matlab快速入门(2)-- 数据处理与可视化
MATLAB的数据处理
1. 数据导入与导出
(1) 从文件读取数据
- Excel 文件:
data = readtable('data.xlsx'); % 读取为表格(Table) - CSV 文件:
data = readtable('data.csv'); % 自动处理表头和分隔符 - 文本文件:
data = load('data.txt'); % 数值数据直接加载为矩阵
(2) 导出数据到文件
- 保存为 Excel:
writetable(data, 'output.xlsx'); - 保存为 CSV:
writetable(data, 'output.csv');
2. 数据清洗与预处理
(1) 处理缺失值
1>查找缺失值:ismissing(data)
missingValues = ismissing(data); % 返回逻辑矩阵标记缺失值(NaN 或空字符)
- 功能:检测
data(可以是数组、表格、时间表等)中的缺失值,生成一个与data维度相同的 逻辑矩阵(logical matrix)。 - 输出规则:
missingValues中true(1)表示对应位置是缺失值。false(0)表示该位置数据正常。
支持的缺失值类型
- 数值型数据:
NaN(Not a Number)。 - 时间型数据:
NaT(Not a Time)。 - 字符串/字符数据:空字符串
""(字符串数组)或<missing>。 - 分类数据:
<undefined>。 - 表格/时间表:自动识别各列的缺失值类型。
示例
假设 data 是一个表格:
| ID | Age | Status |
|---|---|---|
| 1 | 25 | “Complete” |
| 2 | NaN | “” |
| 3 | 30 | “” |
执行 missingValues = ismissing(data) 后,结果如下:
| ID | Age | Status |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 0 | 0 | 1 |
2> 填充缺失值:fillmissing
代码作用
data.Age = fillmissing(data.Age, 'constant', mean(data.Age, 'omitnan')); % 用均值填充
- 功能:将
data.Age列中的缺失值(NaN)填充为该列的均值(忽略缺失值计算)。 - 参数解析:
data.Age:待填充的列(数值型向量)。'constant':填充方式为“常量填充”,即用固定值替换缺失值。mean(data.Age, 'omitnan'):计算data.Age列的均值时忽略NaN值。
关键步骤
-
计算均值:
avg = mean(data.Age, 'omitnan'); % 忽略 NaN 计算均值- 假设
data.Age = [25, NaN, 30],则avg = (25 + 30)/2 = 27.5。
- 假设
-
填充缺失值:
data.Age = fillmissing(data.Age, 'constant', avg);- 原始数据:
[25, NaN, 30]→ 填充后:[25, 27.5, 30]。
- 原始数据:
其他填充方法
- 插值填充:
fillmissing(data.Age, 'linear')(线性插值)。 - 邻近值填充:
fillmissing(data.Age, 'previous')(用前一个有效值填充)。
注意事项
-
确保数据类型一致:
fillmissing的填充值必须与列的数据类型兼容(例如,数值列用数值填充,字符串列用字符串填充)。
-
处理全缺失列:
- 若某列全部为
NaN,mean(..., 'omitnan')会返回NaN,导致填充无效。需额外处理:if all(isnan(data.Age))data.Age = zeros(size(data.Age)); % 用0填充全缺失列 end
- 若某列全部为
-
分类变量处理:
- 分类数据(如
'Male','Female')需用众数填充:modeGender = mode(data.Gender, 'omitnan'); data.Gender = fillmissing(data.Gender, 'constant', modeGender);
- 分类数据(如
完整示例
原始数据
| Age |
|---|
| 25 |
| NaN |
| 30 |
执行代码后
| Age |
|---|
| 25 |
| 27.5 |
| 30 |
总结
ismissing:精准定位数据中的缺失值,生成逻辑掩码。fillmissing:灵活填充缺失值,支持均值、插值、邻近值等方法。- 核心技巧:结合
ismissing的检测结果,选择合适策略清洗数据,确保后续分析可靠性。
(2) 数据筛选
- 按条件筛选行:
highScores = data(data.Score > 90, :); % 筛选 Score 列大于90的行 - 选择特定列:
selectedData = data(:, {'Name', 'Age'}); % 选择 Name 和 Age 列
(3) 数据转换
涵盖 类型转换 和 分类数据编码 的核心操作。
一、类型转换:data.Age = double(data.Age);
1. 作用与原理
- 目标:将
data.Age列的数据类型转换为 双精度浮点数(double)。 - 适用场景:
- 原始数据可能是整数(
int)、字符(char)或其他类型。 - 需要统一数值类型以确保计算精度(例如参与科学计算或统计分析)。
- 原始数据可能是整数(
2. 示例说明
原始数据
假设 data.Age 原本是整数类型(int32):
data = table([25; 30; 28], {'Male'; 'Female'; 'Male'}, 'VariableNames', {'Age', 'Gender'});
disp(class(data.Age)); % 输出 'int32'
原始数据
| Age (double) | Gender |
|---|---|
| 25 | Male |
| 30 | Female |
| 28 | Male |
转换代码
data.Age = double(data.Age); % 转换为双精度浮点数
disp(class(data.Age)); % 输出 'double'
转换后数据
| Age (double) | Gender |
|---|---|
| 25.0 | Male |
| 30.0 | Female |
| 28.0 | Male |
3. 常见类型转换函数
| 函数 | 作用 | 示例 |
|---|---|---|
double() | 转为双精度浮点数 | x = double(int32(5)) → 5.0 |
single() | 转为单精度浮点数 | x = single(3.14) |
int32() | 转为32位整数 | x = int32(10.7) → 10 |
string() | 转为字符串数组 | x = string(123) → "123" |
cellstr() | 转为字符向量元胞数组 | x = cellstr("Text") → {'Text'} |
4. 注意事项
- 精度丢失:将浮点数转换为整数时,小数部分会被截断(非四舍五入)。
x = 3.9; y = int32(x); % y = 3 - 数据溢出:超出目标类型范围的转换会引发错误或产生意外值。
x = 500; y = int8(x); % int8 范围是 [-128, 127],y = 127(溢出)
分类数据编码:data.Gender = categorical(data.Gender);
1. 作用与原理
- 目标:将字符或字符串数据转换为 分类变量(
categorical)。 - 优势:
- 节省内存:分类变量内部存储为整数索引,而非重复的字符串。
- 高效操作:支持快速分组统计、排序、筛选。
- 语义清晰:保留原始标签,方便可视化与分析。
2. 示例说明
原始数据
假设 data.Gender 是字符串数组:
data.Gender = ["Male"; "Female"; "Male"; "Female"];
disp(class(data.Gender)); % 输出 'string'
注意:一定要转换为categorical类型的数据
转换代码
data.Gender = categorical(data.Gender); % 转换为分类变量
disp(class(data.Gender)); % 输出 'categorical'
disp(categories(data.Gender)); % 输出 {'Female', 'Male'}
转换后数据
| Gender (categorical) |
|---|
| Male |
| Female |
| Male |
| Female |
3. 分类变量的核心操作
(1) 统计频数
counts = countcats(data.Gender); % 输出 [2; 2](Female:2, Male:2)
(2) 排序数据
sortedData = sortrows(data, 'Gender'); % 按分类顺序排序(默认字母顺序)
(3) 合并类别
% 将 'Male' 和 'Female' 合并为 'Other'
data.Gender = mergecats(data.Gender, {'Male', 'Female'}, 'Other');
disp(categories(data.Gender)); % 输出 {'Other'}
(4) 处理缺失值
% 添加缺失值并填充
data.Gender(2) = missing; % 设置为 <undefined>
data.Gender = addcats(data.Gender, 'Unknown'); % 添加新类别
data.Gender(isundefined(data.Gender)) = 'Unknown'; % 填充缺失
4. 分类变量的优势对比
| 操作 | 字符串数组 | 分类变量 |
|---|---|---|
| 内存占用 | 高(存储所有字符) | 低(存储整数索引) |
| 分组统计速度 | 慢 | 快 |
| 支持自定义类别顺序 | 不支持 | 支持(有序分类) |
三、综合应用场景
场景:数据预处理流程
% 步骤1:读取数据
data = readtable('survey_data.csv');% 步骤2:类型转换(Age列转为double)
data.Age = double(data.Age);% 步骤3:分类编码(Gender列转为分类变量)
data.Gender = categorical(data.Gender);% 步骤4:处理缺失值(用众数填充Gender)
modeGender = mode(data.Gender, 'omitnan');
data.Gender = fillmissing(data.Gender, 'constant', modeGender);% 步骤5:保存处理后的数据
writetable(data, 'cleaned_survey_data.csv');
四、注意事项
- 类型转换前检查数据:
- 确保转换后的类型适合后续分析(例如日期数据应转为
datetime)。
- 确保转换后的类型适合后续分析(例如日期数据应转为
- 分类变量的顺序:
- 默认按字母顺序排列,可通过
'Ordinal', true指定逻辑顺序。
- 默认按字母顺序排列,可通过
- 缺失值处理:
- 分类变量中的缺失值显示为
<undefined>,需用addcats和fillmissing处理。
- 分类变量中的缺失值显示为
总结
- 类型转换:确保数据格式统一,满足计算需求。
- 分类编码:提升处理离散标签数据的效率和可读性。
- 核心函数:
double(),categorical(),countcats(),mergecats()。
3. 数据分析与统计
一、聚合统计
1. 分组统计:groupsummary
功能:按指定分组变量对数据进行分组,并计算统计量(如均值、总和、标准差等)。
语法
groupStats = groupsummary(data, groupVars, method, dataVars)
data:输入表格(table)。groupVars:分组变量(列名或列索引),支持单列或多列。method:统计方法(如'mean','sum','std')。dataVars:需要统计的数据列(列名或列索引)。
示例 1:按性别计算平均分
% 创建示例数据
data = table({'Male'; 'Female'; 'Male'; 'Female'}, [85; 92; 78; 88], 'VariableNames', {'Gender', 'Score'});% 按性别分组计算平均分
groupStats = groupsummary(data, 'Gender', 'mean', 'Score');
输出结果:
| Gender | GroupCount | mean_Score |
|---|---|---|
| Female | 2 | 90 |
| Male | 2 | 81.5 |
示例 2:多分组变量与多统计方法
% 按性别和部门分组,计算销售额的总和和均值
groupStats = groupsummary(data, {'Gender', 'Dept'}, {'sum', 'mean'}, 'Sales');
2. 交叉分析:crosstab
功能:生成交叉频数表,统计两个或多个分类变量的组合频数。
语法
[table, chi2, p] = crosstab(var1, var2, ...)
var1, var2:分类变量(向量或分类数组)。table:交叉频数表。chi2:卡方检验统计量。p:p 值(检验变量独立性的显著性)。
示例:性别与部门的交叉分析
% 创建示例数据
gender = categorical({'Male'; 'Female'; 'Male'; 'Female'});
dept = categorical({'IT'; 'HR'; 'IT'; 'HR'});% 生成交叉表
[counts, ~, ~] = crosstab(gender, dept);
disp(counts);
输出:
| HR | IT | |
|---|---|---|
| Female | 2 | 0 |
| Male | 0 | 2 |
二、数值计算
1. 矩阵运算:cov(协方差矩阵)
功能:计算数据列之间的协方差矩阵,反映变量间的线性相关性。
语法
covMatrix = cov(data)
data:数值矩阵或表格中的数值列。covMatrix:对称矩阵,对角线为方差,非对角线为协方差。
示例:计算协方差矩阵
% 提取表格中的数值列(第2到5列)
numericData = data{:, 2:5};% 计算协方差矩阵
covariance = cov(numericData);
disp(covariance);
协方差解读:
- 正值:变量同向变化。
- 负值:变量反向变化。
- 绝对值大小:表示相关性强度。
2. 自定义函数应用:arrayfun
功能:对数组的每个元素应用自定义函数,避免显式循环。
语法
output = arrayfun(func, array)
func:函数句柄(如@(x) x + 5)。array:输入数组。output:与输入数组同维度的结果。
示例:所有分数加5
% 定义分数列
data.Score = [85; 92; 78; 88];% 对每个分数加5
data.AdjustedScore = arrayfun(@(x) x + 5, data.Score);
输出:
| Score | AdjustedScore |
|---|---|
| 85 | 90 |
| 92 | 97 |
| 78 | 83 |
| 88 | 93 |
对比向量化操作:
% 更高效的向量化写法
data.AdjustedScore = data.Score + 5;
三、综合应用场景
场景:销售数据分析
% 步骤1:读取数据
data = readtable('sales_data.csv');% 步骤2:按地区和产品类别分组,计算总销售额和平均利润
groupStats = groupsummary(data, {'Region', 'Product'}, {'sum', 'mean'}, {'Sales', 'Profit'});% 步骤3:生成地区和销售员的交叉表
[counts, ~, ~] = crosstab(data.Region, data.Salesperson);% 步骤4:计算销售额与利润的协方差
covMatrix = cov(data{:, {'Sales', 'Profit'}});% 步骤5:调整销售额(所有值乘以1.1)
data.AdjustedSales = arrayfun(@(x) x * 1.1, data.Sales);
四、注意事项
-
数据类型一致性:
- 聚合统计和交叉分析要求分组变量为分类变量或可离散化的数值。
- 协方差计算需确保输入为数值矩阵。
-
缺失值处理:
groupsummary默认忽略缺失值,但需提前确认数据完整性。crosstab会将缺失值单独列为一类(<undefined>)。
-
性能优化:
- 优先使用向量化操作(如
data.Score + 5)替代arrayfun,提升效率。 - 对大型数据,避免在循环中频繁操作表格,可转换为矩阵处理。
- 优先使用向量化操作(如
五、扩展函数推荐
| 函数 | 作用 | 示例 |
|---|---|---|
grpstats | 分组统计(类似 groupsummary) | grpstats(data, group, 'mean') |
varfun | 对表格列应用函数 | varfun(@mean, data) |
corrcoef | 计算相关系数矩阵 | corrcoef(data{:, 2:5}) |
pivot | 生成透视表 | pivot(data, Rows='Gender') |
生命如同寓言,其价值不在于长短,而在于内容。 —塞涅卡
相关文章:
-- 数据处理与可视化)
matlab快速入门(2)-- 数据处理与可视化
MATLAB的数据处理 1. 数据导入与导出 (1) 从文件读取数据 Excel 文件:data readtable(data.xlsx); % 读取为表格(Table)CSV 文件:data readtable(data.csv); % 自动处理表头和分隔符文本文件:data load(data.t…...

Kafka中文文档
文章来源:https://kafka.cadn.net.cn 什么是事件流式处理? 事件流是人体中枢神经系统的数字等价物。它是 为“永远在线”的世界奠定技术基础,在这个世界里,企业越来越多地使用软件定义 和 automated,而软件的用户更…...

Python-列表
3.1 列表是什么 在Python中,列表是一种非常重要的数据结构,用于存储一系列有序的元素。列表中的每个元素都有一个索引,索引从0开始。列表可以包含任何类型的元素,包括其他列表。 # 创建一个列表my_list [1, 2, 3, four, 5.0]…...

51单片机开发:定时器中断
目标:利用定时器中断,每隔1s开启/熄灭LED1灯。 外部中断结构图如下图所示,要使用定时器中断T0,须开启TE0、ET0。: 系统中断号如下图所示:定时器0的中断号为1。 定时器0的工作方式1原理图如下图所示&#x…...

【HarmonyOS之旅】基于ArkTS开发(三) -> 兼容JS的类Web开发(二)
目录 1 -> HML语法 1.1 -> 页面结构 1.2 -> 数据绑定 1.3 -> 普通事件绑定 1.4 -> 冒泡事件绑定5 1.5 -> 捕获事件绑定5 1.6 -> 列表渲染 1.7 -> 条件渲染 1.8 -> 逻辑控制块 1.9 -> 模板引用 2 -> CSS语法 2.1 -> 尺寸单位 …...

算法【混合背包】
混合背包是指多种背包模型的组合与转化。 下面通过题目加深理解。 题目一 测试链接:1742 -- Coins 分析:这道题可以通过硬币的个数将其转化为01背包,完全背包和多重背包。如果硬币的个数是1个,则是01背包;如果硬币的…...
)
WordPress eventon-lite插件存在未授权信息泄露漏洞(CVE-2024-0235)
免责声明: 本文旨在提供有关特定漏洞的深入信息,帮助用户充分了解潜在的安全风险。发布此信息的目的在于提升网络安全意识和推动技术进步,未经授权访问系统、网络或应用程序,可能会导致法律责任或严重后果。因此,作者不对读者基于本文内容所采取的任何行为承担责任。读者在…...

基于微信小程序的医院预约挂号系统设计与实现(LW+源码+讲解)
专注于大学生项目实战开发,讲解,毕业答疑辅导,欢迎高校老师/同行前辈交流合作✌。 技术范围:SpringBoot、Vue、SSM、HLMT、小程序、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、安卓app、大数据、物联网、机器学习等设计与开发。 主要内容:…...

C++初阶 -- 手撕string类(模拟实现string类)
目录 一、string类的成员变量 二、构造函数 2.1 无参版本 2.2 有参版本 2.3 缺省值版本 三、析构函数 四、拷贝构造函数 五、c_str函数 六、operator重载 七、size函数 八、迭代器iterator 8.1 正常版本 8.2 const版本 九、operator[] 9.1 正常版本 9.2 const版…...

【Postman接口测试】Postman的安装和使用
在软件测试领域,接口测试是保障软件质量的关键环节之一,而Postman作为一款功能强大且广受欢迎的接口测试工具,能够帮助测试人员高效地进行接口测试工作。本文将详细介绍Postman的安装和使用方法,让你快速上手这款工具。 一、Pos…...

miniconda学习笔记
文章主要内容:演示miniconda切换不同python环境,安装python库,使用pycharm配置不同的conda建的python环境 目录 一、miniconda 1. 是什么? 2.安装miniconda 3.基本操作 一、miniconda 1. 是什么? miniconda是一个anac…...

区块链项目孵化与包装设计:从概念到市场的全流程指南
区块链技术的快速发展催生了大量创新项目,但如何将一个区块链项目从概念孵化成市场认可的产品,是许多团队面临的挑战。本文将从孵化策略、包装设计和市场落地三个维度,为你解析区块链项目成功的关键步骤。 一、区块链项目孵化的核心要素 明确…...

JavaScript的基本组成
1、JavaScript的组成部分 JavaScript可以分为三个部分:ECMAScript标准、DOM、BOM。 ECMAScript标准 即JS的基本语法,JavaScript的核心,描述了语言的基本语法和数据类型,ECMAScript是一套标 准,定义了一种语言…...
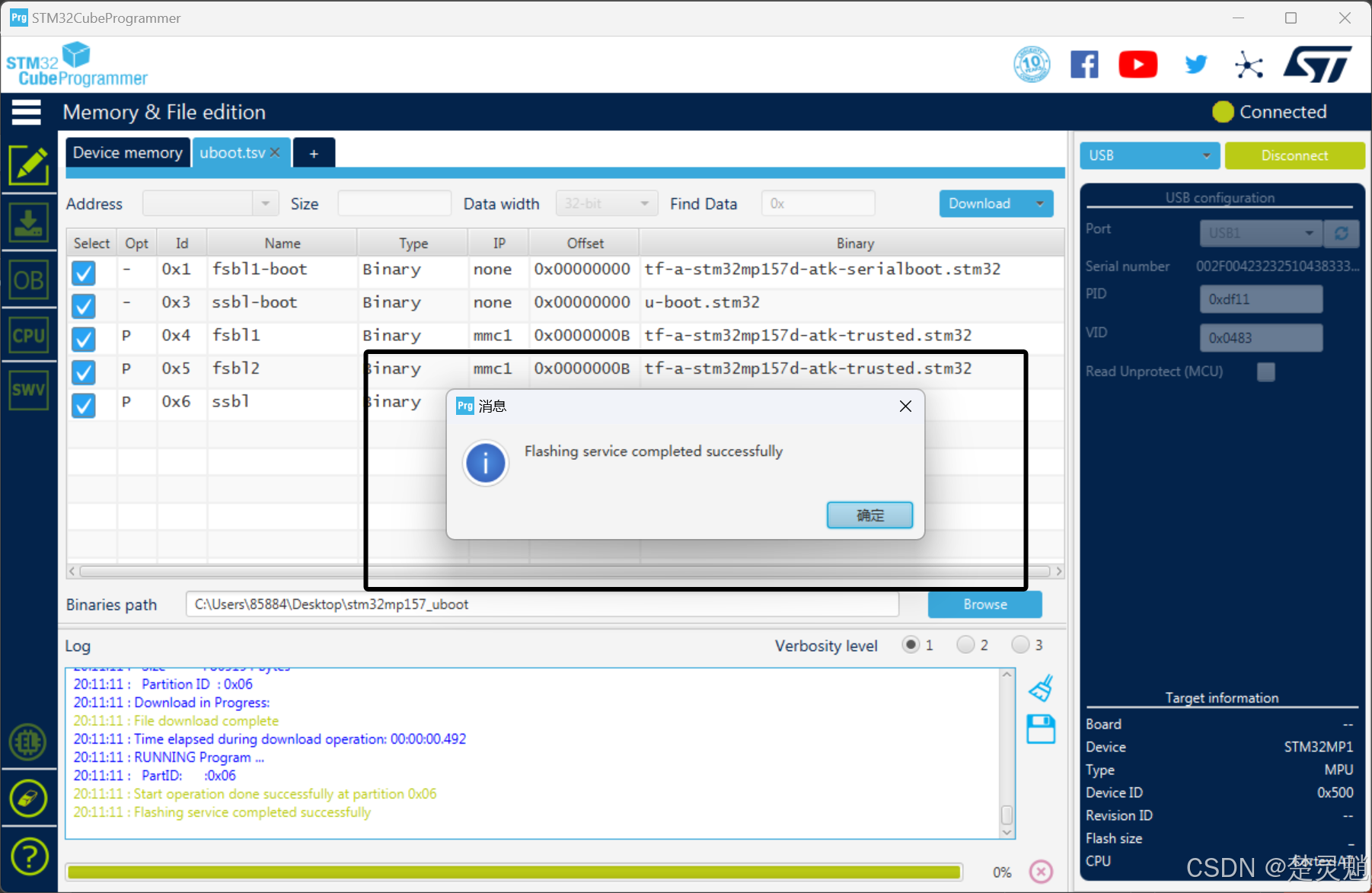
[Linux]从零开始的STM32MP157 U-Boot移植
一、前言 在上一次教程中,我们了解了STM32MP157的启动流程与安全启动机制。我们还将FSBL的相关代码移植成功了。大家还记得FSBL的下一个步骤是什么吗?没错,就是SSBL,而且常见的我们将SSBL作为存放U-Boot的地方。所以本次教程&…...

【Unity3D】实现横版2D游戏——攀爬绳索(简易版)
目录 GeneRope.cs 场景绳索生成类 HeroColliderController.cs 控制角色与单向平台是否忽略碰撞 HeroClampController.cs 控制角色攀爬 OnTriggerEnter2D方法 OnTriggerStay2D方法 OnTriggerExit2D方法 Update方法 开始攀爬 结束攀爬 Sensor_HeroKnight.cs 角色触发器…...

【llm对话系统】大模型 Llama 源码分析之 LoRA 微调
1. 引言 微调 (Fine-tuning) 是将预训练大模型 (LLM) 应用于下游任务的常用方法。然而,直接微调大模型的所有参数通常需要大量的计算资源和内存。LoRA (Low-Rank Adaptation) 是一种高效的微调方法,它通过引入少量可训练参数,固定预训练模型…...

算法随笔_35: 每日温度
上一篇:算法随笔_34: 最后一个单词的长度-CSDN博客 题目描述如下: 给定一个整数数组 temperatures ,表示每天的温度,返回一个数组 answer ,其中 answer[i] 是指对于第 i 天,下一个更高温度出现在几天后。如果气温在这之后都不会升…...

嵌入式硬件篇---CPUGPUTPU
文章目录 第一部分:处理器CPU(中央处理器)1.通用性2.核心数3.缓存4.指令集5.功耗和发热 GPU(图形处理器)1.并行处理2.核心数量3.内存带宽4.专门的应用 TPU(张量处理单元)1.为深度学习定制2.低精…...
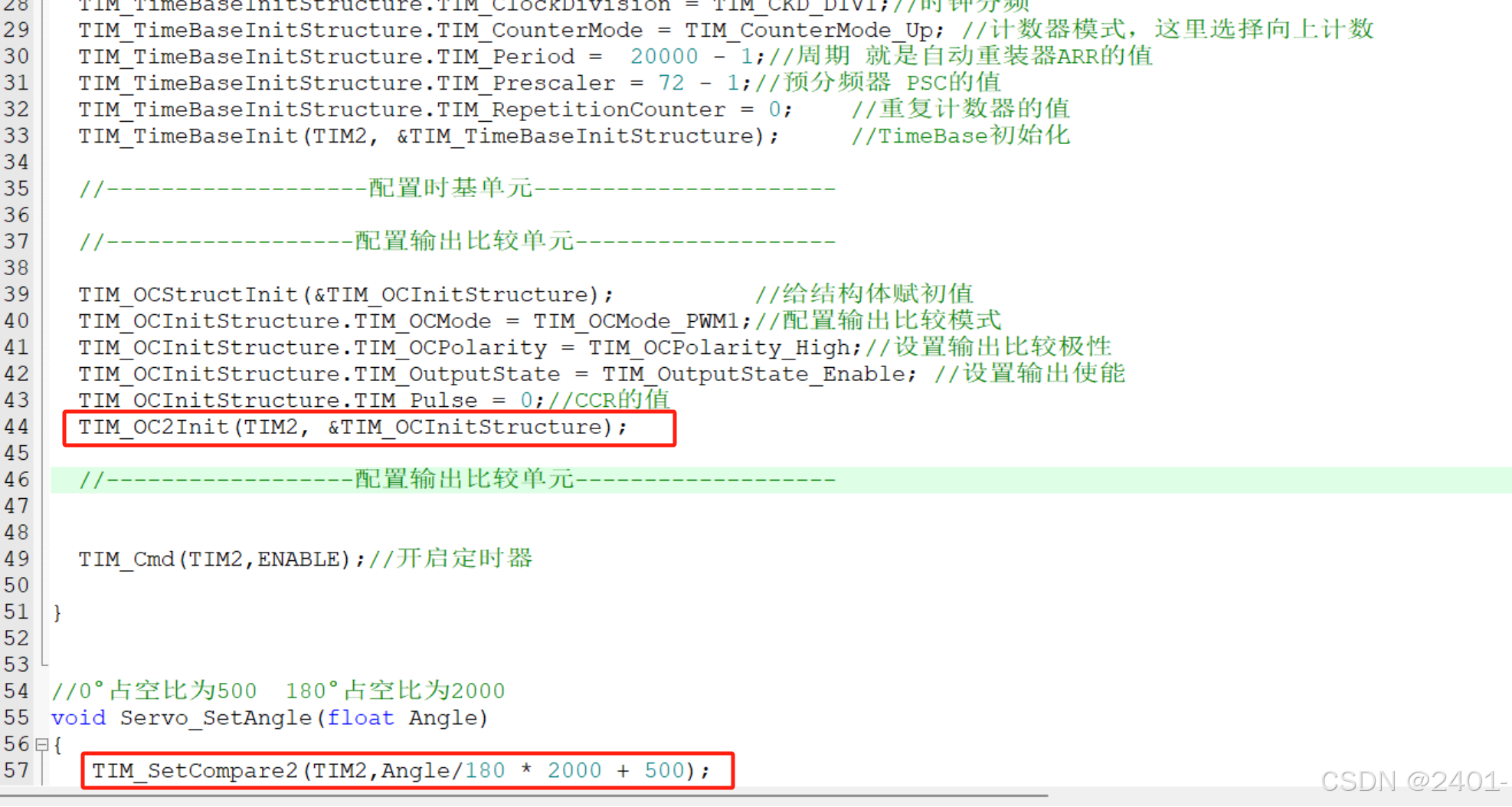
STM32 PWM驱动舵机
接线图: 这里将信号线连接到了开发板的PA1上 代码配置: 这里的PWM配置与呼吸灯一样,呼吸灯连接的是PA0引脚,输出比较单元用的是OC1通道,这里只需改为OC2通道即可。 完整代码: #include "servo.h&quo…...

设计心得——平衡和冗余
一、平衡 在前面分析了一些软件设计的基础和原则后,今天分析一下整体设计上的一些实践问题。首先分析一下设计上的平衡问题。平衡非常好理解,看到过天平或者标称的同学们应该都知道什么平衡。无论在哪个环境里,平衡都是稳定的基础。 既然说到…...

我的Claude Code不再被封号,Taotoken提供了稳定可靠的替代方案
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 我的Claude Code不再被封号,Taotoken提供了稳定可靠的替代方案 作为一名频繁使用Claude Code进行代码生成和审查的个人…...

Java并发编程:CompletableFuture实战
Java并发编程:CompletableFuture实战 引言 Java 8引入的CompletableFuture是现代异步编程的重要工具,它不仅解决了Future的局限性,还提供了丰富的API用于组合、转换和处理异步结果。相比传统的Future,CompletableFuture支持流式调…...
)
保姆级教程:在Ubuntu 20.04上从源码编译aarch64-linux-gnu交叉工具链(GCC 9.2.0 + Glibc 2.30)
深度实践:从源码构建aarch64-linux-gnu交叉工具链全指南 在嵌入式开发领域,交叉编译工具链的构建能力是区分普通开发者与资深工程师的重要标志。当现成的预编译工具链无法满足特定需求时,从源码手动构建工具链不仅能解决兼容性问题࿰…...

LLM Notebooks:从零构建RAG问答系统的实践指南
1. 项目概述:一个面向大语言模型实践的“笔记本”仓库最近在GitHub上闲逛,发现了一个挺有意思的仓库,叫qianniuspace/llm_notebooks。光看名字,llm_notebooks,大语言模型笔记本,这指向性就非常明确了。这大…...

百度网盘直链解析工具:突破下载限速的Python解决方案
百度网盘直链解析工具:突破下载限速的Python解决方案 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 你是否曾经为百度网盘的下载速度而烦恼?作为国内最…...

基于Fire2012算法与FastLED库的Arduino LED篝火制作全攻略
1. 项目概述:用代码点燃一场永不熄灭的数字篝火夏夜、星空、朋友围坐,篝火带来的温暖与氛围是露营的灵魂。但现实是,很多营地禁止明火,或者在城市阳台、室内空间,生一堆真正的火既不安全也不现实。作为一名玩了十多年A…...

Go语言实现跨平台系统更新检查器:自动化运维与安全监控实践
1. 项目概述:一个被低估的系统运维“哨兵”在服务器和桌面系统的日常运维中,有一个场景大家一定不陌生:某天,你管理的服务器突然因为一个已知漏洞被攻击,事后排查发现,相关的安全补丁其实在几周前就已经发布…...

使用mcp-maker快速构建AI工具集成服务器:从MCP协议到实践
1. 项目概述:一个为AI应用注入“超能力”的MCP服务器工厂 如果你最近在折腾AI应用开发,特别是想给ChatGPT、Claude这类大模型配上“手和脚”,让它们能操作你的本地文件、查询数据库,甚至控制你的智能家居,那你大概率已…...

可穿戴电子模块化连接方案:5mm微型按扣实现电路板与织物的可插拔连接
1. 项目概述与核心思路在折腾可穿戴电子项目时,最让人头疼的问题之一,就是如何让电路板与衣物既可靠连接,又能方便地拆下来。传统的做法要么是用导电胶带粘(不牢靠、易氧化),要么是直接把线焊死在板子上然后…...

All in Token,移动,电信,联通,百度,阿里,字节,华为,Token战争,Token无用:李彦宏用DAA终结了AI的度量衡之争
今年4月,AI行业出现了一组让投资人坐立难安的数据:Anthropic年化营收突破300亿美元,正式超过OpenAI的约250亿美元。但反常的是,据第三方机构估算,Claude的月活用户仅约为ChatGPT的2.44%。以及,Anthropic的模…...