浅谈Redis
2007 年,一位程序员和朋友一起创建了一个网站。为了解决这个网站的负载问题,他自己定制了一个数据库。于2009 年开发,称之为Redis。这位意大利程序员是萨尔瓦托勒·桑菲利波(Salvatore Sanfilippo),他被称为Redis之父,更广为人知的名字是Antirez。
1.Redis简介
REmote DIctionary Server(Redis) 是一个开源的使用 ANSI C 语言编写、遵守 BSD 协议、支持网络、可基于内存、分布式、可选持久性的键值对(Key-Value)存储数据库,并提供多种语言的 API。
Redis 通常被称为数据结构服务器,因为值(value)可以是字符串(String)、哈希(Hash)、列表(list)、集合(sets)和有序集合(sorted sets)等类型。
2.内存模型
首先可以进行Redis的内存模型学习,对Redis的使用有很大帮助,例如OOM时定位、内存使用量评估等。
通过info memory命令查看内存的使用情况。

主要参数:
- used_memory:从Redis角度使用了多少内存,即Redis分配器分配的内存总量(单位是字节),包括使用的虚拟内存(即swap);
- used_memory_rss:从操作系统角度实际使用量,即Redis进程占据操作系统的内存(单位是字节),包括进程运行本身需要的内存、内存碎片等,不包括虚拟内存。一般情况下used_memory_rss都要比used_memory大,因为Redis频繁删除读写等操作使得内存碎片较多,而虚拟内存的使用一般是非极端情况下是不怎么使用的;
- mem_fragmentation_ratio:即内存碎片比率,该值是used_memory_rss / used_memory的比值;mem_fragmentation_ratio一般大于1,且该值越大,内存碎片比例越大。如果mem_fragmentation_ratio<1,说明Redis使用了虚拟内存,由于虚拟内存的媒介是磁盘,比内存速度要慢很多,当这种情况出现时,应该及时排查,如果内存不足应该及时处理,如增加Redis节点、增加Redis服务器的内存、优化应用等。一般来说,mem_fragmentation_ratio在1.03左右是比较健康的状态(对于jemalloc来说);
- mem_allocator:即Redis使用的内存分配器,一般默认是jemalloc。
2.1 Redis内存划分
- 数据
作为数据库,数据是最主要的部分,这部分占用的内存会统计在used_memory中。
- 进程本身运行需要的内存
这部分内存不是由jemalloc分配,因此不会统计在used_memory中。
- 缓冲内存
缓冲内存包括:
- 客户端缓冲区:存储客户端连接的输入输出缓冲;
- 复制积压缓冲区:用于部分复制功能;
- aof_buf:用于在进行AOF重写时,保存最近的写入命令。
这部分内存由jemalloc分配,因此会统计在used_memory中。
- 内存碎片
内存碎片是Redis在数据更改频繁分配、回收物理内存过程中产生的。
内存碎片不会统计在used_memory中。
2.2 Redis数据存储的细节
下面看一张经典的图。

- jemalloc
无论是DictEntry对象,还是RedisObject、SDS对象,都需要内存分配器(如jemalloc)分配内存进行存储。Redis在编译时便会指定内存分配器;内存分配器可以是 libc 、jemalloc或者tcmalloc,默认是jemalloc。当Redis存储数据时,会选择大小最合适的内存块进行存储。
jemalloc划分的内存单元如下图所示:

- dictEntry
每个dictEntry都保存着一个键值对,key值保存一个sds结构体,value值保存一个redisObject结构体。 
- redisObject
前面说到,Redis对象有5种类型;无论是哪种类型,Redis都不会直接存储,而是通过RedisObject对象进行存储。

RedisObject的每个字段的含义和作用如下:
- type
type字段表示对象的类型,占4个比特;目前包括REDIS_STRING(字符串)、REDIS_LIST (列表)、REDIS_HASH(哈希)、REDIS_SET(集合)、REDIS_ZSET(有序集合)。
- encoding
encoding表示对象的内部编码,占4个比特(redis-3.0)。

- lru
lru记录的是对象最后一次被命令程序访问的时间,占据的比特数不同的版本有所不同(如4.0版本占24比特,2.6版本占22比特)。
- refcount
refcount记录的是该对象被引用的次数,类型为整型。refcount的作用,主要在于对象的引用计数和内存回收:
- 当创建新对象时,refcount初始化为1;
- 当有新程序使用该对象时,refcount加1;
- 当对象不再被一个新程序使用时,refcount减1;
- 当refcount变为0时,对象占用的内存会被释放。
Redis中被多次使用的对象(refcount>1)称为共享对象。Redis为了节省内存,当有一些对象重复出现时,新的程序不会创建新的对象,而是仍然使用原来的对象。这个被重复使用的对象,就是共享对象。目前共享对象仅支持整数值的字符串对象。
共享对象的具体实现
Redis的共享对象目前只支持整数值的字符串对象。之所以如此,实际上是对内存和CPU(时间)的平衡:共享对象虽然会降低内存消耗,但是判断两个对象是否相等却需要消耗额外的时间。
对于整数值,判断操作复杂度为O(1);
对于普通字符串,判断复杂度为O(n);
而对于哈希、列表、集合和有序集合,判断的复杂度为O(n^2)。
虽然共享对象只能是整数值的字符串对象,但是5种类型都可能使用共享对象(如哈希、列表等的元素可以使用)。
就目前的实现来说,Redis服务器在初始化时,会创建10000个字符串对象,值分别是09999的整数值;当Redis需要使用值为09999的字符串对象时,可以直接使用这些共享对象。10000这个数字可以通过调整参数REDIS_SHARED_INTEGERS(4.0中是OBJ_SHARED_INTEGERS)的值进行改变。
- ptr
ptr指针指向具体的数据,如前面的例子中,set hello world,ptr指向包含字符串world的SDS。
- SDS
Redis没有直接使用C字符串(即以空字符‘\0’结尾的字符数组)作为默认的字符串表示,而是使用了SDS。SDS是简单动态字符串(Simple Dynamic String)的缩写。

)
通过SDS的结构可以看出,buf数组的长度=free+len+1(其中1表示字符串结尾的空字符);所以,一个SDS结构占据的空间为:free所占长度+len所占长度+ buf数组的长度=4+4+free+len+1=free+len+9。
为什么使用SDS而不直接使用C字符串?
SDS在C字符串的基础上加入了free和len字段,带来了很多好处:
- 获取字符串长度:SDS是O(1),C字符串是O(n)。
- 缓冲区溢出:使用C字符串的API时,如果字符串长度增加(如strcat操作)而忘记重新分配内存,很容易造成缓冲区的溢出;而SDS由于记录了长度,相应的API在可能造成缓冲区溢出时会自动重新分配内存,杜绝了缓冲区溢出。
- 修改字符串时内存的重分配:对于C字符串,如果要修改字符串,必须要重新分配内存(先释放再申请),因为如果没有重新分配,字符串长度增大时会造成内存缓冲区溢出,字符串长度减小时会造成内存泄露。而对于SDS,由于可以记录len和free,因此解除了字符串长度和空间数组长度之间的关联,可以在此基础上进行优化——空间预分配策略(即分配内存时比实际需要的多)使得字符串长度增大时重新分配内存的概率大大减小;惰性空间释放策略使得字符串长度减小时重新分配内存的概率大大减小。
- 存取二进制数据:SDS可以,C字符串不可以。因为C字符串以空字符作为字符串结束的标识,而对于一些二进制文件(如图片等),内容可能包括空字符串,因此C字符串无法正确存取;而SDS以字符串长度len来作为字符串结束标识,因此没有这个问题。
3.持久化Persistence
持久化的功能:Redis是内存数据库,数据都是存储在内存中,为了避免进程退出导致数据的永久丢失,需要定期将Redis中的数据以某种形式(数据或命令)从内存保存到硬盘。当下次Redis重启时,利用持久化文件实现数据恢复。除此之外,为了进行灾难备份,可以将持久化文件拷贝到一个远程位置。
Redis持久化分为RDB持久化和AOF持久化,前者将当前数据保存到硬盘,后者则是将每次执行的写命令保存到硬盘(类似于MySQL的Binlog)。由于AOF持久化的实时性更好,即当进程意外退出时丢失的数据更少,因此AOF是目前主流的持久化方式,不过RDB持久化仍然有其用武之地。
3.1 RDB持久化
RDB(Redis Database)持久化方式能够在指定的时间间隔能对你的数据进行快照存储。一般通过bgsave命令会创建一个子进程,由子进程来负责创建RDB文件,父进程(即Redis主进程)则继续处理请求。

图片中的5个步骤所进行的操作如下:
- Redis父进程首先判断:当前是否在执行save,或bgsave/bgrewriteaof(后面会详细介绍该命令)的子进程,如果在执行则bgsave命令直接返回。bgsave/bgrewriteaof 的子进程不能同时执行,主要是基于性能方面的考虑:两个并发的子进程同时执行大量的磁盘写操作,可能引起严重的性能问题。
- 父进程执行fork操作创建子进程,这个过程中父进程是阻塞的,Redis不能执行来自客户端的任何命令;
- 父进程fork后,bgsave命令返回”Background saving started”信息并不再阻塞父进程,并可以响应其他命令;
- 子进程进程对内存数据生成快照文件;
- 子进程发送信号给父进程表示完成,父进程更新统计信息。
这里补充一下第4点是如何生成RDB文件的。一定有读者也有疑问:在同步到磁盘和持续写入这个过程是如何处理数据不一致的情况呢?生成快照RDB文件时是否会对业务产生影响?
- 通过 fork 创建的子进程能够获得和父进程完全相同的内存空间,父进程对内存的修改对于子进程是不可见的,两者不会相互影响;
- 通过 fork 创建子进程时不会立刻触发大量内存的拷贝,采用的是写时拷贝COW (Copy On Write)。内核只为新生成的子进程创建虚拟空间结构,它们来复制于父进程的虚拟究竟结构,但是不为这些段分配物理内存,它们共享父进程的物理空间,当父子进程中有更改相应段的行为发生时,再为子进程相应的段分配物理空间;

3.2 AOF持久化

AOF(Append Only File)持久化方式记录每次对服务器写的操作,当服务器重启的时候会重新执行这些命令来恢复原始的数据,AOF命令以redis协议追加保存每次写的操作到文件末尾。Redis还能对AOF文件进行后台重写,使得AOF文件的体积不至于过大。
AOF的执行流程包括:
3.3 命令追加(append)
Redis先将写命令追加到缓冲区aof_buf,而不是直接写入文件,主要是为了避免每次有写命令都直接写入硬盘,导致硬盘IO成为Redis负载的瓶颈。
3.4 文件写入(write)和文件同步(sync)
根据不同的同步策略将aof_buf中的内容同步到硬盘;
Linux 操作系统中为了提升性能,使用了页缓存(page cache)。当我们将 aof_buf 的内容写到磁盘上时,此时数据并没有真正的落盘,而是在 page cache 中,为了将 page cache 中的数据真正落盘,需要执行 fsync / fdatasync 命令来强制刷盘。这边的文件同步做的就是刷盘操作,或者叫文件刷盘可能更容易理解一些。
AOF缓存区的同步文件策略由参数appendfsync控制,各个值的含义如下:
- always:命令写入aof_buf后立即调用系统write操作和系统fsync操作同步到AOF文件,fsync完成后线程返回。这种情况下,每次有写命令都要同步到AOF文件,硬盘IO成为性能瓶颈,Redis只能支持大约几百TPS写入,严重降低了Redis的性能;即便是使用固态硬盘(SSD),每秒大约也只能处理几万个命令,而且会大大降低SSD的寿命。可靠性较高,数据基本不丢失。
- no:命令写入aof_buf后调用系统write操作,不对AOF文件做fsync同步;同步由操作系统负责,通常同步周期为30秒。这种情况下,文件同步的时间不可控,且缓冲区中堆积的数据会很多,数据安全性无法保证。
- everysec:命令写入aof_buf后调用系统write操作,write完成后线程返回;fsync同步文件操作由专门的线程每秒调用一次。everysec是前述两种策略的折中,是性能和数据安全性的平衡,因此是Redis的默认配置,也是我们推荐的配置。
有同学可能会疑问为什么always策略还是不能100%保障数据不丢失,例如在开启AOF的情况下,有一条写命令,Redis在写命令执行完,写aof_buf未成功的情况下宕机了?
不能,Redis就不能100%保证数据不丢失。
void flushAppendOnlyFile(int force) { ssize_t nwritten; int sync_in_progress = 0; mstime_t latency; if (sdslen(server.aof_buf) == 0) return; if (server.aof_fsync == AOF_FSYNC_EVERYSEC) sync_in_progress = bioPendingJobsOfType(REDIS_BIO_AOF_FSYNC) != 0; if (server.aof_fsync == AOF_FSYNC_EVERYSEC && !force) { /* With this append fsync policy we do background fsyncing. * If the fsync is still in progress we can try to delay * the write for a couple of seconds. */ if (sync_in_progress) { if (server.aof_flush_postponed_start == 0) { /* No previous write postponing, remember that we are * postponing the flush and return. */ server.aof_flush_postponed_start = server.unixtime; return; } else if (server.unixtime - server.aof_flush_postponed_start < 2) { /* We were already waiting for fsync to finish, but for less * than two seconds this is still ok. Postpone again. */ return; } /* Otherwise fall trough, and go write since we can't wait * over two seconds. */ server.aof_delayed_fsync++; redisLog(REDIS_NOTICE,"Asynchronous AOF fsync is taking too long (disk is busy?). Writing the AOF buffer without waiting for fsync to complete, this may slow down Redis."); } } /* We want to perform a single write. This should be guaranteed atomic * at least if the filesystem we are writing is a real physical one. * While this will save us against the server being killed I don't think * there is much to do about the whole server stopping for power problems * or alike */ latencyStartMonitor(latency); nwritten = write(server.aof_fd,server.aof_buf,sdslen(server.aof_buf)); latencyEndMonitor(latency); /* We want to capture different events for delayed writes: * when the delay happens with a pending fsync, or with a saving child * active, and when the above two conditions are missing. * We also use an additional event name to save all samples which is * useful for graphing / monitoring purposes. */ if (sync_in_progress) { latencyAddSampleIfNeeded("aof-write-pending-fsync",latency); } else if (server.aof_child_pid != -1 || server.rdb_child_pid != -1) { latencyAddSampleIfNeeded("aof-write-active-child",latency); } else { latencyAddSampleIfNeeded("aof-write-alone",latency); } latencyAddSampleIfNeeded("aof-write",latency); /* We performed the write so reset the postponed flush sentinel to zero. */ server.aof_flush_postponed_start = 0; if (nwritten != (signed)sdslen(server.aof_buf)) { static time_t last_write_error_log = 0; int can_log = 0; /* Limit logging rate to 1 line per AOF_WRITE_LOG_ERROR_RATE seconds. */ if ((server.unixtime - last_write_error_log) > AOF_WRITE_LOG_ERROR_RATE) { can_log = 1; last_write_error_log = server.unixtime; } /* Log the AOF write error and record the error code. */ if (nwritten == -1) { if (can_log) { redisLog(REDIS_WARNING,"Error writing to the AOF file: %s", strerror(errno)); server.aof_last_write_errno = errno; } } else { if (can_log) { redisLog(REDIS_WARNING,"Short write while writing to " "the AOF file: (nwritten=%lld, " "expected=%lld)", (long long)nwritten, (long long)sdslen(server.aof_buf)); } if (ftruncate(server.aof_fd, server.aof_current_size) == -1) { if (can_log) { redisLog(REDIS_WARNING, "Could not remove short write " "from the append-only file. Redis may refuse " "to load the AOF the next time it starts. " "ftruncate: %s", strerror(errno)); } } else { /* If the ftruncate() succeeded we can set nwritten to * -1 since there is no longer partial data into the AOF. */ nwritten = -1; } server.aof_last_write_errno = ENOSPC; } /* Handle the AOF write error. */ if (server.aof_fsync == AOF_FSYNC_ALWAYS) { /* We can't recover when the fsync policy is ALWAYS since the * reply for the client is already in the output buffers, and we * have the contract with the user that on acknowledged write data * is synced on disk. */ redisLog(REDIS_WARNING,"Can't recover from AOF write error when the AOF fsync policy is 'always'. Exiting..."); exit(1); } else { /* Recover from failed write leaving data into the buffer. However * set an error to stop accepting writes as long as the error * condition is not cleared. */ server.aof_last_write_status = REDIS_ERR; /* Trim the sds buffer if there was a partial write, and there * was no way to undo it with ftruncate(2). */ if (nwritten > 0) { server.aof_current_size += nwritten; sdsrange(server.aof_buf,nwritten,-1); } return; /* We'll try again on the next call... */ } } else { /* Successful write(2). If AOF was in error state, restore the * OK state and log the event. */ if (server.aof_last_write_status == REDIS_ERR) { redisLog(REDIS_WARNING, "AOF write error looks solved, Redis can write again."); server.aof_last_write_status = REDIS_OK; } } server.aof_current_size += nwritten; /* Re-use AOF buffer when it is small enough. The maximum comes from the * arena size of 4k minus some overhead (but is otherwise arbitrary). */ if ((sdslen(server.aof_buf)+sdsavail(server.aof_buf)) < 4000) { sdsclear(server.aof_buf); } else { sdsfree(server.aof_buf); server.aof_buf = sdsempty(); } /* Don't fsync if no-appendfsync-on-rewrite is set to yes and there are * children doing I/O in the background. */ if (server.aof_no_fsync_on_rewrite && (server.aof_child_pid != -1 || server.rdb_child_pid != -1)) return; /* Perform the fsync if needed. */ if (server.aof_fsync == AOF_FSYNC_ALWAYS) { /* aof_fsync is defined as fdatasync() for Linux in order to avoid * flushing metadata. */ latencyStartMonitor(latency); aof_fsync(server.aof_fd); /* Let's try to get this data on the disk */ latencyEndMonitor(latency); latencyAddSampleIfNeeded("aof-fsync-always",latency); server.aof_last_fsync = server.unixtime; } else if ((server.aof_fsync == AOF_FSYNC_EVERYSEC && server.unixtime > server.aof_last_fsync)) { if (!sync_in_progress) aof_background_fsync(server.aof_fd); server.aof_last_fsync = server.unixtime; }}
那么从上面redis-3.0的源码及上下文
if (server.aof_fsync == AOF_FSYNC_ALWAYS)
分析得出,其实我们每次执行客户端命令的时候操作并没有写到aof文件中,只是写到了aof_buf内存当中,只有当下一个事件来临时,才会去fsync到disk中,从redis的这种策略上我们也可以看出,redis和mysql在数据持久化之间的区别,redis的数据持久化仅仅就是一个附带功能,并不是其主要功能。
结论:Redis即使在配制appendfsync=always的策略下,还是会丢失一个事件循环的数据。
3.5 文件重写(rewrite)
定期重写AOF文件,达到压缩的目的。
AOF重写是AOF持久化的一个机制,用来压缩AOF文件,通过fork一个子进程,重新写一个新的AOF文件,该次重写不是读取旧的AOF文件进行复制,而是读取内存中的Redis数据库,重写一份AOF文件,有点类似于RDB的快照方式。
文件重写之所以能够压缩AOF文件,原因在于:
- 过期的数据不再写入文件
- 无效的命令不再写入文件:如有些数据被重复设值(set mykey v1, set mykey v2)、有些数据被删除了(sadd myset v1, del myset)等等
- 多条命令可以合并为一个:如sadd myset v1, sadd myset v2, sadd myset v3可以合并为sadd myset v1 v2 v3。不过为了防止单条命令过大造成客户端缓冲区溢出,对于list、set、hash、zset类型的key,并不一定只使用一条命令;而是以某个常量为界将命令拆分为多条。这个常量在redis.h/REDIS_AOF_REWRITE_ITEMS_PER_CMD中定义,不可更改,3.0版本中值是64。
3.5.1 文件重写时机
相关参数:
- aof_current_size:表示当前 AOF 文件空间
- aof_base_size:表示上一次重写后 AOF 文件空间
- auto-aof-rewrite-min-size: 表示运行 AOF 重写时文件的最小体积,默认为64MB
- auto-aof-rewrite-percentage: 表示当前 AOF 重写时文件空间(aof_current_size)超过上一次重写后 AOF 文件空间(aof_base_size)的比值多少后会重写。
同时满足下面两个条件,则触发 AOF 重写机制:
- aof_current_size 大于 auto-aof-rewrite-min-size
- 当前 AOF 相比上一次 AOF 的增长率:(aof_current_size - aof_base_size)/aof_base_size 大于或等于 auto-aof-rewrite-percentage
3.5.2 文件重写流程

流程说明:
- 执行AOF重写请求。
如果当前进程正在执行bgrewriteaof重写,请求不执行。
如果当前进程正在执行bgsave操作,重写命令延迟到bgsave完成之后再执行。
- 父进程执行fork创建子进程,开销等同于bgsave过程。
3.1 主进程fork操作完成后,继续响应其它命令。所有修改命令依然写入AOF文件缓冲区并根据appendfsync策略同步到磁盘,保证原有AOF机制正确性。
3.2 由于fork操作运用写时复制技术,子进程只能共享fork操作时的内存数据由于父进程依然响应命令,Redis使用“AOF”重写缓冲区保存这部分新数据,防止新的AOF文件生成期间丢失这部分数据。
- 子进程依据内存快照,按照命令合并规则写入到新的AOF文件。每次批量写入硬盘数据量由配置aof-rewrite-incremental-fsync控制,默认为32MB,防止单次刷盘数据过多造成硬盘阻塞。
5.1 新AOF文件写入完成后,子进程发送信号给父进程,父进程更新统计信息。
5.2 父进程把AOF重写缓冲区的数据写入到新的AOF文件。
5.3 使用新的AOF文件替换老的AOF文件,完成AOF重写。
Redis 为什么考虑使用 AOF 而不是 WAL 呢?
很多数据库都是采用的 Write Ahead Log(WAL)写前日志,其特点就是先把修改的数据记录到日志中,再进行写数据的提交,可以方便通过日志进行数据恢复。
但是 Redis 采用的却是 AOF(Append Only File)写后日志,特点就是先执行写命令,把数据写入内存中,再记录日志。
如果先让系统执行命令,只有命令能执行成功,才会被记录到日志中。因此,Redis 使用写后日志这种形式,可以避免出现记录错误命令的情况。
另外还有一个原因就是:AOF 是在命令执行后才记录日志,所以不会阻塞当前的写操作。
4.复制Replication
主从复制过程大体可以分为3个阶段:连接建立阶段(即准备阶段)、数据同步阶段、命令传播阶段;下面分别进行介绍。
4.1 连接建立阶段
- 保存主节点信息
- 建立socket连接
- 发送ping命令
- 身份验证
- 发送从节点端口信息
4.2 数据同步阶段
执行流程:

-
全量复制(完整重同步)
Redis通过psync命令进行全量复制的过程如下:
-
- 从节点判断无法进行部分复制,向主节点发送全量复制的请求;或从节点发送部分复制的请求,但主节点判断无法进行部分复制;具体判断过程需要在讲述了部分复制原理后再介绍;
- 主节点收到全量复制的命令后,执行bgsave,在后台生成RDB文件,并使用一个缓冲区(称为复制缓冲区)记录从现在开始执行的所有写命令;
- 主节点的bgsave执行完成后,将RDB文件发送给从节点;从节点首先清除自己的旧数据,然后载入接收的RDB文件,将数据库状态更新至主节点执行bgsave时的数据库状态;
- 主节点将前述复制缓冲区中的所有写命令发送给从节点,从节点执行这些写命令,将数据库状态更新至主节点的最新状态;
- 如果从节点开启了AOF,则会触发bgrewriteaof的执行,从而保证AOF文件更新至主节点的最新状态。
-
部分复制(部分重同步)
- 复制偏移量
主节点和从节点分别维护一个复制偏移量(offset),代表的是主节点向从节点传递的字节数;主节点每次向从节点传播N个字节数据时,主节点的offset增加N;从节点每次收到主节点传来的N个字节数据时,从节点的offset增加N。
- 复制积压缓冲区
复制积压缓冲区是由主节点维护的、固定长度的、先进先出(FIFO)队列,默认大小1MB;当主节点开始有从节点时创建,其作用是备份主节点最近发送给从节点的数据。注意,无论主节点有一个还是多个从节点,都只需要一个复制积压缓冲区。
- 服务器运行ID(runid)
每个Redis节点(无论主从),在启动时都会自动生成一个随机ID(每次启动都不一样),由40个随机的十六进制字符组成;runid用来唯一识别一个Redis节点。
4.3 命令传播阶段
主->从:PING。
每隔指定的时间,主节点会向从节点发送PING命令,这个PING命令的作用,主要是为了让从节点进行超时判断。
从->主:REPLCONF ACK
在命令传播阶段,从节点会向主节点发送REPLCONF ACK命令,频率是每秒1次;命令格式为:REPLCONF ACK {offset},其中offset指从节点保存的复制偏移量。
5.架构模式
5.1 哨兵模式

5.1.1 哨兵模式工作原理
- 每个 Sentinel 以每秒一次的频率向它所知的 Master,Slave 以及其他 Sentinel 节点发送一个
PING命令; - 如果一个实例(instance)距离最后一次有效回复 PING 命令的时间超过配置文件
own-after-milliseconds选项所指定的值,则这个实例会被 Sentinel 标记为主观下线; - 如果一个 Master 被标记为主观下线,那么正在监视这个 Master 的所有 Sentinel 要以每秒一次的频率确认 Master 是否真的进入主观下线状态;
- 当有足够数量的 Sentinel(大于等于配置文件指定的值)在指定的时间范围内确认 Master 的确进入了主观下线状态,则 Master 会被标记为客观下线;
- 如果 Master 处于 ODOWN 状态,则投票自动选出新的主节点。将剩余的从节点指向新的主节点继续进行数据复制;
- 在正常情况下,每个 Sentinel 会以每 10 秒一次的频率向它已知的所有 Master,Slave 发送
INFO命令;当 Master 被 Sentinel 标记为客观下线时,Sentinel 向已下线的 Master 的所有 Slave 发送 INFO 命令的频率会从 10 秒一次改为每秒一次; - 若没有足够数量的 Sentinel 同意 Master 已经下线,Master 的客观下线状态就会被移除。若 Master 重新向 Sentinel 的 PING 命令返回有效回复,Master 的主观下线状态就会被移除。
主要缺陷:单个节点的写能力,存储能力受到单机的限制,动态扩容困难复杂。
5.2 集群模式
为了解决哨兵模式存储受单机的限制,这里引入分片概念。

5.2.1 分片
Redis Cluster 采用虚拟哈希槽分区,所有的键根据哈希函数映射到 0 ~ 16383 整数槽内,计算公式:HASH_SLOT = CRC16(key) % 16384。每一个节点负责维护一部分槽以及槽所映射的键值数据。

Redis Cluster 提供了灵活的节点扩容和缩容方案。在不影响集群对外服务的情况下,可以为集群添加节点进行扩容也可以下线部分节点进行缩容。可以说,槽是 Redis Cluster 管理数据的基本单位,集群伸缩就是槽和数据在节点之间的移动。
参考文献
- Redis replication | Docs
- Redis persistence | Docs
- 最通俗易懂的 Redis 架构模式详解 - 哈喽沃德先生 - 博客园
- https://mp.weixin.qq.com/s/V2MKyMKtCO1skgWWXBnrgg
- Linux写时拷贝技术(copy-on-write) - as_ - 博客园
- 深入学习Redis(1):Redis内存模型 - 编程迷思 - 博客园
- https://zhuanlan.zhihu.com/p/187596888
- Redis AOF重写阻塞问题分析-腾讯云开发者社区-腾讯云
- Redis持久化——AOF(二) - 明王不动心 - 博客园
相关文章:
浅谈Redis
2007 年,一位程序员和朋友一起创建了一个网站。为了解决这个网站的负载问题,他自己定制了一个数据库。于2009 年开发,称之为Redis。这位意大利程序员是萨尔瓦托勒桑菲利波(Salvatore Sanfilippo),他被称为Redis之父,更…...

Ceisum无人机巡检直播视频投射
接上次的视频投影,Leader告诉我这个视频投影要用在两个地方,一个是我原先写的轨迹回放那里,另一个在无人机起飞后的地图回显,要实时播放无人机拍摄的视频,还要能转镜头,让我把这个也接一下。 我的天&#x…...

【组件库】使用Vue2+AntV X6+ElementUI 实现拖拽配置自定义vue节点
先来看看实现效果: 【组件库】使用 AntV X6 ElementUI 实现拖拽配置自定义 Vue 节点 在现代前端开发中,流程图和可视化编辑器的需求日益增加。AntV X6 是一个强大的图形化框架,支持丰富的图形操作和自定义功能。结合 ElementUI,…...

Vue.js组件开发-如何实现全选反选
在 Vue.js 中实现全选和反选功能,可以通过结合v-model、计算属性和事件处理来完成。 实现思路 • 数据绑定:为每个复选框绑定一个选中状态。 • 全选控制:通过一个复选框控制所有复选框的选中状态。 • 反选控制:通过一个按钮或…...

2025.1.20——四、[强网杯 2019]Upload1 文件上传|反序列化
题目来源:buuctf [强网杯 2019]Upload 1 目录 一、打开靶机,查看信息 二、解题思路 step 1:登陆进去看情况 step 2:大佬来支援——问题在cookie step 3:测试两个思路 1.目录穿越 2.目录扫描 step 4ÿ…...

php代码审计2 piwigo CMS in_array()函数漏洞
php代码审计2 piwigo CMS in_array()函数漏洞 一、目的 本次学习目的是了解in_array()函数和对项目piwigo中关于in_array()函数存在漏洞的一个审计并利用漏洞获得管理员帐号。 二、in_array函数学习 in_array() 函数搜索数组中是否存在指定的值。 in_array($search,$array…...
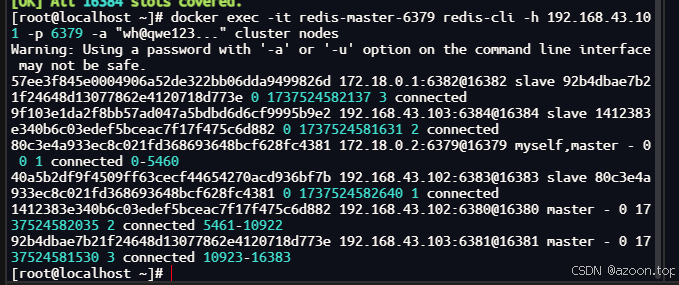
docker搭建redis集群(三主三从)
本篇文章不包含理论解释,直接开始集群(三主三从)搭建 环境 centos7 docker 26.1.4 redis latest (7.4.2) 服务器搭建以及环境配置 请查看本系列前几篇博客 默认已搭建好三个虚拟机并安装配置好docker 相关博客…...
[Datawheel]利用Zigent框架编写智能体-1
1.背景知识 1.1 什么是zigent? Zigent 是一个多智能体框架,旨在简化和优化智能体的开发与部署。Zigent 是由 自塾(Zishu.co) 团队开发的一个开源项目。自塾在 2024 年推出了多个开源项目,其中包括 wow-agent…...

【计算机视觉】人脸识别
一、简介 人脸识别是将图像或者视频帧中的人脸与数据库中的人脸进行对比,判断输入人脸是否与数据库中的某一张人脸匹配,即判断输入人脸是谁或者判断输入人脸是否是数据库中的某个人。 人脸识别属于1:N的比对,输入人脸身份是1&…...

linux环境变量配置文件区别 /etc/profile和~/.bash_profile
在 Linux 系统中,环境变量可以定义用户会话的行为,而这些变量的加载和配置通常涉及多个文件,如 ~/.bash_profile 和 /etc/profile。这些文件的作用和加载时机各有不同。以下是对它们的详细区别和用途的说明: 文章目录 1. 环境变量…...

mac 配置 python 环境变量
最新 mac 电脑,配置原理暂未研究,欢迎答疑 方案一 获取python的安装路径 which python3 配置环境变量 open ~/.bash_profile 末尾添加: PATH"/Library/Frameworks/Python.framework/Versions/3.13/bin:${PATH}" export PATH …...
终极的复杂,是简单
软件仿真拥有最佳的信号可见性和调试灵活性,能够高效捕获很多显而易见的常见错误,被大多数工程师熟练使用。 空间领域应用的一套数据处理系统(Data Handling System),采用抗辐FPGA作为主处理器,片上资源只包含10752个寄存器,软仿也是个挺花时间的事。 Few ms might take …...
)
软件开发中的密码学(国密算法)
1.软件行业中的加解密 在软件行业中,加解密技术广泛应用于数据保护、通信安全、身份验证等多个领域。加密(Encryption)是将明文数据转换为密文的过程,而解密(Decryption)则是将密文恢复为明文的过程。以下…...

【豆包MarsCode 蛇年编程大作战】蛇形烟花
项目体验地址:项目体验地址 官方活动地址:活动地址 目录 【豆包MarsCode 蛇年编程大作战】蛇形烟花演示 引言 豆包 MarsCode介绍 项目准备 第一步:安装插件 第二步:点击豆包图标来进行使用豆包 使用豆包 MarsCodeAI助手实…...
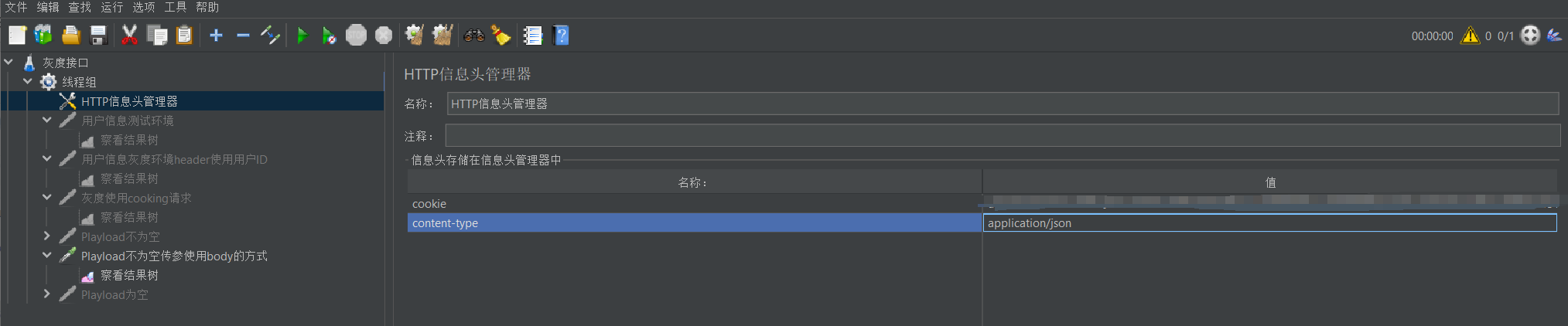
Jmeter使用Request URL请求接口
简介 在Jmeter调试接口时,有时不清楚后端服务接口的具体路径,可以使用Request URL和cookie来实现接口请求。以下内容以使用cookie鉴权的接口举例。 步骤 ① 登录网站后获取具体的Request URL和cookie信息 通过浏览器获取到Request URL和cookie&#…...

使用Pytest Fixtures来提升TestCase的可读性、高效性
关注开源优测不迷路 大数据测试过程、策略及挑战 测试框架原理,构建成功的基石 在自动化测试工作之前,你应该知道的10条建议 在自动化测试中,重要的不是工具 在编写单元测试时,你是否发现自己有很多重复代码? 数据库设…...
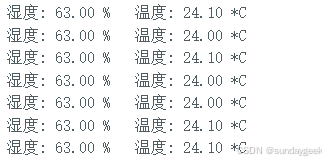
Arduino大师练成手册 -- 读取DHT11
要在 Arduino 上控制 DHT11 温湿度传感器,你可以按照以下步骤进行: 硬件连接: 将 DHT11 的 VCC 引脚连接到 Arduino 的 5V 引脚。 将 DHT11 的 GND 引脚连接到 Arduino 的 GND 引脚。 将 DHT11 的 DATA 引脚连接到 Arduino 的数字引脚&am…...

【Jave全栈】Java与JavaScript比较
文章目录 前言一、Java1、 历史与背景2、语言特点3、应用场景4、生态系统 二、JavaScript1、历史与背景2、语言特点3、应用场景4、 生态系统 三、相同点四、不同点1、语言类型2、用途3、语法和结构4、性能5、生态系统6、开发模式 前言 Java和JavaScript是两种不同的编程语言&a…...

【高项】6.2 定义活动 ITTO
定义活动是识别和记录为完成项目可交付成果而须采取的具体行动的过程。 作用:将工作包分解为进度活动,作为对项目工作进行进度估算、规划、执行、监督和控制的基础 输入 项目管理计划 ① 进度管理计划:定义进度计划方法、滚动式规划的持续…...

openlava/LSF 用户组管理脚本
背景 在openlava运维中经常需要自动化一些常规操作,比如增加用户组以及组成员、删除用户组成员、删除用户组等。而openlava的配置文件需要手动修改,然后再通过badmin reconfig激活配置。因此开发脚本将手工操作自动化就很有必要。 通过将脚本中的User…...

利用DiSEqC协议与AVR单片机驱动卫星天线电机改造户外设备
1. 项目概述:用卫星天线电机驱动一切如果你手头有一些需要承受风吹日晒、还得精确转动的设备,比如一个户外的大型定向天线,或者一个需要定期调整角度的太阳能板支架,甚至是一个坚固的监控云台,你可能会为驱动机构发愁。…...

Office RibbonX Editor:让Office界面定制变得像搭积木一样简单
Office RibbonX Editor:让Office界面定制变得像搭积木一样简单 【免费下载链接】office-ribbonx-editor An overhauled fork of the original Custom UI Editor for Microsoft Office, built with WPF 项目地址: https://gitcode.com/gh_mirrors/of/office-ribbon…...

OpenClaw 连接阿里云百炼图文教程
OpenClaw 连接阿里云百炼图文教程 前置准备 已安装并可以正常打开 OpenClaw Windows。 OpenClaw 顶部 Gateway 状态保持在线。 已准备好可正常登录的阿里云账号。 可以正常访问阿里云百炼登录地址:https://bailian.console.aliyun.com/cn-beijing#/home 建议提…...

三十岁想从零转行现实吗?带你分辨真正有前景的好工作
我是29岁那年,完成从转行裸辞副业的职业转型。 如果你把职业生涯看成是从现在开始30岁,到你退休那年,中间这么漫长的30年,那么30岁转行完全来得及…...

录音会议纪要整理不同使用场景,实用口碑选择建议
针对不同场景的录音整理需求(短录音、中长录音、长内容深度整理),本文基于实际使用体验,分享不同场景下的工具选择建议与使用心得。一、场景一:短录音(15-60分钟,发音清晰)典型场景&…...

Burp Suite证书安装全解:HTTPS抓包失败的根源与跨平台命令行方案
1. 为什么必须亲手安装Burp Suite证书——不是“点一下就完事”的操作很多人第一次在手机或测试设备上配置Burp Suite代理时,会下意识认为:只要把电脑上的Burp监听地址填进Wi-Fi代理设置,再用浏览器访问http://burp,点击那个绿色的…...

【深度解析】AI Coding 模型竞速:从 Claude Mythos 安全编码到 GPT-5.6 传闻,如何落地代码审查智能体
摘要 AI 编码模型正在从“代码补全”进入“复杂代码库理解、漏洞发现与自动修复”阶段。本文结合 Claude Mythos、Claude Opus 4.8 与 GPT-5.6 相关信息,解析新一代 Coding Agent 的技术趋势,并给出基于大模型 API 的代码安全审查实战方案。背景介绍&…...

ZMJS,把 JavaScript 解释器放进 SAP ABAP 应用服务器之后,很多扩展思路会变得不一样
我今天看这个 oisee/zmjs 仓库时,最吸引人的不是它把 JavaScript 语法做进了 ABAP,而是它选择了一条非常 SAP 的路线,纯 ABAP、无外部依赖、无 Kernel Module、以类和接口的形式运行在 SAP 应用服务器内部。仓库自己的定位很直接,ZMJS 是一个面向 SAP ABAP 的 Mini JavaScr…...

Python strip 与 rstrip 函数区别
Python strip 与 rstrip 函数区别 文章目录Python strip 与 rstrip 函数区别一、核心作用二、基础语法三、基础使用示例四、指定删除特定字符五、常用业务场景一、核心作用 函数作用范围strip()移除字符串首尾空白字符rstrip()仅移除字符串右侧末尾字符,左侧保持不…...

为什么你的Midjourney雾效总像“水汽”而非“山岚”?——资深CG总监拆解大气散射物理模型在--v 6.1中的3层映射偏差
更多请点击: https://kaifayun.com 第一章:为什么你的Midjourney雾效总像“水汽”而非“山岚”? Midjourney 生成的雾气常呈现为均匀、半透明、边界模糊的“水汽感”——厚重、潮湿、缺乏层次与呼吸感。这并非模型能力不足,而是提…...