强化学习 DAY1:什么是 RL、马尔科夫决策、贝尔曼方程
第一部分 RL基础:什么是RL与MRP、MDP
1.1 入门强化学习所需掌握的基本概念
1.1.1 什么是强化学习:依据策略执行动作-感知状态-得到奖励
强化学习里面的概念、公式,相比ML/DL特别多,初学者刚学RL时,很容易被接连不断的概念、公式给绕晕,而且经常忘记概念与公式符号表达的一一对应。
为此,学习RL的第一步就是一定要扎实关于RL的一些最基本的概念、公式(不要在扎实基础的阶段图快或图囵吞枣,不然后面得花更多的时间、更大的代价去弥补),且把概念与公式的一一对应关系牢记于心,这很重要。
下面进入正题,且先直接给出强化学习的定义和其流程,然后再逐一拆解、说明。
所谓强化学习(Reinforcement Learning,简称RL),是指基于智能体在复杂、不确定的环境中最大化它能获得的奖励,从而达到自主决策的目的。
经典的强化学习模型可以总结为下图的形式(你可以理解为任何强化学习都包含这几个基本部分:智能体、行为、环境、状态、奖励):

逐一解释每个概念
- Agent,一般译为智能体,就是我们要训练的模型,类似玩超级玛丽的时候操纵马里奥做出相应的动作,而这个马里奥就是Agent
- action(简记为),玩超级玛丽的时候你会控制马里奥做三个动作,即向左走、向右走和向上跳,而马里奥做的这三个动作就是action
- Environment,即环境,它是提供reward的某个对象,它可以是AlphaGo中的人类棋手,也可以是自动驾驶中的人类驾驶员,甚至可以是某些游戏AI里的游戏规则
- reward(简记为),这个奖赏可以类比为在明确目标的情况下,接近目标意味着做得好则奖,远离目标意味着做的不好则惩,最终达到收益/奖励最大化,且这个奖励是强化学习的核心
- State(简介为),可以理解成环境的状态,简称状态
总的而言,Agent依据策略决策从而执行动作action,然后通过感知环境Environment从而获取环境的状态state,进而,最后得到奖励reward(以便下次再到相同状态时能采取更优的动作),然后再继续按此流程“依据策略执行动作-感知状态--得到奖励”循环进行。
1.1.2 RL与监督学习的区别和RL方法的分类
此外,RL和监督学习(supervised learning)的区别:
-
监督学习有标签告诉算法什么样的输入对应着什么样的输出(譬如分类、回归等问题)
所以对于监督学习,目标是找到一个最优的模型函数,使其在训练数据集上最小化一个给定的损失函数,相当于最小化预测误差
最优模型 = arg minE { [损失函数(标签,模型(特征)] }RL没有标签告诉它在某种情况下应该做出什么样的行为,只有一个做出一系列行为后最终反馈回来的reward,然后判断当前选择的行为是好是坏
相当于RL的目标是最大化智能体策略在和动态环境交互过程中的价值,而策略的价值可以等价转换成奖励函数的期望,即最大化累计下来的奖励期望
最优策略 = arg maxE { [奖励函数(状态,动作)] } -
监督学习如果做了比较坏的选择则会立刻反馈给算法
RL的结果反馈有延时,有时候可能需要走了很多步以后才知道之前某步的选择是好还是坏 -
监督学习中输入是独立分布的,即各项数据之间没有关联
RL面对的输入总是在变化,每当算法做出一个行为,它就影响了下一次决策的输入
进一步,RL为得到最优策略从而获取最大化奖励,有
- 基于值函数的方法,通过求解一个状态或者状态下某个动作的估值为手段,从而寻找最佳的价值函数,找到价值函数后,再提取最佳策略
比如Q-learning、DQN等,适合离散的环境下,比如围棋和某些游戏领域 - 基于策略的方法,一般先进行策略评估,即对当前已经搜索到的策略函数进行估值,得到估值后,进行策略改进,不断重复这两步直至策略收敛
比如策略梯度法(policy gradient,简称PG),适合连续动作的场景,比如机器人控制领域
以及Actor-Criti(一般被翻译为演员-评论家算法),Actor学习参数化的策略即策略函数,Criti学习值函数用来评估状态-动作对,不过,Actor-Criti本质上是属于基于策略的算法,毕竟算法的目标是优化一个带参数的策略,只是会额外学习价值函数,从而帮助策略函数更好的学习
此外,还有对策略梯度算法的改进,比如TRPO算法、PPO算法,当然PPO算法也可称之为是一种Actor-Critic架构,下文会重点阐述
可能你还有点懵懵懂懂,没关系,毕竟还有不少背景知识还没有交待,比如RL其实是一个马尔可夫决策过程(Markov decision process,MDP),而为说清楚MDP,得先从随机过程、马尔可夫过程(Markov process,简称MP)开始讲起,故为考虑逻辑清晰,我们还是把整个继承/脉络梳理下。
1.2 什么是马尔科夫决策过程
1.2.1 MDP的前置知识:随机过程、马尔可夫过程、马尔可夫奖励
如HMM学习最佳范例中所说,有一类现象是确定性的现象,比如红绿灯系统,红灯之后一定是红黄、接着绿灯、黄灯,最后又红灯,每一个状态之间的变化是确定的

但还有一类现象则不是确定的,比如今天是晴天,谁也没法百分百确定明天一定是晴天还是雨天、阴天(即便有天气预报)

对于这种假设具有M个状态的模型
- 共有
个状态转移,因为任何一个状态都有可能是所有状态的下一个转移状态
- 每一个状态转移都有一个概率值,称为状态转移概率,相当于从一个状态转移到另一个状态的概率
- 所有的
下面的状态转移矩阵显示的是天气例子中可能的状态转移概率:

也就是说,如果昨天是晴天,那么今天是晴天的概率为0.5,是多云的概率为0.375、是雨天的概率为0.125,且这三种天气状态的概率之和必为1。
接下来,我们来抽象建模下。正如概率论的研究对象是静态的随机现象,而随机过程的研究对象是随时间演变的随机现象(比如天气随时间的变化):
- 随机现象在某时刻t的取值是一个向量随机变量,用
表示
比如上述天气转移矩阵便如下图所示



在马尔可夫过程的基础上加入奖励函数 和折扣因子
,就可以得到马尔可夫奖励过程(Markov reward process,MRP)。其中

奖励函数有点像贪心算法,只考虑下一步的影响
为什么使用期望呢?
奖励可能是随机的
在强化学习或马尔可夫过程的实际应用中,同一个状态 St=s 可能对应不同的奖励,因为环境是随机的(stochastic)。例如:
- 你在游戏中进入一个房间(状态 St=“进入房间”)。
- 可能有 3 种情况(不同的奖励):
- 你发现 10 个金币(奖励 Rt+1=10)。
- 你发现 5 个金币(奖励 Rt+1=5)。
- 你什么都没找到(奖励 Rt+1=0)。
- 你无法确定具体会得到哪个奖励,但可以计算它们的期望值。
假设 3 种情况的概率分别是 50%、30%、20%,那么状态 St 的期望奖励就是:
R(s)=0.5×10+0.3×5+0.2×0=6.5
这就是为什么我们定义奖励函数 R(s) 时,使用期望值(Expectation)。
 回报有点像动态规划,是上面奖励的优化。从贪心算法 —> 动态规划。
回报有点像动态规划,是上面奖励的优化。从贪心算法 —> 动态规划。
可以说奖励是一个时刻的,用大写字母R(reward)表示。回报是一整个过程的,用大字母G(Goal或者是Get)表示
举个例子,一个少年在面对“上大学、去打工、在家啃老”这三种状态,哪一种更能实现人生的价值呢?
奖励函数(基于奖励):只看一瞬间,那就会选择去打工(贪心算法)
价值函数(基于回报):看的比较长远,选上大学,因为上了大学,后面就会好事连连,比如读研读博留学深造、进入大厂、娶个漂亮老婆、生个聪明孩子(动态规划)


相关文章:
强化学习 DAY1:什么是 RL、马尔科夫决策、贝尔曼方程
第一部分 RL基础:什么是RL与MRP、MDP 1.1 入门强化学习所需掌握的基本概念 1.1.1 什么是强化学习:依据策略执行动作-感知状态-得到奖励 强化学习里面的概念、公式,相比ML/DL特别多,初学者刚学RL时,很容易被接连不断…...
理解神经网络:Brain.js 背后的核心思想
温馨提示 这篇文章篇幅较长,主要是为后续内容做铺垫和说明。如果你觉得文字太多,可以: 先收藏,等后面文章遇到不懂的地方再回来查阅。直接跳读,重点关注加粗或高亮的部分。放心,这种“文字轰炸”不会常有的,哈哈~ 感谢你的耐心阅读!😊 欢迎来到 brain.js 的学习之旅!…...

【Docker】dockerfile识别当前构建的镜像平台
在编写dockerfile的时候,可能会遇到需要针对不同平台进行不同操作的时候,这需要我们对dockerfile进行针对性修改。 比如opencv的依赖项libjasper-dev在ubuntu18.04上就需要根据不同的平台做不同的处理,关于这个库的安装在另外一篇博客里面有…...
【VM】VirtualBox安装CentOS8虚拟机
阅读本文前,请先根据 VirtualBox软件安装教程 安装VirtualBox虚拟机软件。 1. 下载centos8系统iso镜像 可以去两个地方下载,推荐跟随本文的操作用阿里云的镜像 centos官网:https://www.centos.org/download/阿里云镜像:http://…...
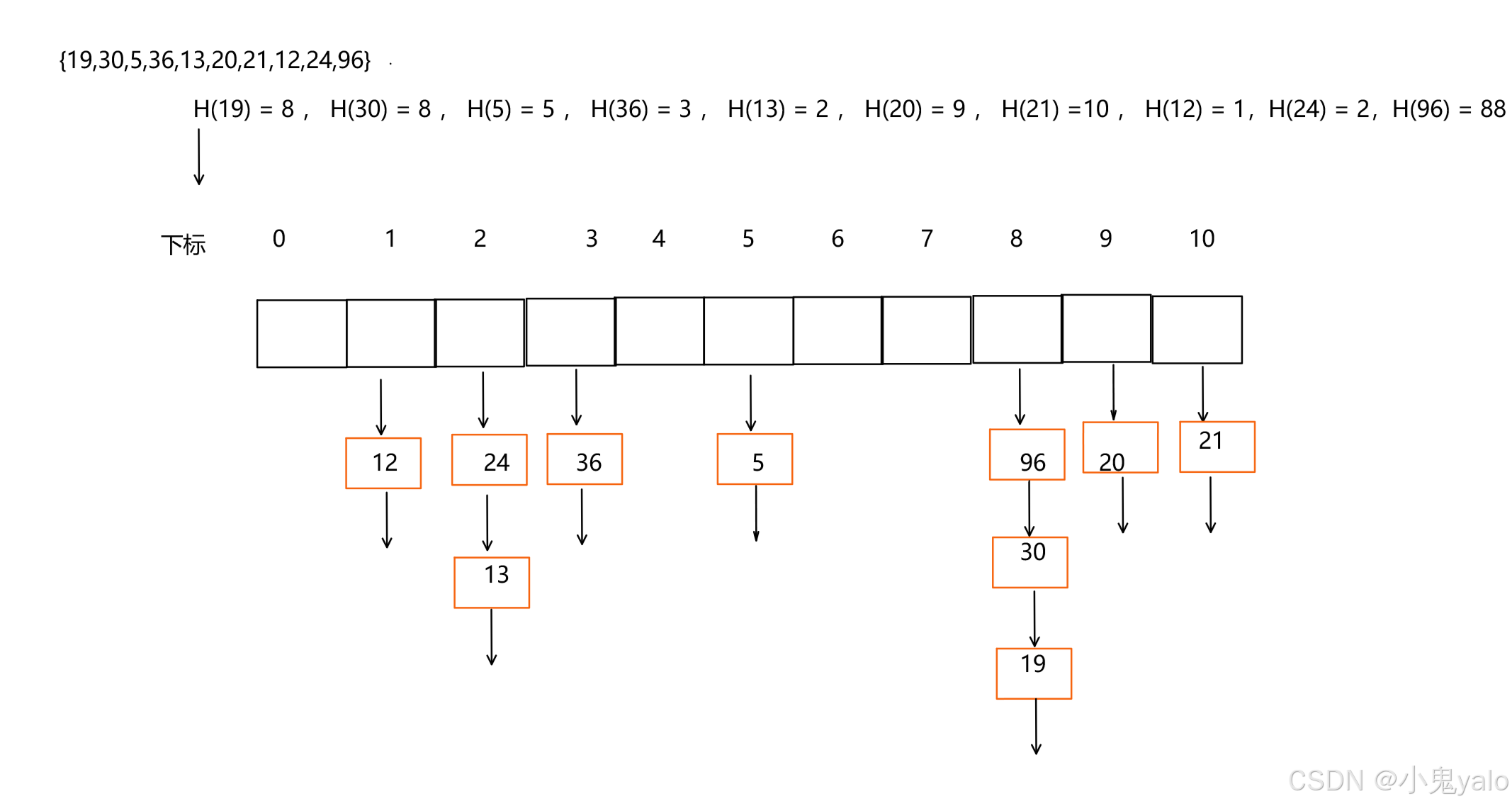
【C++篇】哈希表
目录 一,哈希概念 1.1,直接定址法 1.2,哈希冲突 1.3,负载因子 二,哈希函数 2.1,除法散列法 /除留余数法 2.2,乘法散列法 2.3,全域散列法 三,处理哈希冲突 3.1&…...

Java篇之继承
目录 一. 继承 1. 为什么需要继承 2. 继承的概念 3. 继承的语法 4. 访问父类成员 4.1 子类中访问父类的成员变量 4.2 子类中访问父类的成员方法 5. super关键字 6. super和this关键字 7. 子类构造方法 8. 代码块的执行顺序 9. protected访问修饰限定符 10. 继承方式…...

边缘检测算法(candy)
人工智能例子汇总:AI常见的算法和例子-CSDN博客 Canny 边缘检测的步骤 1. 灰度转换 如果输入的是彩色图像,则需要先转换为 灰度图像,因为边缘检测通常在单通道图像上进行。 2. 高斯滤波(Gaussian Blur) 由于边缘…...

设计模式Python版 组合模式
文章目录 前言一、组合模式二、组合模式实现方式三、组合模式示例四、组合模式在Django中的应用 前言 GOF设计模式分三大类: 创建型模式:关注对象的创建过程,包括单例模式、简单工厂模式、工厂方法模式、抽象工厂模式、原型模式和建造者模式…...
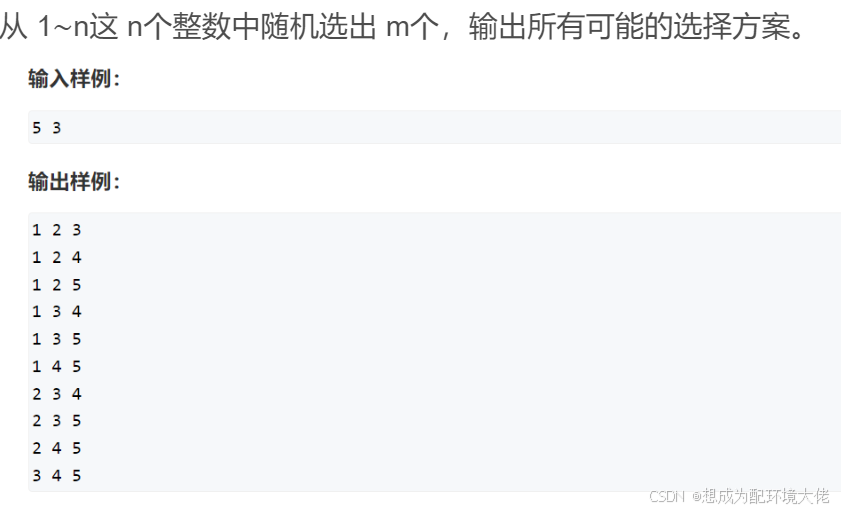
dfs枚举问题
碎碎念:要开始刷算法题备战蓝桥杯了,一切的开头一定是dfs 定义 枚举问题就是咱数学上学到的,从n个数里面选m个数,有三种题型(来自Acwing) 从 1∼n 这 n个整数中随机选取任意多个,输出所有可能的选择方案。 把 1∼n这…...
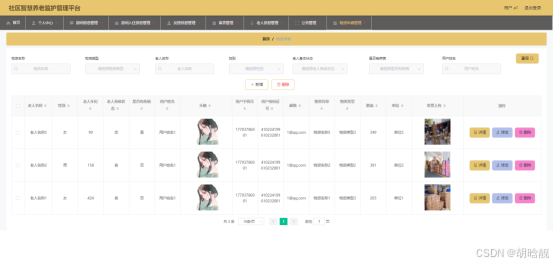
【开源免费】基于SpringBoot+Vue.JS社区智慧养老监护管理平台(JAVA毕业设计)
本文项目编号 T 163 ,文末自助获取源码 \color{red}{T163,文末自助获取源码} T163,文末自助获取源码 目录 一、系统介绍二、数据库设计三、配套教程3.1 启动教程3.2 讲解视频3.3 二次开发教程 四、功能截图五、文案资料5.1 选题背景5.2 国内…...
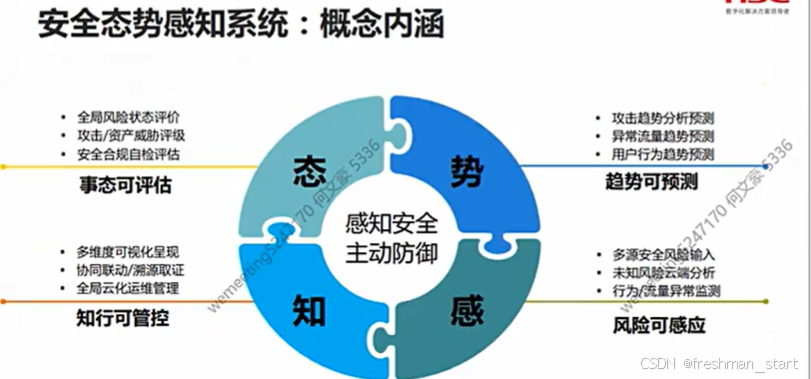
安全防护前置
就业概述 网络安全工程师/安全运维工程师/安全工程师 安全架构师/安全专员/研究院(数学要好) 厂商工程师(售前/售后) 系统集成工程师(所有计算机知识都要会一点) 学习目标 前言 网络安全事件 蠕虫病毒--&…...
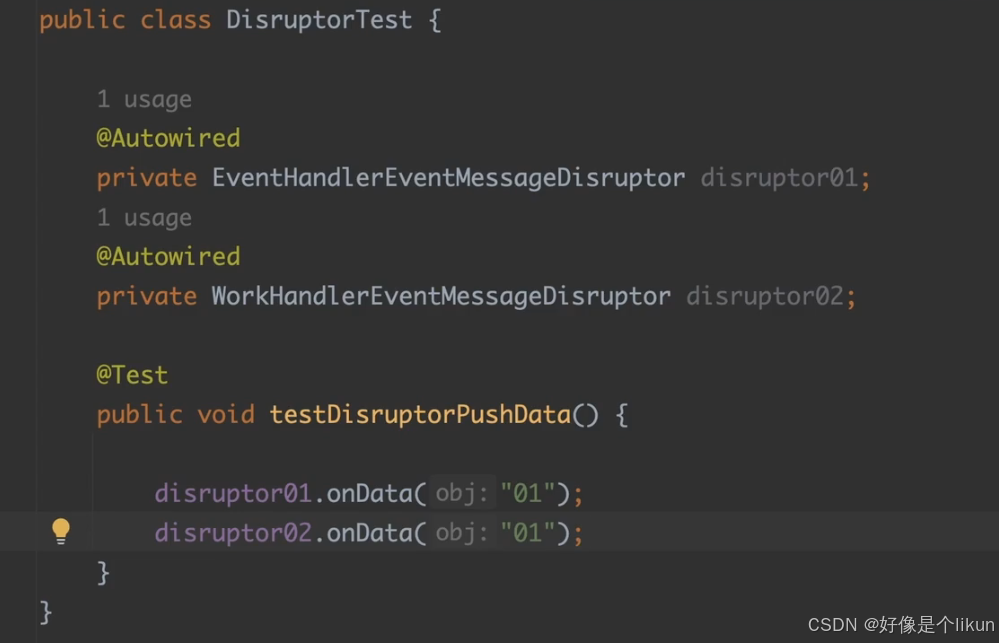
高性能消息队列Disruptor
定义一个事件模型 之后创建一个java类来使用这个数据模型。 /* <h1>事件模型工程类,用于生产事件消息</h1> */ no usages public class EventMessageFactory implements EventFactory<EventMessage> { Overridepublic EventMessage newInstance(…...

kamailio中的sctp模块
以下是关于 Kamailio 配置中 enable_sctpno 的详细解释: 1. 参数作用 enable_sctp: 该参数用于控制 Kamailio 是否启用 SCTP(Stream Control Transmission Protocol) 协议支持。 设置为 yes:启用 SCTP,并加…...
)
前端学习-事件解绑,mouseover和mouseenter的区别(二十九)
目录 前言 解绑事件 语法 鼠标经过事件的区别 鼠标经过事件 示例代码 两种注册事件的区别 总结 前言 人道洛阳花似锦,偏我来时不逢春 解绑事件 on事件方式,直接使用null覆盖就可以实现事件的解绑 语法 btn.onclick function(){alert(点击了…...

独立游戏RPG回顾:高成本
刚看了某纪录片, 内容是rpg项目的回顾。也是这个以钱为核心话题的系列的最后一集。 对这期特别有代入感,因为主角是曾经的同事,曾经在某天晚上听过其项目组的争论。 对其这些年的起伏特别的能体会。 主角是制作人,在访谈中透露这…...

10.4 LangChain核心架构揭秘:模块化设计如何重塑大模型应用开发?
LangChain核心架构揭秘:模块化设计如何重塑大模型应用开发? 关键词: LangChain模块化设计、大模型开发框架、LangChain核心概念、AI应用开发、LLM工程化 一、LangChain的模块化设计哲学:从“手工作坊”到“工业化生产” 传统开发痛点: 代码重复:每个项目从零开始编写胶…...
【学习笔记】深度学习网络-正则化方法
作者选择了由 Ian Goodfellow、Yoshua Bengio 和 Aaron Courville 三位大佬撰写的《Deep Learning》(人工智能领域的经典教程,深度学习领域研究生必读教材),开始深度学习领域学习,深入全面的理解深度学习的理论知识。 在之前的文章中介绍了深度学习中用…...

网站快速收录:如何优化网站头部与底部信息?
本文转自:百万收录网 原文链接:https://www.baiwanshoulu.com/46.html 为了加快网站的收录速度,优化网站头部与底部信息是关键一环。以下是一些具体的优化建议: 网站头部信息优化 标题标签(TitleTag)优化…...
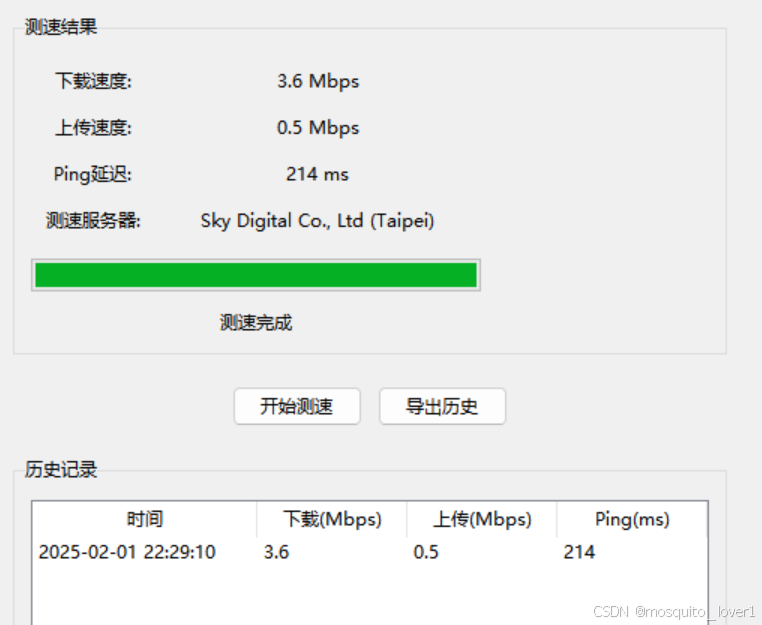
网络测试工具
工具介绍: 这是一个功能完整的网络测速工具,可以测试网络的下载速度、上传速度和延迟。 功能特点: 1. 速度测试 - 下载速度测试 - 上传速度测试 - Ping延迟测试 - 自动选择最佳服务器 2. 实时显示 - 进度条显示测试进度 - 实时显示测试状…...

使用HttpClient和HttpRequest发送HTTP请求
项目中经常会用到向第三方系统发送请求来传递数据或者获得信息,一般用的比较多的为HttpClient 和 HttpRequest,这里简要总结一下 HttpClient 和 HttpRequest 的用法 一、HttpClient 1. 发送get请求 public static String get(String url, Map<Stri…...

解密猫抓:当浏览器成为你的私人视频档案管理员
解密猫抓:当浏览器成为你的私人视频档案管理员 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 你是否曾盯着浏览器中那个精彩的在线讲座…...

Codesys ST语言PID调参避坑指南:从仿真到实战,手把手教你搞定温控/电机项目
Codesys ST语言PID调参避坑指南:从仿真到实战的工程化解决方案 在工业自动化领域,PID控制算法占据着核心地位。无论是恒温控制、电机调速还是压力调节,一个精心调校的PID控制器往往能决定整个系统的性能表现。然而,许多工程师在掌…...

AI量化交易框架解析:从架构设计到实战部署
1. 项目概述:一个AI驱动的加密资产对冲基金框架最近在GitHub上看到一个挺有意思的项目,叫“ai-hedge-fund-crypto”。光看名字,就能感受到一股浓浓的“量化AI加密”的混合气息。这其实是一个开源框架,旨在帮助开发者或量化研究员&…...

【避坑指南】VSCode+EIDE+Keil混合开发环境:从零搭建到项目无缝迁移
1. 为什么需要VSCodeEIDEKeil混合开发环境? 作为一名嵌入式开发者,我深知Keil这个老牌IDE在开发效率上的痛点:代码补全弱、界面老旧、多窗口管理混乱。但直接完全迁移到VSCode又面临工程兼容性问题,特别是对传统AC5编译器的支持。…...

完整实战指南:使用N_m3u8DL-RE高效解决流媒体下载难题
完整实战指南:使用N_m3u8DL-RE高效解决流媒体下载难题 【免费下载链接】N_m3u8DL-RE Cross-Platform, modern and powerful stream downloader for MPD/M3U8/ISM. English/简体中文/繁體中文. 项目地址: https://gitcode.com/GitHub_Trending/nm3/N_m3u8DL-RE …...

终极Windows Defender移除指南:13项核心服务的完整卸载方案
终极Windows Defender移除指南:13项核心服务的完整卸载方案 【免费下载链接】windows-defender-remover A tool which is uses to remove Windows Defender in Windows 8.x, Windows 10 (every version) and Windows 11. 项目地址: https://gitcode.com/gh_mirror…...

3个按键冲突场景,Hitboxer如何帮你重获游戏控制权?
3个按键冲突场景,Hitboxer如何帮你重获游戏控制权? 【免费下载链接】socd Key remapper for epic gamers 项目地址: https://gitcode.com/gh_mirrors/so/socd 你是否曾在激烈的游戏对战中,因为同时按下W和S键而突然卡住?或…...

智慧树自动刷课神器Autovisor:3分钟极速上手的完整指南
智慧树自动刷课神器Autovisor:3分钟极速上手的完整指南 【免费下载链接】Autovisor 2025智慧树刷课脚本 基于Python Playwright的自动化程序 [有免安装版] 项目地址: https://gitcode.com/gh_mirrors/au/Autovisor 还在为智慧树平台的繁琐操作而烦恼吗&#…...

基于大语言模型的本地语义搜索工具LLocalSearch部署与应用指南
1. 项目概述:一个能“读懂”你电脑的本地搜索工具 如果你和我一样,电脑里塞满了各种文档、邮件、聊天记录和代码片段,那么“找东西”这件事,绝对能排进日常最耗时的任务前三。传统的文件搜索,比如Windows自带的搜索或者…...

并行LLM推理技术:Hogwild! Inference原理与应用
1. 并行LLM推理的技术背景与挑战在传统Transformer架构中,语言模型的推理过程本质上是顺序执行的——每个新token的生成都严格依赖于之前所有token的注意力计算结果。这种串行特性导致两个显著瓶颈:首先,硬件计算资源利用率低下,特…...