AIGC技术中常提到的 “嵌入转换到同一个向量空间中”该如何理解
在AIGC(人工智能生成内容)技术中,“嵌入转换到同一个向量空间中”是一个核心概念,其主要目的是将不同类型的输入数据(如文本、图像、音频等)映射到一个统一的连续向量空间中,从而实现数据之间的语义和结构信息的统一表示。这一过程通过嵌入技术完成,具体解释如下:
1. 嵌入的基本定义
嵌入是一种将高维、离散的数据(如单词、短语、句子或图像)映射到低维连续向量空间的技术。这些向量被称为“嵌入向量”或“嵌入表示”,它们能够捕捉数据的语义和关系,并在新的向量空间中以数学形式表示。
2. 嵌入的作用
嵌入的主要作用是:
- 语义表示:通过将数据映射到向量空间,使得相似的数据点在向量空间中彼此靠近,从而反映它们之间的语义关系。例如,在自然语言处理(NLP)中,语义相近的单词会被映射到向量空间中相近的位置。
- 简化计算:将复杂的高维数据转换为低维向量,便于后续的机器学习和深度学习任务,如分类、聚类和相似性计算。
- 通用性:嵌入技术可以应用于多种数据类型,包括文本、图像、音频等,使其能够被统一处理和分析。
3. 嵌入转换到同一个向量空间的意义
在AIGC技术中,不同类型的输入数据(如文本、图像、音频等)通常需要被转换为统一的向量表示,以便进行联合分析或生成。例如:
-
文本嵌入:将文本数据转换为向量表示,捕捉其语法和语义信息。

-
图像嵌入:将图像特征提取为向量,用于图像分类或检索。
-
音频嵌入:将音频信号转换为向量表示,用于语音识别或情感分析。
通过嵌入技术,这些不同模态的数据被映射到同一个向量空间中,从而实现跨模态的统一表示。这种统一性使得模型能够更高效地处理和理解多模态数据之间的关系,进而生成更加丰富和精准的内容。
4. 嵌入技术的应用场景
嵌入技术广泛应用于以下领域:
- 自然语言处理(NLP) :如Word2Vec、GloVe等模型用于生成单词或短语的嵌入向量,捕捉其语义关系。
- 计算机视觉(CV) :如ResNet模型用于图像特征提取,生成图像的嵌入向量。
- 多模态学习:如将文本、图像和音频数据嵌入到同一个向量空间中,用于联合分析和生成任务。
5. 技术实现
嵌入技术通常通过以下步骤实现:
- 预处理:对输入数据进行标准化或归一化处理。
- 编码器网络:使用神经网络(如Transformer、CNN等)将输入数据转换为嵌入向量。
- 降维:通过矩阵运算或其他方法将高维数据压缩为低维向量。


总结
“AIGC技术中常提到的‘嵌入转换到同一个向量空间中’”是指通过嵌入技术将不同类型的输入数据(如文本、图像、音频等)映射到一个统一的连续向量空间中。这一过程不仅能够捕捉数据的语义和结构信息,还能实现跨模态的统一表示,从而为后续的生成任务提供有效的支持。
嵌入技术在跨模态数据统一表示中的具体实现方法是什么?
嵌入技术在跨模态数据统一表示中的具体实现方法主要涉及将不同模态的数据映射到共享的语义空间中,从而实现跨模态的统一表示和关联操作。以下是嵌入技术在跨模态数据统一表示中的具体实现方法:
1. 联合嵌入(Joint Embedding)
联合嵌入是一种将多模态数据共同输入到模型中进行嵌入训练的方法。这种方法通过联合优化不同模态的表示,使得它们能够共享一个统一的语义空间。例如,CLIP(Contrastive Language-Image Pre-training)模型通过对比学习将图像和文本嵌入对齐,从而实现跨模态的统一表示。
2. 对齐嵌入(Align Embedding)
对齐嵌入针对每种模态分别进行嵌入训练,然后通过后续的对齐策略(如注意力机制)使不同模态的表示在语义空间中保持一致。这种方法强调了不同模态之间的相似性和一致性。
3. 编码器-解码器架构
编码器-解码器架构通过使用多个编码器对不同模态的数据进行编码,然后通过解码器生成统一的表示。这种方法可以有效处理不同模态之间的差异性,并通过优化公共空间中的输出来实现跨模态对齐。
4. 对比学习
对比学习是一种通过最大化同一数据点在不同模态中的表示相似性,同时最小化不同数据点表示相似性的方法。例如,OpenAI提出的CLIP模型通过大规模图文数据训练,将图像和文本嵌入到共享空间中,从而实现跨模态的理解和检索。
5. 映射与联合学习
映射方法通过学习从一种模态到另一种模态的映射函数,将不同模态的数据映射到共享空间中。联合学习则同时优化单模态质量和跨模态对齐,通过联合过程找到最佳的表示。
6. 投影+正则化约束
一些模型通过投影矩阵和正则化约束将图像和文本数据映射到共享空间中。例如,Cross-modal Embedding Consensus模型使用投影矩阵将图像和文本映射到共享空间,并通过正则化约束确保投影后的表示在不同模态之间保持一致。
7. 两阶段方法
两阶段方法首先对不同模态的数据进行独立编码(如卷积神经网络处理图像,Word2Vec处理文本),然后通过神经网络学习映射关系,将不同模态的数据映射到潜在空间中。这种方法通过精心设计的损失函数来保持不同模态之间的关联性。
8. 多模态融合
多模态融合通过连接已有的知识表示并应用降维技术(如PCA或SVD)来减少维度,从而得到低维表示。这些低维表示可以用于进一步的分析或建模。
9. Transformer模型
Transformer模型通过输入结构化数据(如文本、图像和语言嵌入),将其整合为统一的表示形式。例如,Transformer模型可以处理位置编码、语言/模态嵌入等,从而生成跨模态的统一表示。
10. 无监督嵌入预测
无监督嵌入预测方法通过预测输入数据的嵌入表示来实现跨模态任务的统一处理。例如,PredNet-5模型通过LSTM层提取特征并输出跨模态相似度预测结果。
总结
嵌入技术在跨模态数据统一表示中的实现方法多种多样,包括联合嵌入、对齐嵌入、编码器-解码器架构、对比学习、映射与联合学习、投影+正则化约束、两阶段方法、多模态融合以及Transformer模型等。
嵌入技术在实际应用中面临的主要挑战和限制有哪些?
多模态学习中嵌入技术的具体应用场景包括哪些?
多模态学习中嵌入技术的具体应用场景非常广泛,涵盖了多个领域和任务。以下是基于我搜索到的资料总结出的一些具体应用场景:
-
图像识别与处理
多模态嵌入技术在图像识别中被广泛应用。例如,通过结合视觉特征和语言特征,可以实现更高效的图像分类、目标检测和分割任务。这种技术利用了深度学习模型(如ResNet)的特性,通过嵌入技术提升模型的性能。 -
文本到图像生成
在文本到图像生成任务中,多模态嵌入技术通过将文本描述转化为图像特征,实现了从文本到图像的生成。例如,CLIP模型通过对比学习训练,将图像和文本嵌入到同一表示空间中,从而实现跨模态的生成任务。 -
视频分析与理解
视频分析是多模态学习的重要应用之一。多模态嵌入技术能够同时处理视频中的视觉信息和音频信息,用于视频分类、行为识别和字幕生成等任务。例如,CNN-RNN架构结合了卷积神经网络和循环神经网络,用于视频描述任务。 -
跨模态检索与问答系统
多模态嵌入技术在跨模态检索和问答系统中也有重要应用。例如,nomic-embed-vision-v1模型结合Ollama模型,实现了图像搜索与问答系统。通过将图像和文本统一表示为嵌入向量,可以实现高效的图像搜索和问题回答。 -
零样本学习与跨模态任务
在零样本学习任务中,多模态嵌入技术通过统一模态表示空间几何结构,解决了模态间的“模态差距”。例如,C3方法通过改进嵌入技术,在图像、音频和视频字幕生成任务中取得了显著效果。 -
动态图嵌入与推荐系统
动态图嵌入方法(如Node2Vec、GraphSAGE)在推荐系统中得到了应用。这些方法通过捕捉节点之间的动态关系,提升了推荐系统的性能。 -
医学与法律领域嵌入
多模态嵌入技术还可以应用于特定领域的创新应用,例如医学嵌入和法律嵌入。这些领域需要结合文本、图像和其他模态数据,以提高诊断或法律分析的准确性。 -
小样本学习与自动化生产
小样本学习结合多模态嵌入技术,可以在数据量有限的情况下实现高效的学习和模型优化。此外,自动化机器学习(AutoML)框架通过嵌入技术优化特征工程和模型构建过程,提高了生产效率。 -
跨模态融合与优化
多模态嵌入技术还被用于跨模态融合和优化任务。例如,在多模态元学习框架中,通过融合不同模态的信息来提升模型性能。
多模态嵌入技术的应用场景非常广泛,涵盖了从基础研究到实际工业应用的多个领域。
如何评估嵌入技术在不同模态数据转换中的效果和准确性?
评估嵌入技术在不同模态数据转换中的效果和准确性,可以从以下几个方面进行详细分析:
1. 嵌入技术的基本原理与方法
嵌入技术的核心思想是将来自不同模态的数据(如文本、图像、语音等)映射到一个共享的向量空间中,从而实现跨模态的相似性或差异性建模。常见的嵌入方法包括联合嵌入(Joint Embedding)和对齐嵌入(Aligned Embedding)。联合嵌入通过将多模态数据共同输入到模型中,利用对比学习(如CLIP)来实现图像和文本的嵌入;而对齐嵌入则分别对每种模态进行嵌入训练,再通过策略(如注意力机制)使模态间表示一致。
2. 评估指标与基准测试
为了全面评估嵌入技术的效果和准确性,可以使用多种基准测试任务,这些任务覆盖了语义相似度、跨模态检索和零样本学习等多个应用场景。例如,MTEB(Multimodal Embedding Benchmark)是一个开源平台,提供了丰富的基准测试任务,包括语义相似度、跨模态检索和零样本学习等,能够帮助评估模型在不同模态数据转换中的表现。
3. 性能指标与实验结果
在具体实验中,性能指标通常包括准确率(Accuracy)、F1分数(F1 Score)以及收敛周期数等。例如,在医学数据集BRSET、HAM10000和SatelliteB上,使用Dino v2 + Llama 2和原始CLIP进行早期融合和联合融合的方法分别达到了0.987和0.994的F1分数,并在第四个周期后收敛。这些实验结果表明,基于嵌入的方法在低资源场景下仍能实现高效的性能提升。
4. 技术方案与应用实例
在实际应用中,深度学习技术被广泛用于多模态嵌入模型的构建。例如:
- 视觉语义嵌入(Visual Semantic Embedding, VSE) :通过将图像的视觉信息和文本的语义信息映射到同一空间,用于比较相似度。
- 图像标注(Image Captioning) :生成图像描述,用于比较原始文本和生成描述的相似度。
- 区域与文本对应(Region-to-Text Mapping) :将图像区域与文本短语对应,用于目标检测和语义分割。
- 对比学习(Contrastive Learning) :通过训练区分正样本和负样本,拉近匹配图片和文本对的距离,提高准确性。
5. 跨模态数据转换中的挑战与解决方案
跨模态数据转换面临的主要挑战包括模态间的差异性、特征分布的不同以及计算资源的限制。为了解决这些问题,可以采用以下方法:
- 特征提取与匹配:使用SURF特征提取器等工具提取图像特征,并结合词汇表进行匹配。
- 正则化损失:通过引入额外的正则化损失(如嵌入对齐损失),缩小模态间的差距。
- 多模态对齐:通过对比学习或其他策略使不同模态的表示更加一致。
6. 未来发展方向
随着深度学习技术的发展,嵌入技术在多模态数据转换中的应用前景广阔。未来的研究可以进一步探索以下方向:
- 更高效的模型架构:如Transformer和BERT等模型在多模态任务中的表现。
- 低资源场景下的优化:如何在计算资源有限的情况下保持模型性能。
- 跨模态检索与生成:如何更好地实现跨模态检索和生成任务,提高用户体验。
综上所述,评估嵌入技术在不同模态数据转换中的效果和准确性需要结合具体的实验设计、性能指标以及实际应用场景。
嵌入技术在处理大规模数据集时的性能优化策略有哪些?
嵌入技术在处理大规模数据集时的性能优化策略可以从多个方面进行探讨,包括算法优化、硬件加速、数据结构设计以及模型架构改进等。以下是基于我搜索到的资料总结出的几种主要策略:
1. 算法优化
- 随机插入和缓存策略:在大规模数据集嵌入过程中,通过随机插入和缓存策略可以显著提高嵌入效率。例如,HPS(GPU嵌入式搜索)通过这些策略在Criteo 1TB数据集上实现了比PyTorch CPU更快的性能,同时大幅减少了内存占用。
- 二进制搜索向量技术:通过将浮点数(fp32)替换为单个0或1,并结合KNN聚类器和重排序器,可以在保持性能的同时大幅缩小内存需求,这为大规模数据集的处理提供了新的解决方案。
2. 硬件加速
- GPU和CAM嵌入加速:GPU嵌入式搜索(如HPS)在大规模数据集上的表现优于CPU实现,尤其是在单GPU环境下,其吞吐量和延迟均优于PyTorch CPU实现。此外,CAM(Content Addressable Memory)嵌入技术在多核系统中表现出色,比多核系统快2.16倍至389.51倍。
- 新兴硬件技术:利用新兴硬件如CAM和MRAM ReRAM等,可以进一步加速计算并支持稠密存储,从而提升大规模数据处理的效率。
3. 数据结构优化
- 稀疏向量与位图:通过使用稀疏向量和位图来存储和操作大规模数据,可以有效减少内存占用并提高计算效率。
- 压缩与筛法:利用压缩技术和筛法对大规模数据进行预处理,可以降低数据规模并提高后续处理的速度。
4. 模型架构改进
- Transformer架构优化:Transformer模型通过多查询注意力、稀疏注意力等机制提升了性能和效率。这些改进特别适用于处理大规模数据集。
- 词嵌入算法优化:Word2vec算法的改进版本(如CBOW和Skip-gram)在处理大规模数据集时表现更佳。CBOW适合大样本数据,而Skip-gram更适合小样本。
5. 分布式计算与并行处理
- 多核处理器与并行计算:结合多核处理器的并行计算能力可以显著提升数据处理速度。例如,在HDC计算中,多核执行模式比单核模式快得多。
- 分布式系统集成:例如,ClickHouse支持高效的数据导入和实时分析,适合大规模数据集的处理。
6. 嵌入模型的高效存储与加载
- Snowflake嵌入模型:Snowflake通过与LangChain集成,支持高效存储和加载嵌入模型。其arctic-embedding模型采用马氏距离优化向量截断,提升了处理速度。
总结
嵌入技术在处理大规模数据集时的性能优化策略涵盖了从算法优化、硬件加速到数据结构设计等多个层面。这些策略可以根据具体的应用场景和技术需求灵活选择和组合,以实现最佳的性能表现。例如,在需要高效内存管理和快速搜索的场景中,GPU嵌入式搜索和CAM嵌入技术是理想选择;
相关文章:
AIGC技术中常提到的 “嵌入转换到同一个向量空间中”该如何理解
在AIGC(人工智能生成内容)技术中,“嵌入转换到同一个向量空间中”是一个核心概念,其主要目的是将不同类型的输入数据(如文本、图像、音频等)映射到一个统一的连续向量空间中,从而实现数据之间的…...

【机器学习理论】朴素贝叶斯网络
基础知识: 先验概率:对某个事件发生的概率的估计。可以是基于历史数据的估计,可以由专家知识得出等等。一般是单独事件概率。 后验概率:指某件事已经发生,计算事情发生是由某个因素引起的概率。一般是一个条件概率。 …...
)
Docker 部署 GLPI(IT 资产管理软件系统)
GLPI 简介 GLPI open source tool to manage Helpdesk and IT assets GLPI stands for Gestionnaire Libre de Parc Informatique(法语 资讯设备自由软件 的缩写) is a Free Asset and IT Management Software package, that provides ITIL Service De…...

【Vaadin flow 实战】第5讲-使用常用UI组件绘制页面元素
vaadin flow官方提供的UI组件文档地址是 https://vaadin.com/docs/latest/components这里,我简单实战了官方提供的一些免费的UI组件,使用案例如下: Accordion 手风琴 Accordion 手风琴效果组件 Accordion 手风琴-测试案例代码 Slf4j PageT…...

强化学习 DAY1:什么是 RL、马尔科夫决策、贝尔曼方程
第一部分 RL基础:什么是RL与MRP、MDP 1.1 入门强化学习所需掌握的基本概念 1.1.1 什么是强化学习:依据策略执行动作-感知状态-得到奖励 强化学习里面的概念、公式,相比ML/DL特别多,初学者刚学RL时,很容易被接连不断…...
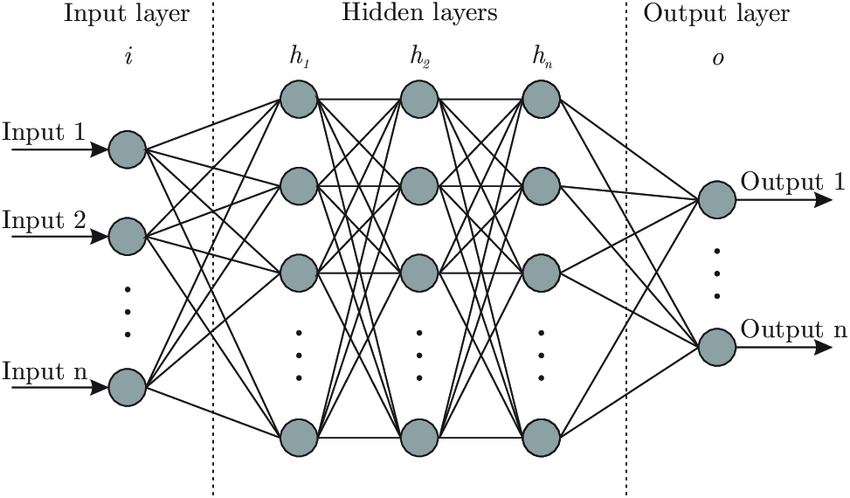
理解神经网络:Brain.js 背后的核心思想
温馨提示 这篇文章篇幅较长,主要是为后续内容做铺垫和说明。如果你觉得文字太多,可以: 先收藏,等后面文章遇到不懂的地方再回来查阅。直接跳读,重点关注加粗或高亮的部分。放心,这种“文字轰炸”不会常有的,哈哈~ 感谢你的耐心阅读!😊 欢迎来到 brain.js 的学习之旅!…...

【Docker】dockerfile识别当前构建的镜像平台
在编写dockerfile的时候,可能会遇到需要针对不同平台进行不同操作的时候,这需要我们对dockerfile进行针对性修改。 比如opencv的依赖项libjasper-dev在ubuntu18.04上就需要根据不同的平台做不同的处理,关于这个库的安装在另外一篇博客里面有…...
【VM】VirtualBox安装CentOS8虚拟机
阅读本文前,请先根据 VirtualBox软件安装教程 安装VirtualBox虚拟机软件。 1. 下载centos8系统iso镜像 可以去两个地方下载,推荐跟随本文的操作用阿里云的镜像 centos官网:https://www.centos.org/download/阿里云镜像:http://…...
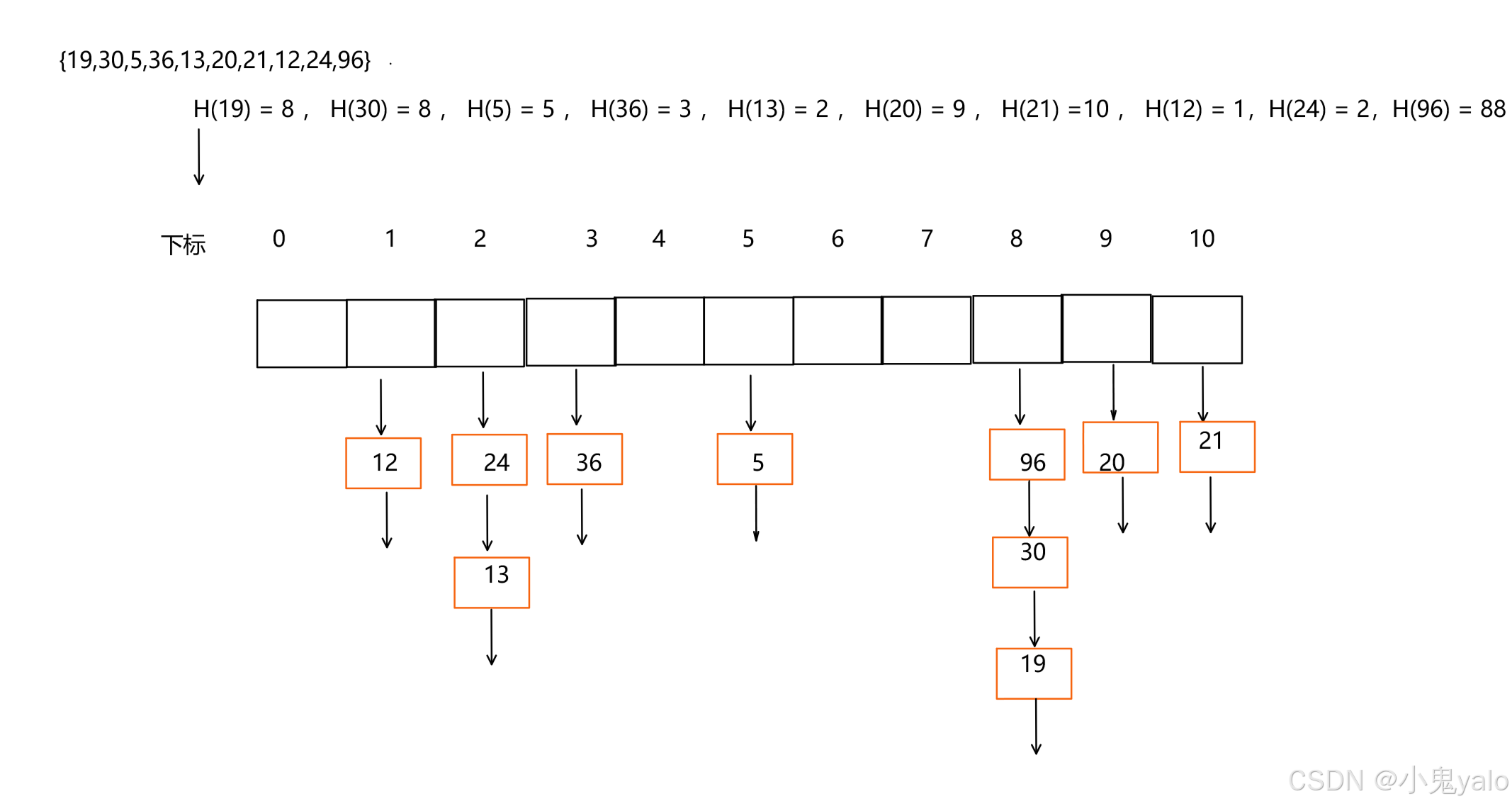
【C++篇】哈希表
目录 一,哈希概念 1.1,直接定址法 1.2,哈希冲突 1.3,负载因子 二,哈希函数 2.1,除法散列法 /除留余数法 2.2,乘法散列法 2.3,全域散列法 三,处理哈希冲突 3.1&…...

Java篇之继承
目录 一. 继承 1. 为什么需要继承 2. 继承的概念 3. 继承的语法 4. 访问父类成员 4.1 子类中访问父类的成员变量 4.2 子类中访问父类的成员方法 5. super关键字 6. super和this关键字 7. 子类构造方法 8. 代码块的执行顺序 9. protected访问修饰限定符 10. 继承方式…...

边缘检测算法(candy)
人工智能例子汇总:AI常见的算法和例子-CSDN博客 Canny 边缘检测的步骤 1. 灰度转换 如果输入的是彩色图像,则需要先转换为 灰度图像,因为边缘检测通常在单通道图像上进行。 2. 高斯滤波(Gaussian Blur) 由于边缘…...

设计模式Python版 组合模式
文章目录 前言一、组合模式二、组合模式实现方式三、组合模式示例四、组合模式在Django中的应用 前言 GOF设计模式分三大类: 创建型模式:关注对象的创建过程,包括单例模式、简单工厂模式、工厂方法模式、抽象工厂模式、原型模式和建造者模式…...
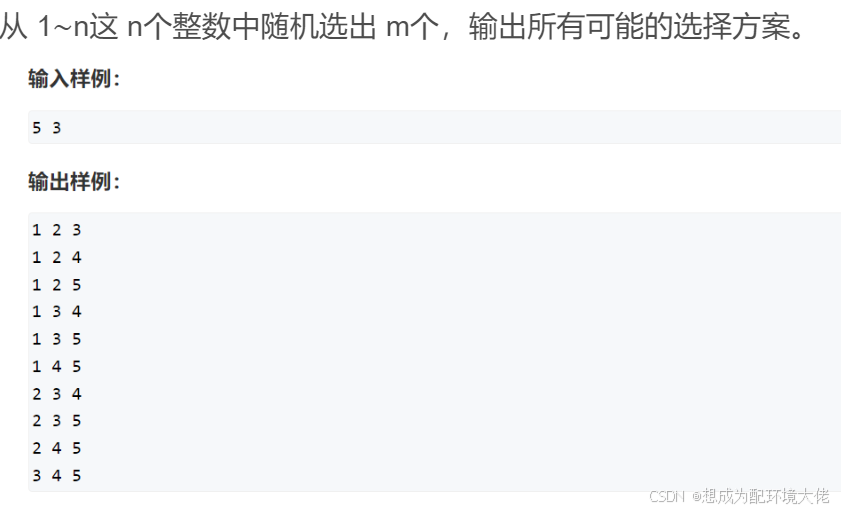
dfs枚举问题
碎碎念:要开始刷算法题备战蓝桥杯了,一切的开头一定是dfs 定义 枚举问题就是咱数学上学到的,从n个数里面选m个数,有三种题型(来自Acwing) 从 1∼n 这 n个整数中随机选取任意多个,输出所有可能的选择方案。 把 1∼n这…...
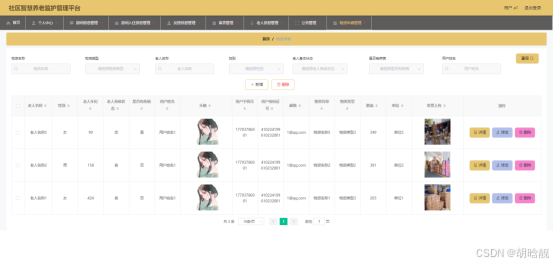
【开源免费】基于SpringBoot+Vue.JS社区智慧养老监护管理平台(JAVA毕业设计)
本文项目编号 T 163 ,文末自助获取源码 \color{red}{T163,文末自助获取源码} T163,文末自助获取源码 目录 一、系统介绍二、数据库设计三、配套教程3.1 启动教程3.2 讲解视频3.3 二次开发教程 四、功能截图五、文案资料5.1 选题背景5.2 国内…...
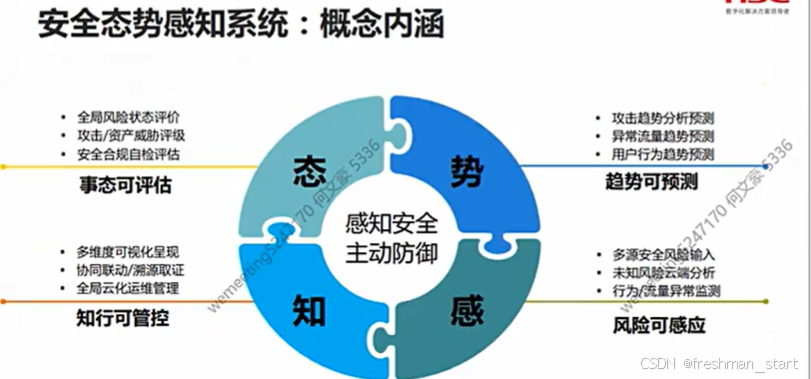
安全防护前置
就业概述 网络安全工程师/安全运维工程师/安全工程师 安全架构师/安全专员/研究院(数学要好) 厂商工程师(售前/售后) 系统集成工程师(所有计算机知识都要会一点) 学习目标 前言 网络安全事件 蠕虫病毒--&…...
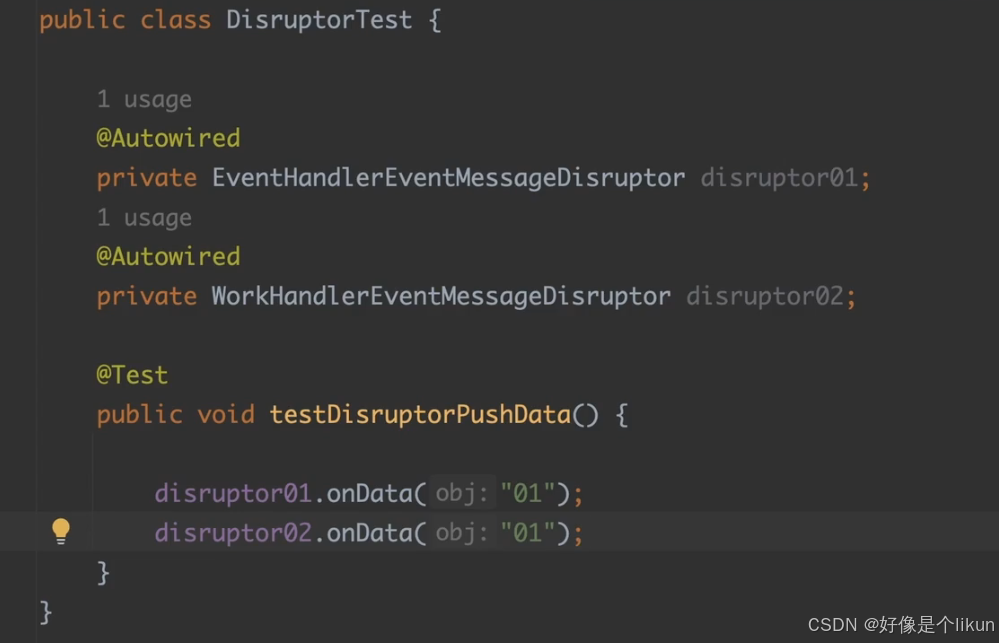
高性能消息队列Disruptor
定义一个事件模型 之后创建一个java类来使用这个数据模型。 /* <h1>事件模型工程类,用于生产事件消息</h1> */ no usages public class EventMessageFactory implements EventFactory<EventMessage> { Overridepublic EventMessage newInstance(…...

kamailio中的sctp模块
以下是关于 Kamailio 配置中 enable_sctpno 的详细解释: 1. 参数作用 enable_sctp: 该参数用于控制 Kamailio 是否启用 SCTP(Stream Control Transmission Protocol) 协议支持。 设置为 yes:启用 SCTP,并加…...
)
前端学习-事件解绑,mouseover和mouseenter的区别(二十九)
目录 前言 解绑事件 语法 鼠标经过事件的区别 鼠标经过事件 示例代码 两种注册事件的区别 总结 前言 人道洛阳花似锦,偏我来时不逢春 解绑事件 on事件方式,直接使用null覆盖就可以实现事件的解绑 语法 btn.onclick function(){alert(点击了…...

独立游戏RPG回顾:高成本
刚看了某纪录片, 内容是rpg项目的回顾。也是这个以钱为核心话题的系列的最后一集。 对这期特别有代入感,因为主角是曾经的同事,曾经在某天晚上听过其项目组的争论。 对其这些年的起伏特别的能体会。 主角是制作人,在访谈中透露这…...

10.4 LangChain核心架构揭秘:模块化设计如何重塑大模型应用开发?
LangChain核心架构揭秘:模块化设计如何重塑大模型应用开发? 关键词: LangChain模块化设计、大模型开发框架、LangChain核心概念、AI应用开发、LLM工程化 一、LangChain的模块化设计哲学:从“手工作坊”到“工业化生产” 传统开发痛点: 代码重复:每个项目从零开始编写胶…...

开源监控面板OpenClaw:从架构设计到生产部署实战指南
1. 项目概述:一个开源监控面板的诞生 在运维和开发的世界里,监控面板就像是驾驶舱里的仪表盘。没有它,你就是在盲飞。今天要聊的这个项目 xingrz/openclaw-dashboard ,就是一个由社区驱动的开源监控面板解决方案。它的名字很有意…...

终极免费离线OCR解决方案:Umi-OCR完整使用指南
终极免费离线OCR解决方案:Umi-OCR完整使用指南 【免费下载链接】Umi-OCR OCR software, free and offline. 开源、免费的离线OCR软件。支持截屏/批量导入图片,PDF文档识别,排除水印/页眉页脚,扫描/生成二维码。内置多国语言库。 …...

Steam Achievement Manager完整指南:快速解决游戏成就难题的终极工具
Steam Achievement Manager完整指南:快速解决游戏成就难题的终极工具 【免费下载链接】SteamAchievementManager A manager for game achievements in Steam. 项目地址: https://gitcode.com/gh_mirrors/st/SteamAchievementManager 核心关键词:S…...

m4s-converter终极指南:如何无损转换B站缓存视频并保留弹幕
m4s-converter终极指南:如何无损转换B站缓存视频并保留弹幕 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 在数字内容日益丰富的今天…...

LLM应用快速演示框架:从架构解析到智能体开发的实战指南
1. 项目概述:一个面向开发者的LLM应用快速演示框架最近在GitHub上闲逛,发现了一个名为wronai/llm-demo的项目,点进去一看,瞬间觉得眼前一亮。这可不是又一个简单的“Hello World”式的大语言模型调用示例,而是一个结构…...

3步强力清理:Pearcleaner让你轻松解决Mac应用残留文件问题
3步强力清理:Pearcleaner让你轻松解决Mac应用残留文件问题 【免费下载链接】Pearcleaner A free, source-available and fair-code licensed mac app cleaner 项目地址: https://gitcode.com/gh_mirrors/pe/Pearcleaner 你是否曾删除Mac应用后,发…...

基于Taotoken统一API开发支持多模型切换的智能对话应用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 基于Taotoken统一API开发支持多模型切换的智能对话应用 应用场景类,场景是开发一个需要支持用户自由选择或系统自动切换…...

Mantic.sh:AI驱动的智能命令行工具,让自然语言生成终端命令
1. 项目概述:一个为开发者打造的智能终端伴侣 如果你和我一样,每天有超过一半的工作时间是在终端(Terminal)里度过的,那你一定对效率有着近乎偏执的追求。敲命令、查日志、管理进程、部署服务……这些重复且琐碎的操作…...

认识Python数据包套接字
如你所知,数据包格式套接字(Datagram Sockets)也叫“无连接的套接字”,在代码中使用 SOCK_DGRAM 表示。可以将 SOCK_DGRAM 比喻成高速移动的摩托车快递,它有以下特征:强调快速传输而非传输顺序;…...

RTKLIB 2.4.3项目在Visual Studio 2019中的工程化配置:告别零散文件,打造清晰结构
RTKLIB 2.4.3项目在Visual Studio 2019中的工程化配置:告别零散文件,打造清晰结构 对于卫星导航领域的开发者而言,RTKLIB无疑是一个绕不开的开源项目。这个由日本学者Tomoji Takasu开发的GNSS定位软件,以其强大的功能和开放的架构…...