AI刷题-最小化团建熟悉程度和
目录
问题描述
输入格式
输出格式
解题思路:
状态表示
状态转移
动态规划数组
预处理
实现:
1.初始化:
2.动态规划部分:
(1)对于已分组状态的,跳过:
(2)对于未分组的:首先是nextMember变量作为存储未分组成员的位置,
(3)尝试对未分组的进行分组
(4)最后返回结果
最终代码:
运行结果:
问题描述
最近团队中新来了许多同事,小茗同学所在部门希望通过团建来促进新老成员的沟通交流,增进信任,同时提升团队协作力、执行力和竞争力。
当团建活动规模较大时,参与人数过多,一般会分成若干个小组以便于活动展开。然而,这也导致了不同小组的成员交流过少。为了缓解这个问题,团队提出了分布式团建的方法:将活动分成若干轮,每轮分成多个 3 人小组,每个小组自由支配活动经费单独活动。团队中的成员两两之间的熟悉程度互不相同,为了最大化降低成员之间的陌生程度,分组时需要考虑尽可能将不熟悉的成员匹配在一起,通过团建活动彼此熟络。每个 3 人小组的熟悉程度定义为小组内成员两两之间的熟悉程度之和,分组方案需最小化所有小组的熟悉程度之和。
作为一名算法工程师,小茗同学开始着手解决这个问题,但是遇到了一点小困难,想请你帮忙一起解决。
输入格式
第一行为一个整数 N,表示团队成员人数。 接下来 N 行,每行有 N 个整数 r_{i,j},表示成员 i 与成员 j 的熟悉程度。
输出格式
输出一个整数,表示将团队成员分成多个 3 人小组后,熟悉程度之和的最小值。
输入样例
- 输入样例 1
3
100 78 97
78 100 55
97 55 100
- 输入样例 2
6
100 56 19 87 38 61
56 100 70 94 88 94
19 70 100 94 43 95
87 94 94 100 85 11
38 88 43 85 100 94
61 94 95 11 94 100
输出样例
- 输出样例 1
230
- 输出样例 2
299
备注
对于样例 2,组队方案为 (1, 3, 5) 和 (2, 4, 6),最小的熟悉程度之和为 (19 + 38 + 43) + (94 + 94 + 11) = 299。
数据范围
数据保证 N 是 3 的倍数, r_{i,j} = r_{j,i}, r_{i,i} = 100。
100% 数据:3 ≤ N ≤ 21, 0 ≤ r_{i,j} ≤ 100 。
解题思路:
本题可以使用动态规划(Dynamic Programming)来解决。我们需要将 N 个成员分成若干个 3 人小组,并最小化所有小组的熟悉程度之和。
状态表示
我们使用一个位掩码(bitmask)来表示当前哪些成员已经被分组。具体来说,mask 是一个二进制数,其中第 i 位为 1 表示第 i 个成员已经被分组,为 0 表示未分组。
状态转移
我们从初始状态(所有成员都未分组)开始,逐步将成员分组。对于每个状态 mask,我们找到一个未分组的成员 nextMember,然后尝试将 nextMember 与另外两个未分组的成员组成一个 3 人小组。更新状态 mask 并计算新的熟悉程度之和。
动态规划数组
我们使用一个数组 dp 来存储每个状态的最小熟悉程度之和。dp[mask] 表示在状态 mask 下,所有成员分组后的最小熟悉程度之和。
预处理
我们预处理每个 3 人小组的熟悉程度之和,并存储在一个哈希表中,以便在动态规划过程中快速查找。
实现:
1.初始化:
提前创建一个dp数组进行计算,一个groupFamiliarityMap集合来预处理每三个 人的组合情况
减少后面dp的计算量
vector<long long> dp(1 << N, LLONG_MAX);dp[0] = 0;// 预处理每个小组的熟悉程度之和unordered_map<string, int> groupFamiliarity;for (int i = 0; i < N; i++) {for (int j = i + 1; j < N; j++) {for (int k = j + 1; k < N; k++) {int sum = familiarMatrix[i][j] + familiarMatrix[i][k] + familiarMatrix[j][k];groupFamiliarity[to_string(i) + "," + to_string(j) + "," + to_string(k)] = sum;}}}2.动态规划部分:
用一个mask(位掩码)作为循环变量
(1)对于已分组状态的,跳过:
if (dp[mask] == LLONG_MAX) {continue;}(2)对于未分组的:首先是nextMember变量作为存储未分组成员的位置,
注意:!(mask & (1 << i))这个判断条件是为了检查第 i 位是否未被设置(即未分组),其中只有第 i 位与 mask(2进制) 的第 i 位都为 1 时,结果的第 i 位才为 1,否则为 0。
// 找到下一个未分组的成员int nextMember = -1;for (int i = 0; i < N; i++) {if (!(mask & (1 << i))) {nextMember = i;break;}}找不到则跳过
if (nextMember == -1) {continue;}(3)尝试对未分组的进行分组
// 尝试将 nextMember 与另外两个未分组的成员组成一个小组for (int j = nextMember + 1; j < N; j++) {if (!(mask & (1 << j))) {for (int k = j + 1; k < N; k++) {if (!(mask & (1 << k))) {int newMask = mask | (1 << nextMember) | (1 << j) | (1 << k);string key = to_string(nextMember) + "," + to_string(j) + "," + to_string(k);int groupFamiliaritySum = groupFamiliarity[key];dp[newMask] = min(dp[newMask], dp[mask] + groupFamiliaritySum);}}}}(4)最后返回结果
return (int)dp[(1 << N) - 1];最终代码:
#include <iostream>
#include <vector>
#include <unordered_map>
#include <climits>
#include <string>using namespace std;int solution(int N, vector<vector<int>> familiarMatrix) {// 初始化 dp 数组vector<long long> dp(1 << N, LLONG_MAX);dp[0] = 0;// 预处理每个小组的熟悉程度之和unordered_map<string, int> groupFamiliarity;for (int i = 0; i < N; i++) {for (int j = i + 1; j < N; j++) {for (int k = j + 1; k < N; k++) {int sum = familiarMatrix[i][j] + familiarMatrix[i][k] + familiarMatrix[j][k];groupFamiliarity[to_string(i) + "," + to_string(j) + "," + to_string(k)] = sum;}}}// 动态规划for (int mask = 0; mask < (1 << N); mask++) {if (dp[mask] == LLONG_MAX) {continue;}// 找到下一个未分组的成员int nextMember = -1;for (int i = 0; i < N; i++) {if (!(mask & (1 << i))) {nextMember = i;break;}}if (nextMember == -1) {continue;}// 尝试将 nextMember 与另外两个未分组的成员组成一个小组for (int j = nextMember + 1; j < N; j++) {if (!(mask & (1 << j))) {for (int k = j + 1; k < N; k++) {if (!(mask & (1 << k))) {int newMask = mask | (1 << nextMember) | (1 << j) | (1 << k);string key = to_string(nextMember) + "," + to_string(j) + "," + to_string(k);int groupFamiliaritySum = groupFamiliarity[key];dp[newMask] = min(dp[newMask], dp[mask] + groupFamiliaritySum);}}}}}return (int)dp[(1 << N) - 1];
}int main() {vector<vector<int>> familiarMatrix1 = {{100, 78, 97},{78, 100, 55},{97, 55, 100}};vector<vector<int>> familiarMatrix2 = {{100, 56, 19, 87, 38, 61},{56, 100, 70, 94, 88, 94},{19, 70, 100, 94, 43, 95},{87, 94, 94, 100, 85, 11},{38, 88, 43, 85, 100, 94},{61, 94, 95, 11, 94, 100}};cout << (solution(3, familiarMatrix1) == 230) << endl; // 输出: 1 (true)cout << (solution(6, familiarMatrix2) == 299) << endl; // 输出: 1 (true)return 0;
}运行结果:

相关文章:
AI刷题-最小化团建熟悉程度和
目录 问题描述 输入格式 输出格式 解题思路: 状态表示 状态转移 动态规划数组 预处理 实现: 1.初始化: 2.动态规划部分: (1)对于已分组状态的,跳过: (2&…...

一文详解Filter类源码和应用
背景 在日常开发中,经常会有需要统一对请求做一些处理,常见的比如记录日志、权限安全控制、响应处理等。此时,ServletApi中的Filter类,就可以很方便的实现上述效果。 Filter类 是一个接口,属于 Java Servlet API 的一部…...

应用层协议 HTTP 讲解实战:从0实现HTTP 服务器
🌈 个人主页:Zfox_ 🔥 系列专栏:Linux 目录 一:🔥 HTTP 协议 🦋 认识 URL🦋 urlencode 和 urldecode 二:🔥 HTTP 协议请求与响应格式 🦋 HTTP 请求…...

DDD-全面理解领域驱动设计中的各种“域”
一、DDD-领域 在领域驱动设计(Domain-Driven Design,DDD)中,**领域(Domain)**指的是软件系统所要解决的特定业务问题的范围。它涵盖了业务知识、规则和逻辑,是开发团队与领域专家共同关注的核心…...

PHP防伪溯源一体化管理系统小程序
🔍 防伪溯源一体化管理系统,品质之光,根源之锁 🚀 引领防伪技术革命,重塑品牌信任基石 我们自豪地站在防伪技术的前沿,为您呈现基于ThinkPHP和Uniapp精心锻造的多平台(微信小程序、H5网页&…...

纯css实现div宽度可调整
<!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8" /><meta name"viewport" content"widthdevice-width, initial-scale1.0" /><title>纯css实现div尺寸可调整</title><style…...

C# 中使用Hash用于密码加密
通过一定的哈希算法(典型的有MD5,SHA-1等),将一段较长的数据映射为较短小的数据,这段小数据就是大数据的哈希值。他最大的特点就是唯一性,一旦大数据发生了变化,哪怕是一个微小的变化࿰…...

如何建设一个企业级的数据湖
建设一个企业级的数据湖是一项复杂且系统化的工程,需要从需求分析、技术选型、架构设计到实施运维等多个方面进行综合规划和实施。以下是基于我搜索到的资料,详细阐述如何建设企业级数据湖的步骤和关键要点: 一、需求分析与规划 明确业务需…...
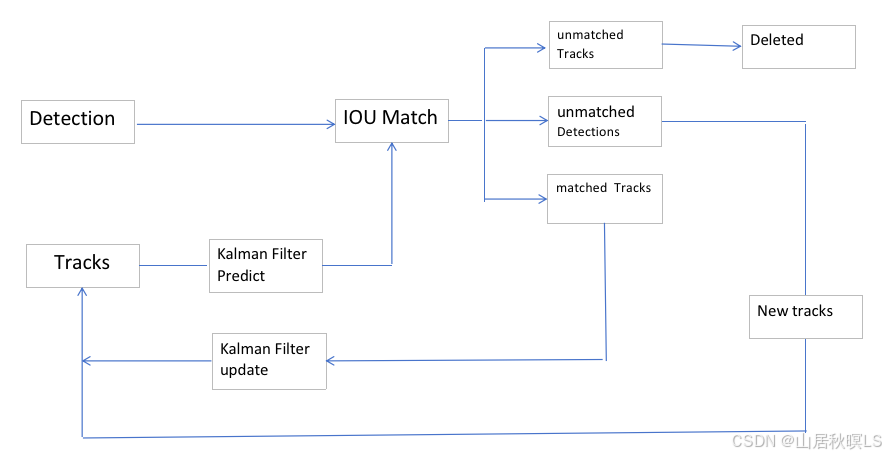
目标跟踪之sort算法(3)
这里写目录标题 1 流程1 预处理2 跟踪 2 代码 参考:sort代码 https://github.com/abewley/sort 1 流程 1 预处理 1.1 获取离线检测数据。1.2 实例化跟踪器。2 跟踪 2.1 轨迹处理。根据上一帧的轨迹预测当前帧的轨迹,剔除到当前轨迹中为空的轨迹得到当前…...

【java数据结构】HashMapOJ练习题
【java数据结构】HashMapOJ练习题 一、只出现一次的数字二 、随机链表的复制三 、宝石与石头四、坏键盘打字五、前K个高频单词 博客最后附有整篇博客的全部代码!!! 一、只出现一次的数字 只出现一次的数字 思路: 先遍历一遍数组…...

Nginx前端后端共用一个域名如何配置
在 Nginx 中配置前端和后端共用一个域名的情况,通常是通过路径或子路径将请求转发到不同的服务。以下是一个示例配置,假设: 前端静态文件在 /var/www/frontend/。 后端 API 服务运行在 http://127.0.0.1:5000。 域名是 example.comÿ…...
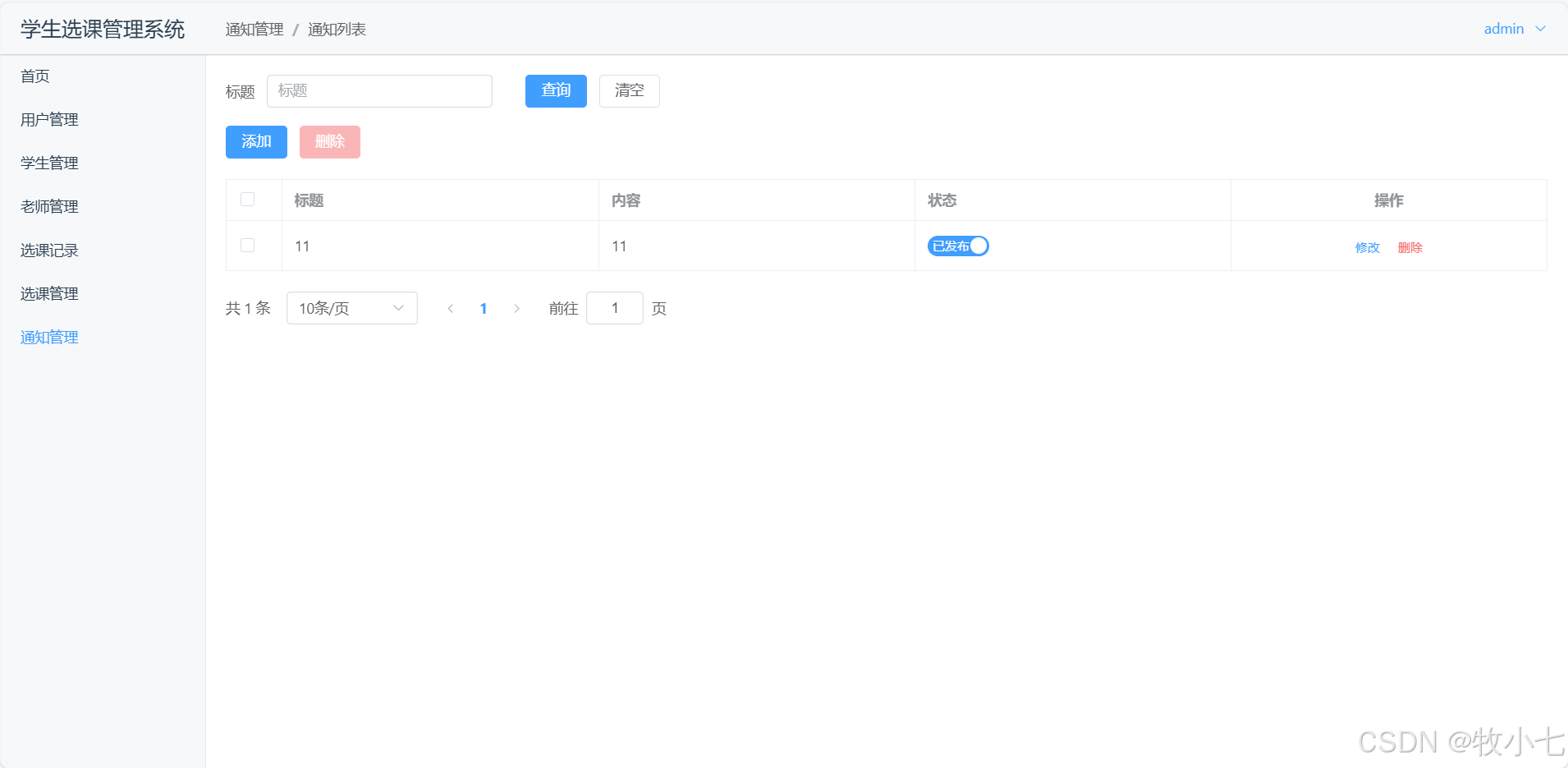
SpringBoot3+Vue3开发学生选课管理系统
功能介绍 分三个角色登录:学生登录,老师登录,教务管理员登录,不同用户功能不同! 1.学生用户功能 选课记录,查看选课记录,退选。选课管理,进行选课。通知管理,查看通知消…...

Linux系统 C/C++编程基础——基于GTK+的图形用户界面编程
ℹ️大家好,我是练小杰,今天星期三了,距离除夕又少了一天,新年的钟声就快敲响了😆 本文是有关Linux C/C编程中的基于GTK的图形用户界面编程知识点,后续会不断添加相关内容 ~~ 回顾:【使用make工具和Makefil…...

【Leetcode 每日一题】40. 组合总和 II
问题背景 给定一个候选人编号的集合 c a n d i d a t e s candidates candidates 和一个目标数 t a r g e t target target,找出 c a n d i d a t e s candidates candidates 中所有可以使数字和为 t a r g e t target target 的组合。 c a n d i d a t e s c…...

python 变量范围的定义与用法
文章目录 1. 局部变量(Local Scope)示例: 2. 嵌套函数变量(Enclosing Scope)示例:说明: 3. 全局变量(Global Scope)示例:说明: 4. 内置变量&#…...
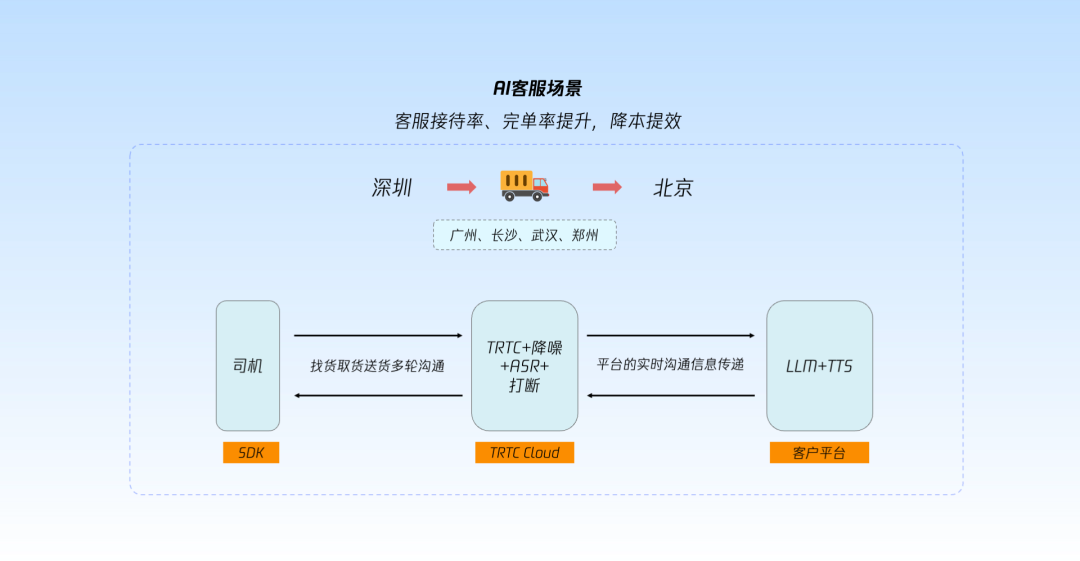
TRTC实时对话式AI解决方案,助力人机语音交互极致体验
近年来,AI热度持续攀升,无论是融资规模还是用户热度都大幅增长。2023 年,中国 AI 行业融资规模达2631亿人民币,较2022年上升51%;2024年第二季度,全球 AI 初创企业融资规模为 240 亿美金,较第一季…...
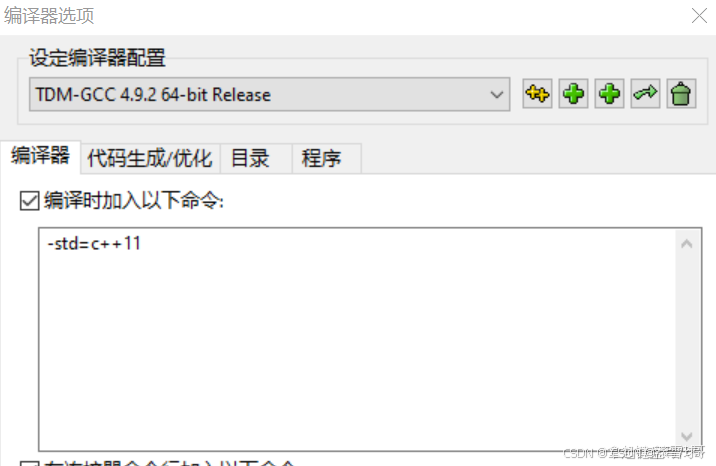
dev c++ ‘unordered_set‘ does not name a type
参考:https://blog.csdn.net/Zaczc/article/details/142531525 启用C11标准步骤 工具->编译选项 勾选编译时加入以下命令 在空白处添加:-stdc11 单击确定,启用成功...

算法每日双题精讲 —— 二分查找(寻找旋转排序数组中的最小值,点名)
🌟快来参与讨论💬,点赞👍、收藏⭐、分享📤,共创活力社区。 🌟 别再犹豫了!快来订阅我们的算法每日双题精讲专栏,一起踏上算法学习的精彩之旅吧💪 在算法的…...

three.js+WebGL踩坑经验合集(4.2):为什么不在可视范围内的3D点投影到2D的结果这么不可靠
上一篇,笔者留下了一个问题,three.js内置的THREE.Vector3.project方法算出来的结果对于超出屏幕可见范围的点来说错得相当离谱。 three.jsWebGL踩坑经验合集(4.1):THREE.Line2的射线检测问题(注意本篇说的是Line2,同样也不是阈值…...
- kafka 查看kafka的运行状态、broker.id不一致导致启动失败问题、topic消息积压量告警监控脚本)
Kafka运维宝典 (二)- kafka 查看kafka的运行状态、broker.id不一致导致启动失败问题、topic消息积压量告警监控脚本
Kafka运维宝典 (二) 文章目录 Kafka运维宝典 (二)一、kafka broker.id冲突问题1. broker.id 冲突的影响2. 如何发现 broker.id 冲突3. 解决 broker.id 冲突的方法4. broker.id 配置管理5. 集群启动后确认 broker.id 唯一性6. brok…...

告别道路预测老套路:用ParkPredict+模型思路,解决停车场里的‘鬼探头’难题
破解泊车场景预测困局:ParkPredict模型的技术革新与实践停车场里的每一次转向、倒车和避让,都是对自动驾驶系统预测能力的极限挑战。与开放道路的规则明确不同,这里没有清晰的车道线指引,没有统一的行驶方向,只有随时可…...

自制射频功率计:基于AD8317芯片,成本43欧元实现1MHz-10GHz测量
1. 项目概述:为什么我要亲手打造一台射频功率计在无人机和模型飞行器的圈子里,尤其是在我们荷兰FMS Spaarnwoude俱乐部,合规飞行是头等大事。我给我的八轴飞行器加装了云台相机和图传系统,工作在5.8GHz频段。根据本地法规…...

如何进行TVA仿真引擎的“光照地狱”训练?
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...

中兴光猫终极管理指南:解锁工厂模式与Telnet权限的实战教程
中兴光猫终极管理指南:解锁工厂模式与Telnet权限的实战教程 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu 掌握中兴光猫的设备管理和权限获取能力是网络管理员和技术爱好者…...

NBTExplorer:让Minecraft数据编辑从专业工具变成人人可用的可视化平台
NBTExplorer:让Minecraft数据编辑从专业工具变成人人可用的可视化平台 【免费下载链接】NBTExplorer A graphical NBT editor for all Minecraft NBT data sources 项目地址: https://gitcode.com/gh_mirrors/nb/NBTExplorer 你是否曾经面对Minecraft世界文件…...

Unity塔防底层架构:ScriptableObject驱动的数据契约设计
1. 这不是“又一个塔防模板”,而是塔防开发的底层操作系统我第一次在Asset Store点开Tower Defense Toolkit 4(TDTK-4)的预览图时,下意识划走了——界面太“干净”了,没有炫酷的粒子特效演示,没有满屏飞舞的…...
)
Lovable内部工具开发方法论(从需求黑洞到用户自发推广的完整闭环)
更多请点击: https://kaifayun.com 第一章:Lovable内部工具开发方法论(从需求黑洞到用户自发推广的完整闭环) Lovable 方法论的核心不是交付功能,而是培育“工具依赖感”——当一线工程师在凌晨三点调试线上问题时&am…...

哪款台灯护眼效果最好孩子用?实测口碑爆款护眼灯品牌,买前必看
哪款台灯护眼效果最好孩子用?作为家长,最揪心的就是孩子的视力问题。有数据显示,现在孩子近视率越来越高,小学就有不少戴眼镜的,中学更是过半,看着实在让人担心。 孩子每天低头写作业、看书,灯光…...

如何用Nucleus Co-Op让单机游戏变身本地多人分屏神器
如何用Nucleus Co-Op让单机游戏变身本地多人分屏神器 【免费下载链接】nucleuscoop Starts multiple instances of a game for split-screen multiplayer gaming! 项目地址: https://gitcode.com/gh_mirrors/nu/nucleuscoop 还在为想和朋友一起玩游戏却只有一台电脑而烦…...

【MATLAB】OFDM系统峰均比抑制算法仿真
【MATLAB】OFDM系统峰均比抑制算法仿真 摘要:OFDM(正交频分复用)技术凭借抗多径衰落、频谱利用率高、抗干扰能力强等优势,广泛应用于4G/5G移动通信、WiFi、数字广播电视等无线通信系统。但OFDM系统存在固有缺陷,多子载波叠加导致时域信号出现大幅峰值,产生较高峰值平均功…...