多模态论文笔记——TECO
大家好,这里是好评笔记,公主号:Goodnote,专栏文章私信限时Free。本文详细解读多模态论文TECO(Temporally Consistent Transformer),即时间一致变换器,是一种用于视频生成的创新模型,旨在解决现有视频生成算法在处理长时依赖关系和时间一致性方面的不足。

文章目录
- 论文
- 摘要
- 1. 引言
- 2. 预备知识
- 2.1 VQ-GAN
- 2.2 MaskGit
- 3. TECO
- 3.1 架构概述
- 编码器
- 时间变换器
- 解码器
- 空间MaskGit
- 训练目标
- 3.2 DropLoss
- 4. 实验
- 4.1 数据集
- 4.2 基线模型
- 4.3 实验设置
- 训练
- 评估
- 4.4 基准测试结果
- 4.5 消融实验
- 4.6 进一步见解
- 5. 讨论
- 热门专栏
- 机器学习
- 深度学习
论文
论文名:Temporally Consistent Transformers for Video Generation
论文链接:https://arxiv.org/pdf/2210.02396
项目地址:https://wilson1yan.github.io/teco
摘要
在视频生成领域,精确捕捉空间和时间依赖关系是生成高质量视频的关键,但现有算法存在显著缺陷,本文提出创新解决方案,具体内容如下:
- 现有算法问题:当前算法虽能在短时间内准确预测,却普遍存在时间不一致问题。当生成内容暂时移出视野后再次出现时,模型会生成与之前不同的内容,这严重影响视频质量。
- 缺乏评估基准:目前,针对具有长时依赖关系的视频生成任务,缺少成熟、可靠的评估基准,阻碍了该领域的发展。
- 构建挑战性数据集:为解决评估难题,作者精心构建了3个具有长程依赖关系的视频数据集,为评估模型在复杂环境下处理长时依赖关系的能力提供了有效工具。
- 评估现有模型:利用构建的数据集,对当前的视频生成模型进行全面评估,清晰地观察到这些模型在时间一致性方面存在的局限性,为后续改进和创新提供了方向。
- 提出TECO模型:为改善现有问题,引入了时间一致变换器(TECO)。这是一种新型生成模型,它通过压缩输入序列、应用时间变换器以及利用空间MaskGit扩展等操作,在提高视频长期一致性的同时,还能减少采样时间,在众多评估指标上超越了现有的视频生成模型。
- 成果展示:文章提供了TECO模型在多个数据集上的视频预测样本,同时展示了部分样本对应的3D可视化效果。
1. 引言
最近,在复杂视频数据上生成高保真且多样样本方面取得巨大进展,主要得益于计算资源增加和高效大容量神经架构。然而,这些进展大多集中在生成短视频上。基于短上下文窗口的模型虽能以滑动窗口方式生成长视频,但缺乏时间一致性,无法在相机平移回原位置时生成相同内容,对未观察位置的预测也难以与新想象场景保持一致。
已有研究针对长期依赖关系建模,包括时间层次结构、带有逐帧插值的跨步采样等技术,还有在稀疏帧集上训练或通过压缩表示对视频建模的方法,详细内容可参考附录L。
但是当前的视频生成方法在处理长程依赖数据集和评估时间一致性方面存在的问题,具体如下:
- 长程依赖数据集处理难题:众多视频生成方法在扩展到具有大量长程依赖关系的数据集时面临困境。例如,Clockwork-VAE受递归影响,训练时间长且难以适应复杂数据;基于潜在空间的变换器方法因注意力机制的二次复杂度,处理长视频时扩展性不佳;在标记子集上训练的方法受截断时间反向传播或简单时间操作的制约。
- 时间一致性评估缺失:目前缺少能准确评估视频生成方法时间一致性的基准。以往工作,有的聚焦于仅靠短期依赖就能精准预测的长视频生成,有的依赖对图像保真度敏感但无法捕捉长程时间依赖的指标,如FVD。
在本文中,作者引入了一组新颖的长时视频生成基准以及相应的评估指标,以更好地捕捉时间一致性。此外,还提出了时间一致视频变换器(TECO),这是一种向量量化的潜在动力学模型,它使用高效的变换器在紧凑的表示空间中有效地对长期依赖关系进行建模。主要贡献总结如下:
- 提出了3个具有长程依赖关系的视频数据集及相关指标,用于更好地评估视频预测中的时间一致性。数据集包括DMLab、我的世界和Habitat中的3D场景生成。
- 在这些数据集上对最先进的视频生成模型进行基准测试,并分析每个模型学习长时依赖关系的能力。
- 引入了TECO,这是一种高效且可扩展的视频生成模型,它学习压缩表示,以便进行高效的训练和生成。作者展示了TECO在各种具有挑战性的视频预测任务上具有强大的性能,并且能够利用长期时间上下文生成高质量且一致的视频,同时保持快速的采样速度。
2. 预备知识
2.1 VQ-GAN
VQ-GAN是一种自动编码器,它学习将数据压缩为离散的潜在表示,由编码器 E E E、解码器 G G G、码本 C C C和判别器 D D D组成。过程如下:
- 给定一个图像 x ∈ R H × W × 3 x \in \mathbb{R}^{H×W×3} x∈RH×W×3,编码器 E E E将 x x x映射到其潜在表示 h ∈ R H ′ × W ′ × D h \in \mathbb{R}^{H'×W'×D} h∈RH′×W′×D,
- 通过在由嵌入 C = { e i } i = 1 K C = \{e_{i}\}_{i = 1}^{K} C={ei}i=1K组成的码本中进行最近邻查找对其进行量化,生成 z ∈ R H ′ × W ′ × D z \in \mathbb{R}^{H'×W'×D} z∈RH′×W′×D。
- z z z通过解码器 G G G进行重构得到 x ^ \hat{x} x^。
在这个过程中,直通估计器(Bengio,2013)用于在量化步骤中保持梯度流动。码本优化以下损失:
L V Q = ∥ s g ( h ) − e ∥ 2 2 + β ∥ h − s g ( e ) ∥ 2 2 ( 1 ) \mathcal{L}_{VQ}=\| sg(h)-e\| _{2}^{2}+\beta\| h-sg(e)\| _{2}^{2} (1) LVQ=∥sg(h)−e∥22+β∥h−sg(e)∥22(1)
其中:
- L V Q \mathcal{L}_{VQ} LVQ:VQ - GAN中码本优化的矢量量化损失,用于衡量量化过程误差。
- h h h:编码器输出的潜在表示。
- e e e:码本 c c c中与 h h h最接近的嵌入向量。
- s g ( ⋅ ) sg(\cdot) sg(⋅):停止梯度操作符,保证量化过程中梯度正确流动。
- β \beta β:超参数,常取0.25,控制两部分损失的相对权重。
公式由两部分组成, ∥ s g ( h ) − e ∥ 2 2 \| sg(h)-e\| _{2}^{2} ∥sg(h)−e∥22关注编码误差, β ∥ h − s g ( e ) ∥ 2 2 \beta\| h - sg(e)\| _{2}^{2} β∥h−sg(e)∥22关注解码误差。
其中 β = 0.25 \beta = 0.25 β=0.25是一个超参数, e e e是从码本 C C C中得到的最近邻嵌入。为了进行重构,VQ-GAN用感知损失(Zhang等人,2012) L L P I P S \mathcal{L}_{LPIPS} LLPIPS代替了原来的 ℓ 2 \ell_{2} ℓ2损失。最后,为了鼓励生成更高保真度的样本,训练补丁级判别器 D D D 对真实图像和重构图像进行分类,损失为:
L G A N = l o g D ( x ) + l o g ( 1 − D ( x ^ ) ) ( 2 ) \mathcal{L}_{GAN}=log D(x)+log (1-D(\hat{x})) (2) LGAN=logD(x)+log(1−D(x^))(2)
其中:
- L G A N \mathcal{L}_{GAN} LGAN:生成对抗网络(GAN)的损失函数,用于训练判别器以区分真实图像和生成图像。
- D D D:判别器,是一个神经网络,用于判断输入图像是真实图像的概率,输出值范围在 [ 0 , 1 ] [0, 1] [0,1]之间。
- x x x:真实图像,来自原始的训练数据集。
- x ^ \hat{x} x^:生成的(重构的)图像,由VQ - GAN的解码器生成。
该公式通过使 D ( x ) D(x) D(x)趋近于1(判别真实图像), D ( x ^ ) D(\hat{x}) D(x^)趋近于0(判别生成图像)来优化判别器。
总体而言,VQ-GAN优化以下损失:
min E , G , C max D L L P I P S + L V Q + λ L G A N ( 3 ) \min_{E, G, C} \max_{D} \mathcal{L}_{LPIPS}+\mathcal{L}_{VQ}+\lambda \mathcal{L}_{GAN} (3) E,G,CminDmaxLLPIPS+LVQ+λLGAN(3)
- L L P I P S \mathcal{L}_{LPIPS} LLPIPS:基于学习的感知图像块相似性损失(Learned Perceptual Image Patch Similarity)。它是一种感知损失,用于衡量生成图像与真实图像在感知上的差异,更符合人类对图像相似性的主观判断。
- L V Q \mathcal{L}_{VQ} LVQ:矢量量化损失,用于优化码本。它包含两部分,主要衡量编码器输出的潜在表示与码本中最近邻嵌入向量之间的编码和解码误差,公式为 L V Q = ∥ s g ( h ) − e ∥ 2 2 + β ∥ h − s g ( e ) ∥ 2 2 \mathcal{L}_{VQ}=\| sg(h)-e\| _{2}^{2}+\beta\| h - sg(e)\| _{2}^{2} LVQ=∥sg(h)−e∥22+β∥h−sg(e)∥22。
- L G A N \mathcal{L}_{GAN} LGAN:生成对抗网络的损失,用于训练判别器区分真实图像和生成图像,公式为 L G A N = log D ( x ) + log ( 1 − D ( x ^ ) ) \mathcal{L}_{GAN}=\log D(x)+\log (1 - D(\hat{x})) LGAN=logD(x)+log(1−D(x^))。
- λ \lambda λ:自适应权重,用于平衡 L G A N \mathcal{L}_{GAN} LGAN与其他损失项的相对重要性,其计算公式为 λ = ∥ ∇ G L L L P I P S ∥ 2 ∥ ∇ G L L G A N ∥ 2 + δ \lambda=\frac{\left\|\nabla_{G_{L}} L_{LPIPS}\right\|_{2}}{\left\|\nabla_{G_{L}} L_{GAN}\right\|_{2}+\delta} λ=∥∇GLLGAN∥2+δ∥∇GLLLPIPS∥2,其中 G L G_{L} GL是解码器的最后一层, δ \delta δ是一个小的常数(如 δ = 1 0 − 6 \delta = 10^{-6} δ=10−6)。
其中 λ = ∥ ∇ G L L L P I P S ∥ 2 ∥ ∇ G L L G A N ∥ 2 + δ \lambda=\frac{\left\|\nabla_{G_{L}} \mathcal{L}_{LPIPS}\right\|_{2}}{\left\|\nabla_{G_{L}} \mathcal{L}_{GAN}\right\|_{2}+\delta} λ=∥∇GLLGAN∥2+δ∥∇GLLLPIPS∥2是一个自适应权重, G L G_{L} GL是解码器的最后一层, δ = 1 0 − 6 \delta = 10^{-6} δ=10−6, L L P I P S \mathcal{L}_{LPIPS} LLPIPS是Zhang等人(2012)中描述的相同距离度量。
VQ其实就是向量量化的意思,在之前的系列文章中,我们介绍了VAE的向量量化版本:多模态论文笔记——VQ-VAE和VQ-VAE-2
2.2 MaskGit
MaskGit 对离散标记(如由VQ-GAN生成的标记)的分布进行建模。它通过在训练期间使用掩码标记预测目标,以一小部分采样成本生成与自回归模型具有竞争力的样本质量的图像。
形式上,将 z ∈ Z H × W z \in \mathbb{Z}^{H×W} z∈ZH×W表示为代表图像的离散潜在标记。对于每个训练步骤,均匀采样 t ∈ [ 0 , 1 ) t \in [0, 1) t∈[0,1),并随机生成一个掩码 m ∈ { 0 , 1 } H × W m \in \{0, 1\}^{H×W} m∈{0,1}H×W,其中有 N = ⌈ γ H W ⌉ N=\lceil\gamma H W\rceil N=⌈γHW⌉个被掩码的值,这里 γ = cos ( π 2 t ) \gamma=\cos (\frac{\pi}{2} t) γ=cos(2πt)。然后,MaskGit通过以下目标学习预测被掩码的标记:
L m a s k = − E z ∈ D [ log p ( z ∣ z ⊙ m ) ] \mathcal{L}_{mask }=-\mathbb{E}_{z \in \mathcal{D}}[\log p(z | z \odot m)] Lmask=−Ez∈D[logp(z∣z⊙m)]
在推理期间,由于MaskGit已被训练以对任何一组无条件和条件概率进行建模,我们可以在每次采样迭代中对任何标记子集进行采样。Chang等人(2022)引入了一种基于置信度的采样机制,而其他工作(Lee等人,2022)提出了一种迭代采样和修正方法。
3. TECO
作者提出时间一致视频变换器(TECO),这是一种视频生成模型,能够更有效地扩展到对更长时间范围的视频进行训练。
3.1 架构概述

图3. TECO的架构设计。(a) 以往基于VQ编码的视频生成模型,会对所有编码采用单一的时空变换器。由于注意力机制具有二次方复杂度,在扩展到长序列时,这种方法的计算成本过高。(b) 我们提出一种新颖且高效的架构,先在空间上进行大幅下采样,再将数据输入到时间变换器中,然后通过逐帧单独应用的空间MaskGit恢复到原始空间尺寸。在图中,变换器模块展示了注意力连接的数量。在300帧的训练序列上,与现有模型相比,TECO的效率提升了几个数量级,使得在给定的计算资源下能够使用更大的模型。
作者提出的框架(如图3所示)含一系列视频帧 x 1 : T x_{1:T} x1:T,主要创新是设计出能扩展到长序列的高效架构。
- 先前方法:先前先进方法在VQ码上训练单一时空变换器对每个码进行建模,处理含数万个标记的序列成本极高,但能学习高度多模态分布且在复杂视频上扩展性好。
- TECO架构目标:保留高容量扩展特性,同时使训练和推理效率提升几个数量级。
在以下部分,将阐述模型各组件的设计动机,并给出一些具体的设计选择,以确保效率和可扩展性。TECO由四个组件(公式 5 )组成:
- 编码器: z t = E ( x t , x t − 1 ) z_{t}=E(x_{t}, x_{t - 1}) zt=E(xt,xt−1)
- 时间变换器: h t = H ( z ≤ t ) h_{t}=H(z_{\leq t}) ht=H(z≤t)
- 空间MaskGit: p ( z t ∣ h t − 1 ) p(z_{t} | h_{t - 1}) p(zt∣ht−1)
- 解码器: p ( x t ∣ z t , h t − 1 ) p(x_{t} | z_{t}, h_{t - 1}) p(xt∣zt,ht−1)
编码器
利用视频数据中的时空冗余来实现压缩表示。为此,作者提出学习一个CNN编码器 z t = E ( x t , x t − 1 ) z_{t}=E(x_{t}, x_{t - 1}) zt=E(xt,xt−1),它通过在通道维度上连接前一帧 x t − 1 x_{t - 1} xt−1对当前帧 x t x_{t} xt进行编码,然后使用码本 c c c对输出进行量化以生成 z t z_{t} zt。作者还做了如下的优化:
- 在每个时间步应用公式(1)中定义的VQ损失。
- 对码本和嵌入进行 ℓ 2 \ell_{2} ℓ2归一化,以鼓励更多地使用码本(Yu等人,2021)。
- 第一帧与零连接,并且不对 z 1 z_{1} z1进行量化以防止信息丢失。
时间变换器
与连续潜在表示相比,压缩的离散潜在表示损失更大,并且往往需要更高的空间分辨率。因此,在对时间信息进行建模之前,先应用一个跨步卷积对每个离散潜在 z t z_{t} zt进行下采样,在视觉上更简单的数据集可以进行更多的下采样,而视觉上复杂的数据集则需要较少的下采样。之后,再学习一个大型变换器对时间依赖关系进行建模,然后应用转置卷积将表示上采样回 z t z_{t} zt的原始分辨率。总之,使用以下架构:
h t = H ( z < t ) = ConvT ( Transformer ( Conv ( z < t ) ) ) h_{t}=H\left(z_{<t}\right)=\text{ConvT}\left(\text{Transformer}\left(\text{Conv}\left(z_{<t}\right)\right)\right) ht=H(z<t)=ConvT(Transformer(Conv(z<t)))
解码器
解码器是一个上采样CNN,用于重建 x ^ t = D ( z t , h t ) \hat{x}_{t}=D(z_{t}, h_{t}) x^t=D(zt,ht),其中 z t z_{t} zt可以解释为时间步 t t t的后验, h t h_{t} ht是时间变换器的输出,它汇总了先前时间步的信息。 z t z_{t} zt和 h t h_{t} ht在通道维度上连接后输入到解码器中。解码器与编码器一起优化以下交叉熵重建损失:
L r e c o n = − 1 T ∑ t = 1 T log p ( x t ∣ z t , h t ) \mathcal{L}_{recon }=-\frac{1}{T} \sum_{t = 1}^{T} \log p\left(x_{t} | z_{t}, h_{t}\right) Lrecon=−T1t=1∑Tlogp(xt∣zt,ht)
这鼓励 z t z_{t} zt特征编码帧之间的相对信息,因为时间变换器输出 h t h_{t} ht随时间聚合信息,从而学习更压缩的代码,以便在更长的序列上进行高效建模。
空间MaskGit
最后,使用MaskGit对先验 p ( z t ∣ h t ) p(z_{t} | h_{t}) p(zt∣ht)进行建模。作者表明,与自回归先验相比,使用MaskGit先验不仅可以实现更快的采样,还能提高采样质量。在每次训练迭代中,我们按照先前的工作对随机掩码 m t m_{t} mt进行采样,并优化:
L p r i o r = − 1 T ∑ t = 1 T log p ( z t ∣ z t ⊙ m t ) \mathcal{L}_{prior }=-\frac{1}{T} \sum_{t = 1}^{T} \log p\left(z_{t} | z_{t} \odot m_{t}\right) Lprior=−T1t=1∑Tlogp(zt∣zt⊙mt)
其中 h t h_{t} ht与被掩码的 z t z_{t} zt在通道维度上连接,以预测被掩码的标记。在生成过程中,作者遵循Lee等人(2022)的方法,即最初每次以 8 个为一组生成每一帧,然后经过两轮修正,每次重新生成一半的标记。
训练目标
最终目标如下:
L T E C O = L V Q + L r e c o n + L p r i o r \mathcal{L}_{TECO }=\mathcal{L}_{VQ}+\mathcal{L}_{recon }+\mathcal{L}_{prior } LTECO=LVQ+Lrecon+Lprior
3.2 DropLoss

图4. DropLoss通过在每次训练迭代中仅对随机选择的时间索引子集计算损失,提高了长序列训练的可扩展性。对于TECO,我们无需为被随机剔除的时间步计算解码器和MaskGit相关内容。
作者提出DropLoss,这是一种简单的技巧,用于实现更具可扩展性和高效的训练(图4)。由于其架构设计,TECO可以分为两个组件:
(1)学习时间表示,由编码器和时间变换器组成;
(2)预测未来帧,由动力学先验和解码器组成。
可以通过随机丢弃不进行解码的时间步来提高训练效率,这些时间步从重建损失中省略。例如,给定一个有 T T T帧的视频,我们计算所有 t ∈ { 1 , … , T } t \in \{1, \ldots, T\} t∈{1,…,T}的 h t h_{t} ht,然后仅对10%的索引计算损失 L p r i o r L_{prior} Lprior和 L r e c o n L_{recon} Lrecon。
由于每次迭代都随机选择索引,模型仍然需要学习准确预测所有时间步。这显著降低了训练成本,因为解码器和动力学先验需要大量计算。DropLoss适用于广泛的架构以及视频预测之外的任务。
4. 实验
4.1 数据集
为衡量视频预测长程一致性,引入三个具挑战性的视频数据集及Kinetics - 600数据集:
- DMLab - 40k:基于DeepMind Lab模拟器生成。在随机纹理的3D迷宫中选点并导航,产生40k个300帧、 64 × 64 64×64 64×64的动作条件视频,智能体在 7 × 7 7×7 7×7迷宫随机遍历。对模型进行动作条件与无条件预测训练,用例在4.3节讨论。
- Minecraft - 200k:源于我的世界游戏,在沼泽生物群系收集200k个300帧、 128 × 128 128×128 128×128的动作条件视频,玩家随机行走与转向,使场景部分进出视野。为便于评估,对模型进行动作条件训练。
- Habitat - 200k:借助Habitat模拟器,编译约1400个室内扫描,生成200k个300帧、 128 × 128 128×128 128×128的动作条件视频,用内置算法构建动作轨迹。对模型进行无条件和动作条件预测训练。
- Kinetics - 600:原用于动作识别的真实世界复杂数据集。在无动作的视频预测任务中评估方法,基于20帧生成80个未来帧,过滤短于100帧视频后,用392k个视频训练评估,分辨率 128 × 128 128×128 128×128。虽长程依赖关系少,但用于表明方法可扩展到复杂自然视频。
4.2 基线模型
我们与从几个不同模型家族中选择的最先进的基线模型进行比较:基于潜在变量的变分模型、自回归似然模型和扩散模型。此外,为了提高效率,我们使用针对每个数据集预训练的VQ-GAN在VQ码上训练所有模型。对于我们的扩散基线模型,我们遵循(Rombach等人,2022)的方法,使用VAE而不是VQ-GAN。请注意,我们的基线模型中没有GAN,因为据我们所知,不存在在潜在空间而不是原始像素上进行训练的GAN,而这对于适当地扩展到长视频序列至关重要。
- 时空变换器相关:将TECO与VideoGPT、Phenaki、MaskViT、Hourglass变换器等时空变换器变体对比,仅在DMLab数据集评估,评估时Phenaki不包含文本条件。
- FitVid:基于CNN和LSTM的先进变分视频模型,通过高效架构设计扩展到复杂视频。
- Clockwork VAE:变分视频模型,借潜在变量层次结构学习长程依赖关系。
- Perceiver AR:作为VQ - GAN离散潜在空间上的AR基线模型,能有效整合长程顺序依赖关系,因其比其他自回归基线模型(如VideoGPT、TATS)在处理大量标记时成本更低而被选用。
- Latent FDM:训练Latent FDM作为扩散基线模型,为公平比较,在潜在空间训练,遵循LDM方法用自动编码器将帧编码为连续潜在变量。
4.3 实验设置
训练
- 训练设置:所有模型在TPU - v3实例(v3 - 8到v3 - 128 TPU pod,类似4个V100到64个V100)上训练,计算预算以TPU - v3天衡量,训练100万次迭代,耗时约3 - 5天。
- 数据集适配:DMLab、Minecraft和Habitat数据集使用完整300帧视频训练,Kinetics - 600用100帧训练。
- VQGAN训练:VQGAN在8个A5000 GPU上训练,每个数据集需2 - 4天,将所有视频下采样到每帧16×16离散潜在网格。具体超参数和计算预算见附录N。
评估
- 传统指标局限:标准评估方法(FVD、PSNR、SSIM、LPIPS)难以衡量长程一致性。FVD对图像保真度敏感且依赖短Kinetics - 600剪辑训练的I3D网络;PSNR、SSIM和LPIPS评估常需采样数百未来帧找最匹配样本,与时间一致性目标不符,因期望模型确定性生成。
- 改进评估指标:提出修改后的评估指标,利用PSNR、SSIM和LPIPS更好衡量时间一致性。对DMLab、Minecraft和Habitat,基于144个过去帧和动作条件设定,用156个未来真实帧测量上述指标;同时在基于36帧条件设定的300帧视频上计算FVD。对Kinetics - 600,在基于20帧条件设定的100帧视频上评估FVD。所有指标在256个示例批次上计算,平均4次运行,共生成1024个样本。
4.4 基准测试结果
在不同数据集上,TECO与其他模型对比结果如下:
- DMLab和Minecraft:定量结果表明,在300帧视频训练时,TECO在所有指标上最优。图6展示其生成的DMLab迷宫更具一致性。CW - VAE、FitVid和Perceiver AR能产生清晰预测,但长程上下文建模欠佳,随预测范围增加,逐帧指标急剧下降。Latent FDM预测有一致性,但因FVD对高频误差敏感,FVD较高。
- Habitat:因模型并行性需求,仅评估Perceiver AR和Latent FDM这两个最强基线模型。由于视频复杂性,所有模型逐帧指标表现不佳,但TECO的FVD明显更优。定性来看,Latent FDM预测易模糊、样本质量差;Perceiver AR生成帧质量高,但时间一致性不如TECO,其生成的智能体运动与实际不符;TECO生成的场景遍历与数据分布更契合。
- Kinetics - 600:在该数据集基于20帧预测80个128×128帧的FVD结果显示,虽数据集长程依赖关系少,但TECO结合更长上下文,生成结果更稳定,退化慢。Perceiver AR易快速退化,Latent FDM表现居中。
4.5 消融实验
在本节通过在SomethingSomething - v2(SSv2)16帧短序列上做消融实验,探究模型架构决策影响,具体如下:
- 证明使用带MaskGit先验的VQ潜在动力学,在复杂真实世界数据上,优于如变分方法等其他潜在动力学模型公式。
- 表明条件编码能为视频预测学习更好的表示。
- 对码本大小消融实验,发现存在最优码本大小,且代码数量不过多就影响不大,过多则难学习先验。
- 展示DropLoss好处,训练速度提升60%,FVD略增,对长序列好处更大,能让视频模型兼顾长程上下文且性能成本低。具体细节见附录表F.1 。
4.6 进一步见解
作者突出了一些设计长程视频生成模型的关键实验见解。更多细节可以在附录I和附录G中找到。
- 保真度与长程依赖的权衡:固定容量网络中,生成高保真与时间一致的视频存在固有权衡。瓶颈表示可侧重长程信息,高分辨率表示能提升保真度。TECO因学习紧凑表示,在保真度与时间一致性间权衡更佳,PSNR/SSIM/LPIPS及FVD表现更优。
- 训练时间与指标变化:训练中,短程指标早期易饱和,长程指标训练后期仍在改善。推测因似然目标下,学习相邻帧比特比长程比特容易。此发现促使TECO采用高效视频架构,在固定预算下增加梯度训练步数。
- 采样速度:图5展示各模型在Minecraft上采样速度,其他数据集使用不同模型大小时结果类似。FitVid和CW - VAE速度快但样本质量差;Perceiver AR和Latent FDM样本质量高,但比TECO慢20 - 60倍;TECO在保证样本质量的同时采样速度较快。
5. 讨论
我们引入了TECO,这是一种高效的视频预测模型,它利用数百帧的时间上下文,以及一个全面的基准来评估长程一致性。我们的评估表明,TECO准确地整合了长程上下文,在广泛的数据集上优于最先进的基线模型。此外,我们引入了几个具有挑战性的视频数据集,希望这些数据集能使未来评估视频预测模型的时间一致性变得更加容易。我们确定了几个限制作为未来工作的方向:
- 评估指标优化:虽在特定条件下PSNR、SSIM和LPIPS可衡量一致性,但随着预测范围增大,需更好的评估指标,因新生成场景与真实情况相关性降低。
- 模型架构拓展:当前重点是结合压缩标记、表达性先验与简单全注意力变换器,参考高效序列模型的前期研究成果,有望进一步扩展模型。
- 训练方式改进:基于预训练的VQ - GAN代码训练模型降低数据维度,虽能训练长序列,但存在重建误差(如Kinetics - 600中的伪影)。TECO直接在像素上训练会因 ℓ 2 \ell_{2} ℓ2损失致预测模糊,采用扩散或GAN损失在像素上训练是值得探索的方向。
热门专栏
机器学习
机器学习笔记合集
深度学习
深度学习笔记合集
相关文章:
多模态论文笔记——TECO
大家好,这里是好评笔记,公主号:Goodnote,专栏文章私信限时Free。本文详细解读多模态论文TECO(Temporally Consistent Transformer),即时间一致变换器,是一种用于视频生成的创新模型&…...

Ubuntu 16.04用APT安装MySQL
个人博客地址:Ubuntu 16.04用APT安装MySQL | 一张假钞的真实世界 安装MySQL 用以下命令安装MySQL: sudo apt-get install mysql-server 这个命令会安装MySQL服务器、客户端和公共文件。安装过程会出现两个要求输入的对话框: 输入MySQL root用户的密…...

Linux 4.19内核中的内存管理:x86_64架构下的实现与源码解析
在现代操作系统中,内存管理是核心功能之一,它直接影响系统的性能、稳定性和多任务处理能力。Linux 内核在 x86_64 架构下,通过复杂的机制实现了高效的内存管理,涵盖了虚拟内存、分页机制、内存分配、内存映射、内存保护、缓存管理等多个方面。本文将深入探讨这些机制,并结…...

JavaScript逆向高阶指南:突破基础,掌握核心逆向技术
JavaScript逆向高阶指南:突破基础,掌握核心逆向技术 JavaScript逆向工程是Web开发者和安全分析师的核心竞争力。无论是解析混淆代码、分析压缩脚本,还是逆向Web应用架构,掌握高阶逆向技术都将助您深入理解复杂JavaScript逻辑。本…...

嵌入式知识点总结 Linux驱动 (四)-中断-软硬中断-上下半部-中断响应
针对于嵌入式软件杂乱的知识点总结起来,提供给读者学习复习对下述内容的强化。 目录 1.硬中断,软中断是什么?有什么区别? 2.中断为什么要区分上半部和下半部? 3.中断下半部一般如何实现? 4.linux中断的…...

在ubuntu下一键安装 Open WebUI
该脚本用于自动化安装 Open WebUI,并支持以下功能: 可选跳过 Ollama 安装:通过 --no-ollama 参数跳过 Ollama 的安装。自动清理旧目录:如果安装目录 (~/open-webui) 已存在,脚本会自动删除旧目录并重新安装。完整的依…...

c语言网 1127 尼科彻斯定理
原题 题目描述 验证尼科彻斯定理,即:任何一个整数m的立方都可以写成m个连续奇数之和。 输入格式 任一正整数 输出格式 该数的立方分解为一串连续奇数的和 样例输入 13 样例输出 13*13*132197157159161163165167169171173175177179181 #include<ios…...
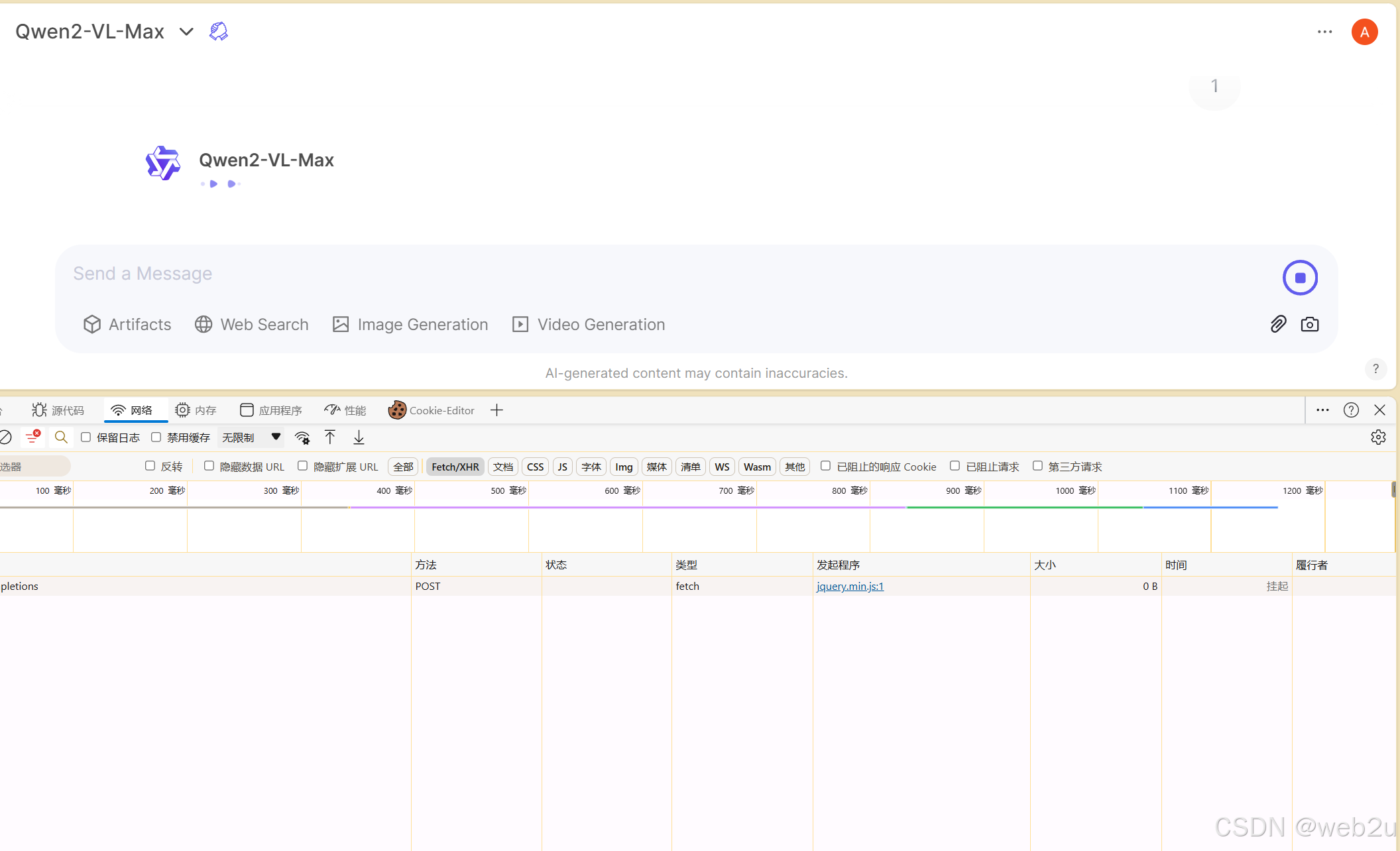
Cloudflare通过代理服务器绕过 CORS 限制:原理、实现场景解析
第一部分:问题背景 1.1 错误现象复现 // 浏览器控制台报错示例 Access to fetch at https://chat.qwenlm.ai/api/v1/files/ from origin https://ocr.doublefenzhuan.me has been blocked by CORS policy: Response to preflight request doesnt pass access con…...
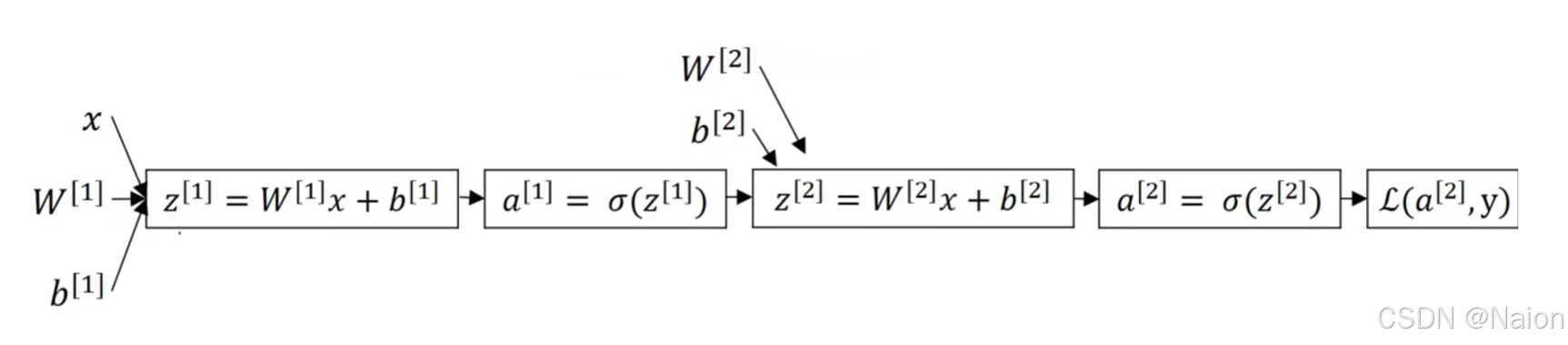
吴恩达深度学习——如何实现神经网络
来自吴恩达深度学习,仅为本人学习所用。 文章目录 神经网络的表示计算神经网络的输出激活函数tanh选择激活函数为什么需要非激活函数双层神经网络的梯度下降法 随机初始化 神经网络的表示 对于简单的Logistic回归,使用如下的计算图。 如果是多个神经元…...

《STL基础之vector、list、deque》
【vector、list、deque导读】vector、list、deque这三种序列式的容器,算是比较的基础容器,也是大家在日常开发中常用到的容器,因为底层用到的数据结构比较简单,笔者就将他们三者放到一起做下对比分析,介绍下基本用法&a…...

LockSupport概述、阻塞方法park、唤醒方法unpark(thread)、解决的痛点、带来的面试题
目录 ①. 什么是LockSupport? ②. 阻塞方法 ③. 唤醒方法(注意这个permit最多只能为1) ④. LockSupport它的解决的痛点 ⑤. LockSupport 面试题目 ①. 什么是LockSupport? ①. 通过park()和unpark(thread)方法来实现阻塞和唤醒线程的操作 ②. LockSupport是一个线程阻塞…...
Android开发基础知识
1 什么是Android? Android(读音:英:[ndrɔɪd],美:[ˈnˌdrɔɪd]),常见的非官方中文名称为安卓,是一个基于Linux内核的开放源代码移动操作系统,由Google成立…...

C++ Lambda 表达式的本质及原理分析
目录 1.引言 2.Lambda 的本质 3.Lambda 的捕获机制的本质 4.捕获方式的实现与底层原理 5.默认捕获的实现原理 6.捕获 this 的机制 7.捕获的限制与注意事项 8.总结 1.引言 C 中的 Lambda 表达式是一种匿名函数,最早在 C11 引入,用于简化函数对象的…...
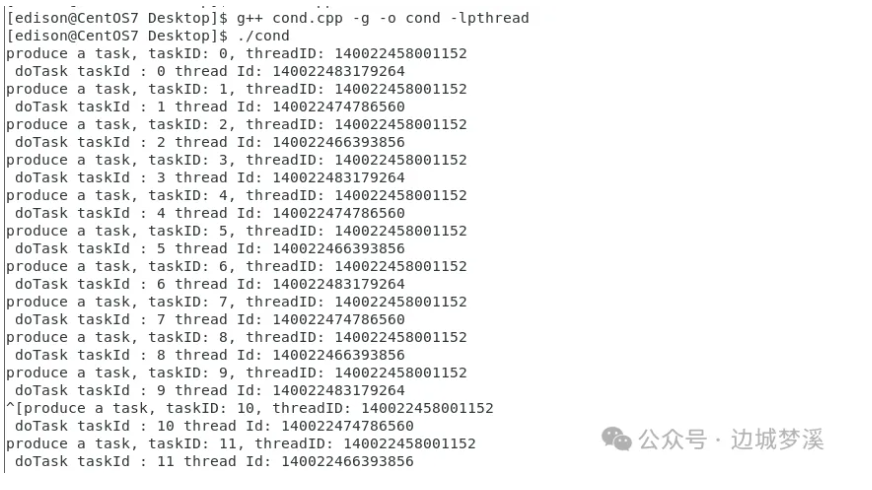
《多线程基础之条件变量》
【条件变量导读】条件变量是多线程中比较灵活而且容易出错的线程同步手段,比如:虚假唤醒、为啥条件变量要和互斥锁结合使用?windows和linux双平台下,初始化、等待条件变量的api一样吗? 本文将分别为您介绍条件变量在w…...
21款炫酷烟花合集
系列专栏 《Python趣味编程》《C/C趣味编程》《HTML趣味编程》《Java趣味编程》 写在前面 Python、C/C、HTML、Java等4种语言实现18款炫酷烟花的代码。 Python Python烟花① 完整代码:Python动漫烟花(完整代码) Python烟花② 完整…...

智能风控 数据分析 groupby、apply、reset_index组合拳
目录 groupby——分组 本例 apply——对每个分组应用一个函数 等价用法 reset_index——重置索引 使用前编辑 注意事项 groupby必须配合聚合函数、 关于agglist 一些groupby试验 1. groupby对象之后。sum(一个列名) 2. groupby对象…...

Python网络自动化运维---用户交互模块
文章目录 目录 文章目录 前言 实验环境准备 一.input函数 代码分段解析 二.getpass模块 前言 在前面的SSH模块章节中,我们都是将提供SSH服务的设备的账户/密码直接写入到python代码中,这样很容易导致账户/密码泄露,而使用Python中的用户交…...

【JVM】调优
目的: 减少minor gc、full gc的次数,也就是减少STW的时间,因为java虚拟机在做后台垃圾收集线程的时候,会停掉其他线程,专门做垃圾收集,这样会影响网站的性能,以及用户的体验。 调优位置&#x…...
软件测试 —— jmeter(2)
软件测试 —— jmeter(2) HTTP默认请求头(元件)元件作用域和取样器作用域HTTP Cookie管理器同步定时器jmeter插件梯度压测线程组(Stepping Thread Group)参数解析总结 Response Times over TimeActive Thre…...
为什么LabVIEW适合软硬件结合的项目?
LabVIEW是一种基于图形化编程的开发平台,广泛应用于软硬件结合的项目中。其强大的硬件接口支持、实时数据采集能力、并行处理能力和直观的用户界面,使得它成为工业控制、仪器仪表、自动化测试等领域中软硬件系统集成的理想选择。LabVIEW的设计哲学强调模…...

OCT-X算法:早期胃癌AI检测的技术突破与应用
1. OCT-X算法:早期胃癌AI检测的技术突破在医疗影像分析领域,胃癌早期检测一直面临着巨大挑战。传统内窥镜检查依赖医生经验判断,存在主观性强、漏诊率高等问题。我们团队开发的OCT-X(One Class Twin Cross Learning)算…...

Proof Engine:简化零知识证明开发,降低区块链应用门槛
1. 项目概述:Proof Engine,一个为现代开发者设计的证明引擎如果你和我一样,在构建需要复杂逻辑验证、状态证明或零知识证明(ZKP)相关应用时,常常感到头疼——工具链复杂、学习曲线陡峭、不同框架间的兼容性…...

数据分析师GitHub作品集构建指南:从项目架构到技术实现
1. 项目概述:一个数据分析师的作品集仓库意味着什么? 在数据驱动的时代,简历上的“精通Python/SQL”已经不够看了。面试官,尤其是那些懂行的技术面试官,更想看到的是你如何用这些工具解决真实世界的问题。这就是为什么…...

ncmdump终极指南:如何快速免费解锁网易云音乐NCM格式
ncmdump终极指南:如何快速免费解锁网易云音乐NCM格式 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 还在为网易云音乐下载的加密文件无法在其他设备播放而烦恼吗?ncmdump正是你需要的解决方案!这…...

基于ESP32-S2与MAX17048的物联网电池监控系统设计与实现
1. 项目概述与核心价值 对于任何一个需要长期部署在户外的物联网设备,比如环境监测站、智能农业传感器或者远程摄像头,最让人头疼的问题往往不是代码bug,而是“它什么时候会没电?”。你不可能天天跑现场去检查,而设备…...
)
ElevenLabs菲律宾语语音突然变卡顿?紧急排查清单:DNS劫持、Token过期、区域节点错配(含curl诊断脚本)
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs菲律宾语语音突然变卡顿?紧急排查清单:DNS劫持、Token过期、区域节点错配(含curl诊断脚本) 当ElevenLabs API在调用菲律宾语(fil-P…...

Harness 中的请求标识染色:端到端追踪
1. 标题选项(核心关键词:Harness、请求标识染色、端到端追踪、可观测性、CI/CD) 「Harness 可观测性实战:请求标识染色实现全链路端到端追踪」 「从0到1搞定Harness请求染色:让微服务调用链路+变更链路无所遁形」 「告别排查黑洞:Harness请求标识染色的端到端追踪落地指南…...

企业信息采集神器:10分钟掌握天眼查企查查双平台爬虫
企业信息采集神器:10分钟掌握天眼查&企查查双平台爬虫 【免费下载链接】company-crawler 天眼查爬虫&企查查爬虫,指定关键字爬取公司信息 项目地址: https://gitcode.com/gh_mirrors/co/company-crawler 还在为获取企业信息而烦恼吗&…...

企业无线准入实战:AC联动RADIUS与内置Portal构建安全访客网络
1. 为什么企业需要安全访客网络? 想象一下这样的场景:你的公司经常有合作伙伴、客户来访,他们需要临时使用Wi-Fi。如果直接开放内部网络,就像把家门钥匙随便发给陌生人;如果用简单密码共享,又像在公共场合大…...

layerJS与现代前端框架集成:Vue、React、Angular中的最佳实践指南 [特殊字符]
layerJS与现代前端框架集成:Vue、React、Angular中的最佳实践指南 🚀 【免费下载链接】layerJS layerJS: Javascript UI composition framework 项目地址: https://gitcode.com/gh_mirrors/la/layerJS layerJS是一个创新的JavaScript UI组合框架&…...