如何建设一个企业级的数据湖
建设一个企业级的数据湖是一项复杂且系统化的工程,需要从需求分析、技术选型、架构设计到实施运维等多个方面进行综合规划和实施。以下是基于我搜索到的资料,详细阐述如何建设企业级数据湖的步骤和关键要点:
一、需求分析与规划
- 明确业务需求:首先需要明确企业的业务目标和数据湖的使用场景,包括数据类型、存储规模、访问频率等需求。这一步骤是整个数据湖建设的基础,需与相关利益相关者充分沟通,确保数据湖能够满足实际业务需求。
- 摸底调研:对现有数据源进行全面摸底,包括数据来源、数据类型、数据形态、数据模式等,为后续的数据湖建设奠定基础。
- 确定数据湖范围和目标:明确数据湖的范围,包括需要存储的数据类型(结构化、半结构化或非结构化数据),并设定清晰的目标,如支持数据分析、实时查询或机器学习等。

二、技术选型与架构设计
- 选择合适的技术平台:根据需求选择合适的技术平台,如AWS S3、Hadoop、Delta Lake、阿里云DLF等。这些平台提供了不同的存储方式和计算能力,可以根据企业需求灵活选择。
- 设计数据湖架构:构建一个分布式、可扩展的数据湖架构,支持多种数据源的接入和统一管理。常见的架构包括:
-
数据摄入层:负责从不同来源收集数据,如API接口、文件上传等。

-
存储层:采用分布式文件系统(如HDFS)或云存储服务(如AWS S3),确保数据的高可用性和扩展性。
-
处理层:通过ETL工具(如Apache Spark)对数据进行清洗、转换和加载。
-
元数据管理:建立统一的元数据管理系统,支持数据分类、权限控制和数据血缘追踪。
-
- 安全性与权限管理:确保数据湖的安全性,包括数据加密、访问控制和审计日志等措施。
三、数据湖的构建与实施
- 数据收集与整合:通过ETL工具或API接口将来自不同来源的数据导入数据湖,并进行初步清洗和转换,使其适合后续分析使用。
- 存储与管理:将原始数据存储在分布式文件系统中,并根据业务需求对数据进行分类和组织。例如,可以使用Delta Lake实现高效的数据管理和版本控制。
- 数据分析与挖掘:利用BI工具、机器学习框架(如TensorFlow)或大数据分析工具(如Hive)对存储在数据湖中的数据进行深入分析,提取有价值的信息。
- 实时处理与查询:对于需要实时响应的场景,可以部署流处理框架(如Apache Kafka)或实时查询引擎(如Presto),以支持快速的数据查询和决策支持。

四、监控与优化
- 性能监控:定期监控数据湖的性能指标,包括存储容量、访问频率、查询响应时间等,及时发现并解决潜在问题。
- 成本优化:合理规划存储和计算资源,避免过度投资。例如,通过按需扩展存储容量或优化计算任务来降低成本。
- 持续改进:根据业务需求和技术发展,不断优化数据湖架构和功能,确保其长期适应企业的发展需求。
五、案例参考与最佳实践
- 借鉴成功案例:参考其他企业的成功案例,如Netflix和Airbnb的数据湖建设经验,学习其在数据治理、安全性和性能优化方面的做法。
- 遵循最佳实践:参考行业最佳实践,如阿里云的DLF解决方案,通过统一的元数据管理和权限控制实现高效的数据湖建设。
六、总结
建设企业级数据湖是一个系统工程,需要从需求分析到实施运维的全过程进行规划和管理。通过合理的技术选型、科学的架构设计以及持续的优化改进,企业可以构建一个高效、安全且灵活的数据湖平台,为业务决策提供强有力的数据支持。
如何在数据湖中实现高效的数据加密和访问控制?
在数据湖中实现高效的数据加密和访问控制,需要结合多种技术和策略,以确保数据的安全性和合规性。以下是基于我搜索到的资料的详细解答:
1. 数据加密
数据加密是保护数据安全的重要手段,可以防止未经授权的访问和数据泄露。以下是实现高效数据加密的关键措施:
- 使用云存储服务的内置加密功能:例如,AWS S3 提供了客户端加密和服务器端加密功能,可以有效防止未经授权的访问和恶意攻击。
- 对象标签和数据分类:通过对象标签对数据进行分类,并结合 IAM 控制访问权限,确保敏感数据得到额外保护。
- 实时数据流加密:对于实时数据处理任务,可以通过流式处理技术对数据进行加密,从而保障数据在传输过程中的安全性。
2. 访问控制
访问控制是确保只有授权用户才能访问特定数据的核心机制。以下是实现高效访问控制的方法:
- 基于角色的访问控制(RBAC) :通过定义不同的角色(如开发者、商业分析师等),并为每个角色分配特定的权限。例如,开发者可以访问所有列,而商业分析师只能访问非个人身份信息(PII)列。
- 最小权限原则:通过 IAM 实现基于规则和角色的访问控制,确保用户只能访问其工作所需的数据,从而降低数据泄露风险。
- 自动化元数据管理:利用自动化工具定期更新元数据,确保数据目录的一致性和准确性,从而支持高效的数据访问控制。
3. 技术架构与工具
为了进一步提升数据湖的安全性和管理效率,可以采用以下技术架构和工具:
- 云平台的弹性扩展能力:利用 AWS、Azure 或 Google Cloud 等云平台提供的弹性资源管理功能,根据需求动态调整计算和存储资源。
- 数据湖构建工具:使用 AWS Lake Formation 或 Azure Data Lake 等工具,可以快速创建和管理数据湖,同时提供内置的安全和合规性功能。
- 自动化工具:通过 ETL/ELT 工具实现数据编排和自动化流程,提高数据治理效率。
4. 数据治理与合规性
为了确保数据湖的长期可持续性,需要实施全面的数据治理策略:
- 强制访问控制:确保所有数据访问都经过严格审批,并记录访问日志以备审计。
- 定期审查隐私政策:定期检查数据访问和隐私政策,确保符合最新的法规要求。
- 数据质量监控:建立数据质量监控机制,检测并修复数据质量问题,确保数据的可靠性和一致性。
5. 最佳实践
结合以上措施,以下是一些最佳实践建议:
- 分层存储策略:将敏感数据存储在更安全的存储层级(如 AWS S3 的加密存储),并为非敏感数据选择成本较低的存储选项。
- 实时监控与性能优化:通过监控工具实时检测异常访问行为,并优化计算性能以支持实时分析需求。
- 持续改进:随着技术的发展和业务需求的变化,持续评估和优化数据湖的安全策略和技术架构。
在选择数据湖技术平台时,哪些因素最影响成本与性能的平衡?
在选择数据湖技术平台时,影响成本与性能平衡的因素主要包括以下几个方面:
-
存储方式的选择:
- 数据湖通常提供多种存储方式,包括磁盘式结构化分析和内存中分析。磁盘式结构化分析价格较低但速度较慢,而内存中分析速度快但成本较高。企业可以根据需求选择适合自己的方法,以实现成本与性能的最佳平衡。
- 腾讯云的原生数据湖存储通过三级加速体系(如GooseFS、元数据加速器和AZ加速器)显著降低对象存储访问带宽,提升元数据操作性能和海量吞吐量,从而在性能和成本之间取得平衡。
-
计算资源的优化:
- 阿里云MaxCompute通过SQL优化、PAFA封装算法服务以及云原生弹性资源与EMR集群资源的互补,实现了资源的削峰填谷,降低了计算成本。
- 云湖仓架构通过动态资源分配和冷热数据分层存储策略,在保持高性能的同时有效控制数据管理的整体成本。
-
技术栈的兼容性和扩展性:
- 数据湖平台需要支持多种数据源接入和全生命周期管理,同时提供强大的连接器和转换工具,以简化企业使用流程。
- 选择合适的数据湖平台和技术是关键,需要考虑其与现有系统的兼容性、扩展性以及是否能够满足不同场景的需求。
-
灵活性与敏捷性:
- 数据湖需要灵活应对业务需求的变化,同时避免数据孤岛问题。这要求设计合理的数据架构,并确保数据湖的灵活性与数据仓库的结构化查询性能之间的平衡。
- 湖仓一体化架构(如Lakehouse)结合了数据湖的可扩展性和数据仓库的可靠性,实现了灵活性和效率的最佳平衡。
-
成本优化策略:
- 数据湖的成本包括存储、计算和管理费用。企业需要根据需求选择合适的技术,并设计可扩展的架构以适应数据增长和处理要求。
- 使用开源或商业解决方案时,需要综合考虑性能、成本和兼容性等因素,以确保数据湖的可持续发展。
-
安全性与合规性:
- 数据湖需要实施访问控制、加密和审计功能,以保护数据免受未经授权的访问和泄露。
数据湖建设中,如何有效结合短期业务需求与长期战略规划?
在数据湖建设中,如何有效结合短期业务需求与长期战略规划是一个复杂但至关重要的问题。以下从多个角度详细分析并提出建议:
一、明确短期业务需求与长期战略目标
- 短期业务需求:数据湖建设初期,企业应首先明确当前业务的实际需求,包括数据存储、分析和应用的具体场景。例如,企业可能需要快速响应市场变化,通过数据湖实现对客户行为的实时分析,以优化营销策略。
- 长期战略规划:同时,企业需要考虑数据湖的长远发展,例如支持未来创新、提升数据治理能力以及应对潜在的业务扩展需求。例如,数据湖可以为未来的AI应用提供基础数据支持,并通过灵活扩展功能满足未来增长。
二、分阶段实施,兼顾灵活性与可扩展性
- 分阶段建设:数据湖的建设通常分为四个阶段:可扩展的数据处理和接入、分析能力增强、数据湖与数据仓库的协作以及端到端的采用和成熟度提升。这种分阶段的方法能够确保在满足当前业务需求的同时,为未来的发展留出空间。
- 灵活架构设计:数据湖的设计应注重灵活性和可扩展性,以适应不同业务场景的需求。例如,通过采用云计算、大数据处理框架(如Hadoop)和ETL工具,企业可以灵活地处理结构化、半结构化和非结构化数据。
三、构建统一的数据入湖标准与流程
- 统一标准:为了确保数据湖能够高效运行,企业需要制定科学、完整且统一的数据入湖标准及流程。这包括明确数据的所有者、发布标准、密级分类以及分域分类的数据入湖策略。
- 动态调整:随着业务需求的变化,企业需要定期评估和调整数据入湖的标准和流程,以确保数据湖始终能够支持当前的业务需求。
四、加强数据治理与安全策略
- 数据治理:数据湖建设过程中,必须重视数据质量、隐私保护和合规性问题。例如,通过加密技术、访问控制和定期审计等措施,确保数据的安全性和可靠性。
- 长期规划中的治理:在长期战略规划中,企业应将数据治理作为核心内容之一,建立全面的数据管理体系,以支持数据湖的可持续发展。
五、推动跨部门协作与信息共享
- 跨部门协作:数据湖的建设需要各部门的密切配合。例如,业务部门可以提出具体的数据需求,而IT部门则负责技术实现。通过明确责任分工,可以确保数据湖建设既满足短期需求又支持长期目标。
- 信息共享平台:构建一个统一的信息共享平台,使不同部门能够根据自身需求访问所需数据。这不仅提高了工作效率,还促进了企业内部的信息流通。
六、持续优化与迭代升级
- 迭代升级:数据湖建设是一个动态的过程,企业需要根据业务发展和技术进步不断优化和升级系统。例如,通过引入更先进的AI技术和机器学习算法,提升数据分析能力。
- 五年规划与中期评估:在长期战略规划中,企业应制定五年规划,并定期进行中期评估,以确保数据湖建设始终符合企业的战略方向。
结论
在数据湖建设中,结合短期业务需求与长期战略规划需要企业在明确目标的基础上,采取分阶段实施、灵活架构设计、统一标准、加强治理和推动协作等措施。
成功的数据湖案例中,有哪些关键的成功因素和最佳实践?
成功的数据湖案例中,关键的成功因素和最佳实践可以从多个方面进行总结。以下是一些重要的因素和实践:
1. 明确的业务目标
- 定义明确的业务目标:在构建数据湖之前,必须明确业务目标,以确保数据湖的设置和管理能够满足业务需求并提供价值。这包括了解数据湖的用途和预期的业务成果。
2. 选择合适的平台
- 选择合适的云平台:根据组织的规模、预算、现有IT基础设施和特定数据需求,选择合适的云平台(如Amazon S3、Microsoft Azure Data Lake Storage或Google Cloud Storage)。这些平台提供了必要的存储和计算资源,支持数据湖的高效运行。
3. 数据治理
- 实施数据治理:确保数据的质量、一致性和安全性是数据湖成功的关键。这包括定义数据治理政策、实施访问控制、加密和监控措施,以保护敏感数据并防止数据泄露。
- 支持元数据:元数据管理对于数据湖的成功至关重要。通过组织和索引数据,可以提高数据的可查找性和可用性。
4. 数据摄取程序
- 建立数据摄取程序:自动化数据摄取过程可以减少人工工作量,提高数据质量,并确保数据的持续更新。这有助于减少错误并提高整体效率。
5. 数据安全
- 优先考虑数据安全:实施访问控制、加密和监控措施,以保护敏感数据免受未授权访问和潜在威胁。这是确保数据湖安全运行的重要步骤。
6. 数据可用性
- 启用数据可用性:通过实施数据目录和元数据管理,确保数据的可查找性和可用性。这有助于用户快速找到所需的数据并进行分析。
7. 定期监控和审计
- 定期监控和审计:确保数据湖架构专为可扩展性而设计,并定期监控和审计数据湖,以验证其性能、准确性和一致性。这有助于及时发现和解决问题。
8. 培养数据文化
- 培育数据文化:教育员工了解数据的价值,鼓励他们使用数据工具并做出基于数据的决策。这有助于提高整个组织的数据意识和能力。
9. 持续学习和改进
- 持续学习和改进:定期收集用户反馈,了解团队的需求,并根据最新趋势和技术更新数据湖策略。这有助于保持数据湖的竞争力和适应性。
10. 成功案例分析
- 参考成功案例:例如,某大型金融机构通过构建数据湖成功整合了海量客户交易数据、市场分析数据等,实现了数据来源的多样性,提升了数据存取效率并降低了管理成本。
- 阿里云的最佳实践:阿里云的数据湖构建服务(DLF)提供了湖上元数据统一管理和企业级权限控制,无缝对接多种计算引擎,打破数据孤岛,实现业务价值。
11. 技术架构
- 技术架构的选择:选择合适的技术架构是成功的关键。例如,使用Apache Spark等分布式计算框架进行实时和批处理数据预处理,以及使用Query and Analytics引擎支持高级SQL查询。
- 云平台的优势:利用云平台提供的原生支持和高级分析能力,可以显著提升数据湖的性能和灵活性。
12. 最佳实践总结
- 了解数据湖的使用场合:摒弃将所有数据收集到一个Hadoop库的想法,认识到它并非企业数据管理系统和实践的替代品。
- 运用现有的数据管理最佳实践:如审计跟踪记录、数据完整性、数据治理和数据所有权。
- 知道数据湖的业务理由:选择合适的架构,如传统关系数据库、Hadoop集群或NoSQL数据库。
- 支持元数据:元数据是数据湖成功的关键,而非数据墓地。
如何监控和优化数据湖的性能,同时降低成本?
监控和优化数据湖的性能,同时降低成本,需要从多个方面入手,包括架构设计、存储技术、查询优化、数据生命周期管理以及成本控制等。以下是基于我搜索到的资料整理出的详细策略:
1. 架构设计与存储优化
- 选择高效的存储格式:使用列式存储引擎(如Apache Parquet或ORC)可以显著提高查询性能并降低存储成本。
- 冷存储策略:将不经常访问的数据迁移到更便宜的存储层(如云中的冷存储),以减少存储费用。
- 分区和索引技术:通过数据分区和创建索引,可以减少查询扫描的数据量,从而提高查询效率并降低计算资源消耗。
2. 查询性能优化
- 实时监控与诊断:通过实时监控集群运行指标,快速定位性能瓶颈,并提供针对性的优化建议。
- 缓存和索引优化:利用数据库缓存和索引优化技术,提高查询速度。
- 分布式文件系统:采用分布式文件系统(如HDFS)和内存计算框架(如Spark),进一步提升数据处理效率。
3. 数据生命周期管理
- 自动化数据存档与清理:通过自动化工具定期清理不再需要的数据,确保数据相关性并降低成本。
- 数据保留策略:制定合理的数据保留策略,平衡合规性和成本。
4. 成本管理
- 基于云的成本策略:利用云平台提供的按需计费模式,避免资源浪费,实现成本优化。
- 资源调度与优化:合理分配计算资源,避免资源闲置或过度使用,从而降低总体成本。
5. 数据治理与安全
- 数据质量和治理:建立数据质量控制流程,确保数据的一致性和准确性。
- 访问控制与加密:实施严格的访问控制和加密措施,保障数据安全。
6. 工具与平台选择
- 选择合适的数据湖平台:根据需求选择合适的数据湖平台(如Amazon S3、Google Cloud或Azure),并利用其内置工具进行优化。
- 自动化工具:使用如Upsolver等工具,自动化实施最佳实践,加速构建高效的数据湖。
7. 实践案例与经验总结
- Paimon数据湖优化:通过实时监控和诊断,快速定位性能瓶颈,并提供有针对性的优化方案。
- SQL Server 数据湖应用:结合SQL Server数据库和数据湖技术,通过环境配置、核心模块实现及测试,提升查询速度。
总结
监控和优化数据湖的性能,同时降低成本的关键在于:
- 构建高效的数据存储架构;
- 采用先进的查询优化技术;
- 实施严格的数据生命周期管理;
- 利用云平台的按需计费模式;
- 强化数据治理与安全措施。
相关文章:
如何建设一个企业级的数据湖
建设一个企业级的数据湖是一项复杂且系统化的工程,需要从需求分析、技术选型、架构设计到实施运维等多个方面进行综合规划和实施。以下是基于我搜索到的资料,详细阐述如何建设企业级数据湖的步骤和关键要点: 一、需求分析与规划 明确业务需…...
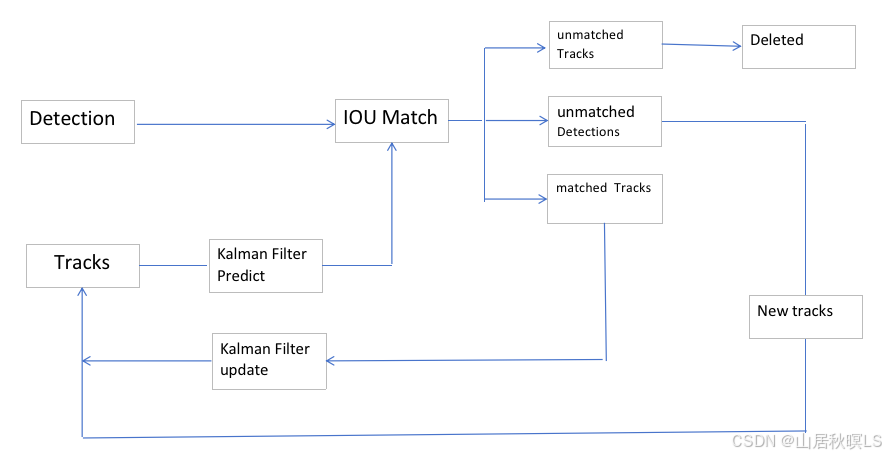
目标跟踪之sort算法(3)
这里写目录标题 1 流程1 预处理2 跟踪 2 代码 参考:sort代码 https://github.com/abewley/sort 1 流程 1 预处理 1.1 获取离线检测数据。1.2 实例化跟踪器。2 跟踪 2.1 轨迹处理。根据上一帧的轨迹预测当前帧的轨迹,剔除到当前轨迹中为空的轨迹得到当前…...

【java数据结构】HashMapOJ练习题
【java数据结构】HashMapOJ练习题 一、只出现一次的数字二 、随机链表的复制三 、宝石与石头四、坏键盘打字五、前K个高频单词 博客最后附有整篇博客的全部代码!!! 一、只出现一次的数字 只出现一次的数字 思路: 先遍历一遍数组…...

Nginx前端后端共用一个域名如何配置
在 Nginx 中配置前端和后端共用一个域名的情况,通常是通过路径或子路径将请求转发到不同的服务。以下是一个示例配置,假设: 前端静态文件在 /var/www/frontend/。 后端 API 服务运行在 http://127.0.0.1:5000。 域名是 example.comÿ…...
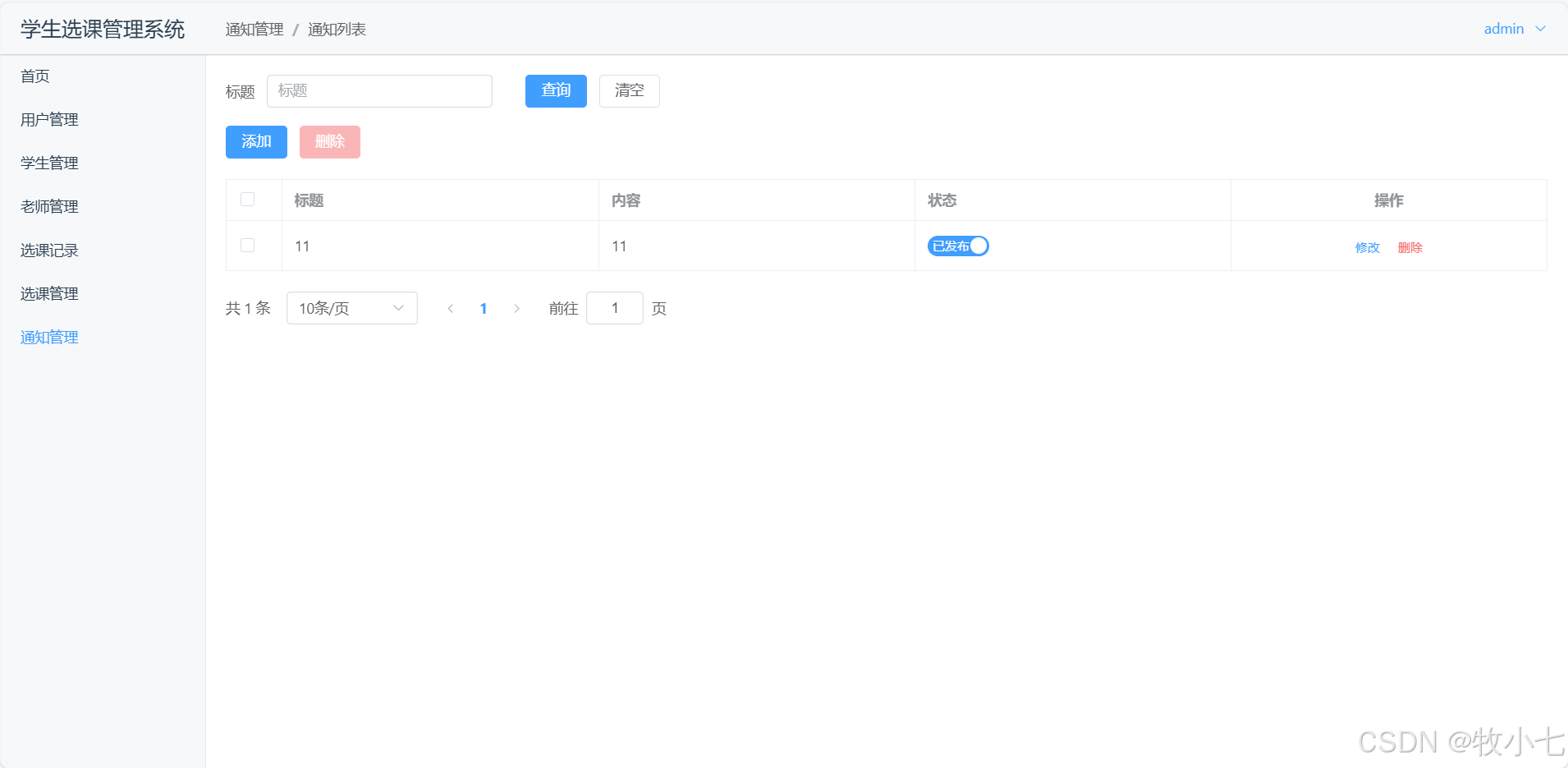
SpringBoot3+Vue3开发学生选课管理系统
功能介绍 分三个角色登录:学生登录,老师登录,教务管理员登录,不同用户功能不同! 1.学生用户功能 选课记录,查看选课记录,退选。选课管理,进行选课。通知管理,查看通知消…...

Linux系统 C/C++编程基础——基于GTK+的图形用户界面编程
ℹ️大家好,我是练小杰,今天星期三了,距离除夕又少了一天,新年的钟声就快敲响了😆 本文是有关Linux C/C编程中的基于GTK的图形用户界面编程知识点,后续会不断添加相关内容 ~~ 回顾:【使用make工具和Makefil…...

【Leetcode 每日一题】40. 组合总和 II
问题背景 给定一个候选人编号的集合 c a n d i d a t e s candidates candidates 和一个目标数 t a r g e t target target,找出 c a n d i d a t e s candidates candidates 中所有可以使数字和为 t a r g e t target target 的组合。 c a n d i d a t e s c…...

python 变量范围的定义与用法
文章目录 1. 局部变量(Local Scope)示例: 2. 嵌套函数变量(Enclosing Scope)示例:说明: 3. 全局变量(Global Scope)示例:说明: 4. 内置变量&#…...
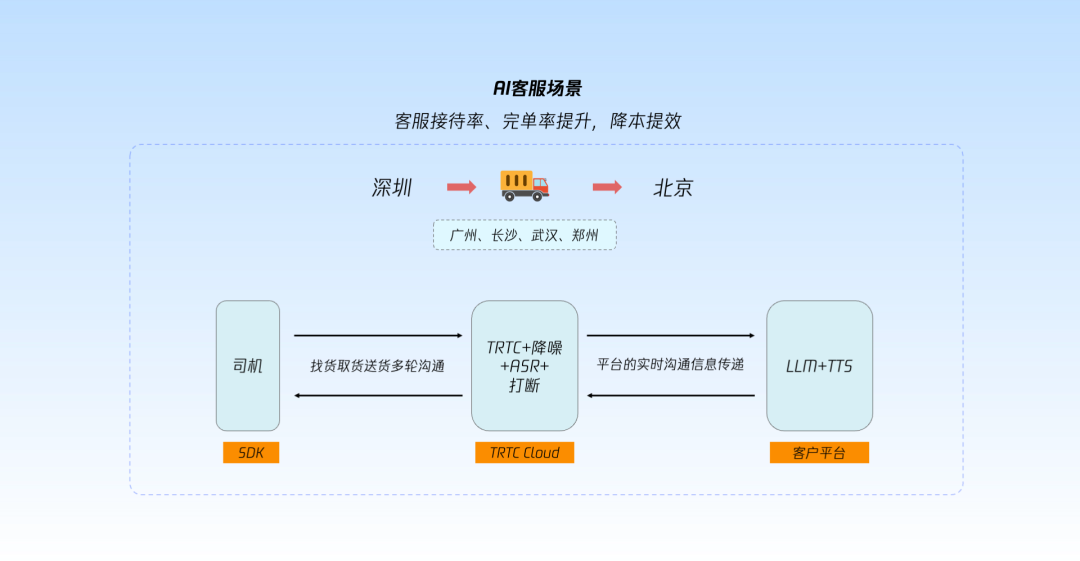
TRTC实时对话式AI解决方案,助力人机语音交互极致体验
近年来,AI热度持续攀升,无论是融资规模还是用户热度都大幅增长。2023 年,中国 AI 行业融资规模达2631亿人民币,较2022年上升51%;2024年第二季度,全球 AI 初创企业融资规模为 240 亿美金,较第一季…...
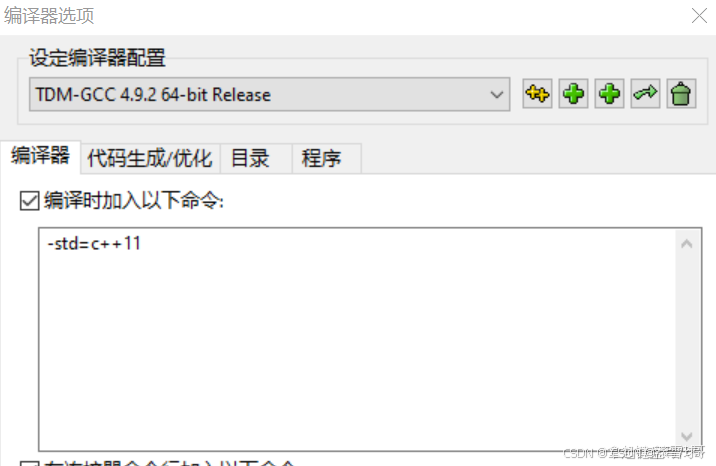
dev c++ ‘unordered_set‘ does not name a type
参考:https://blog.csdn.net/Zaczc/article/details/142531525 启用C11标准步骤 工具->编译选项 勾选编译时加入以下命令 在空白处添加:-stdc11 单击确定,启用成功...

算法每日双题精讲 —— 二分查找(寻找旋转排序数组中的最小值,点名)
🌟快来参与讨论💬,点赞👍、收藏⭐、分享📤,共创活力社区。 🌟 别再犹豫了!快来订阅我们的算法每日双题精讲专栏,一起踏上算法学习的精彩之旅吧💪 在算法的…...

three.js+WebGL踩坑经验合集(4.2):为什么不在可视范围内的3D点投影到2D的结果这么不可靠
上一篇,笔者留下了一个问题,three.js内置的THREE.Vector3.project方法算出来的结果对于超出屏幕可见范围的点来说错得相当离谱。 three.jsWebGL踩坑经验合集(4.1):THREE.Line2的射线检测问题(注意本篇说的是Line2,同样也不是阈值…...
- kafka 查看kafka的运行状态、broker.id不一致导致启动失败问题、topic消息积压量告警监控脚本)
Kafka运维宝典 (二)- kafka 查看kafka的运行状态、broker.id不一致导致启动失败问题、topic消息积压量告警监控脚本
Kafka运维宝典 (二) 文章目录 Kafka运维宝典 (二)一、kafka broker.id冲突问题1. broker.id 冲突的影响2. 如何发现 broker.id 冲突3. 解决 broker.id 冲突的方法4. broker.id 配置管理5. 集群启动后确认 broker.id 唯一性6. brok…...
全球AI模型百科全书,亚马逊云科技Bedrock上的100多款AI模型
今天小李哥给大家介绍的是亚马逊云科技上的AI模型管理平台Amazon Bedrock上的Marketplace,这是亚马逊云科技在今年re:Invent发布的一个全新功能,将亚马逊的电商基因带到了其云计算平台,让我们能够通过Amazon Bedrock访问100多种流行、新兴和专…...
微信小程序中常见的 跳转方式 及其特点的表格总结(wx.navigateTo 适合需要返回上一页的场景)
文章目录 详细说明总结wx.navigateTo 的特点为什么 wx.navigateTo 最常用?其他跳转方式的使用频率总结 以下是微信小程序中常见的跳转方式及其特点的表格总结: 跳转方式API 方法特点适用场景wx.navigateTowx.navigateTo({ url: 路径 })保留当前页面&…...

【Elasticsearch】index:false
在 Elasticsearch 中,index 参数用于控制是否对某个字段建立索引。当设置 index: false 时,意味着该字段不会被编入倒排索引中,因此不能直接用于搜索查询。然而,这并不意味着该字段完全不可访问或没有其他用途。以下是关于 index:…...
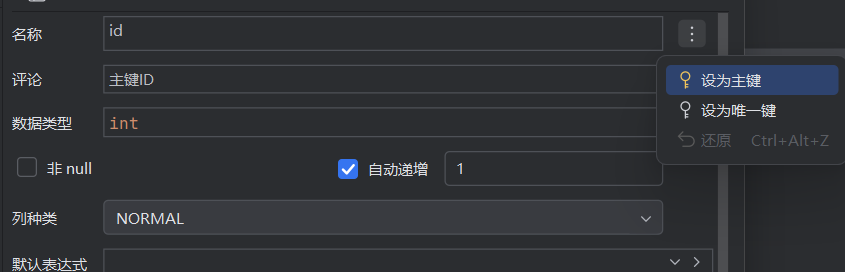
新版IDEA创建数据库表
这是老版本的IDEA创建数据库表,下面可以自己勾选Not null(非空),Auto inc(自增长),Unique(唯一标识)和Primary key(主键) 这是新版的IDEA创建数据库表,Not null和Auto inc可以看得到,但Unique和Primary key…...
输入带空格的字符串,求单词个数
输入带空格的字符串,求单词个数 __ueooe_eui_sjje__ ---->3syue__jdjd____die_ ---->3shuue__dju__kk ---->3 #include <stdio.h> #include <string.h>// 自定义函数来判断字符是否为空白字符 int isSpace(char c) {return c || c \t || …...

C语言程序设计十大排序—希尔排序
文章目录 1.概念✅2.希尔排序🎈3.代码实现✅3.1 直接写✨3.2 函数✨ 4.总结✅ 1.概念✅ 排序是数据处理的基本操作之一,每次算法竞赛都很多题目用到排序。排序算法是计算机科学中基础且常用的算法,排序后的数据更易于处理和查找。在计算机发展…...
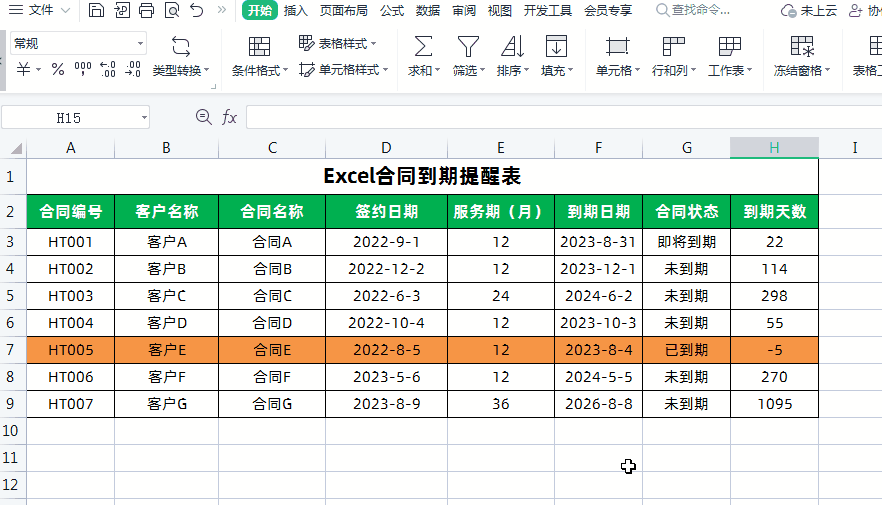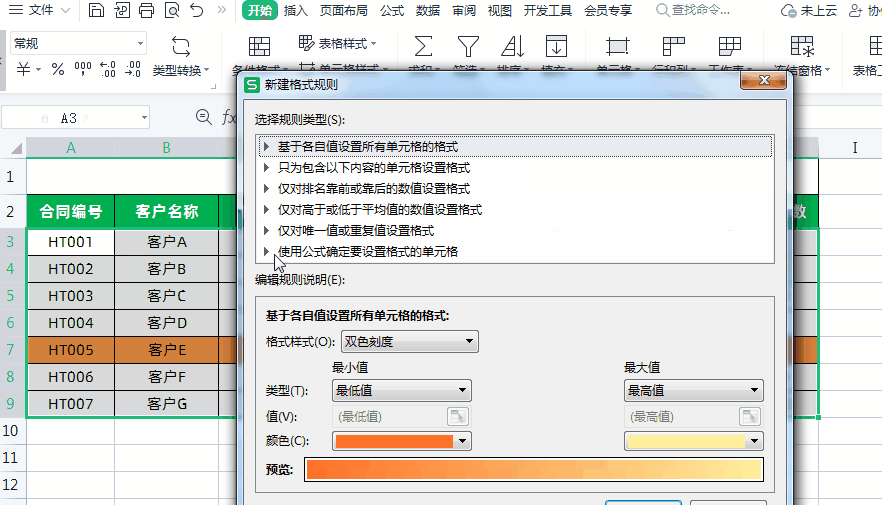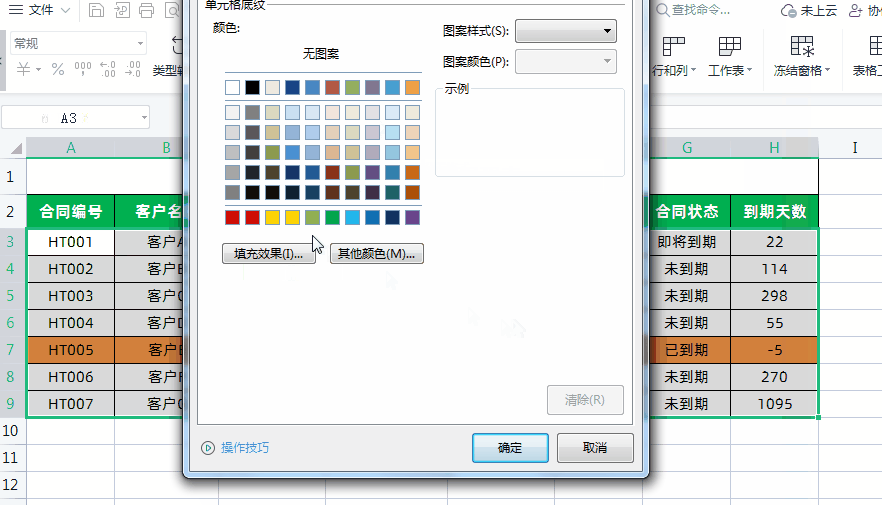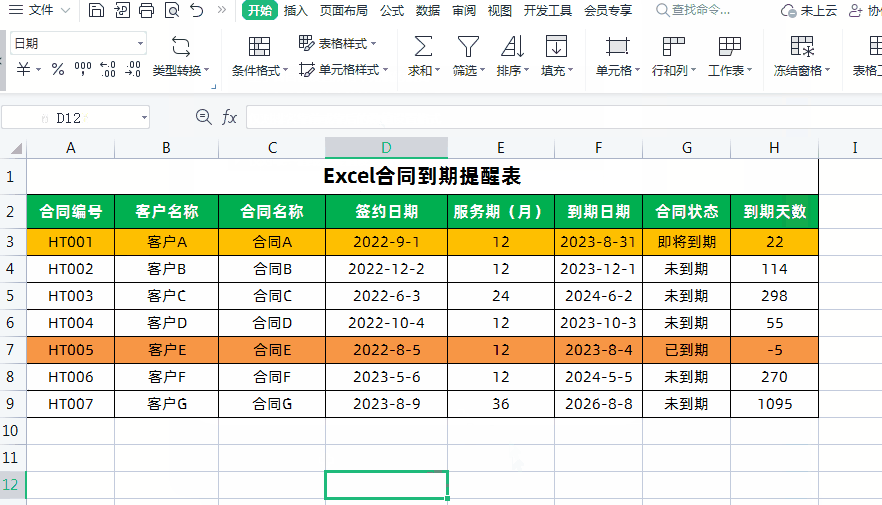
Excel制作合同到期自动提醒!
大家好,我是小鱼。 今天分享一下如何利用Excel制作合同到期提醒表,实现Excel表格自动计算合同到期日和天数,根据合同状态和到期天数自动填充颜色提醒,超实用。先看一下效果,已经到期的合同会自动被填充为红色…...

ZjDroid命令大全:从DEX内存dump到Lua脚本注入的完整教程
ZjDroid命令大全:从DEX内存dump到Lua脚本注入的完整教程 【免费下载链接】ZjDroid Android app dynamic reverse tool based on Xposed framework. 项目地址: https://gitcode.com/gh_mirrors/zj/ZjDroid ZjDroid是一款基于Xposed框架的Android应用动态逆向分…...

Shiro RememberMe反序列化漏洞深度解析与实战利用
1. 这个漏洞不是“老古董”,而是理解Java安全边界的活教材很多人看到CVE-2016-4437,第一反应是“Shiro都淘汰了,还讲这个干啥?”——我去年在给一家做政企内部系统的客户做渗透复测时,就遇到过一个上线三年的审批平台&…...
 显卡排行榜 天梯图)
top50 BF16算力(TFLOPS) 显卡排行榜 天梯图
排名显卡型号BF16算力(TFLOPS)售价(元)单TFLOPS价格(元)1B200(SXM)45002200000488.892H200(SXM)19801200000606.063MI300X1307750000573.834H100 SXM519501100000564.105RTX PRO 6000 Blackwell1150780000678.266H100 PCIe 80GB1560850000544.877RTX 50906803400050.008A100 80…...

告别FTP龟速:用NTFS-3G在CentOS7上直连移动硬盘拷贝200G大文件
告别FTP龟速:用NTFS-3G在CentOS7上直连移动硬盘拷贝200G大文件当面对数百GB的设计素材、日志文件或数据库备份需要迁移时,传统的FTP传输往往会成为效率瓶颈。我曾在一个视频处理项目中,需要将230GB的4K原始素材从移动硬盘导入服务器ÿ…...

《我看见的世界:李飞飞自传》第1-6章阅读笔记:从移民少女到AI教母的“看见“之旅
前言 当我们谈论人工智能时,我们谈论的是算法、数据、算力,是那些冰冷的代码和复杂的模型。但在《我看见的世界:李飞飞自传》中,李飞飞用她独特的视角告诉我们:AI的本质,是人类对"看见"世界的渴望…...

Sangfor文件夹可以删除吗?【图文讲解】深信服文件夹残留清理?如何彻底删除深信服?Sangfor文件夹是什么?
(1)问题背景打开C盘,突然冒出个Sangfor 文件夹,占用好几个 GB 空间,想删又不敢删,怕删坏系统、断网崩溃;上网一查,说法五花八门,有人说是病毒,有人说是办公软…...

浏览器指纹识别机制深度剖析与反识别技术实现
一、浏览器指纹技术基础认知1.1 浏览器指纹的核心定义在数字化时代,每一台接入互联网的设备都会留下独特的数字标识,浏览器指纹便是其中最关键的识别凭证之一。浏览器指纹是网站通过 JavaScript 脚本、HTTP 请求头、硬件接口调用等多种技术手段ÿ…...

基于STM32WL与LoRaWAN的远程空气质量监测系统全栈开发实践
1. 项目概述:构建一个远程空气质量监测系统最近在做一个挺有意思的玩意儿:一个能自己找地方待着、靠太阳能供电,然后把周围空气数据悄无声息传回来的远程监测终端。核心想法很简单,就是想知道某个犄角旮旯,比如工厂周边…...

JavaScript对象创建:告别繁琐,四种灵活写法一学就会
在JavaScript里,创建对象的这般方法常把刚开始学习的新手弄得困惑不已,好像无论走哪条道都行得通,可又不清楚该挑哪一条才好。我编写JavaScript都有十几年功夫了,对象创建这事差不多每天都会碰到可谓基础技能。它不像变量声明那般…...

DSP、FPGA、STM32大对决:谁才是嵌入式开发的“天选之子”?
在嵌入式开发的广阔天地里,DSP、FPGA 和 STM32(作为通用 MCU 的典型代表)可以说是三款绕不开的核心处理器。很多初学者甚至有一定经验的工程师在选择时都会陷入纠结:我的项目到底该选哪一个?为了帮你彻底理清思路&…...