Windows11+PyCharm利用MMSegmentation训练自己的数据集保姆级教程
系统版本:Windows 11
依赖环境:Anaconda3
运行软件:PyCharm
一.环境配置
- 通过Anaconda Prompt(anaconda)打开终端

- 创建一个虚拟环境
conda create --name mmseg python=3.9
3.激活虚拟环境
conda activate mmseg4.安装pytorch和cuda
torch版本要求是1.12或者1.13,这里选择安装1.12,安装命令从pytorch官网找,地址
pip install torch==1.12.1+cu116 torchvision==0.13.1+cu116 torchaudio==0.12.1 --extra-index-url https://download.pytorch.org/whl/cu1165.安装mmcv
安装命令生成地址:地址

pip install mmcv==2.0.0rc4 -f https://download.openmmlab.com/mmcv/dist/cu116/torch1.12/index.html6.下载源码
这里可以去github上下载1.1.1版本代码,也可以下载我准备好的代码:地址
7.用pycharm打开mmsegmentation-1.1.1
选择好配置的环境之后,打开终端,运行如下命令:
pip install -v -e .至此环境配置完成。
二.准备自己的数据集
数据集的准备请查看:数据集制作教程
上面提供的源码中包含可训练的数据集,可以直接下载!
三.开始训练
在pycharm中打开上面下载的源码。
1.在mmseg/datasets文件夹下新建mysegDataset.py
from mmseg.registry import DATASETS
from .basesegdataset import BaseSegDataset@DATASETS.register_module()
class mysegDataset(BaseSegDataset):# 类别和对应的 RGB配色METAINFO = {'classes':['background', 'red', 'green', 'white', 'seed-black', 'seed-white'],'palette':[[127,127,127], [200,0,0], [0,200,0], [144,238,144], [30,30,30], [251,189,8]]}# 指定图像扩展名、标注扩展名def __init__(self,seg_map_suffix='.png', # 标注mask图像的格式reduce_zero_label=False, # 类别ID为0的类别是否需要除去**kwargs) -> None:super().__init__(seg_map_suffix=seg_map_suffix,reduce_zero_label=reduce_zero_label,**kwargs)2.注册数据集
在`mmseg/datasets/__init__.py`中注册刚刚定义的`mysegDataset`数据集类,如下图所示,在最后添加即可

3.pipeline配置文件
在configs/_base_/datasets文件夹下新建mysegDataset_pipeline.py,并添加如下代码。
# 数据集路径
dataset_type = 'mysegDataset' # 数据集类名
data_root = 'Watermelon87_Semantic_Seg_Mask/' # 数据集路径(相对于mmsegmentation主目录)# 输入模型的图像裁剪尺寸,一般是 128 的倍数,越小显存开销越少
crop_size = (512, 512)# 训练预处理
train_pipeline = [dict(type='LoadImageFromFile'),dict(type='LoadAnnotations'),dict(type='RandomResize',scale=(2048, 1024),ratio_range=(0.5, 2.0),keep_ratio=True),dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75),dict(type='RandomFlip', prob=0.5),dict(type='PhotoMetricDistortion'),dict(type='PackSegInputs')
]# 测试预处理
test_pipeline = [dict(type='LoadImageFromFile'),dict(type='Resize', scale=(2048, 1024), keep_ratio=True),dict(type='LoadAnnotations'),dict(type='PackSegInputs')
]# TTA后处理
img_ratios = [0.5, 0.75, 1.0, 1.25, 1.5, 1.75]
tta_pipeline = [dict(type='LoadImageFromFile', file_client_args=dict(backend='disk')),dict(type='TestTimeAug',transforms=[[dict(type='Resize', scale_factor=r, keep_ratio=True)for r in img_ratios],[dict(type='RandomFlip', prob=0., direction='horizontal'),dict(type='RandomFlip', prob=1., direction='horizontal')], [dict(type='LoadAnnotations')], [dict(type='PackSegInputs')]])
]# 训练 Dataloader
train_dataloader = dict(batch_size=2,num_workers=0,persistent_workers=True,sampler=dict(type='InfiniteSampler', shuffle=True),dataset=dict(type=dataset_type,data_root=data_root,data_prefix=dict(img_path='img_dir/train', seg_map_path='ann_dir/train'),pipeline=train_pipeline))# 验证 Dataloader
val_dataloader = dict(batch_size=1,num_workers=0,persistent_workers=True,sampler=dict(type='DefaultSampler', shuffle=False),dataset=dict(type=dataset_type,data_root=data_root,data_prefix=dict(img_path='img_dir/val', seg_map_path='ann_dir/val'),pipeline=test_pipeline))# 测试 Dataloader
test_dataloader = val_dataloader# 验证 Evaluator
val_evaluator = dict(type='IoUMetric', iou_metrics=['mIoU', 'mDice', 'mFscore'])# 测试 Evaluator
test_evaluator = val_evaluator4.配置生成
在主目录下新建configset.py,并添加如下代码。
改代码中主要用于配置训练参数,右键运行生成配置文件。
from mmengine import Config
cfg = Config.fromfile('./configs/unet/unet-s5-d16_fcn_4xb4-160k_cityscapes-512x1024.py') ##选择训练模型
dataset_cfg = Config.fromfile('./configs/_base_/datasets/mysegDataset_pipeline.py') ## 选择pipeline
cfg.merge_from_dict(dataset_cfg)# 类别个数
NUM_CLASS = 6cfg.crop_size = (256, 256)
cfg.model.data_preprocessor.size = cfg.crop_size
cfg.model.data_preprocessor.test_cfg = dict(size_divisor=128)# 单卡训练时,需要把 SyncBN 改成 BN
cfg.norm_cfg = dict(type='BN', requires_grad=True) # 只使用GPU时,BN取代SyncBN
cfg.model.backbone.norm_cfg = cfg.norm_cfg
cfg.model.decode_head.norm_cfg = cfg.norm_cfg
cfg.model.auxiliary_head.norm_cfg = cfg.norm_cfg# 模型 decode/auxiliary 输出头,指定为类别个数
cfg.model.decode_head.num_classes = NUM_CLASS
cfg.model.auxiliary_head.num_classes = NUM_CLASS# 训练 Batch Size
cfg.train_dataloader.batch_size = 2# 结果保存目录
cfg.work_dir = './work_dirs/mysegDataset-UNet'# 模型保存与日志记录
cfg.train_cfg.max_iters = 10000 # 训练迭代次数
cfg.train_cfg.val_interval = 500 # 评估模型间隔
cfg.default_hooks.logger.interval = 100 # 日志记录间隔
cfg.default_hooks.checkpoint.interval = 2500 # 模型权重保存间隔
cfg.default_hooks.checkpoint.max_keep_ckpts = 1 # 最多保留几个模型权重
cfg.default_hooks.checkpoint.save_best = 'mIoU' # 保留指标最高的模型权重# 随机数种子
cfg['randomness'] = dict(seed=0)cfg.dump('myconfigs/mysegDataset_UNet.py')5.修改num_workers=0
使用Windows系统训练,将上一步生成的配置文件中所有的num_workers修改成0。
crop_size = (256,256,
)
data_preprocessor = dict(bgr_to_rgb=True,mean=[123.675,116.28,103.53,],pad_val=0,seg_pad_val=255,size=(512,1024,),std=[58.395,57.12,57.375,],type='SegDataPreProcessor')
data_root = 'Watermelon87_Semantic_Seg_Mask/'
dataset_type = 'mysegDataset'
default_hooks = dict(checkpoint=dict(by_epoch=False,interval=2500,max_keep_ckpts=1,save_best='mIoU',type='CheckpointHook'),logger=dict(interval=100, log_metric_by_epoch=False, type='LoggerHook'),param_scheduler=dict(type='ParamSchedulerHook'),sampler_seed=dict(type='DistSamplerSeedHook'),timer=dict(type='IterTimerHook'),visualization=dict(type='SegVisualizationHook'))
default_scope = 'mmseg'
env_cfg = dict(cudnn_benchmark=True,dist_cfg=dict(backend='nccl'),mp_cfg=dict(mp_start_method='fork', opencv_num_threads=0))
img_ratios = [0.5,0.75,1.0,1.25,1.5,1.75,
]
load_from = None
log_level = 'INFO'
log_processor = dict(by_epoch=False)
model = dict(auxiliary_head=dict(align_corners=False,channels=64,concat_input=False,dropout_ratio=0.1,in_channels=128,in_index=3,loss_decode=dict(loss_weight=0.4, type='CrossEntropyLoss', use_sigmoid=False),norm_cfg=dict(requires_grad=True, type='BN'),num_classes=6,num_convs=1,type='FCNHead'),backbone=dict(act_cfg=dict(type='ReLU'),base_channels=64,conv_cfg=None,dec_dilations=(1,1,1,1,),dec_num_convs=(2,2,2,2,),downsamples=(True,True,True,True,),enc_dilations=(1,1,1,1,1,),enc_num_convs=(2,2,2,2,2,),in_channels=3,norm_cfg=dict(requires_grad=True, type='BN'),norm_eval=False,num_stages=5,strides=(1,1,1,1,1,),type='UNet',upsample_cfg=dict(type='InterpConv'),with_cp=False),data_preprocessor=dict(bgr_to_rgb=True,mean=[123.675,116.28,103.53,],pad_val=0,seg_pad_val=255,size=(256,256,),std=[58.395,57.12,57.375,],test_cfg=dict(size_divisor=128),type='SegDataPreProcessor'),decode_head=dict(align_corners=False,channels=64,concat_input=False,dropout_ratio=0.1,in_channels=64,in_index=4,loss_decode=dict(loss_weight=1.0, type='CrossEntropyLoss', use_sigmoid=False),norm_cfg=dict(requires_grad=True, type='BN'),num_classes=6,num_convs=1,type='FCNHead'),pretrained=None,test_cfg=dict(crop_size=256, mode='whole', stride=170),train_cfg=dict(),type='EncoderDecoder')
norm_cfg = dict(requires_grad=True, type='BN')
optim_wrapper = dict(clip_grad=None,optimizer=dict(lr=0.01, momentum=0.9, type='SGD', weight_decay=0.0005),type='OptimWrapper')
optimizer = dict(lr=0.01, momentum=0.9, type='SGD', weight_decay=0.0005)
param_scheduler = [dict(begin=0,by_epoch=False,end=160000,eta_min=0.0001,power=0.9,type='PolyLR'),
]
randomness = dict(seed=0)
resume = False
test_cfg = dict(type='TestLoop')
test_dataloader = dict(batch_size=1,dataset=dict(data_prefix=dict(img_path='img_dir/val', seg_map_path='ann_dir/val'),data_root='Watermelon87_Semantic_Seg_Mask/',pipeline=[dict(type='LoadImageFromFile'),dict(keep_ratio=True, scale=(2048,1024,), type='Resize'),dict(type='LoadAnnotations'),dict(type='PackSegInputs'),],type='mysegDataset'),num_workers=0,persistent_workers=False,sampler=dict(shuffle=False, type='DefaultSampler'))
test_evaluator = dict(iou_metrics=['mIoU','mDice','mFscore',], type='IoUMetric')
test_pipeline = [dict(type='LoadImageFromFile'),dict(keep_ratio=True, scale=(2048,1024,), type='Resize'),dict(type='LoadAnnotations'),dict(type='PackSegInputs'),
]
train_cfg = dict(max_iters=10000, type='IterBasedTrainLoop', val_interval=500)
train_dataloader = dict(batch_size=2,dataset=dict(data_prefix=dict(img_path='img_dir/train', seg_map_path='ann_dir/train'),data_root='Watermelon87_Semantic_Seg_Mask/',pipeline=[dict(type='LoadImageFromFile'),dict(type='LoadAnnotations'),dict(keep_ratio=True,ratio_range=(0.5,2.0,),scale=(2048,1024,),type='RandomResize'),dict(cat_max_ratio=0.75, crop_size=(512,512,), type='RandomCrop'),dict(prob=0.5, type='RandomFlip'),dict(type='PhotoMetricDistortion'),dict(type='PackSegInputs'),],type='mysegDataset'),num_workers=0,persistent_workers=False,sampler=dict(shuffle=True, type='InfiniteSampler'))
train_pipeline = [dict(type='LoadImageFromFile'),dict(type='LoadAnnotations'),dict(keep_ratio=True,ratio_range=(0.5,2.0,),scale=(2048,1024,),type='RandomResize'),dict(cat_max_ratio=0.75, crop_size=(512,512,), type='RandomCrop'),dict(prob=0.5, type='RandomFlip'),dict(type='PhotoMetricDistortion'),dict(type='PackSegInputs'),
]
tta_model = dict(type='SegTTAModel')
tta_pipeline = [dict(file_client_args=dict(backend='disk'), type='LoadImageFromFile'),dict(transforms=[[dict(keep_ratio=True, scale_factor=0.5, type='Resize'),dict(keep_ratio=True, scale_factor=0.75, type='Resize'),dict(keep_ratio=True, scale_factor=1.0, type='Resize'),dict(keep_ratio=True, scale_factor=1.25, type='Resize'),dict(keep_ratio=True, scale_factor=1.5, type='Resize'),dict(keep_ratio=True, scale_factor=1.75, type='Resize'),],[dict(direction='horizontal', prob=0.0, type='RandomFlip'),dict(direction='horizontal', prob=1.0, type='RandomFlip'),],[dict(type='LoadAnnotations'),],[dict(type='PackSegInputs'),],],type='TestTimeAug'),
]
val_cfg = dict(type='ValLoop')
val_dataloader = dict(batch_size=1,dataset=dict(data_prefix=dict(img_path='img_dir/val', seg_map_path='ann_dir/val'),data_root='Watermelon87_Semantic_Seg_Mask/',pipeline=[dict(type='LoadImageFromFile'),dict(keep_ratio=True, scale=(2048,1024,), type='Resize'),dict(type='LoadAnnotations'),dict(type='PackSegInputs'),],type='mysegDataset'),num_workers=0,persistent_workers=False,sampler=dict(shuffle=False, type='DefaultSampler'))
val_evaluator = dict(iou_metrics=['mIoU','mDice','mFscore',], type='IoUMetric')
vis_backends = [dict(type='LocalVisBackend'),
]
visualizer = dict(name='visualizer',type='SegLocalVisualizer',vis_backends=[dict(type='LocalVisBackend'),])
work_dir = './work_dirs/mysegDataset-UNet'
6.训练模型
在终端中运行以下命令:
python tools/train.py myconfigs/mysegDataset_UNet.py相关文章:
Windows11+PyCharm利用MMSegmentation训练自己的数据集保姆级教程
系统版本:Windows 11 依赖环境:Anaconda3 运行软件:PyCharm 一.环境配置 通过Anaconda Prompt(anaconda)打开终端创建一个虚拟环境 conda create --name mmseg python3.93.激活虚拟环境 conda activate mmseg 4.安装pytorch和cuda tor…...

WPS计算机二级•文档的文本样式与编号
听说这是目录哦 标题级别❤️新建文本样式 快速套用格式🩷设置标题样式 自定义设置多级编号🧡使用自动编号💛取消自动编号💚设置 页面边框💙添加水印🩵排版技巧怎么分栏💜添加空白下划线&#x…...

Word中Ctrl+V粘贴报错问题
Word中CtrlV粘贴时显示“文件未找到:MathPage.WLL”的问题 Word的功能栏中有MathType,但无法使用,显示灰色。 解决方法如下: 首先找到MathType安装目录下MathPage.wll文件以及MathType Commands 2016.dotm文件,分别复…...

python-leetcode 24.回文链表
题目: 给定单链表的头节点head,判断该链表是否为回文链表,如果是,返回True,否则,返回False 输入:head[1,2,2,1] 输出:true 方法一:将值复制到数组中后用双指针法 有两种常用的列表实现&#…...

数据治理双证通关经验分享 | CDGA/CDGP备考全指南
历经1个月多的系统准备,本人于2024年顺利通过DAMA China的CDGA(数据治理工程师)和CDGP(数据治理专家)双认证。现将备考经验与资源体系化整理,助力从业者高效通关。 🌟 认证价值与政策背景 根据…...

3.4 学习UVM中的uvm_monitor类分为几步?
文章目录 前言1. 定义2. 核心功能3. 适用场景4. 使用方法5. 完整代码示例5.1 事务类定义5.2 Monitor 类定义5.3 Scoreboard 类定义5.4 测试平台 6. 代码说明7. 总结 前言 以下是关于 UVM 中 uvm_monitor 的详细解释、核心功能、适用场景、使用方法以及一个完整的代码示例&…...

Java在大数据处理中的应用:从MapReduce到Spark
Java在大数据处理中的应用:从MapReduce到Spark 大数据时代的到来让数据的存储、处理和分析变得前所未有的重要。随着数据量的剧增,传统的单机计算方式已经无法满足处理需求。为了解决这个问题,许多分布式计算框架应运而生,其中Ma…...

日常吐槽。
一、写在前面 stereopy日常出bug(github issue里得有一半的问题是我提的,当然也有可能是因为我菜),stereopy自己生成的anndata自己不能计算空间共现关系,还是靠squidpy才能计算。另外还要一些函数一开并行计算就报错,这里留一些s…...

2025最新版Node.js下载安装~保姆级教程
1. node中文官网地址:http://nodejs.cn/download/ 2.打开node官网下载压缩包: 根据操作系统不同选择不同版本(win7系统建议安装v12.x) 我这里选择最新版win 64位 3.安装node ①点击对话框中的“Next”,勾选同意后点…...
机器学习:学习记录(二)
1. 机器学习中的常用函数 logistic函数(sigmoid函数):非线性激活函数,将R区间映射到(0,1)区间 ReLU函数:非线性激活函数,简单可以写作max(0,x),在0处不可导,但是可以人为定义其导数…...

迁移学习 Transfer Learning
迁移学习(Transfer Learning)是什么? 迁移学习是一种机器学习方法,它的核心思想是利用已有模型的知识来帮助新的任务或数据集进行学习,从而减少训练数据的需求、加快训练速度,并提升模型性能。 …...

实现:多活的基础中间件
APIRouter : 路由分发服务 API Router 是一个 HTTP 反向代理和负载均衡器,部署在公有云中作为 HTTP API 流量的入口,它能识别 出流量的归属 shard ,并根据 shard 将流量转发到对应的 ezone 。 API Router 支持多种路由键&am…...
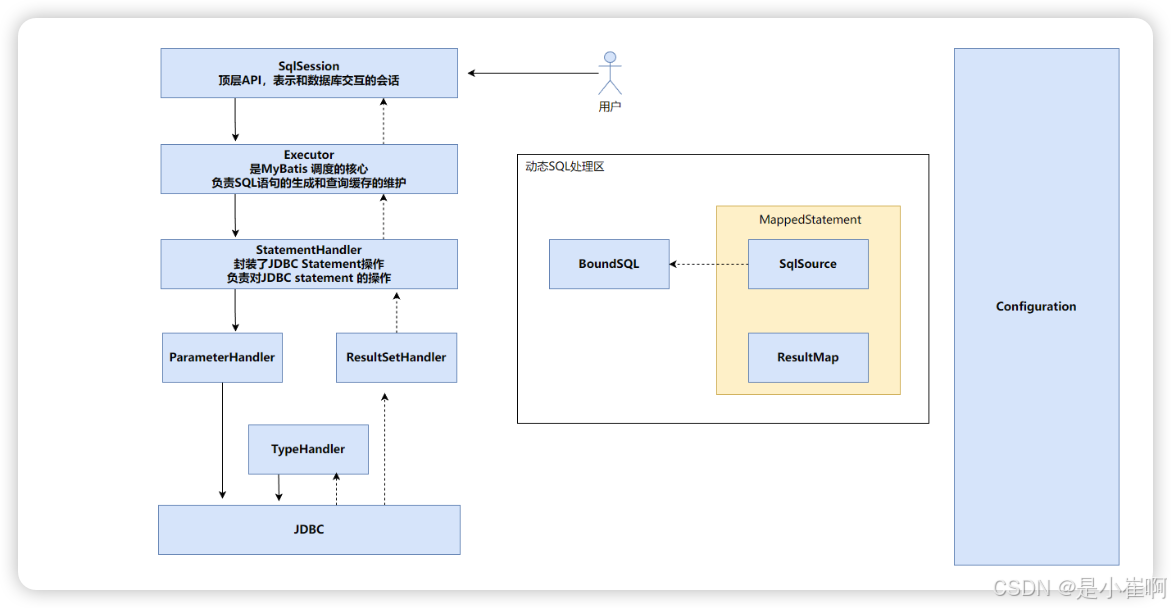
Mybatis源码01 - 总体框架设计
Mybatis总体框架设计 文章目录 Mybatis总体框架设计一:MyBatis架构概览1:接口层1.1:使用传统的MyBatis提供的API1.2:使用Mapper接口 2:数据处理层【核心】2.1:参数映射和动态SQL语句生成2.2:SQL…...

在大型语言模型(LLM)框架内Transformer架构与混合专家(MoE)策略的概念整合
文章目录 传统的神经网络框架存在的问题一. Transformer架构综述1.1 transformer的输入1.1.1 词向量1.1.2 位置编码(Positional Encoding)1.1.3 编码器与解码器结构1.1.4 多头自注意力机制 二.Transformer分步详解2.1 传统词向量存在的问题2.2 详解编解码…...

Selenium WebDriver自动化测试(扩展篇)--Jenkins持续集成
文章目录 一、引言二、Jenkins简介三、安装部署Jenkins安装部署 四、集成Git与Maven安装必要的插件配置Git配置Maven 五、创建Job创建自由风格的项目配置源码管理配置构建触发器配置构建环境配置构建步骤配置Post-build Actions 六、触发构建示例:GitHub Webhook触发…...

Wiki文档转换为Word技术
一、技术背景与目标 Wiki系统导出的文档通常以HTML格式存在,且内容分散在多个文件中,每个页面对应一个HTML文件。然而,Microsoft Word(Word)在处理HTML文件时,仅支持单个HTML文件的导入。因此,为了将Wiki导出的内容转换为Word可识别的格式,必须将分散的HTML文件整合为一…...

1.【线性代数】——方程组的几何解释
一 方程组的几何解释 概述举例举例一1. matrix2.row picture3.column picture 概述 三种表示方法 matrixrow picturecolumn picture 举例 举例一 { 2 x − y 0 − x 2 y 3 \begin{cases} 2x - y 0 \\ -x 2y 3 \end{cases} {2x−y0−x2y3 1. matrix [ 2 − 1 − 1 …...

力扣1448. 统计二叉树中好节点的数目
Problem: 1448. 统计二叉树中好节点的数目 文章目录 题目描述思路复杂度Code 题目描述 思路 对二叉树进行先序遍历,边遍历边对比并更新当前路径上的最大值pathMax,若当pathMax小于等于当前节点值,则好节点的数目加一 复杂度 时间复杂度: O (…...
——C#注释和命名法详解)
【C#零基础从入门到精通】(二)——C#注释和命名法详解
【C#零基础从入门到精通】(二)——C#注释和命名法详解 C# 中的注释 定义 在 C# 里,注释是一种特殊的代码文本,它不会被编译器执行,主要用于对代码进行解释、说明,帮助开发者更好地理解代码的功能、用途、实现思路以及注意事项等,提升代码的可读性和可维护性。 注释类型…...

SQLServer的创建,表创建,主键,约束,模糊查询
设置 注意: 设置完成之后 重新启动 创建数据库 注意: 这个目标路径必须要有该文件名的文件夹 -- 指向 master 数据库,告诉它我们要创建一个新的数据库操作了 use master go-- 创建数据库 create database StudentManageDB on primary (-- 以下四个组成部分缺一不可…...

3分钟搞定!PowerToys中文版终极配置指南,让Windows效率提升300%
3分钟搞定!PowerToys中文版终极配置指南,让Windows效率提升300% 【免费下载链接】PowerToys-CN PowerToys Simplified Chinese Translation 微软增强工具箱 自制汉化 项目地址: https://gitcode.com/gh_mirrors/po/PowerToys-CN 你是否曾经面对Po…...

Windows Defender彻底移除工具:2025终极完整使用教程
Windows Defender彻底移除工具:2025终极完整使用教程 【免费下载链接】windows-defender-remover A tool which is uses to remove Windows Defender in Windows 8.x, Windows 10 (every version) and Windows 11. 项目地址: https://gitcode.com/gh_mirrors/wi/w…...

如何快速解密RPG Maker加密文件:新手必看的完整解密指南
如何快速解密RPG Maker加密文件:新手必看的完整解密指南 【免费下载链接】RPGMakerDecrypter Tool for decrypting and extracting RPG Maker XP, VX and VX Ace encrypted archives and MV and MZ encrypted files. 项目地址: https://gitcode.com/gh_mirrors/rp…...

Google Authenticator停更引发恐慌?自建TOTP动态口令系统其实没那么难,附技术实现方案
摘要:2023年,Google Authenticator推出账号同步功能,将TOTP密钥同步到Google账号云端,引发了安全社区的广泛争议——密钥上云意味着什么?企业级场景中,依赖第三方应用管理关键认证密钥本身就是隐患。本文讲…...

MFC深入-MFC和win32
MFC和Win32 MFC Object和Windows Object的关系 MFC中最重要的封装是对Win32 API的封装,因此,理解Windows Object和MFC Object (C对象,一个C类的实例)之间的关系是理解MFC的关键之一。所谓Windows Object(Windows对象)是…...

10个必备的Solidity安全技巧:Secureum-mind_map实践经验分享
10个必备的Solidity安全技巧:Secureum-mind_map实践经验分享 【免费下载链接】secureum-mind_map Central Repository for the Epoch 0 coursework and quizzes. Contains all the content, cross-referenced and linked. 项目地址: https://gitcode.com/gh_mirr…...

TrollInstallerX终极指南:iOS 14-16.6.1越狱工具一键部署全解析
TrollInstallerX终极指南:iOS 14-16.6.1越狱工具一键部署全解析 【免费下载链接】TrollInstallerX A TrollStore installer for iOS 14.0 - 16.6.1 项目地址: https://gitcode.com/gh_mirrors/tr/TrollInstallerX 想要在iOS 14.0到16.6.1系统上轻松安装Troll…...

告别91卫图!用QGIS Python脚本批量下载Google/Bing卫星图,附完整代码
开源GIS实战:Python脚本自动化下载Google/Bing卫星影像全攻略 当你在深夜赶制城市规划方案时,突然发现91卫图下载的影像分辨率不足;当科研项目需要批量获取区域卫星数据时,商业软件高昂的授权费用让你望而却步——这可能是每个GIS…...
)
汽车资讯网站|基于springboot+vue的汽车资讯网站(源码+数据库+文档)
汽车资讯网站 目录 基于springbootvue的汽车资讯网站 一、前言 二、系统设计 三、系统功能设计 四、数据库设计 五、核心代码 六、论文参考 七、最新计算机毕设选题推荐 八、源码获取: 博主介绍:✌️大厂码农|毕设布道师,阿里云开…...

DS4Windows完全指南:让你的PS4手柄在Windows上大放异彩 [特殊字符]
DS4Windows完全指南:让你的PS4手柄在Windows上大放异彩 🎮 【免费下载链接】DS4Windows Like those other ds4tools, but sexier 项目地址: https://gitcode.com/gh_mirrors/ds/DS4Windows 还在为PC游戏不支持PS4手柄而烦恼吗?想要在W…...