K8S中Service详解(一)
Service介绍
在Kubernetes中,Service资源解决了Pod IP地址不固定的问题,提供了一种更稳定和可靠的服务访问方式。以下是Service的一些关键特性和工作原理:
-
Service的稳定性:由于Pod可能会因为故障、重启或扩容而获得新的IP地址,直接使用Pod的IP来访问服务是不可靠的。Service通过提供一个固定的虚拟IP(ClusterIP)作为访问入口,使得服务访问变得更加稳定。
-
Service的类型:Kubernetes支持不同类型的Service,包括ClusterIP、NodePort、LoadBalancer和ExternalName,每种类型适用于不同的访问场景:
-
ClusterIP:为Service在集群内部提供一个固定的虚拟IP,只有集群内部的客户端可以访问此服务。
-
NodePort:在所有节点的特定端口上公开Service,使得外部可以通过
<NodeIP>:<NodePort>访问服务。 -
LoadBalancer:在NodePort的基础上,通过云服务商的负载均衡器对外提供服务,适用于公有云环境。
-
ExternalName:将服务映射到外部服务的DNS名称,不通过kube-proxy进行代理。
-
-
Service的负载均衡:Service可以对关联的Pod进行轮询或随机的负载均衡,使得请求可以均匀地分发到各个Pod上。
-
Service的发现机制:Kubernetes中的Pod可以通过DNS或环境变量来发现Service。通过DNS,Pod可以通过Service的名称和命名空间来解析Service的ClusterIP。
-
Service和Pod的关系:Service通过标签选择器(label selector)与一组Pod关联。当Service创建后,kube-proxy或相关的网络插件会监控Pod的变化,并更新Service的后端列表(Endpoints。
-
Headless Service:一种特殊的Service,不分配ClusterIP,而是通过DNS返回Pod的IP列表,适用于需要直接访问每个Pod的场景,如StatefulSets。
-
Service的端口:Service可以定义一个或多个端口,将外部请求映射到Pod的特定端口上。端口分为Service端口(port)、Pod端口(targetPort)和NodePort(仅NodePort类型Service)

-
Service在很多情况下只是一个概念,真正起作用的其实是kube-proxy服务进程,每个Node节点上都运行着一个kube-proxy服务进程。当创建Service的时候会通过api-server向etcd写入创建的service的信息,而kube-proxy会基于监听的机制发现这种Service的变动,然后它会将最新的Service信息转换成对应的访问规则。

kube-proxy三种工作模式
1. Userspace 模式
工作原理:
kube-proxy在用户空间中运行,为每个 Service 创建一个监听端口,将发向ClusterIP的请求通过iptables规则重定向到kube-proxy的监听端口,然后kube-proxy根据负载均衡算法选择一个后端 Pod,将流量转发到 Pod。
优点:
- 简单稳定:实现简单,适用于负载较低或要求不高的场景。
- 负载均衡算法灵活:支持不同的负载均衡算法,如轮询、随机等。
- 易于调试:由于运行在用户空间,问题较容易排查。
缺点:
- 性能较低:每个请求都需要从内核空间经过用户空间进行转发,导致性能开销大,尤其是在高流量环境下。
- 延迟较高:数据包需要在内核空间和用户空间之间来回拷贝,增加了延迟。
- 不能进行智能重试:无法像
iptables和ipvs模式那样自动重试不可用的 Pod。
应用场景:
- 低负载环境:适用于流量较小的 Kubernetes 集群,或者不对性能要求极高的应用场景。
- 调试与开发:在开发和调试阶段使用,便于排查问题。
2. iptables 模式
工作原理:
kube-proxy为每个 Service 后端的 Pod 创建对应的iptables规则,流量直接通过网络路由到相应的 Pod,而不经过kube-proxy进程本身。
优点:
- 性能较好:与
userspace模式相比,避免了用户空间和内核空间之间的数据拷贝,提高了性能。 - 低延迟:直接修改内核中的路由规则,减少了处理过程中的开销,转发效率更高。
- 简单高效:不需要额外的代理进程,适合大规模集群。
缺点:
- 负载均衡策略简单:只能通过简单的轮询方式进行负载均衡,无法实现更复杂的负载均衡算法(如基于连接数或源 IP)。
- 重试机制缺失:如果选定的 Pod 不可用,流量会被丢弃,不会自动重试。
- 安全性问题:流量直接路由到 Pod,可能暴露给不受信任的网络,需要额外配置网络策略。
应用场景:
- 高性能需求的应用:对于需要较高性能且负载均衡需求较简单的应用非常适合,如微服务架构中的 HTTP 或 DNS 服务。
- 规模较大的集群:对于大规模集群,
iptables模式因其性能优势而被广泛使用。
3. ipvs 模式
工作原理:
kube-proxy在内核空间使用ipvs进行负载均衡,监控 Pod 和 Service 的变化,并将相应的规则实时同步到ipvs中。
优点:
- 性能最佳:
ipvs在内核空间实现,避免了用户空间和内核空间的数据拷贝,提供极高的转发性能,尤其在高负载和大规模集群中表现优异。 - 丰富的负载均衡算法:支持多种负载均衡算法,包括轮询、最小连接、源 IP 哈希等,能够满足更多复杂的负载均衡需求。
- 会话保持:支持基于客户端 IP 或会话的会话保持,使得某些需要维持会话状态的应用(如 Web 应用)能够始终路由到同一 Pod。
- 健康检查:可以基于 Pod 的健康状态进行流量路由,只将流量发送到健康的 Pod 上,提升可用性。
- SNAT 优化:优化源地址转换(SNAT),对
NodePort或LoadBalancer类型的服务尤其有效。 - 直接路由:通过直接路由减少了网络地址转换(NAT)开销,进一步提高了性能。
缺点:
- 配置复杂:相较于
iptables,ipvs模式的配置和维护稍微复杂。 - 内核依赖:需要内核支持
ipvs,如果内核版本过低或未开启ipvs支持,无法使用此模式。
应用场景:
- 高性能要求的集群:适用于大规模、需要高吞吐量和低延迟的 Kubernetes 集群。
- 复杂的负载均衡需求:适合需要多种负载均衡算法和会话保持机制的场景,例如大规模 Web 应用、数据库负载均衡等。
- 高可用性要求:支持健康检查和流量路由到健康 Pod,提高应用的可用性。
总结对比:
| 模式 | 性能 | 配置复杂度 | 支持的负载均衡算法 | 会话保持 | 健康检查 | 重试机制 | 应用场景 |
|---|---|---|---|---|---|---|---|
| Userspace | 较差 | 简单 | 简单(轮询等) | 不支持 | 不支持 | 支持 | 低负载环境,开发调试阶段 |
| iptables | 较好 | 中等 | 简单(轮询) | 不支持 | 不支持 | 不支持 | 高性能、简单需求、大规模集群 |
| ipvs | 最好 | 较复杂 | 多种(轮询、最小连接等) | 支持 | 支持 | 支持 | 高性能、高可用、大规模集群 |
相关文章:
K8S中Service详解(一)
Service介绍 在Kubernetes中,Service资源解决了Pod IP地址不固定的问题,提供了一种更稳定和可靠的服务访问方式。以下是Service的一些关键特性和工作原理: Service的稳定性:由于Pod可能会因为故障、重启或扩容而获得新的IP地址&a…...
)
Effective C++读书笔记——item23(用非成员,非友元函数取代成员函数)
一、主要观点: 在某些情况下,使用 non-member、non-friend 函数来替换 member 函数可以增强封装性和可扩展性,提供更好的软件设计。 二、详细解释: 封装性: 类成员函数的封装性考量:成员函数可以访问类的…...

云原生前端开发:打造现代化高性能的用户体验
引言:前端开发的新风向 在过去的几年中,前端开发领域经历了快速的演变,从早期的静态网页到如今复杂的单页应用(SPA),再到微前端架构和渐进式Web应用(PWA),前端技术一直处…...

循环队列(C语言版)
循环队列(C语言版) 1.简单介绍循环队列2.使用何种结构来实现3.基本结构4.初始化5.判空判满6.向循环队列插入一个元素7.从循环队列中删除一个元素8.获取队头队尾元素9.释放空间10.完整代码 🌟🌟hello,各位读者大大们你们好呀&#…...

考研408笔记之数据结构(五)——图
数据结构(五)——图 1. 图的基本概念 1.1 图的定义 1.2 有向图和无向图 在有向图中,使用圆括号表示一条边,圆括号里元素位置互换没有影响。 在无向图中,使用尖括号表示一条边,尖括号里元素位置互换则表示…...

没有公网IP实现seafile本地IP访问和虚拟局域网IP同时访问和上传文件
前言 Ubuntu 24.04 LTSDocker 安装 seafileOpenWrtTailscale Ubuntu 24.04 LTS 通过 docker desktop 安装 seafile 搭建个人网盘中,已经实现了本地局域网放问Ubuntu IP来访问Seafile,以及通过 Ubuntu 的 Tailscale IP 访问Seafile。但是,文…...

【Hadoop面试题2025】
文章目录 简单题故障及相应的处理方法中等难度高难度小文件小文件的产生小文件问题的影响小文件治理方案推荐方案 冷文件冷文件的产生冷文件问题的影响冷文件治理方案推荐方案 简单题 一、基础概念类 什么是Hadoop? 答案:Hadoop是一个开源的分布式计算框…...

2000-2010年各省第三产业就业人数数据
2000-2010年各省第三产业就业人数数据 1、时间:2000-2010年 2、来源:统计年鉴、各省年鉴 3、指标:行政区划代码、地区、年份、第三产业就业人员数(万人) 4、范围:31省 5、指标解释:第三产业…...
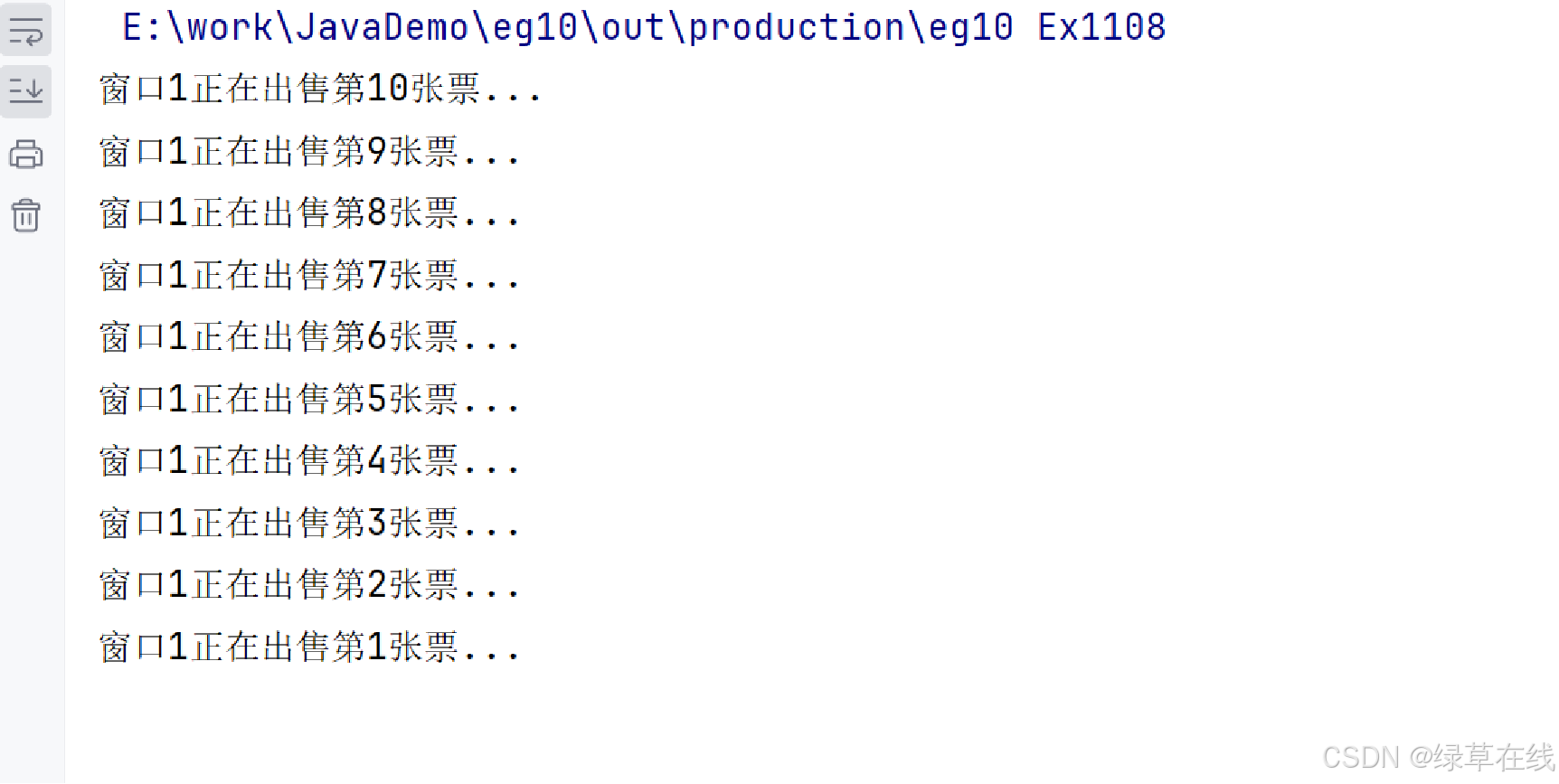
第十一讲 多线程
多线程是提升程序性能非常重要的一种方式,也是Java编程中的一项重要技术。在程序设计中,多线程就是指一个应用程序中有多条并发执行的线索,每条线索都被称作一个线程,它们会交替执行,彼此间可以进行通信。 1. 进程与线…...
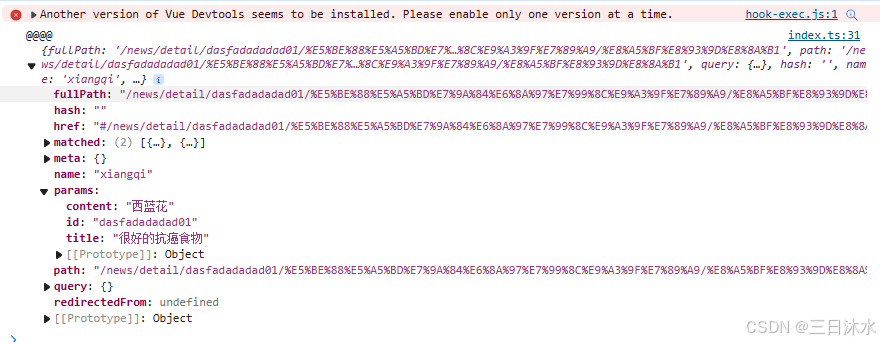
VUE之路由Props、replace、编程式路由导航、重定向
目录 1、路由_props的配置 2、路由_replaces属性 3、编程式路由导航 4、路由重定向 1、路由_props的配置 1)第一种写法,将路由收到的所有params参数作为props传给路由组件 只能适用于params参数 // 创建一个路由器,并暴露出去// 第一步…...

windows安装ES
1. 下载ES 访问ES官网下载Download Elasticsearch | Elastic 2. 配置环境变量 ES_JAVA_HOME : D:\jdk-17.0.9 ES_HOME : D:\elasticsearch-8.17.1-windows-x86_64\elasticsearch-8.17.1 3. 添加一些ES的配置 <1>关闭ES安全认证 打开elasticsearch-8.17.1\config\e…...

论文速读|Multi-Modal Disordered Representation Learning Network for TBPS.AAAI24
论文地址:Multi-Modal Disordered Representation Learning Network for Description-Based Person Search 代码地址:未开源(2025.01.22) bib引用: inproceedings{yang2024multi,title{Multi-Modal Disordered Repres…...

小哆啦解题记:加油站的奇幻冒险
小哆啦解题记:加油站的奇幻冒险 小哆啦开始力扣每日一题的第十三天 https://leetcode.cn/problems/gas-station/description/ 在环形道路上,矗立着一串加油站,宛如等待挑战的谜题。这条路上的每个加油站都有一桶汽油,而开车到下一…...

【前端】CSS实战之音乐播放器
目录 播放器背景旋转音乐封面按钮进度条音量调节音乐信息按钮的效果JavaScript部分播放和暂停音乐切换音乐信息进度条 音量调节避免拖拽时的杂音音量调节条静音和解除静音 自动下一首实现一个小效果最终效果 播放器背景 <div class"play_box"></div>设置…...

Games104——渲染中光和材质的数学魔法
原文链接 渲染方程及挑战 挑战 对于任一给定方向如何获得radiance–阴影 对于光源和表面shading的积分运算(蒙特卡洛积分) 对于反射光多Bounce的无限递归计算 基础光照解决方案 Blinn-Phong模型: 简化阴影 最常见的处理方式就是Shadow M…...

impala增加字段,hsql查不到数据
impala增加字段,插入数据后直接查看文件有值,impala查询是有值的,但是hsq查出来就没有值! Parquet格式的表,在重命名表的列名,或新增列名后,查询重名的列数据时显示当前列所有值为NULL。 原因&a…...

SpringBoot项目中的异常处理
定义错误页面 SpringBoot 默认的处理异常的机制:SpringBoot 默认的已经提供了一套处理异常的机制。一旦程序中出现了异常 SpringBoot 会像/error 的 url 发送请求。在 springBoot 中提供了一个叫 BasicExceptionController 来处理/error 请求,然后跳转到…...
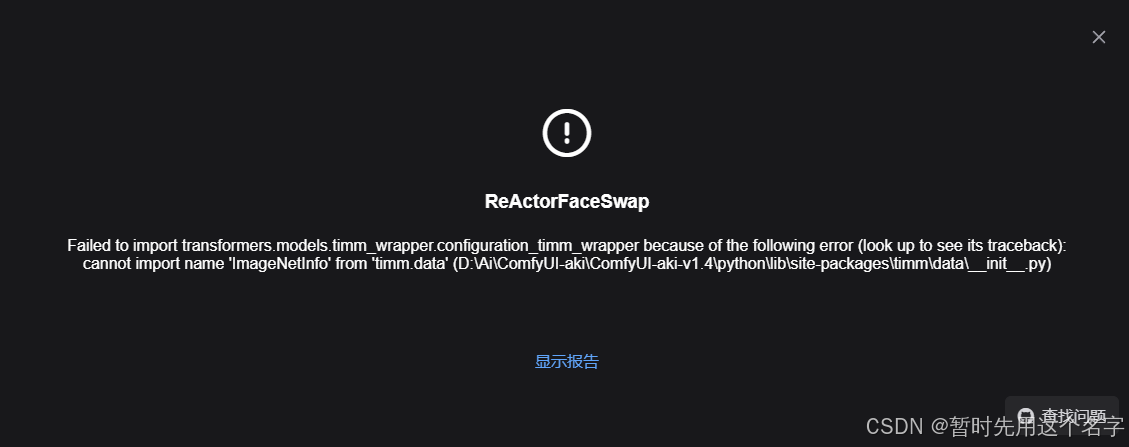
ComfyUI实现老照片修复——AI修复老照片(ComfyUI-ReActor / ReSwapper)尚待完善
AI修复老照片,试试吧,不一定好~~哈哈 2023年4月曾用过ComfyUI,当时就感慨这个工具和虚幻的蓝图很像,以后肯定是专业人玩的。 2024年我写代码去了,AI做图没太关注,没想到,现在ComfyUI真的变成了工…...
)
NLTK命名实体识别(NER)
命名实体识别(Named Entity Recognition, NER)是自然语言处理(NLP)中的一项核心技术,旨在从文本中识别出具有特定意义的实体,如人名、地名、组织名等。通过对文本的自动化处理,NER能够帮助计算机理解和组织大量的非结构化数据,为信息抽取、搜索引擎优化、数据分析等领域…...

【游戏设计原理】78 - 持续注意力
这个原理指出,人类的注意力通常只能维持7至10分钟,因此游戏设计需要根据这一规律进行优化。具体建议包括: 短时间段设计:将游戏体验分解成7到10分钟的任务或场景,以符合玩家的注意力节奏。引入新刺激:在注…...

强化学习在并行机构人形机器人控制中的应用
1. 项目概述在机器人控制领域,强化学习(RL)正逐渐成为解决复杂动力学系统问题的有力工具。然而,当面对具有并行驱动机构的人形机器人时,传统RL训练方法往往面临一个关键挑战:大多数仿真环境无法准确模拟闭环运动链(Closed Kinemat…...

抖音数字资产管理方法论:构建个人内容沉淀系统的技术实践
抖音数字资产管理方法论:构建个人内容沉淀系统的技术实践 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback su…...

App Inventor蓝牙调试避坑指南:从连接失败到数据乱码,一次讲清所有常见问题
App Inventor蓝牙调试避坑指南:从连接失败到数据乱码的实战解决方案在移动应用开发领域,蓝牙通信一直是实现设备间短距离数据交换的核心技术之一。对于使用App Inventor的开发者而言,蓝牙模块提供了无需复杂编码即可实现无线通信的便捷途径。…...

政企数据安全:危机与出路
随着数字化转型的浪潮席卷全球,公共部门积累的数据量呈爆炸式增长。从公民个人信息到公共服务记录,从财政预算到基础设施管理数据——这些宝贵资源在提升政府治理效率的同时,也悄然成为网络犯罪分子的“新猎物”。当公共数据逐渐成为数字时代…...

对比 Token Plan 与按量计费在 Taotoken 平台上的成本体感差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比 Token Plan 与按量计费在 Taotoken 平台上的成本体感差异 对于个人开发者或项目管理者而言,在接入大模型服务时&a…...

写论文的神助攻!好用的AI写作辅助软件,逻辑清晰质量高
作为一名刚完成毕业论文的过来人,我太懂写论文的痛苦了 —— 选题迷茫、文献浩如烟海、框架混乱、逻辑不清、反复修改、查重降重反复折腾... 直到我发现了这套 AI 写作工具组合,简直是论文写作的 "开挂神器",效率直接拉满ÿ…...

MongoDB Limit 与 Skip 方法详解
MongoDB Limit 与 Skip 方法详解 引言 MongoDB 是一个高性能、可伸缩的文档存储系统,它提供了强大的数据存储和查询功能。在处理大量数据时,Limit 与 Skip 方法是 MongoDB 中常用的查询优化工具。本文将详细介绍 MongoDB 中的 Limit 与 Skip 方法,包括其基本用法、性能影响…...

为什么鸿蒙 App 最终都会走向状态驱动?
子玥酱 (掘金 / 知乎 / CSDN / 简书 同名) 大家好,我是 子玥酱,一名长期深耕在一线的前端程序媛 👩💻。曾就职于多家知名互联网大厂,目前在某国企负责前端软件研发相关工作,主要聚…...
)
告别硬编码!在UE5.1里用蓝图动态配置MySQL连接参数(控件蓝图实战)
动态配置MySQL连接:UE5.1控件蓝图的工程化实践在游戏开发中,数据库连接往往是项目架构中不可或缺的一环。传统硬编码方式虽然简单直接,却带来了维护困难、安全性差、灵活性低等一系列问题。本文将深入探讨如何在UE5.1中构建一个完全动态化的M…...

在Hermes Agent项目中接入Taotoken作为自定义模型供应商
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Hermes Agent项目中接入Taotoken作为自定义模型供应商 基础教程类,针对使用Hermes Agent框架的开发者,详…...