sklearn中的决策树-分类树:重要参数
分类树
-
sklearn.tree.DecisionTreeClassifiersklearn.tree.DecisionTreeClassifier (criterion=’gini’ # 不纯度计算方法, splitter=’best’ # best & random, max_depth=None # 树最大深度, min_samples_split=2 # 当前节点可划分最少样本数, min_samples_leaf=1 # 子节点最少样本数, min_weight_fraction_leaf=0.0, max_features=None, random_state=None, max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, class_weight=None, presort=False)
重要参数
criterion
-
criterion这个参数正是用来决定不纯度的计算方法的。sklearn提供了两种选择:- 输入”entropy“,使用信息熵(
Entropy),sklearn实际计算的是基于信息熵的信息增益(Information Gain),即父节点的信息熵和子节点的信息熵之差。 - 输入”gini“,使用基尼系数(Gini Impurity)
E n t r o p y ( t ) = − ∑ i = 0 c − 1 p ( i ∣ t ) log 2 p ( i ∣ t ) Entropy(t) = - \sum \limits_{i=0}^{c-1} p(i|t)\log{_2}p(i|t) Entropy(t)=−i=0∑c−1p(i∣t)log2p(i∣t)
G i n i ( t ) = 1 − ∑ i = 0 c − 1 p ( i ∣ t ) 2 Gini(t) = 1 - \sum_{i=0}^{c-1}p(i|t)^2 Gini(t)=1−i=0∑c−1p(i∣t)2
其中t代表给定的节点,i代表标签的任意分类, p ( i ∣ t ) p(i|t) p(i∣t) 代表标签分类i在节点t上所占的比例。注意,当使用信息熵 时,
sklearn实际计算的是基于信息熵的信息增益(Information Gain),即父节点的信息熵和子节点的信息熵之差。 比起基尼系数,信息熵对不纯度更加敏感,对不纯度的惩罚最强。但是在实际使用中,信息熵和基尼系数的效果基 本相同。信息熵的计算比基尼系数缓慢一些,因为基尼系数的计算不涉及对数。另外,因为信息熵对不纯度更加敏 感,所以信息熵作为指标时,决策树的生长会更加“精细”,因此对于高维数据或者噪音很多的数据,信息熵很容易 过拟合,基尼系数在这种情况下效果往往比较好。当模型拟合程度不足的时候,即当模型在训练集和测试集上都表 现不太好的时候,使用信息熵。当然,这些不是绝对的。参数 criterion 如何影响模型? 确定不纯度的计算方法,帮忙找出最佳节点和最佳分枝,不纯度越低,决策树对训练集 的拟合越好 可能的输入有哪 些? 不填默认基尼系数,填写gini使用基尼系数,填写entropy使用信息增益 怎样选取参数? 通常就使用基尼系数 数据维度很大,噪音很大时使用基尼系数 维度低,数据比较清晰的时候,信息熵和基尼系数没区别 当决策树的拟合程度不够的时候,使用信息熵,两个都试试不好就换另一个 # -*- coding: utf-8 -*-""" ************************************************** @author: Ying @software: PyCharm @file: 分类树_criterion.py @time: 2021-08-20 16:13 ************************************************** """ from sklearn import tree from sklearn.datasets import load_wine from sklearn.model_selection import train_test_split import pandas as pd import graphviz# 加载数据 wine = load_wine() data = pd.DataFrame(wine.data, columns=wine.feature_names) # X target = pd.DataFrame(wine.target) # y# 划分训练测试集 X_train, X_test, y_train, y_test = train_test_split(data, target, test_size=0.3)# 两种criterionfor criterion_ in ['entropy', 'gini']:clf = tree.DecisionTreeClassifier(criterion=criterion_)clf.fit(X_train, y_train)score = clf.score(X_test, y_test) # 返回预测的准确度print(f'criterion:{criterion_} \t accurancy : {score}')# 保存决策树图feature_name = ['酒精', '苹果酸', '灰', '灰的碱性', '镁', '总酚', '类黄酮', '非黄烷类酚类','花青素', '颜色强度', '色调', 'od280/od315稀释葡萄酒', '脯氨酸']dot_data = tree.export_graphviz(clf, feature_names=feature_name, class_names=["琴酒", "雪莉", "贝尔摩德"], filled=True # 填充颜色, rounded=True # 圆角)graph = graphviz.Source(dot_data)graph.render(view=True, format="pdf", filename=f"decisiontree_pdf_{criterion_}")# 特征重要性feature_importances = clf.feature_importances_for i in [*zip(feature_name, feature_importances)]:print(i)print()

"""输出如下"""criterion:entropy accurancy : 0.8703703703703703 ('酒精', 0.0) ('苹果酸', 0.0) ('灰', 0.0) ('灰的碱性', 0.02494246008989065) ('镁', 0.0) ('总酚', 0.0) ('类黄酮', 0.3296114164674079) ('非黄烷类酚类', 0.0) ('花青素', 0.0) ('颜色强度', 0.14329965511242485) ('色调', 0.0) ('od280/od315稀释葡萄酒', 0.0) ('脯氨酸', 0.5021464683302767)criterion:gini accurancy : 0.8148148148148148 ('酒精', 0.0) ('苹果酸', 0.0) ('灰', 0.0) ('灰的碱性', 0.0) ('镁', 0.04779989924874613) ('总酚', 0.06725255711062922) ('类黄酮', 0.3230308396876504) ('非黄烷类酚类', 0.0) ('花青素', 0.0235378291755189) ('颜色强度', 0.0) ('色调', 0.0) ('od280/od315稀释葡萄酒', 0.0878400745934749) ('脯氨酸', 0.45053880018398057) - 输入”entropy“,使用信息熵(
-
回到模型步骤,每次运行score会在某个值附近 波动,引起每次画出来的每一棵树都不一样。它为什么会不稳定呢?如果使用其他数据集,它还会不稳定吗?
无论决策树模型如何进化,在分枝上的本质都还是追求某个不纯度相关的指标的优化,而正如我 们提到的,不纯度是基于节点来计算的,也就是说,决策树在建树时,是靠优化节点来追求一棵优化的树,但最优 的节点能够保证最优的树吗?集成算法被用来解决这个问题:sklearn表示,既然一棵树不能保证最优,那就建更 多的不同的树,然后从中取最好的。怎样从一组数据集中建不同的树?在每次分枝时,不从使用全部特征,而是随 机选取一部分特征,从中选取不纯度相关指标最优的作为分枝用的节点。这样,每次生成的树也就不同了。
random_state&spliter
-
random_state用来设置分枝中的随机模式的参数,默认None,在高维度时随机性会表现更明显,低维度的数据 (比如鸢尾花数据集),随机性几乎不会显现。输入任意整数,会一直长出同一棵树,让模型稳定下来。 -
splitter也是用来控制决策树中的随机选项的,有两种输入值:- best
- random
输入”best",决策树在分枝时虽然随机,但是还是会 优先选择更重要的特征进行分枝(重要性可以通过属性
feature_importances_查看)输入“random",决策树在 分枝时会更加随机,树会因为含有更多的不必要信息而更深更大,并因这些不必要信息而降低对训练集的拟合。这 也是防止过拟合的一种方式。当你预测到你的模型会过拟合,用这两个参数来帮助你降低树建成之后过拟合的可能 性。当然,树一旦建成,我们依然是使用剪枝参数来防止过拟合。
# -*- coding: utf-8 -*-""" ************************************************** @author: Ying @software: PyCharm @file: 2、分类树_random_state&spliter.py @time: 2021-08-20 16:58 ************************************************** """from sklearn import tree from sklearn.datasets import load_wine from sklearn.model_selection import train_test_split import pandas as pd import graphviz# 加载数据 wine = load_wine() data = pd.DataFrame(wine.data, columns=wine.feature_names) # X target = pd.DataFrame(wine.target) # y# 划分训练测试集 X_train, X_test, y_train, y_test = train_test_split(data, target, test_size=0.3)clf = tree.DecisionTreeClassifier(criterion='gini', random_state=30, splitter='best')clf.fit(X_train, y_train) score = clf.score(X_test, y_test) # 返回预测的准确度# 保存决策树图 feature_name = ['酒精', '苹果酸', '灰', '灰的碱性', '镁', '总酚', '类黄酮', '非黄烷类酚类','花青素', '颜色强度', '色调', 'od280/od315稀释葡萄酒', '脯氨酸']dot_data = tree.export_graphviz(clf, feature_names=feature_name, class_names=["琴酒", "雪莉", "贝尔摩德"], filled=True # 填充颜色, rounded=True # 圆角) graph = graphviz.Source(dot_data)graph.render(view=True, format="pdf", filename="decisiontree_pdf")# 特征重要性 feature_importances = clf.feature_importances_a = pd.DataFrame([*zip(feature_name, feature_importances)]) a.columns = ['feature', 'importance'] a.sort_values('importance', ascending=False, inplace=True) print(a)
相关文章:
sklearn中的决策树-分类树:重要参数
分类树 sklearn.tree.DecisionTreeClassifier sklearn.tree.DecisionTreeClassifier (criterion’gini’ # 不纯度计算方法, splitter’best’ # best & random, max_depthNone # 树最大深度, min_samples_split2 # 当前节点可划分最少样本数, min_samples_leaf1 # 子节点最…...

25林业研究生复试面试问题汇总 林业专业知识问题很全! 林业复试全流程攻略 林业考研复试真题汇总
25 林业考研复试,专业面试咋准备?学姐来支招! 宝子们,一提到林业考研复试面试,是不是就慌得不行,感觉老师会扔出一堆超难的问题?别怕别怕,其实林业考研复试就那么些套路,…...

DeepSeek最新开源动态:核心技术公布
2月21日午间,DeepSeek在社交平台X发文称,从下周开始,他们将开源5个代码库,以完全透明的方式与全球开发者社区分享他们的研究进展。并将这一计划定义为“Open Source Week”。 DeepSeek表示,即将开源的代码库是他们在线…...

Electron通过ffi-napi调用dll导出接口
electron使用ffi-napi环境搭建 附打包好的ffi-napi可以直接放到项目目录下使用,避免以后麻烦 一、安装node.js Node.js官网:https://nodejs.org/zh-cn/download,选择LTS长期稳定版本即可 需要注意Node.js 区分32和64位,32位版…...

【排序算法】六大比较类排序算法——插入排序、选择排序、冒泡排序、希尔排序、快速排序、归并排序【详解】
文章目录 六大比较类排序算法(插入排序、选择排序、冒泡排序、希尔排序、快速排序、归并排序)前言1. 插入排序算法描述代码示例算法分析 2. 选择排序算法描述优化代码示例算法分析 3. 冒泡排序算法描述代码示例算法分析与插入排序对比 4. 希尔排序算法描…...

计算机毕业设计Hadoop+Spark+DeepSeek-R1大模型民宿推荐系统 hive民宿可视化 民宿爬虫 大数据毕业设计(源码+LW文档+PPT+讲解)
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 作者简介:Java领…...

【Java学习】抽象类与接口
面向对象系列四 一、抽象方法 二、抽象类 三、意义检查 1.抽象方法的意义 2.意义检查 体现 四、接口 1.级别层次 2.接口变量 3.意义 4.成员 成员变量: 成员方法: 一、抽象方法 没有方法体即没有任何实现的方法是抽象方法,只有在…...

SpringBoot中实现限流和熔断功能
我们将使用Java的ScheduledExecutorService来实现一个简单的令牌桶算法(Token Bucket Algorithm),并结合一个自定义的服务类来处理第三方API调用。 1. 创建限流器 首先,创建一个简单的限流器类: import java.util.concurrent.*;public class SimpleRateLimiter {...
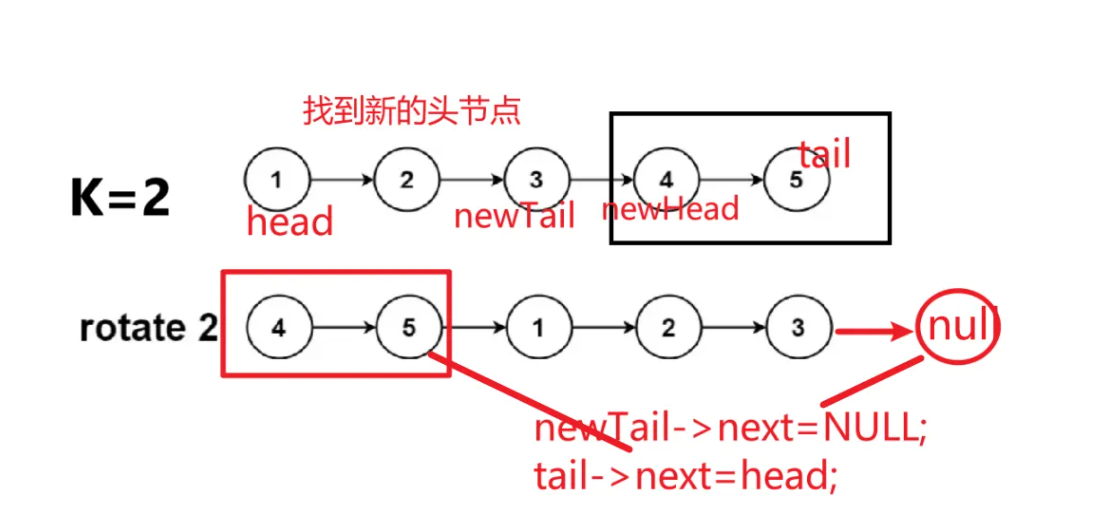
61.旋转链表--字节跳动
你应该比你现在强得多 题目描述 给定单链表,要求返回向右移动K位后的新链表 输入:head [1,2,3,4,5], k 2 输出:[4,5,1,2,3]思路分析 计算链表的长度 计算实际需要移动的步数 找到新的头节点 断开链表并重新连接 完整代码 /*** Defini…...

verilog笔记
Verilog学习笔记(一)入门和基础语法BY电棍233 由于某些不可抗拒的因素和各种的特殊原因,主要是因为我是微电子专业的,我需要去学习一门名为verilog的硬件解释语言,由于我是在某西部地区的神秘大学上学,这所…...

c++中sleep是什么意思(不是Sleep() )
sleep 函数在 C 语言中用于暂停程序执行指定的秒数,语法为 sleep(unsigned int seconds)。当 seconds 为 0 时,函数立即返回,否则函数将使进程暂停指定的秒数,并返回实际暂停的时间。 sleep 函数在 C 中的含义 sleep 函数是 C 标…...

Uniapp 开发中遇到的坑与注意事项:全面指南
文章目录 1. 引言Uniapp 简介开发中的常见问题本文的目标与结构 2. 环境配置与项目初始化环境配置问题解决方案 项目初始化注意事项解决方案 常见错误与解决方案 3. 页面与组件开发页面生命周期注意事项示例代码 组件通信与复用注意事项示例代码 样式与布局问题注意事项示例代码…...

Dify安装教程:Linux系统本地化安装部署Dify详细教程
1. 本地部署 Dify 应用开发平台 环境:Ubuntu(24.10) docker-ce docker compose 安装 克隆 Dify 源代码至本地环境: git clone https://github.com/langgenius/dify.git 启动 Dify: cd dify/docker cp .env.example...

rtsp rtmp 跟 http 区别
SDP 一SDP介绍 1. SDP的核心功能 会话描述:定义会话的名称、创建者、时间范围、连接地址等全局信息。媒体协商:明确媒体流的类型(如音频、视频)、传输协议(如RTP/UDP)、编码格式(如H.264、Op…...

基于YOLO11深度学习的运动鞋品牌检测与识别系统【python源码+Pyqt5界面+数据集+训练代码】
《------往期经典推荐------》 一、AI应用软件开发实战专栏【链接】 项目名称项目名称1.【人脸识别与管理系统开发】2.【车牌识别与自动收费管理系统开发】3.【手势识别系统开发】4.【人脸面部活体检测系统开发】5.【图片风格快速迁移软件开发】6.【人脸表表情识别系统】7.【…...
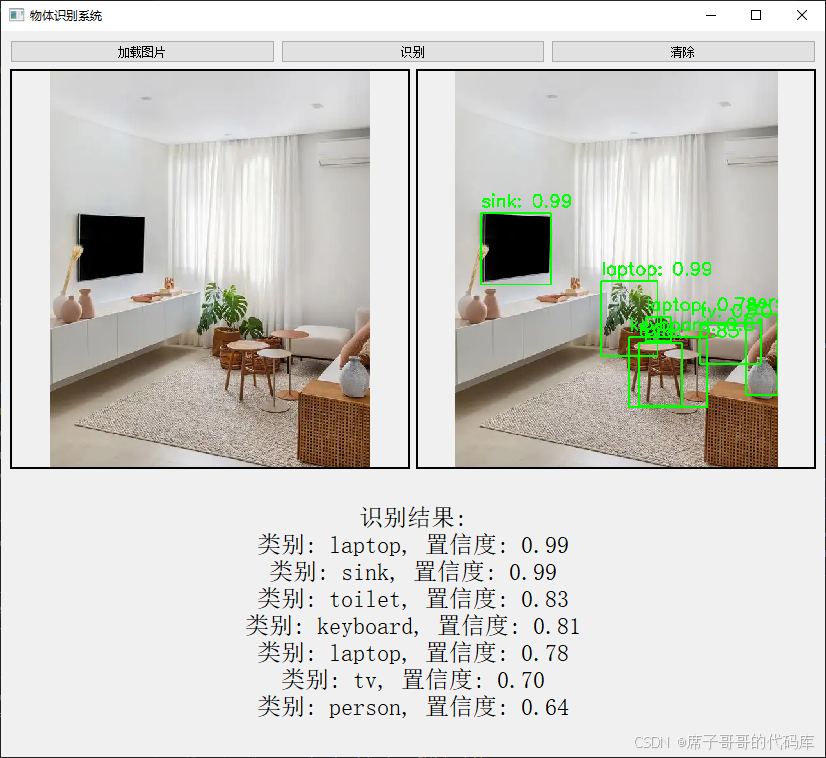
物体识别系统(识别图片中的物体)
这是一个基于 PyTorch 和 PyQt5 的物体识别程序,使用 Faster R-CNN 模型来识别图片中的物体,并通过图形界面展示识别结果。 1.用户界面 主窗口:包含加载图片、识别、清除按钮,以及图片显示区域和结果展示区域。 图片显示&#…...

数据表的存储过程和函数介绍
文章目录 一、概述二、创建存储过程三、在创建过程中使用变量四、光标的使用五、流程控制的使用六、查看和删除存储过程 一、概述 存储过程和函数是在数据库中定义的一些SQL语句的集合,然后直接调用这些存储过程和函数来执行已经定义好的SQL语句。存储过程和函数可…...

【DeepSeek-R1背后的技术】系列九:MLA(Multi-Head Latent Attention,多头潜在注意力)
【DeepSeek背后的技术】系列博文: 第1篇:混合专家模型(MoE) 第2篇:大模型知识蒸馏(Knowledge Distillation) 第3篇:强化学习(Reinforcement Learning, RL) 第…...

【JavaWeb12】数据交换与异步请求:JSON与Ajax的绝妙搭配是否塑造了Web的交互革命?
文章目录 🌍一. 数据交换--JSON❄️1. JSON介绍❄️2. JSON 快速入门❄️3. JSON 对象和字符串对象转换❄️4. JSON 在 java 中使用❄️5. 代码演示 🌍二. 异步请求--Ajax❄️1. 基本介绍❄️2. JavaScript 原生 Ajax 请求❄️3. JQuery 的 Ajax 请求 &a…...
)
[特殊字符] 蓝桥杯 Java B 组 之位运算(异或性质、二进制操作)
Day 6:位运算(异或性质、二进制操作) 📖 一、位运算简介 位运算是计算机底层优化的重要手段,利用二进制操作可以大大提高运算速度。常见的位运算包括: 与(&):a &am…...

skeyevss-performance 长任务Panic隔离与协程恢复源码设计
试用安装包下载 | SMS | 在线演示 开源项目地址:https://github.com/openskeye/go-vss 背景 VSS 长期运行,任何 nil 指针、越界、第三方库 bug 都可能触发 panic。若 panic 发生在 唯一 的 SIP 发送循环或 Catalog 定时器里,会导致 整类信…...

C#怎么实现全文搜索 C#如何集成Elasticsearch或Lucene.Net实现全文检索功能【数据库】
Lucene.Net最轻量但需手动管理索引生命周期:须单例复用IndexWriter、显式设字段索引、用中文分词器、调Commit()提交,否则易出锁异常或搜不到数据。用 Lucene.Net 做本地全文搜索最轻量,但得自己管索引生命周期直接上手 Lucene.Net 是 C# 里最…...

AI优化电动汽车充电:PSO算法与GPU加速实践
1. 电动汽车充电优化的AI革命:从理论到实践作为一名长期关注能源与AI交叉领域的技术从业者,我最近被加拿大皇家军事学院(RMC)团队的研究成果所震撼。他们开发的这套基于粒子群优化(PSO)算法的实时充电调度系统,完美诠释了如何用AI技术解决电动…...

量子纠错与表面码在QCCD架构中的实现与优化
1. 量子纠错与表面码基础解析量子计算的核心挑战在于量子比特的脆弱性——环境噪声会导致量子态退相干,使得计算过程不可靠。量子纠错(QEC)技术通过将逻辑量子比特编码在多个物理量子比特上,实现了对错误的检测和纠正。表面码&…...

【立煌】G150XTN06.0规格友达15寸工业液晶屏幕AUO液晶模组
在工业自动化、机台控制、医疗仪器及安防显示等应用领域,15英寸液晶模组长期被视为“工业标准尺寸”。友达(AUO)推出的G150XTN06.0正是其中的代表型号之一。这款屏凭借宽温设计、可更换背光、内置LED驱动器与6/8位灰阶兼容特性,实…...

从测量到成图:一份完整的中海达RTK+Hi-Survey Road外业数据采集与内业处理全流程
中海达RTKHi-Survey Road测绘全流程:从外业数据采集到内业成图的实战指南 测绘工程师的日常工作中,RTK技术早已成为不可或缺的利器。但真正高效的应用远不止于会操作仪器——从项目规划、外业测量到内业成图的完整闭环,每个环节都藏着影响效率…...
 全栈底层复习指南)
STM32 串口通信 (UART) 全栈底层复习指南
目录 一、 物理层与通信协议基础 (底层时序) 1. 硬件连接规则 2. 通信时序与数据帧 (以最常用的 10 位标准帧 8N1 为例) 二、 UART 底层硬件架构 (双缓冲机制) 1. 接收双缓冲:移位寄存器 & RDR (接收数据寄存器) 2. 发送双缓冲:TDR (发送数据寄…...

Qt 6.5 商用项目选哪个许可证?GPL、LGPL、商业版保姆级避坑指南
Qt 6.5商用项目许可证选择全攻略:从法律风险到成本优化 当技术决策遇上法律条款,选择Qt许可证就像在迷宫中寻找最优路径。作为跨平台开发框架的标杆,Qt 6.5为商业项目提供了三种截然不同的许可证模式——GPL、LGPL和商业授权,每种…...

自动驾驶感知模型训练的内存优化与张量并行实践
1. 自动驾驶感知模型训练的内存挑战在自动驾驶领域,感知模型承担着从多摄像头输入中提取环境特征的关键任务。这类模型通常采用深度卷积神经网络(CNN)作为骨干架构,处理来自多个高分辨率摄像头的并行数据流。以NIO Aquila超感系统…...

胡桃工具箱完整使用指南:从零开始掌握原神最强桌面助手
胡桃工具箱完整使用指南:从零开始掌握原神最强桌面助手 【免费下载链接】Snap.Hutao 实用的开源多功能原神工具箱 🧰 / Multifunctional Open-Source Genshin Impact Toolkit 🧰 项目地址: https://gitcode.com/GitHub_Trending/sn/Snap.Hu…...