Kafka 日志存储 — 日志索引
每个日志分段文件对应两个索引文件:偏移量索引文件用来建立消息偏移量到物理地址之间的映射;时间戳索引文件根据指定的时间戳来查找对应的偏移量信息。
1 日志索引
Kafka的索引文件以稀疏索引的方式构造消息的索引。它并不保证每个消息在索引文件中都有对应的索引项。每当写入一定量的消息时,偏移量索引文件和时间戳索引文件分别增加一个索引项。
使用二分查找法来快速定位偏移量的位置。
1.1 日志分段切分的条件
日志分段文件达到一定添加时需要进行切分,其对应的索引文件也需要进行切分。满足以下一项条件即触发切分:
- 日志分段文件的大小超过了broker端参数log.segment.bytes配置的值。默认为1GB。
- 当前日志分段中消息的最大时间戳与当前系统的时间戳的差值大于log.roll.ms 或log.roll.hourse参数配置的值。log.roll.ms的优先级高,默认值为7天。
- 偏移索引文件或时间戳文件的大小达到broker端参数log.index.size.max.bytes配置的值。默认值为10MB。
- 追加的消息偏移量与当前日志分段的偏移量之间的差值大于Integer.MAX_VALUE。
1.2 索引文件的创建
对应非活跃的日志分段,其对应的日志及索引文件已经固定,不需要再写入,所以被设定为只读。而当前获取的日志分段,被设定为读写。
索引文件切分时,会关闭当前正在写入的索引文件,并设置为只读模式,同时以可读写模式创建新的索引文件。
在创建索引文件时,会为其预分配log.index.size.max.bytes大小的空间,只有当索引文件进行切分时,才把索引文件裁减到实际的数据大小。
1.3 偏移量索引
每个索引项占用8个字节(8B),分为两部分:
relativeOffset(4B):相对偏移量,消息相对于baseOffset的偏移量。当前索引文件的文件名即为baseOffset的值。
position(4B):消息在日志分段文件中对应的物理地址。
消息偏移量(offset)占用8个字节,而Integer 占用4个字节。上面提到追加的消息偏移量与当前日志分段的偏移量之间的差值大于Integer.MAX_VALUE就触发日志分段切分,因为relativeOffset不能用4个字节表示了。
1.3.1 跳跃表
Skip List,简称跳表。本质是一种可以进行二分查找的有序链表。在原有的有序链表上增加了多级索引。提高了搜索、插入及删除性能。

图 跳跃表结构示意图
采用随机技术决定链表中哪些节点应增加向前指针及在该节点应增加多少个指针。头节点需要足够的指针来满足可能构造最大级数的需要,而尾节点不需要指针域。
查找算法:首先在最高级索引查找最好一个小于目标元素的位置,然后在跳到次高级索引继续查找,直到跳到最底层为止。
1.3.2 查找算法
Kafka的每个日志对象中使用来ConcurrentSkipListMap来保存各个日志分段,每个日志分段的baseOffset作为key。查找算法如下:
- 根据跳跃表来确定目标偏移量所在的日志分段及索引文件。
- 计算出相对偏移量: 目标偏移量 - 日志分段偏移量。
- 在索引文件中找到最大的不大于相对偏移量的索引项。
- 根据索引项中的position定位到具体的日志分段文件位置,开始顺序查找目标的最终位置。
Kafka强制要求索引文件的大小必须是索引项大小的整数倍。
1.4 时间戳索引
根据指定的时间戳来查找对应的偏移量信息。
每个索引项占用12个字节,分为两部分:
timestamp(8B):消息对应的时间戳。
relativeOffset(4B):时间戳所对应的消息的相对偏移量。
1.4.1 保证时间戳单调递增
每个追加的时间戳索引项中的timestamp必须大于之前追加的,否则不予追加。如果时间戳类型为LogAppendTime,那么消息的时间戳必定能够保持单调递增。
如果是CreateTime 类型则无法保证。如果两个不同时钟的生产者同时往一个分区中插入消息,则可能会造成当前分区的时间戳乱序。
1.4.2 查找算法
每当写入一定量的消息时,就会在偏移索引文件和时间戳索引文件中分别增加一个索引项。两个文件增加索引操作是同时进行的,但并不意味着两者指向同一个值。
时间戳索引不是通过跳跃表来定位相应的日志片段。步骤如下:
- 查找日志分段,将目标时间戳和每个日志分段中的最大时间戳逐一对比,直到找到不小于目标时间戳的对应日志分段。(日志分段的最大时间戳是先查询该日志所对应的时间戳索引文件,找到最好一条索引项,若时间戳字段大于0,则取其值,否则取该日志分段的最近修改时间)
- 查找相对偏移量。在时间戳索引中使用二分查找找到不大于目标时间戳的最大索引项,来找到一个相对偏移量。
- 在偏移量索引文件中根据这个相对偏移量来查找到其物理位置。
- 从物理位置开始顺序查找最大的不小于目标时间戳的消息。
相关文章:
Kafka 日志存储 — 日志索引
每个日志分段文件对应两个索引文件:偏移量索引文件用来建立消息偏移量到物理地址之间的映射;时间戳索引文件根据指定的时间戳来查找对应的偏移量信息。 1 日志索引 Kafka的索引文件以稀疏索引的方式构造消息的索引。它并不保证每个消息在索引文件中都有…...

【大模型】ChatGPT 高效处理图片技巧使用详解
目录 一、前言 二、ChatGPT 4 图片处理介绍 2.1 ChatGPT 4 图片处理概述 2.1.1 图像识别与分类 2.1.2 图像搜索 2.1.3 图像生成 2.1.4 多模态理解 2.1.5 细粒度图像识别 2.1.6 生成式图像任务处理 2.1.7 图像与文本互动 2.2 ChatGPT 4 图片处理应用场景 三、文生图操…...

OceanBase 社区年度之星专访:北控水务纪晓东,社区铁杆开发者
编者按:作为开源数据库,社区的发展和持续进步,来自于每一位贡献者的智慧与支持。2024年度,OceanBase社区特别设立了“年度之星”奖,以表彰和感谢在过去一年中,为社区发展作出突出贡献的朋友。 今日&#x…...
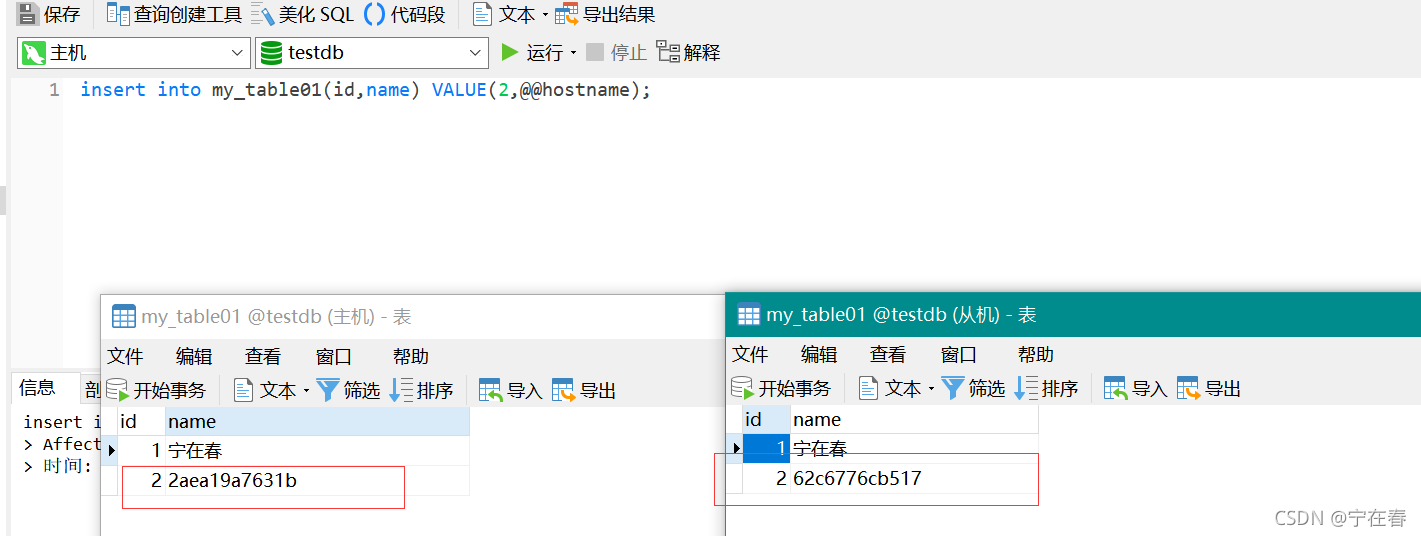
Docker 实现MySQL 主从复制
一、拉取镜像 docker pull mysql:5.7相关命令: 查看镜像:docker images 二、启动镜像 启动mysql01、02容器: docker run -d -p 3310:3306 -v /root/mysql/node-1/config:/etc/mysql/ -v /root/mysql/node-1/data:/var/lib/mysql -e MYS…...

农业农村大数据应用场景|珈和科技“数字乡村一张图”解决方案
近年来,珈和科技持续深耕农业领域,聚焦时空数据服务智慧农业。 珈和利用遥感大数据、云计算、移动互联网、物联网、人工智能等先进技术,搭建“天空地一体化”监测体系,并创新建设了150的全球领先算法模型,广泛应用于高…...

doris 2.1 Queries Acceleration-Hints 学习笔记
1 Hint Classification 1.1 Leading Hint:Specifies the join order according to the order provided in the leading hint. 1.2 Ordered Hint:A specific type of leading hint that specifies the join order as the original text sequence. 1.3 Distribute Hint:Speci…...

STM32 FreeRTOS 任务挂起和恢复---实验
实验目标 学会vTaskSuspend( )、vTaskResume( ) 任务挂起与恢复相关API函数使用: start_task:用来创建其他的三个任务。 task1:实现LED1每500ms闪烁一次。 task2:实现LED2每500ms闪烁一次。 task3:判断按键按下逻辑,KE…...

Ubuntu 24.04 LTS 通过 docker desktop 安装 seafile 搭建个人网盘
准备 Ubuntu 24.04 LTSUbuntu 空闲硬盘挂载Ubuntu 安装 Docker Desktop [我的Ubuntu服务器折腾集](https://blog.csdn.net/jh1513/article/details/145222679。 安装 seafile 参考资料 Docker安装 Seafile OnlyOffice 并配置OnlyOffice到Seafile,实现在线编辑…...

Open3D 最小二乘拟合平面(直接求解法)【2025最新版】
目录 一、算法原理二、代码实现三、结果展示本文由CSDN点云侠原创,原文链接。如果你不是在点云侠的博客中看到该文章,那么此处便是不要脸的爬虫与GPT。 博客长期更新,本文最近更新时间为:2025年1月18日。 一、算法原理 平面方程的一般表达式为:...

【CC2640R2F】香瓜CC2640R2F之SPI读写W25Q80
本文最后修改时间:2022年01月08日 10:45 一、本节简介 本节以simple_peripheral工程为例,介绍如何使用SPI读写W25Q80(外部flash)。 二、实验平台 1)CC2640R2F平台 ①协议栈版本:CC2640R2 SDK v1.40.00.4…...

探秘Shortest与Stagehand:开启高效测试与自动化新篇
探秘Shortest与Stagehand:开启高效测试与自动化新篇 在数字化浪潮的推动下,网页自动化工具如同繁星般涌现,为众多行业带来了效率的变革。在这些工具中,Shortest和Stagehand凭借其出色的表现,成为了众多开发者、测试人…...

llama 3 笔记
0.简介 llama 3 是在 15 万亿个 Token 上预训练的语言模型,具有 8B 和 70B 两种参数规模,可以支持广泛的用户场景,在各种行业基准上取得了最先进的性能,并提供了一些新功能,包括改进的推理能力。 1.改进亮点 参数规模与模型架构:Llama 3提供了8B和70B两种参数规模的模…...

写作利器:如何用 PicGo + GitHub 图床提高创作效率
你好呀,欢迎来到 Dong雨 的技术小栈 🌱 在这里,我们一同探索代码的奥秘,感受技术的魅力 ✨。 👉 我的小世界:Dong雨 📌 分享我的学习旅程 🛠️ 提供贴心的实用工具 💡 记…...
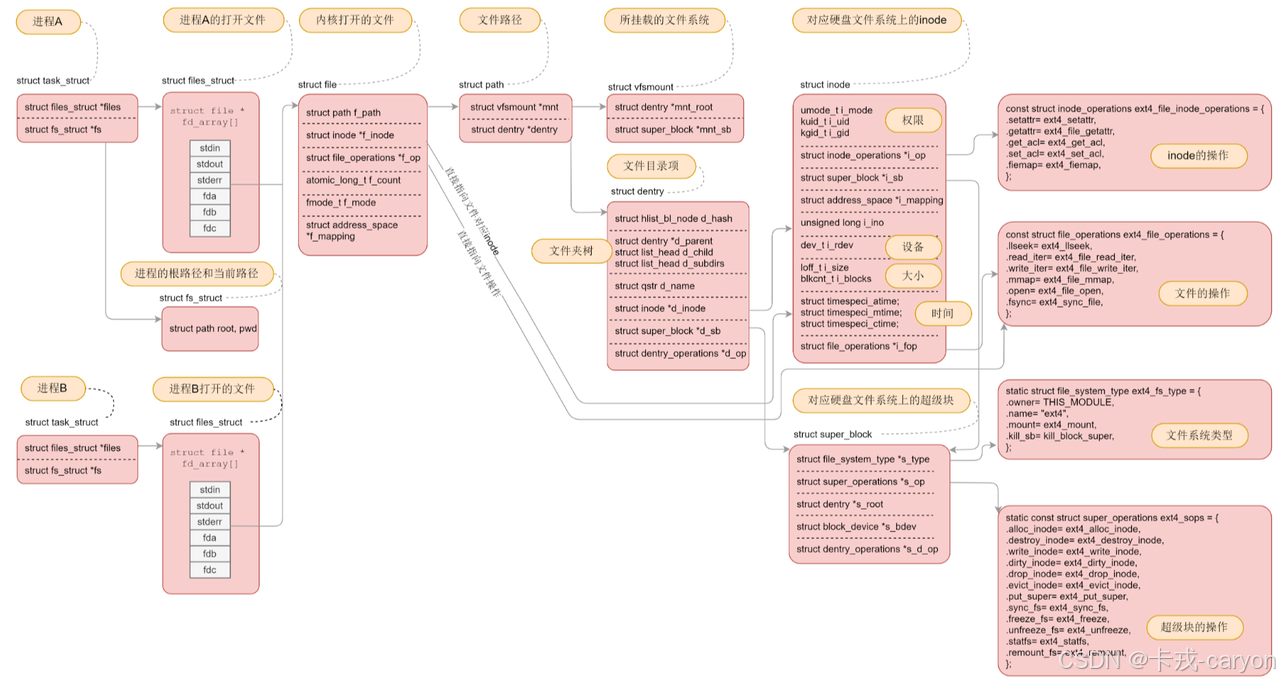
【文件篇】11.磁盘文件系统
上一篇博客中我们介绍到如果我们要访问文件首先需要打开这个文件,而文件是在磁盘上存储的,也就是说需要在磁盘上找到这个文件的路径。但是磁盘上有很多文件,这些文件都有自己的路径的,这些文件还有内容和属性,它们都是…...

嵌入式产品级-超小尺寸热成像相机(从0到1 硬件-软件-外壳)
Thermal_Imaging_Camera This is a small thermal imaging camera that includes everything from hardware and software. 小尺寸热成像相机-Pico-LVGL-RTOS 基于RP2040 Pico主控与RTOS,榨干双核性能实现LVGL和成图任务并行。ST7789驱动240280屏,CST8…...

三维扫描赋能文化:蔡司3D扫描仪让木质文化遗产焕发新生-沪敖3D
挪威文化历史博物馆在其修复工作中融入现代3D扫描技术,让数百年的历史焕发新生。 文化历史博物馆的工作 文化历史博物馆是奥斯陆大学的一个院系。凭借其在文化历史管理、研究和传播方面的丰富专业知识,该博物馆被誉为挪威博物馆研究领域的领先机构。馆…...
《自动驾驶与机器人中的SLAM技术》ch8:基于预积分和图优化的紧耦合 LIO 系统
目录 1 预积分 LIO 系统的经验 2 预积分图优化的顶点 3 预积分图优化的边 3.1 NDT 残差边(观测值维度为 3 维的单元边) 4 基于预积分和图优化 LIO 系统的实现 4.1 IMU 静止初始化 4.2 使用预积分预测 4.3 使用 IMU 预测位姿进行运动补偿 4.4 位姿配准部…...

Linux下PostgreSQL-12.0安装部署详细步骤
一、安装环境 postgresql-12.0 CentOS-7.6 注意:确认linux系统可以正常连接网络,因为在后面需要添加依赖包。 二、pg数据库安装包下载 下载地址:PostgreSQL: File Browser 选择要安装的版本进行下载: 三、安装依赖包 在要安…...

STL—stack与queue
目录 Stack stack的使用 stack的模拟实现 queue queue的使用 queue的模拟实现 priority_queue priority_queue的用法 priority_queue的模拟实现 容器适配器 种类 Stack http://www.cplusplus.com/reference/stack/stack/?kwstack stack是栈,后入先出 stack的…...

docker 使用远程镜像启动一个容器
使用前提: 首先你得安装docker,其次你得拥有一个远程镜像 docker run --name io_11281009 --rm -it -p 2233:22 -v .:/root/py -e ed25519_rootAAAAC3NzaC1lZDI1********Oy7zR7l7aUniR2rul ghcr.lizzie.fun/fj0r/io srv对上述命令解释: 1.docker run:…...

BLE四大广播模式详解:可连接/不可连接/定向/周期广播
一、前言在低功耗蓝牙(BLE)开发中,广播(Advertising)是设备发现、连接建立、数据广播、设备重连的核心基石,所有BLE交互流程均始于广播报文的收发。不同于传统经典蓝牙,BLE所有广播行为标准化、…...

SSE 基础知识
SSE 基础知识 一、概念定义 SSE 全称 Server-Sent Events,是基于HTTP协议的服务器单向数据推送技术。 建立一次长连接后,服务端可主动持续向前端推送数据,无需客户端反复轮询请求。 二、核心特点 单向通信:仅服务器 → 客户端发送…...

打不开JupyterLab
因为安装某些依赖导致JupyterLab的依赖被动升级或降级,从而影响了JupyterLab的运行,此时可以SSH登录到实例,然后输入jupyter-lab命令进行确认,如果执行命令报错则说明是此问题,那么可以通过pip install jupyterlab再次…...

CUDA并行计算与FSR框架优化实践
1. CUDA并行计算与FSR框架概述在GPU加速计算领域,CUDA(Compute Unified Device Architecture)作为NVIDIA推出的并行计算平台和编程模型,已经成为高性能计算的事实标准。其核心设计理念是将计算任务分解为网格(Grid&…...

十年以上经验的建站公司推荐|策划强、落地稳的网站制作公司盘点
互联网时代,企业官网已从单纯的信息展示窗口升级为集品牌价值传递、用户体验连接与业务高效转化于一体的核心数字阵地。行业报告显示,优质官网可帮助企业线上转化率提升35%-60%,而低效官网则可能导致潜在客户大量流失。面对市场上众多的网站建…...

风控系统如何全维度识别爬虫:IP、账号与行为的协同决策机制
1. 这不是“反爬失败”,而是风控系统在对你做全维度画像你写完一段 requests BeautifulSoup 的代码,本地跑通了,开开心心部署到服务器,结果第二天早上发现:所有请求返回 403,日志里全是空响应;…...

LPCM框架:大模型驱动的计算机架构设计革命
1. LPCM框架:计算机系统架构设计的范式革命计算机系统架构设计正站在历史性的转折点上。过去八十年来,从ENIAC的真空管到现代7纳米制程的异构计算芯片,架构设计始终遵循着"专家经验EDA工具"的传统范式。但随着摩尔定律逼近物理极限…...
3分钟搞定专业短视频!Pixelle-Video终极AI创作指南
3分钟搞定专业短视频!Pixelle-Video终极AI创作指南 【免费下载链接】Pixelle-Video 🚀 AI 全自动短视频引擎 | AI Fully Automated Short Video Engine 项目地址: https://gitcode.com/GitHub_Trending/pi/Pixelle-Video 还在为视频制作发愁吗&am…...

Log4Shell漏洞深度解析:Spring Boot日志注入原理与四层修复方案
1. 这个漏洞不是“远程执行代码”那么简单——它是一次对Java生态信任链的系统性击穿Log4j CVE-2021-44228,业内常简称为“Log4Shell”,2021年12月爆发时,我正在给一家金融客户的Spring Boot微服务集群做灰度发布前的安全加固。凌晨三点收到告…...

CTF出题人视角:从NewStarCTF 2023的WEB题,聊聊PHP特性与Flask Debug的那些‘坑’
CTF出题艺术:从PHP特性到Flask Debug的攻防博弈 当一道精心设计的CTF题目被成功破解时,出题人与解题者之间往往存在一场无声的思维交锋。作为NewStarCTF 2023 WEB方向的出题人,我想通过复盘"Begin of PHP"和"ErrorFlask"…...