第39周:猫狗识别 2(Tensorflow实战第九周)
目录
前言
一、前期工作
1.1 设置GPU
1.2 导入数据
输出
二、数据预处理
2.1 加载数据
2.2 再次检查数据
2.3 配置数据集
2.4 可视化数据
三、构建VGG-16网络
3.1 VGG-16网络介绍
3.2 搭建VGG-16模型
四、编译
五、训练模型
5.1 上次程序的主要Bug
5.2 修改版如下
六、模型评估
七、预测
总结
前言
🍨 本文为[🔗365天深度学习训练营](https://mp.weixin.qq.com/s/rnFa-IeY93EpjVu0yzzjkw) 中的学习记录博客🍖 原作者:[K同学啊](https://mtyjkh.blog.csdn.net/)
说在前面
1)本周任务:找到并处理第8周的程序问题;拔高--尝试增加数据增强部分的内容以提高准确率
2)运行环境:Python3.6、Pycharm2020、tensorflow2.4.0
一、前期工作
1.1 设置GPU
代码如下:
# 1.1 设置GPU
import tensorflow as tf
gpus = tf.config.list_physical_devices("GPU")if gpus:tf.config.experimental.set_memory_growth(gpus[0], True) #设置GPU显存用量按需使用tf.config.set_visible_devices([gpus[0]],"GPU")
# 打印显卡信息,确认GPU可用
print(gpus)输出:[PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]
1.2 导入数据
代码如下:
# 1.2 导入数据
import numpy as np
import matplotlib.pyplot as plt
# 支持中文
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
import os,PIL,pathlib#隐藏警告
import warnings
warnings.filterwarnings('ignore')
data_dir = "./data"
data_dir = pathlib.Path(data_dir)
image_count = len(list(data_dir.glob('*/*')))
print("图片总数为:",image_count)输出
图片总数为: 3400
二、数据预处理
2.1 加载数据
使用image_dataset_from_directory方法将磁盘中的数据加载到tf.data.Dataset,tf.keras.preprocessing.image_dataset_from_directory():是 TensorFlow 的 Keras 模块中的一个函数,用于从目录中创建一个图像数据集(dataset)。这个函数可以以更方便的方式加载图像数据,用于训练和评估神经网络模型
测试集与验证集的关系:
- 验证集并没有参与训练过程梯度下降过程的,狭义上来讲是没有参与模型的参数训练更新的。
- 但是广义上来讲,验证集存在的意义确实参与了一个“人工调参”的过程,我们根据每一个epoch训练之后模型在valid data上的表现来决定是否需要训练进行early stop,或者根据这个过程模型的性能变化来调整模型的超参数,如学习率,batch_size等等。因此,我们也可以认为,验证集也参与了训练,但是并没有使得模型去overfit验证集
- 因此,我们也可以认为,验证集也参与了训练,但是并没有使得模型去overfit验证集
代码如下:
# 二、数据预处理
# 2.1 加载数据
batch_size = 64
img_height = 224
img_width = 224
train_ds = tf.keras.preprocessing.image_dataset_from_directory(data_dir,validation_split=0.2,subset="training",seed=12,image_size=(img_height, img_width),batch_size=batch_size)
val_ds = tf.keras.preprocessing.image_dataset_from_directory(data_dir,validation_split=0.2,subset="validation",seed=12,image_size=(img_height, img_width),batch_size=batch_size)
class_names = train_ds.class_names
print(class_names)输出如下:
Found 3400 files belonging to 2 classes.
Using 2720 files for training.
Found 3400 files belonging to 2 classes.
Using 680 files for validation.['cat', 'dog']
2.2 再次检查数据
代码如下:
# 2.2 再次检查数据
for image_batch, labels_batch in train_ds:print(image_batch.shape)print(labels_batch.shape)break输出:
(64, 224, 224, 3)
(64,)
2.3 配置数据集
代码如下:
# 2.3 配置数据集
AUTOTUNE = tf.data.AUTOTUNE
def preprocess_image(image,label):return (image/255.0,label)
# 归一化处理
train_ds = train_ds.map(preprocess_image, num_parallel_calls=AUTOTUNE)
val_ds = val_ds.map(preprocess_image, num_parallel_calls=AUTOTUNE)
train_ds = train_ds.cache().shuffle(1000).prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
2.4 可视化数据
代码如下:
# 2.4 可视化数据
plt.figure(figsize=(15, 10)) # 图形的宽为15高为10
for images, labels in train_ds.take(1):for i in range(8):ax = plt.subplot(5, 8, i + 1)plt.imshow(images[i])plt.title(class_names[labels[i]])plt.axis("off")输出:

三、构建VGG-16网络
3.1 VGG-16网络介绍
结构说明:
- 13个卷积层(Convolutional Layer),分别用
blockX_convX表示 - 3个全连接层(Fully connected Layer),分别用
fcX与predictions表示 - 5个池化层(Pool layer),分别用
blockX_pool表示
VGG优缺点分析:
- VGG优点:VGG的结构非常简洁,整个网络都使用了同样大小的卷积核尺寸(3x3)和最大池化尺寸(2x2)。
- VGG缺点:1)训练时间过长,调参难度大。2)需要的存储容量大,不利于部署。例如存储VGG-16权重值文件的大小为500多MB,不利于安装到嵌入式系统中。
网络结构图如下(包含了16个隐藏层--13个卷积层和3个全连接层,故称为VGG-16)


3.2 搭建VGG-16模型
代码如下:
# 三、构建VGG-16网络
from tensorflow.keras import layers, models, Input
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Dense, Flatten, Dropoutdef VGG16(nb_classes, input_shape):input_tensor = Input(shape=input_shape)# 1st blockx = Conv2D(64, (3,3), activation='relu', padding='same',name='block1_conv1')(input_tensor)x = Conv2D(64, (3,3), activation='relu', padding='same',name='block1_conv2')(x)x = MaxPooling2D((2,2), strides=(2,2), name = 'block1_pool')(x)# 2nd blockx = Conv2D(128, (3,3), activation='relu', padding='same',name='block2_conv1')(x)x = Conv2D(128, (3,3), activation='relu', padding='same',name='block2_conv2')(x)x = MaxPooling2D((2,2), strides=(2,2), name = 'block2_pool')(x)# 3rd blockx = Conv2D(256, (3,3), activation='relu', padding='same',name='block3_conv1')(x)x = Conv2D(256, (3,3), activation='relu', padding='same',name='block3_conv2')(x)x = Conv2D(256, (3,3), activation='relu', padding='same',name='block3_conv3')(x)x = MaxPooling2D((2,2), strides=(2,2), name = 'block3_pool')(x)# 4th blockx = Conv2D(512, (3,3), activation='relu', padding='same',name='block4_conv1')(x)x = Conv2D(512, (3,3), activation='relu', padding='same',name='block4_conv2')(x)x = Conv2D(512, (3,3), activation='relu', padding='same',name='block4_conv3')(x)x = MaxPooling2D((2,2), strides=(2,2), name = 'block4_pool')(x)# 5th blockx = Conv2D(512, (3,3), activation='relu', padding='same',name='block5_conv1')(x)x = Conv2D(512, (3,3), activation='relu', padding='same',name='block5_conv2')(x)x = Conv2D(512, (3,3), activation='relu', padding='same',name='block5_conv3')(x)x = MaxPooling2D((2,2), strides=(2,2), name = 'block5_pool')(x)# full connectionx = Flatten()(x)x = Dense(4096, activation='relu', name='fc1')(x)x = Dense(4096, activation='relu', name='fc2')(x)output_tensor = Dense(nb_classes, activation='softmax', name='predictions')(x)model = Model(input_tensor, output_tensor)return model
model=VGG16(1000, (img_width, img_height, 3))
model.summary()四、编译
代码如下:
model.compile(optimizer="adam",loss='sparse_categorical_crossentropy',metrics=['accuracy'])五、训练模型
5.1 上次程序的主要Bug
训练中的主要问题为acc、loss等的更新计算方式!!!
修改前:将每训练1个batch之后的损失和准确率直接记录进history_train/val_loss和history_train/val_accuracy当中,最后记录的只是整个epoch中最后1个batch所得的损失和准确率而不是整个epoch中训练数据的平均值;
# 记录训练数据,方便后面的分析
history_train_loss = []
history_train_accuracy = []
history_val_loss = []
history_val_accuracy = []
for epoch in range(epochs):train_total = len(train_ds)val_total = len(val_ds)with tqdm(total=train_total, desc=f'Epoch {epoch + 1}/{epochs}', mininterval=1, ncols=100) as pbar:lr = lr * 0.92K.set_value(model.optimizer.lr, lr)for image, label in train_ds:history = model.train_on_batch(image, label)train_loss = history[0]train_accuracy = history[1]pbar.set_postfix({"loss": "%.4f" % train_loss,"accuracy": "%.4f" % train_accuracy,"lr": K.get_value(model.optimizer.lr)})pbar.update(1)history_train_loss.append(train_loss)history_train_accuracy.append(train_accuracy)print('开始验证!')with tqdm(total=val_total, desc=f'Epoch {epoch + 1}/{epochs}', mininterval=0.3, ncols=100) as pbar:for image, label in val_ds:history = model.test_on_batch(image, label)val_loss = history[0]val_accuracy = history[1]pbar.set_postfix({"loss": "%.4f" % val_loss,"accuracy": "%.4f" % val_accuracy})pbar.update(1)history_val_loss.append(val_loss)history_val_accuracy.append(val_accuracy)print('结束验证!')print("验证loss为:%.4f" % val_loss)print("验证准确率为:%.4f" % val_accuracy)5.2 修改版如下
修改后: 每次处理一个 batch后,将该 batch 的损失和准确率保存在loss和accuracy列表中。计算1个epoch中所有batch的训练损失和准确率的平均值,并将均值记录到history_train/val_loss或history_train/val_accuracy中。能够更准确地反映整个训练集和验证集上的表现。
代码如下:
# 五、训练模型
from tqdm import tqdm
import tensorflow.keras.backend as K
epochs = 10
lr = 1e-4
# 记录训练数据,方便后面的分析
history_train_loss = []
history_train_accuracy = []
history_val_loss = []
history_val_accuracy = []
for epoch in range(epochs):train_total = len(train_ds)val_total = len(val_ds)"""total:预期的迭代数目ncols:控制进度条宽度mininterval:进度更新最小间隔,以秒为单位(默认值:0.1)"""with tqdm(total=train_total, desc=f'Epoch {epoch + 1}/{epochs}', mininterval=1, ncols=100) as pbar:lr = lr * 0.92K.set_value(model.optimizer.lr, lr)train_loss = []train_accuracy = []for image, label in train_ds:# 这里生成的是每一个batch的acc与losshistory = model.train_on_batch(image, label)train_loss.append(history[0])train_accuracy.append(history[1])pbar.set_postfix({"train_loss": "%.4f" % history[0],"train_acc": "%.4f" % history[1],"lr": K.get_value(model.optimizer.lr)})pbar.update(1)history_train_loss.append(np.mean(train_loss))history_train_accuracy.append(np.mean(train_accuracy))print('开始验证!')with tqdm(total=val_total, desc=f'Epoch {epoch + 1}/{epochs}', mininterval=0.3, ncols=100) as pbar:val_loss = []val_accuracy = []for image, label in val_ds:# 这里生成的是每一个batch的acc与losshistory = model.test_on_batch(image, label)val_loss.append(history[0])val_accuracy.append(history[1])pbar.set_postfix({"val_loss": "%.4f" % history[0],"val_acc": "%.4f" % history[1]})pbar.update(1)history_val_loss.append(np.mean(val_loss))history_val_accuracy.append(np.mean(val_accuracy))print('结束验证!')print("验证loss为:%.4f" % np.mean(val_loss))print("验证准确率为:%.4f" % np.mean(val_accuracy))打印训练过程:


六、模型评估
代码如下:
# 六、模型评估
from datetime import datetime
current_time = datetime.now() # 获取当前时间
epochs_range = range(epochs)
plt.figure(figsize=(14, 4))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, history_train_accuracy, label='Training Accuracy')
plt.plot(epochs_range, history_val_accuracy, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.xlabel(current_time) # 打卡请带上时间戳,否则代码截图无效
plt.subplot(1, 2, 2)
plt.plot(epochs_range, history_train_loss, label='Training Loss')
plt.plot(epochs_range, history_val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()训练结果可视化如下:

七、预测
代码如下:
# 七、预测
# 采用加载的模型(new_model)来看预测结果
plt.figure(figsize=(18, 3)) # 图形的宽为18高为5
plt.suptitle("预测结果展示")
for images, labels in val_ds.take(1):for i in range(8):ax = plt.subplot(1, 8, i + 1)# 显示图片plt.imshow(images[i].numpy())# 需要给图片增加一个维度img_array = tf.expand_dims(images[i], 0)# 使用模型预测图片中的人物predictions = model.predict(img_array)plt.title(class_names[np.argmax(predictions)])plt.axis("off")
输出:
1/1 [==============================] - 0s 129ms/step
1/1 [==============================] - 0s 19ms/step
1/1 [==============================] - 0s 18ms/step
1/1 [==============================] - 0s 18ms/step
1/1 [==============================] - 0s 17ms/step
1/1 [==============================] - 0s 18ms/step
1/1 [==============================] - 0s 17ms/step
1/1 [==============================] - 0s 17ms/step
总结
- Tensorflow训练过程中打印多余信息的处理,并且引入了进度条的显示方式,更加方便及时查看模型训练过程中的情况,可以及时打印各项指标
- 发现了上次程序的Bug,对于历次准确率和loss的保存逻辑
- 下次继续探索采用不同数据增强方式来提高准确率的方法
相关文章:
第39周:猫狗识别 2(Tensorflow实战第九周)
目录 前言 一、前期工作 1.1 设置GPU 1.2 导入数据 输出 二、数据预处理 2.1 加载数据 2.2 再次检查数据 2.3 配置数据集 2.4 可视化数据 三、构建VGG-16网络 3.1 VGG-16网络介绍 3.2 搭建VGG-16模型 四、编译 五、训练模型 5.1 上次程序的主要Bug 5.2 修改版…...

力扣--239.滑动窗口最大值
问题 给你一个整数数组 nums,有一个大小为 k 的滑动窗口从数组的最左侧移动到数组的最右侧。你只可以看到在滑动窗口内的 k 个数字。滑动窗口每次只向右移动一位。 返回 滑动窗口中的最大值 。 示例 1: 输入:nums [1,3,-1,-3,5,3,6,7], …...
傅里叶变换推导
基本模型 假设在二维直角坐标系中,可以用相互垂直的基向量和表示: 假设: 假设在上的投影为,那么: 所以: 用公式表达: 但是在实际中,基向量和不一定长度都是1,重新推导一…...

扣子工作流中禁止同类别的图像流节点,不能超过4个
一、问题1不能在一个工作流中超过4个图像的并行节点 1、现象 本来想着在扣子中一次生成多张图片。 然后问了扣子小助手 2、图像节点限制 扣子给了如下反馈 近期图像流上线了并发限额,具体规则如下: 针对对象:单用户维度,非 bot…...

Java 语言深度剖析与实践应用
一、引言 Java 作为一种广泛应用于各种领域的编程语言,自 1995 年诞生以来,凭借其跨平台性、面向对象特性、丰富的类库以及强大的生态系统,在软件开发行业占据着重要地位。无论是企业级应用开发、移动应用开发、大数据处理还是分布式系统构建…...

1.14学习总结
日常刷题单 刷了题目后,对于排序方法更加熟练,手搓代码的速度也得到了提高。 感觉字符串还不熟练,高精度更是云里雾里,上升空间极大。 同时看见今晚有个入门难度的测试,去练了练手,想看看自己是什么成分&…...

C++蓝桥杯基础篇(三)
片头 哈喽!小伙伴们,大家好~,今天我们来学习蓝桥杯基础篇(三),继续练习相关习题,准备好了吗?我们开始啦~ 一、while循环 可以简单理解为循环版的if语句。if语句是判断1次࿰…...

微信小程序的制作
制作微信小程序的过程大致可以分为几个步骤:从环境搭建、项目创建,到开发、调试和发布。下面我会为你简要介绍每个步骤。 1. 准备工作 在开始开发微信小程序之前,你需要确保你已经完成了以下几个步骤: 注册微信小程序账号&…...

Sass更新:@import——>@use
背景:将一个公共的CSS样式文件导入到任意一个组件中进行使用 一、创建并使用CSS公共样式文件 1、在目录的assets目录下创建一个style文件夹,里面存放一个.scss文件(例:mixin.scss) 2、文件内以mixin来设置名为flex的…...
Python使用Flask结合DeepSeek开发
一、背景 我之前关于DeepSeek使用ollama部署的文章大家可以把DeepSeek大模型部署起来。那么ollama还提供了可以调用对应部署模型的API接口。我们可以基于这些接口,做自己的二次开发。使用pythonflaskollama就可以进行模型对话调用。并且前端采用SSE的技术࿰…...

python中的抽象类在项目中的实际应用
抽象类在项目中的实际应用主要体现在 规范代码结构、强制子类实现某些方法、提供部分通用功能,让代码更稳定、易维护。 举个例子:数据校验器 假设你在做一个 用户输入校验系统,需要支持 数字校验、字符串校验 和 邮箱校验。如果不用抽象类&…...
)
New Game--(单调队列)
I - New Game 有一种新的游戏,Monocarp 想要玩。这个游戏使用一副包含 n 张牌的牌堆,其中第 i 张牌上写有一个整数 a_i。 在游戏开始时,Monocarp 可以在第一轮选择牌堆中的任意一张牌。在接下来的每一轮中,Monocarp 可以选择一张…...

mapbox V3 新特性,添加下雪效果
👨⚕️ 主页: gis分享者 👨⚕️ 感谢各位大佬 点赞👍 收藏⭐ 留言📝 加关注✅! 👨⚕️ 收录于专栏:mapbox 从入门到精通 文章目录 一、🍀前言1.1 ☘️mapboxgl.Map 地图对象…...

无人机遥感在农林信息提取中的实现方法与GIS融合制图教程
遥感技术作为一种空间大数据手段,能够从多时、多维、多地等角度,获取大量的农情数据。数据具有面状、实时、非接触、无伤检测等显著优势,是智慧农业必须采用的重要技术之一。 一:综合态势分析 1.1 研究区及作物品种分析 ÿ…...
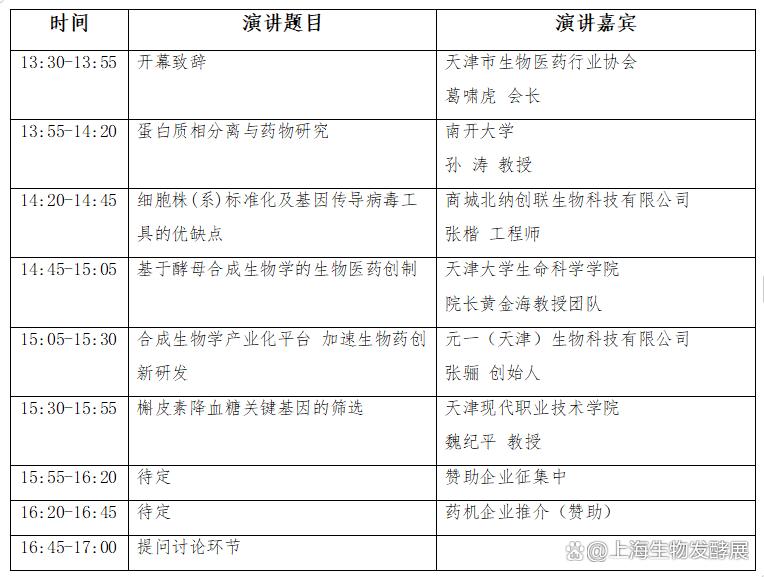
生物发酵展与2025生物医药创新技术与应用发展论坛同期盛大举办
近日,备受瞩目的生物发酵展与2025生物医药创新技术与应用发展论坛暨展览会宣布将同期盛大举办。这一消息标志着生物科技领域两大盛会的强强联合,将为全球生物科技与医药行业带来前所未有的交流与合作机遇。 生物发酵展作为生物科技领域的知名展会&#x…...

Jenkins 配置 Git Repository 五
Jenkins 配置 Git Repository 五 这里包含了 Freestyle project 任务类型 和 Pipeline 任务类型 关于 Git 仓库的配置,如下 不同的任务类型,只是在不同的模块找到 配置 Git 仓库 找到 Git 仓库配置位置之后,所有的任务类型配置都是一样的 …...

记录阿里云CDN配置
网站接入CDN全流程,共4步!-阿里云开发者社区 1、开通阿里云CDN服务 2、添加加速域名 3、验证域名归属权 4、域名添加CDN生成的CNAME解析 按照官网描述增加。细节点: 1. 域名和泛域名区别 2.开启https,要用nginx的证书,和项…...

mapbox 从入门到精通 - 目录
👨⚕️ 主页: gis分享者 👨⚕️ 感谢各位大佬 点赞👍 收藏⭐ 留言📝 加关注✅! 👨⚕️ 收录于专栏:mapbox 从入门到精通 文章目录 一、🍀总目录1.1 ☘️ mapbox基础1.2 ☘️…...

mysql中general_log日志详解
介绍 1.记录范围:这个log里面会记录MySQL所有的SQL语句,不管是查询语句,还是DML语句,还是DDL语句,还是DCL语句,这些语句统统都会被记录在general log文件中。就连我们连接和断开MySQL数据库的这些语句。 2…...

算法与数据结构:从基础到深入
1. 数组 (Array) 定义 一组连续内存空间存储的相同类型元素的集合。特点:通过下标(索引)快速访问元素,但大小固定(静态数组)或可扩展(动态数组)。 核心操作 操作时间复杂度说明访…...

视频时间管理大师:用这款工具让你的学习效率翻倍
视频时间管理大师:用这款工具让你的学习效率翻倍 【免费下载链接】videospeed HTML5 video speed controller (for Google Chrome) 项目地址: https://gitcode.com/gh_mirrors/vi/videospeed 你是否曾有过这样的经历?在线学习时,老师的…...

HyperLynx GHz高速串行通道设计实战与优化技巧
1. HyperLynx GHz高速串行通道设计实战解析在当今高速数字系统设计中,6Gbps以上的串行链路已成为主流接口标准。记得我第一次设计PCIe Gen3通道时,面对振铃、串扰和抖动问题束手无策,直到接触了HyperLynx GHz这套工具。本文将结合两个典型工程…...

Taotoken模型广场如何帮助开发者根据任务需求快速选择合适的模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken模型广场如何帮助开发者根据任务需求快速选择合适的模型 面对市场上众多的大模型,开发者常常陷入选择困境&…...

CANN OpenVLA昇腾推理指南
OpenVLA on 310P具身智能VLA大模型昇腾使用指南 【免费下载链接】cann-recipes-embodied-intelligence 本项目针对具身智能业务中的典型模型、加速算法,提供基于CANN平台的优化样例 项目地址: https://gitcode.com/cann/cann-recipes-embodied-intelligence …...

CANN/ATVOSS块调度运行接口
BaseBlockSchedule::Run 【免费下载链接】atvoss ATVOSS(Ascend C Templates for Vector Operator Subroutines)是一套基于Ascend C开发的Vector算子库,致力于为昇腾硬件上的Vector类融合算子提供极简、高效、高性能、高拓展的编程方式。 项…...

Deep Agent全解析:为什么普通Agent只能“浅尝辄止”,而Deep Agent能真正干复杂活?
一、先说结论:Deep Agent到底是什么?Deep Agent,直译叫“深度智能体”,你可以把它理解成:不是只会调用一个工具、回答一个问题的普通Agent,而是能围绕一个复杂目标,自己拆任务、查资料、调用工具…...

DeepSeek-Reasonix:只绑 DeepSeek,缓存命中率 99.82% 砍 80% 成本的 AI 编程助手
【导语:AI 编程助手赛道迎来新成员 DeepSeek-Reasonix,它只绑定 DeepSeek,将前缀缓存稳定性发挥到极致,成本效率表现出色,还具备多种工作模式。】偏执路线:只绑 DeepSeek 压榨缓存稳定性开发者在 GitHub 上…...

AI伦理框架实战:IEEE与WEF双轨制如何指导负责任的AI系统开发
1. 项目概述:为什么我们需要在AI项目中嵌入伦理框架?最近几年,AI项目从实验室走向了千家万户和各行各业。作为一名从业者,我亲眼见证了从“能用就行”到“必须好用且安全”的观念转变。早期我们更关注模型的准确率、响应速度&…...

CANN/metadef AppendStride函数
AppendStride 【免费下载链接】metadef Ascend Metadata Definition 项目地址: https://gitcode.com/cann/metadef 函数功能 向后扩展一个步长值,如果扩展的步长数量超出Stride的最大限制,那么本函数不做任何事情。 函数原型 Stride& Appe…...

机器学习数据准备度评估:可视化、超参数优化与SHAP分析实践指南
1. 项目概述:为什么数据准备度是ML项目的“隐形地基”在机器学习项目里,我们常常把80%的精力花在模型调优和算法选择上,但根据我过去几年参与和主导的多个工业级项目经验,真正决定项目成败的,往往是那看似不起眼的前期…...