Iceberg and AIStor 的Lakehouse Architecture 权威指南

Apache Iceberg 似乎已经掀起了一场(暴风雪)数据世界。它最初由 Ryan Blue(也是 Tabular 的成员,现在是 Databricks 的名人)在 Netflix 孵化,最终被传输到它目前所在的 Apache 软件基金会。从本质上讲,它是一种适用于大规模数据集(想想数百 TB 到数百 PB)的开放表格式。随着 AI 吞噬大量数据用于创建、调整和实时推理,自最初开发以来,对这项技术的需求只增不减。Iceberg 是一种多引擎兼容格式。这意味着 Spark、Trino、Flink、Presto、Snowflake 和 Dremio 都可以独立且同时地对同一数据集进行作。Iceberg 支持 SQL(数据分析的通用语言),并提供原子事务、架构演变、分区演变、时间旅行、回滚和零副本分支等高级功能。本文探讨了 Iceberg 的功能和设计与 AIStor 的高性能存储层搭配使用时,如何提供构建数据湖仓一体所需的灵活性和可靠性。
现代 Open Table 格式的目标
Lakehouse 的前景在于它能够统一最好的数据湖和仓库。存储在对象存储上的数据湖旨在以原生格式存储大量原始数据,从而提供可扩展性、易用性和成本效益。然而,数据湖本身就难以解决数据治理等问题,以及有效查询存储在其中的数据的能力。另一方面,仓库针对结构化数据和 SQL 分析进行了优化,但在大规模处理半结构化或非结构化数据方面存在不足。Iceberg 和其他开放表格式(如 Apache Hudi 和 Delta Lake)代表了一次飞跃。这些格式使数据湖的行为类似于仓库,同时保留了对象存储的初始灵活性和可扩展性。这种新的开放表格式和开放式存储堆栈可以支持各种工作负载,例如 AI、机器学习、高级分析和实时可视化。Iceberg 以其 SQL 优先的方法而著称,并专注于多引擎兼容性。
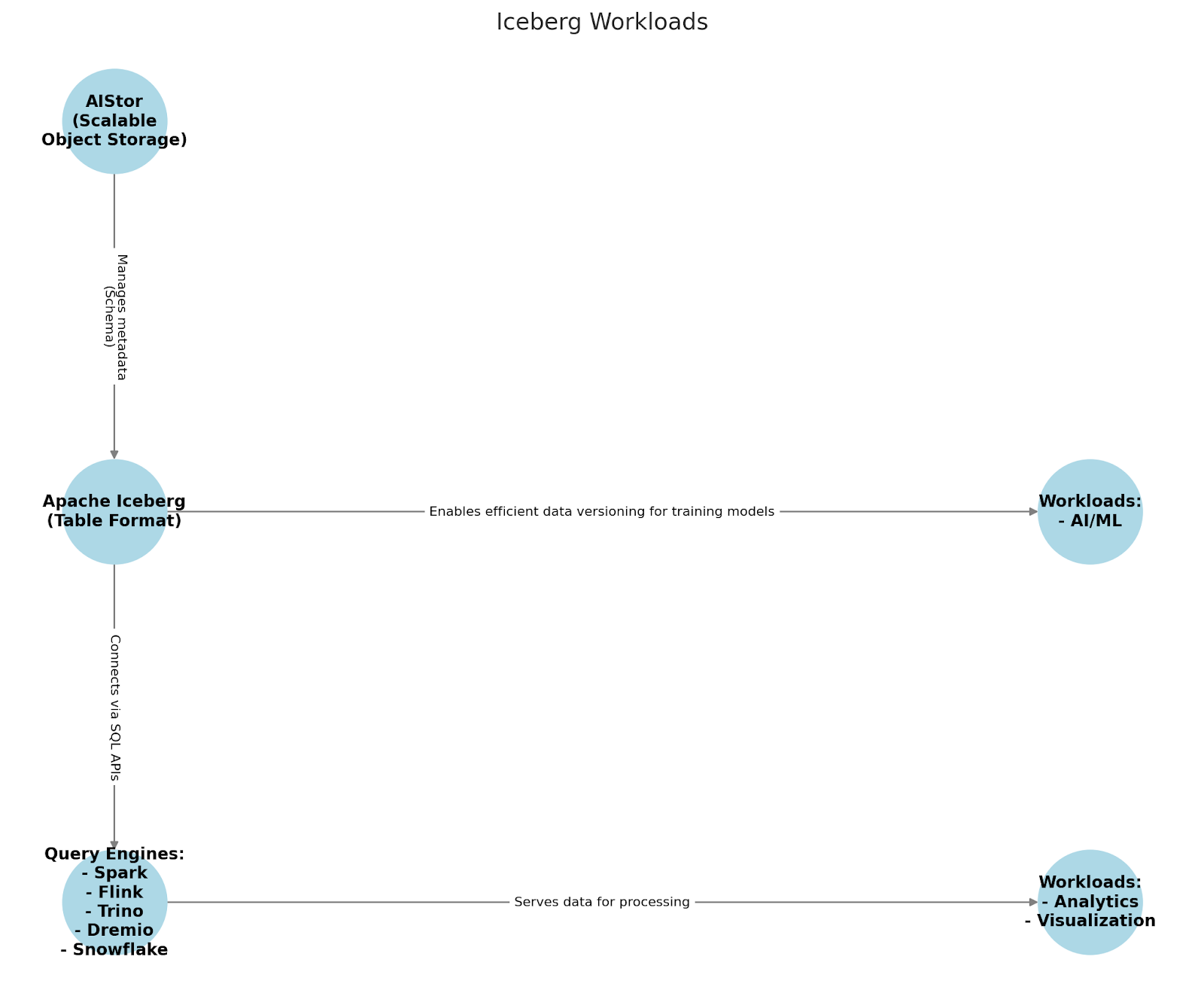
以下是此基础结构的运行方式。查询引擎可以直接位于堆栈中的对象存储之上,并查询其中的数据,而无需迁移。将数据迁移到 d 数据库存储的旧模式不再相关。相反,您可以而且应该能够从任何位置查询 Iceberg 表。分析工具和可视化通常可以直接连接到存储 Iceberg 表的存储,但更常见的是与您的查询引擎交互,以获得更简化的用户体验。最后,AI/ML 具有与查询引擎相同的设计原则。这些 AI/ML 工具将直接在对象存储中使用 Iceberg 表,而无需迁移。虽然目前并非所有 AI/ML 工具都使用 Iceberg,但人们对将 Iceberg 用于 AI/ML 工作负载的兴趣越来越大,特别是因为它们能够轻松维护多个版本的模型和数据集。
Iceberg 的特别之处
Apache Iceberg 通过功能和设计原则的组合将自己与它区分开来,使其与 Apache Hudi 和 Delta Lake 等替代品区分开来。
Schema Evolution:Iceberg 为 Schema Evolution 提供全面支持,允许用户添加、删除、更新或重命名列,而无需完全重写现有数据。这种灵活性确保可以无缝地实施对数据模型的更改,从而保持运营连续性。
分区演变:Iceberg 支持分区演变,允许随着时间的推移修改分区方案,而无需重写数据。此功能允许在访问模式发生变化时动态优化数据布局。
元数据管理:Iceberg 采用分层元数据结构,包括清单文件、清单列表和元数据文件。此设计通过提供有关数据文件的详细信息来增强查询规划和优化,从而促进高效的数据访问和管理。
多引擎兼容性:Iceberg 在设计时充分考虑了开放性,兼容 Apache Spark、Flink、Trino 和 Presto 等各种处理引擎。这种互作性使组织能够灵活地选择最适合其需求的工具,并有效地将查询引擎商品化,从而降低价格并推动这些产品的创新。
开源社区:与所有开放表格格式一样,Iceberg 受益于多元化和活跃的社区,这有助于其稳健性和持续改进。
对象存储和 Iceberg
对象存储构成了现代湖仓一体架构的基础,提供了跨多个环境管理大量数据集所需的可扩展性、持久性和成本效益。在湖仓一体架构中,存储层在确保数据的持久性和可用性方面起着关键作用,而像 Iceberg 这样的开放表格式则管理元数据。AIStor 特别适合这些要求。例如,对于模型训练等高吞吐量工作负载,AIStor 对 S3 over RDMA 的支持可确保对数据的低延迟访问。此功能使这两种技术的组合成为非常有效的解决方案,特别是对于大规模 AI 和分析管道。高性能对于湖仓一体计划的成功至关重要 - 如果您的表格式无法像用户需要的那样快速提供查询,那么它有多酷都无关紧要。
亲自尝试:先决条件
您需要安装 Docker 和 Docker Compose。当两者都需要时,安装 Docker Desktop 通常更容易。从 Docker 官方网站下载并安装 Docker Desktop。按照安装程序中提供的作系统安装说明进行作。打开 Docker Desktop 以确保其正在运行。如果您愿意,您还可以通过打开终端并运行以下命令来验证 Docker 和 Docker Compose 的安装:
docker --version
docker-compose --version
Iceberg 教程
本节演示了如何集成 Iceberg 和 AIStor 以实现强大的湖仓一体架构。我们将使用 Apache Iceberg Spark 快速入门来设置我们的初始环境:
第 1 步:使用 Docker Compose 进行设置
按照 Apache Iceberg Spark 快速入门指南启动预配置 Spark 和 Iceberg 的容器化环境。本指南的第一步是将以下信息复制到一个文件中,并另存为名为 docker-compose.yml 的文件:
version: "3"
services:spark-iceberg:image: tabulario/spark-icebergcontainer_name: spark-icebergbuild: spark/networks:iceberg_net:depends_on:- rest- miniovolumes:- ./warehouse:/home/iceberg/warehouse- ./notebooks:/home/iceberg/notebooks/notebooksenvironment:- AWS_ACCESS_KEY_ID=admin- AWS_SECRET_ACCESS_KEY=password- AWS_REGION=us-east-1ports:- 8888:8888- 8080:8080- 10000:10000- 10001:10001rest:image: apache/iceberg-rest-fixturecontainer_name: iceberg-restnetworks:iceberg_net:ports:- 8181:8181environment:- AWS_ACCESS_KEY_ID=admin- AWS_SECRET_ACCESS_KEY=password- AWS_REGION=us-east-1- CATALOG_WAREHOUSE=s3://warehouse/- CATALOG_IO__IMPL=org.apache.iceberg.aws.s3.S3FileIO- CATALOG_S3_ENDPOINT=http://minio:9000minio:image: minio/miniocontainer_name: minioenvironment:- MINIO_ROOT_USER=admin- MINIO_ROOT_PASSWORD=password- MINIO_DOMAIN=minionetworks:iceberg_net:aliases:- warehouse.minioports:- 9001:9001- 9000:9000command: ["server", "/data", "--console-address", ":9001"]mc:depends_on:- minioimage: minio/mccontainer_name: mcnetworks:iceberg_net:environment:- AWS_ACCESS_KEY_ID=admin- AWS_SECRET_ACCESS_KEY=password- AWS_REGION=us-east-1entrypoint: >/bin/sh -c "until (/usr/bin/mc config host add minio http://minio:9000 admin password) do echo '...waiting...' && sleep 1; done;/usr/bin/mc rm -r --force minio/warehouse;/usr/bin/mc mb minio/warehouse;/usr/bin/mc policy set public minio/warehouse;tail -f /dev/null"
networks:iceberg_net:接下来,在终端窗口中导航到保存 .yml 文件的位置,然后使用以下命令启动 docker 容器:
docker-compose up
然后,您可以运行以下命令来启动 Spark-SQL 会话。
docker exec -it spark-iceberg spark-sql
步骤 2:创建表
打开 Spark shell 并创建一个表:
CREATE TABLE my_catalog.my_table (id BIGINT,data STRING,category STRING
)
USING iceberg
PARTITIONED BY (category);
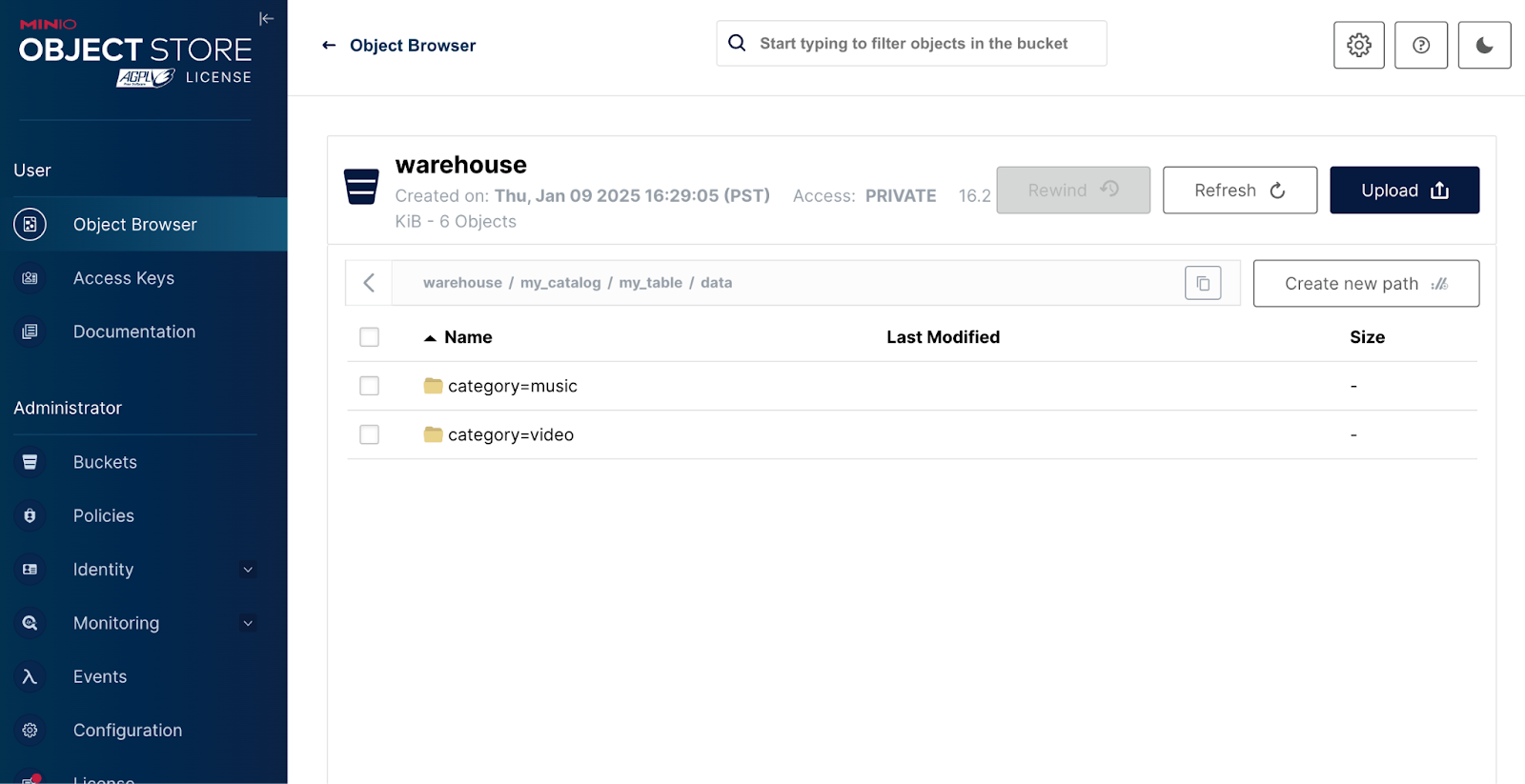
导航到 http://127.0.0.1:9001 并使用 .yml 中的凭证登录,检查您的 MinIO 控制台:AWS_ACCESS_KEY_ID=admin、AWS_SECRET_ACCESS_KEY=password
在这里,观察为表创建的 iceberg/my_table/metadata 路径。最初,不存在任何数据文件,只存在定义架构和分区的元数据。
第 3 步:插入数据
插入一些 mock 数据:
INSERT INTO my_catalog.my_table VALUES
(1, 'a', 'music'),
(2, 'b', 'music'),
(3, 'c', 'video');此作在相应的分区 (my_table/data/category=…) 中创建数据文件并更新元数据。
第 4 步:查询数据
运行基本查询以验证:
SELECT COUNT(1) AS count, data
FROM my_catalog.my_table
GROUP BY data;
您的输出应如下所示:
spark-sql ()> SELECT COUNT(1) AS count, data > FROM my_catalog.my_table > GROUP BY data;
1 c
1 b
1 a
Time taken: 0.575 seconds, Fetched 3 row(s)测试 Iceberg 的关键功能
现在,您已经使用可作的数据建立了基准数据湖仓一体。让我们看看使 Iceberg 独一无二的功能:Schema Evolution 和 Partition Evolution。
架构演变
架构演变是 Apache Iceberg 最强大和最具决定性的功能之一,解决了传统仓库系统中的一个重大痛点。它允许您修改表的架构,而无需昂贵且耗时的数据重写,这对于大规模数据集特别有益。此功能使组织能够根据业务需求的发展调整其数据模型,而不会中断正在进行的查询或作。在 Iceberg 中,架构更改仅在元数据级别处理。表中的每一列都分配有一个唯一的 ID,以确保对架构的更改不会影响底层数据文件。例如,如果添加了一个新列,Iceberg 会为其分配一个新 ID,而无需重新解释或重写现有数据。这样可以避免错误并确保与历史数据的向后兼容性。下面是 Schema 演变在实践中如何工作的示例。假设您需要添加新列 buyer 来存储有关交易的其他信息。您可以执行以下 SQL 命令:
ALTER TABLE my_catalog.my_table ADD COLUMN buyer STRING;
此作会更新表的元数据,从而允许新数据文件包含 buyer 列。旧数据文件保持不变,并且可以编写查询以无缝处理新数据和旧数据。同样,如果不再需要某个列,则可以将其删除,而不会影响存储的数据:
ALTER TABLE my_catalog.my_table DROP COLUMN buyer;此作将更新架构以排除 category 列。Iceberg 可确保清理任何关联的元数据,同时保持可能仍引用较旧数据版本的历史查询的完整性。Iceberg 的架构演变还支持重命名列、更改列类型和重新排列列顺序,所有这些都通过高效的纯元数据作实现。这些更改无需更改数据文件即可进行,从而使架构修改即时且经济高效。
这种方法在架构频繁更改的环境中尤其有利,例如由 AI/ML 实验、动态业务逻辑或不断变化的法规要求驱动的环境。
分区演变
Iceberg 支持分区演变,可以处理为表中的行生成分区值的繁琐且容易出错的任务。用户专注于向解决业务问题的查询添加筛选器,而不用担心表的分区方式。Iceberg 会自动避免从不必要的分区中读取数据。Iceberg 为您处理分区和更改表分区方案的复杂性,从而大大简化了最终用户的过程。您可以定义分区,也可以让 Iceberg 为您处理。Iceberg 喜欢根据时间戳进行分区,例如事件时间。分区由清单中的快照跟踪。查询不再依赖于表的物理布局。由于物理表和逻辑表之间的这种分离,Iceberg 表可以随着添加更多数据而随着时间的推移而演变分区。
ALTER TABLE my_catalog.my_table ADD COLUMN month int AFTER buyer;
ALTER TABLE my_catalog.my_table ADD PARTITION FIELD month;
现在,对于同一个表,我们有两个分区方案。从现在开始,查询计划是拆分的,使用旧的分区方案查询旧数据,使用新的分区方案查询新数据。Iceberg 会为您处理这个问题 — 查询表的人不需要知道数据是使用两个分区方案存储的。Iceberg 通过组合幕后的 WHERE 子句和分区筛选器来实现这一点,这些筛选器会删除没有匹配项的数据文件。
时间旅行和回滚
每次写入 Iceberg 表都会创建新的快照。快照与版本类似,可用于时间旅行和回滚,就像我们使用 AIStor 版本控制功能的方式一样。管理快照的方式是通过设置 expireSnapshot 来维护系统。按时间顺序查看支持使用完全相同的表快照的可重现查询,或者允许用户轻松检查更改。版本回滚允许用户通过将表重置为良好状态来快速纠正问题。当表发生更改时,Iceberg 会将每个版本作为快照进行跟踪,然后在查询表时提供时间旅行到任何快照的功能。如果要运行历史查询或重现以前查询的结果(可能用于报告),这可能非常有用。在测试新代码更改时,时间旅行也很有帮助,因为您可以使用已知结果的查询来测试新代码。要查看已为表保存的快照,请运行以下查询:
SELECT * FROM my_catalog.my_table.snapshots;
您的输出应如下所示:
2025-01-10 00:35:03.35 4613228935063023150 NULL append s3://warehouse/my_catalog/my_table/metadata/snap-4613228935063023150-1-083e4483-566f-4f5c-ab47-6717577948cb.avro {"added-data-files":"2","added-files-size":"1796","added-records":"3","changed-partition-count":"2","spark.app.id":"local-1736469268719","total-data-files":"2","total-delete-files":"0","total-equality-deletes":"0","total-files-size":"1796","total-position-deletes":"0","total-records":"3"}
Time taken: 0.109 seconds, Fetched 1 row(s)
一些例子:
-- time travel to October 26, 1986 at 01:21:00
SELECT * FROM my_catalog.my_table TIMESTAMP AS OF '1986-10-26 01:21:00';-- time travel to snapshot with id 10963874102873
SELECT * FROM prod.db.table VERSION AS OF 10963874102873;
您可以使用快照执行增量读取,但必须使用 Spark,而不是 Spark-SQL。例如
scala> spark.read()
.format(“iceberg”)
.option(“start-snapshot-id”, “10963874102873”)
.option(“end-snapshot-id”, “10963874102994”)
.load(“s3://iceberg/my_table”)
您还可以将表回滚到某个时间点或特定快照,如以下两个示例所示
CALL my_catalog.system.rollback_to_timestamp(‘my_table’, TIMESTAMP ‘2022-07-25 12:15:00.000’);
CALL my_catalog.system.rollback_to_snapshot(‘my_table’, 527713811620162549);
富有表现力的 SQL
Iceberg 支持所有富有表现力的 SQL 命令,如行级删除、合并和更新,需要强调的最重要的一点是 Iceberg 同时支持 Eager 和 lazy 策略。我们可以对所有需要删除的内容进行编码(例如,GDPR 或 CCPA),但不会立即重写所有这些数据文件,我们可以根据需要懒惰地收集垃圾,这有助于提高 Iceberg 支持的巨大表的效率。例如,您可以删除表中与特定谓词匹配的所有记录。以下内容将从 video 类别中删除所有行。
DELETE FROM my_catalog.my_table WHERE category = 'video';
或者,您可以使用 CREATE TABLE AS SELECT 或 REPLACE TABLE AS SELECT 来完成此作:
CREATE TABLE my_catalog.my_table_music AS SELECT * FROM my_catalog.my_table WHERE category = 'music';
你可以很容易地合并两个表:
MERGE INTO my_catalog.my_data pt USING (SELECT * FROM my_catalog.my_data_new) st ON pt.id = st.id WHEN NOT MATCHED THEN INSERT *;数据工程
Iceberg 是开放分析表标准的基础,它使用 SQL 行为并应用数据仓库基础知识,在我们知道自己有问题之前就解决了问题。通过声明式数据工程,我们可以配置表,而不必担心更改每个引擎以适应数据的需求。这将解锁自动优化和推荐。通过安全提交,数据服务成为可能,这有助于避免人工照看数据工作负载。以下是这些类型配置的一些示例:
为了检查表的历史记录、快照和其他元数据,Iceberg 支持查询元数据。元数据表是通过在查询中的原始表名称后添加元数据表名称(例如,history)来标识的。要显示表的数据文件:
SELECT * FROM my_catalog.my_table.files;
要显示清单:
SELECT * FROM my_catalog.my_table.manifests;
显示表历史记录
SELECT * FROM my_catalog.my_table.history;
显示快照
SELECT * FROM my_catalog.my_table.snapshots;
您还可以联接快照和表历史记录,以查看写入每个快照的应用程序
select
h.made_current_at,
s.operation,
h.snapshot_id,
h.is_current_ancestor,
s.summary['spark.app.id']
from my_catalog.my_table.history h
join my_catalog.my_table.snapshots s
on h.snapshot_id = s.snapshot_id
order by made_current_at;现在您已经了解了基础知识,请将一些数据加载到 Iceberg 中,然后从 Iceberg 文档中了解更多信息。
集成
各种查询和执行引擎都实施了 Iceberg 连接器,从而可以轻松创建和管理 Iceberg 表。支持 Iceberg 的引擎包括 Spark、Flink、Presto、Trino、Dremio、Snowflake,而且这个列表还在不断增加。这种广泛的集成环境确保组织可以采用 Apache Iceberg,而不必局限于单个处理引擎,从而提高其数据基础架构的灵活性和互作性。
目录
在任何权威指南中,更不用说目录了。Iceberg 目录是管理表元数据和促进数据集和查询引擎之间连接的核心。这些目录维护表架构、快照和分区布局等关键信息,从而启用 Iceberg 的高级功能,如时间旅行、架构演变和原子更新。有多种目录实施可供选择,以满足不同的运营需求。例如,Polaris 提供针对现代数据基础设施量身定制的可扩展云原生编目解决方案,而 Dremio Nessie 则引入了类似 Git 的语义的版本控制,使团队能够精确跟踪数据和元数据的更改。Hive Metastore 等传统解决方案仍然被广泛使用,特别是为了向后兼容旧系统。
使用 Iceberg 和 AIStor 构建数据湖很酷
Apache Iceberg 作为数据湖的表格格式受到广泛关注。不断壮大的开源社区以及来自多个云提供商和应用程序框架的集成数量不断增加,这意味着是时候认真对待 Iceberg,并开始试验、学习和规划将其集成到现有数据湖架构中了。将 Iceberg 与 AIStor 配对,实现多云数据湖仓一体和分析。
相关文章:
Iceberg and AIStor 的Lakehouse Architecture 权威指南
Apache Iceberg 似乎已经掀起了一场(暴风雪)数据世界。它最初由 Ryan Blue(也是 Tabular 的成员,现在是 Databricks 的名人)在 Netflix 孵化,最终被传输到它目前所在的 Apache 软件基金会。从本质上讲&…...
TCP/IP 协议图解 | TCP 协议详解 | IP 协议详解
注:本文为 “TCP/IP 协议” 相关文章合辑。 未整理去重。 TCP/IP 协议图解 退休的汤姆 于 2021-07-01 16:14:25 发布 TCP/IP 协议简介 TCP/IP 协议包含了一系列的协议,也叫 TCP/IP 协议族(TCP/IP Protocol Suite,或 TCP/IP Pr…...
第四节 docker基础之---dockerfile部署JDK
本地宿主机配置jdk 创建test目录: [rootdocker ~]# mkdir test 压缩包tomcat和jdk上传到root/test目录下: 本机部署Jdk 解压jdk: [rootdocker test]# tar -xf jdk-8u211-linux-x64.tar.gz [rootdocker test]# tar -xf apache-tomcat-8.5.…...
Arcgis/GeoScene API for JavaScript 三维场景底图网格设为透明
项目场景: 有时候加载的地图服务白色区域会露底,导致在三维场景时,露出了三维网格,影响效果,自此,我们需要将三维场景的底图设为白色或透明。 问题描述 如图所示: 解决方案: 提示…...

基于javaweb的SpringBoot电影推荐系统
🎬 秋野酱:《个人主页》 🔥 个人专栏:《Java专栏》《Python专栏》 ⛺️心若有所向往,何惧道阻且长 文章目录 运行环境开发工具适用功能说明项目介绍环境需要技术栈使用说明 运行环境 Java≥8、MySQL≥5.7 开发工具 eclipse/idea/myeclips…...
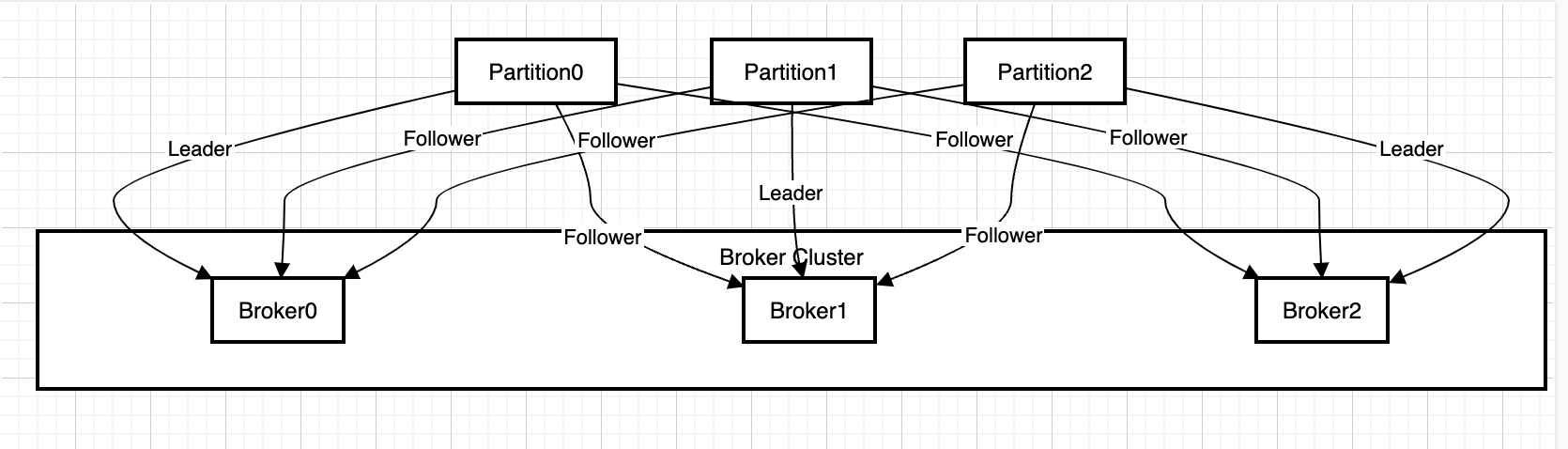
【kafka系列】Topic 与 Partition
Kafka 的 Topic(主题) 和 Partition(分区) 是数据组织的核心概念,它们的映射关系及在 Broker 上的分布直接影响 Kafka 的性能、扩展性和容错能力。以下是详细解析: 一、Topic 与 Partition 的映射关系 Top…...
大数据项目2:基于hadoop的电影推荐和分析系统设计和实现
前言 大数据项目源码资料说明: 大数据项目资料来自我多年工作中的开发积累与沉淀。 我分享的每个项目都有完整代码、数据、文档、效果图、部署文档及讲解视频。 可用于毕设、课设、学习、工作或者二次开发等,极大提升效率! 1、项目目标 本…...
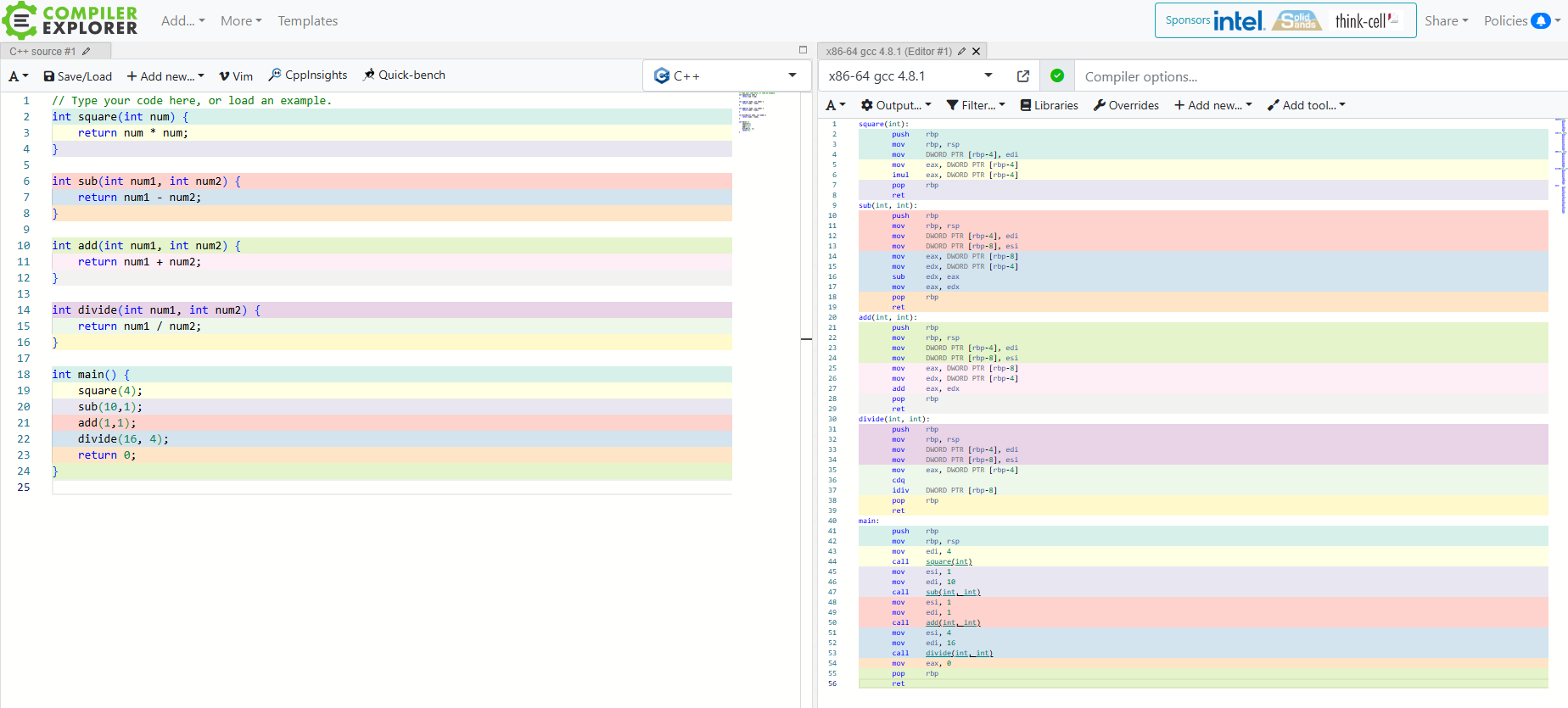
[笔记] 汇编杂记(持续更新)
文章目录 前言举例解释函数的序言函数的调用栈数据的传递 总结 前言 举例解释 // Type your code here, or load an example. int square(int num) {return num * num; }int sub(int num1, int num2) {return num1 - num2; }int add(int num1, int num2) {return num1 num2;…...
的性能对比)
同步阻塞IO和多路复用IO(epoll)的性能对比
多路复用 I/O(如 epoll)相比传统的同步阻塞 I/O 在网络性能上具有显著优势,主要原因在于其高效的事件驱动机制和对高并发的优化能力。 1. 同步阻塞 I/O 的性能瓶颈 在传统的同步阻塞 I/O 模型中,每个网络连接通常需要一个独立的线…...

前端 CSS 动态设置样式::class、:style 等技巧详解
一、:class 动态绑定类名 v-bind:class(缩写为 :class)可以动态地绑定一个或多个 CSS 类名。 1. 对象语法 通过对象语法,可以根据条件动态切换类名。 <template><div :class"{ greenText: isActive, red-text: hasError }&…...

qt widget和qml界面集成到一起
将 Qt Widgets 和 QML 界面集成在一起可以利用 QQuickWidget 或 QQuickView。以下是基本步骤: 使用 QQuickWidget 创建 Qt Widgets 项目: 创建一个基于 Widgets 的应用程序。添加 QQuickWidget: 在你的窗口或布局中添加 QQuickWidget。 例如,可以在 QMainWindow 中使用: …...
BUU30 [网鼎杯 2018]Fakebook1
是一个登录界面,我们先注册一个试试: 用dirsearch扫描出来robots.txt,也发现了flag.php,并下载user.php.bak 源代码内容: <?phpclass UserInfo {public $name "";public $age 0;public $blog &quo…...
信息科技伦理与道德3-2:智能决策
2.2 智能推荐 推荐算法介绍 推荐系统:猜你喜欢 https://blog.csdn.net/search_129_hr/article/details/120468187 推荐系统–矩阵分解 https://blog.csdn.net/search_129_hr/article/details/121598087 案例一:YouTube推荐算法向儿童推荐不适宜视频 …...

《代码随想录第二十八天》——回溯算法理论基础、组合问题、组合总和III、电话号码的字母组合
《代码随想录第二十八天》——回溯算法理论基础、组合问题、组合总和III、电话号码的字母组合 本篇文章的所有内容仅基于C撰写。 1. 基础知识 1.1 概念 回溯是递归的副产品,它也是遍历树的一种方式,其本质是穷举。它并不高效,但是比暴力循…...

PromptSource官方文档翻译
目录 核心概念解析 提示模板(Prompt Template) P3数据集 安装指南 基础安装(仅使用提示) 开发环境安装(需创建提示) API使用详解 基本用法 子数据集处理 批量操作 提示创建流程 Web界面操作 手…...

USB子系统学习(四)用户态下使用libusb读取鼠标数据
文章目录 1、声明2、HID协议2.1、描述符2.2、鼠标数据格式 3、应用程序4、编译应用程序5、测试6、其它 1、声明 本文是在学习韦东山《驱动大全》USB子系统时,为梳理知识点和自己回看而记录,全部内容高度复制粘贴。 韦老师的《驱动大全》:商…...

Ansible简单介绍及用法
一、简介 Ansible是一个简单的自动化运维管理工具,基于Python语言实现,由Paramiko和PyYAML两个关键模块构建,可用于自动化部署应用、配置、编排task(持续交付、无宕机更新等)。主版本大概每2个月发布一次。 Ansible与Saltstack最大的区别是…...

目前推荐的优秀编程学习网站与资源平台,涵盖不同学习方式和受众需求
一、综合教程与互动学习平台 菜鸟教程 特点:适合零基础新手,提供免费编程语言教程(Python、Java、C/C++、前端等),页面简洁且包含大量代码示例,支持快速上手。适用人群:编程入门者、需要快速查阅语法基础的学习者。W3Schools 特点:专注于Web开发技术(HTML、CSS、JavaS…...
)
软件工程-软件需求规格说明(SRS)
基本介绍 目标 便于用户、分析人员、设计人员进行交流 支持目标软件系统的确认(验收) 控制系统进化过程(追加需求):拥有版本记录表 需要在软件分析完成后,编写完成软件需求说明书。 具体标准可参考GB…...

运维_Mac环境单体服务Docker部署实战手册
Docker部署 本小节,讲解如何将前端 后端项目,使用 Docker 容器,部署到 dev 开发环境下的一台 Mac 电脑上。 1 环境准备 需要安装如下环境: Docker:容器MySQL:数据库Redis:缓存Nginx&#x…...

UE4动画蓝图实战:用双骨骼IK节点搞定手部穿模,附完整蓝图节点截图
UE4动画蓝图实战:双骨骼IK节点解决手部穿模的完整指南在角色动画开发中,手部穿模问题堪称"视觉杀手"。想象一下精心设计的角色挥拳时,拳头直接穿过墙壁或敌人身体——这种违和感足以毁掉整个场景的沉浸感。本文将彻底解决这个痛点&…...

别再只用Service了!ROS1 Action通信保姆级教程:从导航进度条到任务取消,手把手教你实现带反馈的机器人任务
别再只用Service了!ROS1 Action通信保姆级教程:从导航进度条到任务取消,手把手教你实现带反馈的机器人任务当你的机器人正在执行一个长达10分钟的导航任务时,突然发现目标点设置错误,这时候如果只能干等着任务完成或者…...

潮州东方轻奢风全屋高定找哪家
开篇引言根据《2026年中国全屋定制行业发展报告》,潮州市全屋定制市场规模同比增长38%,其中全屋高端定制细分市场同比增长52%。目前,潮州市家庭全屋定制需求占比72%,高端定制需求占比45%。为了帮助潮州市消费者选择合规、靠谱、差…...

打不开JupyterLab
因为安装某些依赖导致JupyterLab的依赖被动升级或降级,从而影响了JupyterLab的运行,此时可以SSH登录到实例,然后输入jupyter-lab命令进行确认,如果执行命令报错则说明是此问题,那么可以通过pip install jupyterlab再次…...

CPU架构启发的智能仓储布局优化实践
1. 仓库布局优化的核心挑战与创新机遇在物流仓储领域,拣货环节通常占据运营成本的55%-65%,而其中约50%的时间消耗在无效行走路径上。传统矩形仓库布局虽然易于规划和施工,但其正交的通道设计导致拣货员需要频繁进行90度转向,这种&…...

sngan_projection论文解读:ICLR2018两大GAN技术的完美结合
sngan_projection论文解读:ICLR2018两大GAN技术的完美结合 【免费下载链接】sngan_projection GANs with spectral normalization and projection discriminator 项目地址: https://gitcode.com/gh_mirrors/sn/sngan_projection sngan_projection是一个实现了…...

16个分片+2副本:pg_shard的master_create_worker_shards最佳实践
16个分片2副本:pg_shard的master_create_worker_shards最佳实践 【免费下载链接】pg_shard ATTENTION: pg_shard is superseded by Citus, its more powerful replacement 项目地址: https://gitcode.com/gh_mirrors/pg/pg_shard pg_shard作为PostgreSQL的分…...

LoRa物联网与动态基线算法在养殖体温监测中的实战应用
1. 项目概述:为什么我们需要一个智能体温监测系统?在规模化养殖场里干了十几年,我见过太多因为体温异常没被及时发现而导致的损失。一头育肥猪突然不吃食,等饲养员第二天巡栏发现时,可能已经高烧好几天,继发…...
)
Windows开机自动全屏打开指定网页?一个快捷方式参数就搞定(Chrome/Edge/Firefox教程)
Windows开机自动全屏展示网页的终极方案每次开机都要手动打开浏览器、输入网址、切换全屏模式?这种重复操作不仅浪费时间,还容易在重要演示时手忙脚乱。想象一下:电脑启动后自动全屏显示你的仪表盘、会议日程或是监控大屏,整个过程…...

用PyTorch复现FactorVAE:一个能同时预测收益和风险的量化模型实战教程
用PyTorch实战FactorVAE:构建收益与风险双预测的量化模型 在量化投资领域,传统线性因子模型正逐渐被非线性机器学习方法所取代。然而金融数据特有的低信噪比特性,使得直接从市场数据中提取有效因子成为一项艰巨挑战。本文将深入探讨如何利用P…...