eggnog后kegg结果提取和注释
首先进入KEGG BRITE: KEGG Orthology (KO)
下载json文件
用python处理一下
import json
import re
import osos.chdir("C:/Users/fordata/Downloads/")
with open("ko00001.json","r") as f:fj = f.read()kojson = json.loads(fj)with open("newKegg.tsv", "w") as k:for i in kojson['children']:ii = i['name'].replace(" ", "\t", 1)for j in i['children']:jj = j['name'].replace(" ", "\t", 1)for m in j['children']:if re.findall(r"ko\d{5}", m['name']):mm = "ko" + m['name'].replace(" ", "\t", 1)else:mm = m['name'].replace(" ", "\t", 1)try:for n in m['children']:if ";" in n['name']:nn = n['name'].replace(" ", "\t", 1).replace("; ", "\t", 1)else:nn = n['name'].replace(" ", "\t \t", 1)k.write(ii + "\t" + jj + "\t" + mm + "\t" + nn + "\n")except:nn = " \t \t "k.write(ii+"\t"+jj+"\t"+mm+"\t"+nn+"\n")得到结果

写个代码看看把keggKO和tpm关联起来
#! /usr/bin/env python
#########################################################
# mix eggnog(kegg) result with tpm
# written by PeiZhong in IFR of CAASimport argparse
import pandas as pd# Parse command-line arguments
parser = argparse.ArgumentParser(description='Mix eggnog(kegg) result with TPM')
parser.add_argument('--result', "-r", required=True, help='Path to eggnog result file')
parser.add_argument('--tpm', "-t", required=True, help='Path to TPM table file')
parser.add_argument('--out', "-o", required=True, help='Path to output file')args = parser.parse_args()# Step 1: Read input files
print("Reading input files")# Read dbcan result
df_result = {}
df_kegg = set() # Use a set to store unique CAZy families
with open(args.result, "r") as f:for line in f:if "#" not in line:protein_id = line.split("\t")[0]kegg_str = line.split("\t")[11]if "-" != kegg_str:df_result[protein_id] = kegg_str# Extract CAZy families and remove duplicatesfamilies = set(entry.split(":")[1].strip() for entry in kegg_str.split(','))df_kegg.update(families) # Add unique families to the global set# Read TPM file
df_tpm = pd.read_csv(args.tpm, sep='\t')# Step 2: Process dbcan results and calculate TPM sums for each sample
print("Processing dbcan results and calculating TPM sums for each sample")# Initialize a dictionary to store TPM sums for each CAZy family and sample
kegg_tpm_sums = {ko: {sample: 0.0 for sample in df_tpm.columns[1:]} for ko in df_kegg}# Convert TPM table to a dictionary for faster lookup
tpm_dict = df_tpm.set_index(df_tpm.columns[0]).to_dict(orient='index')# Process each protein in the dbcan result
for protein_id, kegg_str in df_result.items():# Convert protein ID to gene ID by removing trailing "_number"if "_" in protein_id:gene_id = protein_id.rsplit("_", 1)[0] # Split from right on the last "_"else:print(f"Warning: Protein ID {protein_id} has no underscore, using as gene ID")gene_id = protein_id# Get TPM values for this geneif gene_id not in tpm_dict:print(f"Warning: No TPM values found for {gene_id} (protein {protein_id})")continuetpm_values = tpm_dict[gene_id]# Extract unique CAZy families for this proteinfamilies = set(entry.split(':')[1].strip() for entry in kegg_str.split(','))# Update TPM sums for each unique CAZy familyfor family in families:if family in kegg_tpm_sums:for sample in df_tpm.columns[1:]:kegg_tpm_sums[family][sample] += tpm_values[sample]else:# Dynamically add new CAZy familieskegg_tpm_sums[family] = {sample: tpm_values[sample] for sample in df_tpm.columns[1:]}# Create and save output DataFrame
output_df = pd.DataFrame.from_dict(kegg_tpm_sums, orient='index')
output_df.index.name = 'CAZy_Family'
output_df.to_csv(args.out, sep='\t', float_format='%.2f') # Round to 2 decimal places
print(f"Results saved to {args.out}")得到
kegg的对应level,在excel钟使用vlookup函数对应即可
相关文章:
eggnog后kegg结果提取和注释
首先进入KEGG BRITE: KEGG Orthology (KO) 下载json文件 用python处理一下 import json import re import osos.chdir("C:/Users/fordata/Downloads/") with open("ko00001.json","r") as f:fj f.read()kojson json.loads(fj)with open(&qu…...

shell脚本控制——处理信号
Linux利用信号与系统中的进程进行通信。你可以通过对脚本进行编程,使其在收到特定信号时执行某些命令,从而控制shell脚本的操作。 1.重温Linux信号 Linux系统和应用程序可以产生超过30个信号。下表列出了在shell脚本编程时会遇到的最常见的Linux系统信…...

Doris更新某一列数据完整教程
在Doris,要更新数据,并不像mysql等关系型数据库那样方便,可以用update set来直接更新某个列。在Doris只能进行有限的更新,官方文档如下: UPDATE - Apache Doris 1、使用Doris自带的Update功能 描述 该语句是为进行对数据进行更新的操作,UPDATE 语句目前仅支持 UNIQUE…...

VIVADO生成DCP和EDF指南
VIVADO生成DCP和EDF 文章目录 VIVADO生成DCP和EDF前言一、DCP封装二、EDF封装 前言 详细步骤就不贴图了,网上一大堆 在Vivado中,常用的三种封装形式有三种: ● IP ● edif ● dcp 在下文之前,先看几个概念 out_of_context&…...

Python中字节顺序、大小与对齐方式:深入理解计算机内存的底层奥秘
在计算机科学的世界里,理解数据的存储方式是每个程序员必备的技能。无论是处理网络通信、文件读写,还是进行底层系统编程,字节顺序(Endianness)、数据大小(Size)和对齐方式(Alignmen…...

在亚马逊云科技上云原生部署DeepSeek-R1模型(上)
DeepSeek-R1在开源版本发布的第二天就登陆了亚马逊云科技AWS云平台,这个速度另小李哥十分震惊。这又让我想起了在亚马逊云科技全球云计算大会re:Invent2025里,亚马逊CEO Andy Jassy说过的:随着目前生成式AI应用规模的扩大,云计算的…...

Redis实现分布式锁详解
前言 用 Redis 实现分布式锁,是我们常见的实现分布式锁的一种方式 下面是 redis 实现 分布式锁的四种方式,每种方式都有一定的问题,直到最后的 zookeeper 先透露一下: Redission 解决了 set ex nx 无法自动续期的问题 RedLo…...

表单标签(使用场景注册页面)
表单域(了解即可,还要到学习服务器阶段才可以真正送到后台) 定义了一个区域了之后,可以把这部分区域发送到后台上 <form action“url地址” method“提交方式” name"表单域名称">各种表单元素控件 </form>…...

c++ template-3
第 7 章 按值传递还是按引用传递 从一开始,C就提供了按值传递(call-by-value)和按引用传递(call-by-reference)两种参数传递方式,但是具体该怎么选择,有时并不容易确定:通常对复杂类…...
】)
【创建模式-单例模式(Singleton Pattern)】
赐萧瑀 实现方案饿汉模式懒汉式(非线程安全)懒汉模式(线程安全)双重检查锁定静态内部类 攻击方式序列化攻击反射攻击 枚举(最佳实践)枚举是一种类 唐 李世民 疾风知劲草,板荡识诚臣。 勇夫安识义,智者必怀仁…...

攻防世界你猜猜
打开题目发现是一串十六进制的数据 我尝试解码了一下没发现什么,最后找了一下发现因为这是504B0304开头的所以是一个zip文件头 用python代码还原一下 from Crypto.Util.number import * f open("guess.zip","wb") s 0x504B03040A0001080000…...

【Axure教程】标签版分级多选下拉列表
分级多选下拉列表是指一个下拉列表,它包含多个层次的选项,用户可以选择一个或多个选项。这些选项通常是根据某种层级关系来组织的,例如从上到下有不同的分类或者过滤条件,用户选择上层选项后,下层选项会发生变化&#…...

DeepSeek图解10页PDF
以前一直在关注国内外的一些AI工具,包括文本型、图像类的一些AI实践,最近DeepSeek突然爆火,从互联网收集一些资料与大家一起分享学习。 本章节分享的文件为网上流传的DeepSeek图解10页PDF,免费附件链接给出。 1 本地 1 本地部…...

Centos7 停止维护,docker 安装
安装docker报错 执行docker安装命令:sudo yum install -y docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin,出现如下错误 更换yum源 [rootlocalhost yum.repos.d]# sudo mv /etc/yum.repos.d/CentOS-Base.repo /et…...

日志级别修改不慎引发的一场CPU灾难
背景 今天下午16.28有同事通过日志配置平台将某线上应用部分包的日志等级由error调为info,进而导致部分机器CPU升高,甚至有机器CPU达到100%,且ygc次数增加,耗时增加到80~100ms。 故障发现与排查 16.28陆续出现线上C…...

FPGA实现SDI视频缩放转UltraScale GTH光口传输,基于GS2971+Aurora 8b/10b编解码架构,提供2套工程源码和技术支持
目录 1、前言工程概述免责声明 2、相关方案推荐我已有的所有工程源码总目录----方便你快速找到自己喜欢的项目我这里已有的 GT 高速接口解决方案本博已有的 SDI 编解码方案我这里已有的FPGA图像缩放方案 3、工程详细设计方案工程设计原理框图SDI 输入设备GS2971芯片BT1120转RGB…...

二级C语言题解:矩阵主、反对角线元素之和,二分法求方程根,处理字符串中 * 号
目录 一、程序填空📝 --- 矩阵主、反对角线元素之和 题目📃 分析🧐 二、程序修改🛠️ --- 二分法求方程根 题目📃 分析🧐 三、程序设计💻 --- 处理字符串中 * 号 题目…...

利用 Python 爬虫获取按关键字搜索淘宝商品的完整指南
在电商数据分析和市场研究中,获取商品的详细信息是至关重要的一步。淘宝作为中国最大的电商平台之一,提供了丰富的商品数据。通过 Python 爬虫技术,我们可以高效地获取按关键字搜索的淘宝商品信息。本文将详细介绍如何利用 Python 爬虫技术获…...

什么是幂等性
幂等性(Idempotence)是一个在数学、计算机科学等多个领域都有重要应用的概念,下面从不同领域为你详细介绍其含义。 数学领域 在数学中,幂等性是指一个操作或函数进行多次相同的运算,其结果始终与进行一次运算的结果相…...
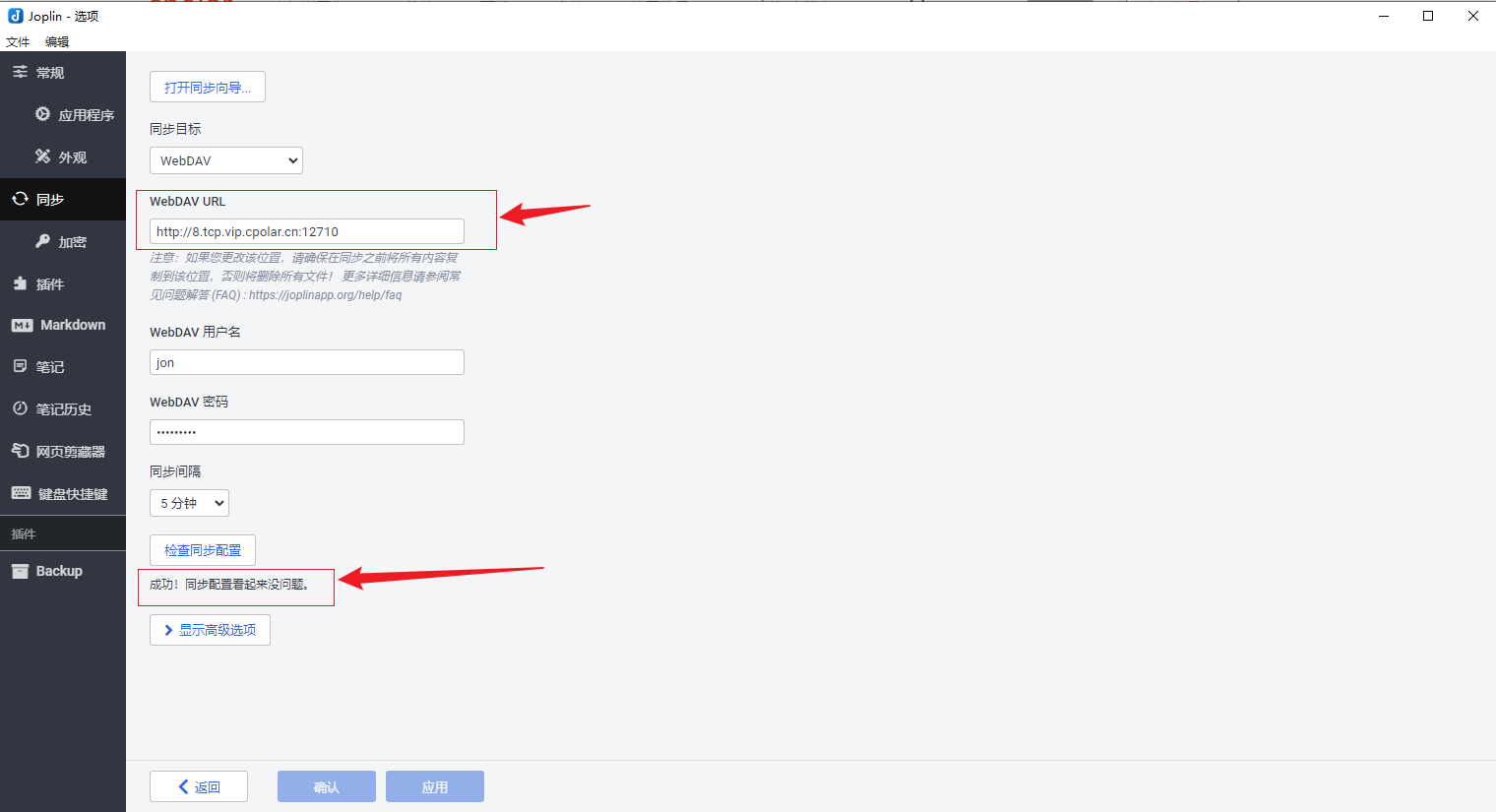
群晖NAS如何通过WebDAV和内网穿透实现Joplin笔记远程同步
文章目录 前言1. 检查群晖Webdav 服务2. 本地局域网IP同步测试3. 群晖安装Cpolar工具4. 创建Webdav公网地址5. Joplin连接WebDav6. 固定Webdav公网地址7. 公网环境连接测试 前言 在数字化浪潮的推动下,笔记应用已成为我们记录生活、整理思绪的重要工具。Joplin&…...

2025届最火的十大AI写作平台实际效果
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 在这个信息呈现爆炸态势的时代当中,内容创作已然变成了个人以及企业所具备的核心…...

为内部工具集成AI能力时选择Taotoken作为统一接口层
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为内部工具集成AI能力时选择Taotoken作为统一接口层 当企业开发团队着手为多个内部系统,例如客户关系管理(…...

告别3389端口暴露:零信任防火墙重塑RDP安全访问新范式
1. 传统RDP安全方案的致命短板 每次看到服务器日志里那些密密麻麻的暴力破解尝试记录,我的后颈都会发凉。作为从业十年的运维老兵,我见过太多因为3389端口暴露引发的安全事故。有个客户的数据库服务器,明明设置了16位复杂密码,还是…...

输入输出:iostream 为什么不是 printf 的替代品
文章目录引言一、printf 的优雅与致命缺陷1.1 printf 为什么好用1.2 三个致命缺陷二、iostream 的哲学:类型安全 可扩展2.1 基本用法2.2 标准流一览2.3 输入:cin 为什么比 scanf 安全三、自定义类型的输出:让 printf 永远做不到的事四、格式…...
)
用Wireshark抓包实战,手把手教你读懂LwIP里的TCP/IP数据帧(附真实数据解析)
Wireshark与LwIP实战:从抓包数据到协议栈实现的深度解析 当你第一次在Wireshark中看到那些密密麻麻的十六进制数据时,是否感到无从下手?作为嵌入式开发者,理解网络数据包的底层结构不仅是调试网络问题的关键,更是优化L…...

从stakpak/paks看现代软件包管理:不可变、声明式与分层架构实践
1. 项目概述:从“stakpak/paks”看现代软件包管理的演进最近在折腾一个老项目的依赖管理,又被各种版本冲突和依赖地狱搞得焦头烂额。这让我想起了几年前第一次接触stakpak/paks这个项目时的情景。当时,它更像是一个前沿的探索,试图…...

ClawForgeAI:基于工作流编排的AIGC创意自动化平台解析
1. 项目概述:从“ClawForgeAI/clawforge”看AI驱动的创意工具新范式最近在GitHub上看到一个挺有意思的项目,叫“ClawForgeAI/clawforge”。光看这个名字,你可能会有点摸不着头脑——“ClawForge”听起来像是个游戏模组工具或者某种机械设计软…...

Web无障碍性自动化检查:CLI工具集成与工程实践指南
1. 项目概述:一个为开发者赋能的Web无障碍性CLI工具 如果你是一名前端开发者、测试工程师,或者正在构建一个需要服务广泛用户群体的Web应用,那么“无障碍性”(Accessibility, 常缩写为 a11y)这个词对你来说…...

在扁平化组织里,技术人如何建立“非职权影响力”?
一、为什么测试人更需要非职权影响力软件测试工程师的岗位设置本身就带有一种结构性矛盾:你对产品质量负责,却很少拥有对等的决策权。开发写代码,你找bug;产品定需求,你验证逻辑;项目经理排期,你…...

PlantUML Editor:用代码思维重塑UML绘图的现代工具
PlantUML Editor:用代码思维重塑UML绘图的现代工具 【免费下载链接】plantuml-editor PlantUML online demo client 项目地址: https://gitcode.com/gh_mirrors/pl/plantuml-editor 你是否厌倦了传统拖拽式UML工具的繁琐操作?PlantUML Editor将彻…...