深度学习|表示学习|卷积神经网络|参数共享是什么?|07
如是我闻: Parameter Sharing(参数共享)是卷积神经网络(CNN)的一个重要特性,帮助它高效地处理数据。参数共享的本质就是参数“本来也没有变过”。换句话说,在卷积层中,卷积核的参数(权重和偏置)是固定不变的,在整个输入上重复使用。

什么是参数共享(Parameter Sharing)?
参数共享 是指:
在卷积层中,同一个卷积核(filter)在整个输入图像上重复使用,计算所有局部区域的特征。
换句话说:
- 对于每一层的卷积操作,同一个卷积核的权重在图像的不同位置是相同的。
- 这样,模型在处理不同位置的局部区域时,使用的是相同的参数(权重)。
参数共享是如何实现的?
1. 卷积核在空间维度上的滑动:
- 假设输入是一个 32 × 32 32 \times 32 32×32的图像,卷积核大小为 3 × 3 3 \times 3 3×3:
- 卷积核会从左上角开始,逐步在图像上滑动(移动一个步长),对每个 3 × 3 3 \times 3 3×3 区域执行点积计算。
- 在滑动过程中,卷积核的参数(权重和偏置)保持不变。
- 这样,卷积核在整个图像上提取相同类型的特征(例如边缘、纹理等)。
2. 跨通道的参数共享:
- 如果输入图像有多个通道(例如 RGB 图像有 3 个通道),每个卷积核的深度与输入的通道数相同。
- 卷积核的权重在所有输入通道上共享,并综合每个通道的特征,生成一个输出值。
3. 多个卷积核产生多个特征图:
- 一层可以有多个卷积核(比如 64 个),每个卷积核学习不同的特征。
- 每个卷积核的参数是独立的,但它本身的参数在输入的不同位置是共享的。
为什么要使用参数共享?
1. 减少参数数量:
- 全连接层:
如果输入是 32 × 32 32 \times 32 32×32 的图像,假设有 1 个神经元连接整个图像,则需要 32 × 32 = 1024 32 \times 32 = 1024 32×32=1024 个参数。如果有 1000 个神经元,则需要 1024 × 1000 = 1 , 024 , 000 1024 \times 1000 = 1,024,000 1024×1000=1,024,000个参数。 - 卷积层:
使用一个大小为 3 × 3 3 \times 3 3×3的卷积核,它只有 3 × 3 = 9 3 \times 3 = 9 3×3=9 个参数(再加一个偏置,共 10 个参数),而它可以在整个图像上滑动重复使用。
因此,参数共享大幅减少了模型的参数数量,使模型更容易训练,并减少过拟合的风险。
2. 捕获空间不变性:
- 自然数据(如图像)中的某些特征是局部的和重复的。例如,边缘、角点或纹理可能出现在图像的不同位置。
- 参数共享允许卷积核在整个图像上“搜索”这些特征,而无需为每个位置单独训练一组参数。
3. 提高计算效率:
- 共享参数减少了计算量,因为在整个输入上重复使用相同的权重,而不是为每个位置训练独立的权重。
参数共享的一个具体示例
输入:
- 假设输入是一个 32 × 32 × 3 32 \times 32 \times 3 32×32×3的 RGB 图像。
卷积核:
- 使用一个大小为 3 × 3 × 3 3 \times 3 \times 3 3×3×3 的卷积核。
- 该卷积核有 3 × 3 × 3 = 27 3 \times 3 \times 3 = 27 3×3×3=27 个权重,加上 1 个偏置参数,总共有 28 个参数。
滑动操作:
- 卷积核会从左上角开始,在整个图像上滑动,逐步提取特征。
- 对于每个 3 × 3 × 3 3 \times 3 \times 3 3×3×3 的局部区域,卷积核会执行点积计算,并生成一个输出值。
- 卷积核的 28 个参数在整个 32 × 32 × 3 32 \times 32 \times 3 32×32×3 的输入上是共享的。
输出:
- 如果输出特征图的大小是 30 × 30 30 \times 30 30×30(假设没有填充),那么整个输出中包含 30 × 30 = 900 30 \times 30 = 900 30×30=900 个值,这 900 个值是由同一个卷积核生成的。
没有参数共享会怎样?
假如没有参数共享,每个位置的感受野都需要一个独立的卷积核参数:
- 如果输入是 32 × 32 × 3 32 \times 32 \times 3 32×32×3,卷积核大小为 3 × 3 × 3 3 \times 3 \times 3 3×3×3,输出大小是 30 × 30 × 1 30 \times 30 \times 1 30×30×1,那么:
- 每个位置需要独立的 3 × 3 × 3 = 27 3 \times 3 \times 3 = 27 3×3×3=27个参数。
- 总参数数目为 30 × 30 × 27 = 24 , 300 30 \times 30 \times 27 = 24,300 30×30×27=24,300。
相比之下,使用参数共享时,卷积核只需要 28 个参数(包含偏置),参数大幅减少。
卷积层的参数共享 vs 全连接层
| 特性 | 卷积层(参数共享) | 全连接层(无参数共享) |
|---|---|---|
| 连接方式 | 每个卷积核只与局部区域相连,参数共享 | 每个神经元与输入的所有单元相连 |
| 参数数量 | 参数数量较少,参数共享 | 参数数量多,与输入规模成正比 |
| 特征提取能力 | 强调局部特征(如边缘、纹理),支持平移不变性 | 更适合全局特征,不支持局部模式提取 |
| 计算效率 | 更高,因为参数共享且局部连接 | 计算开销大,特别是高维输入 |
总的来说
-
参数共享的本质:
卷积核的权重在输入数据的不同区域共享,从而减少参数数量并提高计算效率。 -
带来的优势:
- 参数数量减少,更易训练。
- 特征共享,对输入的不同位置学习相同的模式。
- 提高模型的泛化能力,降低过拟合风险。
以上
相关文章:
深度学习|表示学习|卷积神经网络|参数共享是什么?|07
如是我闻: Parameter Sharing(参数共享)是卷积神经网络(CNN)的一个重要特性,帮助它高效地处理数据。参数共享的本质就是参数“本来也没有变过”。换句话说,在卷积层中,卷积核的参数&…...

基于相机内参推导的透视投影矩阵
基于相机内参推导透视投影矩阵(splatam): M c a m [ 2 ⋅ f x w 0.0 ( w − 2 ⋅ c x ) w 0.0 0.0 2 ⋅ f y h ( h − 2 ⋅ c y ) h 0.0 0 0 f a r n e a r n e a r − f a r 2 f a r ⋅ n e a r n e a r − f a r 0.0 0.0 − 1.0 0.0 ] M_…...

浅析Dubbo 原理:架构、通信与调用流程
一、Dubbo 简介 Dubbo 是阿里巴巴开源的高性能、轻量级的 Java RPC(Remote Procedure Call,远程过程调用)框架,旨在实现不同服务之间的远程通信和调用。在分布式系统中,不同服务可能部署在不同的服务器上,D…...

03垃圾回收篇(D3_垃圾收集器的选择及相关参数)
目录 学习前言 一、收集器的选择 二、GC日志参数 三、垃圾收集相关的常用参数 四、内存分配与回收策略 1. 对象优先在Eden分配 2. 大对象直接进入老年代 3. 长期存活的对象将进入老年代 4. 动态对象年龄判定 5. 空间分配担保 学习前言 本章主要学习垃圾收集器的选择及…...

一、引论,《组合数学(第4版)》卢开澄 卢华明
零、前言 发现自己数数题做的很烂,重新学一遍组合数学吧。 参考卢开澄 卢华明 编著的《组合数学(第4版)》,只打算学前四章。 通过几个经典问题来了解组合数学所研究的内容。 一、幻方问题 据说大禹治水之前,河里冒出来一只乌龟,…...

Vue3+TS 实现批量拖拽文件夹上传图片组件封装
1、html 代码: 代码中的表格引入了 vxe-table 插件 <Tag /> 是自己封装的说明组件 表格列表这块我使用了插槽来增加扩展性,可根据自己需求,在组件外部做调整 <template><div class"dragUpload"><el-dialo…...
)
二叉树的所有路径(力扣257)
因为题目要求路径是从上到下的,所以最好采用前序遍历。这样可以保证按从上到下的顺序将节点的值存入一个路径数组中。另外,此题还有一个难点就是如何求得所有路径。为了解决这个问题,我们需要用到回溯。回溯和递归不分家,每递归一…...
缓存)
Python OrderedDict 实现 Least Recently used(LRU)缓存
OrderedDict 实现 Least Recently used(LRU)缓存 引言正文 引言 LRU 缓存是一种缓存替换策略,当缓存空间不足时,会移除最久未使用的数据以腾出空间存放新的数据。LRU 缓存的特点: 有限容量:缓存拥有固定的…...

LabVIEW项目中的工控机与普通电脑选择
工控机(Industrial PC)与普通电脑在硬件设计、性能要求、稳定性、环境适应性等方面存在显著差异。了解这些区别对于在LabVIEW项目中选择合适的硬件至关重要。下面将详细分析这两种设备的主要差异,并为LabVIEW项目中的选择提供指导。 硬件设…...
Ansys Speos | Speos Meshing 网格最佳实践
概述 网格划分是在各种计算应用中处理3D几何的基本步骤: 表面和体积:网格允许通过将复杂的表面和体积分解成更简单的几何元素(如三角形、四边形、四面体或六面体)来表示复杂的表面和体积。 模拟和渲染:网格是创建离散…...

elasticsearch segment数量对读写性能的影响
index.merge.policy.segments_per_tier 是一个配置选项,用于控制 Elasticsearch 中段(segment)合并策略的行为。它定义了在每一层的段合并过程中,允许存在的最大段数量。调整这个参数可以优化索引性能和资源使用。 假设你有一个索…...
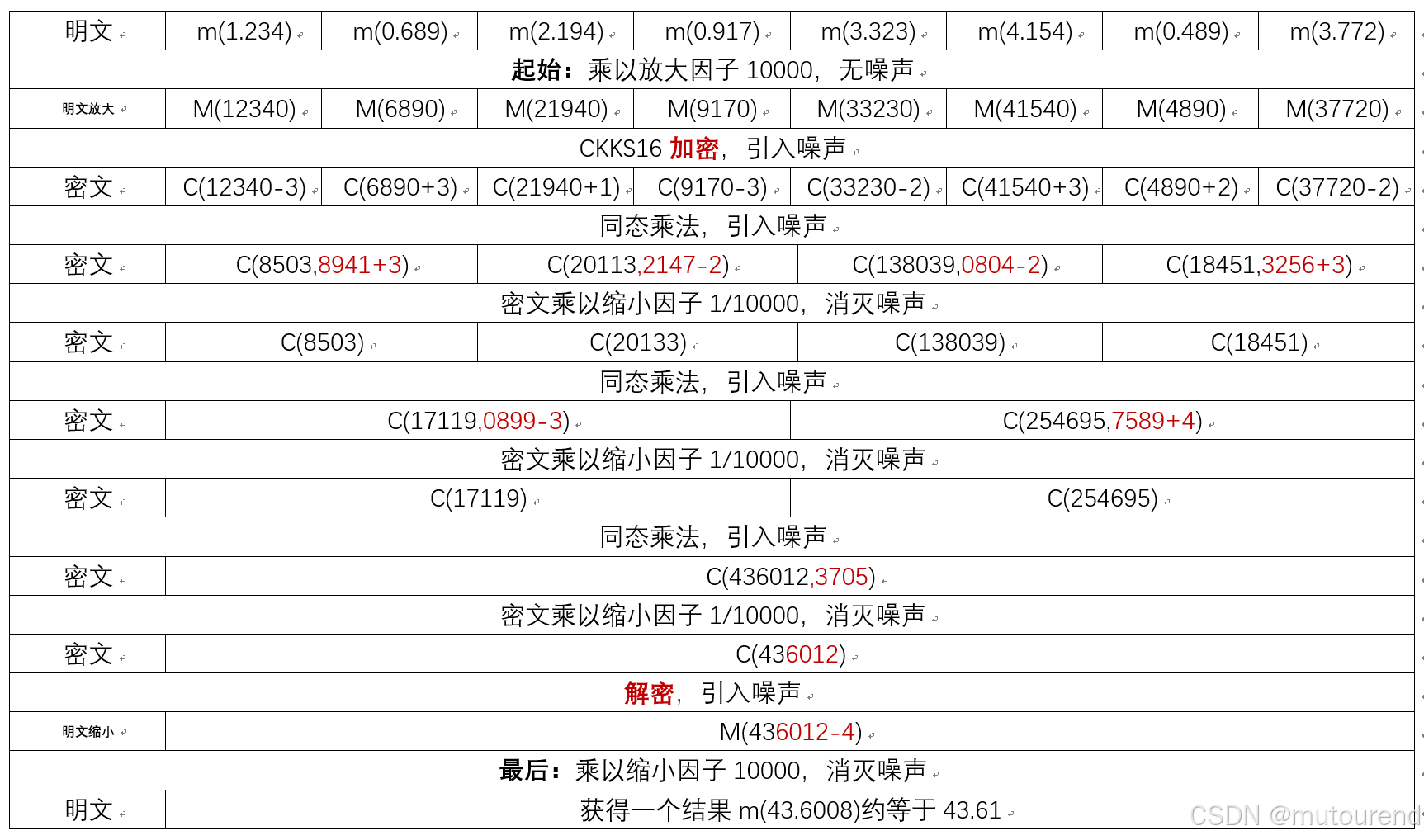
全同态加密理论、生态现状与未来展望(中2)
《全同态加密理论、生态现状与未来展望》系列由lynndell2010gmail.com和mutourend2010gmail.com整理原创发布,分为上中下三个系列: 全同态加密理论、生态现状与未来展望(上):专注于介绍全同态加密理论知识。全同态加密…...
鸿蒙UI(ArkUI-方舟UI框架)-开发布局
返回主章节 → 鸿蒙UI(ArkUI-方舟UI框架) 开发布局 1、布局概述 1)布局结构 2)布局元素组成 3)如何选择布局 声明式UI提供了以下10种常见布局,开发者可根据实际应用场景选择合适的布局进行页面开发。 …...
RPC是什么?和HTTP区别?
RPC 是什么?HTTP 是什么? 作为一个程序员,假设我们需要从A电脑的进程发送一段数据到B电脑的进程,我们一般会在代码中使用 Socket 进行编程。 此时,可选性一般就是 TCP 和 UDP 二选一,由于 TCP 可靠、UDP 不…...

Linux C\C++编程-建立文件和内存映射
【图书推荐】《Linux C与C一线开发实践(第2版)》_linux c与c一线开发实践pdf-CSDN博客 《Linux C与C一线开发实践(第2版)(Linux技术丛书)》(朱文伟,李建英)【摘要 书评 试读】- 京东图书 Linu…...
行政纠错——pycorrector学习
pycorrector是一个开源中文文本纠错工具,它支持对中文文本进行音似、形似和语法错误的纠正。此工具是使用Python3进行开发的,并整合了Kenlm、ConvSeq2Seq、BERT、MacBERT、ELECTRA、ERNIE、Transformer等多种模型来实现文本纠错功能。pycorrector官方仓库…...

Go的defer原理
Go 的 defer 原理 defer 是 Go 语言中的一个关键字,用于延迟执行一个函数调用。它通常用于处理资源释放、连接关闭等操作,确保这些操作在函数返回之前执行。 1. 什么是 defer? defer 关键字用于延迟执行一个函数调用,直到包含它…...

Windows 下本地 Docker RAGFlow 部署指南
Windows 下本地 Docker RAGFlow 部署指南 环境要求部署步骤1. 克隆代码仓库2. 配置 Docker 镜像加速(可选)3. 修改端口配置(可选)4. 启动服务5. 验证服务状态6. 访问服务7. 登录系统8. 配置模型8.1 使用 Ollama 本地模型8.2 使用在线 API 服务9. 开始使用10. 常见问题处理端…...

专题三_穷举vs暴搜vs深搜vs回溯vs剪枝_全排列
dfs解决 全排列&子集 1.全排列 link:46. 全排列 - 力扣(LeetCode) 全局变量回溯 code class Solution { public:vector<vector<int>> ans;vector<int> cur;vector<bool> used;vector<vector<int>> permute…...

【IEEE Fellow 主讲报告| EI检索稳定】第五届机器学习与智能系统工程国际学术会议(MLISE 2025)
重要信息 会议时间地点:2025年6月13-15日 中国深圳 会议官网:http://mlise.org EI Compendex/Scopus稳定检索 会议简介 第五届机器学习与智能系统工程国际学术会议将于6月13-15日在中国深圳隆重召开。本次会议旨在搭建一个顶尖的学术交流平台…...

Unity Il2CppDumper原理与实战:解析元数据与二进制对齐
1. 这不是“破解工具”,而是Unity开发者该懂的二进制真相课 你刚在Unity Asset Store下载了一个功能惊艳的插件,却在打包iOS后发现部分逻辑失效;或者接手一个没有源码的旧项目,只有一堆 .dll 和 .so 文件,连主入口…...

为什么软件开发偏爱 Linux?深度剖析 Linux 相较于 Windows 的核心优势
引言 在软件开发的世界里,一个有趣的现象是:无论是大型互联网公司的服务器集群,还是资深程序员的个人开发机,Linux 操作系统的身影无处不在。与之形成鲜明对比的是,尽管 Windows 在个人消费市场占据绝对主导地位&…...

如何让Rhino 3D模型在Blender中保持完整数据:import_3dm插件深度解析
如何让Rhino 3D模型在Blender中保持完整数据:import_3dm插件深度解析 【免费下载链接】import_3dm Blender importer script for Rhinoceros 3D files 项目地址: https://gitcode.com/gh_mirrors/im/import_3dm 当建筑师需要在Blender中渲染Rhino设计的建筑模…...

METSO A413248自动化系统
METSO A413248 自动化系统模块产品特点: 品牌归属:芬兰METSO(美卓)工业自动化系统原装备件。 产品类型:工业级自动化控制模块/接口模块。 核心功能:用于控制信号处理、数据采集及系统集成。 系统兼容&am…...

CUDA并行计算与FSR框架优化实践
1. CUDA并行计算与FSR框架概述在GPU加速计算领域,CUDA(Compute Unified Device Architecture)作为NVIDIA推出的并行计算平台和编程模型,已经成为高性能计算的事实标准。其核心设计理念是将计算任务分解为网格(Grid&…...

如何快速解锁艾尔登法环帧率限制:终极性能优化指南
如何快速解锁艾尔登法环帧率限制:终极性能优化指南 【免费下载链接】EldenRingFpsUnlockAndMore A small utility to remove frame rate limit, change FOV, add widescreen support and more for Elden Ring 项目地址: https://gitcode.com/gh_mirrors/el/EldenR…...

ComfyUI-WD14-Tagger:3分钟实现AI智能图像标签提取,效率提升10倍
ComfyUI-WD14-Tagger:3分钟实现AI智能图像标签提取,效率提升10倍 【免费下载链接】ComfyUI-WD14-Tagger A ComfyUI extension allowing for the interrogation of booru tags from images. 项目地址: https://gitcode.com/gh_mirrors/co/ComfyUI-WD14-…...

基于树莓派打造万能遥控器:从硬件选型到Web控制界面全解析
1. 项目概述:打造一个能“学习”的万能遥控器家里遥控器越来越多,电视、空调、风扇、灯带……每个设备都配一个,找起来麻烦,用起来也乱。市面上所谓的“万能遥控器”其实并不万能,它内置的码库有限,很多小众…...

观察Token消耗明细,Taotoken用量看板如何帮助控制预算
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察Token消耗明细,Taotoken用量看板如何帮助控制预算 对于个人开发者或项目管理者而言,在使用大模型API时…...
与 NOT EXISTS 优化)
PostgreSQL Join 执行策略(Nested Loop、Hash Join、Merge Join)与 NOT EXISTS 优化
以集成数据压缩 SQL 优化为例,用大白话讲清楚 Nested Loop、Hash Join、Merge Join 三种执行策略。一、背景:一条慢 SQL 引发的思考 在对上游下发数据做压缩时,有这样一条 UPDATE SQL: -- ❌ 原始写法 UPDATE magellan_nk_order_i…...