【三维分割】Gaga:通过3D感知的 Memory Bank 分组任意高斯

文章目录
- 摘要
- 一、引言
- 二、主要方法
- 2.1 3D-aware Memory Bank
- 2.2 三维分割的渲染与下游应用
- 三、实验
- 消融实验
- 应用: Scene Manipulation
地址:https://www.gaga.gallery
标题:Gaga: Group Any Gaussians via 3D-aware Memory Bank
来源:加利福尼亚大学;Nvidia;Google
摘要
Gaga,一个通过利用zero shot分割模型预测的不一致的2D mask来重建和分割开放世界的3D场景的框架。与之前严重依赖于视频物体跟踪的3D场景分割方法相比,Gaga利用了空间信息,并有效地关联了不同相机pose中的物体mask
。通过消除训练图像中连续视图变化的假设,Gaga展示了对相机姿态变化的鲁棒性,特别有利于稀疏采样的图像,确保了精确的mask标签的一致性。此外,Gaga适应了来自不同来源的二维分割mask,并在不同的开放世界zero shot分割模型中表现出了稳健的性能,增强了其通用性。
一、引言
有效的开放世界三维分割对场景的理解和操作至关重要。尽管2D分割技术有了显著的进步,例如SAM和EntitySeg ,将这些方法扩展到3D领域,但遇到了确保多视图图像之间一致的mask标签分配的挑战。具体来说,不同视图的mask可能有不同的mask id,因为多视图图像是由二维分割模型单独处理的。简单地将这些不一致的二维掩模提升到3D中会导致模糊性,导致三维场景分割效果较差。因此,我们认为,在将每个掩模提升到3D之前,为每个掩模分配一个多视图一致的通用掩模ID是至关重要的。我们将此任务称为掩码关联。
先前的研究工作[9,26]建立在三维重建的高斯溅射[3DGS],试图通过将多视图图像数据集视为视频序列,采用现成的视频对象跟踪方法[6]来解决这一任务。然而,这种设计依赖于多视图图像之间的视图变化最小的假设,这种情况在现实世界的3D场景中可能并不一致地存在。因此,这些方法会与类似的物体或被遮挡的物体作斗争,这些物体会不时地消失和重新出现,如图2所示。

因此,我们分析了三维mask关联和视频对象跟踪任务之间的基本差异:对固有的三维信息的利用。具体来说,不同视图的同一对象的mask应对应于同一组三维高斯。因此,如果两组分散的三维高斯分布之间有很大的重叠,我们可以从具有相同通用mask ID的不同视图分配两个mask。
基于这种直觉,我们提出了Gaga,一个框架,将任何3D高斯进行分组,并在不同视图中呈现一致的3D分割。给定一组假设的RGB图像,我们首先使用高斯溅射法重建一个三维场景,并使用开放世界分割方法提取二维掩模。随后,我们迭代地构建一个三维感知存储库,它收集和存储按类别分组的高斯数据。具体来说,对于每个输入视图,我们使用相机参数将每个二维掩模投影到三维空间中,并在内存库中搜索与失投影掩模重叠最大的类别。根据重叠的程度,我们要么将掩码分配给一个现有的类别,要么创建一个新的类别。最后,按照上述掩模关联过程,我们利用一致的二维掩模学习每个高斯分布的特征进行渲染分割。
我们的方法Gaga能够1)合成新的RGB视图图像,分割具有固有的三维一致性;2)基于二维分割掩模对三维高斯分布进行分组,为场景操作提供精确的三维实例分割;3)适应任何二维分割方法,不需要额外的掩模预处理。我们的贡献总结如下:
- 我们提出了一个框架,使用由开放世界分割模型生成的不一致的二维掩模来重建和分割三维场景。
- 为了解决二维掩模跨视图的不一致性,我们设计了一个3守护软件存储库,收集相同语义组的高斯数据。然后使用这个内存库跨不同的视图对齐2D掩模。
- 研究结果表明,该方法可以有效地利用任何二维分割掩模,使其易于适用于合成新的视图图像和分割mask。
- 我们在不同的数据集和具有挑战性的场景上进行了全面的实验,包括稀疏输入视图,以定性和定量地证明所提方法的有效性
二、主要方法
高斯的图像像素渲染公式:

身份编码。每个高斯分配一个16维特征,通过分类器 L L L 解码为一个逐像素的分割mask ID m x , y m_{x,y} mx,y的每个像素(x,y):

产生的mask IDs 由 2D 分割masks监督。
2.1 3D-aware Memory Bank
给定带pose图像,目标是重建一个具有语义标签的三维场景进行分割渲染。为此,首先利用高斯溅射法进行场景重建。然后使用一种开放世界的二维分割方法,如SAM [14]或EntitySeg [21]来预测每个输入图像的类未知分割。然而,由于分割模型独立地处理每个输入图像,所得到的掩模自然不是多视图一致的。为了解决这个问题,[9,26]假设附近的输入视图是相似的,并应用一个视频对象跟踪器来关联不同视图的不一致的2D掩模。然而,这个假设可能并不适用于所有的3D场景,特别是当输入视图是稀疏的时。
Gaga的灵感来自于跨多个视图的面具关联任务和视频中的跟踪对象之间的根本差异:3D信息的整合。为了在不同的视图中可靠地生成一致的mask,我们提出了一种利用三维信息的方法,而不依赖于对输入图像的任何假设:在不同视图中属于同一实例的mask将对应于三维空间中的同一高斯群。因此,这些高斯分布应该被分组在一起,并分配一个相同的 group ID。
我们首先将每个二维分割mask与其相应的三维高斯分布关联起来。具体地说,给定每个输入图像的pose,将所有三维高斯splat到相机帧上。随后,对于图像中的每个mask,识别出哪些三维高斯被投影在该mask中。这些高斯模型应该被识别为3D mask的表示,并作为关联不同视角的mask的指导。
值得注意的是,mask通常描述了在当前相机pose下的前景物体的形状。然而,如图4 (a)所示,很大一部分高斯对二维分割mask的像素没有贡献,因为它们代表了位于后面的对象。为了解决这个问题,我们选择最接近相机帧的三维高斯的前x%作为mask对应的高斯。x是一个超参数,根据场景的性质进行调整。如图4 (b)行1所示,基于整个mask选择对应的高斯不能准确地表示大的mask的形状,且不能将不同像机pose的mask关联起来。为了解决这个问题,我们提出了一种策略,将图像划分为32个×32个patch,将每个patch内最接近像机帧的三维高斯的前x%的集合识别为mask m m m的对应高斯,记为G (m)。如图4 (b)行2所示,这种简单的策略有效地提高了不同视图间关联掩模的一致性。
3D-aware Memory Bank,用于收集并分组三维高斯,用来关联不同视图中的mask:给定一组图像,先将第一张图像中每个mask的相应高斯分储到一个group中,并使用一个group ID来初始化3d感知记忆库。对于后续图像的二维mask,首先找到对应的高斯,然后将其分配给内存库中的已有group;如果它们与内存库中的现有group没有相似之处,则建立一个新的group。
通过高斯重叠,来分配Group ID。这里,我们通过共享高斯的百分比来定义两组3DGS的相似性。具体来说,给定二维mask m m md 对应的3DGS(记为 G ( m ) G(m) G(m) 和Memory Bank中的group i i i(记为G_i)的3DGS,计算共享高斯(利用索引) G ( m ) ∩ G i G(m)∩G_i G(m)∩Gi的重叠的比例:

如果group i i i在Memory Bank的所有组中与mask m m m 的重叠最高,且大于阈值,则:

2.2 三维分割的渲染与下游应用
在分配group ID之后,由同一组3DGS投影的mask应该在不同的视图中具有相同的ID。与Gaussian grouping]类似,使用这些mask作为伪标签,并通过训练身份编码将它们提升到3D。由于已经预训练过3DGS,所以只修复其他属性(例如,位置、不透明度等)
三、实验
数据集。使用了一个场景理解数据集LERF-Mask [26],以及两个室内场景数据集:Replica[23]和ScanNet [8]。LERF-Mask是基于LERF数据集[12],并由[26]的作者用任务和地面真相进行了注释。它包含了3个场景:figurines, ramen,和 teatime。对于每个场景,选择6-10个对象作为文本查询,并使用Grounding DINO [17]从渲染的分割中选择mask ID。Replica[23]和ScanNet使用了8个场景,每个场景包含180张训练图像和相同数量的图像用于测试。在ScanNet中使用了7个场景,每个场景包含超过300张训练图像和大约100张测试图像。请注意,所有注释的分割mask在训练期间都是不可用的。
评估指标。使用mIoU和边界IoU(mBIoU)对LERF-Mask数据集进行评估。Replica和ScanNet使用真实全光学分割,不考虑类别信息。为了处理预测的和真实mask标签之间的差异,我们计算了基于IoU的最佳线性分配。此外,以IoU = 0.5为标准,我们报告了精度和召回率。
表1与表2:


实验细节。我们使用SAM [14]和Entity[21]来分割2D掩码,通过对置信度较高的mask排序,分低于0.5的mask被丢弃。先训练30K原始高斯溅射,然后冻结其他参数,训练10K的身份编码;选择最接近相机帧的前20%三维高斯函数作为mask对应的3D高斯。新的group ID的重叠阈值设置为0.1。为了公平比较,我们训练高斯分组[26]进行40K迭代,所有用于训练三维高斯的参数的身份编码与[3DGS]和[Gaussian grouping]相同。



消融实验
Gaga对训练图像数量变化的鲁棒性(分别对replica数据集按比例0.3、0.2、0.1和0.05的副本稀疏采样),效果如表3:


与GaussianGrouping相比,Gaga对训练图像数量减少的敏感性较低,这可以从IoU下降值较小得到证明。可视化结果如图7所示。只有5%的训练数据,Gaga仍然可以提供准确的分割掩模,而高斯分组由于不准确的跟踪,无法为很大一部分物体提供掩模。

应用: Scene Manipulation
Gaga实现了高质量、多视图一致的3D分割,有利于Scene Manipulation任务,因为我们可以准确地分割3D对象的高斯分布并编辑它们的属性。利用预先训练的具有身份编码的三维高斯模型,我们使用经过身份编码训练的分类器来预测每个三维高斯模型的掩模标签。随后,我们选择与目标对象共享相同mask标签的三维高斯,并编辑它们的属性,如对象着色、删除和位置移动

其他消融实验:

相关文章:
【三维分割】Gaga:通过3D感知的 Memory Bank 分组任意高斯
文章目录 摘要一、引言二、主要方法2.1 3D-aware Memory Bank2.2 三维分割的渲染与下游应用 三、实验消融实验应用: Scene Manipulation 地址:https://www.gaga.gallery 标题:Gaga: Group Any Gaussians via 3D-aware Memory Bank 来源:加利福…...

期权懂|明日股指期货交割日该如何操作?
锦鲤三三每日分享期权知识,帮助期权新手及时有效地掌握即市趋势与新资讯! 明日股指期货交割日该如何操作? 一、需要确认股指期货交割日: 查查看明日是否为交割日,别忘了关注交易所公告,以免错过。 二、需要…...

大牙的2024年创作总结
文章目录 一、自动驾驶通讯协议的学习心得二、PyTorch框架应用的心得体会三、大规模语言模型(LLM)的研究心得四、神经网络架构与实战经验五、我的年度文章六、未来展望与个人成长 引言 2024年是我个人在深度学习和自动驾驶领域不断探索、实践并取得显著…...

AI软件栈:中间表示
概念 编译器通常可以分为前端、优化器和后端三个部分中间表示属于变异过程中表达源程序的方法,作为单独的表示语言。将不同的前端语言(例如C、python、Java等)描述转换为中间表示。优化器对中间表示进行转换和优化,输出新的中间表示。后端将优化后的中间表示转换为特定硬件…...

【PowerQuery专栏】PowerQuery的M语言函数Access数据库访问
Access是相对比较小型的文件型数据库,PowerQuery 进行Access数据库解析非常简单,直接使用Access.Database的函数可以实现数据库访问,函数包含如下参数,函数结果为Table表类型。 Access.Database(参数1 as binary,参数2 as record) as Table 参数1为数据库,数据类型为二进…...

C# OpenCvSharp 部署文档矫正,包括文档扭曲/模糊/阴影等情况
目录 说明 效果 模型 项目 代码 下载 参考 C# OpenCvSharp 部署文档矫正,包括文档扭曲/模糊/阴影等情况 说明 地址:https://github.com/RapidAI/RapidUnDistort 修正文档扭曲/模糊/阴影等情况,使用onnx模型简单轻量部署,…...

go读取excel游戏配置
1.背景 游戏服务器,配置数据一般采用csv/excel来作为载体,这种方式,策划同学配置方便,服务器解析也方便。在jforgame框架里,我们使用以下的excel配置格式。 然后可以非常方便的进行数据检索,例如ÿ…...

特殊类设计
[本节目标] 掌握常见特殊类的设计方式 1.请设计一个类,不能被拷贝 拷贝只会放生在两个场景中:拷贝构造函数以及赋值运算符重载,因此想要让一个类禁止拷贝,只需让该类不能调用拷贝构造函数以及赋值运算符重载即可。 C98 将拷贝构…...

图像去雾数据集的下载和预处理操作
前言 目前,因为要做对比实验,收集了一下去雾数据集,并且建立了一个数据集的预处理工程。 这是以前我写的一个小仓库,我决定还是把它用起来,下面将展示下载的路径和数据处理的方法。 下面的代码均可以在此找到。Auo…...
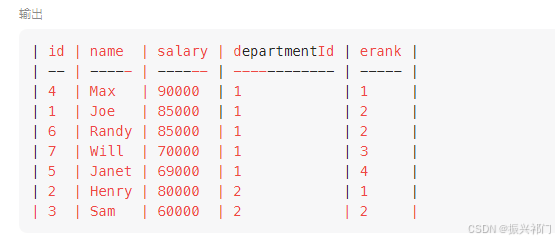
【LeetCode】--- MySQL刷题集合
1.组合两个表(外连接) select p.firstName,p.lastName,a.city,a.state from Person p left join Address a on p.personId a.personId; 以左边表为基准,去连接右边的表。取两表的交集和左表的全集 2.第二高的薪水 (子查询、if…...

基于Python的多元医疗知识图谱构建与应用研究(上)
一、引言 1.1 研究背景与意义 在当今数智化时代,医疗数据呈爆发式增长,如何高效管理和利用这些数据,成为提升医疗服务质量的关键。传统医疗数据管理方式存在数据孤岛、信息整合困难等问题,难以满足现代医疗对精准诊断和个性化治疗的需求。知识图谱作为一种知识表示和管理…...

小哆啦解题记:如何计算除自身以外数组的乘积
小哆啦开始力扣每日一题的第十二天 https://leetcode.cn/problems/product-of-array-except-self/description/ 《小哆啦解题记:如何计算除自身以外数组的乘积》 在一个清晨的阳光下,小哆啦坐在书桌前,思索着一道困扰已久的题目:…...

渐进式图片的实现原理
渐进式图片(Progressive JPEG)的实现原理与传统的基线 JPEG(Baseline JPEG)不同。它通过改变图片的编码和加载方式,使得图片在加载时能够逐步显示从模糊到清晰的图像。 1. 传统基线 JPEG 的加载方式 在传统的基线 JP…...
)
SQL刷题快速入门(三)
其他章节: SQL刷题快速入门(一) SQL刷题快速入门(二) 承接前两个章节,本系列第三章节主要讲SQL中where和having的作用和区别、 GROUP BY和ORDER BY作用和区别、表与表之间的连接操作(重点&…...

mybatis(19/134)
大致了解了一下工具类,自己手敲了一边,java的封装还是真的省去了很多麻烦,封装成一个工具类就可以不用写很多重复的步骤,一个工厂对应一个数据库一个environment就好了。 mybatis中调用sql中的delete占位符里面需要有字符…...

sqlmap 自动注入 -01
1: 先看一下sqlmap 的help: 在kali-linux 系统里面,可以sqlmap -h看一下: Target: At least one of these options has to be provided to define the target(s) -u URL, --urlURL Target URL (e.g. "Salesforce Platform for Application Development | Sa…...

3.8.Trie树
Trie树 Trie 树,又称字典树或前缀树,是一种用于高效存储和检索字符串数据的数据结构,以下是关于它的详细介绍: 定义与原理 定义:Trie 树是一种树形结构,每个节点可以包含多个子节点,用于存储…...

day 21
进程、线程、协程的区别 进程:操作系统分配资源的最小单位,其中可以包含一个或者多个线程,进程之间是独立的,可以通过进程间通信机制(管道,消息队列,共享内存,信号量,信…...

基于模板方法模式-消息队列发送
基于模板方法模式-消息队列发送 消息队列广泛应用于现代分布式系统中,作为解耦、异步处理和流量控制的重要工具。在消息队列的使用中,发送消息是常见的操作。不同的消息队列可能有不同的实现方式,例如,RabbitMQ、Kafka、RocketMQ…...

俄语画外音的特点
随着全球媒体消费的增加,语音服务呈指数级增长。作为视听翻译和本地化的一个关键方面,画外音在确保来自不同语言和文化背景的观众能够以一种真实和可访问的方式参与内容方面发挥着重要作用。说到俄语,画外音有其独特的特点、挑战和复杂性&…...
)
用Python+OpenCV手把手实现Prewitt边缘检测(附完整代码与效果对比图)
用PythonOpenCV手把手实现Prewitt边缘检测(附完整代码与效果对比图) 边缘检测是计算机视觉中最基础也最关键的预处理步骤之一。想象一下,当你需要让计算机"看清"一张照片中的物体轮廓时,边缘检测算法就是它的"视觉…...

番茄小说下载器终极指南:三步构建你的离线阅读自由王国
番茄小说下载器终极指南:三步构建你的离线阅读自由王国 【免费下载链接】Tomato-Novel-Downloader 番茄小说下载器不精简版 项目地址: https://gitcode.com/gh_mirrors/to/Tomato-Novel-Downloader 你是否曾在地铁里读到精彩章节时突然断网?是否在…...
Transient、QuickEye、VerifyEye傻傻分不清?一文讲透Ansys里三种眼图仿真方法的适用场景与避坑指南
Transient、QuickEye、VerifyEye深度解析:Ansys眼图仿真技术选型实战指南 在高速数字系统设计中,眼图分析是评估信号完整性的黄金标准。面对Ansys工具链中三种截然不同的眼图生成方法,工程师常常陷入选择困境——是追求精确度的传统瞬态分析&…...

关于psthon问题
我想问问各位 我python可以查到 但是我的bit文件查不到python怎么回事...
)
手把手教你用Mind+和Blynk,让手机轻松遥控掌控板(含自建服务器避坑指南)
从零搭建物联网控制平台:Mind与Blynk深度整合实战 当你第一次尝试用手机控制硬件设备时,那种"隔空取物"的奇妙感总会让人兴奋不已。想象一下,躺在沙发上就能调节书桌上的智能台灯亮度,或者在外出时随时查看家中的温湿度…...

终极歌词同步神器LRCGET:5分钟为你的音乐库添加完美歌词
终极歌词同步神器LRCGET:5分钟为你的音乐库添加完美歌词 【免费下载链接】lrcget Utility for mass-downloading LRC synced lyrics for your offline music library. 项目地址: https://gitcode.com/gh_mirrors/lr/lrcget 你是否厌倦了在听歌时手动搜索歌词…...

Driver Store Explorer终极指南:轻松管理Windows驱动存储区,释放宝贵磁盘空间
Driver Store Explorer终极指南:轻松管理Windows驱动存储区,释放宝贵磁盘空间 【免费下载链接】DriverStoreExplorer Driver Store Explorer 项目地址: https://gitcode.com/gh_mirrors/dr/DriverStoreExplorer 你是否曾为Windows系统越来越慢而烦…...

UE5项目打包后RenderTarget导出图片全黑?手把手教你解决伽马校正与资产打包问题
UE5打包后RenderTarget导出图片全黑的终极解决方案当你花了整整三天时间调试RenderTarget导出功能,终于在编辑器里看到完美的截图效果,却在打包成可执行文件后发现所有导出的图片都变成了一片漆黑——这种从云端跌入谷底的感觉,每个UE开发者都…...

【C++】零基础入门 · 第 6 节:数组
上一节我们学习了函数,知道了如何把代码封装起来方便复用。但在实际编程中,你很快就会遇到一个问题:如果要存储 100 个学生的成绩,难道要定义 100 个变量吗?这显然不现实。数组就是 C++ 给出的答案——它让我们能用一个变量名管理一组相同类型的数据。 1. 为什么需要数组…...

如何让旧款Mac运行最新系统:OpenCore Legacy Patcher完整指南
如何让旧款Mac运行最新系统:OpenCore Legacy Patcher完整指南 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 想让你的老旧Mac设备重新焕发活力&a…...