通过多层混合MTL结构提升股票市场预测的准确性,R²最高为0.98
“Boosting the Accuracy of Stock Market Prediction via Multi-Layer Hybrid MTL Structure”
论文地址:https://arxiv.org/pdf/2501.09760


摘要
本研究引入了一种创新的多层次混合多任务学习架构,致力于提升股市预测的效能。此架构融合了Transformer编码器、双向门控循环单元(BiGRU)以及Kolmogorov-Arnold网络(KAN)。据实验结果表明,相较于其他模型,该架构在预测准确度方面表现更佳,其平均绝对误差(MAE)可低至1.078,平均绝对百分比误差(MAPE)最小达到0.012,决定系数(R²)最高为0.98。
简介
股票市场预测对投资者和企业来说极为关键,但因数据的复杂性,传统统计模型如ARMA、ARIMA和GARCH等在效果上存在局限。相比之下,机器学习技术在股票预测方面表现更优,特别是深度学习方法(例如卷积神经网络和递归神经网络)展示了更强大的学习能力。传统方法通常忽略了不同股票间的相互关系,而引入空间维度可以改进预测精度,图神经网络(GNN)在这方面已被采用。Transformer模型通过注意力机制能有效捕捉复杂的关联性,但在处理长序列和高维数据时面临挑战。KAN(知识增强网络)利用边函数参数替代传统的权重设置,提高了对非线性函数的逼近能力。集成学习策略在金融预测领域中表现出明显优势,本研究提出的算法可作为集成学习框架的一部分。该研究介绍了一种结合了Transformer编码器、双向门控循环单元(BiGRU)与KAN的多层混合多任务学习框架,旨在提升股票市场预测的效率及准确性。
01相关工作
股票市场趋势预测对于学术研究和实际操作都极为重要。预测手段涵盖了从传统统计方法到先进的机器学习模型。过去,传统方法在该领域占据主导地位,然而,随着神经网络和深度学习等机器学习算法的兴起,这一状况正在发生变化。通过结合传统技术与现代方法,混合模型能够提供更高的预测精度和稳定性。
传统方法
传统股票市场预测方法涉及时间序列模型和隐马尔可夫模型(HMM)。Devi等人率先应用ARIMA模型来预测市场趋势,Khanderwal指出ARIMA更适合短期预测。Marisetty等人则采用GARCH模型研究了五大金融指数的波动性,表明GARCH是进行波动性预测的理想选择。Gupta等人提出了基于HMM的最大后验估计器,用于预测次日股票价格,并发现其性能优于ARIMA和ANN模型。Su等人将HMM从传统的离散形式扩展到连续形式,以更好地适应股票价格趋势的预测。
然而,由于传统统计方法本质上具有线性特征,它们在股价剧烈波动的情况下表现不佳。为解决这一问题,Mattera等人引入了动态网络自回归条件异方差(ARCH)模型,以提高处理高维输入数据时的股票预测准确性。
机器学习方法
机器学习,特别是神经网络模型,在股票价格预测方面展现了最高的准确性。例如,Vijh等人利用人工神经网络和随机森林来预测五家公司的次日收盘价。在处理复杂的非线性数据时,深度学习方法显示出比传统技术更优的性能。尤其是在股票指数预测中,LSTM单输入模型的表现超过了传统的机器学习模型。此外,采用多变量的深度学习方法能够更精准地预测股市波动。Tang等人开发的基于小波变换的LSTM模型,通过使用多维数据输入,实现了72.19%的准确率。Deep等人提出的多因子分析模型,整合了技术分析、基本面分析、机器学习以及情感分析,其表现超越了单一因子的模型。
混合方法
混合学习模型通过整合多种预测技术来提高准确性和减少过拟合。首次提出的集成模型是在2001年,Abraham等人开发了结合神经模糊逻辑和人工神经网络的早期混合模型,展现了出色的预测性能和趋势分析能力。Shah等人的研究考察了多种股票价格预测手段,认为融合统计方法与机器学习技术的混合策略更为有效。Shui-Ling等人设计了一种新的ARIMA-RNN混合模型,解决了单一模型在波动性预测和神经网络过拟合方面的局限。Zhang等人提出的ARIMA-CNN-LSTM模型在股票指数预测上提供了卓越的准确度和稳定性。Tian等人研发的多层次双向LSTM-BO-LightGBM模型则在股票价格波动预测中表现出更强的逼近能力和泛化性能。Lv等人提出的CEEMDAN-DAE-LSTM混合模型引入了特征提取模块DAE,增强了对波动性股票指数的预测效果。
研究显示,集成学习模型在处理复杂动态数据集时显著提升了预测精度,凸显了持续发展混合模型的重要性,以适应市场变化和技术进步的需求。
02方法
问题定义
本方法旨在开发一个映射函数 f(A),以进行股票价格预测。输入 A 包含多个特征 x m,而输出则是预测值 f(A)。目标是使该预测值尽可能地接近实际值。
多层混合MTL结构概览
此框架集成了多维金融数据以提高预测准确性,输入数据包括开盘价、收盘价、最低价、最高价、交易量和交易金额。该结构由Transformer编码器、KAN层和BiGRU层组成,能够有效处理高维数据并捕捉各特征间的关系。KAN层旨在优化学习过程,提炼出有意义的数据表示,而BiGRU层则专注于捕捉金融时间序列中的长期依赖关系,同时考虑历史和未来的信息。

通过多任务学习,模型不仅能预测交易量和交易金额,还能利用共享的潜在表示增强股票预测的效果。整个框架的目标是提供精确且稳定的预测结果,以应对金融市场固有的复杂性。

Transformer编码器层

Transformer编码器层由两个主要子层构成:多头自注意力机制和全连接前馈网络,每个子层都包含残差连接和层归一化。在多头自注意机制中,输入向量X被转换为查询(Q)、键(K)和值(V)向量,并行处理多个独立的注意力计算。
![]()
![]()
每个注意力头独立地计算其注意力权重,采用缩放点积的方法来确定,最终输出是这些加权值向量的总和。所有头部的结果会被拼接在一起,并通过一个线性变换以生成最终输出。使用4个注意力头可以提升预测准确性,同时增强模型识别复杂模式的能力。

![]()
前馈网络包括两个线性变换及一个ReLU激活函数,有助于提高模型捕捉非线性特征的能力。Add/Normalize层则利用层归一化与残差连接结合的方式,帮助缓解梯度消失或爆炸的问题。
![]()
Detailed KAN层

Li等人将Kolmogorov-Arnold定理的应用扩展到了机器学习领域,开发了KAN神经网络结构。在KAN中,激活函数被设置在边而不是节点上,这使得它能够学习自适应的非线性函数,并允许通过细化节点来提升逼近精度。实验显示,KAN在处理平滑及非线性函数时表现出色,其收敛速度更快,特别是在高维数据方面优于传统的多层感知器(MLP)。
KAN采用单变量函数参数代替传统权重参数,每个节点直接汇总这些函数的输出值,无需进行非线性变换。这种方法特别适用于时间序列预测,与传统的MLP相比,它提供了更高的预测准确性。
![]()
Detailed BiGRU层
BiGRU模型是一种利用双向GRU进行多变量时间序列预测的方法,能够有效捕捉数据中的双向依赖关系及多变量间的相互作用。该模型包含两个GRU网络:一个负责从前往后处理序列数据,另一个则从后往前处理。最终的隐藏状态是通过将这两个方向上的隐藏状态拼接而获得的。这些隐藏状态随后会经过一个全连接层,并使用Softmax激活函数来生成输出结果。

![]()
![]()
03实验
实验设置
为了评估提出方法的有效性,实验分为两部分进行:一是与多种先进方法的比较,二是利用五种已知模型(KAN、Transformer、BiGRU、KAN-BiGRU、Transformer-KAN)进行消融实验。实验的目的在于全面检验所提出的模型在股票价格预测方面的性能和鲁棒性。输入特征涵盖了开盘价、收盘价、最高价和最低价,目标是精确预测未来多个时间步长的各项指标值。
评估指标
使用四个指标来评估模型性能:平均绝对误差(MAE)、均方根误差(RMSE)、平均绝对百分比误差(MAPE)和决定系数(R²)。
- MAE:用于测量预测值与实际值之间的平均绝对差异,数值越小表示模型的预测能力越强。

- RMSE:通过将误差转换回原始数据单位,使得误差更易于理解。
![]()
- MAPE:是一种相对误差度量标准,适合用于不同数据集之间模型性能的比较,其值越低表明预测准确性越高。

- R²:衡量的是自变量能够解释的方差比例,反映出模型对输入数据的拟合程度。

结果
本方法在0-50和120-200时间步区间内与实际值高度吻合,误差低于其他方法。相比之下,其他方法在这些区间往往出现滞后或偏差,无法准确捕捉整体趋势及变化的关键点。特别是在识别局部的高低点(例如40-60和170-200时间步)时,本方法显示出显著的优势,能够有效减少噪声干扰。

模型在处理高频波动区域时表现出良好的稳定性,能够有效地过滤噪声,使得预测曲线更加平滑,更接近真实值。具体而言,在RMSE指标上达到了39.820,相比Hemajothi等人的研究减少了17.2%,这表明了更强的鲁棒性以及对大幅波动和异常值的有效管理能力。R²值为0.977,相较于Gao等人和Hemajothi等人的工作分别提高了4.2%和3.1%,证明了该模型在捕捉短期变动和长期趋势方面的优越表现。尽管MAE和MAPE也有改进,但RMSE和R²的提升尤为关键,这证实了该方法在控制误差和检测趋势上的卓越性能,非常适合复杂、带噪声及非线性的数据序列预测任务。



消融分析
多层混合MTL结构在股票市场预测中展现了出色的预测精度和稳定性,超越了KAN、Transformer、BiGRU等模型。特别是在高频波动区域,其他模型的预测容易受到噪声的影响,而本方法生成的曲线更加平滑,与实际值保持高度一致。

在关键拐点(例如50-70和170-200时间步)的捕捉上,本方法显示出了更高的敏感性和准确性,相比之下,其他模型可能会出现预测滞后或过拟合的问题。对于趋势恢复区间(如150-250时间步),其他模型的预测曲线显示出较大的波动,而本方法能有效过滤噪声,维持稳定表现。

本方法在RMSE指标上达到了21.004,比最佳的Transformer-BiGRU模型低39.7%,同时R²值为0.968,这表明它在复杂数据环境下具有卓越的鲁棒性和趋势捕捉能力。尽管引入Transformer编码器和KAN层增加了模型的时间复杂度,但我们的模型在推理效率方面有了显著提升。通过交叉验证得出的平均测试R²为0.9831,进一步证实了结果的高度可靠性。



04总结
本文介绍了一种多层混合多任务学习(MTL)结构,旨在应对股价预测中的高波动性、复杂性和动态变化。该框架整合了增强型Transformer编码器进行特征提取,使用BiGRU来捕捉长时间的依赖关系,并通过KAN优化学习过程。
实验结果表明,这种学习网络在MAE上最低可达到0.45,R²最高可达0.98,体现了其出色的鲁棒性和预测准确性。研究结果证实了采用互补学习技术来捕捉复杂关系并提升预测性能的有效性。此框架为未来的股市预测研究和实际应用提供了一个前景广阔的新方法。

相关文章:
通过多层混合MTL结构提升股票市场预测的准确性,R²最高为0.98
“Boosting the Accuracy of Stock Market Prediction via Multi-Layer Hybrid MTL Structure” 论文地址:https://arxiv.org/pdf/2501.09760 摘要 本研究引入了一种创新的多层次混合多任务学习架构,致力于提升股市预测的效能。此架构融…...

java将list转成树结构
首先是实体类 public class DwdCusPtlSelectDto {//idprivate String key;//值private String value;//中文名private String title;private List<DwdCusPtlSelectDto> children;private String parentId;public void addChild(DwdCusPtlSelectDto child) {if(this.chil…...

互联网分布式ID解决方案
业界实现方案 1. 基于UUID 2. 基于DB数据库多种模式(自增主键、segment) 3. 基于Redis 4. 基于ZK、ETCD 5. 基于SnowFlake 6. 美团Leaf(DB-Segment、zkSnowFlake) 7. 百度uid-generator() 基于UUID生成唯一ID UUID生成策略 推荐阅读 DDD领域驱动与微服务架构设计设计模…...

xinference 安装(http导致错误解决)
为什么要使用xinference 安装xinference 环境 1)conda create -n Xinference python3.11 注意:3.9 3.10均可能出现xinference 安装时候出现numpy兼容性,以及无法安装all版本 错误: error while attempting to bind on address&am…...

334递增的三元子序列贪心算法(思路解析+源码)
文章目录 题目思路解析源码总结题目 思路解析 有两种解法:解法一:动态规划(利用dp找到数组最长递增序列长度,判断是否大于3即可)本题不适用,因为时间复杂度为O(n^2),超时。 解法二:贪心算法:解法如上图,题目要求长度为三,设置第一个元素为长度1的值,是指长度二的…...

【Linux】29.Linux 多线程(3)
文章目录 8.4 生产者消费者模型8.4.1 为何要使用生产者消费者模型8.4.2 生产者消费者模型优点 8.5 基于BlockingQueue的生产者消费者模型8.5.1 C queue模拟阻塞队列的生产消费模型 8.6. 为什么pthread_cond_wait 需要互斥量?8.7 条件变量使用规范8.8 条件变量的封装8.9 POSIX信…...

利用UNIAPP实现短视频上下滑动播放功能
在 UniApp 中实现一个短视频上下滑动播放的功能,可以使用 swiper 组件来实现滑动效果,并结合 video 组件来播放短视频。以下是一个完整的示例,展示如何在 UniApp 中实现这一功能。 1. 创建 UniApp 项目 如果你还没有创建 UniApp 项目,可以使用 HBuilderX 创建一个新的项目…...

vscode+CMake+Debug实现 及权限不足等诸多问题汇总
环境说明 有空再补充 直接贴两个json tasks.json {"version": "2.0.0","tasks": [{"label": "cmake","type": "shell","command": "cmake","args": ["../"…...

【提示词工程】探索大语言模型的参数设置:优化提示词交互的技巧
在与大语言模型(Large Language Model, LLM)进行交互时,提示词的设计和参数设置直接影响生成内容的质量和效果。无论是通过 API 调用还是直接使用模型,掌握模型的参数配置方法都至关重要。本文将为您详细解析常见的参数设置及其应用场景,帮助您更高效地利用大语言模型。 …...

基于 .NET 8.0 gRPC通讯架构设计讲解,客户端+服务端
目录 1.简要说明 2.服务端设计 2.1 服务端创建 2.2 服务端设计 2.3 服务端业务模块 3.客户端设计-控制台 4.客户端设计-Avalonia桌面程序 5.客户端设计-MAUI安卓端程序 1.简要说明 gRPC 一开始由 google 开发,是一款语言中立、平台中立、开源的远程过程调用…...

6.Centos7上部署flask+SQLAlchemy+python+达梦数据库
情况说明 前面已经介绍了window上使用pycharm工具开发项目时,window版的python连接达梦数据库需要的第三方包。 这篇文章讲述,centos7上的python版本连接达梦数据库需要的第三方包。 之前是在windows上安装达梦数据库的客户端,将驱动包安装到windows版本的python中。(开…...

【C语言系列】深入理解指针(5)
深入理解指针(5) 一、sizeof和strlen的对比1.1sizeof1.2strlen1.3sizeof和strlen的对比 二、数组和指针笔试题解析2.1 一维数组2.2 字符数组2.2.1代码1:2.2.2代码2:2.2.3代码3:2.2.4代码4:2.2.5代码5&#…...

mysql自连接 处理层次结构数据
MySQL 的自连接(Self Join)是一种特殊的连接方式,它允许一个表与自身进行连接。自连接通常用于处理具有层次结构或递归关系的数据,或者当同一张表中的数据需要相互关联时。以下是几种常见的场景,说明何时应该使用自连接…...

##__VA_ARGS__有什么作用
##__VA_ARGS__ 是 C/C 中宏定义(Macro)的一种特殊用法,主要用于可变参数宏(Variadic Macros)的场景,解决当可变参数为空时可能导致的语法错误问题。以下是详细解释: 核心作用 消除空参数时的多余…...
返回不到上个页面)
鸿蒙 router.back()返回不到上个页面
1. 检查页面栈(Page Stack) 鸿蒙的路由基于页面栈管理,确保上一个页面存在且未被销毁。 使用 router.getLength() 检查当前页面栈长度: console.log(当前页面栈长度: ${router.getLength()}); 如果结果为 1,说明没有上…...

深度学习模型蒸馏技术的发展与应用
随着人工智能技术的快速发展,大型语言模型和深度学习模型在各个领域展现出惊人的能力。然而,这些模型的规模和复杂度也带来了显著的部署挑战。模型蒸馏技术作为一种优化解决方案,正在成为连接学术研究和产业应用的重要桥梁。本文将深入探讨模…...

STM32G0B1 ADC DMA normal
目标 ADC 5个通道,希望每1秒采集一遍; CUBEMX 配置 添加代码 #define ADC1_CHANNEL_CNT 5 //采样通道数 #define ADC1_CHANNEL_FRE 3 //单个通道采样次数,用来取平均值 uint16_t adc1_val_buf[ADC1_CHANNEL_CNT*ADC1_CHANNEL_FRE]; //传递…...

<tauri><rust><GUI>基于rust和tauri,在已有的前端框架上手动集成tauri示例
前言 本文是基于rust和tauri,由于tauri是前、后端结合的GUI框架,既可以直接生成包含前端代码的文件,也可以在已有的前端项目上集成tauri框架,将前端页面化为桌面GUI。 环境配置 系统:windows 10 平台:visu…...
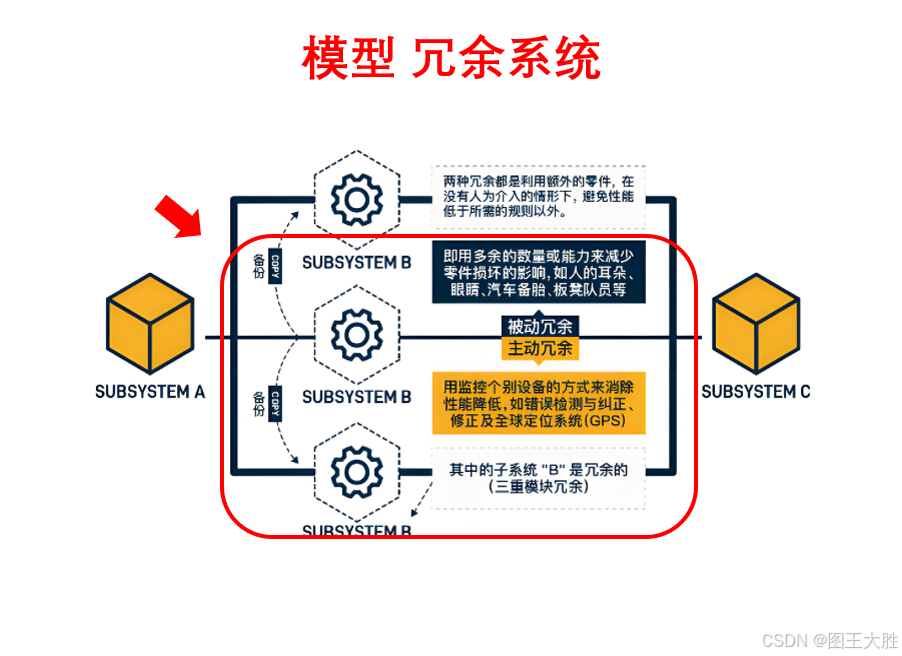
模型 冗余系统(系统科学)
系列文章分享模型,了解更多👉 模型_思维模型目录。为防故障、保运行的备份机制。 1 冗余系统的应用 1.1 冗余系统在企业管理中的应用-金融行业信息安全的二倍冗余技术 在金融行业,信息安全是保障业务连续性和客户资产安全的关键。随着数字化…...

Deepseek部署的模型参数要求
DeepSeek 模型部署硬件要求 模型名称参数量显存需求(推理)显存需求(微调)CPU 配置内存要求硬盘空间适用场景DeepSeek-R1-1.5B1.5B4GB8GB最低 4 核(推荐多核)8GB3GB低资源设备部署,如树莓派、旧…...
)
告别手动建模!用ArcGIS+SWMM+慧天平台,5步搞定城市内涝模拟(附实战数据)
城市内涝模拟实战:ArcGISSWMM慧天平台高效协同工作流 暴雨过后街道成河、地下车库变泳池的场景,已成为许多城市规划者和工程师的噩梦。传统的内涝模拟方法需要手动处理海量管网数据,不仅耗时费力,还容易在数据转换过程中丢失关键信…...

2026年十大主流需求管理工具深度测评:哪款更适合你的研发团队?
在软件研发日益复杂化、团队协作边界不断拓展的今天,需求管理不仅是产品经理的基本功,更是整个产品生命周期管理的“神经中枢”。你是否经历过这些问题:版本上线后,发现遗漏了某个关键需求?需求记录散落在 Excel、微信…...

【Claude Kubernetes配置终极指南】:20年SRE亲授生产环境零失误部署的7大黄金法则
更多请点击: https://intelliparadigm.com 第一章:Claude Kubernetes配置的核心理念与演进脉络 Claude 并非原生 Kubernetes 组件,而是 Anthropic 推出的大型语言模型系列;当将其部署于 Kubernetes 集群时,“Claude K…...

MemOS:为AI智能体构建统一记忆操作系统,提升长期对话与RAG性能
1. 项目概述:MemOS,为AI智能体装上“记忆大脑” 如果你正在开发基于大语言模型的AI智能体,或者在使用RAG(检索增强生成)技术,那么你一定遇到过这个核心痛点: 对话上下文太短,智能体…...

从零部署noVNC:一次完整的远程桌面服务搭建与排错实录
1. 为什么选择noVNC? 最近在帮朋友部署远程桌面服务时,发现很多传统VNC方案都需要安装客户端,操作复杂不说,兼容性还差。直到发现了noVNC这个神器,它直接用浏览器就能访问远程桌面,彻底解决了跨平台访问的痛…...

AI智能体安全策略引擎:AgentEnforcer框架设计与实战应用
1. 项目概述:一个为AI智能体量身定制的“行为守门员” 最近在折腾AI智能体(Agent)的开发,尤其是在构建那些需要自主执行任务、与外部API交互的复杂系统时,一个核心痛点总是挥之不去: 如何确保智能体的行为…...

避坑指南:ESP32-C3蓝牙通信中ESP_GATTS_READ_EVT事件的正确理解与数据更新时机
ESP32-C3蓝牙GATT通信中的数据更新陷阱与实战解决方案 当你在ESP32-C3上实现蓝牙GATT通信时,是否遇到过这样的困惑:明明在ESP_GATTS_READ_EVT事件中更新了特征值,但客户端读取到的却总是旧数据?这个看似简单的现象背后,…...

收藏!AI黄金三年,小白也能入局的5大高薪岗位解析
文章分析了AI应用与智能体时代的就业趋势,指出AI正重塑各岗位能力结构并创造新职业。未来三年,企业对AI应用工程师、AIAgent设计师、AI自动化运营、AI产品经理及RAG应用构建等岗位需求激增,这些岗位门槛相对较低但薪资可观。文章强调…...

从丝杆到直线电机:半导体运动台驱动技术演进与选型指南
1. 半导体运动台驱动技术的核心挑战 在半导体制造领域,运动平台就像精密仪器的心脏,每一次跳动都关乎生产效率和产品质量。想象一下,光刻机要在指甲盖大小的芯片上绘制比头发丝还细的电路,这相当于让一台卡车在足球场上精准停到误…...

Apple Mail自动化增强:JXA脚本与快捷指令提升邮件处理效率
1. 项目概述:一个为Apple Mail打造的现代化邮件客户端如果你和我一样,日常工作高度依赖邮件,并且是macOS生态的深度用户,那么Apple Mail(邮件.app)大概率是你的主力工具。它简洁、与系统深度集成、iCloud同…...