论文速读|Multi-Modal Disordered Representation Learning Network for TBPS.AAAI24
论文地址:Multi-Modal Disordered Representation Learning Network for Description-Based Person Search
代码地址:未开源(2025.01.22)
bib引用:
@inproceedings{yang2024multi,title={Multi-Modal Disordered Representation Learning Network for Description-Based Person Search},author={Yang, Fan and Li, Wei and Yang, Menglong and Liang, Binbin and Zhang, Jianwei},booktitle={Proceedings of the AAAI Conference on Artificial Intelligence},volume={38},number={15},pages={16316--16324},year={2024}
}
动机:全局方法忽视视觉和文本信息的细粒度细节;局部方法因手工分割或依赖额外模型,忽略了局部特征间的整体对应关系;局部+全局的方法忽视全局特征、依赖额外模型或计算量大且无法端到端训练等问题
解决方案:ViT+BERT(无序局部学习模块+跨模态交互模块)
InShort
提出了一种多模态无序表示学习网络(MDRL),用于基于描述的行人搜索,在CUHK - PEDES和ICFG - PEDES数据集上的实验结果表明,该方法优于现有方法,取得了最先进的性能。
- 研究背景:基于描述的行人搜索旨在通过文本描述检索目标行人的图像,是跨模态学习的关键任务,在公共安全和智能监控等领域意义重大。当前方法存在忽视局部特征全局关系、引入额外模型影响网络性能且无法端到端训练的问题。
- 相关工作
- 行人重识别:多种方法被提出,如分区策略、基于姿态信息的方法、结合整体与局部表示的方法等,但这些方法存在忽视全局特征、依赖额外模型或计算量大等问题。
- 基于描述的行人搜索:许多模型被设计用于完成该任务,部分方法聚焦全局层面,忽视了视觉和文本信息的细粒度细节;一些探索局部特征的方法,因手工分割或依赖额外模型,忽略了局部特征间的整体对应关系。
- 方法
- 总体框架:包含跨模态全局特征学习架构、局部学习模块(LLM)和跨模态交互模块(CIM),使用识别(ID)损失和跨模型投影匹配(CMPM)损失优化模型。
- 跨模态全局特征学习架构:由视觉信息学习分支和文本信息学习分支组成。视觉分支利用视觉Transformer(ViT)提取视觉表示,文本分支使用预训练语言模型BERT结合可学习的Transformer编码器学习文本嵌入。
- 无序局部学习模块:对视觉或文本嵌入令牌序列进行随机打乱和重组,结合全局特征学习局部特征,再通过局部空间Transformer编码器探索局部特征,增强网络的表示学习能力和鲁棒性。
- 跨模态交互模块:由多个跨模态交互Transformer编码器构成,将视觉和文本令牌序列连接并添加可学习的跨模态[cls]嵌入令牌,学习跨模态交互表示,促进两个分支在提取信息时考虑模态间的相关性。
- 实验
- 实验设置:在CUHK - PEDES和ICFG - PEDES数据集上进行评估,采用累积匹配特征曲线(CMC),以Rank - 1、Rank - 5和Rank - 10准确率作为评估指标,对图像和文本进行预处理,设置训练参数。
- 对比实验:与现有先进方法对比,在两个数据集上MDRL均取得最佳性能,在CUHK - PEDES数据集上Rank - 1准确率达74.56% ,比现有最佳方法IRRA高1.18%;在ICFG - PEDES数据集上Rank - 1准确率为65.88% ,比IRRA高2.42%。
- 消融实验:验证了各组件的有效性,无序局部学习模块(DDL)和跨模态交互模块(CIM)能提升性能;确定了可学习Transformer编码器(LTE)、CIM的合适数量,以及视觉和文本信息的最佳分割组数;证明了MDRL的无序分组方法优于传统分割方法。
- 研究结论:提出的MDRL能充分提取有判别力的视觉和文本特征,通过无序局部学习策略和跨模态交互,在不依赖额外辅助模型的情况下,表现出强大的判别表示学习能力,实验结果验证了其优越性。
摘要
基于描述的人物搜索旨在通过文本描述检索目标身份的图像。这项任务的挑战之一是从图像和描述中提取歧视性表示。现有的方法大多采用part based split 方法(基于分割成组件的方法)或外部模型来探索局部特征的细粒度细节,忽略了部分信息之间的全局关系,导致网络不稳定。为了克服这些问题,我们提出了一个多模态无序表示学习网络 (MDRL),用于基于描述的人物搜索,以完全提取视觉和文本表示。具体来说,我们设计了一个跨模态全局特征学习架构,从两种模态中学习全局特征,满足任务的需求。基于我们的全局网络,我们引入了无序局部学习模块,通过无序重组策略从视觉和文本两个方面探索局部特征,增强整个网络的稳健性。此外,我们引入了一个跨模态交互模块,以指导两个流在考虑模态之间的相关性的情况下提取视觉或文本表示。在两个公共数据集上进行了广泛的实验,结果表明,我们的方法在 CUHK-PEDES 和 ICFGPEDES 数据集上优于最先进的方法,并取得了卓越的性能。
Introduction
1.1. 研究现状【局部表征提取的方法大多采用hard split策略忽略了局部-全局之间的关系】
许多方法利用 Local Representation Extract 方案来丰富视觉和文本信息。然而,这些现有的方法大多采用硬分割策略,将视觉和文本表示按部分划分,提取部分信息,忽略了局部特征之间的全局关系。如果仅按局部或短语提取两种模式的局部特征,则将探索每个部分的单个细节,但它们之间的整体相关性将被破坏。例如,当两个不同的行人同时背着白色背包时,有关白色背包的信息几乎不会为行人区分提供有益的帮助。但是,当背包与其他部分线索(如蓝色外套或白色裤子)相关联时,如图 1 所示,包含整体相关性的部分表示将为最终特征的可区分性提供更有力的支持。因此,有必要探索具有全局相关性的部分表示。另一方面,其中一些方法(Wang 等人,2020 年;Jing et al. 2020)在网络中引入了额外的模型,例如语义分割、姿态估计或属性识别,以指导区域的划分。附加模型的准确性直接影响框架的性能,整个网络无法进行端到端的训练。

图 1:现有方法和我们的方法图示。我们设计了一种无序策略,无需额外模型即可增强局部线索的全局相关性,并增强图像/文本特征。
1.2. 本文工作【多模态无序表示学习网络:局部特征重组来学习相关性】
针对上述问题,我们提出了一种基于描述的人物搜索的多模态无序表示学习网络,以提高跨模态模型的学习能力。首先,我们构建了一个强大的跨模态全局特征学习架构来促进任务,它包含一个视觉信息学习分支和一个文本信息学习分支,分别生成图片和文本的特征。为了有效地提取图像和描述中的部分信息,我们将视觉或文本标记序列进行整合,并将它们重新组织成不同的组。与传统的分割方法不同,每组都包含整个图像或描述的随机部分。我们将图像或文本的全局表示与每个组连接起来,以了解局部特征以及来自这些无序标记序列的部分信息之间的相关性。此外,我们将视觉和文本标记序列结合起来,并在训练阶段利用识别损失将它们关联起来,以同时优化两个分支。

图 2:所提出的方法图示。
3. 方法
整体网络在图 2 中展示,框架包含跨模态全局特征学习架构、局部学习模块(LLM)和跨模态交互模块(CIM)。
在训练过程中,训练数据假设为 D = D= D= I r , T r r = 1 G {I_{r}, T_{r}}_{r=1}^{G} Ir,Trr=1G,其中 G 表示每批的图像 - 文本对数量。将行人的图像和描述都输入到全局学习架构中,利用视觉模型和语言模型学习视觉整体表示 f g I f_{g}^{I} fgI和文本全局表示 f g T f_{g}^{T} fgT。
然后,视觉补丁标记序列 f i I ( i ∈ [ 1 , N ] ) {f_{i}^{I}(i \in[1, N])} fiI(i∈[1,N])和文本单词标记序列 f j T ( j ∈ [ 1 , M ] ) {f_{j}^{T}(j \in[1, M])} fjT(j∈[1,M])分别由 LLM 和 CIM 处理,以学习视觉/文本局部特征和跨模态表示,i 和 j 是整数。
最后,结合识别(ID)损失和跨模型投影匹配(CMPM)损失(Zhang and Lu 2018)来监督和优化整个模型。
3.1. 跨模态全局特征学习架构
我们为基于描述的人物搜索构建了一个跨模态全局特征学习架构,其中包含一个视觉信息学习分支和一个文本信息学习分支。该管道如图 2 所示。
3.2. 视觉信息学习分支
我们利用 视觉Transformer(ViT) 提取视觉表示。给定一张图像 I ∈ R ( C × H × W ) I ∈ R^{(C×H×W)} I∈R(C×H×W),其中 C、H 和 W 分别表示图像的通道数、高度和宽度。我们将图像分割为 N 个固定大小的图像块 I i ∣ i ∈ [ 1 , N ] {I_i | i ∈ [1, N]} Ii∣i∈[1,N]。然后这些块被输入视觉骨干网络以学习全局视觉特征 f g f_g fg。
具体而言,我们使用一个线性投影嵌入层将每个图像块映射到 D 维空间,表示为“tokens” x i x_i xi。特征嵌入公式如下: x i = E ( I i ) (1) x_i = E(I_i) \tag{1} xi=E(Ii)(1)其中,E(·) 表示线性投影嵌入层。
为了提取全局视觉表示,额外可学习的 [cls] 嵌入标记 x c l s x_cls xcls 被用于图像块序列的开始位置。由于 Transformer 的特性,平铺后的图像块在一维空间中丢失了原始的局部位置信息,因此我们利用一个可学习的位置嵌入 P ∈ R ( N × D ) P ∈ R^{(N×D)} P∈R(N×D) 来为每个图像块学习位置信息。输入特征序列 X 的公式为: X = ( x c l s ; x 1 ; x 2 ; … ; x N ) + P (2) X = (x_{cls}; x_1; x_2; \dots; x_N) + P \tag{2} X=(xcls;x1;x2;…;xN)+P(2)视觉骨干网络的输出公式为:
F 1 = V ( B ( X ) ) = ( f g 1 ; f g 2 ; … ; f g h ) (3) F^1 = V(B(X)) = (f^1_g; f^2_g; \dots; f^h_g) \tag{3} F1=V(B(X))=(fg1;fg2;…;fgh)(3)其中, F 1 F^1 F1 表示输出的视觉特征序列,V(B(·)) 是视觉骨干网络, f g 1 f^1_g fg1 表示全局视觉特征。
3.3. 文本信息学习分支
为了学习文本表示,我们首先使用预训练的 BERT 模型。给定与行人相关的句子 Y,我们在句子开始和结尾分别添加可学习的 [cls] 和 [sep] 嵌入标记。文本标记序列公式如下: T = ( g c l s ; T 1 ; T 2 ; … ; T M ; g s e p ) (4) T = (g_{cls}; T_1; T_2; \dots; T_M; g_{sep}) \tag{4} T=(gcls;T1;T2;…;TM;gsep)(4)
与文本标记序列类似,位置信息同样重要,因此我们添加可学习的位置嵌入 P 到文本标记序列中。文本分支的输入公式为: Y = ( g c l s ; T 1 ; T 2 ; … ; T M ; g s e p ) + P (5) Y = (g_{cls}; T_1; T_2; \dots; T_M; g_{sep}) + P \tag{5} Y=(gcls;T1;T2;…;TM;gsep)+P(5)
然后,我们将描述的文本序列输入到 BERT 模型中以学习其嵌入标记。值得注意的是,为了进一步增强语言表征能力,我们冻结 BERT 的参数并在其后添加可学习的 Transformer 解码器(LTE)。最终文本分支的输出公式为: F T = T B ( Y ) = ( f 1 T ; f 2 T ; … ; f m T ) (6) F^T = TB(Y) = (f^T_1; f^T_2; \dots; f^T_m) \tag{6} FT=TB(Y)=(f1T;f2T;…;fmT)(6)其中,F^T 表示输出的文本嵌入序列,TB(·) 表示文本分支, f g T f^T_g fgT 表示全局表示。
3.4. 无序局部学习模块
为了从视觉和文本信息中探索行人细节,我们提出了 无序局部学习模块(DLL),如图 3 所示。与传统的硬性分组方式不同,我们在训练期间动态打乱视觉标记序列 f g i ∣ i ∈ [ 1 , N ] {f^i_g | i ∈ [1, N]} fgi∣i∈[1,N] 和文本标记序列 f T j ∣ j ∈ [ 1 , M ] {f^j_T | j ∈ [1, M]} fTj∣j∈[1,M],然后将新的视觉和文本嵌入序列分成 P 和 Q 两组(假设 N 和 M 可以被 P 和 Q 整除)。通过这种随机打乱策略,每次从整体图像描述中选择一些随机嵌入,结合每组学习局部特征。视觉和文本局部标记序列公式如下:
Z g i = ( f g i , 1 , f g i , 2 , … , f g i , p ) , p ∈ [ 1 , P ] , i ∈ [ 1 , N ] ( 7 ) Z^i_g = (f_g^{i,1}, f_g^{i,2}, \dots, f_g^{i,p}), p ∈ [1, P], i ∈ [1, N](7) Zgi=(fgi,1,fgi,2,…,fgi,p),p∈[1,P],i∈[1,N](7)
Z T j = ( f T j , 1 , f T j , 2 , … , f T j , q ) , q ∈ [ 1 , Q ] , j ∈ [ 1 , M ] ( 8 ) Z^j_T = (f_T^{j,1}, f_T^{j,2}, \dots, f_T^{j,q}), q ∈ [1, Q], j ∈ [1, M] (8) ZTj=(fTj,1,fTj,2,…,fTj,q),q∈[1,Q],j∈[1,M](8)
在文本局部序列和视觉局部序列中,分别通过自注意力层和局部共享层进行学习,公式如下:
Z g i = Z g i W q ; Z T j = Z T j W q ( 9 ) Z^i_g = Z^i_gW_q; \quad Z^j_T = Z^j_TW_q (9) Zgi=ZgiWq;ZTj=ZTjWq(9)
F g i = A ⋅ s o f t m a x ( a k T ( W q T / √ d ) ) ( 10 ) F^i_g = A·softmax(a^T_k(W_q^T/√d))(10) Fgi=A⋅softmax(akT(WqT/√d))(10)
F g i = A 0 + M L P ( L N ( A ) ) ( 11 ) F^i_g = A_0 + MLP(LN(A))(11) Fgi=A0+MLP(LN(A))(11)
其中,W_q 是可学习的参数,A 是注意力层, F g i F^i_g Fgi 是局部特征,LN(·) 表示层归一化。
3.5. 跨模态交互模块CIM
虽然图像和文本是不同的模态,但描述同一个人的视觉和文本信息具有很强的相关性。因此,我们提出了一个交叉模态交互模块(CIM)来学习图像和文本的交互表示,这有利于模型对不同的人进行分类,学习两个分支的视觉和文本表示。CIM由K个交叉模态交互变压器编码器(CITE)组成,如图2所示。我们将视觉令牌序列 f i I ∣ i ∈ [ 1 , N ] {f_{i}^{I}|i\in[1, N]} fiI∣i∈[1,N]和文本令牌序列 f j T ∣ j ∈ [ 1 , M ] {f_{j}^{T}|j\in[1,M]} fjT∣j∈[1,M]连接起来,并在重组令牌序列之前添加一个可学习的交叉模态[cls]嵌入令牌 x c l s c x_{c l s}^{c} xclsc来学习交叉模态交互表示。CIM的输入可以表示为
W = x c l s c ; f 1 I ; f 2 I ; … ; f N I ; f 1 T ; f 2 T ; … ; f M T W=x_{c l s}^{c};f_{1}^{I};f_{2}^{I};…;f_{N}^{I};f_{1}^{T};f_{2}^{T};…;f_{M}^{T} W=xclsc;f1I;f2I;…;fNI;f1T;f2T;…;fMT
CITE的输出是
F c = C I T E ( W ) = f c ; f 1 c ; … ; f N c ; f N + 1 c ; … ; f N + M c F_{c}=CITE(W)=f_{c};f_{1}^{c};…;f_{N}^{c};f_{N+1}^{c};…;f_{N+M}^{c} Fc=CITE(W)=fc;f1c;…;fNc;fN+1c;…;fN+Mc其中 F c F_{c} Fc代表交叉模态序列, C I T E ( − ) CITE(-) CITE(−)表示交叉模态交互变压器编码器, f c f_{c} fc为交叉模态交互特征。交叉模态交互特征 f c f_{c} fc通过训练阶段的识别损失处理,很好地优化整个网络,并促进两个分支分别在提取文本或图像信息的过程中考虑模态之间的相关性。
3.6. 损失函数【ID损失+CMPM损失】
4. 实验
Implementation detail. 对所有输入图像进行尺寸调整为 384×128,并且将输入文本的长度统一为 64。接着提到整个网络训练 150 个 epoch,使用随机梯度下降(SGD)优化模型,其中权重衰减为 0.01,动量为 0.9。学习率设置为 7×10⁻⁵,并且在最初的 10 个 epoch 中通过热身技巧初始化学习率。
5. 结论
在本文中,我们提出了一个多模态无序表示学习网络,用于基于描述的人物搜索,以充分提取判别性的视觉和文本特征。通过这个网络,我们通过无序局部学习策略提取判别性局部特征,并通过结合视觉和文本信息来获得交互特征,以推动平行分支感知训练阶段模态之间的相关性。整体框架具有很强的判别表示学习能力,无需任何其他额外的辅助模型。在 CUHKPEDES 和 ICFG-PEDES 数据集上进行了广泛的实验,结果证实我们的方法优于现有的先进方法,并实现了最先进的性能。
相关文章:
论文速读|Multi-Modal Disordered Representation Learning Network for TBPS.AAAI24
论文地址:Multi-Modal Disordered Representation Learning Network for Description-Based Person Search 代码地址:未开源(2025.01.22) bib引用: inproceedings{yang2024multi,title{Multi-Modal Disordered Repres…...

小哆啦解题记:加油站的奇幻冒险
小哆啦解题记:加油站的奇幻冒险 小哆啦开始力扣每日一题的第十三天 https://leetcode.cn/problems/gas-station/description/ 在环形道路上,矗立着一串加油站,宛如等待挑战的谜题。这条路上的每个加油站都有一桶汽油,而开车到下一…...

【前端】CSS实战之音乐播放器
目录 播放器背景旋转音乐封面按钮进度条音量调节音乐信息按钮的效果JavaScript部分播放和暂停音乐切换音乐信息进度条 音量调节避免拖拽时的杂音音量调节条静音和解除静音 自动下一首实现一个小效果最终效果 播放器背景 <div class"play_box"></div>设置…...

Games104——渲染中光和材质的数学魔法
原文链接 渲染方程及挑战 挑战 对于任一给定方向如何获得radiance–阴影 对于光源和表面shading的积分运算(蒙特卡洛积分) 对于反射光多Bounce的无限递归计算 基础光照解决方案 Blinn-Phong模型: 简化阴影 最常见的处理方式就是Shadow M…...

impala增加字段,hsql查不到数据
impala增加字段,插入数据后直接查看文件有值,impala查询是有值的,但是hsq查出来就没有值! Parquet格式的表,在重命名表的列名,或新增列名后,查询重名的列数据时显示当前列所有值为NULL。 原因&a…...

SpringBoot项目中的异常处理
定义错误页面 SpringBoot 默认的处理异常的机制:SpringBoot 默认的已经提供了一套处理异常的机制。一旦程序中出现了异常 SpringBoot 会像/error 的 url 发送请求。在 springBoot 中提供了一个叫 BasicExceptionController 来处理/error 请求,然后跳转到…...
ComfyUI实现老照片修复——AI修复老照片(ComfyUI-ReActor / ReSwapper)尚待完善
AI修复老照片,试试吧,不一定好~~哈哈 2023年4月曾用过ComfyUI,当时就感慨这个工具和虚幻的蓝图很像,以后肯定是专业人玩的。 2024年我写代码去了,AI做图没太关注,没想到,现在ComfyUI真的变成了工…...
)
NLTK命名实体识别(NER)
命名实体识别(Named Entity Recognition, NER)是自然语言处理(NLP)中的一项核心技术,旨在从文本中识别出具有特定意义的实体,如人名、地名、组织名等。通过对文本的自动化处理,NER能够帮助计算机理解和组织大量的非结构化数据,为信息抽取、搜索引擎优化、数据分析等领域…...

【游戏设计原理】78 - 持续注意力
这个原理指出,人类的注意力通常只能维持7至10分钟,因此游戏设计需要根据这一规律进行优化。具体建议包括: 短时间段设计:将游戏体验分解成7到10分钟的任务或场景,以符合玩家的注意力节奏。引入新刺激:在注…...
Android设备:Linux远程lldb调试
更多内容:XiaoJ的知识星球 目录 一、环境准备1.1 安装llvm/NDK1.2 开启lldb-server服务1.3 lldb连接lldb-server 二、使用lldb调试Android native源码2.1 运行调试2.2 .lldbinit文件 下面介绍Android设备(Android手机为例),在Linu…...

多层 RNN原理以及实现
数学原理 多层 RNN 的核心思想是堆叠多个 RNN 层,每一层的输出作为下一层的输入,从而逐层提取更高层次的抽象特征。 1. 单层 RNN 的数学表示 首先,单层 RNN 的计算过程如下。对于一个时间步 t t t,单层 RNN 的隐藏状态 h t h_t…...

[Computer Vision]实验三:图像拼接
目录 一、实验内容 二、实验过程及结果 2.1 单应性变换 2.2 RANSAC算法 三、实验小结 一、实验内容 理解单应性变换中各种变换的原理(自由度),并实现图像平移、旋转、仿射变换等操作,输出对应的单应性矩阵。利用RANSAC算法优…...
)
【Vim Masterclass 笔记22】S09L40 + L41:同步练习11:Vim 的配置与 vimrc 文件的相关操作(含点评课内容)
文章目录 S09L40 Exercise 11 - Vim Settings and the Vimrc File1 训练目标2 操作指令2.1. 打开 vimrc-sample 文件2.2. 尝试各种选项与设置2.3. 将更改内容保存到 vimrc-sample 文件2.4. 将文件 vimrc-sample 的内容复制到寄存器2.5. 创建专属 vimrc 文件2.6. 对于 Mac、Linu…...
模块的 “时光记录仪”)
5.9 洞察 OpenAI - Translator:日志(Logger)模块的 “时光记录仪”
洞察 OpenAI - Translator:日志(Logger)模块的 “时光记录仪” 在开发和生产环境中,日志记录是确保应用程序正常运行和快速调试的核心机制之一。日志模块(Logger)用于记录应用程序的运行信息,包括错误、警告、调试信息、信息性事件等。通过日志,开发者可以实时监控程序…...
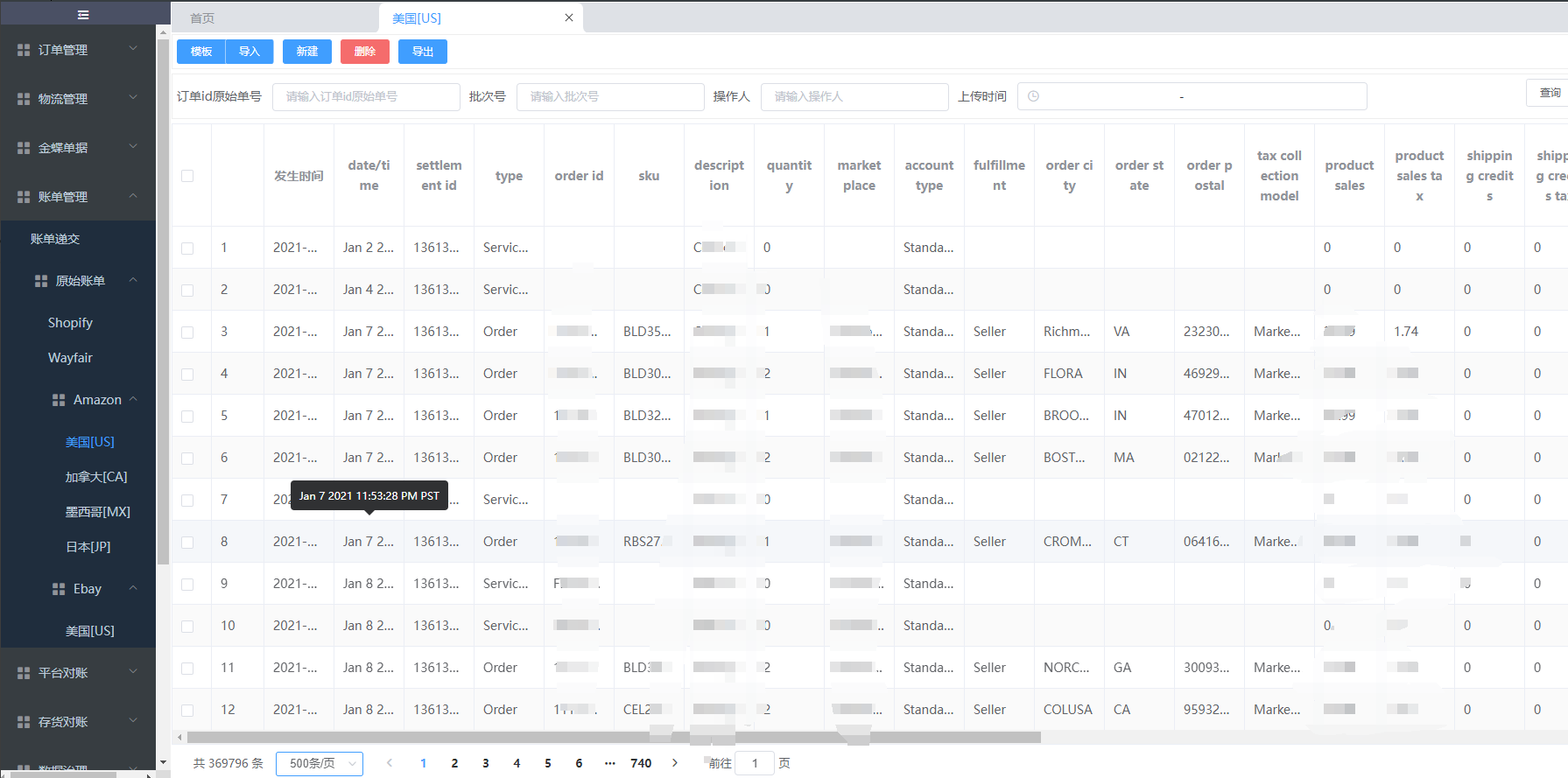
客户案例:电商平台对帐-账单管理(亚马逊amazon)
账单管理: 功能定义: 账单管理用于上传亚马逊(amazon)平台下载的原始账单数据,美国站、日本站、墨西哥站等账单模板直接进行数据上传,做到0调整,下载下来的账单数据无缝上传至对账平台-账单管…...

IP协议特性
在网络层中,最重要的协议就是IP协议,IP协议也有两个特性,即地址管理和路由选择。 1、地址管理 由于IPv4地址为4个字节,所以最多可以支持42亿个地址,但在现在,42亿明显不够用了。这就衍生出下面几个机制。…...

Kubernetes入门学习
kubernetes技术架构模型 一、kubernetes的Label标签 1.标签是以keyvalue的格式通过用户自定义指定,目的是将其加入到各种资源对象上来实现多维度的资源分组管理使其更方便的进行资源分配、调度、配置和部署管理工作。 2.标签可以结合Label Selector(标签选择器)查询…...
支持向量机SVM的应用案例
支持向量机(Support Vector Machine,SVM)是一种强大的监督学习算法,广泛应用于分类和回归任务。 基本原理 SVM的主要目标是周到一个最优的超平面,该超平面能够将不同类别的数据点尽可能分开,并且使离该超平面最近的数…...
Chrome 132 版本新特性
Chrome 132 版本新特性 一、Chrome 132 版本浏览器更新 1. 在 iOS 上使用 Google Lens 搜索 在 Chrome 132 版本中,开始在所有平台上推出这一功能。 1.1. 更新版本: Chrome 126 在 ChromeOS、Linux、Mac、Windows 上:在 1% 的稳定版用户…...
(5)STM32 USB设备开发-USB键盘
讲解视频:2、USB键盘-下_哔哩哔哩_bilibili 例程:STM32USBdevice: 基于STM32的USB设备例子程序 - Gitee.com 本篇为使用使用STM32模拟USB键盘的例程,没有知识,全是实操,按照步骤就能获得一个STM32的USB键盘。本例子是…...

基于2D工程图几何特征与梯度提升模型的制造成本智能预测
1. 项目概述:从图纸到报价的智能革命在制造业,尤其是像汽车零部件这样的离散制造领域,报价速度直接决定了订单的生死。传统上,拿到一张新的2D工程图(DWG格式),成本工程师需要花上几天甚至几周时…...

UE4动画蓝图实战:用双骨骼IK节点搞定手部穿模,附完整蓝图节点截图
UE4动画蓝图实战:双骨骼IK节点解决手部穿模的完整指南在角色动画开发中,手部穿模问题堪称"视觉杀手"。想象一下精心设计的角色挥拳时,拳头直接穿过墙壁或敌人身体——这种违和感足以毁掉整个场景的沉浸感。本文将彻底解决这个痛点&…...

Hitboxer:开源SOCD清理工具,3分钟提升游戏操作精准度
Hitboxer:开源SOCD清理工具,3分钟提升游戏操作精准度 【免费下载链接】socd Key remapper for epic gamers 项目地址: https://gitcode.com/gh_mirrors/so/socd 你是否在激烈的游戏对抗中经历过这样的挫败:同时按下左右方向键时角色卡…...

2026智慧校园规划必读:如何在预算吃紧下选到高性价比方案
✅作者简介:合肥自友科技 📌核心产品:智慧校园平台(包括教工管理、学工管理、教务管理、考务管理、后勤管理、德育管理、资产管理、公寓管理、实习管理、就业管理、离校管理、科研平台、档案管理、学生平台等26个子平台) 。公司所有人员均有多…...

从CTF题看RSA安全:为什么你的密钥不能‘共享素数’?
从CTF实战看RSA密钥安全:那些年我们踩过的坑 在网络安全竞赛和实际渗透测试中,RSA算法的错误实现方式往往成为突破的关键点。本文将通过典型CTF赛题案例,揭示五种常见RSA实现漏洞背后的数学原理和安全启示,帮助开发者在实际项目中…...

基于可解释机器学习的城市人口流动空间降尺度分析实践
1. 项目概述:从宏观到微观,解码城市脉搏在城市的肌理中,人口的流动如同血液的循环,承载着经济活力、社会互动与空间结构的全部信息。无论是城市规划师优化公交线路,还是商业分析师评估店铺选址,亦或是公共卫…...

METSO A413248自动化系统
METSO A413248 自动化系统模块产品特点: 品牌归属:芬兰METSO(美卓)工业自动化系统原装备件。 产品类型:工业级自动化控制模块/接口模块。 核心功能:用于控制信号处理、数据采集及系统集成。 系统兼容&am…...

量子机器学习与傅里叶分析:革新期权定价的混合计算范式
1. 项目概述:当量子机器学习遇见金融定价在金融工程的核心地带,期权定价一直是个计算密集型的硬骨头。传统的蒙特卡洛模拟虽然通用,但为了达到足够的精度,动辄需要百万甚至千万次的路径模拟,计算成本高昂。近年来&…...

qobuz-dl终极实战指南:专业无损音乐下载工具架构解析与高效应用
qobuz-dl终极实战指南:专业无损音乐下载工具架构解析与高效应用 【免费下载链接】qobuz-dl A complete Lossless and Hi-Res music downloader for Qobuz 项目地址: https://gitcode.com/gh_mirrors/qo/qobuz-dl 在数字音乐时代,追求极致音质的音…...

基于Arduino Uno与MQ-2传感器的智能气体检测报警系统DIY全攻略
1. 项目概述与核心思路最近在捣鼓家里的智能安防,琢磨着能不能自己做一个成本可控、反应灵敏的气体检测报警装置。市面上成品烟雾报警器虽然成熟,但要么功能单一,要么价格不菲,而且很难根据自己的需求进行定制化调整,比…...