深度学习-神经机器翻译模型
以下为你介绍使用Python和深度学习框架Keras(基于TensorFlow后端)实现一个简单的神经机器翻译模型的详细步骤和代码示例,该示例主要处理英 - 法翻译任务。
1. 安装必要的库
首先,确保你已经安装了以下库:
pip install tensorflow keras numpy pandas
2. 代码实现
import numpy as np
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, LSTM, Dense# 示例数据,实际应用中应使用大规模数据集
english_sentences = ['I am a student', 'He likes reading books', 'She is very beautiful']
french_sentences = ['Je suis un étudiant', 'Il aime lire des livres', 'Elle est très belle']# 对输入和目标文本进行分词处理
input_tokenizer = Tokenizer()
input_tokenizer.fit_on_texts(english_sentences)
input_sequences = input_tokenizer.texts_to_sequences(english_sentences)target_tokenizer = Tokenizer()
target_tokenizer.fit_on_texts(french_sentences)
target_sequences = target_tokenizer.texts_to_sequences(french_sentences)# 获取输入和目标词汇表的大小
input_vocab_size = len(input_tokenizer.word_index) + 1
target_vocab_size = len(target_tokenizer.word_index) + 1# 填充序列以确保所有序列长度一致
max_input_length = max([len(seq) for seq in input_sequences])
max_target_length = max([len(seq) for seq in target_sequences])input_sequences = pad_sequences(input_sequences, maxlen=max_input_length, padding='post')
target_sequences = pad_sequences(target_sequences, maxlen=max_target_length, padding='post')# 定义编码器模型
encoder_inputs = Input(shape=(max_input_length,))
encoder_embedding = Dense(256)(encoder_inputs)
encoder_lstm = LSTM(256, return_state=True)
_, state_h, state_c = encoder_lstm(encoder_embedding)
encoder_states = [state_h, state_c]# 定义解码器模型
decoder_inputs = Input(shape=(max_target_length,))
decoder_embedding = Dense(256)(decoder_inputs)
decoder_lstm = LSTM(256, return_sequences=True, return_state=True)
decoder_outputs, _, _ = decoder_lstm(decoder_embedding, initial_state=encoder_states)
decoder_dense = Dense(target_vocab_size, activation='softmax')
decoder_outputs = decoder_dense(decoder_outputs)# 定义完整的模型
model = Model([encoder_inputs, decoder_inputs], decoder_outputs)# 编译模型
model.compile(optimizer='rmsprop', loss='sparse_categorical_crossentropy')# 训练模型
model.fit([input_sequences, target_sequences[:, :-1]], target_sequences[:, 1:],epochs=100, batch_size=1)# 定义编码器推理模型
encoder_model = Model(encoder_inputs, encoder_states)# 定义解码器推理模型
decoder_state_input_h = Input(shape=(256,))
decoder_state_input_c = Input(shape=(256,))
decoder_states_inputs = [decoder_state_input_h, decoder_state_input_c]
decoder_outputs, state_h, state_c = decoder_lstm(decoder_embedding, initial_state=decoder_states_inputs)
decoder_states = [state_h, state_c]
decoder_outputs = decoder_dense(decoder_outputs)
decoder_model = Model([decoder_inputs] + decoder_states_inputs,[decoder_outputs] + decoder_states)# 实现翻译函数
def translate_sentence(input_seq):states_value = encoder_model.predict(input_seq)target_seq = np.zeros((1, 1))target_seq[0, 0] = target_tokenizer.word_index['<start>'] # 假设存在 <start> 标记stop_condition = Falsedecoded_sentence = ''while not stop_condition:output_tokens, h, c = decoder_model.predict([target_seq] + states_value)sampled_token_index = np.argmax(output_tokens[0, -1, :])sampled_word = target_tokenizer.index_word[sampled_token_index]decoded_sentence += ' ' + sampled_wordif (sampled_word == '<end>' orlen(decoded_sentence) > max_target_length):stop_condition = Truetarget_seq = np.zeros((1, 1))target_seq[0, 0] = sampled_token_indexstates_value = [h, c]return decoded_sentence# 测试翻译
test_input = input_tokenizer.texts_to_sequences(['I am a student'])
test_input = pad_sequences(test_input, maxlen=max_input_length, padding='post')
translation = translate_sentence(test_input)
print("Translation:", translation)
3. 代码解释
- 数据预处理:使用
Tokenizer对英文和法文句子进行分词处理,将文本转换为数字序列。然后使用pad_sequences对序列进行填充,使所有序列长度一致。 - 模型构建:
- 编码器:使用LSTM层处理输入序列,并返回隐藏状态和单元状态。
- 解码器:以编码器的状态作为初始状态,使用LSTM层生成目标序列。
- 全连接层:将解码器的输出通过全连接层转换为目标词汇表上的概率分布。
- 模型训练:使用
fit方法对模型进行训练,训练时使用编码器输入和部分解码器输入来预测解码器的下一个输出。 - 推理阶段:分别定义编码器推理模型和解码器推理模型,通过迭代的方式生成翻译结果。
4. 注意事项
- 此示例使用的是简单的示例数据,实际应用中需要使用大规模的平行语料库,如WMT数据集等。
- 可以进一步优化模型,如使用注意力机制、更复杂的网络结构等,以提高翻译质量。
相关文章:

深度学习-神经机器翻译模型
以下为你介绍使用Python和深度学习框架Keras(基于TensorFlow后端)实现一个简单的神经机器翻译模型的详细步骤和代码示例,该示例主要处理英 - 法翻译任务。 1. 安装必要的库 首先,确保你已经安装了以下库: pip insta…...

.NET周刊【2月第1期 2025-02-02】
国内文章 dotnet 9 已知问题 默认开启 CET 导致进程崩溃 https://www.cnblogs.com/lindexi/p/18700406 本文记录 dotnet 9 的一个已知且当前已修问题。默认开启 CET 导致一些模块执行时触发崩溃。 dotnet 使用 ColorCode 做代码着色器 https://www.cnblogs.com/lindexi/p/…...
【合集】Java进阶——Java深入学习的笔记汇总 amp; 再论面向对象、数据结构和算法、JVM底层、多线程
前言 spring作为主流的 Java Web 开发的开源框架,是Java 世界最为成功的框架,持续不断深入认识spring框架是Java程序员不变的追求;而spring的底层其实就是Java,因此,深入学习Spring和深入学习Java是硬币的正反面&…...

GPU、CUDA 和 cuDNN 学习研究【笔记】
分享自己在入门显存优化时看过的一些关于 GPU 和 CUDA 和 cuDNN 的网络资料。 更多内容见: Ubuntu 22.04 LTS 安装 PyTorch CUDA 深度学习环境-CSDN博客CUDA 计算平台 & CUDA 兼容性【笔记】-CSDN博客 文章目录 GPUCUDACUDA Toolkit都包含什么?NVID…...

【5】阿里面试题整理
[1]. 介绍一下ZooKeeper ZooKeeper是一个开源的分布式协调服务,核心功能是通过树形数据模型(ZNode)和Watch机制,解决分布式系统的一致性问题。 它使用ZAB协议保障数据一致性,典型场景包括分布式锁、配置管理和服务注…...

计算机毕业设计hadoop+spark+hive物流预测系统 物流大数据分析平台 物流信息爬虫 物流大数据 机器学习 深度学习
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 作者简介:Java领…...
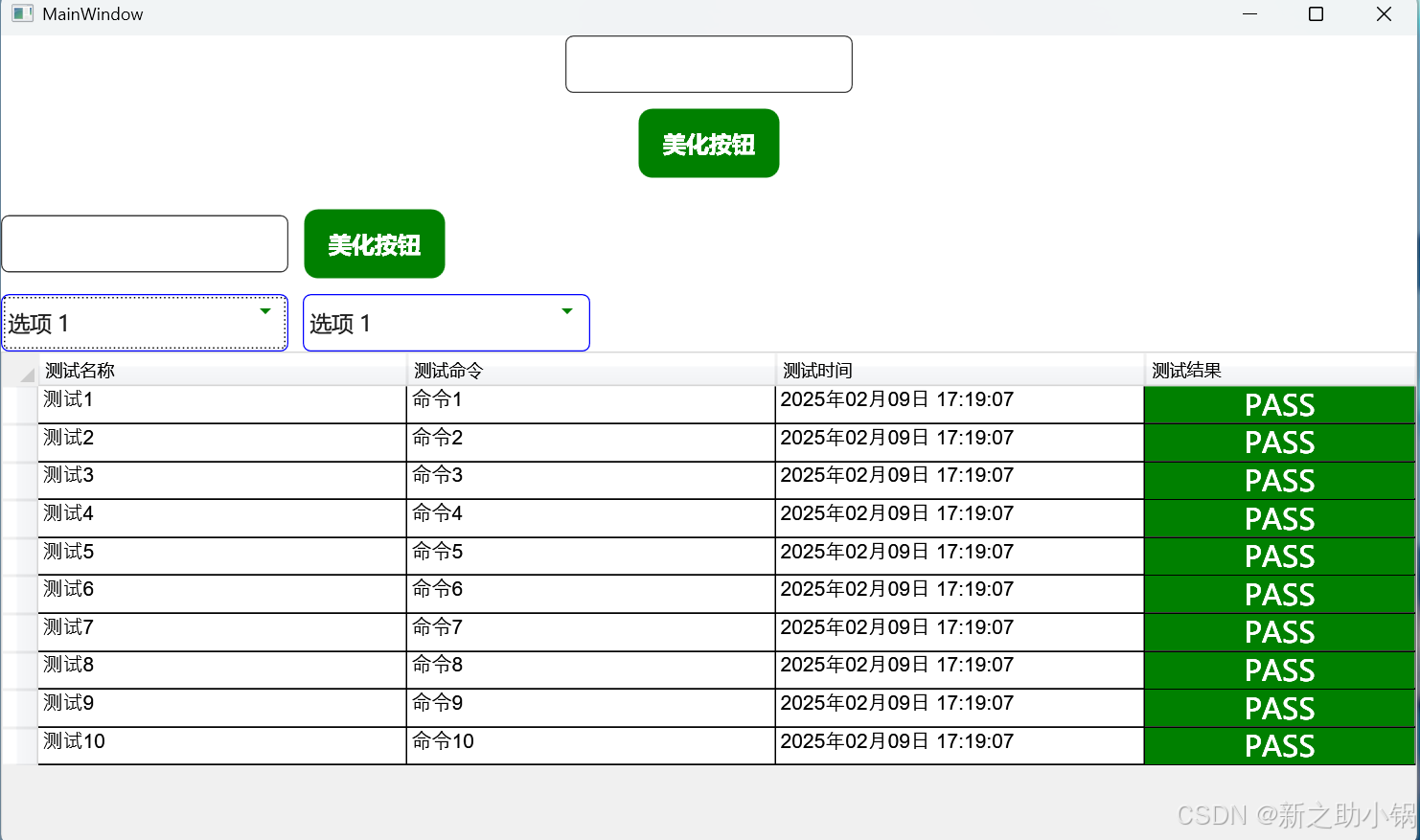
Wpf美化按钮,输入框,下拉框,dataGrid
Wpf美化按钮,输入框,下拉框,dataGrid 引用代码后 引用资源 <ControlTemplate x:Key"CustomProgressBarTemplate" TargetType"ProgressBar"><Grid><Border x:Name"PART_Track" CornerRadius&q…...

搜索插入位置:二分查找的巧妙应用
问题描述 给定一个已排序的整数数组 nums 和一个目标值 target,要求在数组中找到目标值并返回其索引。如果目标值不存在于数组中,则返回它按顺序插入的位置。必须使用时间复杂度为 O(log n) 的算法。 示例: 示例1: 输入: nums …...

Cocos2d-x 游戏开发-打包apk被默认自带了很多不必要的权限导致apk被报毒,如何在Cocos 2d-x中强制去掉不必要的权限-优雅草卓伊凡
Cocos2d-x 游戏开发-打包apk被默认自带了很多不必要的权限导致apk被报毒,如何在Cocos 2d-x中强制去掉不必要的权限-优雅草卓伊凡 实战操作 去除权限 要在 Cocos2d-x 开发的游戏中去掉 APK 自带权限,可以按照以下步骤操作: 编辑 AndroidMa…...

自动化xpath定位元素(附几款浏览器xpath插件)
在 Web 自动化测试、数据采集、前端调试中,XPath 仍然是不可或缺的技能。虽然 CSS 选择器越来越强大,但面对复杂 DOM 结构时,XPath 仍然更具灵活性。因此,掌握 XPath,不仅能提高自动化测试的稳定性,还能在爬…...

String类(6)
大家好,今天我们继续来学习一下String类的查找方法,主要是反向查找的一些方法。 ⭐️从后往前找一样的道理,如果找到了就返回对应字符的下标. 如果后面有对应的字符,则会返回第一个遇到的字符下标. ⭐️注意一下传入字符串的找法…...

动态表格html
题目: 要求: 1.表格由专业班级学号1-10号同学的信息组成,包括:学号、姓 名、性别、二级学院、班级、专业、辅导员; 2.表格的奇数行字体为黑色,底色为白色;偶数行字体为白色,底 色为黑…...
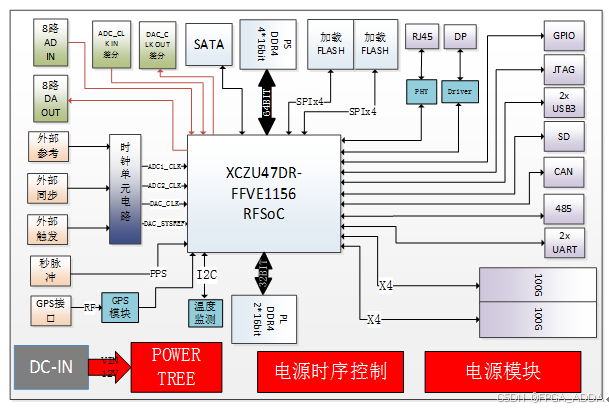
ZU47DR 100G光纤 高性能板卡
简介 2347DR是一款最大可提供8路ADC接收和8路DAC发射通道的高性能板卡。板卡选用高性价比的Xilinx的Zynq UltraScale RFSoC系列中XCZU47DR-FFVE1156作为处理芯片(管脚可以兼容XCZU48DR-FFVE1156,主要差别在有无FEC(信道纠错编解码࿰…...
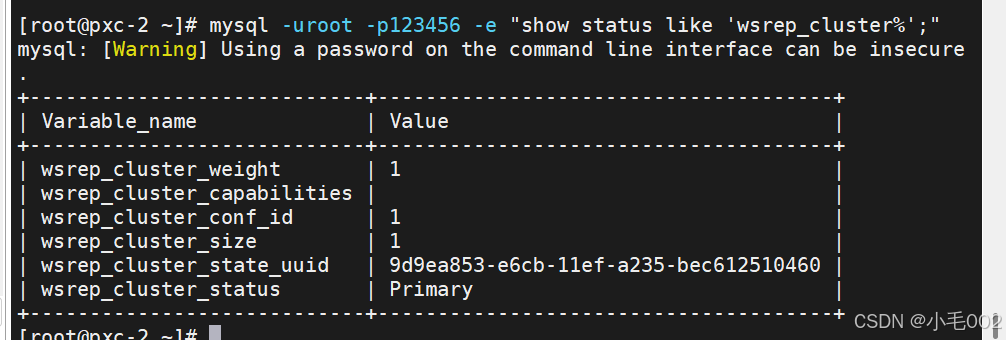
mysql8.0使用pxc实现高可用
环境准备 准备三台虚拟机,其对应的主机名和IP地址为 pxc-1192.168.190.129pxc-2192.168.190.133pxc-3192.168.190.134 解析,都要做解析 测试 下载pxc的安装包, 官网:https://www.percona.com/downloads 选择8.0的版本并下载,…...

Kotlin 使用 Chrome 无头浏览器
1. 概念 无头浏览器在类似于流行网络浏览器的环境中提供对网页的自动控制,但是通过命令行界面或使用网络通信来执行。 它们对于测试网页特别有用,因为它们能够像浏览器一样呈现和理解超文本标记语言,包括页面布局、颜色、字体选择以及JavaSc…...
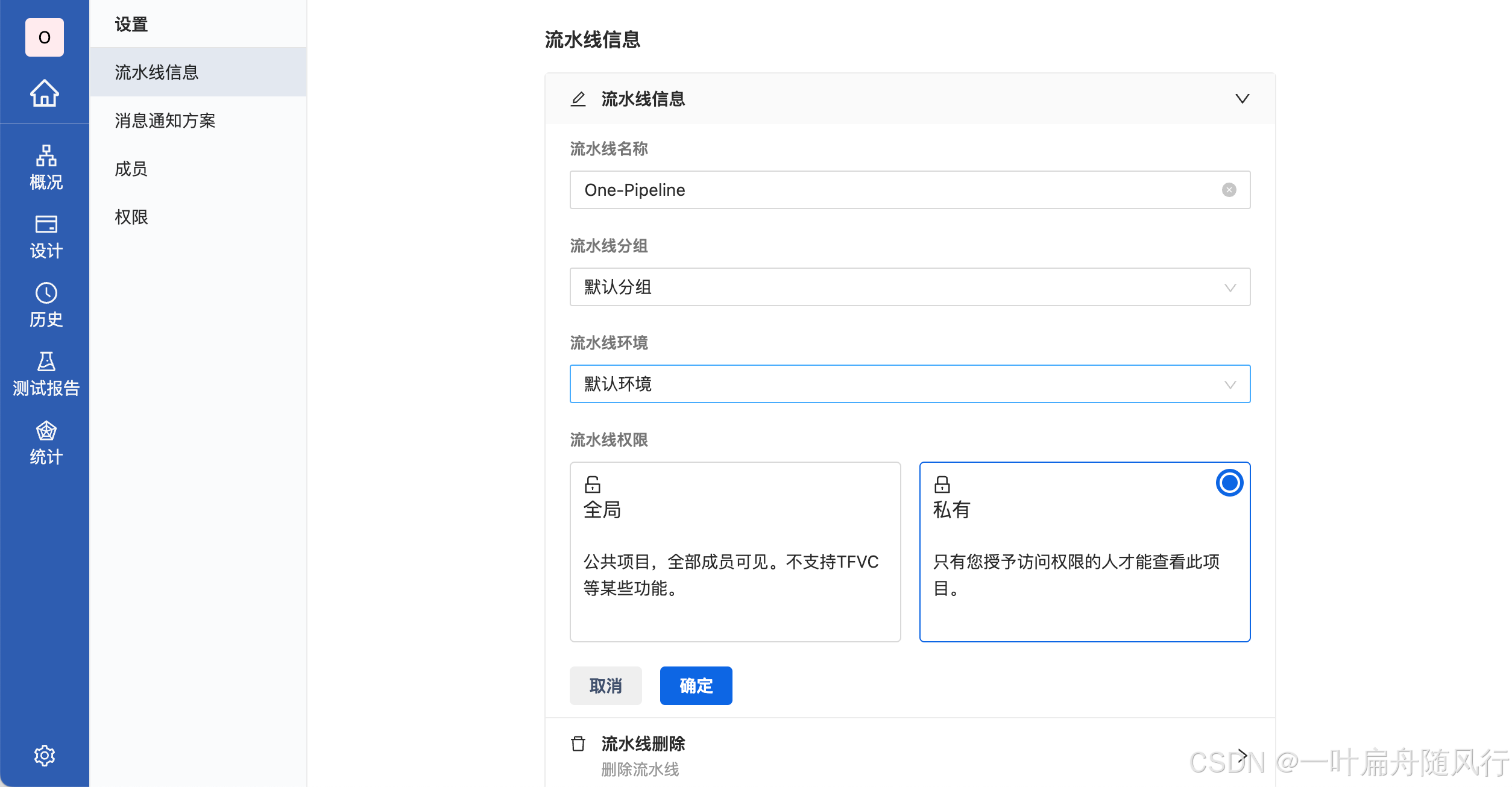
Arbess基础教程-创建流水线
Arbess(谐音阿尔卑斯) 是一款开源免费的 CI/CD 工具,本文将介绍如何使用 Arbess 配置你的第一条流水线,以快速入门上手。 1. 创建流水线 根据不同需求来创建不同的流水线。 1.1 配置基本信息 配置流水线的基本信息,如分组,环境&…...
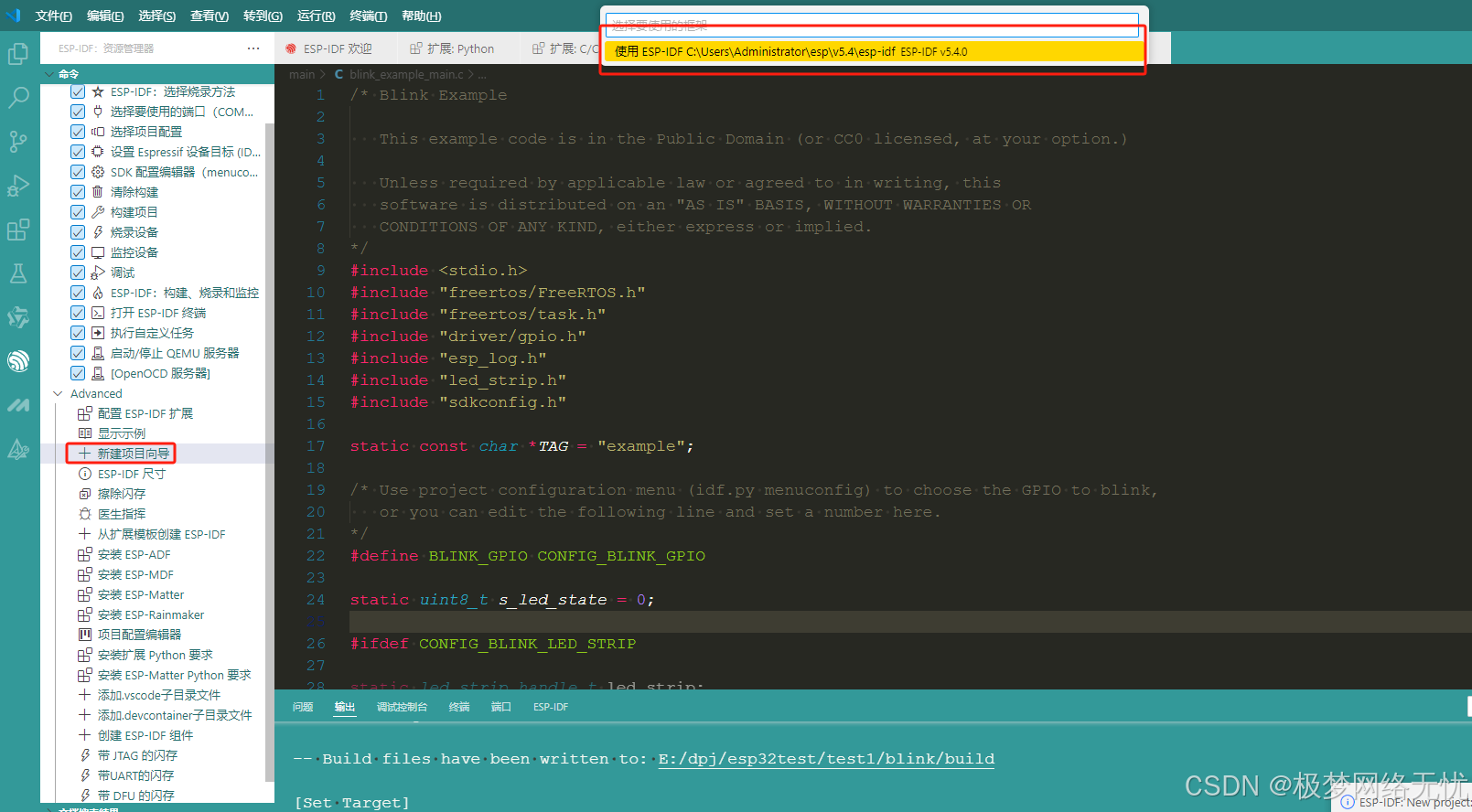
vscode安装ESP-IDF
引言 ESP-IDF(Espressif IoT Development Framework)是乐鑫官方为其 ESP32、ESP32-S 系列等芯片提供的物联网开发框架。结合 Visual Studio Code(VSCode)这一强大的开源代码编辑器,能极大提升开发效率。本教程将详细介…...
第31周:文献阅读
目录 摘要 Abstract 文献阅读 问题引入 研究背景 研究动机 创新点 动态预训练方法(DynPT) 深度循环神经网络(DRNN) 传感器选择 方法论 时间序列的动态预训练 异构传感器数据的DRNN 基于稀疏度的传感器过滤 实验研…...

GenAI + 电商:从单张图片生成可动态模拟的3D服装
在当今数字化时代,电子商务和虚拟现实技术的结合正在改变人们的购物体验。特别是在服装行业,消费者越来越期待能够通过虚拟试衣来预览衣服的效果,而无需实际穿戴。Dress-1-to-3 技术框架正是为此而生,它利用生成式AI模型(GenAI)和物理模拟技术,将一张普通的穿衣照片转化…...

进程(1)
1.什么是进程 要回答这个问题首先我们要解答什么是程序的问题。什么是程序呢?程序本质是就是存放在磁盘上的文件。我们要运行程序,首先必须要将其加载到内存中,这样才能与cpu交互,这是冯诺依曼体系架构所决定的。 程序运行起来后…...

Unity Il2CppDumper原理与实战:解析元数据与二进制对齐
1. 这不是“破解工具”,而是Unity开发者该懂的二进制真相课 你刚在Unity Asset Store下载了一个功能惊艳的插件,却在打包iOS后发现部分逻辑失效;或者接手一个没有源码的旧项目,只有一堆 .dll 和 .so 文件,连主入口…...

物理引导的机器学习工作流:气候建模的融合创新与实践
1. 项目概述:当气候建模遇见机器学习如果你像我一样,在气候模拟这个领域摸爬滚打超过十年,就会深刻体会到一种“甜蜜的负担”:我们构建的地球系统模型(ESM)越来越精细,物理过程越来越复杂&#…...

从电磁炉到户外电源:拆解单相SVPWM如何让你的逆变器更安静、更高效
从电磁炉到户外电源:单相SVPWM如何实现静音与高效的双重突破当你深夜用电磁炉煮面时,是否曾被突然的蜂鸣声吓一跳?或是发现户外电源给设备充电时,散热风扇的噪音盖过了山林鸟鸣?这些常见问题背后,隐藏着一个…...

RevSSH反向SSH隧道:无公网IP设备的安全远程运维方案
1. 这不是又一个SSH封装工具——RevSSH解决的是“根本性连接悖论”你有没有遇到过这样的场景:一台部署在客户内网的嵌入式设备,没有公网IP,NAT穿透失败,防火墙策略死死锁住所有入向端口,连ICMP都被禁了;或者…...

如何在3分钟内为任何活动搭建专业级滚动抽奖系统?Magpie-LuckyDraw全平台开源方案深度解析
如何在3分钟内为任何活动搭建专业级滚动抽奖系统?Magpie-LuckyDraw全平台开源方案深度解析 【免费下载链接】Magpie-LuckyDraw 🏅A fancy lucky-draw tool supporting multiple platforms💻(Mac/Linux/Windows/Web/Docker) 项目地址: https…...

别再只比参数了!从插件生态到中文优化,聊聊ChatGPT和文心一言的“隐形”差异
超越参数之争:ChatGPT与文心一言的生态与本土化实战解析 当技术评测文章还在反复比较模型参数量与发布时间时,真正影响日常工作效率的往往是那些未被量化的"软实力"。本文将从插件生态构建与中文场景优化两个维度,带您重新认识这两…...

Lovable电商网站搭建:如何用不到3人技术团队,72小时内上线PCI-DSS合规MVP版本?
更多请点击: https://codechina.net 第一章:Lovable电商网站搭建 Lovable 是一个面向中小商户的轻量级电商解决方案,采用现代 Web 技术栈构建,强调可扩展性、用户体验与快速部署能力。本章将指导你从零开始搭建一个具备商品展示、…...

Xia Sql插件:可调试的SQL注入决策引擎
1. 这不是又一个“自动扫SQL”的插件,而是把渗透工程师的判断逻辑塞进了Burp里你有没有过这种经历:在Burp Proxy里看着一堆GET参数、POST JSON、Cookie字段,心里清楚“这里大概率能注入”,但手动拼payload试了七八轮,还…...

3步零基础掌握星露谷物语SMAPI模组加载器:高效管理你的模组世界
3步零基础掌握星露谷物语SMAPI模组加载器:高效管理你的模组世界 【免费下载链接】SMAPI The modding API for Stardew Valley. 项目地址: https://gitcode.com/gh_mirrors/smap/SMAPI SMAPI(Stardew Valley Modding API)是星露谷物语官…...
运营管理与服务保障平台建设方案)
低空旅游观光与低空通勤(eVTOL)运营管理与服务保障平台建设方案
本方案旨在为eVTOL载具构建集运营管理、空中交通管制、安全保障与乘客服务于一体的数字化平台。通过微服务架构、5G-A融合感知、空域网格化与零信任安全等核心技术,解决高密度飞行中的资源调度与安全冲突问题。目标实现毫秒级冲突解算与15分钟内快速周转,…...