【大模型LLM面试合集】大语言模型架构_MHA_MQA_GQA
MHA_MQA_GQA
1.总结
- 在 MHA(Multi Head Attention) 中,每个头有自己单独的 key-value 对;标准的多头注意力机制,h个Query、Key 和 Value 矩阵。
- 在 MQA(Multi Query Attention) 中只会有一组 key-value 对;多查询注意力的一种变体,也是用于自回归解码的一种注意力机制。与MHA不同的是,MQA 让所有的头之间共享同一份 Key 和 Value 矩阵,每个头只单独保留了一份 Query 参数,从而大大减少 Key 和 Value 矩阵的参数量。
- 在 GQA(Grouped Query Attention)中,会对 attention 进行分组操作,query 被分为 N 组,每个组共享一个 Key 和 Value 矩阵GQA将查询头分成G组,每个组共享一个Key 和 Value 矩阵。GQA-G是指具有G组的grouped-query attention。GQA-1具有单个组,因此具有单个Key 和 Value,等效于MQA。而GQA-H具有与头数相等的组,等效于MHA。
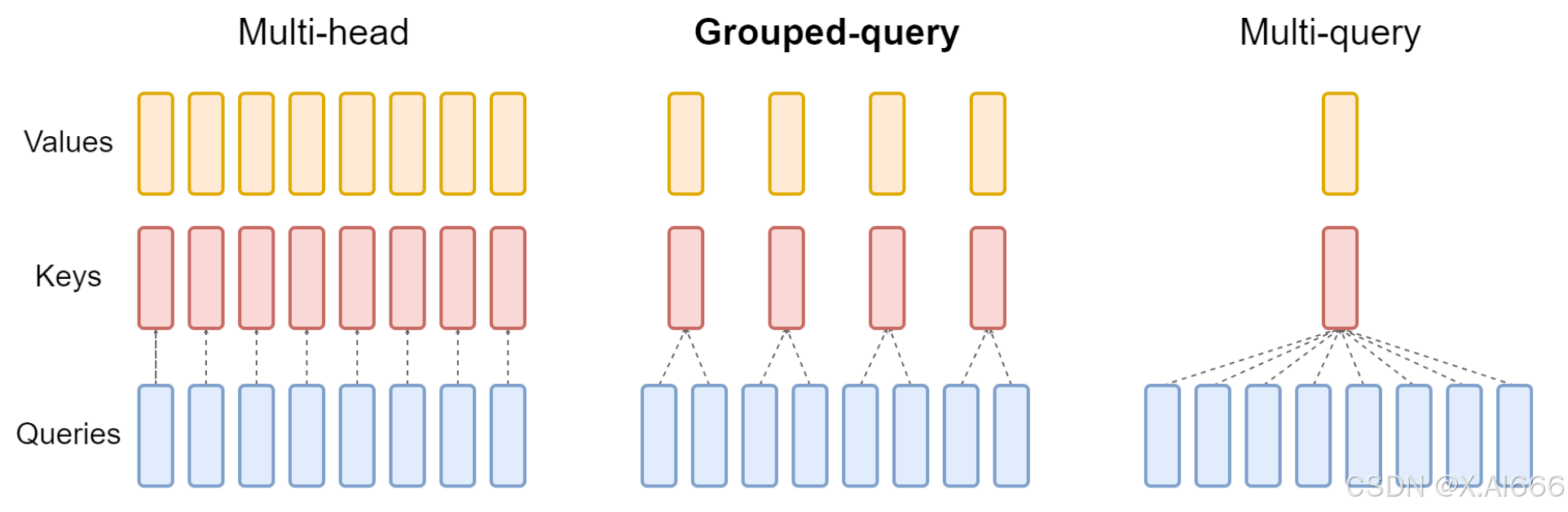
GQA-N 是指具有 N 组的 Grouped Query Attention。GQA-1具有单个组,因此具有单个Key 和 Value,等效于MQA。而GQA-H具有与头数相等的组,等效于MHA。
GQA介于MHA和MQA之间。GQA 综合 MHA 和 MQA ,既不损失太多性能,又能利用 MQA 的推理加速。不是所有 Q 头共享一组 KV,而是分组一定头数 Q 共享一组 KV,比如上图中就是两组 Q 共享一组 KV。
2.代码实现
2.1 MHA
多头注意力机制是Transformer模型中的核心组件。在其设计中,"多头"意味着该机制并不只计算一种注意力权重,而是并行计算多种权重,每种权重都从不同的“视角”捕获输入的不同信息。
- 为输入序列中的每个元素计算q, k, v,这是通过将输入此向量与三个权重矩阵相乘实现的:
q = x W q k = x W k v = x W v \begin{aligned} q & =x W_{q} \\ k & =x W_{k} \\ v & =x W_{v}\end{aligned} qkv=xWq=xWk=xWv
其中, x x x是输入词向量, W q W_q Wq, W k W_k Wk和 W v W_v Wv是q, k, v的权重矩阵 - 计算q, k 注意力得分: score ( q , k ) = q ⋅ k T d k \operatorname{score}(q, k)=\frac{q \cdot k^{T}}{\sqrt{d_{k}}} score(q,k)=dkq⋅kT,其中, d k d_k dk是k的维度
- 使用softmax得到注意力权重: Attention ( q , K ) = softmax ( score ( q , k ) ) \operatorname{Attention}(q, K)=\operatorname{softmax}(\operatorname{score}(q, k)) Attention(q,K)=softmax(score(q,k))
- 使用注意力权重和v,计算输出: O u t p u t = Attention ( q , K ) ⋅ V Output =\operatorname{Attention}(q, K) \cdot V Output=Attention(q,K)⋅V
- 拼接多头输出,乘以 W O W_O WO,得到最终输出: M u l t i H e a d O u t p u t = C o n c a t ( O u t p u t 1 , O u t p u t 2 , … , O u t p u t H ) W O MultiHeadOutput = Concat \left(\right. Output ^{1}, Output ^{2}, \ldots, Output \left.^{H}\right) W_{O} MultiHeadOutput=Concat(Output1,Output2,…,OutputH)WO
代码实现
import torch
from torch import nn
class MutiHeadAttention(torch.nn.Module):def __init__(self, hidden_size, num_heads):super(MutiHeadAttention, self).__init__()self.num_heads = num_headsself.head_dim = hidden_size // num_heads## 初始化Q、K、V投影矩阵self.q_linear = nn.Linear(hidden_size, hidden_size)self.k_linear = nn.Linear(hidden_size, hidden_size)self.v_linear = nn.Linear(hidden_size, hidden_size)## 输出线性层self.o_linear = nn.Linear(hidden_size, hidden_size)def forward(self, hidden_state, attention_mask=None):batch_size = hidden_state.size()[0]query = self.q_linear(hidden_state)key = self.k_linear(hidden_state)value = self.v_linear(hidden_state)query = self.split_head(query)key = self.split_head(key)value = self.split_head(value)## 计算注意力分数attention_scores = torch.matmul(query, key.transpose(-1, -2)) / torch.sqrt(torch.tensor(self.head_dim))if attention_mask != None:attention_scores += attention_mask * -1e-9## 对注意力分数进行归一化attention_probs = torch.softmax(attention_scores, dim=-1)output = torch.matmul(attention_probs, value)## 对注意力输出进行拼接output = output.transpose(-1, -2).contiguous().view(batch_size, -1, self.head_dim * self.num_heads)output = self.o_linear(output)return outputdef split_head(self, x):batch_size = x.size()[0]return x.view(batch_size, -1, self.num_heads, self.head_dim).transpose(1,2)2.2 MQA
上图最右侧,直观上就是在计算多头注意力的时候,query仍然进行分头,和多头注意力机制相同,而key和value只有一个头。
正常情况在计算多头注意力分数的时候,query、key的维度是相同的,所以可以直接进行矩阵乘法,但是在多查询注意力(MQA)中,query的维度为 [batch_size, num_heads, seq_len, head_dim],key和value的维度为 [batch_size, 1, seq_len, head_dim]。这样就无法直接进行矩阵的乘法,为了完成这一乘法,可以采用torch的广播乘法
## 多查询注意力
import torch
from torch import nn
class MutiQueryAttention(torch.nn.Module):def __init__(self, hidden_size, num_heads):super(MutiQueryAttention, self).__init__()self.num_heads = num_headsself.head_dim = hidden_size // num_heads## 初始化Q、K、V投影矩阵self.q_linear = nn.Linear(hidden_size, hidden_size)self.k_linear = nn.Linear(hidden_size, self.head_dim) ###self.v_linear = nn.Linear(hidden_size, self.head_dim) ##### 输出线性层self.o_linear = nn.Linear(hidden_size, hidden_size)def forward(self, hidden_state, attention_mask=None):batch_size = hidden_state.size()[0]query = self.q_linear(hidden_state)key = self.k_linear(hidden_state)value = self.v_linear(hidden_state)query = self.split_head(query)key = self.split_head(key, 1)value = self.split_head(value, 1)## 计算注意力分数attention_scores = torch.matmul(query, key.transpose(-1, -2)) / torch.sqrt(torch.tensor(self.head_dim))if attention_mask != None:attention_scores += attention_mask * -1e-9## 对注意力分数进行归一化attention_probs = torch.softmax(attention_scores, dim=-1)output = torch.matmul(attention_probs, value)output = output.transpose(-1, -2).contiguous().view(batch_size, -1, self.head_dim * self.num_heads)output = self.o_linear(output)return outputdef split_head(self, x, head_num=None):batch_size = x.size()[0]if head_num == None:return x.view(batch_size, -1, self.num_heads, self.head_dim).transpose(1,2)else:return x.view(batch_size, -1, head_num, self.head_dim).transpose(1,2)相比于多头注意力,多查询注意力在W_k和W_v的维度映射上有所不同,还有就是计算注意力分数采用的是广播机制,计算最后的output也是广播机制,其他的与多头注意力完全相同。
2.3 GQA
GQA将MAQ中的key、value的注意力头数设置为一个能够被原本的注意力头数整除的一个数字,也就是group数。
不同的模型使用GQA有着不同的实现方式,但是总体的思路就是这么实现的,注意,设置的组一定要能够被注意力头数整除。
## 分组注意力查询
import torch
from torch import nn
class GroupQueryAttention(torch.nn.Module):def __init__(self, hidden_size, num_heads, group_num):super(MutiQueryAttention, self).__init__()self.num_heads = num_headsself.head_dim = hidden_size // num_headsself.group_num = group_num## 初始化Q、K、V投影矩阵self.q_linear = nn.Linear(hidden_size, hidden_size)self.k_linear = nn.Linear(hidden_size, self.group_num * self.head_dim)self.v_linear = nn.Linear(hidden_size, self.group_num * self.head_dim)## 输出线性层self.o_linear = nn.Linear(hidden_size, hidden_size)def forward(self, hidden_state, attention_mask=None):batch_size = hidden_state.size()[0]query = self.q_linear(hidden_state)key = self.k_linear(hidden_state)value = self.v_linear(hidden_state)query = self.split_head(query)key = self.split_head(key, self.group_num)value = self.split_head(value, self.group_num)## 计算注意力分数attention_scores = torch.matmul(query, key.transpose(-1, -2)) / torch.sqrt(torch.tensor(self.head_dim))if attention_mask != None:attention_scores += attention_mask * -1e-9## 对注意力分数进行归一化attention_probs = torch.softmax(attention_scores, dim=-1)output = torch.matmul(attention_probs, value)output = output.transpose(-1, -2).contiguous().view(batch_size, -1, self.head_dim * self.num_heads)output = self.o_linear(output)return outputdef split_head(self, x, group_num=None):batch_size,seq_len = x.size()[:2]if group_num == None:return x.view(batch_size, -1, self.num_heads, self.head_dim).transpose(1,2)else:x = x.view(batch_size, -1, group_num, self.head_dim).transpose(1,2)x = x[:, :, None, :, :].expand(batch_size, group_num, self.num_heads // group_num, seq_len, self.head_dim).reshape(batch_size, self.num_heads // group_num * group_num, seq_len, self.head_dim)return x
相关文章:
【大模型LLM面试合集】大语言模型架构_MHA_MQA_GQA
MHA_MQA_GQA 1.总结 在 MHA(Multi Head Attention) 中,每个头有自己单独的 key-value 对;标准的多头注意力机制,h个Query、Key 和 Value 矩阵。在 MQA(Multi Query Attention) 中只会有一组 k…...
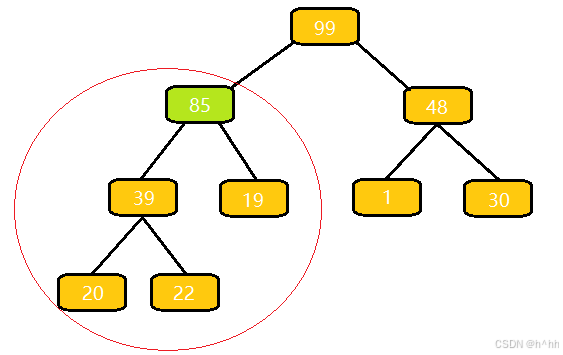
向上调整算法(详解)c++
算法流程: 与⽗结点的权值作⽐较,如果⽐它⼤,就与⽗亲交换; 交换完之后,重复 1 操作,直到⽐⽗亲⼩,或者换到根节点的位置 这里为什么插入85完后合法? 我们插入一个85,…...
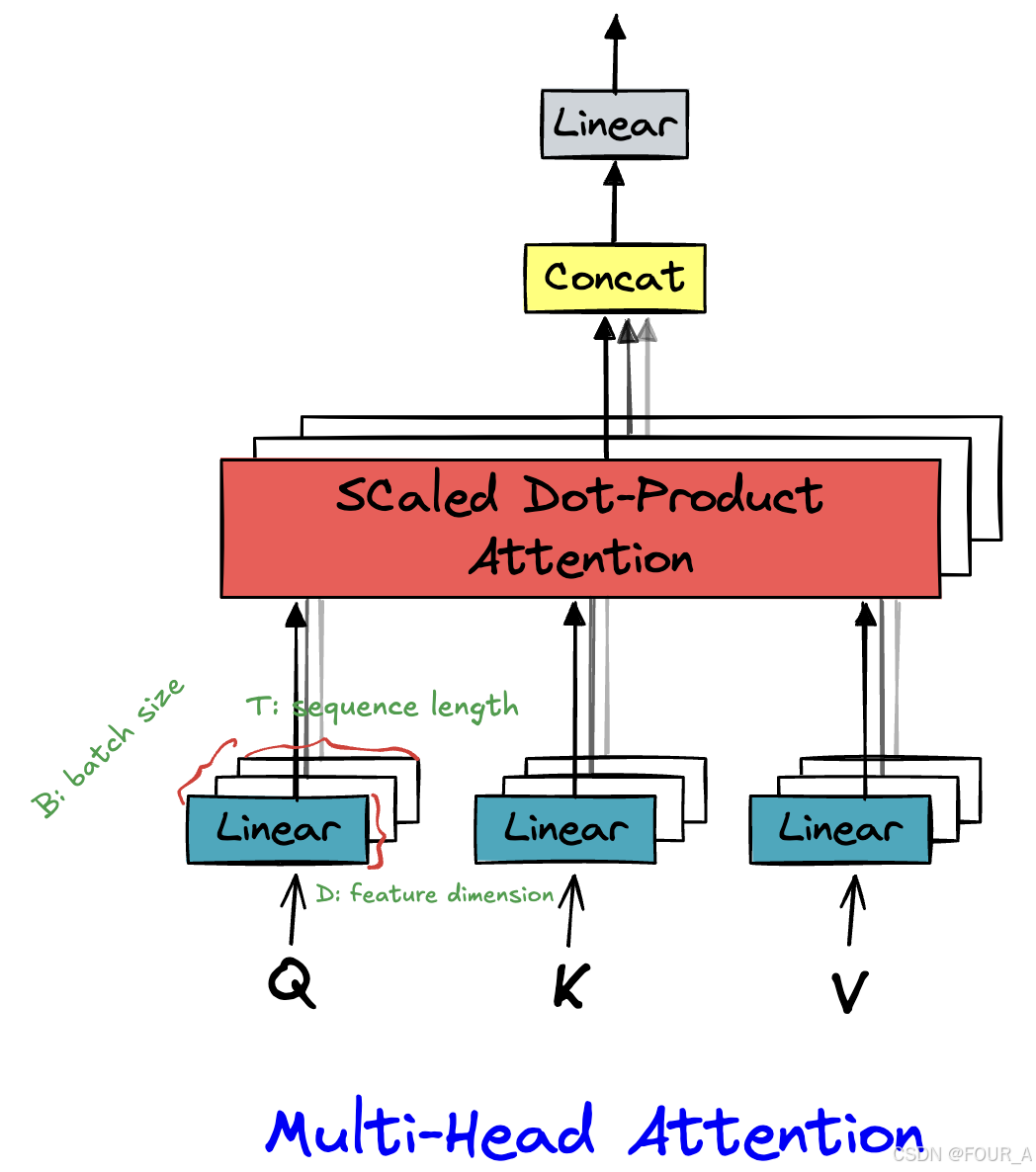
【Transformer】手撕Attention
import torch from torch import nn import torch.functional as F import mathX torch.randn(16,64,512) # B,T,Dd_model 512 # 模型的维度 n_head 8 # 注意力头的数量多头注意力机制 class multi_head_attention(nn.Module): def __init__(self, d_model, n_hea…...

844.比较含退格的字符串
目录 题目思路解法收获 题目 给定 s 和 t 两个字符串,当它们分别被输入到空白的文本编辑器后,如果两者相等,返回 true 。# 代表退格字符。 注意:如果对空文本输入退格字符,文本继续为空。 思路 如何解退格之后left…...

图书管理系统 Axios 源码__编辑图书
目录 功能概述: 代码实现(index.js): 代码解析: 图书管理系统中,删除图书功能是核心操作之一。下是基于 HTML、Bootstrap、JavaScript 和 Axios 实现的删除图书功能的详细介绍。 功能概述: …...
LabVIEW纤维集合体微电流测试仪
LabVIEW开发纤维集合体微电流测试仪。该设备精确测量纤维材料在特定电压下的电流变化,以分析纤维的结构、老化及回潮率等属性,对于纤维材料的科学研究及质量控制具有重要意义。 项目背景 在纤维材料的研究与应用中,电学性能是评估其性能…...

Commander 一款命令行自定义命令依赖
一、安装 commander 插件 npm install commander 二、基本用法 1. 创建一个简单的命令行程序 创建一个 JavaScript 文件,例如 mycli.js,并添加以下代码: // 引入 commander 模块并获取 program 对象。const { program } require("…...
)
Day24 洛谷普及2004(内涵前缀和与差分算法)
零基础洛谷刷题记录 Day01 2024.11.18 Day02 2024.11.25 Day03 2024.11.26 Day04 2024.11.28 Day05 2024.11.29 Day06 2024 12.02 Day07 2024.12.03 Day08 2024 12 05 Day09 2024.12.07 Day10 2024.12.09 Day11 2024.12.10 Day12 2024.12.12 Day13 2024.12.16 Day14 2024.12.1…...
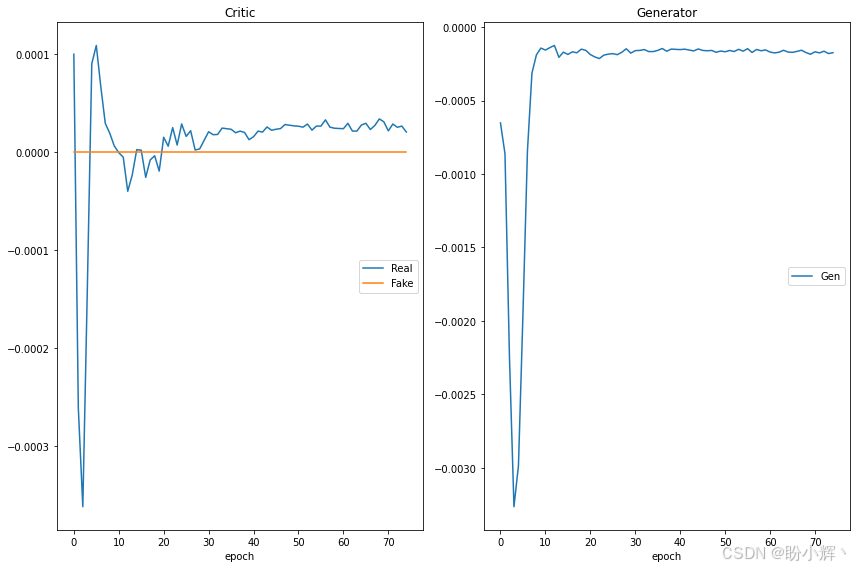
遗传算法与深度学习实战(33)——WGAN详解与实现
遗传算法与深度学习实战(33)——WGAN详解与实现 0. 前言1. 训练生成对抗网络的挑战2. GAN 优化问题2.1 梯度消失2.2 模式崩溃 2.3 无法收敛3 Wasserstein GAN3.1 Wasserstein 损失3.2 使用 Wasserstein 损失改进 DCGAN 小结系列链接 0. 前言 原始的生成…...
gitlab云服务器配置
目录 1、关闭防火墙 2、安装gitlab 3、修改配置 4、查看版本 GitLab终端常用命令 5、访问 1、关闭防火墙 firewall-cmd --state 检查防火墙状态 systemctl stop firewalld.service 停止防火墙 2、安装gitlab xftp中导入安装包 [rootgitlab ~]#mkdir -p /service/tool…...

SAP SD学习笔记27 - 请求计划(开票计划)之1 - 定期请求(定期开票)
上两章讲了贩卖契约(框架协议)的概要,以及贩卖契约中最为常用的 基本契约 - 数量契约和金额契约。 SAP SD学习笔记26 - 贩卖契约(框架协议)的概要,基本契约 - 数量契约_sap 框架协议-CSDN博客 SAP SD学习笔记27 - 贩卖契约(框架…...

HTML DOM 修改 HTML 内容
HTML DOM 修改 HTML 内容 引言 HTML DOM(文档对象模型)是浏览器内部用来解析和操作HTML文档的一种机制。通过DOM,我们可以轻松地修改HTML文档的结构、样式和行为。本文将详细介绍如何使用HTML DOM来修改HTML内容,包括元素的增删改查、属性修改以及事件处理等。 1. HTML …...

基于VMware的ubuntu与vscode建立ssh连接
1.首先安装openssh服务 sudo apt update sudo apt install openssh-server -y 2.启动并检查ssh服务状态 到这里可以按q退出 之后输入命令 : ip a 红色挡住的部分就是我们要的地址,这里就不展示了哈 3.配置vscode 打开vscode 搜索并安装:…...
Flutter Candies 一桶天下
| | | | | | | | 入魔的冬瓜 最近刚入桶的兄弟,有责任心的开发者,对自己的项目会不断进行优化,达到最完美的状态 自定义日历组件 主要功能 支持公历,农历,节气,传统节日,常用节假日 …...

maven如何不把依赖的jar打包到同一个jar?
spring boot项目打jar包部署: 经过以下步骤, 最终会形成maven依赖的多个jar(包括lib下添加的)、 我们编写的程序代码打成一个jar,将程序jar与 依赖jar分开,便于管理: success: 最终…...

HTML5 技术深度解读:本地存储与地理定位的最佳实践
系列文章目录 01-从零开始学 HTML:构建网页的基本框架与技巧 02-HTML常见文本标签解析:从基础到进阶的全面指南 03-HTML从入门到精通:链接与图像标签全解析 04-HTML 列表标签全解析:无序与有序列表的深度应用 05-HTML表格标签全面…...

AIGC技术中常提到的 “嵌入转换到同一个向量空间中”该如何理解
在AIGC(人工智能生成内容)技术中,“嵌入转换到同一个向量空间中”是一个核心概念,其主要目的是将不同类型的输入数据(如文本、图像、音频等)映射到一个统一的连续向量空间中,从而实现数据之间的…...

【机器学习理论】朴素贝叶斯网络
基础知识: 先验概率:对某个事件发生的概率的估计。可以是基于历史数据的估计,可以由专家知识得出等等。一般是单独事件概率。 后验概率:指某件事已经发生,计算事情发生是由某个因素引起的概率。一般是一个条件概率。 …...
)
Docker 部署 GLPI(IT 资产管理软件系统)
GLPI 简介 GLPI open source tool to manage Helpdesk and IT assets GLPI stands for Gestionnaire Libre de Parc Informatique(法语 资讯设备自由软件 的缩写) is a Free Asset and IT Management Software package, that provides ITIL Service De…...

【Vaadin flow 实战】第5讲-使用常用UI组件绘制页面元素
vaadin flow官方提供的UI组件文档地址是 https://vaadin.com/docs/latest/components这里,我简单实战了官方提供的一些免费的UI组件,使用案例如下: Accordion 手风琴 Accordion 手风琴效果组件 Accordion 手风琴-测试案例代码 Slf4j PageT…...
)
别再依赖SDK了!手把手教你用OpenCV和Eigen从零实现RGB-D相机对齐(附完整C++代码)
从零实现RGB-D相机对齐:OpenCV与Eigen实战指南 在计算机视觉领域,RGB-D相机的深度与彩色图像对齐(D2C)是一个基础但至关重要的技术环节。虽然市面上大多数商用RGB-D相机都提供了现成的SDK和API来实现这一功能,但对于真…...

如何免费下载百度文库文档:三步搞定PDF保存的终极指南
如何免费下载百度文库文档:三步搞定PDF保存的终极指南 【免费下载链接】baidu-wenku fetch the document for free 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wenku 你是否经常在百度文库找到完美的学习资料或工作报告,却因为需要下载券…...
)
告别Demo!用EMQX和Java模拟真实物联网设备上报数据流(Windows本地开发环境)
告别Demo!用EMQX和Java构建真实物联网数据流模拟方案 在物联网开发中,最令人头疼的莫过于缺乏真实设备进行测试。想象一下,当你精心设计的平台等待设备接入时,硬件团队却告诉你"下周才能交付原型机"。这种等待不仅拖延进…...

5步实现AutoHotkey脚本独立运行:Ahk2Exe编译实战指南
5步实现AutoHotkey脚本独立运行:Ahk2Exe编译实战指南 【免费下载链接】Ahk2Exe Official AutoHotkey script compiler - written itself in AutoHotkey 项目地址: https://gitcode.com/gh_mirrors/ah/Ahk2Exe 你是否遇到过这样的困扰?精心编写的A…...

轻量级工作流引擎pro-workflow:Go语言实现与实战解析
1. 项目概述:一个为专业开发者量身打造的工作流引擎如果你是一名开发者,尤其是经常需要处理复杂业务逻辑、数据流转或自动化任务的后端或全栈工程师,那么你一定对“工作流”这个概念不陌生。从简单的审批流到复杂的微服务编排,工作…...

Windows上运行Swift代码的三种实战路径
1. 为什么Windows开发者需要Swift? Swift作为苹果生态的主力编程语言,近年来在服务端开发、机器学习等领域的应用越来越广泛。但很多刚接触Swift的Windows开发者会发现:官方文档里压根没提Windows支持!这其实是因为Swift最初就是…...

Lingoose:轻量级LLM编排框架的设计哲学与工程实践
1. 项目概述:从“Lingo”到“Goose”,一个轻量级LLM编排框架的诞生最近在折腾大语言模型应用开发的朋友,估计都绕不开一个核心问题:如何高效、优雅地编排和串联多个LLM调用、工具调用以及数据处理流程?当你从简单的单次…...

Oracle数据库触发器概述
Oracle数据库触发器概述触发器介绍数据库触发器是一个 已编译的存储程序单元 ,使用 PL/SQL 或 Java 编写。 触发器是模式对象,类似于子程序;但其调用方法不同。 子程序由用户、应用程序、或触发器显式运行。而触发器是在触发的事件发生时由 数…...

MPLAB代码配置器实战:图形化配置PIC/AVR单片机外设,提升开发效率
1. 项目概述:为什么你需要关注MPLAB代码配置器如果你正在使用Microchip的PIC或AVR单片机,并且还在手动编写外设初始化代码、一遍遍翻阅数据手册核对寄存器位,那今天聊的这个工具,可能会让你有种“相见恨晚”的感觉。我说的就是MPL…...

Sophia优化器:二阶曲率感知如何加速大模型训练与调参
1. 项目概述:当优化器遇上“二阶”智慧最近在复现一些前沿的论文实验时,我又一次被优化器的选择给卡住了。AdamW虽然稳,但在某些超大规模模型或特定任务上,总觉得收敛速度不够快,调参又是个玄学。就在我对着损失曲线发…...