Java在大数据处理中的应用:从MapReduce到Spark
Java在大数据处理中的应用:从MapReduce到Spark
大数据时代的到来让数据的存储、处理和分析变得前所未有的重要。随着数据量的剧增,传统的单机计算方式已经无法满足处理需求。为了解决这个问题,许多分布式计算框架应运而生,其中MapReduce和Apache Spark是两种主流的解决方案。在大数据处理过程中,Java作为一种高效、平台无关的编程语言,扮演了至关重要的角色。本文将带你深入了解Java在大数据处理中的应用,重点探讨从MapReduce到Spark的演进。
一、MapReduce:分布式计算的先驱
MapReduce是Google提出的分布式计算模型,已被广泛应用于大数据处理。其核心思想是将一个复杂的任务分解为多个小的任务,并通过Map阶段和Reduce阶段进行并行处理。Java在MapReduce的实现中起到了关键作用,特别是Hadoop生态系统中的实现。
1.1 MapReduce工作原理
MapReduce作业通常包括两个阶段:Map阶段和Reduce阶段。
- Map阶段:将输入数据分成多个小块并进行处理,输出一组键值对。
- Reduce阶段:将相同键的键值对汇总进行处理,并产生最终结果。
1.2 Java实现MapReduce
在Hadoop框架中,Java是MapReduce的主要编程语言。下面是一个简单的MapReduce示例,实现统计文本中每个单词出现的次数。
代码示例:WordCount
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;public class WordCount {// Map类public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {private final static IntWritable one = new IntWritable(1);private Text word = new Text();public void map(Object key, Text value, Context context) throws IOException, InterruptedException {String[] words = value.toString().split("\\s+");for (String w : words) {word.set(w);context.write(word, one);}}}// Reduce类public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {private IntWritable result = new IntWritable();public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {int sum = 0;for (IntWritable val : values) {sum += val.get();}result.set(sum);context.write(key, result);}}// 主函数public static void main(String[] args) throws Exception {Configuration conf = new Configuration();Job job = Job.getInstance(conf, "word count");job.setJarByClass(WordCount.class);job.setMapperClass(TokenizerMapper.class);job.setCombinerClass(IntSumReducer.class);job.setReducerClass(IntSumReducer.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);FileInputFormat.addInputPath(job, new Path(args[0]));FileOutputFormat.setOutputPath(job, new Path(args[1]));System.exit(job.waitForCompletion(true) ? 0 : 1);}
}
1.3 MapReduce的优缺点
优点:
- 高可靠性:由于数据是分布式存储的,即使部分节点失效,作业仍能继续执行。
- 扩展性强:可以轻松扩展集群规模,以处理更大的数据集。
缺点:
- 性能问题:MapReduce作业的性能可能受到磁盘I/O瓶颈的限制,尤其是中间数据的存储。
- 编程复杂性:开发者需要处理很多底层细节,如数据的序列化、作业的调度等。
二、Spark:提升大数据处理效率的利器
Spark是一个开源的大数据计算框架,诞生于UC Berkeley,并已经成为大数据处理领域的领先技术。与MapReduce不同,Spark提供了更高效的内存计算能力,同时也提供了更简洁的编程模型。Spark基于RDD(Resilient Distributed Dataset)提供了分布式数据处理能力,支持包括批处理、流处理、机器学习和图计算在内的多种功能。
2.1 Spark的核心特性
- 内存计算:Spark最大的一大亮点是内存计算。它通过将数据集缓存到内存中,避免了MapReduce中频繁的磁盘I/O操作,从而显著提升了计算性能。
- 简化编程模型:与MapReduce相比,Spark的API更加简单,尤其是对Java开发者来说,使用Spark时可以借助丰富的操作符(如
map、reduce、filter等)来简化大数据处理任务。 - 支持多种计算类型:Spark不仅支持批处理,还可以处理流数据、机器学习模型和图计算任务。
2.2 Java实现Spark任务
Spark的Java API可以方便地进行大数据处理。下面是一个简单的Spark示例,计算一个文本文件中每个单词的出现次数。
代码示例:Spark WordCount
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.SparkConf;
import scala.Tuple2;public class WordCount {public static void main(String[] args) {// 创建Spark配置和上下文SparkConf conf = new SparkConf().setAppName("WordCount");JavaSparkContext sc = new JavaSparkContext(conf);// 读取文件并生成RDDJavaRDD<String> input = sc.textFile(args[0]);// 处理数据,统计单词数量JavaRDD<String> words = input.flatMap(line -> Arrays.asList(line.split(" ")).iterator());JavaPairRDD<String, Integer> wordCounts = words.mapToPair(word -> new Tuple2<>(word, 1)).reduceByKey((a, b) -> a + b);// 输出结果wordCounts.saveAsTextFile(args[1]);sc.close();}
}
2.3 Spark的优缺点
优点:
- 性能优越:由于Spark使用内存计算,避免了MapReduce中的磁盘I/O,性能更高。
- 易于使用:Spark提供了更高层次的API,支持更直观的操作。
- 多样化计算:Spark不仅支持批处理任务,还支持流处理、机器学习、图计算等任务。
缺点:
- 内存消耗大:虽然内存计算加速了计算,但对于内存的要求较高,集群资源的消耗也可能变得比较大。
- 依赖较多:使用Spark时,可能需要更多的配置和调优,特别是在大规模集群上运行时。
三、MapReduce与Spark的应用对比
在实际应用中,选择MapReduce还是Spark往往依赖于具体的业务需求和场景。虽然两者都用于分布式数据处理,但它们的技术特点和适用场景有所不同。本文将进一步对比这两者在实际应用中的差异,帮助开发者更好地做出选择。
3.1 性能对比:MapReduce vs Spark
性能是MapReduce与Spark之间的核心差异之一。在处理大数据时,Spark的内存计算通常会比MapReduce的磁盘I/O计算效率更高。下面我们详细分析两者的性能差异。
MapReduce性能特点
MapReduce依赖于将数据分布到多个节点,并在每个节点上执行操作。每次Map或Reduce阶段的计算结果都会写入磁盘,这会导致磁盘I/O瓶颈。对于一些任务,如需要多次迭代的计算,MapReduce的性能就显得较为低下。
Spark性能特点
Spark通过将数据存储在内存中,避免了频繁的磁盘I/O,从而大大提升了性能。Spark还支持将中间结果缓存到内存中,避免了重复计算,因此在处理类似机器学习算法(如K-means聚类)或图算法时,Spark能够比MapReduce更高效。
3.2 扩展性对比:MapReduce vs Spark
扩展性是指处理数据量逐渐增大的时候,系统的表现如何。MapReduce和Spark在扩展性方面有不同的优势。
MapReduce扩展性
MapReduce具有良好的扩展性。由于它的核心依赖于Hadoop的分布式存储(HDFS)和任务调度框架(YARN),它能够非常容易地通过增加节点来扩展计算能力。因此,对于超大规模数据集,MapReduce能够提供较为稳定的扩展性。
Spark扩展性
Spark也具有较好的扩展性,但其内存计算模式要求节点的内存容量更大,因此在某些情况下,扩展性可能受限。特别是在处理大规模数据时,如果内存不够,可能会导致计算失败。不过,Spark的内存计算优势使得它在数据处理速度上比MapReduce更具优势。
3.3 易用性对比:MapReduce vs Spark
MapReduce易用性
MapReduce的编程模型较为底层,要求开发者明确地处理任务的分解、输入输出、以及中间数据的存储等细节。这些细节虽然提供了灵活性,但也增加了编程的复杂性。对于不熟悉分布式计算的开发者来说,编写MapReduce作业可能需要较高的学习曲线。
Spark易用性
Spark的API设计更加简洁,开发者可以通过高层次的操作(如map、reduce、filter)来表达数据处理逻辑,极大地简化了编程。Spark还提供了大量的内建函数,如groupBy、flatMap、reduceByKey等,方便开发者进行各种复杂的数据处理任务。
3.4 任务类型适应性:MapReduce vs Spark
MapReduce任务类型
MapReduce最适合用来处理批量数据的单次计算任务。例如,日志分析、ETL(Extract, Transform, Load)操作等大多数离线批处理任务都能非常适合MapReduce。然而,MapReduce并不擅长处理复杂的迭代计算任务,尤其是需要多次计算的算法,如机器学习算法或图算法。
Spark任务类型
Spark更为适合于处理包括流处理、机器学习、图计算等在内的多种任务。对于机器学习任务,Spark提供了MLlib库,能够高效地进行各种算法训练与评估。对于图计算,Spark也提供了GraphX库,支持大规模图的处理与计算。此外,Spark支持实时流处理(通过Spark Streaming),适合处理需要实时响应的数据流。
四、Java与Spark结合的实践案例
在现代大数据应用中,Java与Spark的结合已经成为许多企业和开发者的首选方案。Java不仅能够利用Spark的强大功能,而且由于其平台无关性和较强的性能表现,成为大数据处理中的重要语言。
4.1 使用Java开发Spark作业
Java与Spark的结合相对直观。我们可以通过Java API在Spark中实现各种数据处理任务,以下是一个实际的案例:假设我们需要处理一个日志文件,提取出每个IP访问的次数。
代码示例:日志文件的IP访问统计
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.SparkConf;
import scala.Tuple2;public class LogIPCount {public static void main(String[] args) {// 创建Spark配置和上下文SparkConf conf = new SparkConf().setAppName("LogIPCount");JavaSparkContext sc = new JavaSparkContext(conf);// 读取日志文件并生成RDDJavaRDD<String> logs = sc.textFile(args[0]);// 通过正则表达式提取IP地址,并统计访问次数JavaRDD<String> ipAddresses = logs.map(new Function<String, String>() {@Overridepublic String call(String logLine) throws Exception {// 假设IP地址位于日志的第一部分return logLine.split(" ")[0];}});JavaPairRDD<String, Integer> ipCounts = ipAddresses.mapToPair(new PairFunction<String, String, Integer>() {@Overridepublic Tuple2<String, Integer> call(String ip) throws Exception {return new Tuple2<>(ip, 1);}}).reduceByKey((a, b) -> a + b);// 输出结果ipCounts.saveAsTextFile(args[1]);sc.close();}
}
4.2 实际应用场景:电商数据分析
在电商平台的日志分析中,Java和Spark常常结合使用来进行海量数据的实时处理与分析。通过Spark Streaming和Java API,可以实现对用户行为数据的实时分析,如统计某一商品的点击量、用户的实时购物行为、推荐系统的实时计算等。
例如,假设我们需要在用户点击商品的同时,实时计算出当前用户的点击数,并将结果存储在数据库中。利用Spark Streaming结合Java,可以轻松实现这一需求,保证系统的实时响应能力。
4.3 Java与Spark的结合:优势与挑战
优势:
- 成熟的生态系统:Java在大数据领域拥有强大的生态系统,特别是在与Hadoop、Spark等大数据技术的结合方面,Java提供了丰富的库和框架。
- 平台无关性:Java的跨平台特性确保了开发的应用可以在多种操作系统上运行,适合多样化的部署需求。
挑战:
- 内存消耗问题:虽然Java可以高效地与Spark结合,但由于Spark的大规模内存计算,仍需要合理配置集群的内存资源,避免内存溢出等问题。
- 调试困难:分布式环境下的应用调试相比单机程序要复杂得多,尤其是在Java与Spark的结合过程中,调试过程可能较为繁琐。
五、Java在大数据生态系统中的整合
Java不仅在MapReduce和Spark中扮演着重要角色,它还在整个大数据生态系统中发挥着至关重要的作用。除了MapReduce和Spark,Java还可以与许多其他大数据工具和框架无缝集成,包括Hadoop、Hive、HBase等。这些工具的组合帮助开发者构建强大且高效的大数据应用,解决不同的数据处理需求。
5.1 Java与Hadoop的整合
Hadoop是一个流行的开源大数据框架,它的核心组成包括HDFS(分布式文件系统)和YARN(资源管理器)。Java与Hadoop的结合使得开发者可以通过编写MapReduce作业来处理存储在HDFS上的海量数据。
Hadoop与Java的关系
Hadoop的MapReduce框架主要是用Java来实现的。因此,Java开发者能够轻松使用Hadoop来处理分布式计算任务,Hadoop提供了Java API用于与HDFS和YARN进行交互。通过Java,我们可以创建MapReduce作业并将其提交给Hadoop集群进行执行。
代码示例:读取HDFS中的文件
以下是一个简单的Java代码示例,展示了如何使用Hadoop API来读取HDFS中的文件并打印文件内容:
import org.apache.hadoop.fs.*;
import org.apache.hadoop.conf.Configuration;import java.io.IOException;public class HDFSReader {public static void main(String[] args) throws IOException {// 配置Hadoop环境Configuration conf = new Configuration();FileSystem fs = FileSystem.get(conf);// 获取HDFS文件路径Path filePath = new Path(args[0]);FSDataInputStream inputStream = fs.open(filePath);// 读取并打印文件内容int byteRead;while ((byteRead = inputStream.read()) != -1) {System.out.print((char) byteRead);}// 关闭输入流inputStream.close();fs.close();}
}
这个例子展示了如何通过Java API读取HDFS中的文件。Java与Hadoop的紧密集成使得在大数据处理过程中能够高效地访问分布式数据。
5.2 Java与Hive的整合
Apache Hive是一个基于Hadoop的数据仓库工具,它提供了SQL查询能力来处理存储在HDFS中的数据。Java可以通过Hive JDBC连接来与Hive进行交互,执行SQL查询并获取处理结果。
Java调用Hive
开发者可以通过使用Hive的JDBC驱动,在Java应用中执行Hive SQL查询。以下是一个简单的Java代码示例,展示如何通过JDBC连接Hive,并执行一个SQL查询。
import java.sql.*;public class HiveJDBCExample {public static void main(String[] args) {// Hive JDBC连接URLString jdbcUrl = "jdbc:hive2://localhost:10000/default";String user = "hive";String password = "";// 连接到Hive并执行查询try (Connection conn = DriverManager.getConnection(jdbcUrl, user, password)) {Statement stmt = conn.createStatement();ResultSet rs = stmt.executeQuery("SELECT * FROM my_table");// 输出查询结果while (rs.next()) {System.out.println("Column 1: " + rs.getString(1) + ", Column 2: " + rs.getString(2));}} catch (SQLException e) {e.printStackTrace();}}
}
这个示例展示了如何通过Hive的JDBC连接在Java中执行SQL查询,操作存储在HDFS中的结构化数据。Java与Hive的集成为开发者提供了方便的查询接口,特别适用于需要在大数据平台上进行数据分析的场景。
5.3 Java与HBase的整合
HBase是一个分布式、列式存储的NoSQL数据库,通常用于存储海量的结构化和半结构化数据。Java可以通过HBase的客户端API与HBase进行交互,读取和写入数据。
HBase与Java的结合
HBase提供了Java API来执行各种数据库操作,如插入、更新、删除和查询。以下是一个简单的Java示例,展示如何通过Java连接到HBase,并执行一个基本的插入操作。
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.*;
import org.apache.hadoop.conf.Configuration;import java.io.IOException;public class HBaseExample {public static void main(String[] args) throws IOException {// 配置HBaseConfiguration config = HBaseConfiguration.create();Connection connection = ConnectionFactory.createConnection(config);Table table = connection.getTable(TableName.valueOf("my_table"));// 创建Put对象Put put = new Put("row1".getBytes());put.addColumn("cf1".getBytes(), "col1".getBytes(), "value1".getBytes());// 插入数据table.put(put);// 关闭连接table.close();connection.close();}
}
在这个示例中,Java通过HBase API插入了一行数据。HBase与Java的整合使得开发者可以灵活地操作大规模分布式数据库,并能够高效地处理大量数据。
六、Java与大数据工具的高级集成
随着大数据技术的不断发展,Java在大数据处理中的作用变得更加多样化。除了MapReduce、Spark、Hive和HBase,Java还可以与许多其他大数据工具进行高级集成,包括Flume、Kafka、Flink等。下面我们简要介绍一些常见的大数据工具以及它们如何与Java协作。
6.1 Java与Apache Flume的整合
Apache Flume是一个分布式的日志收集、聚合和传输系统。它主要用于将日志和数据从不同的来源(如Web服务器、应用服务器等)流式传输到HDFS或其他数据存储系统。Java可以通过Flume的客户端API来发送数据流。
Flume与Java集成
Java通过Flume的客户端API,可以将应用程序生成的日志或数据实时发送到Flume。Flume会将这些数据传输到目标存储系统(如HDFS、HBase等)。
6.2 Java与Apache Kafka的整合
Apache Kafka是一个高吞吐量的分布式消息队列系统,广泛用于实时流数据的传输。Java可以使用Kafka的Producer和Consumer API来发送和接收消息。
Kafka与Java集成
Java应用程序可以通过Kafka的Producer API将数据流推送到Kafka主题,并通过Consumer API实时消费这些消息。Kafka与Java的集成使得开发者能够构建实时数据流处理系统。
6.3 Java与Apache Flink的整合
Apache Flink是一个分布式流处理框架,适用于实时数据处理和批处理任务。Java可以使用Flink的API来定义实时数据流处理应用,如流式计算和事件驱动的分析。
Flink与Java集成
Java开发者可以使用Flink提供的丰富API,编写实时数据流处理程序,处理来自Kafka、HDFS等的数据流。Flink与Java的结合,使得实时流数据处理变得更加高效和灵活。
七、未来展望:Java与大数据的深度融合
随着大数据技术的不断演进,Java在大数据领域的应用也将不断深化。从MapReduce到Spark,再到与Hive、HBase、Flink等大数据工具的集成,Java将继续在大数据处理领域扮演着重要角色。未来,随着数据处理需求的不断增长,Java在大数据生态系统中的角色将更加不可或缺,尤其是在高效的分布式计算、流数据处理、机器学习等领域,Java的能力将继续得到广泛的发挥。

相关文章:
Java在大数据处理中的应用:从MapReduce到Spark
Java在大数据处理中的应用:从MapReduce到Spark 大数据时代的到来让数据的存储、处理和分析变得前所未有的重要。随着数据量的剧增,传统的单机计算方式已经无法满足处理需求。为了解决这个问题,许多分布式计算框架应运而生,其中Ma…...

日常吐槽。
一、写在前面 stereopy日常出bug(github issue里得有一半的问题是我提的,当然也有可能是因为我菜),stereopy自己生成的anndata自己不能计算空间共现关系,还是靠squidpy才能计算。另外还要一些函数一开并行计算就报错,这里留一些s…...

2025最新版Node.js下载安装~保姆级教程
1. node中文官网地址:http://nodejs.cn/download/ 2.打开node官网下载压缩包: 根据操作系统不同选择不同版本(win7系统建议安装v12.x) 我这里选择最新版win 64位 3.安装node ①点击对话框中的“Next”,勾选同意后点…...
机器学习:学习记录(二)
1. 机器学习中的常用函数 logistic函数(sigmoid函数):非线性激活函数,将R区间映射到(0,1)区间 ReLU函数:非线性激活函数,简单可以写作max(0,x),在0处不可导,但是可以人为定义其导数…...

迁移学习 Transfer Learning
迁移学习(Transfer Learning)是什么? 迁移学习是一种机器学习方法,它的核心思想是利用已有模型的知识来帮助新的任务或数据集进行学习,从而减少训练数据的需求、加快训练速度,并提升模型性能。 …...

实现:多活的基础中间件
APIRouter : 路由分发服务 API Router 是一个 HTTP 反向代理和负载均衡器,部署在公有云中作为 HTTP API 流量的入口,它能识别 出流量的归属 shard ,并根据 shard 将流量转发到对应的 ezone 。 API Router 支持多种路由键&am…...
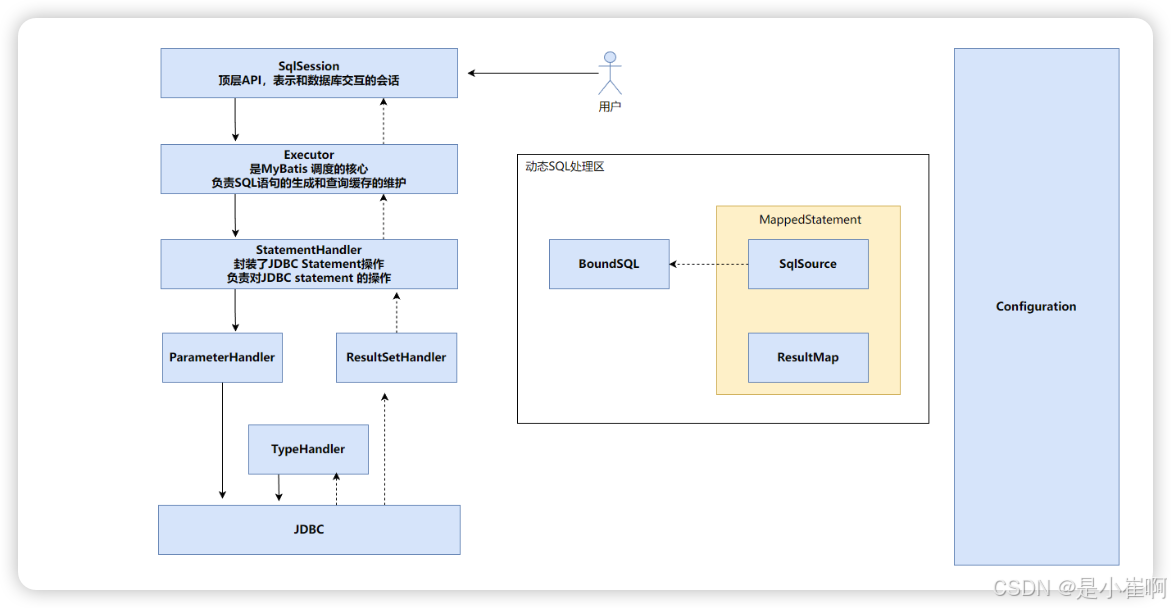
Mybatis源码01 - 总体框架设计
Mybatis总体框架设计 文章目录 Mybatis总体框架设计一:MyBatis架构概览1:接口层1.1:使用传统的MyBatis提供的API1.2:使用Mapper接口 2:数据处理层【核心】2.1:参数映射和动态SQL语句生成2.2:SQL…...

在大型语言模型(LLM)框架内Transformer架构与混合专家(MoE)策略的概念整合
文章目录 传统的神经网络框架存在的问题一. Transformer架构综述1.1 transformer的输入1.1.1 词向量1.1.2 位置编码(Positional Encoding)1.1.3 编码器与解码器结构1.1.4 多头自注意力机制 二.Transformer分步详解2.1 传统词向量存在的问题2.2 详解编解码…...

Selenium WebDriver自动化测试(扩展篇)--Jenkins持续集成
文章目录 一、引言二、Jenkins简介三、安装部署Jenkins安装部署 四、集成Git与Maven安装必要的插件配置Git配置Maven 五、创建Job创建自由风格的项目配置源码管理配置构建触发器配置构建环境配置构建步骤配置Post-build Actions 六、触发构建示例:GitHub Webhook触发…...

Wiki文档转换为Word技术
一、技术背景与目标 Wiki系统导出的文档通常以HTML格式存在,且内容分散在多个文件中,每个页面对应一个HTML文件。然而,Microsoft Word(Word)在处理HTML文件时,仅支持单个HTML文件的导入。因此,为了将Wiki导出的内容转换为Word可识别的格式,必须将分散的HTML文件整合为一…...

1.【线性代数】——方程组的几何解释
一 方程组的几何解释 概述举例举例一1. matrix2.row picture3.column picture 概述 三种表示方法 matrixrow picturecolumn picture 举例 举例一 { 2 x − y 0 − x 2 y 3 \begin{cases} 2x - y 0 \\ -x 2y 3 \end{cases} {2x−y0−x2y3 1. matrix [ 2 − 1 − 1 …...

力扣1448. 统计二叉树中好节点的数目
Problem: 1448. 统计二叉树中好节点的数目 文章目录 题目描述思路复杂度Code 题目描述 思路 对二叉树进行先序遍历,边遍历边对比并更新当前路径上的最大值pathMax,若当pathMax小于等于当前节点值,则好节点的数目加一 复杂度 时间复杂度: O (…...
——C#注释和命名法详解)
【C#零基础从入门到精通】(二)——C#注释和命名法详解
【C#零基础从入门到精通】(二)——C#注释和命名法详解 C# 中的注释 定义 在 C# 里,注释是一种特殊的代码文本,它不会被编译器执行,主要用于对代码进行解释、说明,帮助开发者更好地理解代码的功能、用途、实现思路以及注意事项等,提升代码的可读性和可维护性。 注释类型…...

SQLServer的创建,表创建,主键,约束,模糊查询
设置 注意: 设置完成之后 重新启动 创建数据库 注意: 这个目标路径必须要有该文件名的文件夹 -- 指向 master 数据库,告诉它我们要创建一个新的数据库操作了 use master go-- 创建数据库 create database StudentManageDB on primary (-- 以下四个组成部分缺一不可…...
架构设计指南)
DeepSeek深度思考:客户端(Android/iOS)架构设计指南
目标读者:中高级开发者、架构师 适用场景:大型复杂应用开发、跨团队协作、长期维护迭代 一、架构设计核心原则 1.模块化(Modularization) 横向拆分:按功能边界划分(如登录、支付、消息模块)纵向…...

亚远景-精通ASPICE:专业咨询助力汽车软件开发高效合规
在竞争日益激烈的汽车行业,软件开发已成为决定成败的关键因素。ASPICE(汽车软件过程改进和能力确定) 作为行业公认的软件开发框架,为汽车制造商和供应商提供了实现高效、合规开发的路线图。 然而,ASPICE 的实施并非易…...

OpenCV 相机标定流程指南
OpenCV 相机标定流程指南 前置准备标定流程结果输出与验证建议源代码 OpenCV 相机标定流程指南 https://docs.opencv.org/4.x/dc/dbb/tutorial_py_calibration.html https://learnopencv.com/camera-calibration-using-opencv/ 前置准备 制作标定板:生成高精度棋…...

项目场景拷打
补偿事务解决超卖 通过补偿事务避免超卖问题,可以通过以下几种方式实现: 1. 使用数据库事务与锁机制 事务管理:将库存扣减和订单生成操作放在同一个数据库事务中,确保操作的原子性。如果事务中任何一个步骤失败,则整…...

Vue2生命周期面试题
在 Vue 2 中,this.$el 和 this.$data 都是 Vue 实例的属性,代表不同的内容。 1. this.$el this.$el 是 Vue 实例的根 DOM 元素,它指向 Vue 实例所控制的根节点元素。在 Vue 中,el 是在 Vue 实例创建时,指定的根元素&…...

【每日一题 | 2025】2.3 ~ 2.9
个人主页:GUIQU. 归属专栏:每日一题 文章目录 1. 【2.3】P8784 [蓝桥杯 2022 省 B] 积木画2. 【2.4】P8656 [蓝桥杯 2017 国 B] 对局匹配3. 【2.5】[ABC365D] AtCoder Janken 34. 【2.6】P8703 [蓝桥杯 2019 国 B] 最优包含5. 【2.7】P8624 [蓝桥杯 2015…...

从零构建可控AI智能体中枢:Comobot部署、配置与实战指南
1. 项目概述:从零构建一个可控的智能体中枢如果你和我一样,对市面上的AI助手感到既兴奋又有些许无奈——兴奋于它们强大的能力,无奈于它们要么是“黑盒”服务,数据安全存疑;要么部署复杂,难以深度定制——那…...

网盘直链解析方案:如何通过浏览器脚本实现多平台文件下载优化
网盘直链解析方案:如何通过浏览器脚本实现多平台文件下载优化 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘…...

在Windows系统中快速配置Taotoken的Python调用环境
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Windows系统中快速配置Taotoken的Python调用环境 对于Windows平台的开发者而言,快速搭建一个能够调用多种大模型的环…...

AK7739 TDM调试避坑指南:从tinymix命令到SA6125平台时钟极性BUG排查
AK7739 TDM音频接口深度调试:从寄存器配置到时钟极性异常实战解析 当我们在嵌入式音频系统中集成AK7739编解码器时,TDM(时分复用)接口的调试往往是工程师面临的最大挑战之一。不同于标准的I2S协议,TDM接口的高度可配置…...

点云配准避坑指南:当ICP把深度图配到‘中心’时,我的自适应阈值调整方案
点云配准避坑指南:动态阈值优化解决ICP中心化失效问题 在三维重建和SLAM项目中,工程师们常常会遇到一个令人头疼的现象:使用标准ICP算法对深度图点云进行配准时,点云会神秘地"滑向"彼此的中心位置。这种看似魔法的行为背…...

AI编程助手如何通过MCP协议安全访问本地代码库
1. 项目概述:一个连接代码与AI的“翻译官”最近在折腾AI编程助手的时候,发现了一个挺有意思的东西:semihkayan/codeweave-mcp。这名字乍一看有点唬人,又是“code weave”(代码编织)又是“MCP”的࿰…...

云薪酬系统与传统系统的核心差异与实施指南
1. 云薪酬系统与传统系统的本质差异薪酬管理作为企业人力资源的核心模块,经历了从手工台账到本地软件再到云端服务的演进历程。我曾为多家企业实施过新旧系统的替换,深刻体会到两种架构的根本区别不仅在于技术实现,更在于管理理念的革新。传统…...

AI API中转服务全解析:从概念到实战,轻松接入GPT-4与Claude
1. 项目概述:一个关于AI API服务的开源项目最近在GitHub上闲逛,发现了一个挺有意思的项目,名字叫“-chatgpt4.0-api-key”。点进去一看,这其实是一个围绕“云雾API”服务的资源汇总和指南仓库。说白了,它不是一个能直接…...

LinkedIn Liger Kernel:移动设备内核定制与性能优化实战
1. 项目概述:一个面向移动设备的开源内核探索如果你在移动设备开发、嵌入式系统或者内核研究的圈子里待过一段时间,大概率听说过或者接触过“Liger Kernel”这个名字。它不是一个商业产品,而是一个在GitHub上由LinkedIn开源并维护的Android内…...
)
别再求公司账号了!个人开发者也能搞定uniapp打包iOS(保姆级证书+profile配置)
个人开发者独立完成uniapp iOS打包全流程指南 在移动应用开发领域,iOS平台始终是开发者无法绕开的重要阵地。然而,许多独立开发者和小团队常常被苹果开发者账号的门槛所困扰,误以为必须依赖企业级账号才能完成应用打包和上架。实际上&#x…...