xxl-job的分片广播
目录
xxl-job的分片广播
场景引入
xxl-job简介
xxl-job的部署安装
代码编写
1.导入依赖
2.yml文件编写
3.编写xxl-job执行器配置类,维护一个xxl-job执行器的bean
4.编写第一个任务,任务名字叫firstJob
5.进入服务端,增加执行器和任务
编辑 6.启动两个服务实例
7.执行任务
8.使用分片广播的任务(重点操作)
xxl-job的分片广播
这里分享以下xxl-job的分片广播的使用
场景引入
在分布式架构下,一个服务往往会部署多个实例来运行我们的业务,如果在这种分布式系统环境下运行任务调度,我们称之为分布式任务调度。
在单体项目中,可以直接使用SpringTask来完成,但如果在集群项目中,不同的项目之间无法知道任务的完成情况。那为什么要使用分布式集群项目,以下是分布式的优点:
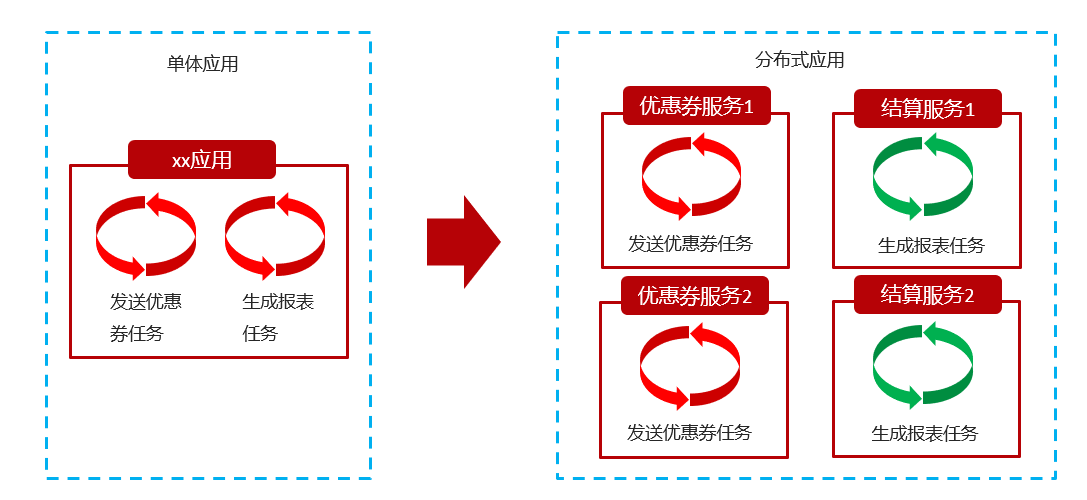
分布式系统的特点,并且提高任务的调度处理能力:
- 并行任务调度
-
- 集群部署单个服务,这样就可以多台计算机共同去完成任务调度,我们可以将任务分割为若干个分片,由不同的实例并行执行(这就是分片广播),来提高任务调度的处理效率。
- 高可用
-
- 若某一个实例宕机,不影响其他实例来执行任务。
- 弹性扩容
-
- 当集群中增加实例就可以提高并执行任务的处理效率。
- 任务管理与监测
-
- 对系统中存在的所有定时任务进行统一的管理及监测。
- 让开发人员及运维人员能够时刻了解任务执行情况,从而做出快速的应急处理响应。
xxl-job简介
XXL-JOB是一个分布式任务调度平台,其核心设计目标是开发迅速、学习简单、轻量级、易扩展。现已开放源代码并接入多家公司线上产品线,开箱即用。
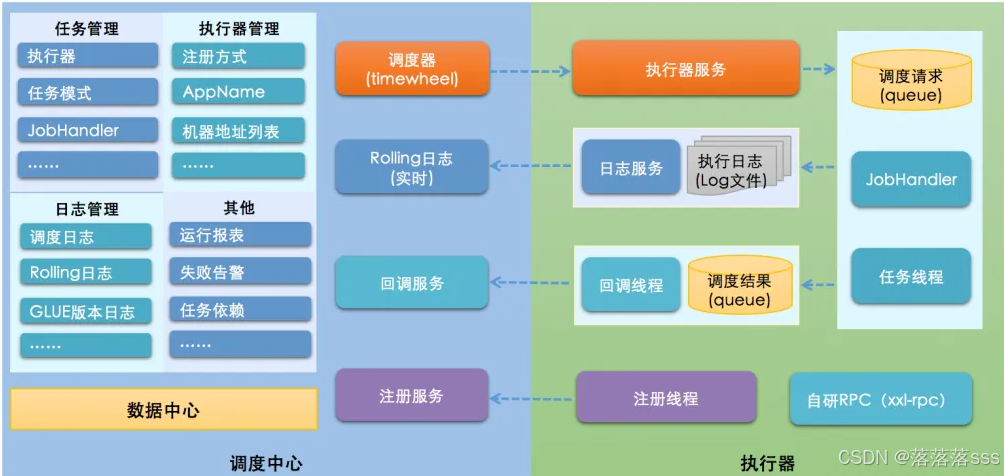
xxl-job的部署安装
xxl-job想要使用,需要安装admin服务端
这里我们在docker安装
docker run \
-e PARAMS="--spring.datasource.url=jdbc:mysql://192.168.150.101:3306/xxl_job?Unicode=true&characterEncoding=UTF-8 \
--spring.datasource.username=root \
--spring.datasource.password=123" \
--restart=always \
-p 28080:8080 \
-v xxl-job-admin-applogs:/data/applogs \
--name xxl-job-admin \
-d \
xuxueli/xxl-job-admin:2.3.0
- 默认端口映射到28080
- 日志挂载到/var/lib/docker/volumes/xxl-job-admin-applogs
- 通过PARAMS环境变量设置数据库链接参数
- 数据库脚本:doc/db/tables_xxl_job.sql · 许雪里/xxl-job - Gitee.com
xxl-job使用的8张表
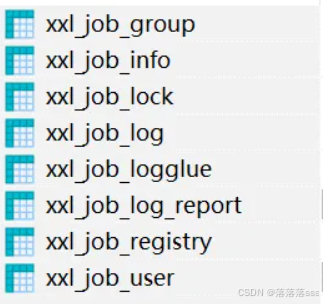
- xxl_job_lock:任务调度锁表;
- xxl_job_group:执行器信息表,维护任务执行器信息;
- xxl_job_info:调度扩展信息表: 用于保存XXL-JOB调度任务的扩展信息,如任务分组、任务名、机器地址、执行器、执行入参和报警邮件等等;
- xxl_job_log:调度日志表: 用于保存XXL-JOB任务调度的历史信息,如调度结果、执行结果、调度入参、调度机器和执行器等等;
- xxl_job_log_report:调度日志报表:用户存储XXL-JOB任务调度日志的报表,调度中心报表功能页面会用到;
- xxl_job_logglue:任务GLUE日志:用于保存GLUE更新历史,用于支持GLUE的版本回溯功能;
- xxl_job_registry:执行器注册表,维护在线的执行器和调度中心机器地址信息;
- xxl_job_user:系统用户表;
代码编写
1.导入依赖
<dependency><groupId>com.xuxueli</groupId><artifactId>xxl-job-core</artifactId></dependency>2.yml文件编写
application:version: v1.0
spring:application:name: sl-express-xxl-job
server:port: 9901
xxl:job:admin:addresses: http://192.168.150.101:28080/xxl-job-adminexecutor:ip: 192.168.150.1appname: ${spring.application.name}#执行器运行日志文件存储磁盘路径logpath: /data/applogs/xxl-job/jobhandler#执行器日志文件保存天数logretentiondays: 30这里我们设置了执行器的ip地址,让执行器与xxl-job的服务端同处一个网络下,让服务端可以扫描到这个执行器,这样一来我们就不用自己配置了。
3.编写xxl-job执行器配置类,维护一个xxl-job执行器的bean
@Configuration
public class XxlJobConfig {private Logger logger = LoggerFactory.getLogger(XxlJobConfig.class);@Value("${xxl.job.admin.addresses}")private String adminAddresses;@Value("${xxl.job.accessToken:}")private String accessToken;@Value("${xxl.job.executor.appname}")private String appname;@Value("${xxl.job.executor.address:}")private String address;@Value("${xxl.job.executor.ip:}")private String ip;@Value("${xxl.job.executor.port:0}")private int port;@Value("${xxl.job.executor.logpath:}")private String logPath;@Value("${xxl.job.executor.logretentiondays:}")private int logRetentionDays;@Beanpublic XxlJobSpringExecutor xxlJobExecutor() {logger.info(">>>>>>>>>>> xxl-job config init.");XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor();xxlJobSpringExecutor.setAdminAddresses(adminAddresses);xxlJobSpringExecutor.setAppname(appname);xxlJobSpringExecutor.setAddress(address);xxlJobSpringExecutor.setIp(ip);xxlJobSpringExecutor.setPort(port);xxlJobSpringExecutor.setAccessToken(accessToken);xxlJobSpringExecutor.setLogPath(logPath);xxlJobSpringExecutor.setLogRetentionDays(logRetentionDays);return xxlJobSpringExecutor;}}4.编写第一个任务,任务名字叫firstJob
@Component
public class JobHandler {private List<Integer> dataList = Arrays.asList(1, 2, 3, 4, 5);/*** 普通任务*/@XxlJob("firstJob")public void firstJob() throws Exception {System.out.println("firstJob执行了.... " + LocalDateTime.now());for (Integer data : dataList) {XxlJobHelper.log("data= {}", data);Thread.sleep(RandomUtil.randomInt(100, 500));}System.out.println("firstJob执行结束了.... " + LocalDateTime.now());}
}5.进入服务端,增加执行器和任务
增加执行器
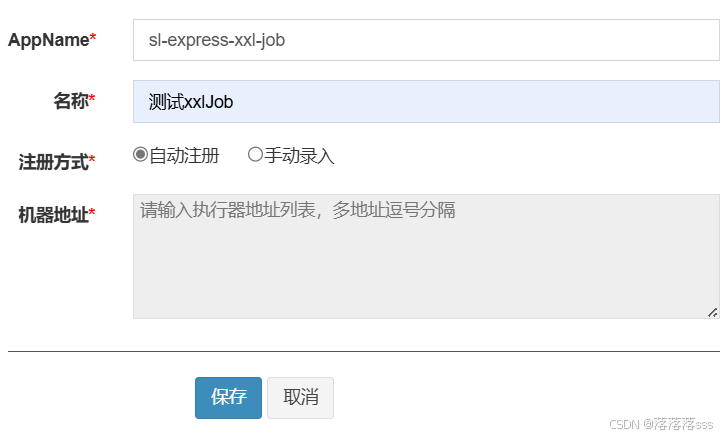
增加任务,我们这里先使用轮询策略
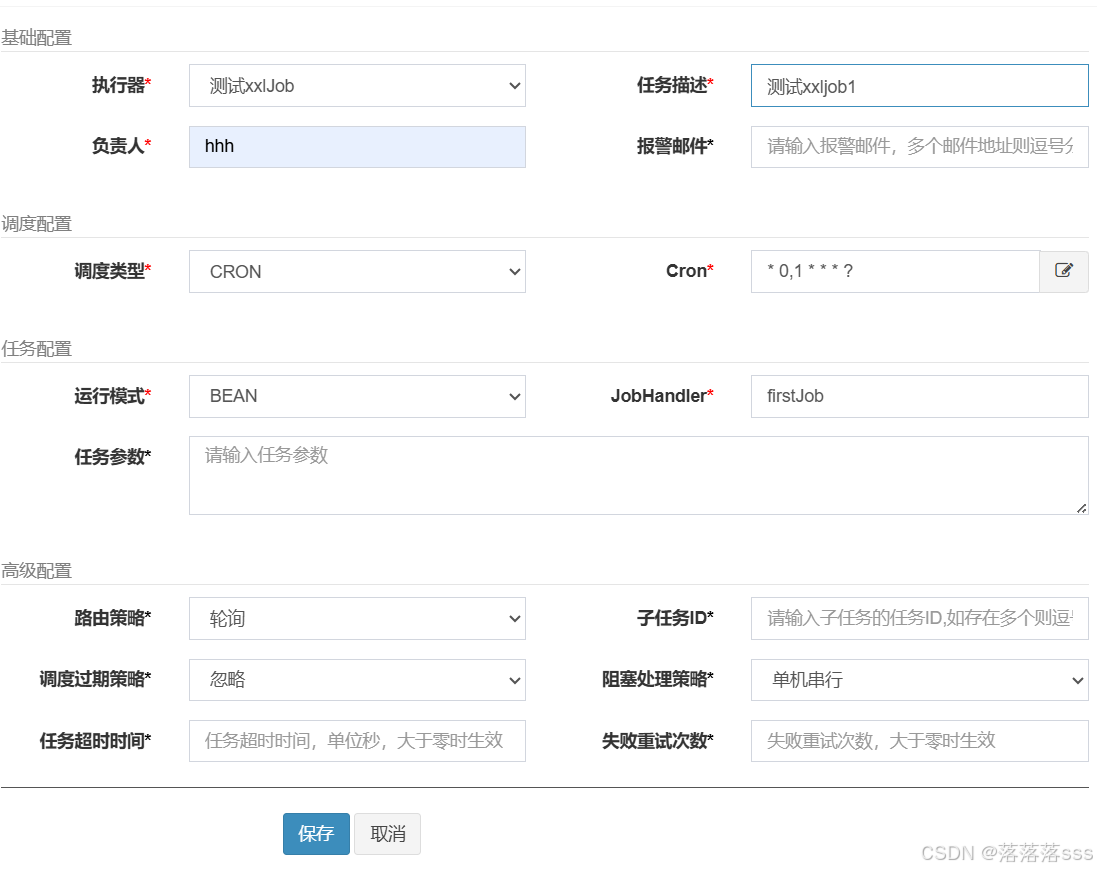 6.启动两个服务实例
6.启动两个服务实例
7.执行任务
第一个服务器把所有任务都执行了
 再执行一次,第二个服务器又把所有任务执行了
再执行一次,第二个服务器又把所有任务执行了
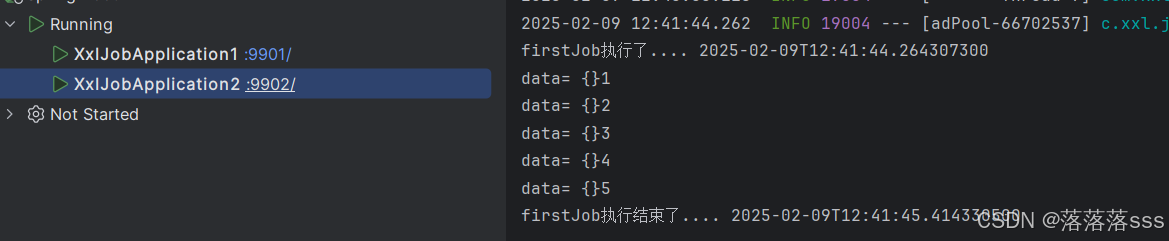
这样一来我们可以发现并没有把分布式的优势利用上,如果任务特别多,都是只让一个服务器(执行器)执行任务 ,效率十分低下,所以我们需要使用分片广播
8.使用分片广播的任务(重点操作)
/*** 分片式任务*/@XxlJob("shardingJob")public void shardingJob() throws Exception {// 分片参数// 分片节点总数int shardTotal = XxlJobHelper.getShardTotal();// 当前节点下标,从0开始int shardIndex = XxlJobHelper.getShardIndex();System.out.println("shardingJob执行了.... " + LocalDateTime.now());for (Integer data : dataList) {if (data % shardTotal == shardIndex) {System.out.println("data= {}"+ data);Thread.sleep(RandomUtil.randomInt(100, 500));}}System.out.println("shardingJob执行结束了.... " + LocalDateTime.now());}如何把任务分片给不同的服务器(执行器)呢,xxl-job给了两个方法
// 分片节点总数
int shardTotal = XxlJobHelper.getShardTotal();
// 当前节点下标,从0开始
int shardIndex = XxlJobHelper.getShardIndex();这两个方法分别获取了执行器的总数量,和当前执行器的下标,然后我们可以让任务的某一个唯一参数对总数量进行取模,最后让对应的执行器执行任务,这样一来就完成了任务的分片执行
任务选择分片广播
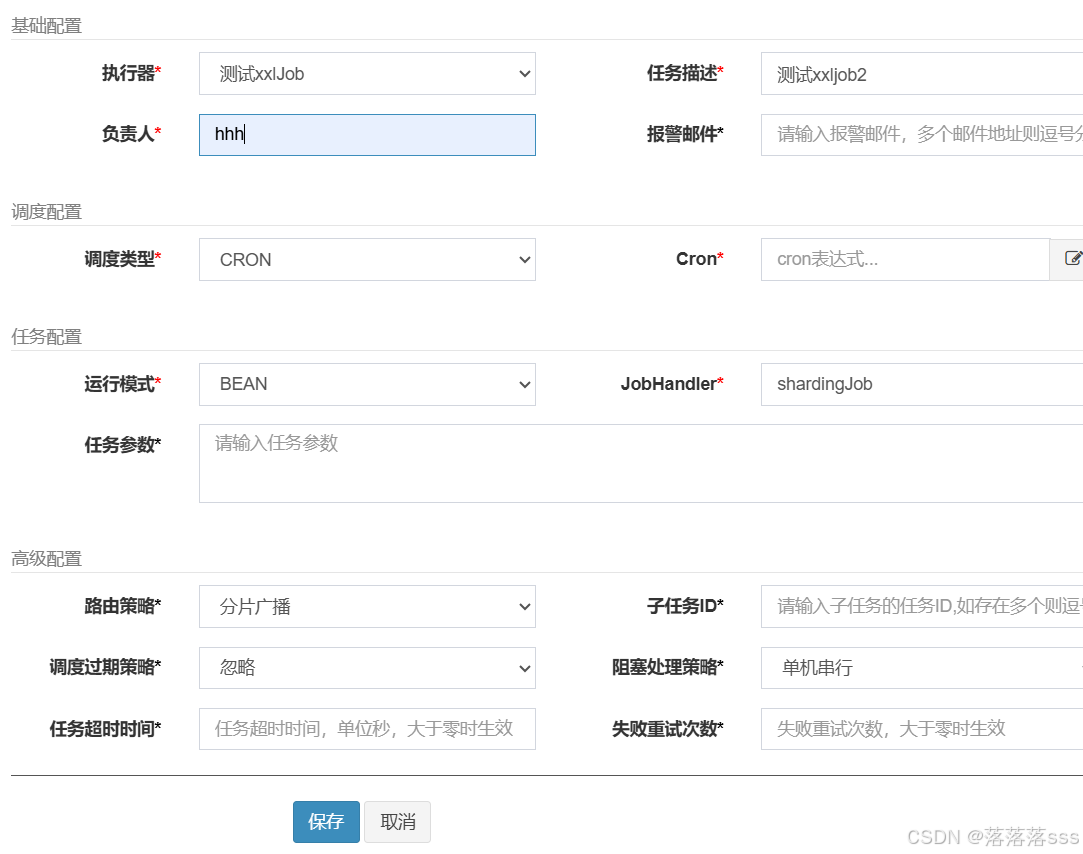
执行一次,任务成功完成分片


相关文章:
xxl-job的分片广播
目录 xxl-job的分片广播 场景引入 xxl-job简介 xxl-job的部署安装 代码编写 1.导入依赖 2.yml文件编写 3.编写xxl-job执行器配置类,维护一个xxl-job执行器的bean 4.编写第一个任务,任务名字叫firstJob 5.进入服务端,增加执行器和任务…...
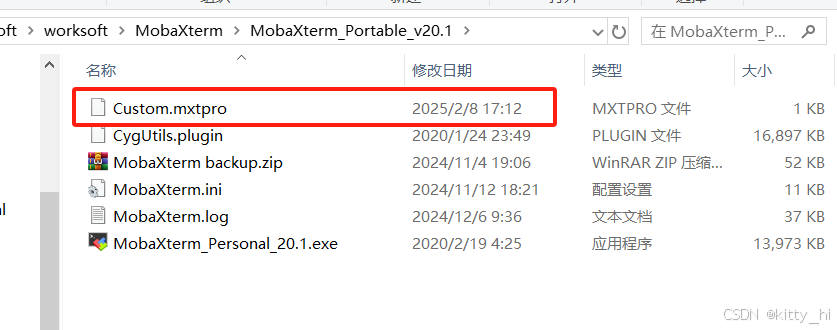
MobaXterm破解会话上限限制
1. 下载安装包MobaXterm-Keygen 下载路径: https://gitcode.com/gh_mirrors/mob/MobaXterm-Keygen 2. 搭建python3环境 window下python3环境搭建可参考网站: https://blog.csdn.net/enteracity/article/details/135479689 3. 生成文件Custom.mxtpro…...

vscode设置保存时自动缩进和格式化
参考博客 如何在 VSCode 中自动缩进你的代码 | Linux 中国 省流 使用 Ctrl Shift P 来打开命令模式,搜索 Open User Settings 并按下回车你需要搜索 Auto Indent,并在 “编辑器:自动缩进(Editor: Auto Indent)” 中选择 “全部(Full)”P…...

一键查看电脑各硬件详细信息 轻松查看电脑硬件参数
今天为大家推荐两款非常实用的电脑硬件查看软件,它们能够一键快速查看电脑的各种配置信息,使用起来非常方便。 一键查看电脑各硬件详细信息 这款软件是绿色版的,无需安装,打开即可使用,文件大小仅为900多KB࿰…...

【C++11】lambda和包装器
1.新的类功能 1.1默认的移动构造和移动赋值 原来C类中,有6个默认成员函数:构造函数/析构函数/拷⻉构造函数/拷⻉赋值重载/取地址重 载/const 取地址重载,最后重要的是前4个,后两个⽤处不⼤,默认成员函数就是我们不写…...

react redux用法学习
参考资料: https://www.bilibili.com/video/BV1ZB4y1Z7o8 https://cn.redux.js.org/tutorials/essentials/part-5-async-logic AI工具:deepseek,通义灵码 安装相关依赖: 使用redux的中间件: npm i react-reduxreact-…...

前端HTML标签 meta中常见的一些属性
meta中常见的一些属性 <meta/> 标签的属性 <meta/> 是什么? <meta/> 标签主要用于表示和当前文档相关的 元数据 信息。 而 元数据(metadata),简单的来说就是描述数据的数据。例如,一个 HTML 文件是一…...

127,【3】 buuctf [NPUCTF2020]ReadlezPHP
进入靶场 吓我一跳 查看源码 点击 审计 <?php// 定义一个名为 HelloPhp 的类,该类可能用于执行与日期格式化相关的操作 class HelloPhp {// 定义一个公共属性 $a,用于存储日期格式化的模板public $a;// 定义一个公共属性 $b,用于存储…...
)
继承(python)
一、基础知识 (一)定义:子类能继承父类所有的公有属性和公有方法(先使用子类的方法、属性) (二)格式: class 子类名(父类名): #父类 class Ph…...

驱动开发系列36 - Linux Graphics 2D 绘制流程
一: 概述 在Linux中,2D绘制流程是操作系统、图形库、显示协议、驱动程序等多个组件协调工作的结果。整体流程如下步骤所示: 1. 客户端请求:客户端程序(如GTK、Qt应用程序)通过X11协议与Xorg-Server通信(或通过Wayland协议与Wayland合成器通信)、请求绘制2D图形,比如绘制…...

STL函数算法笔记
STL函数算法笔记 今天我们来学习的是STL库中的一些函数。首先,STL这个东西大家一定非常熟悉,里面很多的数据结构都帮了大家不少忙,那么今天我们就来说几个重要的数据结构。 向量 向量,也就是数据结构vector,你也可以称之为动态数组,本质跟数组差不多,只不过有一些好处…...

【Vue】在Vue3中使用Echarts的示例 两种方法
文章目录 方法一template渲染部分js部分方法一实现效果 方法二template部分js or ts部分方法二实现效果 贴个地址~ Apache ECharts官网地址 Apache ECharts示例地址 官网有的时候示例显示不出来,属于正常现象,多进几次就行 开始使用前,记得先…...

小红书自动化:如何利用Make批量生成爆款笔记
小红书自动化:如何利用Make制作个人自媒体中心,批量生成爆款笔记 引言 在如今信息爆炸的时代,如何高效地获取和分享优质内容,成为了每位自媒体工作者必须面对的挑战。你是否想过,如果能够将这项繁复的工作实现自动化…...

学习率调整策略 | PyTorch 深度学习实战
前一篇文章,深度学习里面的而优化函数 Adam,SGD,动量法,AdaGrad 等 | PyTorch 深度学习实战 本系列文章 GitHub Repo: https://github.com/hailiang-wang/pytorch-get-started 本篇文章内容来自于 强化学习必修课:引…...

DeepSeekMoE 论文解读:混合专家架构的效能革新者
论文链接:DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models 目录 一、引言二、背景知识(一)MoE架构概述(二)现有MoE架构的问题 三、DeepSeekMoE架构详解(一&a…...

以下是基于巨控GRM241Q-4I4D4QHE模块的液位远程控制系统技术方案:
以下是基于巨控GRM241Q-4I4D4QHE模块的液位远程控制系统技术方案: 一、系统概述 本系统采用双巨控GRM241Q模块构建4G无线物联网络,实现山上液位数据实时传输至山下水泵站,通过预设逻辑自动控制水泵启停,同时支持APP远程监控及人工…...

【JVM详解五】JVM性能调优
示例: 配置JVM参数运行 #前台运行 java -XX:MetaspaceSize-128m -XX:MaxMetaspaceSize-128m -Xms1024m -Xmx1024m -Xmn256m -Xss256k -XX:SurvivorRatio8 - XX:UseConcMarkSweepGC -jar /jar包路径 #后台运行 nohup java -XX:MetaspaceSize-128m -XX:MaxMetaspaceS…...

2.10日学习总结
题目一: AC代码 #include <stdio.h>#define N 1000000typedef long long l;int main() {int n, m;l s 0;l a[N 1], b[N 1];int i 1, j 1;scanf("%d %d", &n, &m);for (int k 1; k < n; k) {scanf("%lld", &a[k]);…...
)
疯狂前端面试题(四)
一、Ajax、JSONP、JSON、Fetch 和 Axios 技术详解 1. Ajax(异步 JavaScript 和 XML) 什么是 Ajax? Ajax 是一种用于在不刷新页面的情况下与服务器进行数据交互的技术。它通过 XMLHttpRequest 对象实现。 优点 - 支持同步和异步请求。 - 能…...

YOLOv11-ultralytics-8.3.67部分代码阅读笔记-metrics.py
metrics.py ultralytics\utils\metrics.py 目录 metrics.py 1.所需的库和模块 2.def bbox_ioa(box1, box2, iouFalse, eps1e-7): 3.def box_iou(box1, box2, eps1e-7): 4.def bbox_iou(box1, box2, xywhTrue, GIoUFalse, DIoUFalse, CIoUFalse, eps1e-7): 5.def mas…...

从入门到上岗,Java+AI 复合型人才养成攻略
当下编程行业格局正在悄然改变,纯 Java 后端岗位内卷日趋严重,薪资增长逐步放缓;纯粹的 AI 算法岗门槛居高不下,对学历、数理功底要求严苛,普通开发者很难入局。 而Java+AI 复合型开发顺势成为行业刚需岗位,既依托成熟的 Java 体系承接业务开发,又能融入人工智能技术实…...

告别浪费!SolidWorks企业级共享方案,实现降本增效全攻略
还在为 SolidWorks 高昂的硬件投入和混乱的图纸管理头疼?告别“一人一机”的浪费模式,企业级共享方案才是降本增效的正解。这套攻略基于“1 台高性能服务器 云飞云共享云桌面”架构,帮你把硬件成本砍掉 60%,把软件利用率翻倍。一…...

内存占用3KB!极致瘦身释放MCU无限可能
极致小体积,给工业领域带来了无限的可能:更低硬件成本,更小芯片体积,更低功耗,更高可靠性,让每一颗小MCU都拥有大系统的完整能力。 https://www.bilibili.com/video/BV1eZLi6PEjc/?spm_id_from333.1387.ho…...

别再死记硬背了!用5个生活化比喻彻底搞懂Linux进程的fork、exec和wait
别再死记硬背了!用5个生活化比喻彻底搞懂Linux进程的fork、exec和wait想象你正在厨房准备一顿大餐。菜谱上写着"切菜"、"炒菜"、"装盘"等步骤,但突然发现需要同时处理多道菜品——这时候,你会本能地让家人分工…...

别被忽悠了!2026亲测靠谱的AI论文网站|避坑精选版
2026 年学术写作工具已高度分化,千笔AI与ThouPen为全流程首选,豆包、DeepSeek 为专项强手;避坑关键:拒绝假文献、严控 AIGC 率、优先国内适配、免费试用先行。 一、TOP3 全流程首选(亲测不踩雷) 1. 千笔AI&…...

厨房空调技术白皮书:从风冷到水冷,制冷系统在厨房场景中的工程化演进
厨房空调是暖通行业近三年技术迭代最密集的细分品类。从最初的"凉霸"(本质是风扇),到风冷分体式,再到水冷一体式,每代技术都在解决上一代没有覆盖的用户痛点。本文以工程技术视角,梳理四代厨房制…...

taotoken如何帮助ubuntu开发者应对大模型api的频繁更新与版本迭代
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken如何帮助Ubuntu开发者应对大模型API的频繁更新与版本迭代 对于在Ubuntu环境下进行开发的工程师而言,大模型API…...

【与我学 ClaudeCode】协作篇 之 Worktree + Task Isolation :目录隔离的并行执行通道
作者:逆境不可逃 技术永无止境 希望我的内容可以帮助到你!!!! 大家吼 ! 我是 逆境不可逃 今天给大家带来文章《【与我学 ClaudeCode】协作篇 之 Worktree Task Isolation :目录隔离的并行执行通道》. Le…...

不止于绘图:用GMT 6.4的`grdtrack`和`project`命令玩转地形剖面分析与可视化
不止于绘图:用GMT 6.4的grdtrack和project命令玩转地形剖面分析与可视化 当我们谈论地理空间分析时,很多人首先想到的是绘制精美的地图。但GMT(Generic Mapping Tools)的真正魅力在于它强大的地理计算能力。本文将带你超越基础绘图…...

别再乱建索引了!用Explain的key_len字段,一眼看穿你的MySQL联合索引到底生效了几个字段
解密MySQL联合索引:用key_len精准判断索引生效范围 在数据库性能优化领域,联合索引的使用一直是个既基础又容易踩坑的话题。很多开发者虽然知道"最左匹配原则"这个名词,但在实际业务场景中,面对复杂的查询条件组合时&a…...