【论文精读】VLM-AD:通过视觉-语言模型监督实现端到端自动驾驶

论文地址: VLM-AD: End-to-End Autonomous Driving through Vision-Language Model Supervision
摘要
人类驾驶员依赖常识推理来应对复杂多变的真实世界驾驶场景。现有的端到端(E2E)自动驾驶(AD)模型通常被优化以模仿数据中观察到的驾驶模式,但未能捕捉到背后的推理过程。这种限制使得它们在处理具有挑战性的驾驶场景时能力受限。为了弥合这一差距,我们提出了VLM-AD,一种利用视觉语言模型(VLMs)作为教师来增强训练的方法,通过提供额外的监督信号,将非结构化的推理信息和结构化的动作标签融入训练中。这种监督能够增强模型学习更丰富的特征表示的能力,从而捕捉驾驶模式背后的逻辑。重要的是,我们的方法在推理时不需要VLM,使其适合实时部署。当与现有最先进的方法结合时,VLM-AD在nuScenes数据集上显著提高了规划精度,并降低了碰撞率。

1. 引言
端到端自动驾驶(AD)将感知、预测和规划统一到一个框架中,旨在协调包括检测、跟踪、建图、预测和规划在内的多个复杂任务。近期的研究方法通过使用传感器数据生成规划的自我轨迹,采用单一的整体模型来解决这些挑战。尽管这些方法已经显示出一些有希望的结果,但它们在处理具有挑战性的长尾事件时性能会下降。另一方面,人类驾驶员通常能够通过推理驾驶环境并相应地调整行为来有效处理这些场景。这突显了当前端到端模型在训练中的一个缺口,它们仅依赖于轨迹监督作为一系列点,缺乏用于学习丰富且鲁棒特征表示的推理信息,以实现更好的驾驶性能。手动标注推理信息通常成本高昂、耗时且容易出现不一致和主观的结果,这使得获取高质量和可扩展的标注变得困难。大型基础模型通过提供复杂任务(如驾驶)的推理能力提供了一种替代方案。近期的一些方法直接将大型基础模型(如大型语言模型[LLMs]和视觉语言模型[VLMs])集成到AD系统中,以利用它们的推理能力。然而,这些方法需要大量的特定领域微调,以将基于语言的输出转化为精确的数值结果,如规划轨迹或控制信号。此外,这些方法在推理时依赖于大型基础模型,这显著增加了训练成本和推理时间,使得这些方法不适合实际应用。
鉴于手动标注的局限性和直接将大型基础模型集成到驾驶系统中的挑战,我们提出了以下问题:大型基础模型(如VLMs)是否可以生成基于推理的文本信息,以增强自动驾驶模型,而无需在推理时进行集成?受此问题的启发,我们提出了VLM-AD(如图1所示),一种利用VLMs作为教师自动生成基于推理的文本标注的新方法。这些标注随后作为补充监督信号用于训练端到端流程,超越了标准轨迹标签的范围。具体来说,给定一个多视角图像序列和自车的未来轨迹,我们将未来轨迹投影到初始前视图像上,以纳入关键的时间运动信息。然后,我们通过针对车辆当前状态、预期未来行为和推理过程的针对性问题提示VLM模型,生成自由形式和结构化的响应,从而将关键的VLM知识注入训练流程。这种可扩展的方法使我们能够构建一个富含VLM生成标注的数据集,有效解决了现有驾驶数据集中缺乏推理线索的问题。我们基于这些标注设计了辅助任务,并无缝地将其整合到现有的端到端模型中进行联合训练。这些任务鼓励模型学习更丰富的特征表示,以提升驾驶性能,而无需在推理时使用VLM。我们的贡献可以总结如下:
-
我们提出了VLM-AD,这是一种简单而有效的方法,通过精心设计的提示将VLM的驾驶推理知识提炼到端到端AD流程中,生成基于推理的行为文本标注的高质量数据集。
-
我们设计了两个即插即用的辅助任务,通过非结构化的自由形式文本和结构化的动作标签监督现有的端到端AD流程。这些任务无需对VLM进行微调或在推理时使用,即可有效地提炼VLM知识,指导模型学习更丰富的特征表示以提升规划性能。
-
在nuScenes数据集上的广泛实验验证了我们提出方法的有效性,显示出在L2规划误差上分别提升了14.6%和33.3%,并将UniAD和VAD的碰撞率分别降低了38.7%和57.4%。
2. 相关工作
End-to-End Autonomous Driving. 端到端自动驾驶系统将所有模块联合训练以实现统一目标,从而减少整个流程中的信息丢失。例如,ST-P3 [17] 和 UniAD [18] 提出了基于视觉的端到端自动驾驶系统,将感知、预测和规划统一起来。这些模型在开放环路的nuScenes数据集 [3] 上取得了最先进的结果。后续的研究,如VAD [26] 和VADv2 [6],引入了矢量化编码方法以实现高效的场景表示,并扩展到CARLA [14] 上的闭环仿真。近期的方法,如Ego-MLP [62]、BEV-Planner [35] 和PARA-Drive [58],进一步探索了自我状态和模块化堆栈中的新设计空间,以提升驾驶性能。尽管端到端驾驶方法在开发中显示出潜力,但它们主要被优化以模仿数据中的驾驶模式,而未能捕捉到背后的推理过程。这种局限性主要是由于现有数据集中缺乏推理信息。因此,这些方法无法获取更深层次的推理知识,这可能会限制它们在复杂场景中的性能。
Foundation Models for Autonomous Driving. 基础模型,包括大型语言模型(LLMs)和视觉语言模型(VLMs),正越来越多地被应用于自动驾驶领域,以利用它们的高级推理能力。GPT-Driver [39] 和Driving-with-LLMs [4] 使用LLMs提供带有解释的动作建议,从而增强决策的透明性。近期的一种方法 [11] 利用LLMs评估车道占用和安全性,实现更具人类直觉的场景理解。然而,基于LLM的方法主要依赖于语言输入,这限制了它们整合驾驶中丰富的视觉特征的潜力。
VLMs通过整合语言和视觉实现多模态推理,支持诸如场景理解 [10, 21, 42, 49] 和数据生成 [24, 56, 64] 等任务。VLMs还被用于统一导航和规划 [15, 29, 51, 53] 以及端到端自动驾驶 [27, 40, 55, 61]。然而,现有的基于VLM的方法通常需要大量的特定领域微调,这显著增加了计算成本和推理延迟。与我们的方法密切相关的是,VLP [40] 将轨迹和边界框标签转换为用于对比学习的文本特征,但它没有引入超出现有监督标签的信息。相比之下,我们的方法利用VLM提供额外的推理信息,以进一步提升驾驶性能。
Multi-Task Learning. 多任务学习(MTL)通过共享表示联合执行多个相关任务,通过单独的分支或头部实现。这种方法利用共享的领域知识,增强特征的鲁棒性和泛化能力,使其非常适合端到端自动驾驶。在AD系统中,辅助任务如语义分割 [9, 19, 23, 33, 60]、深度估计 [33, 60]、高精地图和鸟瞰图分割 [8, 25, 47, 48, 63] 常被采用,以提取有意义的感知表示用于后续目标。除了视觉任务外,其他方法 [22, 59] 还预测额外的交通灯状态或控制信号,以提升驾驶性能。受多任务学习成功的启发,我们设计了新的辅助任务,通过从VLM获取高质量的推理标注,鼓励模型学习更丰富的特征表示,从而实现更可靠的规划性能。

3. 方法
图2展示了我们提出的VLM-AD框架的概述,它由两个主要部分组成。第一部分是注释分支,我们利用VLM生成额外的信息,创建一个补充数据集作为监督信号。第二部分是我们设计的辅助头,旨在与这种额外的监督信号对齐,并且可以有效地集成到任何端到端模型中,跟随规划模块之后。

3.1 VLM文本注释
图3展示了注释过程,我们利用VLM作为教师,通过视觉输入丰富数据集中的额外信息,利用其从视觉输入中推理驾驶行为的能力,加深端到端模型对驾驶行为的理解。注释过程可以定义为:
![]()
其中,M(·) 表示VLM模型,P 表示语言提示,V 是视觉输入,而A 是模型的自然语言输出,作为数据集的注释。我们的目标是提供来自自车摄像头的图像,以及精心设计的提示,以从VLM获得详细且信息丰富的响应,利用其广泛的世界知识。
在我们的工作中,我们使用了GPT-4o [2],这是一个在互联网规模数据上训练的高性能VLM,用于自动标注我们的数据集。GPT-4o能够解释场景,生成合适的基于推理的响应,并在复杂场景中准确识别自车的动作。
Visual Input. 在确定视觉输入时,我们面临两个挑战。第一个挑战是从多个摄像头中选择合适的图像,这些摄像头提供了围绕自车的360度覆盖。我们探索了两种方法:从所有视图创建一个复合大图像,或者仅使用前视图像,后者通常包含大多数驾驶任务所需的相关信息。我们的注释结果显示,这两种方法的输出质量相当,因此我们选择仅使用前视图像以降低整体复杂性。
第二个挑战是整合时间信息,这对于有效的规划和决策至关重要。我们考虑了两种方法。一种直接的方法是输入多个连续帧作为序列,并在提示中指示未来的时间戳。然而,我们观察到VLM在时间连续性方面存在困难,经常混淆自车的身份,这可能是由于其在时间定位方面的限制 [28, 43]。因此,我们选择将自车的未来轨迹投影到单个前视图像上,利用相机的内参和外参以及传感器规格。我们在提示中指定,投影的轨迹反映了车辆的未来路径。这种成本效益高的设计允许VLM比使用图像序列更可靠地解释时间信息。
Freeform Reasoning Annotation. 作为VLM的关键输入,精心设计的问题对于增强推理能力和提高VLM响应的可解释性至关重要 [57]。在我们的方法中,我们专注于规划任务,通过设计提示来获得VLM的推理。我们创建了两种类型的问题,首先是开放式问题,旨在生成自由形式的、非结构化的响应,这些响应包含丰富且高维的语言信息。我们将这些响应称为非结构化推理注释。为了最大化VLM的推理能力,我们在提出具体问题之前提供详细的上下文描述作为初步指令。具体来说,上下文和问题定义如下:
-
:这是自车的前视图像。红线表示未来轨迹,没有线表示停止或减速。在解释推理时,请专注于相机图像及其周围上下文,而不是引用绘制的轨迹。
-
:请描述自车的当前行为。
-
:请预测自车的未来行为。
-
:请解释当前和未来行为的推理。
完整的输入提示定义为 = [
,
],其中
表示问题集,
= {
,
,
}。这些开放式问题生成自由形式的文本注释,描述自车的当前状态、预期的未来行为以及VLM知识背后的推理。
Structured Action Annotation. 为了测试我们方法的灵活性,我们定义了第二种类型的问题,采用结构化格式。具体来说,我们创建了三个不同的动作集,并提示VLM从这些预定义选项中选择答案。这使我们能够为每个问题获得一个特定的动作注释。具体来说,上下文和问题定义如下:
-
:这是自车的前视图像。红线表示未来轨迹,没有线表示停止或减速。
-
:请从控制动作列表中描述自车的动作:{直行、慢行、停止、倒车}。
-
:请从转弯动作列表中描述自车的动作:{左转、右转、掉头、无}。
-
:请从车道动作列表中描述自车的动作:{向左变道、向右变道、并入左车道、并入右车道、无}。
完整的输入提示定义为= [
],其中
3.2 Auxiliary Heads
通常,数据驱动的端到端自动驾驶方法 [18, 26] 关注于总结一个可学习的自我特征,以产生规划结果,这对于生成可靠且准确的规划轨迹至关重要。这个可学习的自我特征聚合了来自上游模块的所有相关信息,通过不同的网络传递。在我们的方法中,我们开发了辅助头,以该自我特征作为输入,使模型能够提炼VLM响应中的知识。
Annotation Encoding. 使用 问题,我们获得三个文本响应,记为
![]() ,分别代表当前动作的描述、未来动作预测和推理。使用
,分别代表当前动作的描述、未来动作预测和推理。使用 问题,我们从预定义集合中获得三个动作,记为
![]() ,分别对应控制动作、转弯动作和车道动作。为了将这些注释转换为监督信号,我们采用两种不同的方法生成两种对应的标签,有效地将它们集成到端到端自动驾驶流程中作为监督信号。对于来自
,分别对应控制动作、转弯动作和车道动作。为了将这些注释转换为监督信号,我们采用两种不同的方法生成两种对应的标签,有效地将它们集成到端到端自动驾驶流程中作为监督信号。对于来自 的自由形式文本注释,我们使用现成的语言模型(如CLIP [45])将文本转换为特征表示。对于结构化答案,每个动作被编码为一个独热标签。形式化表示为:
![]()
其中 和
各有三个组成部分:
= {
,
,
} 和
= {
,
,
}。这里,
、
、和
是大小为C的特征向量,其中C是文本嵌入的维度,而
、
和
是三个独热动作标签,大小分别为
= 4、
= 4 和
= 5。
Text Feature Alignment. 使用三个文本特征 = {
,
,
} 作为监督信号,我们开发了一个特征对齐头,它以自我特征
作为输入。这种设置类似于知识蒸馏 [16],其中特征对齐头学习与教师VLM提供的文本特征对齐。在这个头中,我们初始化三个可学习的文本查询,
= {
,
}。每个查询通过多头交叉注意力(MHCA)块与自我特征
交互,其中文本查询作为注意力查询q,自我特征作为键k 和值v,产生更新后的文本查询。然后,这些更新后的查询与自我特征连接,形成该文本头的特征表示,随后通过一个多层感知机(MLP)层生成最终的特征对齐输出。这一过程可以表示为:

其中⊕表示连接操作,而 = {
,
,
} 表示三个输出特征,用于与相应的VLM文本特征对齐。需要注意的是,我们为每个组成部分分别使用了三个独立的MHCA块,使每个文本查询能够专注于自我特征中可以用文本形式表示的特定方面。
受到DINO [1]中知识蒸馏方法的启发,该方法通过控制特征向量的平滑度和锐度来增强特征对齐质量,我们采用了类似的策略,分别对文本特征和输出特征进行归一化处理,生成特征分布而非原始特征值。具体公式如下:

其中和
是控制这些分布锐度的温度参数。这种调整能够更好地对齐输出特征和监督标签,提升知识蒸馏的对齐质量。需要注意的是,我们没有应用中心化操作,因为我们认为监督信号是真实值。
Structured Action Classification. 我们通过问题 从 VLM 中获得结构化的动作标签
= {
,
,
}。我们构建了一个动作分类头,它以自我特征
作为输入。与前面的特征对齐阶段类似,我们初始化了三个可学习的动作查询
、
和
,并通过三个多头交叉注意力(MHCA)块与
进行交互。在此设置中,每个动作查询作为注意力查询 q,而自我特征作为键 k 和值 v,从而产生更新后的动作查询。然后,我们将这些更新后的查询与自我特征连接,形成动作分类头的特征表示,并通过一个多层感知机(MLP)层,随后使用 Softmax 函数生成动作预测。这一过程可以表示为:

其中 = {
,
,
} 分别表示预测的控制动作、转弯动作和车道动作。我们为每个动作查询使用独立的 MHCA 块,以生成不同的动作标签。
3.3 Auxiliary Loss
我们定义了两个平行的辅助任务,跟随规划模块之后,以使模型能够从视觉语言模型(VLM)中提炼知识。整体训练损失定义为这两个辅助任务损失的加权和:
![]()
其中每个组成部分对应一个特定的辅助文本头,为模型提供针对性的监督信号:

对于特征对齐任务,我们使用交叉熵loss来对齐监督特征和输出特征,确保模型能够学习到文本中传达的关键信息。对于动作分类任务,我们同样使用交叉熵损失,以确保动作分类的准确性。
4. 实验
4.1 设置
Baselines.我们提出的方法是一个通用框架,兼容多种端到端自动驾驶方法。我们通过将其应用于两个广泛认可的开源方法——UniAD [18] 和 VAD [26]——来验证其有效性。此外,我们还将我们的方法与 VLP [40] 进行比较,VLP 通过 CLIP [45] 将自车的真值标签投影到文本特征空间中,用于对比学习。
Dataset. 我们使用 nuScenes 数据集 [3] 进行开放环路规划评估。nuScenes 是一个大规模的自动驾驶数据集,包含 1000 个场景,每个场景持续约 20 秒,标注频率为 2Hz。该数据集包含详细的标注,是端到端自动驾驶研究中的热门基准。
Evaluation Protocol. 我们专注于规划任务,并使用标准指标(如 L2 位移误差和碰撞率)来评估性能。
Implementation Details. 我们使用 UniAD [18] 和 VAD [26] 的官方代码,并遵循其指定的超参数。对于我们的 VLM-AD 方法,我们为每个辅助任务头定义了一个包含 8 个头和 3 层交叉注意力的多头交叉注意力(MHCA)模块,并为每个问题 和
设置了 3 个文本查询。在训练过程中,我们将温度参数
设置为 0.1,
设置为 0.04,以控制特征的锐度,并将
设置为 1,
设置为 0.1,以平衡
和
的权重。所有模型均在 8 块 NVIDIA H100 GPU 上使用 PyTorch 框架 [41] 进行训练。完整的实现细节、标注质量分析以及更多实验结果已在补充材料中提供。

4.2 主要结果
表 1 展示了将我们的 VLM-AD 方法应用于 UniAD 和 VAD 的结果,并与 VLP 进行了比较。通过比较方法 ID 0 和 1,我们使用作者提供的官方训练检查点,得到了几乎相同的规划结果。对于方法 IDs 6 和 7,以及 IDs 12 和 13,我们发现在作者的复现结果与报告值之间存在一些差异,我们认为这是由于官方代码库中图像配置的修正 [3] 所导致的。从表的第一部分可以看出,通过引入 和
,VLM-AD 在平均 L2 规划误差和平均碰撞率方面显著优于 UniAD,并且在两项指标上均优于最先进的基线 VLP。对于 VAD,我们的 VLM-AD 一致优于 VAD-Base 和 VAD-Tiny,尤其是在 L2 规划误差指标上,并且在 VAD-Base 中的性能优于 VLP。这些结果证明了我们 VLM-AD 方法的有效性和优势。此外,
的表现优于
,验证了通过丰富的推理信息监督驾驶模型的价值。

4.3 消融研究
子问题的贡献。我们进一步分析了 中的每个子问题(
、
和
)的贡献。每个子问题提供了与自车当前状态、预测的未来动作和推理相关的特定文本信息。表 2 展示了这些子问题的消融研究结果。结果表明,每个子问题都对整体性能产生了积极影响,证明了我们设计的问题为规划任务提供了有价值的信息。值得注意的是,推理特征对降低 L2 规划误差的贡献最大,突显了推理信息在提升驾驶性能中的重要性。
特征对齐损失。我们还研究了特征对齐的其他选项,包括使用 CLIP [45] 中的对比学习损失、均方误差(MSE)损失、KL 散度损失 [30] 或最大化负余弦相似度来对齐 的三个特征。表 3 的结果表明,MSE 损失在最小化特征之间的欧几里得距离时表现略优于 UniAD,但会导致训练过程中信息丢失。CLIP 损失、KL 散度和余弦相似度均优于 UniAD,但不如我们提出的对齐损失。这突显了使用不同温度对教师-学生特征的平滑度和锐度进行归一化的重要性。
模型设计。我们研究了方法中的替代设计选项。首先,我们在结构化动作分类头中用多层感知机(MLP)层代替 MHCA 块。其次,我们研究了不同的语言模型,如 T5 [46] 和 MPNet [50],除了 CLIP 之外,还用于将 的文本标注编码为监督标签。从表 4 可以看出,使用 MLP 的方法在 L2 性能上略逊于 UniAD,碰撞率则相同。此外,T5 和 MPNet 的表现均优于 UniAD 基线,但略逊于 CLIP。

Hyperparameter Study. 在多任务学习中,平衡不同任务的损失是一个关键挑战。我们研究了在 UniAD 中 和
的超参数。表 5 的结果表明,所有三种变体均优于 UniAD。在这些变体中,当
= 0.1 且
= 1 时,性能最差,因为
的标注包含的信息比
的标注更有价值。

图4. UniAD与我们方法的定性比较。黄色箭头突出显示了VLM-AD优于UniAD的区域。红色框表示UniAD的失败规划命令,紫色框表示我们VLM-AD辅助文本头预测的三个动作输出。
4.4 可视化
我们从 nuScenes 数据集中提供了四个可视化示例,如图 4 所示,以展示我们提出方法的有效性。在第一、第三和最后一行的案例中,UniAD 生成的规划轨迹曲折且缺乏平滑性,而我们的方法生成的轨迹能够准确地沿着道路行驶。此外,在第二、第三和最后一行的案例中,基线方法错误地建议了转弯意图,而自车实际上是在直行。我们的动作文本头正确地输出了“直行”的控制动作,不仅验证了 VLM 监督的有效性,还为模型的决策提供了可解释性。
5. 结论
在本工作中,我们提出了 VLM-AD,这是一种通过利用视觉语言模型(VLMs)作为辅助教师来增强端到端自动驾驶模型的新方法。通过针对 VLM 提出包含非结构化推理文本和结构化动作标签的问题,我们将推理和动作监督信息整合到训练过程中。我们的方法在 nuScenes 数据集上显著提升了规划精度,并降低了碰撞率,同时通过动作预测为输出轨迹提供了可解释性。重要的是,VLM-AD 在推理时不需要 VLM,使其能够以即插即用的方式部署于实际应用中,而不会增加额外的推理成本。
A. 实现细节
当将我们提出的 VLM-AD 方法集成到 UniAD [18] 中时,我们遵循 UniAD 定义的联合训练协议。在第一阶段,我们使用 BEVFormer [34] 的权重初始化模型,并训练感知和建图任务共 6 个epoch。在第二阶段,我们冻结图像主干网络和鸟瞰图编码器(BEV encoder),并使用我们提出的 VLM-AD 方法进行端到端训练,共 20 个epoch。模型使用初始学习率2 × 、学习率衰减因子 0.1,并采用 AdamW 优化器 [37],权重衰减为 0.01 进行训练。
当将 VLM-AD 方法集成到 VAD [26] 中时,我们采用了与原始实现相同的超参数。模型使用 AdamW优化器 [37] 和余弦退火调度器 [38] 进行训练,权重衰减为 0.01,初始学习率为 2×。
为了将自由形式的标注编码为文本特征,我们使用预训练的 CLIP-ViT-B/32 [45] 模型,其维度为 512。此外,我们还尝试了其他文本编码器,例如 T5-base [46] 和 MPNet-base [50],它们都将自由形式的标注编码为维度为 768 的文本特征,如第 4.3 节所述。
B. VLM Annotation



B.1. Visual Input
虽然我们在方法中使用了前视图像(如图5所示)作为视觉输入,我们也尝试了其他替代方案,包括使用覆盖自车周围360度全景的6张图像(如图6所示),以及使用连续的前视图像序列(如图7所示)。与使用全景图像作为输入相比,我们的方法能够产生类似的标注结果,同时显著降低了计算成本,因为我们处理的输入图像更小。使用连续图像序列的第二种替代方案,通常会导致错误的标注,例如错误地识别当前动作状态,以及未能检测到左转动作。这是因为VLM在理解自我中心视觉信号的时间动态方面存在挑战。此外,使用连续图像会将标注时间增加约80%,相比我们的方法。



B.2. Annotation Statistics
我们对nuScenes数据集的训练集进行了标注,该数据集包含700个场景和28,130帧图像。按照第3节中描述的方法,我们将自车的未来轨迹投影到前视图像上,并将时间步长T设置为6。与UniAD [18]一致,我们排除了缺乏足够输入数据的样本,最终得到28,032个标注样本。对于使用的自由形式推理标注,我们计算了每个子问题(
、
和
)的响应文本长度。统计结果如表6所示,其中推理标注Ar的平均响应长度最长,因为该子问题专注于详细的推理信息。对于使用
的结构化动作标注,我们分析了三种类型动作的分布,结果如图8、图9和图10所示。大约62%的帧被标注为“直行”,89.4%为“无转弯动作”,97.3%为“无变道动作”。值得注意的是,没有帧被标注为“倒车”或“掉头”,只有极少数帧被标注为“并入左车道”或“并入右车道”。这些统计结果表明nuScenes数据集在驾驶动作的多样性方面存在一定局限性。一个有趣的观察是,VLM偶尔会输出不在我们预定义动作列表中的动作,例如“轻微左转”、“轻微右转”、“稍微向左移动”和“稍微向右移动”。在我们的工作中,我们将这些输出合并到预定义的独热类别中:“轻微左转”合并到“左转”,“轻微右转”合并到“右转”,“稍微向左移动”合并到“向左变道”,“稍微向右移动”合并到“向右变道”。这突显了使用结构化标注的优势,因为它们可以通过将VLM的输出限制在预定义的类别中来减少幻觉(hallucinations)。

B.3. Annotation Quality
为了验证VLM生成的标注质量,我们制作了一个包含50个随机样本的问卷进行评估。对于每个样本,参与者被提供了自车的前视图像(带有未来轨迹的投影),以及相应的VLM标注(和
)。然后,我们要求参与者对每个响应进行打分。对于自由形式的推理标注,我们设定了一个1到5分的评分标准,如下所示:
-
5分:高度一致
-
文本描述与图像完美匹配。
-
图像的关键元素(例如车辆状态、动作、推理)被准确描述。
-
文本清晰、简洁且完整,没有不必要的细节或矛盾之处。
-
-
4分:大多一致
-
文本描述与图像大部分一致,但存在少量不准确或遗漏之处。
-
关键元素被描述,但可能缺少一些次要细节。
-
或者,文本可能包含少量冗余或略微不相关的细节,但不影响整体匹配。
-
-
3分:部分一致
-
文本描述与图像部分匹配,但存在明显的不准确或缺失细节。
-
图像的重要方面(例如车辆速度、道路状况)可能被低估或错误描述。
-
可能存在一些冲突或模糊的陈述。
-
-
2分:大多不一致
-
文本描述与图像大部分不一致,但包含少量相关信息。
-
描述未能捕捉到图像的关键细节或包含明显的错误。
-
文本中存在逻辑错误或矛盾。
-
-
1分:完全不一致
-
文本描述与图像完全不匹配。
-
文本完全不相关或在重要方面与图像相矛盾。
-
包含误导性信息,严重影响可解释性。
-
对于结构化动作标注,我们要求参与者对每个动作标注进行“正确”或“错误”的判断。
我们对5名参与者的评估结果进行了汇总,如表7所示。评分结果验证了标注的整体质量。具体来说,预测未来动作的标注 Af 得分最高,而描述推理的标注 Ar 得分最低。此外,对于动作标注,所有三种动作类型的准确率均在90%以上,其中车道动作的准确率最高,达到96%。


B.4. Successful Annotation Examples
我们提供了三个示例来展示VLM标注的质量,如图11、图12和图13所示。在图11中,VLM准确识别了红灯,并建议在路口停车。它还合理地预测了未来的动作,并清晰地解释了决策背后的逻辑。在图12中,前方有一辆白色货车,但位于对面车道。VLM正确评估了这辆货车不会影响自车的行驶,并输出了适当的驾驶动作。在图13中,自车在雨天的路口停下。尽管能见度较低,VLM仍然成功识别了红灯,并根据交通灯的状态预测了未来的动作。

B.5. Imperfect Annotation Examples
我们也提供了三个标注失败的案例,如图14、图15和图16所示。在图14中,VLM准确识别了绿灯,并根据推理标注预测了未来右转的动作。然而,它错误地从动作标注中输出了左转动作。由于我们分别查询Q1和Q2,因此Q1的响应不会影响Q2。一个可能的解决方案是引入额外的提示,以建立一个逐步提问的过程,从而获得更准确的动作标注。
在图15中,VLM输出“停车”或“慢行”作为自车的当前状态。尽管这些输出是合理的,但它们与真实情况不一致,因为投影的未来轨迹表明自车正在右转。另一方面,动作标注成功预测了正确的未来动作。在图16中,VLM错误地将行人交通灯误认为是交通灯,并提供了错误的响应。总体而言,尽管偶尔会出现错误,但VLM能够生成有意义的标注,揭示驾驶决策背后的逻辑,这也验证了我们的实验结果。通过分别查询两个独立的标注问题,我们的方法对VLM的错误具有一定的鲁棒性,因为错误通常只出现在其中一个响应中,如图14和图15所示。我们将获取更准确的VLM响应作为未来的工作,以进一步提升端到端规划模型的性能。
C. Additional Qualitative Examples
我们提供了图4的增强版本,通过一系列单独的图像展示:图17、图18、图19和图20。每幅图像都包含了数据集中的全部6个摄像头的图像,尽管我们的VLM标注流程仅关注前视图像,如第3.1节所述。除了图4之外,我们还额外提供了4个定性比较示例,以展示我们提出的方法与UniAD之间的规划结果差异,如图21、图22、图23和图24所示。在图21和图22中,UniAD生成的规划轨迹曲折且缺乏平滑性,未能保持在车道中心。相比之下,我们的方法生成的轨迹明显更加平滑,并且能够保持在车道边界内。同样,在图23和图24中,UniAD生成的命令是错误的,因为自车实际上是在直行。然而,我们的动作头成功预测了这些场景中的正确动作。这些定性示例突显了VLM-AD在复杂驾驶场景中生成更平滑、更准确的规划轨迹的能力,同时提供了更强的可解释性。



相关文章:
【论文精读】VLM-AD:通过视觉-语言模型监督实现端到端自动驾驶
论文地址: VLM-AD: End-to-End Autonomous Driving through Vision-Language Model Supervision 摘要 人类驾驶员依赖常识推理来应对复杂多变的真实世界驾驶场景。现有的端到端(E2E)自动驾驶(AD)模型通常被优化以模仿…...

2024年数字政府服务能力优秀创新案例汇编(附下载)
12月19日,由中国电子信息产业发展研究院指导、中国软件评测中心主办的“2024数字政府评估大会”在北京召开,大会主题是:为公众带来更好服务体验。 会上,中国软件评测中心副主任吴志刚发布了2024年数字政府服务能力评估结果&#…...

Ollama Docker 镜像部署
文章来源:Docker 部署文档 -- Ollama 中文文档|Ollama官方文档 仅 CPU docker run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama英伟达 GPU 安装 NVIDIA Container Toolkit。 使用 Apt 安装 配置存储库 curl -fsSL https://nvidia.g…...

[深度学习][python]yolov12+bytetrack+pyqt5实现目标追踪
【算法介绍】 实时目标检测因其低延迟特性而持续受到广泛关注,具有重要的实际应用价值[4, 17, 24, 28]。其中,YOLO系列[3, 24, 28, 29, 32, 45-47, 53, 57, 58]通过有效平衡延迟与精度,在该领域占据主导地位。尽管YOLO的改进多集中在损失函数…...

【深度学习】矩阵的理解与应用
一、矩阵基础知识 1. 什么是矩阵? 矩阵是一个数学概念,通常表示为一个二维数组,它由行和列组成,用于存储数值数据。矩阵是线性代数的基本工具之一,广泛应用于数学、物理学、工程学、计算机科学、机器学习和数据分析等…...

我是如何从 0 到 1 找到 Web3 工作的?
作者:Lotus的人生实验 关于我花了一个月的时间,从 0 到 1 学习 Web3 相关的知识和编程知识。然后找到了一个 Web3 创业公司实习的远程工作。 👇👇👇 我的背景: 计算机科班,学历还可以(大厂门槛水平) 毕业工…...
《Keras 3 :使用 Vision Transformers 进行物体检测》:此文为AI自动翻译
《Keras 3 :使用 Vision Transformers 进行物体检测》 作者:Karan V. Dave 创建日期:2022 年 3 月 27 日最后修改时间:2023 年 11 月 20 日描述:使用 Vision Transformer 进行对象检测的简单 Keras 实现。 (i) 此示例使用 Keras 3 在 Colab 中查看 GitHub 源 介绍 A…...
实现向deepseek/GPT等模型的api发送请求/多轮对话(附源码))
java(spring boot)实现向deepseek/GPT等模型的api发送请求/多轮对话(附源码)
我们再启动应用并获取api密钥后就可以对它发送请求了,但是官方文档对于如何进行多轮对话以及怎么自定义参数并没有说的很清楚,给的模板也没有java的,因此我们需要自己实现。 import org.json.JSONArray; import org.json.JSONObject;import j…...

module ‘cv2.dnn‘ has no attribute ‘DictValue‘解决办法
module ‘cv2.dnn‘ has no attribute ‘DictValue‘解决办法 pip install opencv-python4.7.0.72 -i https://pypi.tuna.tsinghua.edu.cn/simple 测试: python -c"import cv2"...

将RocketMQ集成到了Spring Boot项目中,实现站内信功能
1. 添加依赖 首先,在pom.xml中添加RocketMQ的依赖: <dependencies><!-- Spring Boot Starter Web --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifac…...

Deepseek 怼CHATGPT实况
提示词: 用犀利的语言批评ChatGPT 深度思考(R1) 嗯,用户让我用犀利的语言批评ChatGPT。首先,我需要理解他们的动机。可能他们遇到了ChatGPT的某些问题,比如回答不准确或者缺乏深度,所以想表达不满。也有…...
--阈值的方法)
基础篇11-图像分割(上)--阈值的方法
图像分割是图像处理的重要内容,是位于底层的图像处理、特征提取与上一层次的图像分析之间的关键步骤。图像分割的相关技术较多,分为三篇介绍。本节是上篇,介绍基于阈值的技术。 1 引言 图像分割是计算机视觉和图像处理中的核心任务之一&…...

[特殊字符] LeetCode 62. 不同路径 | 动态规划+递归优化详解
在解 LeetCode 的过程中,路径计数问题是动态规划中一个经典的例子。今天我来分享一道非常基础但极具代表性的题目——不同路径。不仅适合初学者入门 DP(动态规划),还能帮助你打下递归思维的基础。 本文将介绍: &…...

常用的 JVM 参数:配置与优化指南
文章目录 常用的 JVM 参数:配置与优化指南引言 1. 内存管理参数1.1 堆内存配置1.2 方法区(元空间)配置1.3 直接内存配置 2. 垃圾回收参数2.1 垃圾回收器选择2.2 GC 日志配置2.3 GC 调优参数 3. 性能监控参数3.1 堆内存转储3.2 JVM 监控3.3 远…...

【JavaWeb学习Day17】
Tlias智能学习系统(员工管理) 新增员工: 三层架构职责: Controller:1.接收请求参数(员工信息);2.调用service方法;3.响应结果。 具体实现: /***新增员工…...

DeepSeek 提示词:定义、作用、分类与设计原则
🧑 博主简介:CSDN博客专家,历代文学网(PC端可以访问:https://literature.sinhy.com/#/?__c1000,移动端可微信小程序搜索“历代文学”)总架构师,15年工作经验,精通Java编…...

前端大文件上传
1. 开场概述 “大文件上传是前端开发中常见的需求,但由于文件体积较大,直接上传可能会遇到网络不稳定、服务器限制等问题。因此,通常需要采用分片上传、断点续传、并发控制等技术来优化上传体验” 2. 核心实现方案 “我通常会采用以下方案…...

JDK源码系列(一)Object
Object 概述 Object类是所有类的基类——java.lang.Object。 Object类是所有类的基类,当一个类没有直接继承某个类时,默认继承Object类Object类属于java.lang包下,此包下的所有类在使用时无需手动导入,系统会在程序编译期间自动…...
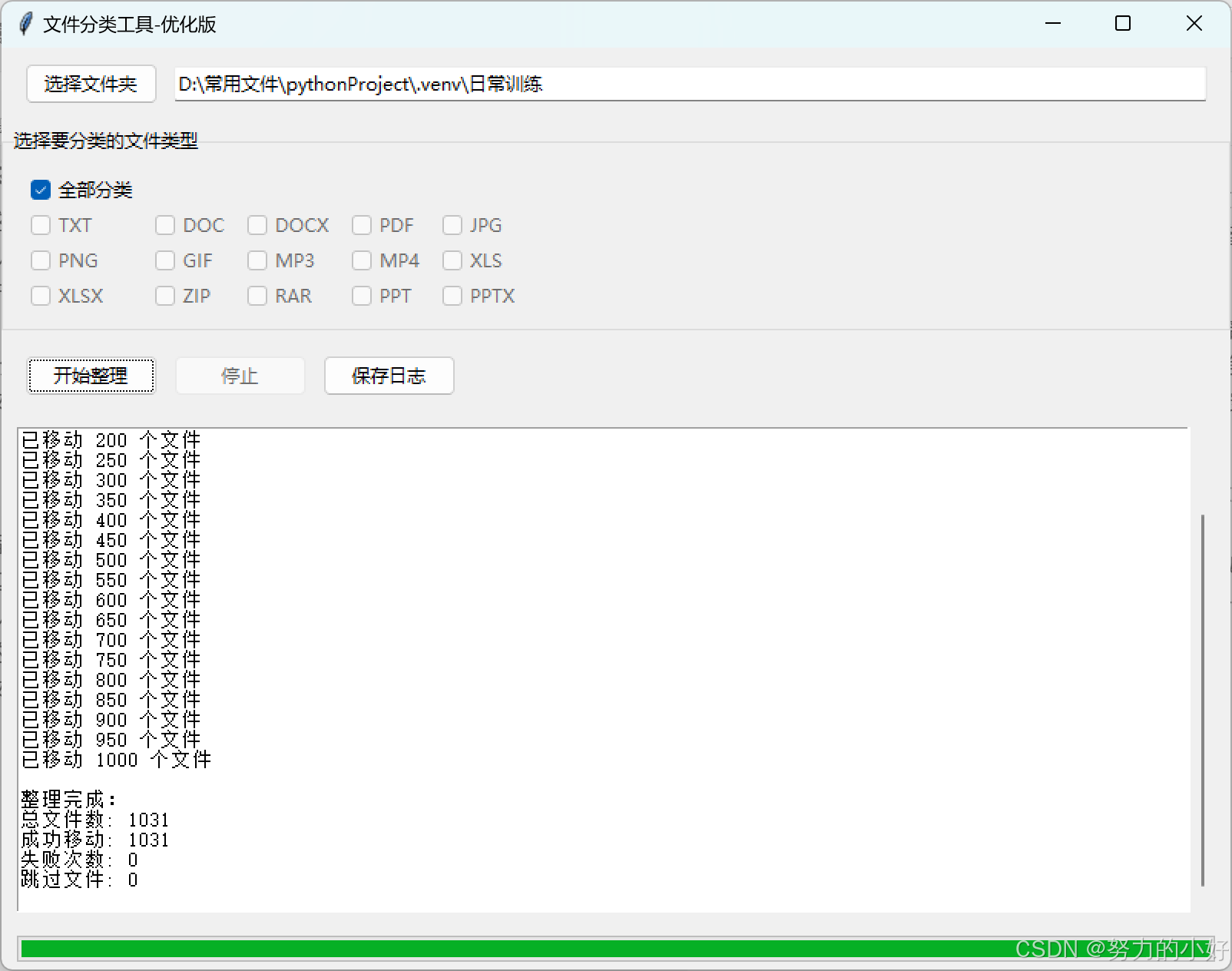
【Python 打造高效文件分类工具】
【Python】 打造高效文件分类工具 一、代码整体结构二、关键代码解析(一)初始化部分(二)界面创建部分(三)核心功能部分(四)其他辅助功能部分 三、运行与使用四、示图五、作者有话说 …...

大数据组件(四)快速入门实时数据湖存储系统Apache Paimon(1)
Paimon的下载及安装,并且了解了主键表的引擎以及changelog-producer的含义参考: 大数据组件(四)快速入门实时数据湖存储系统Apache Paimon(1) 利用Paimon表做lookup join,集成mysql cdc等参考: 大数据组件(四)快速入门实时数据…...

保姆级教程:在Windows/Linux终端里设置PYTORCH_CUDA_ALLOC_CONF环境变量,彻底告别Pytorch显存碎片
彻底解决Pytorch显存碎片化:PYTORCH_CUDA_ALLOC_CONF环境变量设置全指南 当你正在训练一个深度学习模型,突然看到那个令人心碎的报错——"CUDA out of memory",而明明你的GPU显存看起来还有不少剩余空间。这种情况往往是由显存碎片…...

fastp性能优化秘籍:如何根据数据类型选择最佳参数配置
fastp性能优化秘籍:如何根据数据类型选择最佳参数配置 【免费下载链接】fastp An ultra-fast all-in-one FASTQ preprocessor (QC/adapters/trimming/filtering/splitting/merging...) 项目地址: https://gitcode.com/gh_mirrors/fa/fastp fastp是一款超快速…...

OpenMV的PWM控制舵机,你踩过这几个坑吗?关于Timer、引脚和占空比的避坑指南
OpenMV的PWM控制舵机:从Timer配置到实战避坑全解析 在机器人控制和自动化项目中,精确的舵机控制往往是实现精准动作的关键。OpenMV作为一款集成了图像处理能力的微控制器,其PWM输出功能为开发者提供了直接控制舵机的便捷途径。然而࿰…...

AO3镜像站终极指南:快速解锁全球同人创作宝库
AO3镜像站终极指南:快速解锁全球同人创作宝库 【免费下载链接】AO3-Mirror-Site 项目地址: https://gitcode.com/gh_mirrors/ao/AO3-Mirror-Site Archive of Our Own(AO3)是全球最大的非营利性同人创作平台,汇聚了数百万创…...

OBS多路RTMP推流插件终极指南:一键实现多平台直播全覆盖
OBS多路RTMP推流插件终极指南:一键实现多平台直播全覆盖 【免费下载链接】obs-multi-rtmp OBS複数サイト同時配信プラグイン 项目地址: https://gitcode.com/gh_mirrors/ob/obs-multi-rtmp 想要将你的直播内容同时推送到YouTube、Twitch、Bilibili等多个平台…...

七旬阿婆半年打赏330万,儿子回家发现连15块电费都交不起
王建国(化名)怎么也没想到,自己援边多年攒下的积蓄,会以这种方式化为乌有。今年4月初,他回到上海家中,发现母亲江阿婆神情恍惚,家里冷清得不像话。问起近况,老人才支支吾吾地说&…...
)
不止于华文细黑:在Unity中为你的游戏UI打造一套完整的字体资产管理方案(含TextMeshPro)
不止于华文细黑:在Unity中为你的游戏UI打造一套完整的字体资产管理方案(含TextMeshPro) 当游戏UI中的文字从"任务完成"变成"你拯救了这片大陆的最后希望",字体就不再只是信息的载体,而是情感传递的…...

Origin 2022b 新功能实战:除了画图,这些效率提升技巧你知道吗?
Origin 2022b科研效率革命:5个被低估的高级功能深度解析 科研绘图工具早已不再是简单的数据可视化载体,而是演变为贯穿整个研究流程的智能协作平台。Origin 2022b的升级绝非仅是界面微调或性能优化,它在工作流自动化、跨平台协作、实验记录标…...

Windows 11任务栏拖放功能修复:如何恢复被微软移除的高效操作
Windows 11任务栏拖放功能修复:如何恢复被微软移除的高效操作 【免费下载链接】Windows11DragAndDropToTaskbarFix "Windows 11 Drag & Drop to the Taskbar (Fix)" fixes the missing "Drag & Drop to the Taskbar" support in Window…...

Docker 27边缘容器编排实战:从零部署到万级IoT节点稳定运行的7个硬核配置诀窍
第一章:Docker 27边缘容器编排的演进逻辑与核心挑战边缘计算场景下,容器编排正从中心化调度向轻量、自治、低延迟协同范式迁移。Docker 27并非官方版本号(Docker CE 最新稳定版为 24.x),但作为技术演进的抽象符号&…...