PostgreSQL和MySQL有什么区别?
一、数据存储与管理方面
-
数据类型支持
- PostgreSQL:
- 提供了非常丰富的数据类型。除了基本的整数、浮点数、字符、日期等类型外,对复杂数据类型的支持很出色。例如,它原生支持数组(Array)类型,可以方便地存储和操作数组数据。像
int[]可以存储整数数组,在处理如存储用户的兴趣标签(假设标签 ID 是整数)列表等场景时非常有用。 - 对 JSON 和 XML 数据类型也有很好的支持。可以直接在数据库中存储和查询 JSON 或 XML 格式的数据,并且提供了一系列的函数来处理这些复杂数据结构。例如,可以使用
jsonb数据类型(一种用于存储 JSON 数据的优化类型)来存储和检索具有复杂层次结构的配置数据。
- 提供了非常丰富的数据类型。除了基本的整数、浮点数、字符、日期等类型外,对复杂数据类型的支持很出色。例如,它原生支持数组(Array)类型,可以方便地存储和操作数组数据。像
- MySQL:
- 基本数据类型也很全面,但在复杂数据类型支持上相对较弱。虽然从 MySQL 5.7 开始支持 JSON 数据类型,但功能和操作的丰富程度较 PostgreSQL 稍逊一筹。例如,在处理复杂的嵌套 JSON 查询时,PostgreSQL 可能提供更灵活的函数和操作符。
- MySQL 对数组没有原生的数据类型支持,通常需要通过一些变通的方法,如使用字符串存储并用分隔符来模拟数组,在数据处理的效率和便捷性上不如 PostgreSQL。
- PostgreSQL:
-
事务处理
- PostgreSQL:
- 遵循 ACID(原子性、一致性、隔离性、持久性)原则,实现了多版本并发控制(MVCC)。这意味着在高并发环境下,它可以很好地处理多个事务对同一数据的读写操作。例如,在一个银行转账系统中,多个用户同时进行转账操作,PostgreSQL 能够通过 MVCC 机制确保每个事务看到的数据版本是一致的,不会出现数据混乱的情况。
- 支持可序列化(Serializable)隔离级别,这是最高的隔离级别,可以提供最严格的数据一致性保证。不过,这种隔离级别可能会带来一定的性能开销,需要根据具体的应用场景谨慎使用。
- MySQL:
- 同样遵循 ACID 原则,也采用 MVCC 机制。但是在事务处理的细节上与 PostgreSQL 有所不同。例如,MySQL 的 InnoDB 存储引擎实现的 MVCC 在某些场景下的并发性能表现可能因具体的查询模式和数据分布而有所差异。
- 隔离级别默认通常是可重复读(Repeatable Read),在这个隔离级别下,MySQL 通过使用 Next - Key Locking 机制来防止幻读,其实现方式与 PostgreSQL 的可序列化隔离级别的实现方式在性能和行为上有一些差别。
- PostgreSQL:
-
存储引擎架构
- PostgreSQL:
- 只有一种主要的存储引擎,所有的数据存储和管理方式是相对统一的。它的存储引擎设计注重数据的完整性和一致性,对于复杂的查询和数据结构处理能力较强。例如,在处理包含大量连接(JOIN)操作的复杂查询时,其存储引擎能够有效地利用索引和缓存来提高性能。
- MySQL:
- 有多种存储引擎可供选择,如 InnoDB、MyISAM 等。InnoDB 是目前最常用的存储引擎,它支持事务、行级锁和外键等特性,适合于对数据一致性要求较高的应用场景,类似 PostgreSQL 的使用场景。而 MyISAM 存储引擎不支持事务,但在一些简单的读密集型应用场景下,如一些简单的内容管理系统的文档读取操作,可能具有更高的性能,因为它的存储结构相对简单,索引和数据存储方式更侧重于快速读取。
- PostgreSQL:
二、性能方面
-
读写性能
- PostgreSQL:
- 在处理复杂的读操作,特别是涉及到大量连接(JOIN)、子查询(Sub - Query)和窗口函数(Window Function)的查询时,性能表现较好。这是因为它的查询优化器能够有效地处理复杂的查询逻辑,对索引的利用也比较充分。例如,在一个数据分析应用中,需要对多个维度的数据表进行关联分析,PostgreSQL 能够通过合理的索引和查询计划生成来快速返回结果。
- 对于写入操作,由于其对数据完整性的严格要求和事务处理机制,在高并发写入场景下可能会有一定的性能开销。不过,通过合理的配置和优化,如调整事务隔离级别和缓存参数等,可以在一定程度上提高写入性能。
- MySQL:
- 在简单的读写操作场景下,如基于主键的快速读取和简单的插入操作,性能表现出色。特别是 MyISAM 存储引擎在只读操作场景下,由于其简单的存储结构和高效的索引机制,能够快速地返回数据。
- 在处理复杂查询时,MySQL 的性能可能会受到查询优化器的限制。不过,随着版本的不断更新,MySQL 的查询优化器也在不断改进,在处理复杂查询方面的性能也在逐步提升。
- PostgreSQL:
-
扩展性和负载均衡
- PostgreSQL:
- 具有较好的扩展性,可以通过多种方式实现水平扩展,如使用数据库集群(如 PGPool - II 或 Patroni 等工具)。这些工具可以帮助在多个节点之间分配负载,实现高可用性和负载均衡。例如,在一个大型的 Web 应用中,随着用户数量的增加,可以通过添加更多的 PostgreSQL 节点来分担数据库的负载,并且这些节点可以通过集群软件进行有效的管理和数据同步。
- MySQL:
- 也支持扩展性,通过 MySQL Cluster 等技术可以实现分布式存储和负载均衡。不过,在实际应用中,MySQL 的扩展性可能会受到存储引擎和集群架构的限制。例如,在使用某些存储引擎时,数据的分布和同步策略可能会比较复杂,需要更多的配置和管理工作来实现高效的负载均衡。
- PostgreSQL:
三、应用场景和生态系统方面
- 应用场景偏好
- PostgreSQL:
- 更适合于对数据完整性和复杂数据类型处理要求较高的应用场景。例如,在地理信息系统(GIS)中,它可以很好地存储和处理地理空间数据,因为它提供了丰富的 GIS 扩展插件和函数。在企业级的数据分析、复杂的业务逻辑系统(如金融交易系统、供应链管理系统等)中,由于其强大的事务处理和复杂查询能力,也得到了广泛的应用。
- MySQL:
- 广泛应用于 Web 应用开发,特别是一些对读写性能要求较高、数据结构相对简单的应用场景。例如,大多数的内容管理系统(CMS)、博客系统等,使用 MySQL 作为后端数据库可以快速地实现数据的存储和读取。同时,在一些对事务处理要求不是特别严格的互联网应用中,如简单的社交网络应用的部分功能(如用户信息存储、动态发布等),MySQL 也能发挥很好的作用。
- PostgreSQL:
- 生态系统和社区支持
- PostgreSQL:
- 拥有一个活跃的开源社区,社区提供了大量的插件、扩展和文档。例如,有用于全文搜索的扩展(如 tsvector 和 tsquery),这些扩展可以方便地实现高级的文本搜索功能。其文档也非常详细,涵盖了从基础的安装配置到高级的性能优化和功能扩展等各个方面。
- MySQL:
- 生态系统非常庞大,由于其在 Web 应用领域的广泛应用,有大量的开发工具、框架与之集成。例如,许多流行的 PHP 框架(如 Laravel)对 MySQL 有很好的支持,提供了方便的数据库操作接口。同时,MySQL 由 Oracle 公司维护,也能得到一定的商业支持,这对于一些企业用户来说是一个重要的考虑因素。
- PostgreSQL:
相关文章:

PostgreSQL和MySQL有什么区别?
一、数据存储与管理方面 数据类型支持 PostgreSQL: 提供了非常丰富的数据类型。除了基本的整数、浮点数、字符、日期等类型外,对复杂数据类型的支持很出色。例如,它原生支持数组(Array)类型,可以方便地存储…...

比较之舞,优雅演绎排序算法的智美篇章
大家好,这里是小编的博客频道 小编的博客:就爱学编程 很高兴在CSDN这个大家庭与大家相识,希望能在这里与大家共同进步,共同收获更好的自己!!! 本文目录 引言正文一、冒泡排序:数据海…...

C语言数据结构与算法(排序)详细版
大家好,欢迎来到“干货”小仓库!! 很高兴在CSDN这个大家庭与大家相识,希望能在这里与大家共同进步,共同收获更好的自己!!无人扶我青云志,我自踏雪至山巅!!&am…...

JAVA:利用 RabbitMQ 死信队列实现支付超时场景的技术指南
1、简述 在支付系统中,订单支付的超时自动撤销是一个非常常见的业务场景。通常用户未在规定时间内完成支付,系统会自动取消订单,释放相应的资源。本文将通过利用 RabbitMQ 的 死信队列(Dead Letter Queue, DLQ)来实现…...

pytest+request+yaml+allure搭建低编码调试门槛的接口自动化框架
接口自动化非常简单,大致分为以下几步: 准备入参调用接口拿到2中response,继续组装入参,调用下一个接口重复步骤3校验结果是否符合预期 一个优秀接口自动化框架的特点: 【编码门槛低】,又【能让新手学到…...

Elasticsearch实战指南:从入门到高效使用
Elasticsearch实战指南:从入门到高效使用 1. 引言:Elasticsearch是什么? Elasticsearch是一个分布式、RESTful风格的搜索和分析引擎,广泛应用于全文搜索、日志分析、实时数据分析等场景。它的核心特点包括: 高性能&…...

Open FPV VTX开源之嵌入式OSD配置
Open FPV VTX开源之嵌入式OSD配置 1. 源由2. 安装3. 配置步骤一:备份/etc/telemetry.conf步骤二:修改/etc/telemetry.conf步骤三:配置时区步骤四:重启摄像头 4. 实测5. 参考资料 1. 源由 穿越机模拟图传延迟通常在10ms左右。 最…...

2Hive表类型
2Hive表类型 1 Hive 数据类型2 Hive 内部表3 Hive 外部表4 Hive 分区表5 Hive 分桶表6 Hive 视图 1 Hive 数据类型 Hive的基本数据类型有:TINYINT,SAMLLINT,INT,BIGINT,BOOLEAN,FLOAT,DOUBLE&a…...
)
计算机网络之---公钥基础设施(PKI)
公钥基础设施 公钥基础设施(PKI,Public Key Infrastructure) 是一种用于管理公钥加密的系统架构,它通过结合硬件、软件、策略和标准来确保数字通信的安全性。PKI 提供了必要的框架,用于管理密钥对(包括公钥…...

EF Core执行原生SQL语句
目录 EFCore执行非查询原生SQL语句 为什么要写原生SQL语句 执行非查询SQL语句 有SQL注入漏洞 ExecuteSqlInterpolatedAsync 其他方法 执行实体相关查询原生SQL语句 FromSqlInterpolated 局限性 执行任意原生SQL查询语句 什么时候用ADO.NET 执行任意SQL Dapper 总…...

GaussDB分布式数据倾斜处理
常规数据倾斜巡检 在库中表个数少于1W的场景,直接使用倾斜视图查询当前库内所有表的数据倾斜情况 SELECT * FROM pgxc_get_table_skewness ORDER BY totalsize DESC;在库中表个数非常多(至少大于1W)的场景,因PGXC_GET_TABLE_SKEWN…...

代码随想录Day34 | 62.不同路径,63.不同路径II,343.整数拆分,96.不同的二叉搜索树
代码随想录Day34 | 62.不同路径,63.不同路径II,343.整数拆分,96.不同的二叉搜索树 62.不同路径 动态规划第二集: 比较标准简单的一道动态规划,状态转移方程容易想到 难点在于空间复杂度的优化,详见代码 class Solution {public int uniq…...

vue.js辅助函数-mapMutations
在Vue.js中,使用辅助函数可以更方便地使用Vuex的mutation。而mapMutations就是Vuex提供的一个辅助函数,它可以将mutation映射到组件的methods中,使得我们可以在组件中直接调用mutation,而不需要手动进行commit。 mapMutations函数…...

Vue3组件设计模式:高可复用性组件开发实战
Vue3组件设计模式:高可复用性组件开发实战 一、前言 在Vue3中,组件设计和开发是非常重要的,它直接影响到应用的可维护性和可复用性。本文将介绍如何利用Vue3组件设计模式来开发高可复用性的组件,让你的组件更加灵活和易于维护。 二、单一职责…...

PHP 8.4 安装和升级指南
文章精选推荐 1 JetBrains Ai assistant 编程工具让你的工作效率翻倍 2 Extra Icons:JetBrains IDE的图标增强神器 3 IDEA插件推荐-SequenceDiagram,自动生成时序图 4 BashSupport Pro 这个ides插件主要是用来干嘛的 ? 5 IDEA必装的插件&…...

什么是 OpenResty
1、OpenResty简介 1.1 了解OpenResty OpenResty是一个基于 Nginx 与 Lua 的高性能 Web 平台,其内部集成了大量精良的 Lua 库、第三方模块以及大多数的依赖项。用于方便地搭建能够处理超高并发、扩展性极高的动态 Web 应用、Web 服务和动态网关。 简单地说OpenRes…...
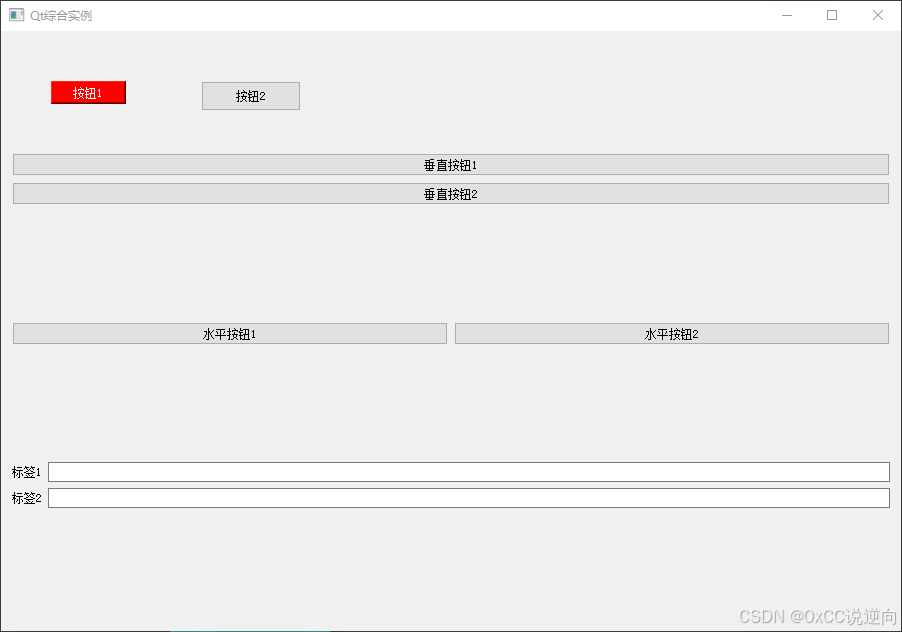
Windows图形界面(GUI)-QT-C/C++ - QT控件创建管理初始化
公开视频 -> 链接点击跳转公开课程博客首页 -> 链接点击跳转博客主页 目录 控件创建 包含对应控件类型头文件 实例化控件类对象 控件设置 设置父控件 设置窗口标题 设置控件大小 设置控件坐标 设置文本颜色和背景颜色 控件排版 垂直布局 QVBoxLayout …...

【计算机网络】lab8 DNS协议
🌈 个人主页:十二月的猫-CSDN博客 🔥 系列专栏: 🏀计算机网络_十二月的猫的博客-CSDN博客 💪🏻 十二月的寒冬阻挡不了春天的脚步,十二点的黑夜遮蔽不住黎明的曙光 目录 1. 前言 2.…...

了解linux中的“of_property_read_u32()”
of_property_read_u32(node, "post-pwm-on-delay-ms",&data->post_pwm_on_delay); /*根据"post-pwm-on-delay-ms",从属性中查找并读取一个32位整数*/ /*读到一个32位整数,保存到data->post_pwm_on_delay中*/ of_property_read_u32…...

iOS - Objective-C 底层中的内存屏障
1. 基本实现 // objc-os.h 中的内存屏障实现 #define OSMemoryBarrier() __sync_synchronize()// ARM 架构特殊处理 static ALWAYS_INLINE void OSMemoryBarrierBeforeUnlock() { #if defined(__arm__) || defined(__arm64__)OSMemoryBarrier(); #endif } 2. 解锁前的内存屏…...

告别拍脑袋规划!用ArcGIS做绿道选线:如何科学量化坡度、水域、道路成本并加权计算
科学规划绿道的ArcGIS高阶技法:从成本栅格构建到最优路径生成绿道规划从来不是简单的"两点之间直线最短",而是需要综合考虑地形、生态、人文等多维因素的复杂决策过程。传统规划中常见的"拍脑袋"决策方式,往往导致建成后…...

告别手写UI!用NXP GUI Guider拖拽设计LVGL界面,5分钟搞定音乐播放器Demo
嵌入式UI开发革命:5分钟用GUI Guider构建LVGL音乐播放器在嵌入式系统开发中,用户界面(UI)设计曾长期是工程师的痛点——既要考虑资源受限的硬件环境,又要实现流畅美观的交互体验。传统手动编写UI代码的方式不仅效率低下,调试过程更…...

Onekey终极指南:如何5分钟快速获取Steam游戏清单的免费神器
Onekey终极指南:如何5分钟快速获取Steam游戏清单的免费神器 【免费下载链接】Onekey Onekey Steam Depot Manifest Downloader 项目地址: https://gitcode.com/gh_mirrors/one/Onekey 还在为复杂的Steam游戏清单下载而头疼吗?想要备份游戏资源却不…...
:支持Anthropic API兼容、流式响应、模型热切换与RBAC权限隔离)
Claude本地化部署终极方案(企业级容器化全栈手册):支持Anthropic API兼容、流式响应、模型热切换与RBAC权限隔离
更多请点击: https://codechina.net 第一章:Claude本地化部署的架构全景与企业级价值定位 Claude本地化部署并非简单地将模型权重下载后运行,而是一套融合推理引擎优化、安全沙箱隔离、API网关治理与可观测性集成的端到端架构体系。其核心目…...

写论文的神助攻!好用的AI写作辅助软件,逻辑清晰质量高
作为一名刚完成毕业论文的过来人,我太懂写论文的痛苦了 —— 选题迷茫、文献浩如烟海、框架混乱、逻辑不清、反复修改、查重降重反复折腾... 直到我发现了这套 AI 写作工具组合,简直是论文写作的 "开挂神器",效率直接拉满ÿ…...

基于可解释机器学习的城市人口流动空间降尺度分析实践
1. 项目概述:从宏观到微观,解码城市脉搏在城市的肌理中,人口的流动如同血液的循环,承载着经济活力、社会互动与空间结构的全部信息。无论是城市规划师优化公交线路,还是商业分析师评估店铺选址,亦或是公共卫…...

电子商务设计师软考备战:特别篇 - 综合模拟与备考策略
1. 考试形式与内容结构1.1 考试基本信息考试科目与时间基础知识考试:上午9:00-11:30(150分钟)应用技术考试:下午2:00-4:30(150分钟)题型与分值分布上午考试(基础知识): -…...

2026 文章代码高亮方案选型
将基于 Prism.js 或 Highlight.js 的传统高亮方案与基于 Shiki 的现代化高亮方案进行对比,其核心区别在于底层解析原理的不同(正则表达式 vs. TextMate 语法树)。 以下是两种方案的底层原理、各自优缺点、核心对比矩阵以及适用场景的详细分析…...

开源ELM327 OBD-II适配器:从硬件设计到多协议固件实现全解析
1. 项目概述:开源ELM327 OBD适配器如果你对汽车诊断、数据监控或者嵌入式开发感兴趣,那么自己动手做一个OBD-II适配器绝对是个能让你学到很多东西的硬核项目。今天要聊的,就是一个完全开源的、基于NXP LPC1517微控制器的ELM327兼容OBD适配器。…...
)
在线文档协作工具选型必看:14款产品对比(2026版)
一、在线文档协作工具的概念解析及其核心功能 在线文档协作工具是基于云端的文档创建、编辑、共享与协同沟通平台,核心目标是让团队在同一份资料上“实时共同工作”,减少反复传文件、版本混乱与沟通成本。 企业常见的核心能力包括: 多人实…...