HBase高级技巧:解锁更强大的数据处理能力
HBase高级技巧:解锁更强大的数据处理能力
嘿,小伙伴们!在掌握了HBase的基本操作之后,今天我们将深入探讨一些HBase的高级技巧。这些技巧将帮助你在面对复杂的数据处理需求时更加得心应手,进一步提升系统的性能和可靠性。
1. 高效的行键设计策略
1.1 基于时间戳的行键设计
如果你的应用场景涉及大量基于时间的数据(如日志分析),可以考虑将时间戳作为行键的一部分。例如:
# 行键格式为:yyyy-MM-dd-HH:mm:ss:user_id
put 'logs', '2025-02-12-14:30:00:user1', 'info:action', 'login'这种设计不仅有助于按时间范围查询数据,还能有效避免热点问题。
1.2 散列化行键
为了防止写入集中在某个特定区域,导致热点问题,可以通过散列化行键来分散写入压力。常见的方法是使用哈希函数对行键进行散列:
# 使用MD5散列行键
put 'users', 'md5(user_id)', 'info:name', 'John'1.3 复合行键
复合行键可以将多个字段组合成一个行键,从而实现更灵活的查询方式。例如,结合用户ID和事件类型:
# 行键格式为:user_id:event_type
put 'events', 'user1:login', 'info:timestamp', '2025-02-12T14:30:00'2. 列族与列限定符的优化
2.1 合理设置块大小
每个列族都有一个块大小(Block Size)属性,默认值通常为64KB。较大的块大小可以减少I/O次数,但会增加内存占用;较小的块大小则相反。根据具体应用场景调整块大小,以达到最佳性能。
<!-- hbase-site.xml -->
<property><name>hbase.hregion.blocksize</name><value>131072</value> <!-- 128KB -->
</property>2.2 列族压缩
启用列族压缩可以显著减少存储空间,并提高读取性能。HBase支持多种压缩算法,如GZip、Snappy等。
create 'users', {NAME => 'info', COMPRESSION => 'SNAPPY'}3. 数据模型优化
3.1 宽表 vs 高表
HBase支持宽表模型(Wide Table)和高表模型(Tall Table)。宽表适合存储稀疏数据,而高表适合存储密集数据。选择合适的模型取决于你的具体需求。
宽表示例:
put 'users', 'user1', 'personal_info:name', 'John'
put 'users', 'user1', 'personal_info:age', '25'
put 'users', 'user1', 'activity_logs:clicks', '100'
put 'users', 'user1', 'activity_logs:visits', '10'高表示例:
put 'users', 'user1_clicks', 'metrics:count', '100'
put 'users', 'user1_visits', 'metrics:count', '10'3.2 版本管理策略
合理设置版本数可以有效控制存储开销。默认情况下,HBase只保留最新版本的数据,但你可以根据需要调整最大版本数。
create 'users', {NAME => 'info', VERSIONS => 3}4. 高级查询与过滤器
4.1 组合过滤器
HBase提供了多种过滤器,你可以通过组合它们来实现复杂的查询逻辑。例如,使用SingleColumnValueFilter和PrefixFilter组合查询:
scan 'users', {FILTER => "SingleColumnValueFilter('info', 'age', =, 'binary:25') AND PrefixFilter('user')"}4.2 批量扫描
批量扫描可以显著提高查询效率,特别是在处理大规模数据时。使用Scan对象的setBatch方法可以限制每次返回的结果数量。
// Java代码示例
Scan scan = new Scan();
scan.setBatch(100);
ResultScanner scanner = table.getScanner(scan);
for (Result result : scanner) {// 处理结果
}5. 性能调优
5.1 MemStore 调优
MemStore 是 HBase 中用于缓存写入数据的内存区域。适当调整 MemStore 的大小可以提高写入性能。
<!-- hbase-site.xml -->
<property><name>hbase.hregion.memstore.flush.size</name><value>134217728</value> <!-- 128MB -->
</property>5.2 Compaction 策略
Compaction 是 HBase 中用于合并小文件的过程。合理的 Compaction 策略可以减少磁盘 I/O,提高读取性能。
<!-- hbase-site.xml -->
<property><name>hbase.hstore.compaction.min</name><value>3</value>
</property>
<property><name>hbase.hstore.compaction.max</name><value>10</value>
</property>6. 高可用性和容错性
6.1 HDFS 配置优化
HBase 依赖于 HDFS 进行数据存储,因此 HDFS 的配置对 HBase 的性能有很大影响。确保 HDFS 配置正确,特别是副本数和块大小。
<!-- hdfs-site.xml -->
<property><name>dfs.replication</name><value>3</value>
</property>6.2 ZooKeeper 配置
ZooKeeper 是 HBase 分布式协调服务的核心组件。确保 ZooKeeper 配置正确,以保证集群的高可用性。
<!-- hbase-site.xml -->
<property><name>hbase.zookeeper.property.clientPort</name><value>2181</value>
</property>
<property><name>hbase.zookeeper.quorum</name><value>zk1,zk2,zk3</value>
</property>7. 实际应用案例
7.1 日志分析系统
假设你有一个网站,每天都会生成大量的访问日志。你可以将这些日志存储到 HBase 中,并通过行键设计来优化查询性能。例如,行键可以设计为 日期+用户ID,这样可以快速查询某一天某个用户的访问记录。
7.2 物联网数据存储
物联网设备通常会产生大量的传感器数据。这些数据通常是无序的,适合存储在 HBase 中。你可以根据设备 ID 作为行键,将不同传感器的数据存储在不同的列族中。
总结与思考
通过这篇文章,我们学习了一些 HBase 的高级技巧,包括高效的行键设计、列族与列限定符的优化、数据模型优化、高级查询与过滤器、性能调优以及高可用性和容错性。希望这些技巧能帮助你在实际项目中更好地应用 HBase。
关键点回顾
- • 行键设计:基于时间戳、散列化和复合行键设计,避免热点问题。
- • 列族与列限定符优化:合理设置块大小和压缩策略,提高存储和读取性能。
- • 数据模型优化:选择合适的宽表或高表模型,合理设置版本管理策略。
- • 高级查询与过滤器:使用组合过滤器和批量扫描,实现复杂查询需求。
- • 性能调优:调整 MemStore 和 Compaction 策略,优化写入和读取性能。
- • 高可用性和容错性:优化 HDFS 和 ZooKeeper 配置,确保集群的高可用性。
互动环节
看完这篇文章后,你是否对 HBase 的高级技巧有了更深的理解?你觉得在你的工作或生活中,哪些地方可以用到这些技巧呢?欢迎在评论区分享你的见解,大家一起交流学习吧!
记住,技术的学习永无止境,让我们一起在这条路上不断探索前进吧!🚀
注:本文旨在通过通俗易懂的方式解释复杂的概念,希望能为读者带来启发和思考。
相关文章:

HBase高级技巧:解锁更强大的数据处理能力
HBase高级技巧:解锁更强大的数据处理能力 嘿,小伙伴们!在掌握了HBase的基本操作之后,今天我们将深入探讨一些HBase的高级技巧。这些技巧将帮助你在面对复杂的数据处理需求时更加得心应手,进一步提升系统的性能和可靠性…...

【进阶】JVM篇
为什么学习jvm 1、面试的需要 学过java的程序员对jvm应该不陌生,程序员为什么要学习jvm呢?其实不懂jvm也可以照样写出优质的代码,但是不懂jvm会被大厂的面试官虐的体无完肤。 2、高级程序员需要了解 jvm作用 jvm负责把编译后的字节码转换…...

DeepSeek官方推荐的AI集成系统
DeepSeek模型虽然强大先进,但是模型相当于大脑,再聪明的大脑如果没有输入输出以及执行工具也白搭,所以需要有配套工具才能让模型发挥最大的作用。下面是一个典型AI Agent架构图,包含核心组件与数据流转关系: #mermaid-…...

【动态规划篇】:当回文串遇上动态规划--如何用二维DP“折叠”字符串?
✨感谢您阅读本篇文章,文章内容是个人学习笔记的整理,如果哪里有误的话还请您指正噢✨ ✨ 个人主页:余辉zmh–CSDN博客 ✨ 文章所属专栏:动态规划篇–CSDN博客 文章目录 一.回文串类DP核心思想(判断所有子串是否是回文…...

JENKINS(全面)
一.linux系统中JENKINS的安装 注意:安装jenkins需要安装jdk,而且具体版本的jenkins有相对应的jdk版本。可参考以下链接。 Redhat Jenkins 软件包https://pkg.jenkins.io/redhat-stable/https://pkg.jenkins.io/redhat-stable/https://pkg.jenkins.io/r…...

Promise详解大全:介绍、九个方法使用和区别、返回值详解
Promise的介绍 Promise是异步编程的一种解决方案,它的构造函数是同步执行的,then 方法是异步执行的,所以Promise创建后里面的函数会立即执行,构造函数中的resolve和reject只有第一次执行有效,,也就是说Pro…...

尚硅谷爬虫note004
一、urllib库 1. python自带,无需安装 # _*_ coding : utf-8 _*_ # Time : 2025/2/11 09:39 # Author : 20250206-里奥 # File : demo14_urllib # Project : PythonProject10-14#导入urllib.request import urllib.request#使用urllib获取百度首页源码 #1.定义一…...

Debezium系列之:时区转换器,时间戳字段转换到指定时区
Debezium系列之:时区转换器,时间戳字段转换到指定时区 示例:基本配置应用TimezoneConverter SMT的效果示例:高级配置配置选项当Debezium发出事件记录时,记录中的时间戳字段的时区值可能会有所不同,这取决于数据源的类型和配置。为了在数据处理管道和应用程序中保持数据一…...

ubuntu20.04声音设置
step1:打开pavucontrol,设置Configuration和Output Devices, 注意需要有HDMI / DisplayPort (plugged in)这个图标。如果没有,就先选择Configuration -> Digital Stereo (HDMI 7) Output (unplugged) (unvailable),…...

如何设置Python爬虫的User-Agent?
在Python爬虫中设置User-Agent是模拟浏览器行为、避免被目标网站识别为爬虫的重要手段。User-Agent是一个HTTP请求头,用于标识客户端软件(通常是浏览器)的类型和版本信息。通过设置合适的User-Agent,可以提高爬虫的稳定性和成功率…...

深度学习框架探秘|TensorFlow:AI 世界的万能钥匙
在人工智能(AI)蓬勃发展的时代,各种强大的工具和框架如雨后春笋般涌现,而 TensorFlow 无疑是其中最耀眼的明星之一。它不仅被广泛应用于学术界的前沿研究,更是工业界实现 AI 落地的关键技术。今天,就让我们…...

C++:高度平衡二叉搜索树(AVLTree) [数据结构]
目录 一、AVL树 二、AVL树的理解 1.AVL树节点的定义 2.AVL树的插入 2.1更新平衡因子 3.AVL树的旋转 三、AVL的检查 四、完整代码实现 一、AVL树 AVL树是什么?我们对 map / multimap / set / multiset 进行了简单的介绍,可以发现,这几…...

建筑兔零基础自学python记录18|实战人脸识别项目——视频检测07
本次要学视频检测,我们先回顾一下图片的人脸检测建筑兔零基础自学python记录16|实战人脸识别项目——人脸检测05-CSDN博客 我们先把上文中代码复制出来,保留红框的部分。 然后我们来看一下源代码: import cv2 as cvdef face_detect_demo(…...

【MySQL数据库】Ubuntu下的mysql
目录 1,安装mysql数据库 2,mysql默认安装路径 3,my.cnf配置文件? 4,mysql运用的相关指令及说明 5,数据库、表的备份和恢复 mysql是一套给我们提供数据存取的,更加有利于管理数据的服务的网络程序。下…...
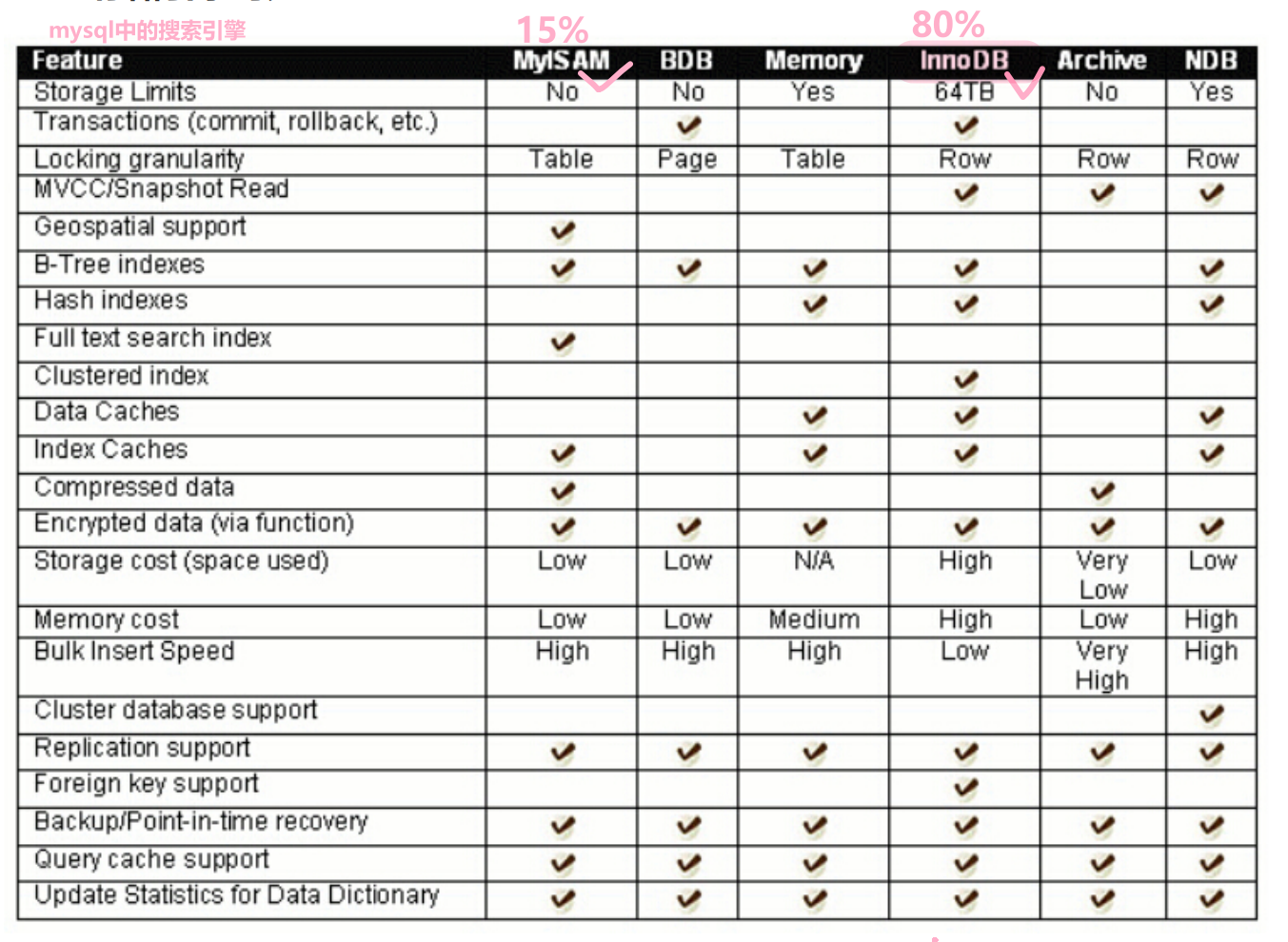
[MySQL#1] database概述 常见的操作指令 MySQL架构 存储引擎
#1024程序员节|征文# 目录 一. 数据库概念 0.连接服务器 1. 什么是数据库 口语中的数据库 为什么数据不直接以文件形式存储,而需要使用数据库呢? 总结 二. ??基础操作 三. 主流数据库 四. 基础知识 服务器,数据库&…...

1.从零开始学会Vue--{{基础指令}}
全新专栏带你快速掌握Vue2Vue3 1.插值表达式{{}} 插值表达式是一种Vue的模板语法 我们可以用插值表达式渲染出Vue提供的数据 1.作用:利用表达式进行插值,渲染到页面中 表达式:是可以被求值的代码,JS引擎会将其计算出一个结果 …...

VS2022中.Net Api + Vue 从创建到发布到IIS
VS2022中.Net Api Vue 从创建到发布到IIS 前言一、先决条件二、创建项目三、运行项目四、增加API五、发布到IIS六、设置Vue的发布 前言 最近从VS2019 升级到了VS2022,终于可以使用官方的.Net Vue 组合了,但是使用过程中还是有很多问题,这里记录一下. 一、先决条件 Visual …...

RFID技术在制造环节的应用与价值
在现代制造业中,信息化和智能化已经成为企业提升竞争力的重要手段。RFID技术因其非接触式、远距离和高效识别的特点,广泛应用于生产的多个环节。本文将详细解读生产过程中RFID的关键应用场景,并结合实际案例,展示其为制造业带来的…...

(前端基础)HTML(一)
前提 W3C:World Wide Web Consortium(万维网联盟) Web技术领域最权威和具有影响力的国际中立性技术标准机构 其中标准包括:机构化标准语言(HTML、XML) 表现标准语言(CSS) 行为标准…...

Linux文件管理:硬链接与软链接
文章目录 1. 硬链接的设计目的(1)节省存储空间(2)提高文件管理效率(3)数据持久性(4)文件系统的自然特性 2. 软链接的设计目的**(1)跨文件系统引用****&#x…...

基于 4sapi 搭建 AI 多模态内容生产矩阵:自媒体与企业内容营销的全流程自动化落地方案
引言 2026 年,内容营销已经成为企业品牌增长、自媒体商业变现的核心抓手,从图文笔记、短视频脚本、行业白皮书,到多平台内容分发、SEO 优化、热点追更,内容生产的需求呈现爆发式增长。但绝大多数自媒体团队与企业市场部ÿ…...

内存级向量检索库memsearch:原理、实战与性能调优
1. 项目概述:向量检索的“内存级”加速方案最近在折腾RAG(检索增强生成)应用时,向量数据库的检索延迟成了性能瓶颈。尤其是在处理高并发、低延迟的在线服务场景,即使是最优的索引,一次检索也常常需要几十到…...
)
OpenClaw 全套落地包(可直接复制即用)
一、Docker 一键部署配置 新建文件夹 openclaw,里面新建文件 docker-compose.yml,复制下面全部内容: yaml version: 3.8 services:openclaw:image: openclaw/openclaw:latestcontainer_name: openclawports:- "8000:8000"volume…...

如何使用Newton创建交互式仿真?用户输入与实时控制完整指南
如何使用Newton创建交互式仿真?用户输入与实时控制完整指南 【免费下载链接】newton An open-source, GPU-accelerated physics simulation engine built upon NVIDIA Warp, specifically targeting roboticists and simulation researchers. 项目地址: https://g…...

AI编程项目品牌系统生成:一分钟打造语义化设计令牌与CLAUDE.md指南
1. 项目概述:一分钟搞定AI编程项目的品牌系统 如果你和我一样,日常重度依赖 Cursor、Claude 或 Windsurf 这类 AI 编程工具来快速构建项目,那你一定也遇到过这个痛点:项目功能做出来了,但界面看起来千篇一律ÿ…...

高瞬态高功率激光级储能锂电池系统设计要求【浩博电池】
高能激光类设备(工业/科研级)对电源系统的核心要求是: 极短时间内释放极高功率 极低内阻 极高稳定母线电压 极强安全冗余控制能力。一、系统总体设计目标该类高功率脉冲能源系统需满足:毫秒级瞬态放电能力(脉冲负载…...

AI智能体执行引擎OpenClaw-Worker:从原理到实战部署
1. 项目概述与核心价值最近在折腾AI智能体(Agent)相关的项目,发现一个挺有意思的开源项目叫qodex-ai/openclaw-worker。这名字听起来就有点“机械爪”的感觉,实际上它也确实是一个为AI智能体提供“抓取”和“执行”能力的核心工作…...

如何3步安装Koikatu HF Patch:终极游戏增强与200+插件整合指南
如何3步安装Koikatu HF Patch:终极游戏增强与200插件整合指南 【免费下载链接】KK-HF_Patch Automatically translate, uncensor and update Koikatu! and Koikatsu Party! 项目地址: https://gitcode.com/gh_mirrors/kk/KK-HF_Patch 想要彻底提升Koikatu和K…...

Go语言集成OpenAI API:otiai10/openaigo轻量级客户端实战指南
1. 项目概述:一个轻量级的Go语言OpenAI客户端 如果你正在用Go语言开发应用,并且需要集成OpenAI的API,比如调用GPT-3.5/4.0、DALLE或者Whisper,那么你大概率会面临一个选择:是直接去啃OpenAI官方的Go SDK,还…...

拖拉机PST换挡规律与控制策略GABP神经网络【附代码】
✨ 本团队擅长数据搜集与处理、建模仿真、程序设计、仿真代码、EI、SCI写作与指导,毕业论文、期刊论文经验交流。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,查看文章底部二维码(1)基于GABP的换挡点在线预测与动态更新:设…...