【llm对话系统】大模型 Llama 源码分析之 LoRA 微调
1. 引言
微调 (Fine-tuning) 是将预训练大模型 (LLM) 应用于下游任务的常用方法。然而,直接微调大模型的所有参数通常需要大量的计算资源和内存。LoRA (Low-Rank Adaptation) 是一种高效的微调方法,它通过引入少量可训练参数,固定预训练模型的权重,从而在保持性能的同时大大减少了计算开销。
本文将深入分析 LoRA 的原理,并结合 Llama 源码解读其实现逻辑,最后探讨 LoRA 的优势。
2. LoRA 原理
LoRA 的核心思想是:预训练模型中已经包含了大量的低秩 (low-rank) 特征,微调时只需要对这些低秩特征进行微调即可。
具体来说,LoRA 假设权重更新矩阵 ΔW 也是低秩的。对于一个预训练的权重矩阵 W ∈ R^(d×k),LoRA 将其更新表示为:
W' = W + ΔW = W + BA
其中:
W是预训练的权重矩阵。ΔW是权重更新矩阵。B ∈ R^(d×r)和A ∈ R^(r×k)是两个低秩矩阵,r远小于d和k,r被称为 LoRA 的秩 (rank)。
在训练过程中,W 被冻结,只有 A 和 B 是可训练的。
直观理解:
可以将 W 看作一个编码器,将输入 x 编码成一个高维表示 Wx。LoRA 认为,在微调过程中,我们不需要完全改变这个编码器,只需要通过 BA 对其进行一个低秩的调整即可。
3. Llama 中 LoRA 的实现
虽然 Llama 官方代码没有直接集成 LoRA,但我们可以使用一些流行的库 (例如 peft by Hugging Face) 来实现 Llama 的 LoRA 微调。peft 库提供了 LoraConfig 和 get_peft_model 等工具,可以方便地将 LoRA 应用于各种 Transformer 模型。
3.1 使用 peft 库实现 Llama 的 LoRA 微调
以下是一个使用 peft 库实现 Llama 的 LoRA 微调的简化示例:
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import get_peft_model, LoraConfig, TaskType# 加载预训练的 Llama 模型和分词器
model_name = "meta-llama/Llama-2-7b-hf" # 假设使用 Llama 2 7B
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)# LoRA 配置
config = LoraConfig(task_type=TaskType.CAUSAL_LM,inference_mode=False,r=8, # LoRA 的秩lora_alpha=32, # LoRA 的缩放因子lora_dropout=0.1, # Dropout 比例target_modules=["q_proj", "v_proj"], # 需要应用 LoRA 的模块
)# 获取支持 LoRA 的模型
model = get_peft_model(model, config)# 打印可训练参数的比例
model.print_trainable_parameters()# ... (加载数据,进行训练) ...
代码解释:
- 加载预训练模型:使用
transformers库加载预训练的 Llama 模型和分词器。 - LoRA 配置:创建一个
LoraConfig对象,指定 LoRA 的配置参数:task_type:任务类型,这里是因果语言模型 (Causal Language Modeling)。r:LoRA 的秩。lora_alpha:LoRA 的缩放因子,用于控制 LoRA 模块的权重。lora_dropout:Dropout 比例。target_modules: 指定需要应用 LoRA 的模块, 通常是注意力层中的q_proj,v_proj, 还可以是k_proj,o_proj,gate_proj,up_proj,down_proj等。不同的模型需要根据实际情况配置。
- 获取支持 LoRA 的模型:使用
get_peft_model函数将原始的 Llama 模型转换为支持 LoRA 的模型。 - 打印可训练参数:使用
model.print_trainable_parameters()可以查看模型中可训练参数的比例,通常 LoRA 的可训练参数比例非常小。
3.2 peft 库中 LoRA 的实现细节 (部分)
peft 库中 LoraModel 类的部分代码 (为了清晰起见,已进行简化):
class LoraModel(torch.nn.Module):# ...def _find_and_replace(self, model):# ... (遍历模型的每一层) ...if isinstance(module, nn.Linear) and name in self.config.target_modules:new_module = Linear(module.in_features,module.out_features,bias=module.bias is not None,r=self.config.r,lora_alpha=self.config.lora_alpha,lora_dropout=self.config.lora_dropout,)# ... (将原模块的权重赋值给新模块) ...# ...class Linear(nn.Linear):def __init__(self,in_features: int,out_features: int,r: int = 0,lora_alpha: int = 1,lora_dropout: float = 0.0,**kwargs,):super().__init__(in_features, out_features, **kwargs)# LoRA 参数self.r = rself.lora_alpha = lora_alpha# 初始化 A 和 Bif r > 0:self.lora_A = nn.Parameter(torch.randn(r, in_features))self.lora_B = nn.Parameter(torch.zeros(out_features, r)) # B 初始化为全 0self.scaling = self.lora_alpha / self.rdef forward(self, x: torch.Tensor):result = F.linear(x, self.weight, bias=self.bias) # W @ xif self.r > 0:result += (self.lora_B @ self.lora_A @ x.transpose(-2, -1) # (B @ A) @ x).transpose(-2, -1) * self.scalingreturn result
代码解释:
_find_and_replace函数:遍历模型的每一层,找到需要应用 LoRA 的线性层 (例如,q_proj,v_proj),并将其替换为Linear层。Linear类:继承自nn.Linear,并添加了 LoRA 的参数lora_A和lora_B。lora_A初始化为随机值。lora_B初始化为全 0,这是为了保证在训练开始时,LoRA 部分的输出为 0,不影响预训练模型的原始行为。scaling是一个缩放因子,用于控制 LoRA 模块的权重。
forward函数:F.linear(x, self.weight, bias=self.bias)计算原始的线性变换W @ x。(self.lora_B @ self.lora_A @ x.transpose(-2, -1)).transpose(-2, -1) * self.scaling计算 LoRA 部分的输出(B @ A) @ x,并乘以缩放因子。- 将两者相加,得到最终的输出。
4. LoRA 的优势
- 高效的参数利用:LoRA 只需微调少量的参数 (A 和 B),而冻结了预训练模型的大部分参数,大大减少了训练时的内存占用和计算开销。
- 快速的训练速度:由于可训练参数较少,LoRA 的训练速度通常比全量微调快得多。
- 防止过拟合:LoRA 的低秩约束起到了一定的正则化作用,有助于防止过拟合。
- 性能相当:在许多任务上,LoRA 可以达到与全量微调相当的性能。
- 易于部署:训练完成后,可以将
W和BA相加,得到新的权重矩阵W',然后像使用原始的预训练模型一样进行部署,无需额外的计算开销。
相关文章:

【llm对话系统】大模型 Llama 源码分析之 LoRA 微调
1. 引言 微调 (Fine-tuning) 是将预训练大模型 (LLM) 应用于下游任务的常用方法。然而,直接微调大模型的所有参数通常需要大量的计算资源和内存。LoRA (Low-Rank Adaptation) 是一种高效的微调方法,它通过引入少量可训练参数,固定预训练模型…...

算法随笔_35: 每日温度
上一篇:算法随笔_34: 最后一个单词的长度-CSDN博客 题目描述如下: 给定一个整数数组 temperatures ,表示每天的温度,返回一个数组 answer ,其中 answer[i] 是指对于第 i 天,下一个更高温度出现在几天后。如果气温在这之后都不会升…...

嵌入式硬件篇---CPUGPUTPU
文章目录 第一部分:处理器CPU(中央处理器)1.通用性2.核心数3.缓存4.指令集5.功耗和发热 GPU(图形处理器)1.并行处理2.核心数量3.内存带宽4.专门的应用 TPU(张量处理单元)1.为深度学习定制2.低精…...
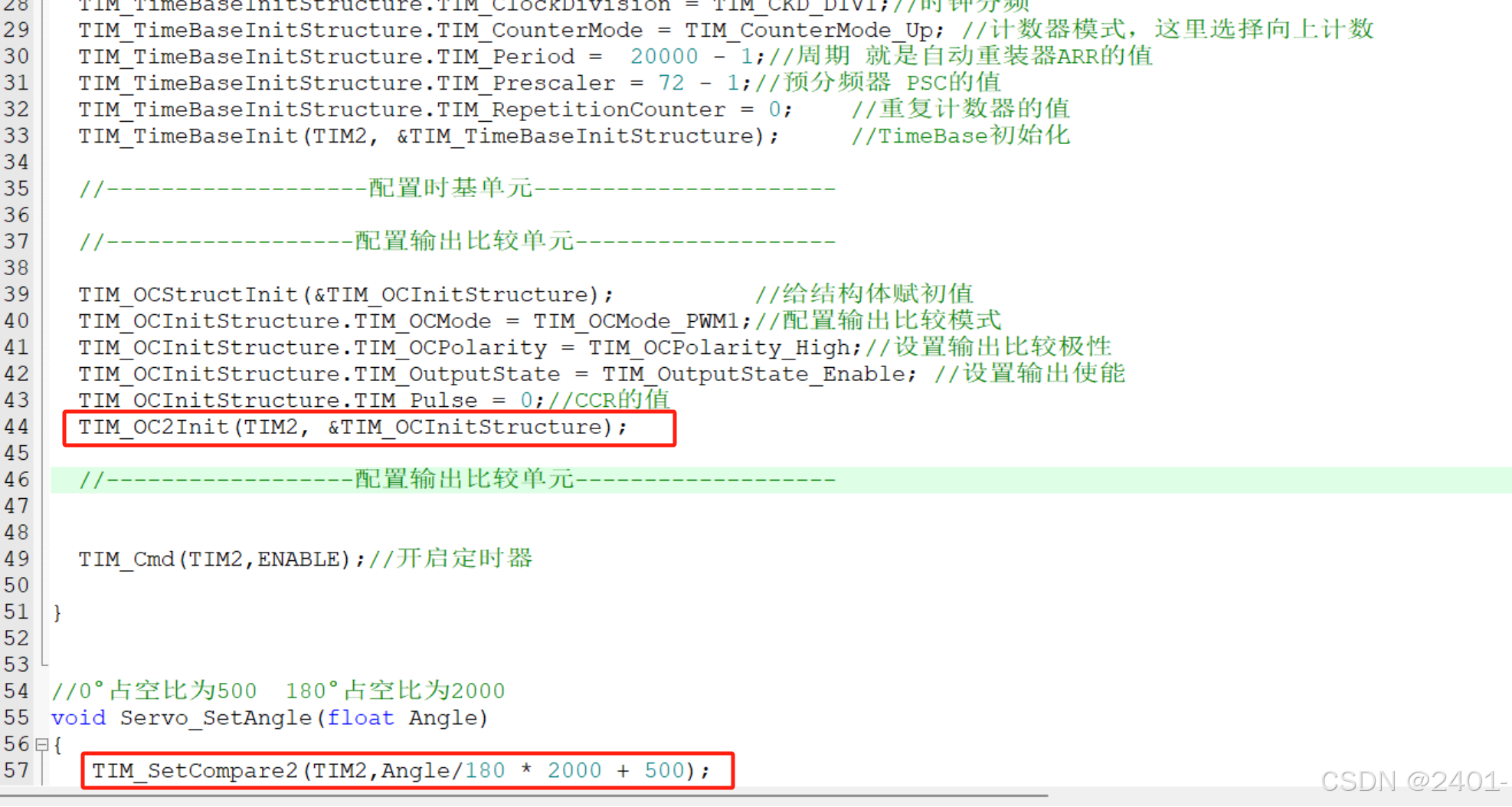
STM32 PWM驱动舵机
接线图: 这里将信号线连接到了开发板的PA1上 代码配置: 这里的PWM配置与呼吸灯一样,呼吸灯连接的是PA0引脚,输出比较单元用的是OC1通道,这里只需改为OC2通道即可。 完整代码: #include "servo.h&quo…...

设计心得——平衡和冗余
一、平衡 在前面分析了一些软件设计的基础和原则后,今天分析一下整体设计上的一些实践问题。首先分析一下设计上的平衡问题。平衡非常好理解,看到过天平或者标称的同学们应该都知道什么平衡。无论在哪个环境里,平衡都是稳定的基础。 既然说到…...

webrtc协议详细解释
### 一、概述与背景 WebRTC(Web Real-Time Communication)最早由 Google 在 2011 年开源,旨在为浏览器与移动端应用提供客户端直连(点对点)方式进行实时音视频及数据传输的能力。传统的网络应用在进行高实时性音视频通…...
动手学强化学习(四)——蒙特卡洛方法
一、蒙特卡洛方法 蒙特卡洛方法是一种无模型(Model-Free)的强化学习算法,它通过直接与环境交互采样轨迹(episodes)来估计状态或动作的价值函数(Value Function),而不需要依赖环境动态…...
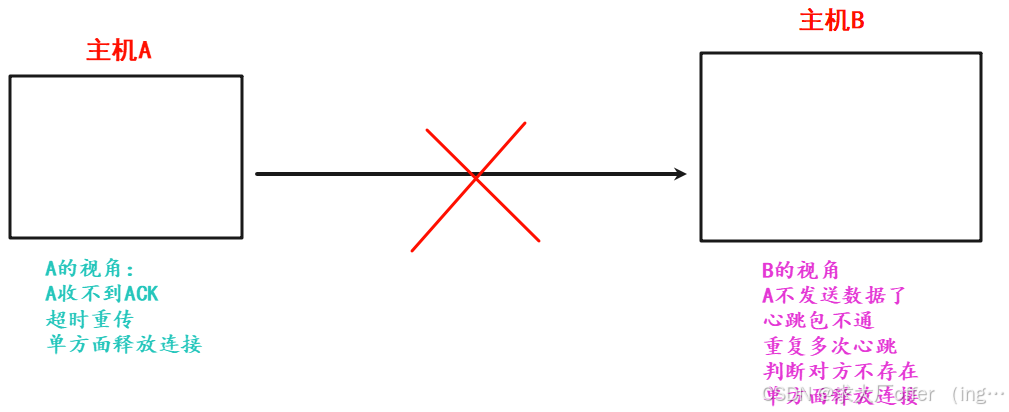
网络原理(3)—— 传输层详解
目录 一. 再谈端口号 二. UDP协议(用户数据报协议) 2.1 UDP协议端格式 2.2 UDP报文长度 2.3 UDP校验和 三. TCP协议(传输控制协议) 3.1 TCP协议段格式 3.2 核心机制 3.2.1 确认应答 —— “感知对方是否收到” 3.2.2 超时重传 3.3.3 连接管理 —— 三次握手与四…...
2025美赛美国大学生数学建模竞赛A题完整思路分析论文(43页)(含模型、可运行代码和运行结果)
2025美国大学生数学建模竞赛A题完整思路分析论文 目录 摘要 一、问题重述 二、 问题分析 三、模型假设 四、 模型建立与求解 4.1问题1 4.1.1问题1思路分析 4.1.2问题1模型建立 4.1.3问题1样例代码(仅供参考) 4.1.4问题1样例代码运行结果&…...
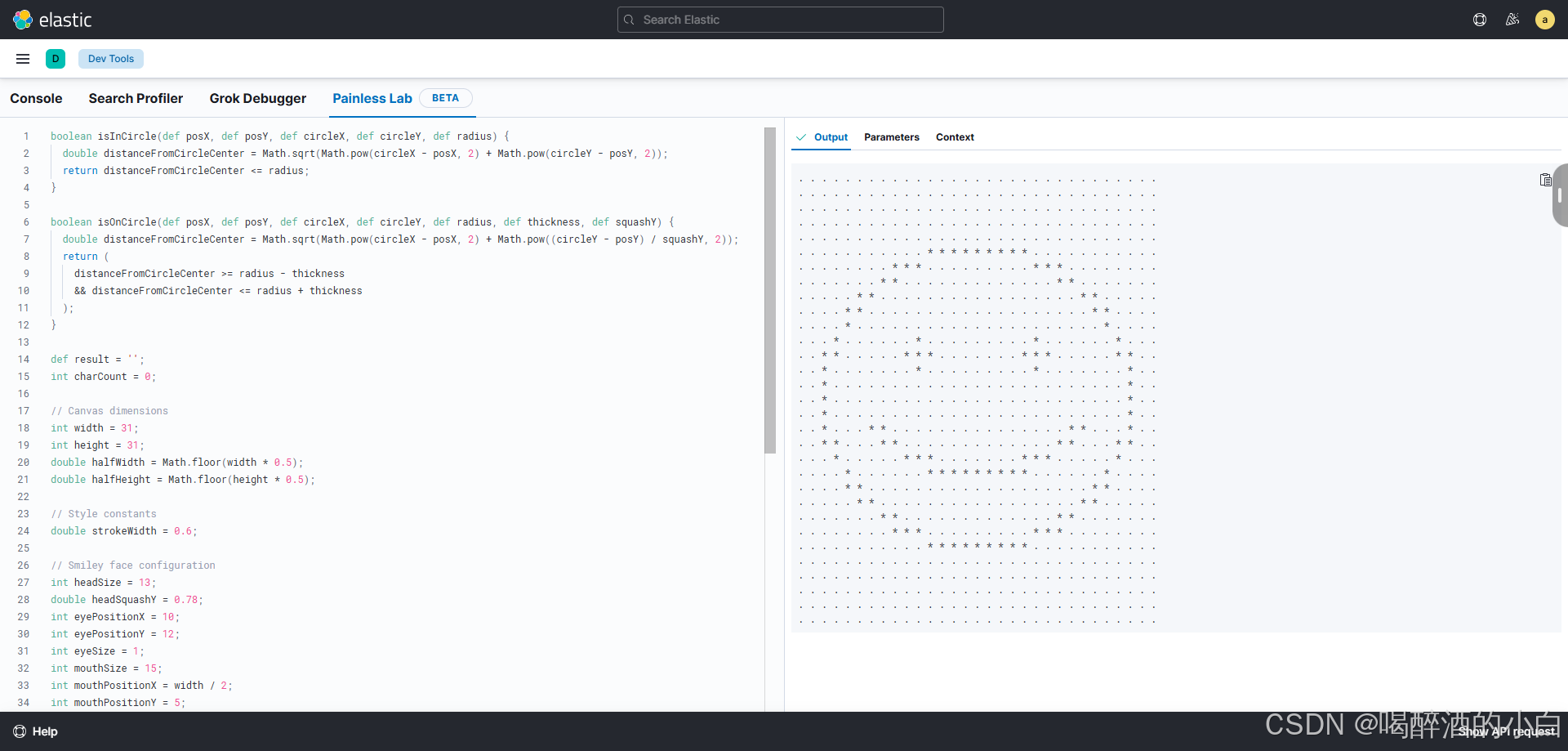
Elasticsearch的开发工具(Dev Tools)
目录 说明1. **Console**2. **Search Profiler**3. **Grok Debugger**4. **Painless Lab**总结 说明 Elasticsearch的开发工具(Dev Tools)在Kibana中提供了多种功能强大的工具,用于调试、优化和测试Elasticsearch查询和脚本。以下是关于Cons…...

Python-基于PyQt5,pdf2docx,pathlib的PDF转Word工具
前言:日常生活中,我们常常会跟WPS Office打交道。作表格,写报告,写PPT......可以说,我们的生活已经离不开WPS Office了。与此同时,我们在这个过程中也会遇到各种各样的技术阻碍,例如部分软件的PDF转Word需要收取额外费用等。那么,可不可以自己开发一个小工具来实现PDF转…...
小程序-视图与逻辑
前言 1. 声明式导航 open-type"switchTab"如果没有写这个,因为是tabBar所以写这个,就无法跳转。路径开始也必须为斜线 open-type"navigate"这个可以不写 现在开始实现后退的效果 现在我们就在list页面里面实现后退 2.编程式导航…...
UE5制作视差图
双目深度估计开源数据集很多都是用UE制作的,那么我们自己能否通过UE制作自己想要的场景的数据集呢。最近花了点时间研究了一下,分享给需要的小伙伴。 主要使用的是UnrealCV插件,UnrealCV是一个开源项目,旨在帮助计算机视觉研究人…...

海浪波高预测(背景调研)
#新星杯14天创作挑战营第7期# ps:图片由通义千问生成 历史工作: 针对更高细粒度、更高精度的波浪高度预测任务: Mumtaz Ali 等人提出了一种多元线性回归模型(MLR-CWLS),该模型利用协方差加权最小二乘法&a…...

代码随想录算法训练营第四十二天-动态规划-股票-188.买卖股票的最佳时机IV
题目要求进行k次买卖其实就是上一题的扩展,把2次扩展为k次定义动规数组依然是二维,第一个维度表示第几天,第二个维度表示第几次买入和卖出所以第二个维度的长度应该是2k1在for循环内,要使用一个内循环来表示第几次买入或卖出&…...
Gradle配置指南:深入解析settings.gradle.kts(Kotlin DSL版)
文章目录 Gradle配置指南:深入解析settings.gradle.kts(Kotlin DSL版)settings.gradle.kts 基础配置选项单项目配置多项目配置 高级配置选项插件管理(Plugin Management)基础配置模板案例:Android项目标准配…...
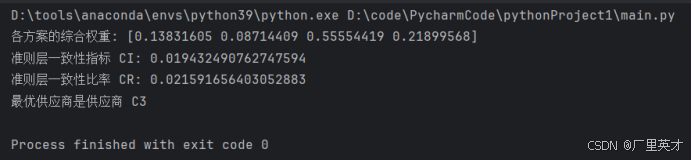
软件工程经济学-日常作业+大作业
目录 一、作业1 作业内容 解答 二、作业2 作业内容 解答 三、作业3 作业内容 解答 四、大作业 作业内容 解答 1.建立层次结构模型 (1)目标层 (2)准则层 (3)方案层 2.构造判断矩阵 (1)准则层判断矩阵 (2)方案层判断矩阵 3.层次单排序及其一致性检验 代码 …...
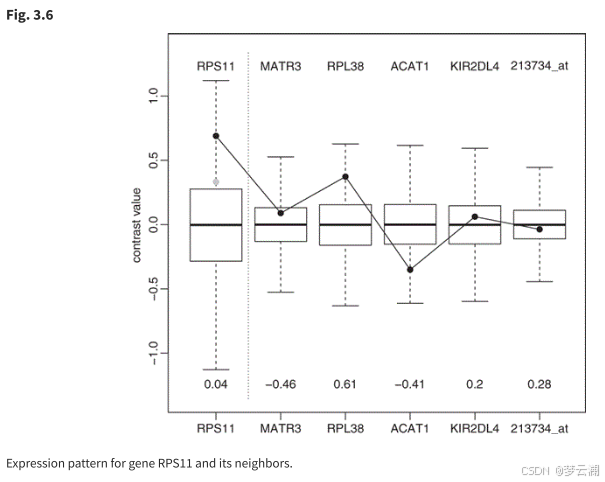
论文阅读(三):微阵列数据的图形模型和多变量分析
1.论文链接:Graphical Models and Multivariate Analysis of Microarray Data 摘要: 基因表达数据的通常分析忽略了基因表达值之间的相关性。从生物学上讲,这种假设是不合理的。本章介绍的方法允许通过稀疏高斯图形模型来描述基因之间的相关…...
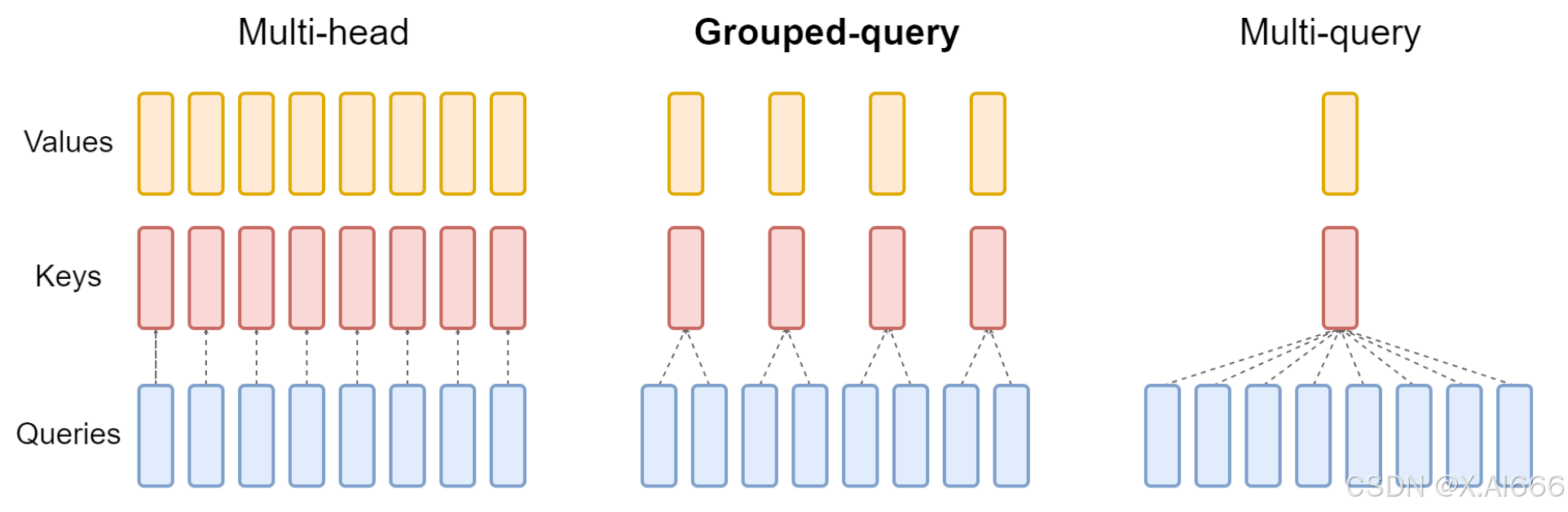
【大模型LLM面试合集】大语言模型架构_MHA_MQA_GQA
MHA_MQA_GQA 1.总结 在 MHA(Multi Head Attention) 中,每个头有自己单独的 key-value 对;标准的多头注意力机制,h个Query、Key 和 Value 矩阵。在 MQA(Multi Query Attention) 中只会有一组 k…...
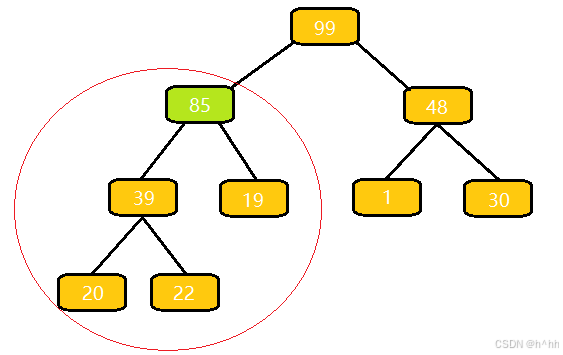
向上调整算法(详解)c++
算法流程: 与⽗结点的权值作⽐较,如果⽐它⼤,就与⽗亲交换; 交换完之后,重复 1 操作,直到⽐⽗亲⼩,或者换到根节点的位置 这里为什么插入85完后合法? 我们插入一个85,…...

告别showSoftInput失效:一文读懂Android 11+的WindowInsetsController输入法控制
Android输入法控制演进:从InputMethodManager到WindowInsetsController的深度解析 在移动应用开发中,输入法交互是最基础却又最容易被忽视的细节之一。许多开发者都曾遇到过这样的场景:精心设计的登录界面,光标在输入框闪烁&#…...

恶劣环境下LED发光服饰的可靠系统构建:从设计到工艺的工程实践
1. 项目概述与核心挑战如果你曾经尝试过制作一件会发光的服装,无论是为了音乐节、万圣节还是水下表演,你大概都体会过那种“亮一次,修三次”的挫败感。LED灯带在工作室的桌面上测试时完美无瑕,一旦穿到身上,开始活动、…...

如何快速提升游戏帧率:OpenSpeedy游戏加速优化终极指南
如何快速提升游戏帧率:OpenSpeedy游戏加速优化终极指南 【免费下载链接】OpenSpeedy 🎮 An open-source game speed modifier. 项目地址: https://gitcode.com/gh_mirrors/op/OpenSpeedy 你是否厌倦了游戏卡顿和掉帧?OpenSpeedy是一款…...

Gitclaw:封装复杂Git操作,提升开发效率的命令行工具
1. 项目概述:一个为Git操作注入“爪牙”的命令行工具如果你和我一样,日常开发工作重度依赖Git,那你肯定也经历过这样的时刻:面对一个需要多步操作才能完成的复杂Git任务,比如清理多个已合并的分支、批量重写提交历史中…...

AI驱动全栈开发:Cursor集成模板与高效协作实践
1. 项目概述:当AI代码助手遇上全栈开发最近在GitHub上看到一个挺有意思的项目,叫“Cursor-FullStack-AI-App”。光看名字,你大概能猜到它和Cursor这个AI编程工具,以及全栈应用开发有关。作为一个在前后端都摸爬滚打过多年的开发者…...

gnamiblast-skill:基于技能化与管道化的智能文本处理工具解析
1. 项目概述与核心价值最近在GitHub上闲逛,又发现了一个挺有意思的项目,叫gabrivardqc123/gnamiblast-skill。光看这个名字,可能有点摸不着头脑,gnamiblast听起来像是个自造词,skill又指向了某种技能或功能。作为一名常…...

基于RP2040的客制化宏键盘:从硬件设计到KMK固件开发全攻略
1. 项目概述与核心价值最近在折腾一个挺有意思的开源项目,叫clawdpad,作者是kudretyilmazz。乍一看这个名字,可能有点摸不着头脑,但如果你对机械键盘、客制化输入设备或者桌面自动化感兴趣,那这个项目绝对值得你花时间…...

多数人支持!微软或把 Xbox 重新品牌化为 XBOX,回归最初形式
Xbox 品牌重塑:从民意调查到账号更名微软 Xbox 首席执行官阿莎夏尔马在 X(原推特)上发起民意调查,询问粉丝微软应使用 Xbox 还是 XBOX,结果多数人支持 XBOX,随后公司将其 X 账号更名。不过,Xbox…...

pgui:轻量级跨平台C++ GUI框架的设计与集成实践
1. 项目概述:一个轻量级、跨平台的现代GUI框架如果你是一名C开发者,并且厌倦了Qt的臃肿、MFC的古老,或者觉得Dear ImGui虽然强大但需要自己管理太多渲染细节,那么你很可能和我一样,一直在寻找一个“刚刚好”的GUI解决方…...

AMD Ryzen调试神器SMUDebugTool:免费开源工具让你的处理器性能飞起来!
AMD Ryzen调试神器SMUDebugTool:免费开源工具让你的处理器性能飞起来! 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Tab…...