【Python实现机器遗忘算法】复现2023年TNNLS期刊算法UNSIR
【Python实现机器遗忘算法】复现2023年TNNLS期刊算法UNSIR

1 算法原理
Tarun A K, Chundawat V S, Mandal M, et al. Fast yet effective machine unlearning[J]. IEEE Transactions on Neural Networks and Learning Systems, 2023.
本文提出了一种名为 UNSIR(Unlearning with Single Pass Impair and Repair) 的机器遗忘框架,用于从深度神经网络中高效地卸载(遗忘)特定类别数据,同时保留模型对其他数据的性能。以下是算法的主要步骤:
1. 零隐私设置(Zero-Glance Privacy Setting)
- 假设:用户请求从已训练的模型中删除其数据(例如人脸图像),并且模型无法再访问这些数据,即使是为了权重调整。
- 目标:在不重新训练模型的情况下,使模型忘记特定类别的数据,同时保留对其他数据的性能。
2. 学习误差最大化噪声矩阵(Error-Maximizing Noise Matrix)
-
初始化:随机初始化噪声矩阵 N,其大小与模型输入相同。
-
优化目标:通过最大化模型对目标类别的损失函数来优化噪声矩阵 N。具体优化问题为:
a r g N m i n E ( θ ) = − L ( f , y ) + λ ∥ w n o i s e ∥ argNminE(θ)=−L(f,y)+λ∥wnoise∥ argNminE(θ)=−L(f,y)+λ∥wnoise∥其中:
- L(f,y) 是针对要卸载的类别的分类损失函数。
- λ∥wnoise∥ 是正则化项,防止噪声值过大。
- 使用交叉熵损失函数 L 和 L2 归一化。
-
噪声矩阵的作用:生成的噪声矩阵 N 与要卸载的类别标签相关联,用于在后续步骤中破坏模型对这些类别的记忆。
3. 单次损伤与修复(Single Pass Impair and Repair)
- 损伤步骤(Impair Step):
- 操作:将噪声矩阵 N 与保留数据子集Dr结合,训练模型一个周期(epoch)。
- 目的:通过高学习率(例如 0.02)快速破坏模型对要卸载类别的权重。
- 结果:模型对要卸载类别的性能显著下降,同时对保留类别的性能也会受到一定影响。
- 修复步骤(Repair Step):
- 操作:仅使用保留数据子集 Dr再次训练模型一个周期(epoch),学习率较低(例如 0.01)。
- 目的:恢复模型对保留类别的性能,同时保持对要卸载类别的遗忘效果。
- 结果:最终模型在保留数据上保持较高的准确率,而在卸载数据上准确率接近于零。
2 Python代码实现
相关函数
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torchvision import datasets, transforms, models
from torch.utils.data import DataLoader, Subset,TensorDataset
from torch.amp import autocast, GradScaler
import numpy as np
import matplotlib.pyplot as plt
import os
import warnings
import random
from copy import deepcopy
random.seed(2024)
torch.manual_seed(2024)
np.random.seed(2024)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = Falsewarnings.filterwarnings("ignore")
MODEL_NAMES = "MLP"
# 设置设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 定义三层全连接网络
class MLP(nn.Module):def __init__(self):super(MLP, self).__init__()self.fc1 = nn.Linear(28 * 28, 256)self.fc2 = nn.Linear(256, 128)self.fc3 = nn.Linear(128, 10)def forward(self, x):x = x.view(-1, 28 * 28)x = F.relu(self.fc1(x))x = F.relu(self.fc2(x))x = self.fc3(x)return x# 加载MNIST数据集
def load_MNIST_data(batch_size,forgotten_classes,ratio):transform = transforms.Compose([transforms.ToTensor()])train_data = datasets.MNIST(root='./data', train=True, download=True, transform=transform)test_data = datasets.MNIST(root='./data', train=False, download=True, transform=transform)train_loader = DataLoader(train_data, batch_size=batch_size, shuffle=True)test_loader = DataLoader(test_data, batch_size=batch_size, shuffle=False)forgotten_train_data,_ = generate_subset_by_ratio(train_data, forgotten_classes,ratio)retain_train_data,_ = generate_subset_by_ratio(train_data, [i for i in range(10) if i not in forgotten_classes])forgotten_train_loader= DataLoader(forgotten_train_data, batch_size=batch_size, shuffle=True)retain_train_loader= DataLoader(retain_train_data, batch_size=batch_size, shuffle=True)return train_loader, test_loader, retain_train_loader, forgotten_train_loader# worker_init_fn 用于初始化每个 worker 的随机种子
def worker_init_fn(worker_id):random.seed(2024 + worker_id)np.random.seed(2024 + worker_id)
def get_transforms():train_transform = transforms.Compose([transforms.RandomCrop(32, padding=4),transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)), # 标准化为[-1, 1]])test_transform = transforms.Compose([transforms.Resize((32, 32)),transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)), # 标准化为[-1, 1]])return train_transform, test_transform
# 模型训练函数
def train_model(model, train_loader, criterion, optimizer, scheduler=None,use_fp16 = False):use_fp16 = True# 使用新的初始化方式:torch.amp.GradScaler("cuda")scaler = GradScaler("cuda") # 用于混合精度训练model.train()running_loss = 0.0for images, labels in train_loader:images, labels = images.to(device), labels.to(device)# 前向传播with autocast(enabled=use_fp16, device_type="cuda"): # 更新为使用 "cuda"outputs = model(images)loss = criterion(outputs, labels)# 反向传播和优化optimizer.zero_grad()if use_fp16:scaler.scale(loss).backward()scaler.step(optimizer)scaler.update()else:loss.backward()optimizer.step()running_loss += loss.item()if scheduler is not None:# 更新学习率scheduler.step()print(f"Loss: {running_loss/len(train_loader):.4f}")
# 模型评估(计算保留和遗忘类别的准确率)
def test_model(model, test_loader, forgotten_classes=[0]):"""测试模型的性能,计算总准确率、遗忘类别准确率和保留类别准确率。:param model: 要测试的模型:param test_loader: 测试数据加载器:param forgotten_classes: 需要遗忘的类别列表:return: overall_accuracy, forgotten_accuracy, retained_accuracy"""model.eval()correct = 0total = 0forgotten_correct = 0forgotten_total = 0retained_correct = 0retained_total = 0with torch.no_grad():for images, labels in test_loader:images, labels = images.to(device), labels.to(device)outputs = model(images)_, predicted = torch.max(outputs.data, 1)# 计算总的准确率total += labels.size(0)correct += (predicted == labels).sum().item()# 计算遗忘类别的准确率mask_forgotten = torch.isin(labels, torch.tensor(forgotten_classes, device=device))forgotten_total += mask_forgotten.sum().item()forgotten_correct += (predicted[mask_forgotten] == labels[mask_forgotten]).sum().item()# 计算保留类别的准确率(除遗忘类别的其他类别)mask_retained = ~mask_forgottenretained_total += mask_retained.sum().item()retained_correct += (predicted[mask_retained] == labels[mask_retained]).sum().item()overall_accuracy = correct / totalforgotten_accuracy = forgotten_correct / forgotten_total if forgotten_total > 0 else 0retained_accuracy = retained_correct / retained_total if retained_total > 0 else 0# return overall_accuracy, forgotten_accuracy, retained_accuracyreturn round(overall_accuracy, 4), round(forgotten_accuracy, 4), round(retained_accuracy, 4)主函数
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torchvision import datasets, transforms
from torch.utils.data import DataLoader, Subset
import numpy as np
from models.Base import load_MNIST_data, test_model, load_CIFAR100_data, init_modelclass UNSIRForget:def __init__(self, model):self.model = modelself.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 学习误差最大化噪声矩阵def learn_error_maximizing_noise(self, train_loader, forgotten_classes, lambda_reg=0.01, learning_rate=0.01, num_epochs=5):self.model.eval()# 初始化噪声矩阵 N,大小与输入图像相同(例如28x28图像)noise_matrix = torch.randn(1, 1, 28, 28, device=self.device, requires_grad=True) # 假设输入是28x28的图像# 优化器用于优化噪声矩阵optimizer = torch.optim.SGD([noise_matrix], lr=learning_rate)noise_data = []noise_labels = []# 生成噪声数据集for epoch in range(num_epochs):total_loss = 0.0for images, labels in train_loader:images, labels = images.to(self.device), labels.to(self.device)# 只对属于遗忘类别的数据进行优化mask_forgotten = torch.isin(labels, torch.tensor(forgotten_classes, device=self.device))noisy_images = images.clone()# 对遗忘类别的图像添加噪声noisy_images[mask_forgotten] += noise_matrix# 保存噪声数据noise_data.append(noisy_images)noise_labels.append(labels)# 前向传播outputs = self.model(noisy_images.view(-1, 28 * 28)) # 假设模型的输入是28x28的图像loss = F.cross_entropy(outputs, labels)# L2 正则化项(噪声矩阵的L2范数)l2_reg = lambda_reg * torch.norm(noise_matrix)# 总损失(包含交叉熵损失和L2正则化)total_loss = loss + l2_reg# 反向传播并更新噪声矩阵optimizer.zero_grad()total_loss.backward()optimizer.step()print(f"Epoch [{epoch+1}/{num_epochs}], Loss: {total_loss.item():.4f}")# 返回包含噪声数据和标签的噪声数据集return torch.cat(noise_data), torch.cat(noise_labels), noise_matrix.detach()# 实现机器遗忘(针对特定类别,使用噪声矩阵进行干扰)def unlearn(self, train_loader, forgotten_classes, noise_data, noise_labels, noise_matrix, alpha_impair, alpha_repair, num_epochs=1):# 损伤步骤self.model.train()print("执行损伤中...")for epoch in range(num_epochs):for images, labels in train_loader:images, labels = images.to(self.device), labels.to(self.device)# 仅选择保留类别的数据mask_retained = ~torch.isin(labels, torch.tensor(forgotten_classes, device=self.device))retained_images = images[mask_retained]retained_labels = labels[mask_retained]# 生成新的数据集,将噪声数据添加到保留数据中augmented_images = torch.cat([retained_images, noise_data], dim=0)augmented_labels = torch.cat([retained_labels, noise_labels], dim=0)# 前向传播outputs = self.model(augmented_images.view(-1, 28 * 28)) # 假设模型的输入是28x28的图像loss = F.cross_entropy(outputs, augmented_labels)# 更新模型权重self.model.zero_grad()loss.backward()with torch.no_grad():for param in self.model.parameters():param.data -= alpha_impair * param.grad.data# 修复步骤print("执行修复中...")for epoch in range(num_epochs):for images, labels in train_loader:images, labels = images.to(self.device), labels.to(self.device)# 仅使用保留类别的数据进行修复mask_retained = ~torch.isin(labels, torch.tensor(forgotten_classes, device=self.device))retained_images = images[mask_retained]retained_labels = labels[mask_retained]if retained_images.size(0) == 0:continue# 前向传播和损失计算outputs = self.model(retained_images.view(-1, 28 * 28))loss = F.cross_entropy(outputs, retained_labels)# 更新模型权重self.model.zero_grad()loss.backward()with torch.no_grad():for param in self.model.parameters():param.data -= alpha_repair * param.grad.datareturn self.model# UNSIR算法的主要流程
def unsir_unlearning(model_before, retrain_data, forget_data, all_data, forgotten_classes, lambda_reg=0.01, learning_rate=0.01, alpha_impair=0.5, alpha_repair=0.001, num_epochs=5):"""执行 UNSIR 算法的主要流程,包括学习误差最大化噪声矩阵、损伤、修复步骤,最终返回遗忘后的模型。"""unsir_forgetter = UNSIRForget(model_before)# 计算学习误差最大化噪声矩阵noise_data, noise_labels, noise_matrix = unsir_forgetter.learn_error_maximizing_noise(all_data, forgotten_classes, lambda_reg, learning_rate, num_epochs)# 执行 unlearn(损伤与修复步骤)unlearned_model = unsir_forgetter.unlearn(all_data, forgotten_classes, noise_data, noise_labels, noise_matrix, alpha_impair, alpha_repair, num_epochs)return unlearned_modeldef main():# 超参数设置batch_size = 256forgotten_classes = [0]ratio = 1model_name = "MLP"# 加载数据train_loader, test_loader, retain_loader, forget_loader = load_MNIST_data(batch_size, forgotten_classes, ratio)model_before = init_model(model_name, train_loader)# 在训练之前测试初始模型准确率overall_acc_before, forgotten_acc_before, retained_acc_before = test_model(model_before, test_loader)print("执行 UNSIR 遗忘...")model_after = unsir_unlearning(model_before,retain_loader,forget_loader,train_loader,forgotten_classes,lambda_reg=0.01,learning_rate=0.01,alpha_impair=0.5,alpha_repair=0.001,num_epochs=5,)# 测试遗忘后的模型overall_acc_after, forgotten_acc_after, retained_acc_after = test_model(model_after, test_loader)# 输出遗忘前后的准确率变化print(f"Unlearning前遗忘准确率: {100 * forgotten_acc_before:.2f}%")print(f"Unlearning后遗忘准确率: {100 * forgotten_acc_after:.2f}%")print(f"Unlearning前保留准确率: {100 * retained_acc_before:.2f}%")print(f"Unlearning后保留准确率: {100 * retained_acc_after:.2f}%")if __name__ == "__main__":main()3 总结
当前方法不支持随机样本或类别子集的卸载,这可能违反零隐私假设。
仍属于重新优化的算法,即还需要训练。
相关文章:
【Python实现机器遗忘算法】复现2023年TNNLS期刊算法UNSIR
【Python实现机器遗忘算法】复现2023年TNNLS期刊算法UNSIR 1 算法原理 Tarun A K, Chundawat V S, Mandal M, et al. Fast yet effective machine unlearning[J]. IEEE Transactions on Neural Networks and Learning Systems, 2023. 本文提出了一种名为 UNSIR(Un…...

Object类(3)
大家好,今天继续给大家介绍一下object类中的方法,那么话不多说,来看。 hashcode()这个方法,帮我们算了一个具体的对象位置,这里面涉及到数据结构,简单认为它是个内存地址,然后调用Integer.toHexString ()将这个地址以16进制输出。 该方法是一…...
 Zookeeper的版本号(version)是什么?)
Zookeeper(32) Zookeeper的版本号(version)是什么?
在 Zookeeper 中,每个节点都有多个版本号(version),用于跟踪节点的状态变化。版本号帮助 Zookeeper 实现乐观并发控制,确保在并发环境中的数据一致性。主要的版本号包括: version:数据版本号&a…...

C# as 和 is 运算符区别和用法
前言 在C#中,as 和 is 关键字都用于处理类型转换的运算符,但它们有不同的用途和行为。本文我们将详细解释这两个运算符的区别和用法。 is 运算符 is 运算符用于检查对象是否是某个特定类型,或者是否可以转换为该类型。它返回一个布尔值 (t…...

求解旅行商问题的三种精确性建模方法,性能差距巨大
文章目录 旅行商问题介绍三种模型对比求解模型1决策变量目标函数约束条件Python代码 求解模型2决策变量目标函数约束条件Python代码 求解模型3决策变量目标函数约束条件Python代码 三个模型的优势与不足 旅行商问题介绍 旅行商问题 (Traveling Salesman Problem, TSP) 是一个经…...

SQL-leetcode—1193. 每月交易 I
1193. 每月交易 I 表:Transactions ---------------------- | Column Name | Type | ---------------------- | id | int | | country | varchar | | state | enum | | amount | int | | trans_date | date | ---------------------- id 是这个表的主键。 该表包含…...

【MySQL — 数据库增删改查操作】深入解析MySQL的 Retrieve 检索操作
Retrieve 检索 示例 1. 构造数据 创建表结构 create table exam1(id bigint, name varchar(20) comment同学姓名, Chinesedecimal(3,1) comment 语文成绩, Math decimal(3,1) comment 数学成绩, English decimal(3,1) comment 英语成绩 ); 插入测试数据 insert into ex…...

项目开发实践——基于SpringBoot+Vue3实现的在线考试系统(九)(完结篇)
文章目录 一、成绩查询模块实现1、学生成绩查询功能实现1.1 页面设计1.2 前端页面实现1.3 后端功能实现2、成绩分段查询功能实现2.1 页面设计2.2 前端页面实现2.3 后端功能实现二、试卷练习模块实现三、我的分数模块实现1、 页面设计2、 前端页面实现3、 后端功能实现四、交流区…...
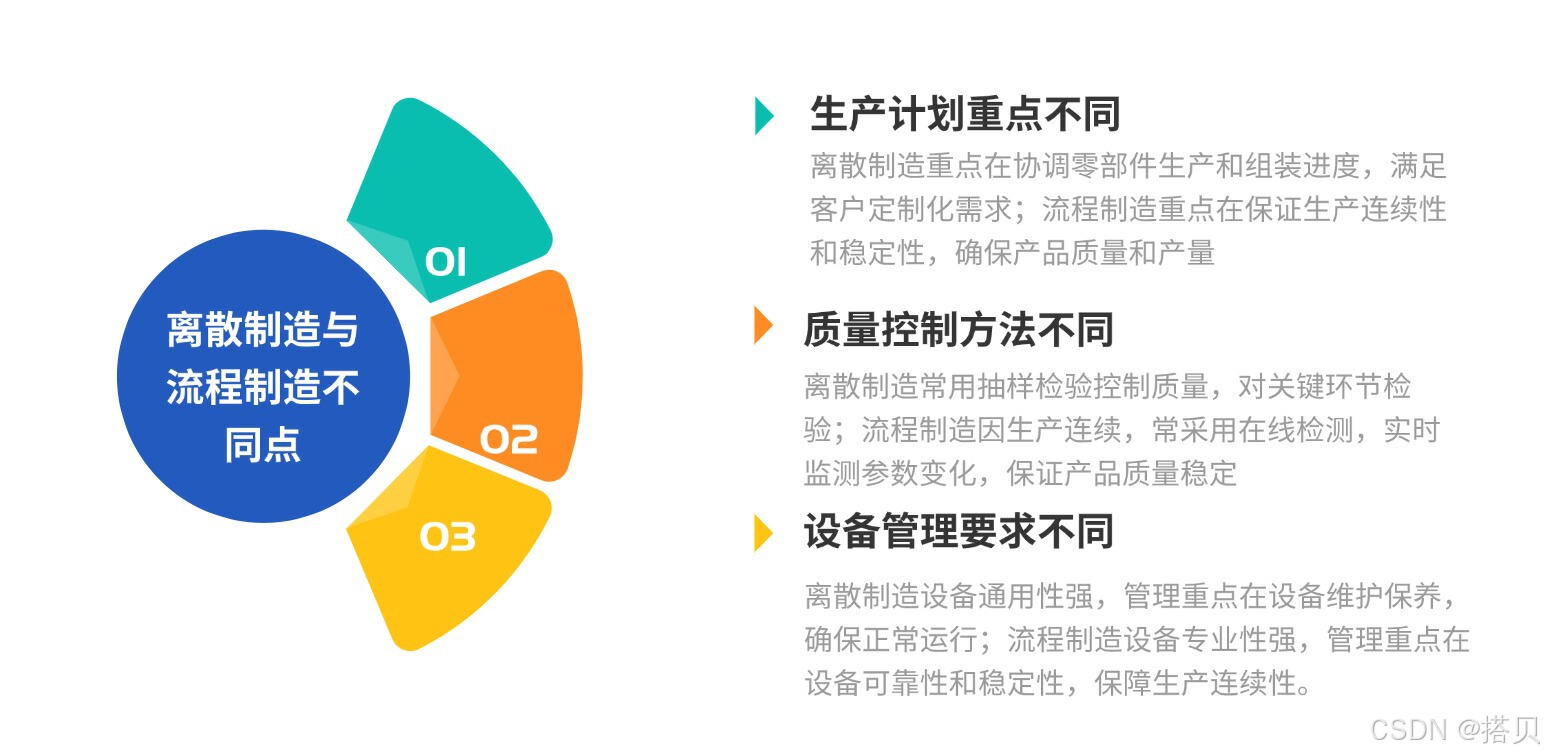
离散 VS 流程制造,制造业的 “双生花” 如何绽放
在制造业中,我们常看到两种不同生产景象:有的企业生产一气呵成,有的则由众多环节组合。 这源于离散制造和流程制造两种常见生产模式。它们在生产管理上特点与区别明显。 下面,我们从概念、特点、企业生产管理方式,以…...

freeswtch目录下modules.conf各个模块的介绍【freeswitch版本1.6.8】
应用模块(applications) mod_abstraction: 为其他模块提供抽象层,有助于简化模块开发,让开发者能在统一框架下开发新功能,减少与底层系统的直接交互,提高代码可移植性和可维护性。 mod_av&#…...

循序渐进kubernetes-RBAC(Role-Based Access Control)
文章目录 概要Kubernetes API了解 Kubernetes 中的 RBACRoles and Role Bindings:ClusterRoles and ClusterRoleBindings检查访问权限:外部用户结论 概要 Kubernetes 是容器化应用的强大引擎,但仅仅关注部署和扩展远远不够,集群的安全同样至…...

第3章 基于三电平空间矢量的中点电位平衡策略
0 前言 在NPC型三电平逆变器的直流侧串联有两组参数规格完全一致的电解电容,由于三电平特殊的中点钳位结构,在进行SVPWM控制时,在一个完整开关周期内,直流侧电容C1、C2充放电不均匀,各自存储的总电荷不同,电容电压便不均等,存在一定的偏差。在不进行控制的情况下,系统无…...

基于SpringBoot的阳光幼儿园管理系统
作者:计算机学姐 开发技术:SpringBoot、SSM、Vue、MySQL、JSP、ElementUI、Python、小程序等,“文末源码”。 专栏推荐:前后端分离项目源码、SpringBoot项目源码、Vue项目源码、SSM项目源码、微信小程序源码 精品专栏:…...

Python 数据分析 - Matplotlib 绘图
Python 数据分析 - Matplotlib 绘图 简介绘图折线图单线多线子图 散点图直方图条形图纵置横置多条 饼图 简介 Matplotlib 是 Python 提供的一个绘图库,通过该库我们可以很容易的绘制出折线图、直方图、散点图、饼图等丰富的统计图,安装使用 pip install…...

uniapp版本升级
1.样式 登录进到首页,弹出更新提示框,且不可以关闭,侧边返回直接退出! 有关代码: <uv-popup ref"popupUpdate" round"8" :close-on-click-overlay"false"><view style"…...

Django ORM解决Oracle表多主键的问题
现状 以Django 3.2为例 Django ORM 设计为默认使用单一主键(通常是自增的 id 字段),这一选择主要基于以下核心原因: 简化ORM设计与操作 统一访问方式外键关联简化 避免歧义冲突 主键语义明确防止隐式依赖 性能与数据库兼容 索引…...

机器学习2 (笔记)(朴素贝叶斯,集成学习,KNN和matlab运用)
朴素贝叶斯模型 贝叶斯定理: 常见类型 算法流程 优缺点 集成学习算法 基本原理 常见方法 KNN(聚类模型) 算法性质: 核心原理: 算法流程 优缺点 matlab中的运用 朴素贝叶斯模型 朴素贝叶斯模型是基于贝叶斯…...

ubuntu解决普通用户无法进入root
项目场景: 在RK3566上移植Ubuntu20.04之后普通用户无法进入管理员模式 问题描述 在普通用户使用sudo su试图进入管理员模式的时候报错 解决方案: 1.使用 cat /etc/passwd 查看所有用户.最后一行是 若无用户,则使用 sudo useradd -r -m -s /…...

Time Constant | RC、RL 和 RLC 电路中的时间常数
注:本文为 “Time Constant” 相关文章合辑。 机翻,未校。 How To Find The Time Constant in RC and RL Circuits June 8, 2024 💡 Key learnings: 关键学习点: Time Constant Definition: The time constant (τ) is define…...

数据结构测试题2
一、单选题(每题 2 分,共20分) 1. 栈和队列的共同特点是( A )。 A.只允许在端点处插入和删除元素 B.都是先进后出 C.都是先进先出 D.没有共同点 2. 用链接方式存储的队列,在进行插入运算时( C ) A. 仅修改头指针 B. 头…...

非标设备集成指南:如何用德创V+平台统一管理相机、PLC和视觉算法
非标设备集成实战:基于V平台的视觉系统协同管理方案 在工业自动化领域,非标设备集成往往面临多品牌硬件兼容性差、通讯协议复杂、调试周期长等痛点。传统解决方案需要工程师编写大量底层代码来桥接不同设备,不仅效率低下,后期维护…...
)
运维老鸟复盘:一次CentOS7物理机安装踩坑全记录(从RAID0到安装源验证)
运维实战:CentOS7物理机安装全流程避坑指南 引言 那台尘封已久的联想RD550服务器静静躺在仓库角落,表面覆盖着一层薄灰。作为运维工程师,我们总会遇到这样的挑战——老旧设备突然需要重新部署系统。这次任务看似简单:为这台双盘…...

基于Three.js与WebSocket构建虚拟小镇:全栈技术架构与优化实践
1. 项目概述与核心价值最近在折腾一个叫“Alicization-Town”的开源项目,它来自GitHub上的ceresOPA组织。乍一看这个名字,可能会联想到某个动漫或者游戏里的场景,但实际接触后,我发现它远不止于此。这是一个围绕“虚拟小镇”或“数…...
的选型与实战踩坑)
从手机SoC到汽车芯片:深入聊聊AMBA总线家族(AHB/APB/AXI)的选型与实战踩坑
从手机SoC到汽车芯片:AMBA总线家族的选型与实战经验 在移动计算和汽车电子两大领域,芯片架构师们每天都在面临类似的挑战:如何在有限的硅片面积和功耗预算内,实现最高的系统性能。AMBA总线作为连接处理器、内存和各种外设的"…...

STC-ISP软件隐藏技巧:一键添加头文件到Keil5,并手动验证芯片包是否真正生效
STC-ISP软件隐藏技巧:深度验证Keil5芯片包安装的底层逻辑 当你按照教程点击了STC-ISP的"添加型号和头文件到Keil中"按钮,看到成功提示后满心欢喜打开Keil5,却发现下拉列表里根本没有"STC MCU Database"选项——这种挫败…...

GPTPortal:基于模型抽象层的AI应用快速部署与统一管理平台
1. 项目概述:一个面向开发者的AI应用快速部署门户 最近在GitHub上看到一个挺有意思的项目,叫GPTPortal。乍一看名字,可能会让人联想到某个特定的AI模型服务,但深入了解一下就会发现,它的定位其实更偏向于一个“门户”或…...

Java-Callgraph2:Java静态分析工具终极指南
Java-Callgraph2:Java静态分析工具终极指南 【免费下载链接】java-callgraph2 Programs for producing static call graphs for Java programs. 项目地址: https://gitcode.com/gh_mirrors/ja/java-callgraph2 Java-Callgraph2是一款功能强大的Java静态分析工…...

Cadence 17.4重装系统后,PCB快捷键失灵?别急着重装,先检查这个‘文件类型’
Cadence 17.4重装系统后PCB快捷键失效的深度排查指南 当你在Windows系统重装后,发现Cadence 17.4的PCB编辑器快捷键全部失灵,那种感觉就像突然失去了双手——每个操作都变得异常笨拙和低效。本文将从底层文件系统原理出发,带你深入排查这个看…...

NAT 类型详解:四种 NAT 的数据流与原理解析
NAT 类型详解:四种 NAT 的数据流与原理解析摘要:NAT(Network Address Translation)是 P2P 通信中绕不开的关卡。不同的 NAT 类型决定了内网设备能否被外部直接访问,直接影响 WebRTC 等 P2P 技术的穿透成功率。本文通过…...

DevUI布局系统完全指南:响应式设计的终极解决方案
DevUI布局系统完全指南:响应式设计的终极解决方案 【免费下载链接】ng-devui Angular UI Component Library based on DevUI Design 项目地址: https://gitcode.com/DevCloudFE/ng-devui DevUI布局系统是Angular UI组件库中的核心功能,为开发者提…...