es 3期 第25节-运用Rollup减少数据存储
#### 1.Elasticsearch是数据库,不是普通的Java应用程序,传统数据库需要的硬件资源同样需要,提升性能最有效的就是升级硬件。
#### 2.Elasticsearch是文档型数据库,不是关系型数据库,不具备严格的ACID事务特性,任何企图直接替代严格事务性场景的应用项目都会失败!!!
#### 3.Elasticsearch原则上适合一切非事务性应用场景或能够容许一定的延迟的事务性场景;能最大限度的替代mongodb与传统关系型数据库
##### 索引字段与属性都属于静态设置,若后期变更历史数据需要重建索引才可生效
##### 对历史数据无效!!!!
##### 一定要重建索引!!!!
#### 1、Materialized view 概念介绍
### 概念介绍
## 物化视图名词
# Materialized view
## 物化视图概念介绍
# 将原始数据按照一定规则提前计算好,并存储起来,供其它应用使用,达到高效查询分析的需求
# join/aggs
## 物化数据需求背景
# 原始数据量过大,转换压缩后,节约存储空间,时序数据;
# 聚合压缩后,数据统计检索更快:
## 行业数据产品
# MMP产品: Clickhosue、Greenplum、dorisdb等
### 物化视图技术便利
## 技术便利
# 原有数据压缩,需要自己开发三方应用,或借助三方产品如Spark/Hive,将数据明细聚合之后,存储到ES中,便于查询,需要很多开发工作;
# 2.ES提供的Rollup/Transforms,可以直接将原始数据进行实时的转换,存储到新的索引空间,查询检索更加高效便捷。
### ES物化视图能力
## 自有能力
# 1.Rollup,数据上卷
# 2.Transformer,数据聚合
# 3.自有能力仅限能处理单索引,不能跨多个索引关联
## 外部能力
# 1.基于Spark/Hive/Prestodb查询聚合能力,将多个索引数据关联合并到单个大宽表索引
#### 2、Rollup应用实战
### Rollup概念
# 1.数据上卷,基于时间维度,将原有细粒度时间的数据按照粗一点的粒度汇总,并移除原有的数据;节约存储空间,应用在时序数据领域;
# 2.大数据广告应用产品:Apache Druid
### Rollup应用场景
# 应用场景
# 1.基于时间维度提取预聚合数据,典型的时序数据领域。
# 2.业务数据具备时序特征,都可以运用。
# 3.物联网IOT
# 4.监控系统
# 5.其它
### Rollup接口API
# 1.创建API
# 2.管理维护API3.查询API
## /job/
# PUT /_rollup/job/<job_id>: Create a rollup job
# GET /_rollup/job: List rollup jobs
# GET /_rollup/job/<job_id>: Get rollup job details
# POST /_rollup/job/<job_id>/_start: Start a rollup job
# POST /_rollup/job/<job_id>/_stop: Stop a rollup job
# DELETE /_rollup/job/<job_id>: Delete a rollup job
## /data/
# GET /_rollup/data/<index_pattern>/_rollup_caps: Get Rollup CapabilitiesGET/<index_name>/_rollup/data/: Get Rollup Index Capabilities
## /<index_name>/
# GET/<index_name>/_rollup_search: Search rollup data
# aggs聚合,天维度统计每个洲的销售额
GET kibana_sample_data_ecommerce/_search
{"track_total_hits": true,"size": 0,"aggs": {"date_histogram_order_date": {"date_histogram": {"field": "order_date","calendar_interval": "day"},"aggs": {"terms_continent_name": {"terms": {"field": "geoip.continent_name","size": 100},"aggs": {"stats_taxful_total_price": {"stats": {"field": "taxful_total_price"}}}}}}}
}### 创建rollup
## 通用参数说明
# 创建有 2种方式,一种直接基于 Api,一种基于 Kibana 可视化
# _rollup,创建 Rollup的API接口
# cron,定时任务,cron 表达式
# groups,分组逻辑,支持多个分组分桶函数
# index_pattern,指定索引数据,可以指定多个索引,支持通配符
# metrics,指标数据,分组分桶之后聚合的数据,支持常规的指标聚合
# page_size,分页大小,数据分组时,单页大小,默认1000
# rollup_index,新创建的索引名称,聚合之后的数据从这个所有查询
# timeout,超时时间,任务执行超时时间,默认20s
## groups 参数
# 设定滚动分桶聚合函数,建议采用 date_histogram
# groups,分组逻辑,支持多个分组分桶函数
# 创建
PUT _rollup/job/job_ecommerce_001
{// 数据来源索引"index_pattern": "kibana_sample_data_ecommerce",// 转入的索引"rollup_index": "index_ecommerce_001",// 定时"cron": "*/5 * * * * ?",// 每次统计多少条"page_size": 1000,// 分组条件"groups": {"date_histogram": {"field": "order_date","calendar_interval": "day"},"terms": {"fields": "geoip.continent_name"}},// 需要统计的值"metrics": {// 统计字段"field": "taxful_total_price",// 计算方式"metrics": ["max","min","avg","sum"]}
}
// 查询
GET _rollup/job/job_ecommerce_001// 启动,创建完后需要启动
POST _rollup/job/job_ecommerce_001/_start// 暂停
POST _rollup/job/job_ecommerce_001/_stop
// 删除,需要先暂停了才能删除
DELETE _rollup/job/job_ecommerce_001
# 普通查询数据
GET index_ecommerce_001/_search
{}
# rollup 查询语法,一级分桶
GET index_ecommerce_001/_rollup_search
{"size":0,// 再次根据continent_name聚合"aggs":{"terms_continent_name":{"terms": {"field": "geoip.continent_name"}}}
}
# rollup对比aggs聚合,结果是一样的,但是过程不一样
GET kibana_sample_data_ecommerce/_search
{"track_total_hits": true,"size": 0,"aggs": {"terms_continent_name": {"terms": {"field": "geoip.continent_name","size": 100},"aggs": {"stats_taxful_total_price": {"stats": {"field": "taxful_total_price"}}}}}
}# rollup 查询语法,二级分桶
GET index_ecommerce_001/_rollup_search
{"size":0,"aggs":{"terms_continent_name":{"terms": {"field": "geoip.continent_name"},"aggs": {"max_taxful_total_price": {"max": {"field": "taxful_total_price"}},"min_taxful_total_price": {"min": {"field": "taxful_total_price"}}}}}
}# 基于数据再次统计
GET index_ecommerce_001/_search
{"size":1,"aggs":{"terms_continent_name":{"terms": {"field": "geoip.continent_name.terms.value","size": 100},"aggs": {"NAME": {"sum": {"field": "geoip.continent_name.terms._count"}}}}}
}# 查看有多少个rollup任务
GET _rollup/data/_all# 查看rollup绑定了哪个索引
GET index_ecommerce_001/_rollup/data# 通过索引找rollup
GET _rollup/data/kibana_sample_data_ecommerce
### Rollup分桶支持函数
# 分桶聚合函数支持
# 1.分组分桶Group支持的聚合函数
### 支撑的分桶分组聚合函数:date_histogram、histogram、terms
## Rollup数值聚合计算
# 数值聚合支持函数
# 1.Metric数值聚合函数支持
## 支撑的数值聚合函数:min、max、sum、avg、value_count
### Rollup数据查询限制
# 1.支持的查询表达式与类型
# 支持查询的类型语法 说明
# Term Query 精确词项查询
# Terms Query 精确词项查询
# Range Query 范围查询
# MatchAll Query 默认查询
# Any compound query (Boolean, Boosting, ConstantScore, etc)
### Rollup其它限制
# 其它限制
# 1.一个索引同时仅一个Rollup任务支持
# 2.数据必须有时间字段,建议时支持到毫秒的
### Kibana创建示例
# Kibana创建Kibana提供了可视化,非常方便创建维护
## path:Stack Management -> Rollup Jobs
#### 3、Transforms应用实战
## Transform概念
# 概念解释
# 1.与Rollup类似,将数据转换变化,基于聚合的思维,区别在于,可以不受时间限制,主要是在已有的聚合上做一次预聚合;
# 2.自带Checkpoint机制,可实时的刷新数据。
## Transform应用场景
# 应用场景海量明细数据提前预聚合统计;
# 需要进行二次聚合的数据统计
## Transform操作API
# 操作API
# 创建Transforms
# 维护Transforms
# Create transforms
# Delete transforms
# Get transforms
# Get transforms statistics
# Preview transforms
# Start transforms
# Stop transforms
# Update transforms
### 创建Transform
## 通用参数说明
# transform,创建 Transforms接口,后面参数为任务名称
# description,任务描述,定义转换任务描述
# dest,目标索引,按照规则新生成的索引,只能设定一个索引名称
# frequency,检查原始索引数据是否变化的间隔,最小 1s,建议按照业务需求设定,实际就是定时器,与 Rollup-cron表达式有点类似
# latest,标识数据字段是否最新,
# pivot,数据转换入口参数,包括分组group_by与aggregations聚合统计2部分
# retention_policy,数据保留策略,设置 time,setting
# settings,数据转换性能限制
# source,设置需要转换的索引信息
# sync,数据同步设定
## defer_validation 参数
# 依赖索引有效性验证,取值范围 true/false,默认false
# 部分索引是动态创建,不一定立刻就有
## dest 参数
# 设定目标索引信息
# 目标索引,按照规则新生成的索引,只能设定一个索引名称dest,
# pipeline,设定数据加工管道处理函数名称
## latest 参数
# latest,标识数据字段是否最新,用于判断哪些数据是否变化,便于计算挑选
# unique_key,指定唯一标识数据字段
# sort,设定排序字段
## pivot 参数
# pivot,数据转换入口参数,包括分组group_by与aggregations聚合统计2部分
# group_by,分组分桶字段选择,内部支持多个分组分桶,函数也支持多种,与Rollup不一样
# aggs/aggregations,聚合统计的数据值,一般建议是数值统计,支持多种指标聚合函数
## retention_policy 参数
# retention_policy,设定转换后的数据有效期
# field,指定数据字段
# max_age,设定有效期,可以设置多种维度
## settings 参数
# 设定数据抽取的频率限制
# 限制数据转换对于性能影响
# settings,数据转换性能限制
# docs_per_second,控制查询数据源,单秒阀值,默认无限制,集群任务过多,考虑资源建议限制,若从原数据-次查询过度,会交叉影响原始索引别的业务应用。
# max_page_search _size,默认500,范围【10,10000】,限制组合分桶时的输入数据量,到达这个阀值就开始执行聚合逻辑。防止单次聚合原始数据过多。白话就是每次聚合时,单次数据量尽量别太多。
# dates_as_epoch_milis,设置转换的时间字段是否符合iso 标准,取值范围 true/false、默认 false
## source 参数
# 设置需要转换的索引信息
# source,设置需要转换的索引信息
# index,指定原有索引名称,可以指定多个,支持通配符,最好是同一类索引数据
# query,限定原有数据集合,满足查询过滤条件,详细参考 DSL-query部分
# runtime_mappings,设定运行时字段
## sync 参数
# 设置数据写入到新索引策略
# sync,数据同步设定
# time,时间策略
# delay,间隔写入新索引的时间,默认60s,建议设置稍微大点
# field,设定前后间隔时间对比时参考的字段数据,一般建议设定时间
### 查询案例:按照大洲区域,按照客户性别,统计订单金额数据
GET kibana_sample_data_ecommerce/_search
{"track_total_hits": true,"size": 1,"aggs": {"terms_continent_name": {"terms": {"field": "geoip.continent_name","size": 7,"order": {"_key": "asc"}},"aggs": {"terms_customer_gender": {"terms": {"field": "customer_gender","size": 10},"aggs": {"stats_taxful_total_price": {"stats": {"field": "taxful_total_price"}}}}}}}
}
# 创建Transform
PUT _transform/my-trans-001
{"description": "我的转换-001","source": {"index": "kibana_sample_data_ecommerce","query": {"match_all": {}}},"pivot": {"group_by": {"terms_continent_name": {"terms": {"field": "geoip.continent_name"}},"terms_customer_gender": {"terms": {"field": "customer_gender"}}},"aggregations": {"max_taxful_total_price": {"max": {"field": "@timestamp"}},"min_taxful_total_price": {"min": {"field": "@timestamp"}},"avg_taxful_total_price": {"avg": {"field": "@timestamp"}},"sum_taxful_total_price": {"sum": {"field": "@timestamp"}}}},"dest":{"index":"index-trans-001"},"frequency":"1m","sync":{"time":{"field":"order_date","delay":"60s"}},"settings":{"docs_per_second":500,"max_page_search_size":500}
}
## 启动暂停
# transfroms与 rollup 一样,基于定时运行规则,也需要人为的启动/暂停
# start
POST _transform/my-trans-001/_start
# stop
POST _transform/my-trans-001/_stop## 查询数据
# 查询数据,直接从新索引查询
# _search 查询,与 rollup不一样
GET index-trans-001/_search
{}## 管理维护
# preview
# 在线预览创建后的 transfroms生成的数据
# preview,在线预览
POST _transform/_preview
{#此处与创建内容一样
}## update
# 更新 transform 设置
# _update,在线更新
POST _transform/trans01/_update
{#此处与创建内容一样
}## DELETE
DELETE _transform/<transform_id>
DELETE _transform/my-trans-001## 查询GET
# transforms创建后,就会存储在 ES 之中
# 运行中会产生很多统计信息
# GET transform/<transform id>
# GET transform/<transform_id>,<transform_id>
# GET transform/
# # GET transform/_all
# GET transform/*
## 状态stats
# GET transform/<transform id>/ stats
# GET transform/<transform_id>,<transform_id>/ stats
# GET transform/stats
# GET transform/_all/_stats
# GET transform/*/stats
### Transform 限制
## aggregations聚合函数支持
# 注意高级的聚合函数支持,并非所有的都支持
# 支持计算聚合函数:avg、max、min、sum、bucket_script 管道聚合、cardinality、filter、geo_bounds、geo_centroid、median_absolute_deviation、missing、percentiles、rare_terms、scripted_metric、terms、value_count、weighted_avg
## group_by分桶支持函数
# 限制条件
# 函数限制,并非所有的聚合函数都支持,支持常用的大部分;
# 支持分桶聚合函数:date_histogram、geotile_grid、histogram、terms
## 其它限制条件
# 限制条件
# 1.当前限制单集群1000个数据转换任务iob
### 转换节点设置
# ES为了大规模应用转换,启用了独立的节点角色,需要在节点启动之前配置好
# 参数设置
# 配置文件:{ES_HOME}/config/elasticsearch.yml
# node.roles:[transform]
#### 4、数据转换建议以及经验分享
## 任务数量限制
## 数据转换角色
## 可大规模运用ES分析能力,可有条件的替代市面上部分数据产品
# rollup & transform
# https://www.elastic.co/guide/en/elasticsearch/reference/8.6/data-rollup-transform.html
# rollup
# https://www.elastic.co/guide/en/elasticsearch/reference/8.6/xpack-rollup.html
# rollup-apis
# https://www.elastic.co/guide/en/elasticsearch/reference/8.6/rollup-apis.html
# transforms
# https://www.elastic.co/guide/en/elasticsearch/reference/8.6/transforms.html
# transform-checkpoints 局部更新机制
# https://www.elastic.co/guide/en/elasticsearch/reference/8.6/transform-checkpoints.html
# transform-apis
# https://www.elastic.co/guide/en/elasticsearch/reference/8.6/transform-apis.html
# transforms 节点角色
# https://www.elastic.co/guide/en/elasticsearch/reference/8.6/modules-node.html
# Apache Druid 产品
# https://druid.apache.org
相关文章:

es 3期 第25节-运用Rollup减少数据存储
#### 1.Elasticsearch是数据库,不是普通的Java应用程序,传统数据库需要的硬件资源同样需要,提升性能最有效的就是升级硬件。 #### 2.Elasticsearch是文档型数据库,不是关系型数据库,不具备严格的ACID事务特性ÿ…...

小菜鸟系统学习Python第三天
1.优先级问题: 结论: 幂运算>正负号>加减乘除和整除>比较运算符>逻辑运算符 2.三元运算符 3.assert断言:抛出AssertionError异常 4.for循环 4. 5.break和continue...

七.网络模型
最小(支撑)树问题 最小部分树求解: 破圈法:任取一圈,去掉圈中最长边,直到无圈; 加边法:取图G的n个孤立点{v1,v2,…, vn }作为一个支撑图,从最短…...
)
1170 Safari Park (25)
A safari park(野生动物园)has K species of animals, and is divided into N regions. The managers hope to spread the animals to all the regions, but not the same animals in the two neighboring regions. Of course, they also realize that t…...

数字图像处理:实验五
uu们!大家好,欢迎来到数字图像处理第五章节内容的学习,在本章中有关空间滤波的理论学习是十分重要的,所以建议大家要去用心的学习本章,在之后的传感器的相关图像采集时,不可避免的会有噪声等的影响…...

2024我在csdn走过的路
自我介绍 ✏️博客名✏️: zy_destiny 🌸粉丝数🌸: 1万 🌿擅长领域🌿: 人工智能 👀欢迎访问👀: 我的主页 我的2024 回顾下2024年,起点要从去年写…...

网络安全等级保护基本要求——等保二级
《信息安全技术网络安全等级保护基本要求》GB/T22239-2019 7.1 安全通用要求 7.1.1 安全物理环境 7.1.1.1 物理位置选择 本项要求包括: a) 机房场地应选择在具有防震、防风和防雨等能力的建筑内;b) 机房场地应避免设在建筑物的顶层或地下室,否则应加…...

了解 .mgJSON 文件
.mgJSON (Motion Graphics JSON)是一个基于标准 JSON 格式的文件扩展名,专门用于存储和交换与动态图形、动画和多媒体应用相关的数据。该格式支持静态和动态数据流,能够精确描述动画、物体变换、图形效果等。 .mgJSON 文件通过层级…...

django使用踩坑经历
DRF 使用drf获取序列化后的id visitor_serializer VisitorSaveSerializer(data{…}) if visitor_serializer.is_valid():visitor visitor_serializer.save() visitor_id visitor.pkpostgrepsql踩坑 django使用postgrepsql,使用聚合函数如:sum 等,被…...

【数据分享】1929-2024年全球站点的逐年最低气温数据(Shp\Excel\免费获取)
气象数据是在各项研究中都经常使用的数据,气象指标包括气温、风速、降水、湿度等指标!说到气象数据,最详细的气象数据是具体到气象监测站点的数据! 有关气象指标的监测站点数据,之前我们分享过1929-2024年全球气象站点…...

Leetcode:2239
1,题目 2,思路 循环遍历满足条件就记录,最后返回结果值 3,代码 public class Leetcode2239 {public static void main(String[] args) {System.out.println(new Solution2239().findClosestNumber(new int[]{-4, -2, 1, 4, 8})…...

【FPGA】MIPS 12条整数指令【1】
目录 修改后的仿真结果 修改后的完整代码 实现bgtz、bltz、jalr 仿真结果(有问题) bltz------并未跳转,jCe? 原因是该条跳转语句判断的寄存器r7,在该时刻并未被赋值 代码(InstMem修改前) i…...

Halcon 3D基础知识及常用函数
一、基本概念 1、点云(Point Cloud) 点云是一组3D数据点,每个点由笛卡尔坐标系或其他坐标系中的一个三维坐标表示,它被认为是一组非结构化的三维点,象征着三维物体的几何形状。点云是一种简单、完整的数据结构&#…...

贵金属铟,钌,铱,钯铂铑回收工艺详解
Tulsimer CH-95S 是一款为了从工业废水中去除回收汞和贵金属而专门开发的螯合树脂。 Tulsimer CH-95S 是一款拥有聚乙烯异硫脲官能基的大孔树脂,这种树脂对汞有极高的选择性。它也选 择其他的贵金属,如黄金,铂金和其他铂金族金属。…...

AutoSAR CP RTE 规范核心内容简介以及BswScheduler工作原理解析
一、Autosar CP RTE规范核心内容简介 本规范详细介绍了AUTOSAR运行时环境(RTE)和基本软件调度器(BswScheduler)的软件规范。 研究背景 背景介绍: 这篇文章的研究背景是AUTOSAR(Automotive Open System Architecture…...

Python Pyside6 加Sqlite3 写一个 通用 进销存 系统 初型
图: 说明: 进销存管理系统说明文档 功能模块 1. 首页 显示关键业务数据商品总数供应商总数本月采购金额本月销售金额显示预警信息库存不足预警待付款采购单待收款销售单2. 商品管理 商品信息维护商品编码(唯一标识)商品名称规格型号单位分类进货价销售价库存数量预警…...
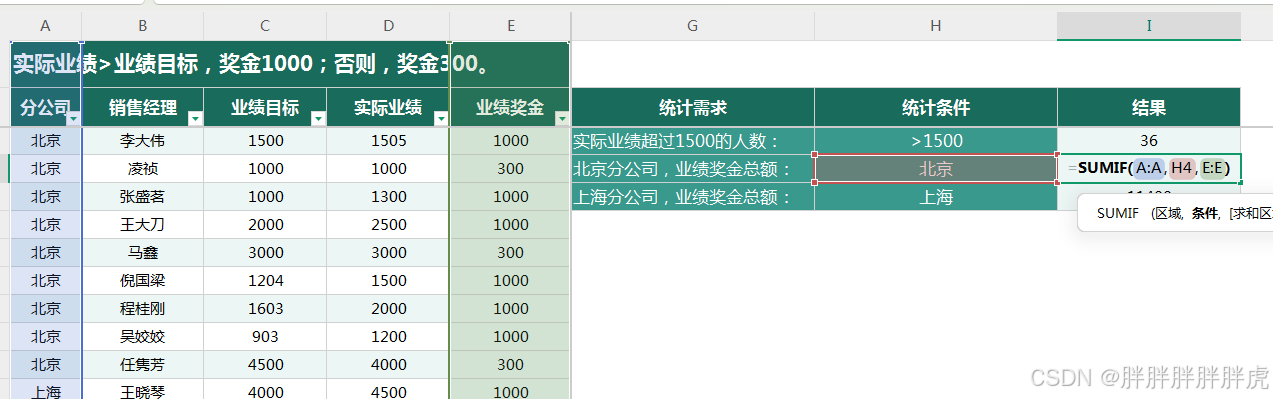
office 学习
Excel 视图 切片 通过视图进行数据分析 条形格式 函数 countif sumif sumifs 多条件 countifs 多条件...

【三维分割】Gaga:通过3D感知的 Memory Bank 分组任意高斯
文章目录 摘要一、引言二、主要方法2.1 3D-aware Memory Bank2.2 三维分割的渲染与下游应用 三、实验消融实验应用: Scene Manipulation 地址:https://www.gaga.gallery 标题:Gaga: Group Any Gaussians via 3D-aware Memory Bank 来源:加利福…...

期权懂|明日股指期货交割日该如何操作?
锦鲤三三每日分享期权知识,帮助期权新手及时有效地掌握即市趋势与新资讯! 明日股指期货交割日该如何操作? 一、需要确认股指期货交割日: 查查看明日是否为交割日,别忘了关注交易所公告,以免错过。 二、需要…...

大牙的2024年创作总结
文章目录 一、自动驾驶通讯协议的学习心得二、PyTorch框架应用的心得体会三、大规模语言模型(LLM)的研究心得四、神经网络架构与实战经验五、我的年度文章六、未来展望与个人成长 引言 2024年是我个人在深度学习和自动驾驶领域不断探索、实践并取得显著…...

AMLP框架实战:基于MACE构建高精度机器学习势函数
1. 项目概述:当机器学习势函数遇上自动化管道在计算化学和材料科学领域,我们长久以来面临着一个核心矛盾:精度与效率的权衡。密度泛函理论(DFT)能提供接近实验的精度,但计算成本高昂,通常只能处…...

亚马逊 Rufus 关停,Alexa 正式上线:卖家必须读懂的6条新规则
2026年5月13日,亚马逊官方正式宣布,下线Rufus,推出全新AI购物助手:Alexa for Shopping。但是,这不是粗暴地直接下线 Rufus,而是一次购物AI底层架构的重组 —— 将 Rufus 的商品专长 与 Alexa的用户理解力&a…...

skills CANN开源社区贡献技能包开发指南
前言 开源社区的健康运转,不仅依赖核心代码的贡献,还需要降低贡献门槛、提供清晰的指南和自动化工具。skills仓库是CANN开源社区的"贡献技能包",提供了一系列辅助脚本、代码模板、CI检查和文档生成工具,帮助新手快速上…...

在多轮对话应用中观察Taotoken计费对成本的影响
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在多轮对话应用中观察Taotoken计费对成本的影响 效果展示类,结合一个需要维护长上下文的多轮对话应用案例,…...

账务台账数据
银行里说的 “账务台账数据”,本质就是按会计规则把每笔业务逐笔、分户、分科目记下来的完整明细流水 余额 辅助信息,核心是 “可逐笔追溯、可对账、可审计” 的一套明细数据。下面用通俗、具体的方式拆开说:一、银行 “账务台账” 到底是什…...

深度解析DeTikZify:科研工作者的智能图表生成神器
深度解析DeTikZify:科研工作者的智能图表生成神器 【免费下载链接】DeTikZify Synthesizing Graphics Programs for Scientific Figures and Sketches with TikZ. 项目地址: https://gitcode.com/gh_mirrors/de/DeTikZify 在科研工作中,创建高质量…...

百度深度学习研究院的“叛将“,带着一颗芯片改变了中国智能驾驶——地平线余凯,从ImageNet冠军到征程出货1000万
大家好,我是写代码的篮球球痴。这篇文章跟我自己有点关系——我开的是理想汽车。理想的智驾系统 AD Pro,搭载的就是地平线征程 5 芯片。2026 年 1 月理想 AD Pro 4.0 推送,基于单颗征程 6M 实现了城市 NOA——这是行业里第一个用单颗 128TOPS…...

特定任务需求场景下的过约束并联机构构型设计与控制方法【附代码】
✨ 长期致力于曲面加工、构型综合、运动学和动力学建模、性能评价、多目标优化、滑模控制、鲁棒控制、视觉传感技术研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (…...

从API调用成功率看Taotoken服务的稳定性与容灾表现
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 从API调用成功率看Taotoken服务的稳定性与容灾表现 在将大模型能力集成到自动化流程或日常开发工具链时,服务的稳定性和…...

别只盯着主控芯片!拆解STM32最小系统板:电源、时钟、复位三大支柱电路深度解析
STM32最小系统板设计进阶:电源、时钟与复位电路的工程实践 在嵌入式系统开发中,我们常常将注意力集中在主控芯片的功能实现上,却忽略了支撑系统稳定运行的三大基础电路——电源、时钟和复位。这些看似简单的电路模块,实则是整个系…...