方法都可以加上三数取中提高代码效率。
②小区间优化(小区间用插入排序)。
代码解析及图解:

//三数取中
int GetMidNum(int* a, int left, int right)
{int mid = left + rand() % (right - left);/*int mid = (left + right) / 2;*/if (a[left] > a[right]){if (a[mid] > a[left])return left;else if (a[mid] < a[right])return right;elsereturn mid;}else{if (a[mid] > a[right])return right;else if (a[mid] < a[left])return left;elsereturn mid;}
}
//交换
void Swap(int* a, int* b)
{int tmp = *a;*a = *b;*b = tmp;
}//前后指针法
int Part3(int* a, int left, int right)
{int tmp = GetMidNum(a, left, right);if (tmp != left)Swap(&a[tmp], &a[left]);int keyi = left;int prev = left;int cur = left+1;while (cur<=right){if (a[cur] >= a[keyi])++cur;else{++prev;if (prev != cur){Swap(&a[prev], &a[cur]);++cur;}else++cur;}}Swap(&a[keyi], &a[prev]);keyi = prev;return keyi;
}
//快排
void QuickSort(int* a, int left, int right)
{if (left >= right)return;//小区间优化--小区间直接使用插入排序if ((right - left + 1) > 10){//int keyi = Part1(a, left, right); //hoare版本//int keyi = Part2(a, left, right); //挖坑法int keyi = Part3(a, left, right); //前后指针法// [left,keyi-1] keyi [keyi+1,right]QuickSort(a, left, keyi - 1);QuickSort(a, keyi + 1, right);}else{InsertSort(a + left, right - left + 1);//插入排序}
}6.5三路划分法
结合了三数取中、小区间优化。
特殊用途:用于解决大量数据相同的情况。
原理:
①比基准值小的数据往左边放。
②和基准值相等的数据往中间放。
③比基准值大的数据往右边放。
代码解析及图解:

void QuickSortPart4(int* a, int left, int right)
{if (left >= right)return;if ((right - left + 1) < 10){InsertSort(a + left, right - left + 1);//插入排序}else{int begin = left;int end = right;int tmp = GetMidNum(a, left, right);if (tmp != left)Swap(&a[tmp], &a[left]);int keyi = left;int cur = left + 1;while (cur <= right){if (a[cur] < a[keyi]){Swap(&a[cur], &a[keyi]);++left;++keyi;}else if (a[cur] > a[keyi]){Swap(&a[cur], &a[right]);--right;}else++cur;}QuickSortPart4(a, begin, left - 1);QuickSortPart4(a, right + 1, end);}
}6.6总结
①快速排序整体的综合性能和使用场景都是比较好的,所以才敢叫快速排序
② 时间复杂度:O(N*logN)
③空间复杂度:O(logN)
④稳定性:不稳定
7.快速排序的非递归
递归的问题:
①效率。(影响不是很大)
②深度太深,会导致栈溢出。
递归改非递归有两种方式:
①直接改成循环。类似斐波那契等情况。
②使用栈辅助改循环
通过画出快排的递归展开图,可以看出,本质就是区间在不断的变化。
代码解析:

void QuickSortNonR(int* a, int left, int right)
{//利用之前栈的实现接口函数Stack st; StackInit(&st);StackPush(&st, right);StackPush(&st, left);while (!StackEmpty(&st)){int begin = StackTop(&st);StackPop(&st);int end = StackTop(&st);StackPop(&st);int keyi = Part3(a, begin, end);//前后指针法//[begin,keyi-1] keyi [keyi+1,end]if (keyi + 1 < end){StackPush(&st, end);StackPush(&st, keyi + 1);}if (begin < keyi - 1){StackPush(&st, keyi - 1);StackPush(&st, begin);}}StackDestroy(&st);
}
8.归并排序
8.1基本思想
归并排序(MERGE-SORT)是建立在归并操作上的一种有效的排序算法,该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为二路归并。 归并排序核心步骤:

8.2实现
①归并排序先递归到区间只有一个数据的时候(分解),才开始进行往回排序(合并)。
②在合并的时候,需要改变数据的位置,而且又不能对其他数据造成影响,故需要另外的一个数组,暂时存储排好序的数据,然后拷贝回原数组。
递归展开图:

void _MergeSort(int* a, int left, int right, int* tmp)
{if (left >= right)return;int mid = (left + right) / 2;//[left,mid] [mid+1,right]_MergeSort(a, left, mid,tmp);_MergeSort(a, mid + 1, right, tmp);int begin1 = left; int end1 = mid;int begin2 = mid + 1; int end2 = right;int i = left;while (begin1 <= end1 && begin2 <= end2){if (a[begin1] <= a[begin2]){tmp[i++] = a[begin1++];}elsetmp[i++] = a[begin2++];}while (begin1 <= end1)tmp[i++] = a[begin1++];while (begin2 <= end2)tmp[i++] = a[begin2++];memcpy(a + left, tmp + left, sizeof(int) * (right - left + 1));
}
//归并排序
void MergeSort(int* a, int left, int right)
{int* tmp = (int*)malloc(sizeof(int) * (right - left + 1));if (tmp==NULL)exit(2);_MergeSort(a, left, right, tmp);free(tmp);
}归并排序的特性总结:
1. 归并的缺点在于需要O(N)的空间复杂度,归并排序的思考更多的是解决在磁盘中的外排序问题。
2. 时间复杂度:O(N*logN)
3. 空间复杂度:O(N)
4. 稳定性:稳定
9.归并排序的非递归
归并排序的递归,本质上就是在改变要排序的数据的个数,可以直接改成循环。
图解:


//归并非递归
void MergeSortNonR(int* a, int n)
{int* tmp = (int*)malloc(sizeof(int) * (n));if (tmp == NULL)exit(2);int gap = 1;while (gap < n){for (int i = 0; i < n; i += 2 * gap){int begin1 = i; int end1 = i + gap - 1;int begin2 = i + gap; int end2 = i + 2 * gap - 1;if (end1 >= n || begin2 >= n)break;else if (end2 >= n)end2 = n - 1;int j = i;while (begin1 <= end1 && begin2 <= end2){if (a[begin1] <= a[begin2]){tmp[j++] = a[begin1++];}elsetmp[j++] = a[begin2++];}while (begin1 <= end1)tmp[j++] = a[begin1++];while (begin2 <= end2)tmp[j++] = a[begin2++];//归并一部分拷贝一部分(拷贝回原组)memcpy(a+i, tmp+i, sizeof(int) * (end2-i+1));}gap *= 2;}
}10.计数排序
10.1基本思想
① 统计相同元素出现次数② 根据统计的结果将序列回收到原来的
10.2实现
代码分析:
 、
、
//计数排序
void CountSort(int* a, int n)
{int min = a[0];int max = a[0];for (int i = 1; i < n; i++){if (min > a[i])min = a[i];if (max < a[i])max = a[i];}int range = max - min + 1;int* CountA = (int*)malloc(sizeof(int) * range);//计数数组if (CountA == NULL){perror("malloc fail\n");exit(2);}memset(CountA, 0, sizeof(int) * range);for (int i = 0; i < n; i++){CountA[a[i] - min]++;}int j = 0;for (int i = 0; i < range; i++){while (CountA[i]--){a[j++] = i + min;}}free(CountA);//释放
}11.排序稳定性分析
稳定性:假定在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序,这些记录的相对次序保持不变,即在原序列中,r[i]=r[j],且r[i]在r[j]之前,而在排序后的序列中,r[i]仍在r[j]之前,则称这种排序算法是稳定的;否则称为不稳定的。(简单来说就是排好序后,相同数据的相对位置保持不变则是稳定的,否则不稳定)。

快乐的时光总是短暂,咱们下篇博客再见啦!!!觉得不错的,不要忘了给默默努力的自己点个赞和收藏咯,感谢支持,谢谢大家!!!
相关文章:
C语言数据结构与算法(排序)详细版
大家好,欢迎来到“干货”小仓库!! 很高兴在CSDN这个大家庭与大家相识,希望能在这里与大家共同进步,共同收获更好的自己!!无人扶我青云志,我自踏雪至山巅!!&am…...

JAVA:利用 RabbitMQ 死信队列实现支付超时场景的技术指南
1、简述 在支付系统中,订单支付的超时自动撤销是一个非常常见的业务场景。通常用户未在规定时间内完成支付,系统会自动取消订单,释放相应的资源。本文将通过利用 RabbitMQ 的 死信队列(Dead Letter Queue, DLQ)来实现…...

pytest+request+yaml+allure搭建低编码调试门槛的接口自动化框架
接口自动化非常简单,大致分为以下几步: 准备入参调用接口拿到2中response,继续组装入参,调用下一个接口重复步骤3校验结果是否符合预期 一个优秀接口自动化框架的特点: 【编码门槛低】,又【能让新手学到…...

Elasticsearch实战指南:从入门到高效使用
Elasticsearch实战指南:从入门到高效使用 1. 引言:Elasticsearch是什么? Elasticsearch是一个分布式、RESTful风格的搜索和分析引擎,广泛应用于全文搜索、日志分析、实时数据分析等场景。它的核心特点包括: 高性能&…...

Open FPV VTX开源之嵌入式OSD配置
Open FPV VTX开源之嵌入式OSD配置 1. 源由2. 安装3. 配置步骤一:备份/etc/telemetry.conf步骤二:修改/etc/telemetry.conf步骤三:配置时区步骤四:重启摄像头 4. 实测5. 参考资料 1. 源由 穿越机模拟图传延迟通常在10ms左右。 最…...

2Hive表类型
2Hive表类型 1 Hive 数据类型2 Hive 内部表3 Hive 外部表4 Hive 分区表5 Hive 分桶表6 Hive 视图 1 Hive 数据类型 Hive的基本数据类型有:TINYINT,SAMLLINT,INT,BIGINT,BOOLEAN,FLOAT,DOUBLE&a…...
)
计算机网络之---公钥基础设施(PKI)
公钥基础设施 公钥基础设施(PKI,Public Key Infrastructure) 是一种用于管理公钥加密的系统架构,它通过结合硬件、软件、策略和标准来确保数字通信的安全性。PKI 提供了必要的框架,用于管理密钥对(包括公钥…...

EF Core执行原生SQL语句
目录 EFCore执行非查询原生SQL语句 为什么要写原生SQL语句 执行非查询SQL语句 有SQL注入漏洞 ExecuteSqlInterpolatedAsync 其他方法 执行实体相关查询原生SQL语句 FromSqlInterpolated 局限性 执行任意原生SQL查询语句 什么时候用ADO.NET 执行任意SQL Dapper 总…...

GaussDB分布式数据倾斜处理
常规数据倾斜巡检 在库中表个数少于1W的场景,直接使用倾斜视图查询当前库内所有表的数据倾斜情况 SELECT * FROM pgxc_get_table_skewness ORDER BY totalsize DESC;在库中表个数非常多(至少大于1W)的场景,因PGXC_GET_TABLE_SKEWN…...

代码随想录Day34 | 62.不同路径,63.不同路径II,343.整数拆分,96.不同的二叉搜索树
代码随想录Day34 | 62.不同路径,63.不同路径II,343.整数拆分,96.不同的二叉搜索树 62.不同路径 动态规划第二集: 比较标准简单的一道动态规划,状态转移方程容易想到 难点在于空间复杂度的优化,详见代码 class Solution {public int uniq…...

vue.js辅助函数-mapMutations
在Vue.js中,使用辅助函数可以更方便地使用Vuex的mutation。而mapMutations就是Vuex提供的一个辅助函数,它可以将mutation映射到组件的methods中,使得我们可以在组件中直接调用mutation,而不需要手动进行commit。 mapMutations函数…...

Vue3组件设计模式:高可复用性组件开发实战
Vue3组件设计模式:高可复用性组件开发实战 一、前言 在Vue3中,组件设计和开发是非常重要的,它直接影响到应用的可维护性和可复用性。本文将介绍如何利用Vue3组件设计模式来开发高可复用性的组件,让你的组件更加灵活和易于维护。 二、单一职责…...

PHP 8.4 安装和升级指南
文章精选推荐 1 JetBrains Ai assistant 编程工具让你的工作效率翻倍 2 Extra Icons:JetBrains IDE的图标增强神器 3 IDEA插件推荐-SequenceDiagram,自动生成时序图 4 BashSupport Pro 这个ides插件主要是用来干嘛的 ? 5 IDEA必装的插件&…...

什么是 OpenResty
1、OpenResty简介 1.1 了解OpenResty OpenResty是一个基于 Nginx 与 Lua 的高性能 Web 平台,其内部集成了大量精良的 Lua 库、第三方模块以及大多数的依赖项。用于方便地搭建能够处理超高并发、扩展性极高的动态 Web 应用、Web 服务和动态网关。 简单地说OpenRes…...
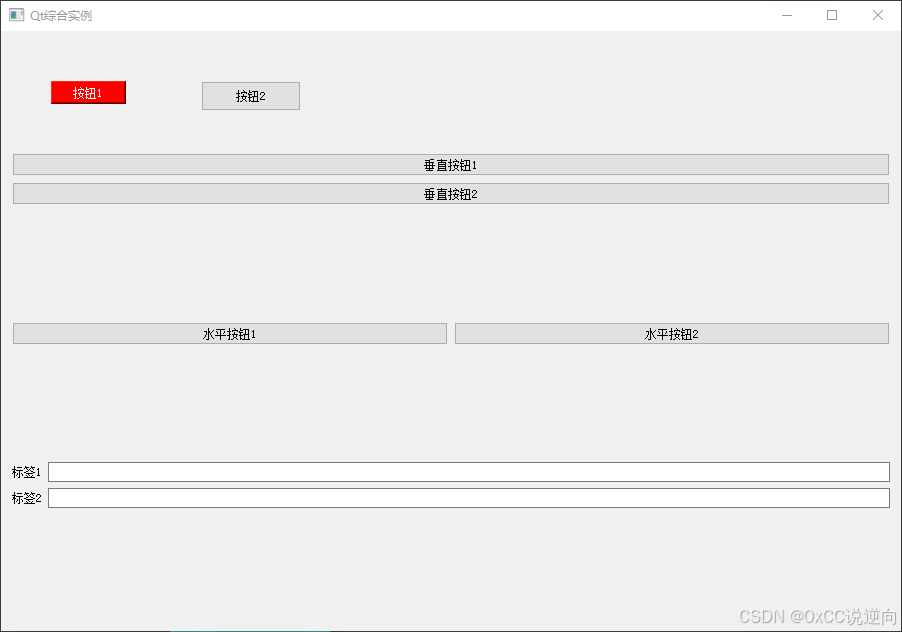
Windows图形界面(GUI)-QT-C/C++ - QT控件创建管理初始化
公开视频 -> 链接点击跳转公开课程博客首页 -> 链接点击跳转博客主页 目录 控件创建 包含对应控件类型头文件 实例化控件类对象 控件设置 设置父控件 设置窗口标题 设置控件大小 设置控件坐标 设置文本颜色和背景颜色 控件排版 垂直布局 QVBoxLayout …...

【计算机网络】lab8 DNS协议
🌈 个人主页:十二月的猫-CSDN博客 🔥 系列专栏: 🏀计算机网络_十二月的猫的博客-CSDN博客 💪🏻 十二月的寒冬阻挡不了春天的脚步,十二点的黑夜遮蔽不住黎明的曙光 目录 1. 前言 2.…...

了解linux中的“of_property_read_u32()”
of_property_read_u32(node, "post-pwm-on-delay-ms",&data->post_pwm_on_delay); /*根据"post-pwm-on-delay-ms",从属性中查找并读取一个32位整数*/ /*读到一个32位整数,保存到data->post_pwm_on_delay中*/ of_property_read_u32…...

iOS - Objective-C 底层中的内存屏障
1. 基本实现 // objc-os.h 中的内存屏障实现 #define OSMemoryBarrier() __sync_synchronize()// ARM 架构特殊处理 static ALWAYS_INLINE void OSMemoryBarrierBeforeUnlock() { #if defined(__arm__) || defined(__arm64__)OSMemoryBarrier(); #endif } 2. 解锁前的内存屏…...

阿里云服务器扩容系统盘后宝塔面板不显示扩容后的大小
解决方法步骤: 1. yum install cloud-utils-growpart xfsprogs -y 2.growpart /dev/vda 3 扩容系统盘的第3个分区 主要是这个命令1 3. fdisk -l 4. df -h 5. xfs_growfs /dev/vda3 主要是这个命令2 主要使用 df -Th 这个命令查看对应的文件系统类型 (1)、ext…...

c语言——【linux】多进程编程 【进程的创建,相关shell指令,进程状态切换,回收资源,守护进程等】
1.思维导图 2.进程的创建 函数原型:pid_t fork(void); 功能描述:以当前进程为父进程,创建一个子进程 进程链和进程扇的创建 3.多进程具体使用 3.1进程替换 exec 函数一族 int execl(const char *path, const char *arg, ... /* (char *) N…...
)
保姆级教程:在ROS2 Humble/Foxy的Gazebo中配置RGB-D相机(附解决点云颜色/坐标问题)
ROS2 Humble/Foxy中Gazebo深度相机仿真全攻略:从配置到点云问题解决在机器人仿真开发中,深度相机(RGB-D)是不可或缺的传感器之一。它能够同时提供彩色图像和深度信息,为SLAM、物体识别、避障等任务提供关键数据支持。本…...

【DeepSeek事件驱动架构实战指南】:20年架构师亲授5大核心陷阱与避坑清单
更多请点击: https://kaifayun.com 第一章:DeepSeek事件驱动架构全景认知 DeepSeek事件驱动架构(Event-Driven Architecture, EDA)并非单一技术组件的堆叠,而是一种以事件为第一公民、强调松耦合与异步协作的系统设计…...

Unity UI交互进阶:手把手教你打造一个支持单击、双击、长按的万能按钮组件
Unity UI交互进阶:手把手教你打造一个支持单击、双击、长按的万能按钮组件在游戏开发中,UI交互的流畅性和多样性直接影响玩家的游戏体验。想象一下,当你在开发一个RPG游戏的背包系统时,需要实现道具的单击查看详情、双击快速使用、…...

Burp Suite拦截与替换机制深度解析:从协议层到规则链
1. 这不是“点开就能用”的功能,而是你和目标系统之间的一道可编程闸门很多人第一次在Burp Suite里点开Proxy → Intercept,看到HTTP请求被拦下来,兴奋地改个User-Agent、删个Cookie就点Forward,以为自己已经掌握了“拦截与替换”…...

从RD、CS到WK:一文讲透SAR主流成像算法的演进与选型实战
从RD、CS到WK:SAR成像算法选型实战指南 当无人机掠过灾区上空,或卫星扫描地球表面时,合成孔径雷达(SAR)正通过电磁波穿透云层和黑暗,将地面信息转化为高分辨率图像。而决定图像质量的关键,在于工…...

phpMyAdmin CVE-2018-12613:从文件读取到RCE的伪协议利用链
1. 这个漏洞不是“能读文件”那么简单,而是后台权限的彻底失守phpMyAdmin 4.8.1里那个CVE-2018-12613,很多人扫到就报个“存在文件包含”,顺手贴个?targetphp://filter/convert.base64-encode/resource/etc/passwd截图完事。我去年在给一家教…...

如何在3分钟内为任何活动搭建专业级滚动抽奖系统?Magpie-LuckyDraw全平台开源方案深度解析
如何在3分钟内为任何活动搭建专业级滚动抽奖系统?Magpie-LuckyDraw全平台开源方案深度解析 【免费下载链接】Magpie-LuckyDraw 🏅A fancy lucky-draw tool supporting multiple platforms💻(Mac/Linux/Windows/Web/Docker) 项目地址: https…...

AB包相关知识
Lua与AB包/Addressables以及YooAsset 摘自千问: Lua 是菜谱(逻辑):决定了菜怎么做,味道如何。因为你需要随时换菜谱(热更新),所以菜谱不能死板地印在墙上(编译进主包&a…...

收藏|2026年大模型算法岗崛起!程序员小白入门高薪赛道全攻略
前些年,算法岗位一直稳居技术圈高薪行列,无数程序员争相入局,也成为计算机专业毕业生求职首选方向。 伴随大模型技术飞速迭代落地,行业就业格局迎来重大变革。如今含金量最高、人才缺口最大、长期发展潜力顶尖的岗位,已…...

哪款台灯护眼效果最好孩子用?实测口碑爆款护眼灯品牌,买前必看
哪款台灯护眼效果最好孩子用?作为家长,最揪心的就是孩子的视力问题。有数据显示,现在孩子近视率越来越高,小学就有不少戴眼镜的,中学更是过半,看着实在让人担心。 孩子每天低头写作业、看书,灯光…...