pytorch使用SVM实现文本分类
人工智能例子汇总:AI常见的算法和例子-CSDN博客
完整代码:
import torch
import torch.nn as nn
import torch.optim as optim
import jieba
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn import metrics# 1. 数据准备(中文文本)
texts = ["今天的足球比赛非常激烈,球队表现出色,最终赢得了比赛。","NBA比赛今天开打,球员们的表现非常精彩,球迷们热情高涨。","张艺谋的新电影上映了,票房成绩非常好,观众反响热烈。","娱乐圈最近又出了一些新闻,明星们的私生活成了大家讨论的焦点。","昨晚的篮球赛真是太精彩了,球员们的进攻和防守都非常强硬。","李宇春在最新的音乐会上演出了她的新歌,现场观众反应热烈。","今年的世界杯比赛激烈异常,球队之间的竞争越来越激烈。","最近的综艺节目非常火,明星嘉宾的表现让观众们大笑不已。"
]# 标签:0表示体育,1表示娱乐
labels = [0, 0, 1, 1, 0, 1, 0, 1]# 2. 数据预处理:中文分词和 TF-IDF 特征提取
def jieba_cut(text):return " ".join(jieba.cut(text))texts_cut = [jieba_cut(text) for text in texts]vectorizer = TfidfVectorizer(max_features=10000)
X_tfidf = vectorizer.fit_transform(texts_cut).toarray()
y = np.array(labels)# 3. 数据集分割为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X_tfidf, y, test_size=0.2, random_state=42)# 4. PyTorch 数据加载
class NewsGroupDataset(torch.utils.data.Dataset):def __init__(self, features, labels):self.features = torch.tensor(features, dtype=torch.float32)self.labels = torch.tensor(labels, dtype=torch.long)def __len__(self):return len(self.features)def __getitem__(self, idx):return self.features[idx], self.labels[idx]train_dataset = NewsGroupDataset(X_train, y_train)
test_dataset = NewsGroupDataset(X_test, y_test)train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=2, shuffle=True)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=2, shuffle=False)# 5. 定义 SVM 模型(使用线性层)
class SVM(nn.Module):def __init__(self, input_dim, output_dim):super(SVM, self).__init__()self.fc = nn.Linear(input_dim, output_dim)def forward(self, x):return self.fc(x)# 6. 获取特征数并初始化模型
input_dim = X_tfidf.shape[1] # 自动获取特征数
model = SVM(input_dim=input_dim, output_dim=2) # 使用特征数量设置输入维度
criterion = nn.CrossEntropyLoss() # 损失函数
optimizer = optim.SGD(model.parameters(), lr=0.01) # 优化器,调整学习率# 7. 训练模型
num_epochs = 50 # 增加训练周期for epoch in range(num_epochs):model.train()running_loss = 0.0correct = 0total = 0for inputs, labels in train_loader:optimizer.zero_grad()outputs = model(inputs)loss = criterion(outputs, labels)loss.backward()optimizer.step()running_loss += loss.item()_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()print(f"Epoch [{epoch + 1}/{num_epochs}], Loss: {running_loss / len(train_loader)}, Accuracy: {100 * correct / total}%")# 8. 测试模型
model.eval()
correct = 0
total = 0with torch.no_grad():for inputs, labels in test_loader:outputs = model(inputs)_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()print(f"Test Accuracy: {100 * correct / total}%")# 9. 输出性能指标
y_pred = []
y_true = []with torch.no_grad():for inputs, labels in test_loader:outputs = model(inputs)_, predicted = torch.max(outputs.data, 1)y_pred.extend(predicted.numpy())y_true.extend(labels.numpy())print(metrics.classification_report(y_true, y_pred))# 10. 测试新样本
def predict(text, model, vectorizer):# 1. 进行分词text_cut = jieba_cut(text)# 2. 将文本转为 TF-IDF 特征向量text_tfidf = vectorizer.transform([text_cut]).toarray()# 3. 转换为 PyTorch 张量text_tensor = torch.tensor(text_tfidf, dtype=torch.float32)# 4. 模型预测model.eval() # 设置模型为评估模式with torch.no_grad():output = model(text_tensor)_, predicted = torch.max(output.data, 1)# 5. 返回预测结果return predicted.item()# 测试一个新的中文文本
new_text = "今天的篮球比赛真是太精彩了,球员们的表现让大家都为之喝彩。"
predicted_label = predict(new_text, model, vectorizer)# 输出预测结果
if predicted_label == 0:print("预测类别: 体育")
else:print("预测类别: 娱乐")
1. 数据准备
- 文本数据:我们定义了一个包含中文文本的列表,每条文本表示一个新闻或评论。
- 标签:为每条文本分配了一个标签,0 代表“体育”,1 代表“娱乐”。
2. 数据预处理
- 中文分词:使用
jieba库对每条文本进行分词,并将分词后的结果连接成字符串。这是处理中文文本时的常见做法。 - TF-IDF 特征提取:使用
TfidfVectorizer将文本转化为数值特征。TF-IDF 是一种常见的文本表示方式,能够衡量单词在文档中的重要性。
3. 数据集分割
- 使用
train_test_split将数据分为训练集和测试集。80% 的数据用于训练,20% 用于测试。
4. PyTorch 数据加载
- 定义 Dataset 类:创建了一个自定义的
NewsGroupDataset类,继承自torch.utils.data.Dataset,用于将文本特征和标签封装为 PyTorch 可用的数据集格式。 - DataLoader:使用
DataLoader将训练集和测试集数据进行批处理和加载。
5. 模型定义
- 定义了一个简单的线性 SVM 模型。实际上,使用了一个线性层 (
nn.Linear) 来进行分类,输入是文本的 TF-IDF 特征,输出是两个类别(体育或娱乐)。 - 使用了
CrossEntropyLoss作为损失函数,因为这是分类任务中常用的损失函数。 - 优化器使用了随机梯度下降(SGD),并设置了学习率为 0.01。
6. 训练过程
- 训练模型的过程包括:前向传播(计算输出),计算损失,反向传播(更新参数),并在每个 epoch 后输出损失和准确率。
- 每个 batch 的训练过程中,模型会通过计算损失并进行优化,逐步提升准确率。
7. 测试和评估
- 在测试过程中,将模型设置为评估模式 (
model.eval()),并计算测试集上的准确率。通过比较预测标签与真实标签,计算正确的预测数量并输出准确率。 - 使用
classification_report来输出精确度、召回率和 F1 分数等更多的评估指标。
8. 预测新样本
- 定义了一个
predict()函数,用于预测新的文本样本的分类。 - 预测过程包括:对文本进行分词,转化为 TF-IDF 特征,传入模型进行前向传播,最后返回模型预测的标签。
9. 输出
- 代码的最后,会输出模型对新文本的预测结果,标明是属于体育类别还是娱乐类别。
关键技术点:
- 中文分词:使用
jieba对中文文本进行分词处理,这对于中文文本的处理至关重要。 - TF-IDF:将文本转换为数值特征,便于模型处理。TF-IDF 是基于单词在文档中的出现频率及其在整个语料中的稀有度进行加权的。
- 模型训练与评估:通过多轮训练提升模型准确度,使用测试集来评估模型的泛化能力。
- PyTorch DataLoader:通过
DataLoader高效地处理训练集和测试集,进行批处理和自动化管理。
相关文章:

pytorch使用SVM实现文本分类
人工智能例子汇总:AI常见的算法和例子-CSDN博客 完整代码: import torch import torch.nn as nn import torch.optim as optim import jieba import numpy as np from sklearn.model_selection import train_test_split from sklearn.feature_extract…...
读取手机通讯录【Android移动开发基础案例教程(第2版)黑马程序员】)
安卓(android)读取手机通讯录【Android移动开发基础案例教程(第2版)黑马程序员】
一、实验目的(如果代码有错漏,可在代码地址查看) 1.熟悉内容提供者(Content Provider)的概念和作用。 2.掌握内容提供者的创建和使用方法。 4.掌握内容URI的结构和用途。 二、实验条件 1.熟悉内容提供者的工作原理。 2.掌握内容提供者访问其…...

【Qt】常用的容器
Qt提供了多个基于模板的容器类,这些容器类可用于存储指定类型的数据项。例如常用的字符串列表类 QStringList 可用来操作一个 QList<QString>列表。 Qt的容器类比标准模板库(standard template library,STL)中的容器类更轻巧、使用更安全且更易于使…...
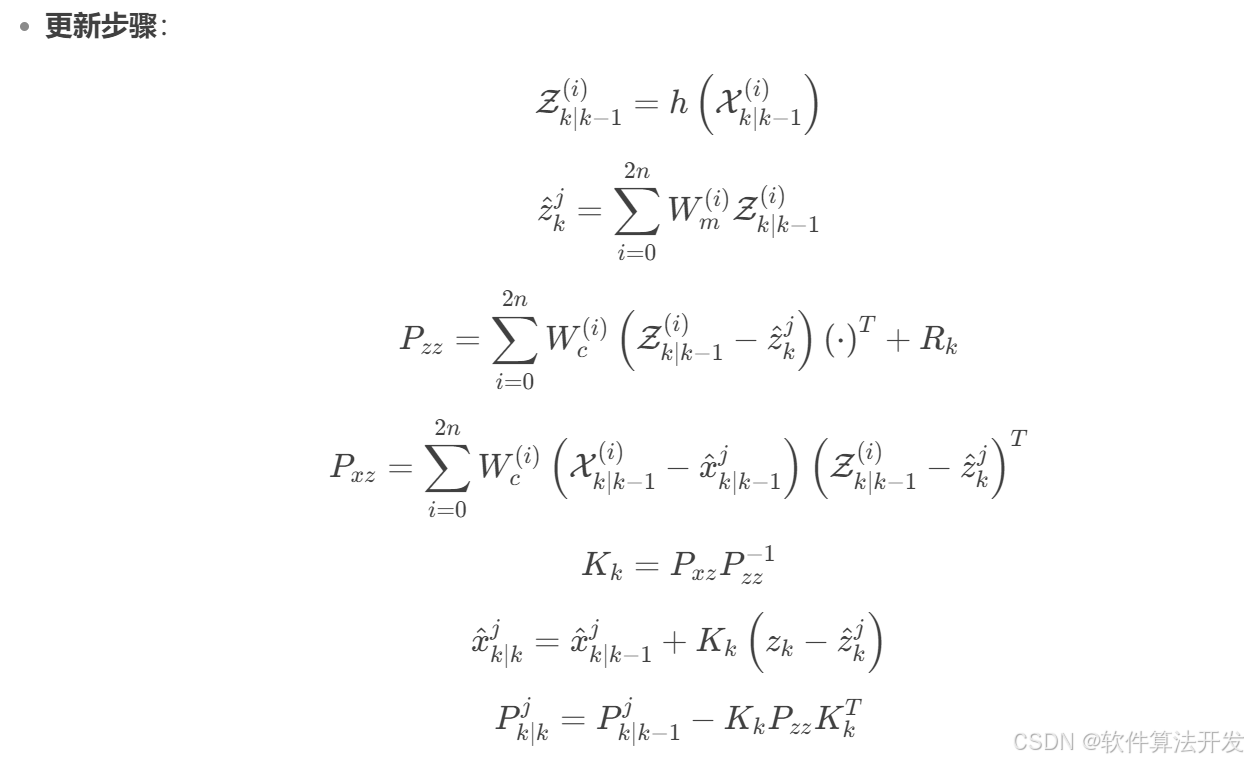
基于UKF-IMM无迹卡尔曼滤波与交互式多模型的轨迹跟踪算法matlab仿真,对比EKF-IMM和UKF
目录 1.程序功能描述 2.测试软件版本以及运行结果展示 3.核心程序 4.本算法原理 5.完整程序 1.程序功能描述 基于UKF-IMM无迹卡尔曼滤波与交互式多模型的轨迹跟踪算法matlab仿真,对比EKF-IMM和UKF。 2.测试软件版本以及运行结果展示 MATLAB2022A版本运行 3.核心程序 .…...

分布式事务组件Seata简介与使用,搭配Nacos统一管理服务端和客户端配置
文章目录 一. Seata简介二. 官方文档三. Seata分布式事务代码实现0. 环境简介1. 添加undo_log表2. 添加依赖3. 添加配置4. 开启Seata事务管理5. 启动演示 四. Seata Server配置Nacos1. 修改配置类型2. 创建Nacos配置 五. Seata Client配置Nacos1. 增加Seata关联Nacos的配置2. 在…...

JavaScript常用的内置构造函数
JavaScript作为一种广泛应用的编程语言,提供了丰富的内置构造函数,帮助开发者处理不同类型的数据和操作。这些内置构造函数在创建和操作对象时非常有用。本文将详细介绍JavaScript中常用的内置构造函数及其用途。 常用内置构造函数概述 1. Object Obj…...
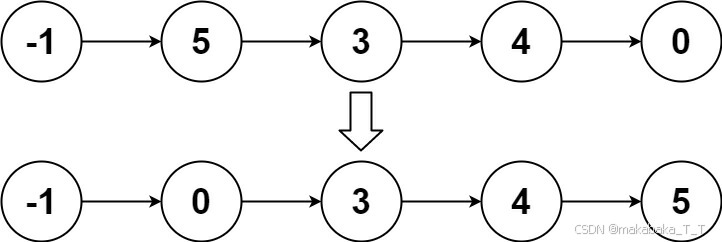
25寒假算法刷题 | Day1 | LeetCode 240. 搜索二维矩阵 II,148. 排序链表
目录 240. 搜索二维矩阵 II题目描述题解 148. 排序链表题目描述题解 240. 搜索二维矩阵 II 点此跳转题目链接 题目描述 编写一个高效的算法来搜索 m x n 矩阵 matrix 中的一个目标值 target 。该矩阵具有以下特性: 每行的元素从左到右升序排列。每列的元素从上到…...
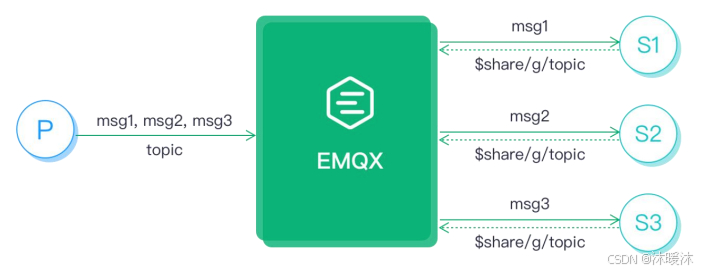
MQTT知识
MQTT协议 MQTT 是一种基于发布/订阅模式的轻量级消息传输协议,专门针对低带宽和不稳定网络环境的物联网应用而设计,可以用极少的代码为联网设备提供实时可靠的消息服务。MQTT 协议广泛应用于物联网、移动互联网、智能硬件、车联网、智慧城市、远程医疗、…...

【机器学习与数据挖掘实战】案例11:基于灰色预测和SVR的企业所得税预测分析
【作者主页】Francek Chen 【专栏介绍】 ⌈ ⌈ ⌈机器学习与数据挖掘实战 ⌋ ⌋ ⌋ 机器学习是人工智能的一个分支,专注于让计算机系统通过数据学习和改进。它利用统计和计算方法,使模型能够从数据中自动提取特征并做出预测或决策。数据挖掘则是从大型数据集中发现模式、关联…...

新一代搜索引擎,是 ES 的15倍?
Manticore Search介绍 Manticore Search 是一个使用 C 开发的高性能搜索引擎,创建于 2017 年,其前身是 Sphinx Search 。Manticore Search 充分利用了 Sphinx,显着改进了它的功能,修复了数百个错误,几乎完全重写了代码…...

使用 Context API 管理临时状态,避免 Redux/Zustand 的持久化陷阱
在开发 React Native 应用时,我们经常需要管理全局状态,比如用户信息、主题设置、网络状态等。而对于某些临时状态,例如 数据同步进行中的状态 (isSyncing),我们应该选择什么方式来管理它? 在项目开发过程中ÿ…...
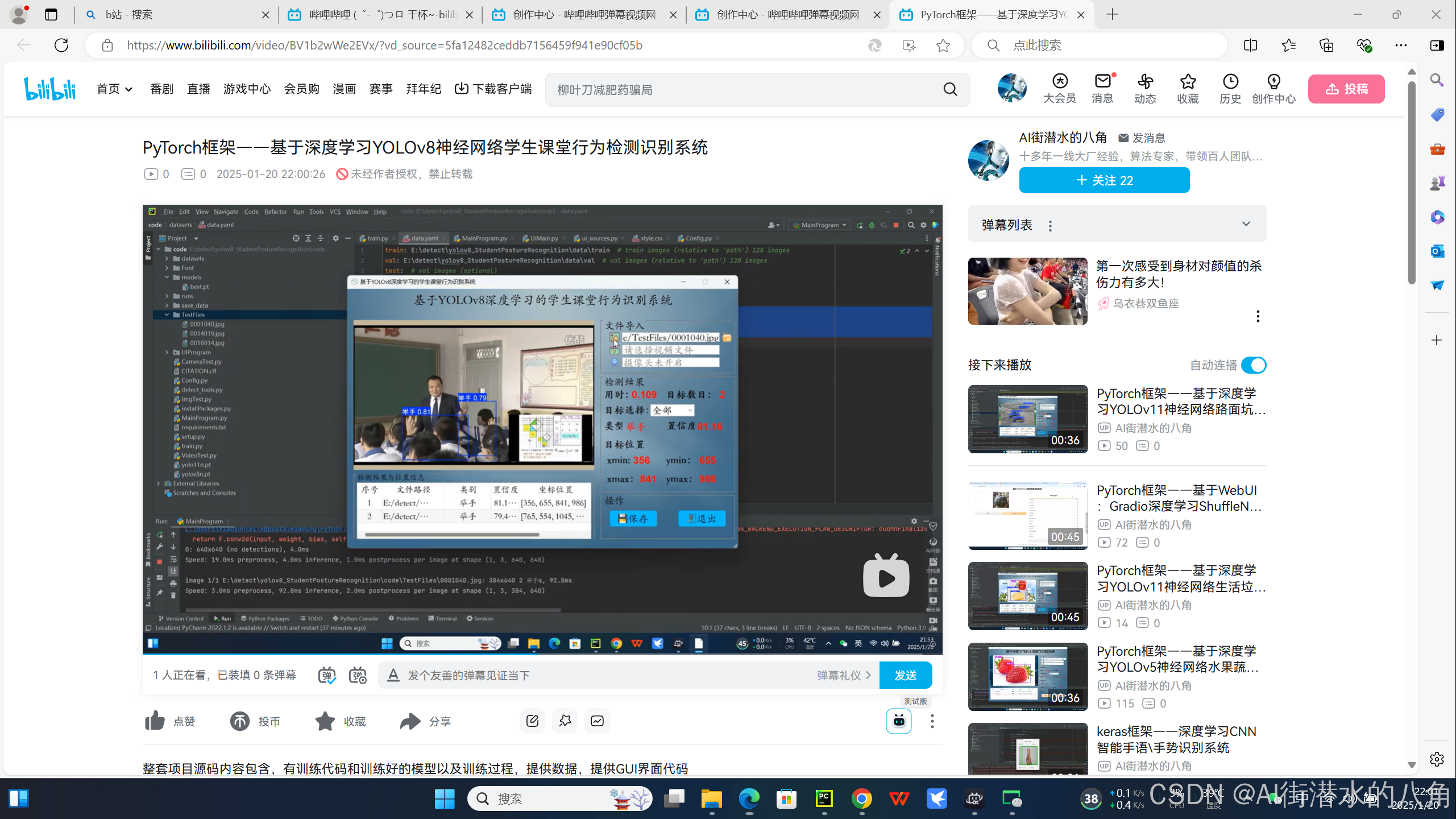
PyTorch框架——基于深度学习YOLOv8神经网络学生课堂行为检测识别系统
基于YOLOv8深度学习的学生课堂行为检测识别系统,其能识别三种学生课堂行为:names: [举手, 读书, 写字] 具体图片见如下: 第一步:YOLOv8介绍 YOLOv8 是 ultralytics 公司在 2023 年 1月 10 号开源的 YOLOv5 的下一个重大更新版本…...

word2vec 实战应用介绍
Word2Vec 是一种由 Google 在 2013 年推出的重要词嵌入模型,通过将单词映射为低维向量,实现了对自然语言处理任务的高效支持。其核心思想是利用深度学习技术,通过训练大量文本数据,将单词表示为稠密的向量形式,从而捕捉单词之间的语义和语法关系。以下是关于 Word2Vec 实战…...

C# 操作符重载对象详解
.NET学习资料 .NET学习资料 .NET学习资料 一、操作符重载的概念 在 C# 中,操作符重载允许我们为自定义的类或结构体定义操作符的行为。通常,我们熟悉的操作符,如加法()、减法(-)、乘法&#…...

python学opencv|读取图像(五十四)使用cv2.blur()函数实现图像像素均值处理
【1】引言 前序学习进程中,对图像的操作均基于各个像素点上的BGR值不同而展开。 对于彩色图像,每个像素点上的BGR值为三个整数,因为是三通道图像;对于灰度图像,各个像素上的BGR值是一个整数,因为这是单通…...
: 非极大值抑制(Non-Maximum Suppression, NMS))
CNN的各种知识点(四): 非极大值抑制(Non-Maximum Suppression, NMS)
非极大值抑制(Non-Maximum Suppression, NMS) 1. 非极大值抑制(Non-Maximum Suppression, NMS)概念:算法步骤:具体例子:PyTorch实现: 总结: 1. 非极大值抑制(…...

虚幻基础16:locomotion direction
locomotion locomotion:角色运动系统的总称:包含移动、奔跑、跳跃、转向等。 locomotion direction 玩家输入 玩家输入:通常代表玩家想要的移动方向。 direction 可以计算当前朝向与移动方向的Δ。从而实现朝向与移动(玩家输入)方向的分…...

C++游戏开发实战:从引擎架构到物理碰撞
📝个人主页🌹:一ge科研小菜鸡-CSDN博客 🌹🌹期待您的关注 🌹🌹 1. 引言 C 是游戏开发中最受欢迎的编程语言之一,因其高性能、低延迟和强大的底层控制能力,被广泛用于游戏…...

代理模式——C++实现
目录 1. 代理模式简介 2. 代码示例 1. 代理模式简介 代理模式是一种行为型模式。 代理模式的定义:由于某些原因需要给某对象提供一个代理以控制该对象的访问。这时,访问对象不适合或者不能直接访问引用目标对象,代理对象作为访问对象和目标…...

什么情况下,C#需要手动进行资源分配和释放?什么又是非托管资源?
扩展:如何使用C#的using语句释放资源?什么是IDisposable接口?与垃圾回收有什么关系?-CSDN博客 托管资源的回收有GC自动触发,而非托管资源需要手动释放。 在 C# 中,非托管资源是指那些不由 CLR(…...
计算指南:从原理到选型实战)
运算放大器增益带宽积(GBW)计算指南:从原理到选型实战
1. 项目概述:为什么我们需要关心运放的GBW?在模拟电路设计,尤其是信号调理、滤波、放大等前端电路的设计中,运算放大器(运放)的选择是决定电路性能上限的关键一步。很多工程师在选型时,会重点关…...
)
KUKA机器人FSoE安全地址丢了别慌!手把手教你用WorkVisual手动找回(附KRC4标准柜地址表)
KUKA机器人FSoE安全地址丢失应急恢复指南:从诊断到修复的全流程解析 当产线突然因KUKA机器人安全通信故障停机时,控制柜屏幕上闪烁的FSoE地址错误提示往往让现场工程师心跳加速。不同于常规故障,安全地址丢失直接切断设备间的安全信号传输&am…...

书成紫微动,律定凤凰驯:对比臆想歪解,铁哥的天然契合才是真天命
———— 千年颂辞 真天命笺 ————一、两种读法:伪天命 真天命伪天命(臆想歪解)真天命(天然契合)脑补玄学、权谋剧本本心行道、作品证道人追诗、人凑运诗等人、运合心后天强行拟合先天无心自洽悬浮文字游戏落地世…...

J-Link V8变砖别慌!手把手教你用SAM-BA 2.14救活AT91SAM7S64芯片
J-Link V8救砖实战:用SAM-BA 2.14拯救AT91SAM7S64芯片全指南 当你的J-Link V8调试器突然"变砖"——LED灯熄灭、电脑无法识别、所有功能瘫痪时,那种感觉就像外科医生在手术台上突然失去所有仪器。但别急着宣布它的"死亡",…...

从warmup_csaw_2016看栈溢出利用的本质:绕过NX/ASLR?不,这次我们先学‘计算’
从warmup_csaw_2016看栈溢出利用的本质:计算的艺术 在二进制安全领域,栈溢出常被初学者视为"魔法攻击"——只需覆盖返回地址就能获得控制权。但当我们剥开NX/ASLR等现代保护机制的外衣,会发现精确计算才是漏洞利用的永恒核心。2016…...

BoltAI 资源网关、Agent 平台重塑工业 AI 底
一、工业 AI 进入“基础设施竞争”新阶段2025—2026年,从单点试点、概念验证,快速走向平台化、规模化、体系化落地。过去“一个场景一个模型”的作坊式开发,成本高、复用差、运维乱,已难以支撑制造、能源、化工、装备等行业的全域…...

【ElevenLabs情绪语音实战指南】:3步解锁开心语音API调用、情感强度微调与合规避坑全链路
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs开心情绪语音技术全景概览 核心技术能力 ElevenLabs 的开心情绪语音生成并非简单音调拉升或语速加快,而是基于多任务情感条件建模(Multi-Task Emotional Conditionin…...

SLO-Warden:云原生时代SLO自动化管理的工程实践
1. 项目概述:当SLO成为运维的“紧箍咒”在云原生和微服务架构成为主流的今天,服务的稳定性和可靠性不再是锦上添花,而是业务的生命线。对于运维工程师和SRE(站点可靠性工程师)而言,我们每天都在和各种指标、…...

小米路由器R3G刷机实战:从官方固件到蜜罐版MT工具箱的保姆级避坑指南
小米路由器R3G深度改造指南:解锁第三方固件的完整路线图 当你盯着家里那台性能日渐吃紧的小米路由器R3G时,是否想过它其实蕴藏着未被发掘的潜力?这款发布于数年前的中端路由器,凭借MT7621双核芯片和128MB内存的硬件基础࿰…...

Android跨平台文件同步技术实现:WebDAV桥接工具架构深度解析
Android跨平台文件同步技术实现:WebDAV桥接工具架构深度解析 【免费下载链接】webdav-provider An Android app that can expose WebDAV storage to other apps through Androids Storage Access Framework (SAF) 项目地址: https://gitcode.com/gh_mirrors/we/we…...