人工智能之深度学习_[2]-PyTorch入门
PyTorch
1.PyTorch简介
1.1 什么是PyTorch
PyTorch是一个基于Python的科学计算包
PyTorch安装
pip install torch -i https://pypi.tuna.tsinghua.edu.cn/simple
- PyTorch一个基于Python语言的深度学习框架,它将数据封装成张量(Tensor)来进行处理。
- PyTorch提供了灵活且高效的工具,用于构建、训练和部署机器学习和深度学习模型。
- PyTorch广泛应用于学术研究和工业界,特别是在计算机视觉、自然语言处理、强化学习等领域。
1.2 PyTorch特点
PyTorch与TensorFlow的比较
- PyTorch与TensorFlow的区别:PyTorch是基于动态图(动态计算图)的,而TensorFlow 1.x是基于静态计算图的(TensorFlow 2.x支持动态图)。这使得PyTorch在灵活性和调试方面优于TensorFlow,尤其是在研究和原型设计中。此外,PyTorch的API设计更加贴近Python,易于学习和使用。
- TensorFlow 2.x(引入了Eager Execution)和PyTorch都支持动态图,但PyTorch因其更直观的编程模式和调试支持,在学术界和一些工业界应用中更为流行。
-
类似于NumPy的张量计算
- PyTorch中的基本数据结构是张量(Tensor),它与NumPy中的数组类似,但PyTorch的张量具有GPU加速的能力(通过CUDA),这使得深度学习模型能够高效地在GPU上运行。
-
自动微分系统
- PyTorch提供了强大的自动微分功能(
autograd模块),能够自动计算模型中每个参数的梯度。 - 自动微分使得梯度计算过程变得简洁和高效,并且支持复杂的模型和动态计算图。
- PyTorch提供了强大的自动微分功能(
-
深度学习库
- PyTorch提供了一个名为torch.nn的子模块,用于构建神经网络。它包括了大量的预构建的层(如全连接层、卷积层、循环神经网络层等),损失函数(如交叉熵、均方误差等),以及优化算法(如SGD、Adam等)。
torch.nn.Module是PyTorch中构建神经网络的基础类,用户可以通过继承该类来定义自己的神经网络架构。
-
动态计算图
- PyTorch使用动态计算图机制,允许在运行时构建和修改模型结构,具有更高的灵活性,适合于研究人员进行实验和模型调试。
-
GPU加速(CUDA支持)
- PyTorch提供对GPU的良好支持,能够在NVIDIA的CUDA设备上高效地进行计算。用户只需要将数据和模型转移到GPU上,PyTorch会自动优化计算过程。
- 通过简单的
tensor.to(device)方法,可以轻松地将模型和数据从CPU转移到GPU或从一个GPU转移到另一个GPU。
-
跨平台支持
- PyTorch支持在多种硬件平台(如CPU、GPU、TPU等)上运行,并且支持不同操作系统(如Linux、Windows、macOS)以及分布式计算环境(如多GPU、分布式训练)。
1.3 PyTorch发展历史
-
Torch
Torch是最早的Torch框架,最初由Ronan Collobert、Clement Farabet等人开发。它是一个科学计算框架,提供了多维张量操作和科学计算工具。
-
Torch7
Torch7是Torch的一个后续版本,引入了Lua编程语言,并在深度学习领域取得了一定的成功。遗憾的是,随着pytorch的普及,Torch便不再维护,Torch7也就成为了Torch的最后一个版本。
-
Pytorch 0.1.0
在Torch的基础上,Facebook人工智能研究院(FAIR)于2016年发布了PyTorch的第一个版本,标志着PyTorch的正式诞生。
初始版本的PyTorch主要基于Torch7,但引入了更加Pythonic的设计风格,使得深度学习模型的定义和调试更加直观和灵活。
-
Pytorch 0.2.0
该版本首次引入了动态图机制,使得用户能够在构建神经网络时更加灵活。作为Pytorch后期制胜tensorflow的关键机制,该版本象征着Pytorch进入了一个新的阶段。
-
Pytorch 1.0.0
2018年发布了Pytorch的首个稳定版本,引入了Eager模式简化了模型的构建和训练过程。
-
Pytorch 2.0
Pytorch2.0引入了torch.compile,可以支持对训练过程的加速,同时引入了TorchDynamo,主要替换torch.jit.trace和torch.jit.script。另外在这个版本中编译器性能大幅提升,分布式运行方面也做了一定的优化。
2 张量创建
2.1 什么是张量
张量是PyTorch中的核心数据抽象
-
PyTorch中的张量就是元素为同一种数据类型的多维矩阵,与NumPy数组类似。
-
PyTorch中,张量以"类"的形式封装起来,对张量的一些运算、处理的方法(数值计算、矩阵操作、自动求导)被封装在类中。



2.2 基本创建方式
- 张量的数据类型有

-
张量中默认的数据类型是**float32(torch.FloatTensor)*
-
torch.tensor(data=, dtype=) 根据指定数据创建张量
import torch # 需要安装torch模块 import numpy as np# 1. 创建张量标量 data = torch.tensor(10) print(data) # 2. numpy 数组, 由于data为float64, 张量元素类型也是float64 data = np.random.randn(2, 3) data = torch.tensor(data) print(data) # 3. 列表, 浮点类型默认float32 data = [[10., 20., 30.], [40., 50., 60.]] data = torch.tensor(data) print(data) -
torch.Tensor(size=) 根据形状创建张量, 其也可用来创建指定数据的张量
# 1. 创建2行3列的张量, 默认 dtype 为 float32 data = torch.Tensor(2, 3) print(data) # 2. 注意: 如果传递列表, 则创建包含指定元素的张量 data = torch.Tensor([10]) print(data) data = torch.Tensor([10, 20]) print(data) -
torch.IntTensor()/torch.FloatTensor() 创建指定类型的张量
# 1. 创建2行3列, dtype 为 int32 的张量 data = torch.IntTensor(2, 3) print(data) # 2. 注意: 如果传递的元素类型不正确, 则会进行类型转换 data = torch.IntTensor([2.5, 3.3]) print(data) # 3. 其他的类型 data = torch.ShortTensor() # int16 data = torch.LongTensor() # int64 data = torch.FloatTensor() # float32 data = torch.DoubleTensor() # float64
2.3 线性和随机张量
-
torch.arange(start=, end=, step=):固定步长线性张量
-
torch.linspace(start=, end=, steps=):固定元素数线性张量
# 1. 在指定区间按照步长生成元素 [start, end, step) data = torch.arange(0, 10, 2) print(data)# 2. 在指定区间按照元素个数生成 [start, end, steps] # step = (end-start) / (steps-1) # value_i = start + step * i data = torch.linspace(0, 9, 10) print(data) -
torch.randn/rand(size=) 创建随机浮点类型张量
-
torch.randint(low=, high=, size=) 创建随机整数类型张量
-
torch.initial_seed() 和 torch.manual_seed(seed=) 随机种子设置
# 1. 创建随机张量 data = torch.randn(2, 3) # 创建2行3列张量 print(data) # 查看随机数种子 print('随机数种子:', torch.initial_seed())# 2. 随机数种子设置 torch.manual_seed(100) data = torch.randn(2, 3) print(data) print('随机数种子:', torch.initial_seed())
2.4 0、1、指定值张量
-
torch.zeros(size=) 和 torch.zeros_like(input=) 创建全0张量
# 1. 创建指定形状全0张量 data = torch.zeros(2, 3) print(data)# 2. 根据张量形状创建全0张量 data = torch.zeros_like(data) print(data) -
torch.ones(size=) 和 torch.ones_like(input=) 创建全1张量
# 1. 创建指定形状全1张量 data = torch.ones(2, 3) print(data)# 2. 根据张量形状创建全1张量 data = torch.ones_like(data) print(data) -
torch.full(size=, fill_value=) 和 torch.full_like(input=, fill_value=) 创建全为指定值张量
# 1. 创建指定形状指定值的张量 data = torch.full([2, 3], 10) print(data)# 2. 根据张量形状创建指定值的张量 data = torch.full_like(data, 20) print(data)
2.5 指定元素类型张量
-
data.type(dtype=)
data = torch.full([2, 3], 10) print(data.dtype) # 将 data 元素类型转换为 float64 类型 data = data.type(torch.DoubleTensor) print(data.dtype) # 转换为其他类型 # data = data.type(torch.ShortTensor) # data = data.type(torch.IntTensor) # data = data.type(torch.LongTensor) # data = data.type(torch.FloatTensor) # data = data.type(dtype=torch.float16) -
data.half/double/float/short/int/long()
data = torch.full([2, 3], 10) print(data.dtype) # 将 data 元素类型转换为 float64 类型 data = data.double() print(data.dtype) # 转换为其他类型 # data = data.short() # data = data.int() # data = data.long() # data = data.float()
3 张量类型转换
3.1 张量转换为NumPy数组
-
使用 t.numpy() 函数可以将张量转换为 ndarray 数组,但是共享内存,可以使用copy函数避免共享。
# 1. 将张量转换为 numpy 数组 data_tensor = torch.tensor([2, 3, 4]) # 使用张量对象中的 numpy 函数进行转换 data_numpy = data_tensor.numpy() print(type(data_tensor)) print(type(data_numpy)) # 注意: data_tensor 和 data_numpy 共享内存 # 修改其中的一个,另外一个也会发生改变 # data_tensor[0] = 100 data_numpy[0] = 100 print(data_tensor) print(data_numpy)# 2. 对象拷贝避免共享内存 data_tensor = torch.tensor([2, 3, 4]) # 使用张量对象中的 numpy 函数进行转换,通过copy方法拷贝对象 data_numpy = data_tensor.numpy().copy() print(type(data_tensor)) print(type(data_numpy)) # 注意: data_tensor 和 data_numpy 此时不共享内存 # 修改其中的一个,另外一个不会发生改变 # data_tensor[0] = 100 data_numpy[0] = 100 print(data_tensor) print(data_numpy)
3.2 NumPy数组转换为张量
-
使用 n.from_numpy(ndarray=) 可以将ndarray数组转换为 tensor张量,默认共享内存,使用copy函数避免共享。
-
使用 torch.tensor(data=) 可以将ndarray数组转换为tensor张量,默认不共享内存。
data_numpy = np.array([2, 3, 4]) # 将 numpy 数组转换为张量类型 # 1. torch.from_numpy(ndarray) data_tensor = torch.from_numpy(data_numpy) # nunpy 和 tensor 共享内存 # data_numpy[0] = 100 data_tensor[0] = 100 print(data_tensor) print(data_numpy)# 2. torch.tensor(ndarray) data_numpy = np.array([2, 3, 4]) data_tensor = torch.tensor(data_numpy) # nunpy 和 tensor 不共享内存 # data_numpy[0] = 100 data_tensor[0] = 100 print(data_tensor) print(data_numpy)
3.3 提取标量张量的数值
-
对于只有一个元素的张量,使用item()函数将该值从张量中提取出来
# 当张量只包含一个元素时, 可以通过 item() 函数提取出该值 data = torch.tensor([30,]) print(data.item()) data = torch.tensor(30) print(data.item())
4 张量数值计算
4.1 基本运算
加减乘除取负号:
-
+、-、*、/、-
-
add(other=)、sub、mul、div、neg
-
add_(other=)、sub_、mul_、div_、neg_(其中带下划线的版本会修改原数据)data = torch.randint(0, 10, [2, 3]) print(data) # 1. 不修改原数据 new_data = data.add(10) # 等价 new_data = data + 10 print(new_data) # 2. 直接修改原数据 注意: 带下划线的函数为修改原数据本身 data.add_(10) # 等价 data += 10 print(data) # 3. 其他函数 print(data.sub(100)) print(data.mul(100)) print(data.div(100)) print(data.neg())
4.2 点乘运算
点乘(Hadamard)也称为元素级乘积,指的是相同形状的张量对应位置的元素相乘,使用mul和运算符 * 实现。
data1 = torch.tensor([[1, 2], [3, 4]])
data2 = torch.tensor([[5, 6], [7, 8]])
# 第一种方式
data = torch.mul(data1, data2)
print(data)
# 第二种方式
data = data1 * data2
print(data)
4.3 矩阵乘法运算
矩阵乘法运算要求第一个矩阵 shape: (n, m),第二个矩阵 shape: (m, p), 两个矩阵点积运算 shape 为: (n, p)。
-
运算符 @ 用于进行两个矩阵的乘积运算
-
torch.matmul(input=, other=) 对进行乘积运算的两矩阵形状没有限定。对于输入shape不同的张量, 对应的最后几个维度必须符合矩阵运算规则
# 点积运算 data1 = torch.tensor([[1, 2], [3, 4], [5, 6]]) data2 = torch.tensor([[5, 6], [7, 8]]) # 方式一: data3 = data1 @ data2 print("data3-->", data3) # 方式二: data4 = torch.matmul(data1, data2) print("data4-->", data4)
5 张量运算函数
-
tensor.mean(dim=):平均值 -
tensor.sum(dim=):求和 -
tensor.min/max(dim=):最小值/最大值 -
tensor.pow(exponent=):幂次方 x n x^n xn -
tensor.sqrt(dim=):平方根 -
tensor.exp():指数 e x e^x ex -
tensor.log(dim=):对数 以e为底 -
dim=0按列计算,dim=1按行计算
import torchdata = torch.randint(0, 10, [2, 3], dtype=torch.float64) print(data) # 1. 计算均值 # 注意: tensor 必须为 Float 或者 Double 类型 print(data.mean()) print(data.mean(dim=0)) # 按列计算均值 print(data.mean(dim=1)) # 按行计算均值 # 2. 计算总和 print(data.sum()) print(data.sum(dim=0)) print(data.sum(dim=1)) # 3. 计算平方 print(torch.pow(data,2)) # 4. 计算平方根 print(data.sqrt()) # 5. 指数计算, e^n 次方 print(data.exp()) # 6. 对数计算 print(data.log()) # 以 e 为底 print(data.log2()) print(data.log10())
6 张量索引操作
我们在操作张量时,经常需要去获取某些元素就进行处理或者修改操作,在这里我们需要了解在torch中的索引操作。
import torch# 随机生成数据
data = torch.randint(0, 10, [4, 5])
print(data)# 1.简单行、列索引
print(data[0])
print(data[:, 0])# 2.列表索引
# 返回 (0, 1)、(1, 2) 两个位置的元素
print(data[[0, 1], [1, 2]])
# 返回 0、1 行的 1、2 列共4个元素
print(data[[[0], [1]], [1, 2]])# 3.范围索引
# 前3行的前2列数据
print(data[:3, :2])
# 第2行到最后的前2列数据
print(data[2:, :2])# 4.布尔索引
# 第三列大于5的行数据
print(data[data[:, 2] > 5])
# 第二行大于5的列数据
print(data[:, data[1] > 5])# 5.多维索引
# 随机生成三维数据
data = torch.randint(0, 10, [3, 4, 5])
print(data)
# 获取0轴上的第一个数据
print(data[0, :, :])
# 获取1轴上的第一个数据
print(data[:, 0, :])
# 获取2轴上的第一个数据
print(data[:, :, 0])
7 张量形状操作
张量形状操作是指对张量的维度进行变换的一系列操作。
张量的形状则描述了每个维度上的元素数量。
7.1 reshape
保证张量数据不变的前提下改变数据的维度
import torchdata = torch.tensor([[10, 20, 30], [40, 50, 60]])
# 1. 使用 shape 属性或者 size 方法都可以获得张量的形状
print(data.shape, data.shape[0], data.shape[1])
print(data.size(), data.size(0), data.size(1))# 2. 使用 reshape 函数修改张量形状
new_data = data.reshape(1, 6)
print(new_data.shape)
7.2 squeeze和unsqueeze
squeeze:删除指定位置形状为1的维度,不指定位置删除所有形状为1的维度,降维
unsqueeze:在指定位置添加形状为1的维度,升维
mydata1 = torch.tensor([1, 2, 3, 4, 5])
print('mydata1--->', mydata1.shape, mydata1) # 一个普通的数组 1维数据
mydata2 = mydata1.unsqueeze(dim=0)
print('在0维度上 拓展维度:', mydata2, mydata2.shape) # 1*5
mydata3 = mydata1.unsqueeze(dim=1)
print('在1维度上 拓展维度:', mydata3, mydata3.shape) # 5*1
mydata4 = mydata1.unsqueeze(dim=-1)
print('在-1维度上 拓展维度:', mydata4, mydata4.shape) # 5*1
mydata5 = mydata4.squeeze()
print('压缩维度:', mydata5, mydata5.shape) # 1*5
7.3 transpose和permute
transpose:实现交换张量形状的指定维度, 例如: 一个张量的形状为 (2, 3, 4) ,把 3 和 4 进行交换, 将张量的形状变为 (2, 4, 3)
permute:一次交换更多的维度
data = torch.tensor(np.random.randint(0, 10, [3, 4, 5]))
print('data shape:', data.size())
# 1. 交换1和2维度
mydata2 = torch.transpose(data, 1, 2)
print('mydata2.shape--->', mydata2.shape)
# 2. 将data 的形状修改为 (4, 5, 3), 需要变换多次
mydata3 = torch.transpose(data, 0, 1)
mydata4 = torch.transpose(mydata3, 1, 2)
print('mydata4.shape--->', mydata4.shape)
# 3. 使用 permute 函数将形状修改为 (4, 5, 3)
# 3-1 方法1
mydata5 = torch.permute(data, [1, 2, 0])
print('mydata5.shape--->', mydata5.shape)
# 3-2 方法2
mydata6 = data.permute([1, 2, 0])
print('mydata6.shape--->', mydata6.shape)
7.4 view和contiguous
view函数也可以用于修改张量的形状,只能用于修改连续的张量。在PyTorch中,有些张量的底层数据在内存中的存储顺序与其在张量中的逻辑顺序不一致,view函数无法对这样的张量进行变形处理,例如: 一个张量经过了 transpose 或者 permute 函数的处理之后,就无法使用 view 函数进行形状操作。
contiguous:将不连续张量转为连续张量
is_contiguous:判断张量是否连续,返回True或False
# 1 一个张量经过了 transpose 或者 permute 函数的处理之后,就无法使用 view 函数进行形状操作
# 若要使用view函数, 需要使用contiguous() 变成连续以后再使用view函数
# 2 判断张量是否连续
data = torch.tensor( [[10, 20, 30],[40, 50, 60]])
print('data--->', data, data.shape)
# 1 判断张量是否连续
print(data.is_contiguous()) # True
# 2 view
mydata2 = data.view(3, 2)
print('mydata2--->', mydata2, mydata2.shape)
# 3 判断张量是否连续
print('mydata2.is_contiguous()--->', mydata2.is_contiguous())
# 4 使用 transpose 函数修改形状
mydata3 = torch.transpose(data, 0, 1)
print('mydata3--->', mydata3, mydata3.shape)
print('mydata3.is_contiguous()--->', mydata3.is_contiguous())
# 5 需要先使用 contiguous 函数转换为连续的张量,再使用 view 函数
print (mydata3.contiguous().is_contiguous())
mydata4 = mydata3.contiguous().view(2, 3)
print('mydata4--->', mydata4.shape, mydata4)
8 张量拼接操作
张量拼接操作用于组合来自不同来源或经过不同处理的数据。
8.1 cat/concat
沿着现有维度连接一系列张量。所有输入张量除了指定的拼接维度外,其他维度必须匹配。
import torchdata1 = torch.randint(0, 10, [1, 2, 3])
data2 = torch.randint(0, 10, [1, 2, 3])
print(data1)
print(data2)
# 1. 按0维度拼接
new_data = torch.cat([data1, data2], dim=0)
print(new_data)
print(new_data.shape)
# 2. 按1维度拼接
new_data = torch.cat([data1, data2], dim=1)
print(new_data)
print(new_data.shape)
# 3. 按2维度拼接
new_data = torch.cat([data1, data2], dim=2)
print(new_data)
print(new_data.shape)
8.2 stack
在一个新的维度上连接一系列张量,这会增加一个新维度,并且所有输入张量的形状必须完全相同。
import torch
data1 = torch.randint(0, 10, [2, 3])
data2 = torch.randint(0, 10, [2, 3])
print(data1)
print(data2)
# 1. 在0维度上拼接
new_data = torch.stack([data1, data2], dim=0)
print(new_data)
print(new_data.shape)
# 2. 在1维度上拼接
new_data = torch.stack([data1, data2], dim=1)
print(new_data)
print(new_data.shape)
# 3. 在2维度上拼接
new_data = torch.stack([data1, data2], dim=2)
print(new_data)
print(new_data.shape)
相关文章:

人工智能之深度学习_[2]-PyTorch入门
PyTorch 1.PyTorch简介 1.1 什么是PyTorch PyTorch是一个基于Python的科学计算包 PyTorch安装 pip install torch -i https://pypi.tuna.tsinghua.edu.cn/simplePyTorch一个基于Python语言的深度学习框架,它将数据封装成张量(Tensor)来进行…...

基于Java的语音陪聊软件——支持聊天私聊-礼物系统-直播系统-缘分匹配-游戏陪玩
丰富的经验、成熟的技术,打造适合当下市场发展的语音交友软件源码。Java 语言凭借其独特的优势,为这款语音陪聊软件的稳健运行和持续发展奠定了坚实基础。它不仅融合了聊天私聊、礼物系统和直播系统等实用且有趣的功能,还创新性地引入了缘分匹…...

Go语言的文件操作
Go语言的文件操作 Go语言是一种开源的编程语言,由谷歌开发,具有简单、高效和并发的特点。在日常开发中,文件操作是一个非常重要且常见的任务。从读取配置文件到写入日志文件,从处理数据到存储结果,文件操作无处不在。…...

php审计1-extract函数变量覆盖
php审计1-extract函数变量覆盖 这是一个关于php审计的栏目,本人也是初学者,分享一下网上的关于php审计的一些知识,学习一下php的语法,顺便记录一下学习过程。 以下是一个关于php审计ctf题 <?php$flagflag.txt; extract($_…...

百度热力图数据原理,处理及论文应用7
目录 0、数据简介0、示例数据1、百度热力图数据日期如何选择1.1、其他实验数据的时间1.2、看日历1.3、看天气 2、百度热力图几天够研究?部分文章统计3、数据原理3.1.1 ** 这个比较重要,后面还会再次出现。核密度的值怎么理解?**3.1.2 Csv->…...

端口镜像和端口安全
✍作者:柒烨带你飞 💪格言:生活的情况越艰难,我越感到自己更坚强;我这个人走得很慢,但我从不后退。 📜系列专栏:网络安全从菜鸟到飞鸟的逆袭 目录 一,端口镜像二…...

Elasticsearch:Jira 连接器教程第一部分
作者:来自 Elastic Gustavo Llermaly 将我们的 Jira 内容索引到 Elaasticsearch 中以创建统一的数据源并使用文档级别安全性进行搜索。 在本文中,我们将回顾 Elastic Jira 原生连接器的一个用例。我们将使用一个模拟项目,其中一家银行正在开发…...

ThreeJs功能演示——几何体操作导入导出
1、内部创建几何体导出编辑能力 1)支持内部创建的面、正方体、球体 内部创建物体时,如果是三维物体,要创建集合形状geometry,和对应的材质material。再一起创建一个三维物体。 // 存储创建的几何体列表const geometries [];cre…...

LeetCode::2270. 分割数组的方案数
2270. 分割数组的方案数 思路 前缀和 提示 给你一个下标从 0 开始长度为 n 的整数数组 nums 。 如果以下描述为真,那么 nums 在下标 i 处有一个 合法的分割 : 前 i 1 个元素的和 大于等于 剩下的 n - i - 1 个元素的和。下标 i 的右边 至少有一个 元…...

elementui表单验证,数据层级过深验证失效
先看示例代码,代码为模拟动态获取表单数据,然后动态添加rules验证规则,示例表单内输入框绑定form内第四层: <template><el-form :model"form" :rules"rules" ref"ruleForm" label-width&…...
淘汰缓存的使用)
【Java】LinkedHashMap (LRU)淘汰缓存的使用
文章目录 **1. initialCapacity(初始容量)****2. loadFactor(加载因子)****3. accessOrder(访问顺序)****完整参数解释示例****示例验证** LinkedHashMap 在 Java 中可维护元素插入或访问顺序,并…...

CancerGPT :基于大语言模型的罕见癌症药物对协同作用少样本预测研究
今天我们一起来剖析一篇发表于《npj Digital Medicine》的论文——《CancerGPT for few shot drug pair synergy prediction using large pretrained language models》。该研究聚焦于一个极具挑战性的前沿领域:如何利用大语言模型(LLMs)在数…...

《汽车维护与修理》是什么级别的期刊?是正规期刊吗?能评职称吗?
问题解答: 问:《汽车维护与修理》是不是核心期刊? 答:不是,是知网收录的正规学术期刊。 问:《汽车维护与修理》级别? 答:国家级。主管单位:中国汽车维修行业协会 …...

tomcat状态一直是Exited (1)
docker run -di -p 80:8080 --nametomcat001 你的仓库地址/tomcat:9执行此命令后tomcat一直是Exited(1)状态 解决办法: 用以下命令创建运行 docker run -it --name tomcat001 -p 80:8080 -d 你的仓库地址/tomcat:9 /bin/bash最终结果 tomcat成功启动...

消息中间件的基础概念入门
目录 一、什么是消息中间件 1.1、简介 1.2、消息中间件的主要作用 解耦合 异步通信 负载均衡 可靠性与持久性 消息路由与调度 削峰 事务支持 监控与审计 跨平台和跨语言支持 二、常用消息中间件对比 2.1、 RabbitMQ 2.1.1、特点 2.1.2、适用场景 2.2、Apache K…...

基于Web的宠物医院看诊系统设计与实现(源码+定制+开发)在线预约平台、宠物病历管理、医生诊疗记录、宠物健康数据分析 宠物就诊预约、病历管理与健康分析
博主介绍: ✌我是阿龙,一名专注于Java技术领域的程序员,全网拥有10W粉丝。作为CSDN特邀作者、博客专家、新星计划导师,我在计算机毕业设计开发方面积累了丰富的经验。同时,我也是掘金、华为云、阿里云、InfoQ等平台…...

Excel数据叠加生成新DataFrame:操作指南与案例
目录 一、准备工作 二、读取Excel文件 三、数据叠加 四、处理重复数据(可选) 五、保存新DataFrame到Excel文件 六、案例演示 七、注意事项 八、总结 在日常数据处理工作中,我们经常需要将不同Excel文档中的数据整合到一个新的DataFrame中,以便进行进一步的分析和处…...

Web 开发入门之旅:从静态页面到全栈应用的第一步
Web 开发入门之旅:从静态页面到全栈应用的第一步 在当今互联网飞速发展的时代,掌握 Web 开发技能已成为众多技术爱好者和职场人士的必修课。然而,对于初学者而言,面对繁杂的技术栈和庞大的学习资源,往往感到无从下手。…...

WebSocket实现分布式的不同方案对比
引言 随着实时通信需求的日益增长,WebSocket作为一种基于TCP的全双工通信协议,在实时聊天、在线游戏、数据推送等场景中得到了广泛应用。然而,在分布式环境下,如何实现WebSocket的连接管理和消息推送成为了一个挑战。本文将对比几…...
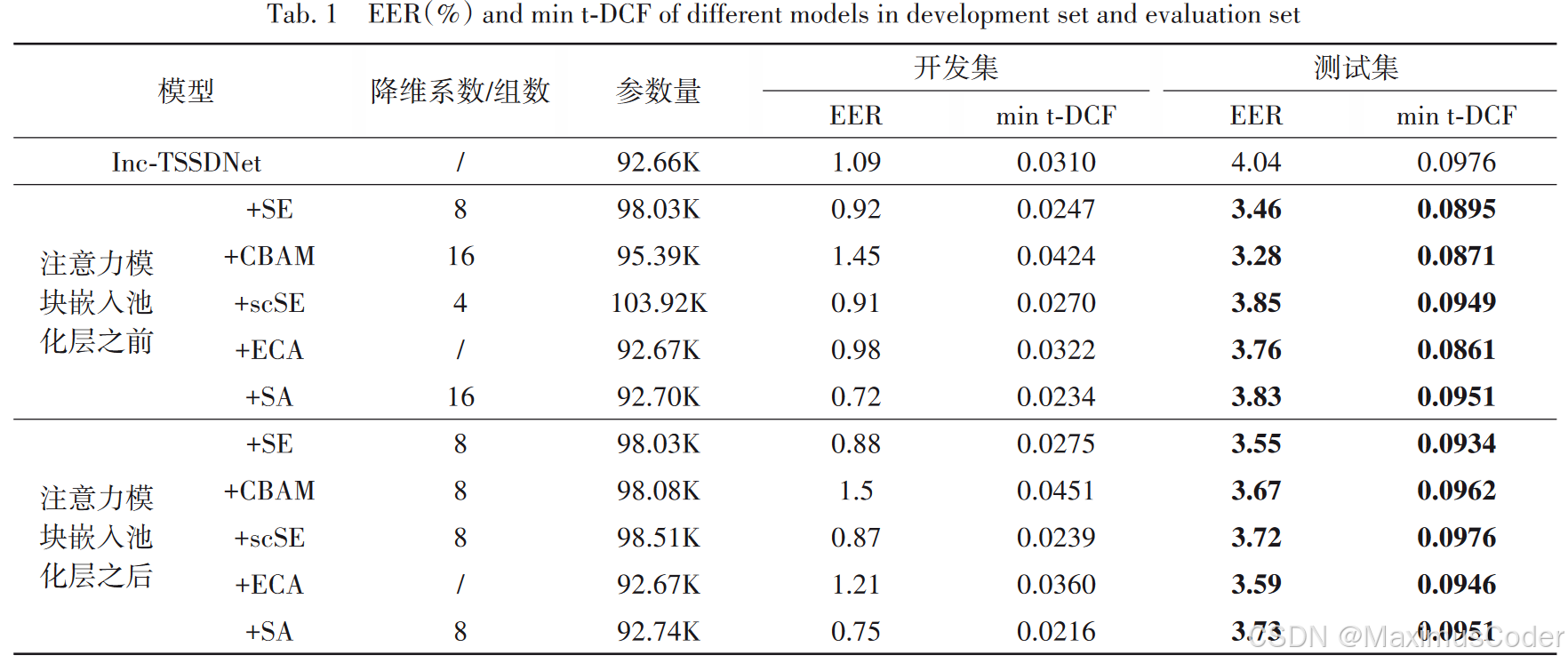
基于注意力机制的端到端合成语音检测
End-to-end Synthetic Speech Detection Based on Attention Mechanism 摘要: 五种轻量级注意力模块改为适用于语音序列的 通道注意力机制和 一维空间注意力机制 ASVspoof2019测试集的 等错误率和 最小串联检测代价函数都有所降低 池化层之前嵌入CBAM、ECA的模型测试…...

3个关键功能解析:USBToolBox如何简化macOS与Windows的USB端口映射难题
3个关键功能解析:USBToolBox如何简化macOS与Windows的USB端口映射难题 【免费下载链接】tool the USBToolBox tool 项目地址: https://gitcode.com/gh_mirrors/too/tool 在Hackintosh和跨平台开发领域,USB端口映射一直是个令人头疼的技术难题。US…...

GEMM内核与MHA中的寄存器分配优化策略
1. GEMM内核与寄存器分配基础解析通用矩阵乘法(GEMM)作为深度学习计算的核心算子,其性能表现直接决定了神经网络训练和推理的效率。在硬件层面,寄存器分配的优劣往往能带来数倍的性能差异。我们以典型的GEMM运算C αAB βC为例&…...

别再手动改路径了!用LabVIEW + MATLAB Script做自动化测试,这份环境配置指南让你效率翻倍
LabVIEW与MATLAB深度整合:构建自动化测试系统的工程实践指南在工业自动化与测试测量领域,LabVIEW和MATLAB的组合堪称黄金搭档。LabVIEW擅长硬件接口和实时控制,而MATLAB在算法开发和数据分析方面具有无可比拟的优势。本文将深入探讨如何将两者…...

微信小程序3D开发框架技术对比:XR-Frame与threejs-miniprogram
随着微信小程序逐步支持3D渲染与AR能力,开发者面临两个主要官方方案:自研的XR-Frame和适配Three.js的threejs-miniprogram。本文将从架构设计、渲染机制、功能集成、开发模式及适用场景等维度进行技术分析,为技术选型提供参考。一、XR-Frame&…...

我靠这个测试设计方法,把漏测率降低了80%
当“直觉测试”撞上南墙很长一段时间里,我和许多测试同行一样,测试用例的设计主要依靠两样东西:需求文档和“测试直觉”。这种模式在业务逻辑相对简单、迭代速度平缓时还能勉强应付。一旦面对复杂的企业级应用、高频的敏捷迭代,或…...

开启Python GUI开发新纪元:Tkinter Designer可视化界面自动化生成终极指南
开启Python GUI开发新纪元:Tkinter Designer可视化界面自动化生成终极指南 【免费下载链接】Tkinter-Designer An easy and fast way to create a Python GUI 🐍 项目地址: https://gitcode.com/gh_mirrors/tk/Tkinter-Designer 在Python GUI开发…...

Airtest Poco实战:5分钟搞定微信小程序自动化测试环境搭建与元素抓取
Airtest Poco实战:5分钟搞定微信小程序自动化测试环境搭建与元素抓取微信小程序作为轻量级应用的代表,已经渗透到电商、社交、工具等各个领域。随着小程序功能的日益复杂,自动化测试成为保障产品质量的重要手段。本文将带你快速搭建微信小程序…...

为什么鸿蒙 App 最终都会走向状态驱动?
子玥酱 (掘金 / 知乎 / CSDN / 简书 同名) 大家好,我是 子玥酱,一名长期深耕在一线的前端程序媛 👩💻。曾就职于多家知名互联网大厂,目前在某国企负责前端软件研发相关工作,主要聚…...

如何在浏览器中一键解密所有加密音乐文件:Unlock-Music完全指南
如何在浏览器中一键解密所有加密音乐文件:Unlock-Music完全指南 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地…...

Codex使用API Key授权无法使用插件?
小伙伴们,大家好,我是小溪,见字如面。对于没有ChatGPT账号的小伙伴来说,虽然可以通过API Key授权的方式使用Codex桌面端,但是会有一些限制。比如无法使用插件功能,无法使用Codex移动端进行远程控制等。为了…...