【排序算法】六大比较类排序算法——插入排序、选择排序、冒泡排序、希尔排序、快速排序、归并排序【详解】
文章目录
- 六大比较类排序算法(插入排序、选择排序、冒泡排序、希尔排序、快速排序、归并排序)
- 前言
- 1. 插入排序
- 算法描述
- 代码示例
- 算法分析
- 2. 选择排序
- 算法描述
- 优化
- 代码示例
- 算法分析
- 3. 冒泡排序
- 算法描述
- 代码示例
- 算法分析
- 与插入排序对比
- 4. 希尔排序
- 算法描述
- 代码示例
- 算法分析
- 5. 快速排序
- 5.1 挖坑法
- 算法描述
- 单轮操作
- 代码示例
- 算法分析
- 优化(三数取中,小区间优化)
- 5.2 左右指针法
- 算法描述
- 代码示例
- 5.3 前后指针法
- 算法描述
- 代码示例
- 6. 归并排序
- 算法描述
- 代码示例
- 总结对比
六大比较类排序算法(插入排序、选择排序、冒泡排序、希尔排序、快速排序、归并排序)
前言
排序:所谓排序,就是使一串记录,按照其中的某个或某些关键字的大小,递增或递减地排列起来地操作。
稳定性:假定在待排序地记录序列中,存在多个具有相同的关键字的记录,若经过排序,这些记录的相对次序保持不变,即在原序列中,r[i] = r[j],且 r[i] 在 r[j] 之前,而在排序后的序列中。r[i] 仍在 r[j] 之前。则称这种排序算法是稳定的。否则称为不稳定的。
内部排序:数据元素全部放在内存中的排序。(我们下面讲的排序都是属于内部排序)
外部排序:数据元素太多不能同时放在内存中,根据排序过程的要求不能在内外存之间移动数据的排序。
1. 插入排序
直接插入排序是一种简单的插入排序法,其基本思想是:把待排序的记录按其关键码值的大小逐个插入到一个已经排好序的有序序列中,直到所有的记录插入完为止,得到一个新的有序序列。
插入排序的原理很好理解,打过扑克牌的人应该都能懂这种思想。
当我们在插入第 i (i>=1) 个元素时,前面的
array[0],array[1],…,array[i-1]已经排好序(初始时,已排序部分只包含第一个元素,未排序部分包含剩余元素),此时用array[i]的排序码依次与它前面的array[i-1],array[i-2],… 的排序码顺序进行比较,找到插入位置时就就将array[i]插入。原来位置上的元素顺序后移一位。

下面是动图演示:

// 插入排序
void InsertSort(int* a, int n) { // n表示数组的大小for (int i = 0; i < n - 1; i++) {int end = i; int tmp = a[end + 1]; // 待排序元素while (end >= 0) {if (a[end] > tmp) { // 依次向前比较a[end + 1] = a[end]; // 向后移移位--end;}else { break;}}a[end + 1] = tmp; // 插入操作}
}
元素集合越接近有序,直接插入排序算法的时间复杂度效率越高
时间复杂度: O ( N 2 ) O(N^2) O(N2)
最坏情况下为 O ( N 2 ) O(N^2) O(N2),此时待排序列为逆序,或者说接近逆序
最好情况下为 O ( N ) O(N) O(N),此时待排序列为升序,或者说接近升序。空间复杂度: O ( 1 ) O(1) O(1)
稳定性:稳定
2. 选择排序
选择排序的基本思想是每次从待排序列中选出一个最小值(或最大值),然后放在序列的起始(或末尾)位置,直到全部待排数据排完即可。
下面是动图演示:

实际上,我们可以一趟选出两个值,一个最大值一个最小值,然后将其放在序列开头和末尾,这样可以使选择排序的效率快一倍。
void SelectSort(int* a, int n) {int begin = 0, end = n - 1; // 保存开头和末尾的下标while (begin < end) {int mini = begin, maxi = begin; // 记录区间内最小值和最大值的下标for (int i = begin; i <= end; ++i) { // 该循环用于找到区间内的最大和最小值if (a[i] < a[mini]) {mini = i; }if (a[i] > a[maxi]) {maxi = i;}}// Swap函数在外部需要自己写一下Swap(&a[begin], &a[mini]); // 把最小的放在开头Swap(&a[end], &a[maxi]); // 把最大的放在末尾++begin;--end;}
}
这就完了吗?当然没有,还有一点小瑕疵,我们来看这两行:
Swap(&a[begin], &a[mini]); // 把最小的放在开头
Swap(&a[end], &a[maxi]); // 把最大的放在末尾
这里万一我最大的数就是开头的数呢?就有可能在第一次交换的时候和最小值交换走,那么下一行交换的时候 a[maxi] 就不是最大值了,所以在第一次交换的时候我们需要判断一下 begin 和 maxi 的位置是否重叠。完整代码如下:
void SelectSort(int* a, int n) {int begin = 0, end = n - 1;while (begin < end) {int mini = begin, maxi = begin;for (int i = begin; i <= end; ++i) {if (a[i] < a[mini]) {mini = i;}if (a[i] > a[maxi]) {maxi = i;}}Swap(&a[begin], &a[mini]); // 把最小的放在开头// 如果 begin 和 maxi 的位置重叠,maxi 的位置要修正一下if (begin == maxi) {maxi = mini; // 也就是说值换了那么对应的下标也得改}Swap(&a[end], &a[maxi]); // 把最大的放在末尾++begin;--end;}
}
时间复杂度:最坏情况: O ( N 2 ) O(N^2) O(N2)
最好情况: O ( N 2 ) O(N^2) O(N2)
空间复杂度: O ( 1 ) O(1) O(1)稳定性:不稳定
3. 冒泡排序
冒泡排序通过比较相邻的元素并交换它们的位置来实现排序。即从列表的第一个元素开始,比较相邻的两个元素。如果前一个元素比后一个元素大,则交换它们的位置。对列表中的每一对相邻元素重复上述步骤,直到列表的末尾。这样,最大的元素会被 “冒泡” 到列表的最后。忽略已经排序好的最后一个元素,重复上述步骤,直到整个列表排序完成。
下面是动图演示:

void BubbleSort(int* a, int n) {for (int i = 0; i < n - 1; i++) {int flag = 0;for (int j = 1; j < n - i; j++) {if (a[j - 1] > a[j]) {Swap(&a[j - 1], &a[j]); // 前面比后面大就交换flag = 1;}}// 没有发生交换说明已经有序,不需要再比较了if (flag == 0) {break;}}
}
时间复杂度:最坏情况: O ( N 2 ) O(N^2) O(N2)
最好情况: O ( N ) O(N) O(N)(通过设置一个变量 flag 来实现)
空间复杂度: O ( 1 ) O(1) O(1)稳定性:稳定
当一个数组很接近有序的时候,比如
[1, 2, 3, 5, 4, 6],这个时候采用插入排序循环的执行次数只需要 N N N 次, 而冒泡排序需要 ( N − 1 ) + ( N − 2 ) (N-1)+(N-2) (N−1)+(N−2) 次。可见,对于接近有序的数组,插入排序比冒泡排序的局部适应性更强。
4. 希尔排序
希尔排序又称缩小增量法,它的基本思想是:将待排序的元素分为多个子序列,然后对每个子序列进行插入排序。这些子序列是原始序列中相隔一定增量的元素组成的。然后逐渐减小增量,重复这个过程,最终将增量减小到 1,完成最后一轮的插入排序,此时序列已经基本有序,只需进行少量的比较和交换操作,大大提高了排序效率。

也就是说,我们需要指定一个 gap(间隔),从第一个数开始每各一个这个 gap 的距离直到最后的这些数为一组,在同一个组内的数它们进行插入排序的操作。然后进行了这一轮 “预排序” 之后再逐渐缩小这个 gap,直到 gap 为 1,最后这个数组就有序了。而我们会发现:
- gap 越大,大的数可以越快地到后面,小的数可以越快地到前面。但是这样预排序完数组也越不接近有序。
- gap 越小,排完之后地数组越接近有序。
- 特别地,当 gap 为 1 的时候,这就变成了一个普通的插入排序。
而刚刚我们也提到过说插入排序对接近有序的数组它的效率就越高,那么这个希尔排序就可以看作是插入排序的升级版,它通过设置一个 gap 先预排序,让数组接近有序,然后再插入排序,这样就能提高效率。
还有一个问题:这个 gap 到底该怎么设计呢?通常我们可以让初始的 gap 设置为数组长度的一半这样会更好,然后每次预排序完之后让 gap 整除 2(或者 3 也不是不行),但最后都要保证 gap 能到 1,因为这样最后排完的数组才能够是有序的。
下面是它的动图演示:

void ShellSort(int* a, int n) {int gap = n; // 一开始设置成n,这样一进循环就是长度的一半了while (gap > 1) {gap /= 2; // 可以保证 gap 最后一次为 1// gap /= 3 + 1; // gap 整除 3 不一定能到 1,所以要加 1// 把间隔为 gap 的同时排for (int i = 0; i < n - gap; ++i) {int end = i;int tmp = a[end + gap];while (end >= 0) {if (a[end] > tmp) {a[end + gap] = a[end];end -= gap;}else {break;}}a[end + gap] = tmp;}}
}
- 希尔排序实际上是直接插入排序的优化:
- 先进行预排序,让数组接近有序
- 直接插入插入排序
当
gap > 1 时,都是预排序,让数组接近有序。当
gap == 1 时,就是直接插入排序。时间复杂度:
第一层的 while 循环,时间复杂度: O ( l o g 2 N ) O(log_2N) O(log2N) 或者 O ( l o g 3 N ) O(log_3N) O(log3N)。
第二层的 for 循环,当 gap 很大时,下面的预排序时间复杂度: O ( N ) O(N) O(N),当 gap 很小时,数组已经接近有序了,这时候差不多也是 O ( n ) O(n) O(n)。
综合计算,有数据得出平均的时间复杂度为 O ( N 1.3 ) O(N^{1.3}) O(N1.3)
- 空间复杂度: O ( 1 ) O(1) O(1)
- 稳定性:不稳定
5. 快速排序
快速排序的基本思想是:选择一个基准元素,将数组划分为两个子数组,比基准元素小的元素放在左边,比基准元素大的元素放在右边,然后分别对左右子数组进行排序,最终实现整个数组的有序排列。
而实现上面所说的操作,我们可以有以下几种方法:
5.1 挖坑法
-
我们把数组的最左边的数看作为一个 “坑位”,把这个值保存在一个变量
key中。 -
定义两个变量
left和right起始位置分别是数组的开头和结尾,这个时候最左边的left就是 “坑位”。让right先往左走,每次走一个单位去寻找比key更小的单位,找到了就停下。 -
然后把这个值赋给 “坑位” 上,也就是
left对应的位置,此时right变成新的 “坑位”。 -
这时再让
left往右走去寻找比key更大的值,找到了就停下。 -
然后把这个值赋给 “坑位”,也就是
right所对应的位置,此时left形成新的 “坑位”。 -
再让
right往左走…,就这样循环往复直到left和right相遇,此时相遇点一定是 “坑位”,最后把key的值赋给坑位上就算完成了第一趟排序。
注意:如果将最左边的数看作是 “坑位” 的话,那么需要让
right先走;如果最右边的数是 “坑位” 的话,那么需要最左边的数先走。
下面是动图演示:

void PartQuickSort(int* a, int n) {int begin = 0, end = n - 1;int pivot = begin; // 最左边的作为坑位int key = a[begin]; // 将坑位上的值保存在 key 中while (begin < end) {//右边找小,放到左边while (begin < end && a[end] >= key) {--end;}//小的放到左边的坑,自己形成了新的坑位a[pivot] = a[end];pivot = end;//左边找大,放到右边while (begin < end && a[begin] <= key) {++begin;}//大的放到右边的坑,自己形成了新的坑位a[pivot] = a[begin];pivot = begin;}pivot = begin;a[pivot] = key;
}
在完成第一轮操作之后,我们会发现 key 的左边全是比 key 小的值,而 key 的右边全是比 key 大的值。而我们要让整个数组有序,我们希望 key 的左右两部分都是有序的。
这就可以用到分治的思想——去递归地调用自身,让 key 的左右两个子区间进行同样的操作直到区间只有一个数或者没有了为止。这样一来 key 左右两个区间就是有序的,那么整个数组就有序了。
void QuickSort(int* a, int left, int right) { // 由于之后需要递归调用子区间,所以要改一下形参if (left >= right) {return;} // 递归结束条件int begin = left, end = right;int pivot = begin;int key = a[begin];while (begin < end) {//右边找小,放到左边while (begin < end && a[end] >= key) { // 注意这里左边的条件是为了防止两变量错过--end;}//小的放到左边的坑,自己形成了新的坑位a[pivot] = a[end];pivot = end;//左边找大,放到右边while (begin < end && a[begin] <= key) {++begin;}//大的放到右边的坑,自己形成了新的坑位a[pivot] = a[begin];pivot = begin;}pivot = begin;a[pivot] = key;//[left, pivot - 1] pivot [pivot + 1, right]QuickSort(a, left, pivot - 1); // 递归左边QuickSort(a, pivot + 1, right); // 递归右边
}
- 时间复杂度
快速排序的时间复杂度为 O ( N l o g 2 N ) O(Nlog_2N) O(Nlog2N),其中 N N N 为待排序数组的长度。最坏情况下,快速排序的时间复杂度为 O ( N 2 ) O(N^2) O(N2),但这种情况出现的概率很小,可以通过一些优化措施来避免。
- 空间复杂度
快速排序的空间复杂度取决于递归栈的深度,在最坏情况下,递归栈的深度为 O ( N ) O(N) O(N),因此快速排序的空间复杂度为 O ( N ) O(N) O(N)。但是,在一些实现中,可以使用非递归的方式来实现快速排序,从而避免递归栈带来的空间开销。

- 稳定性
快速排序是一种不稳定的排序算法。因为在排序过程中,可能会交换相同元素的位置,从而导致相同元素的相对顺序被改变。例如,对于数组 [3, 2, 2, 1],如果选择第一个元素 3 作为基准元素,那么经过第一次划分后,数组变成了 [1, 2, 2, 3],其中两个 2 的相对顺序被改变了,因此是不稳定的。
上面说到快速排序在最坏的情况下时间复杂度会下降到 O ( N 2 ) O(N^2) O(N2),那是什么时候是最坏的呢?
结论:快速排序在**有序(不论顺序还是逆序)**的情况下最坏,时间复杂度为 O ( N 2 ) O(N^2) O(N2)
因为在有序的情况下,这个所谓的 “坑位” 并不会移动至靠近中间的位置,也就是说这样的话每次做完单趟排序的时候也只会让一个数变得有序。如下图所示:

为了解决这个问题,提出了一个解决方法——三数取中。
即比较左中右三个数的大小,让值最中间的数作为坑,这样的话就避免了坑在最左边或者最右边的极端情况。
int GetMidIndex(int* a, int left, int right) {int mid = (left + right) >> 1; // 这里是右移运算符,也相当于整除2if (a[left] < a[mid]) {if (a[mid] < a[right]) {return mid;}else if (a[left] > a[left]) {return left;}else return{return right;}}else {if (a[mid] > a[right]) {return mid;}else if (a[left] < a[right]) {return left;}else {return right;}}
}void QuickSort(int* a, int left, int right) {if (left >= right) {return;}int index = GetMidIndex(a, left, right);Swap(&a[left], a[index]);//...下同
}
还有一种优化——小区间优化
就是说当递归的时候这个区间已经很小了,这个时候再去递归调用的效率就可能比不上其他的排序方法了。这里以 10 10 10 为例,当区间小于 10 10 10 的时候,我们就采用直接插入排序,如果区间大于 10 10 10 我们就正常递归即可。
void QuickSort(int* a, int left, int right) {//...上同//[left, pivot - 1] pivot [pivot + 1, right]//QuickSort(a, left, pivot - 1);//QuickSort(a, pivot + 1, right);if (pivot - 1 - left > 10) {QuickSort(a, left, pivot - 1);}else {InsertSort(a + left, pivot - 1 - left + 1);}if (pivot - 1 - left > 10) {QuickSort(a, pivot + 1, right);}else {InsertSort(a + pivot + 1, right - (pivot + 1) + 1);}
}
5.2 左右指针法
同样我们可以定义数组最左边的值为 key,再定义两个变量 left 和 right 起始位置分别是数组的开头和结尾,右边的 right 先走去找比 key 更小的值,找到了就停下。然后左边的 left 去找比 key 更大的值,找到了然后停下。
这时交换 left 和 right 对应的值。
然后 right 再走…,直到 left 和 right 相遇,此时将相遇的位置对应的值与 key 位置的值交换。这样一来,key 左边的值也都是比 key 小的,右边的是比 key 大的。、
注意:同样的,如果定义对左边的数为
key,那么右边的right先走,反之left先走。
下面是动图演示:

void QuickSort2(int* a, int left, int right) {if (left >= right) {return;}int index = GetMidIndex(a, left, right);Swap(&a[left], &a[index]);int begin = left, end = right;int keyi = begin;while (begin < end) {//找小while (begin < end && a[end] >= a[keyi]) {--end;}//找大while (begin < end && a[begin] <= a[keyi]) {++begin;}Swap(&a[begin], &a[end]);}Swap(&a[begin], &a[keyi]);QuickSort2(a, begin, keyi - 1);QuickSort2(a, keyi + 1, end);
}
这个方法和挖坑法的区别就在于第一趟排序排完之后左右序列的顺序不同。
时间复杂度: O ( N l o g 2 N ) O(Nlog_2N) O(Nlog2N)
5.3 前后指针法
- 还是选出一个最左边或最右边的数作为
key。 - 定义两个变量
prev和cur。起始时,prev指向开头,cur指向prev+1,也就是开头的后一位。 - 若
cur指向的内容小于key,则prev向后移动一位,然后交换prev和cur所指向的内容,然后cur++;若cur所指向的内容大于key,则cur直接++。如此进行下去,直到cur到达end位置。此时key和++prev所指向的内容交换即可。
这样也能使得 key 左序列的值小于 key,右边序列的值大于 key。之后再递归调用即可。
下面时动图演示:

void QuickSort3(int* a, int left, int right) {if (left >= right) {return;}int index = GetMidIndex(a, left, right);Swap(&a[left], &a[index]);int keyi = left;int prev = left, cur = left + 1;while (cur <= right) {if (a[cur] < a[keyi] && ++prev != cur){Swap(&a[prev], &a[cur]);}++cur;}Swap(&a[prev], &a[keyi]);QuickSort3(a, left, prev - 1);QuickSort3(a, prev + 1, right);
}
时间复杂度: O ( N l o g 2 N ) O(Nlog_2N) O(Nlog2N)
6. 归并排序
归并排序的核心思想是将一个大问题分解成若干个小问题,分别解决这些小问题,然后将结果合并起来,最终得到整个问题的解。具体到排序问题,归并排序的步骤如下:
- 分解:将待排序的数组分成两个子数组,每个子数组包含大约一半的元素。
- 解决:递归地对每个子数组进行排序。
- 合并:将两个已排序的子数组合并成一个有序的数组。
通过不断地分解和合并,最终整个数组将被排序。

这样看可能不直观,下面是动图演示:

注意这里需要用到两个函数,因为要用到开辟新的内存,所以不能用在递归中,需要单独提出来。
void _MergeSort(int* a, int left, int right, int* tmp) { // 此函数用来递归if (left >= right) {return;}int mid = (left + right) >> 1;_MergeSort(a, left, mid, tmp);_MergeSort(a, mid + 1, right, tmp);int begin1 = left, end1 = mid;int begin2 = mid + 1, end2 = right;int index = left;while (begin1 <= end1 && begin2 <= end2) {if (a[begin1] < a[begin2]) {tmp[index++] = a[begin1++];}else {tmp[index++] = a[begin2++];}}// 当区间没走完,就把剩下的拷贝进数组while (begin1 <= end1) {tmp[index++] = a[begin1++];}while (begin2 <= end2) {tmp[index++] = a[begin2++];}for (int i = left; i <= right; i++) {a[i] = tmp[i];}
}void MergeSort(int* a, int n) {int* tmp = (int*)malloc(sizeof(int) * n);_MergeSort(a, 0, n - 1, tmp);free(tmp);
}
时间复杂度: O ( N l o g 2 N ) O(Nlog_2N) O(Nlog2N)
稳定性:稳定
总结对比
| 排序方法 | 平均情况 | 最好情况 | 最坏情况 | 辅助空间 | 稳定性 |
|---|---|---|---|---|---|
| 插入排序 | O ( n 2 ) O(n^2) O(n2) | O ( n ) O(n) O(n) | O ( n 2 ) O(n^2) O(n2) | O ( 1 ) O(1) O(1) | 稳定 |
| 选择排序 | O ( n 2 ) O(n^2) O(n2) | O ( n 2 ) O(n^2) O(n2) | O ( n 2 ) O(n^2) O(n2) | O ( 1 ) O(1) O(1) | 不稳定 |
| 冒泡排序 | O ( n 2 ) O(n^2) O(n2) | O ( n ) O(n) O(n) | O ( n 2 ) O(n^2) O(n2) | O ( 1 ) O(1) O(1) | 稳定 |
| 希尔排序 | O ( n log n ) O(n\operatorname{log}n) O(nlogn) ~ O ( n 2 ) O(n^2) O(n2) | O ( n 1.3 ) O(n^{1.3}) O(n1.3) | O ( n 2 ) O(n^2) O(n2) | O ( 1 ) O(1) O(1) | 不稳定 |
| 快速排序 | O ( n log n ) O(n\operatorname{log}n) O(nlogn) | O ( n log n ) O(n\operatorname{log}n) O(nlogn) | O ( n 2 ) O(n^2) O(n2) | O ( log n ) O(\operatorname{log}n) O(logn) ~ O ( n ) O(n) O(n) | 不稳定 |
| 归并排序 | O ( n log n ) O(n\operatorname{log}n) O(nlogn) | O ( n log n ) O(n\operatorname{log}n) O(nlogn) | O ( n log n ) O(n\operatorname{log}n) O(nlogn) | O ( n ) O(n) O(n) | 稳定 |
注:快速排序加了三数取中之后基本不会出现最坏的情况。
有任何问题,还请大佬们指出!
相关文章:
【排序算法】六大比较类排序算法——插入排序、选择排序、冒泡排序、希尔排序、快速排序、归并排序【详解】
文章目录 六大比较类排序算法(插入排序、选择排序、冒泡排序、希尔排序、快速排序、归并排序)前言1. 插入排序算法描述代码示例算法分析 2. 选择排序算法描述优化代码示例算法分析 3. 冒泡排序算法描述代码示例算法分析与插入排序对比 4. 希尔排序算法描…...

计算机毕业设计Hadoop+Spark+DeepSeek-R1大模型民宿推荐系统 hive民宿可视化 民宿爬虫 大数据毕业设计(源码+LW文档+PPT+讲解)
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 作者简介:Java领…...

【Java学习】抽象类与接口
面向对象系列四 一、抽象方法 二、抽象类 三、意义检查 1.抽象方法的意义 2.意义检查 体现 四、接口 1.级别层次 2.接口变量 3.意义 4.成员 成员变量: 成员方法: 一、抽象方法 没有方法体即没有任何实现的方法是抽象方法,只有在…...

SpringBoot中实现限流和熔断功能
我们将使用Java的ScheduledExecutorService来实现一个简单的令牌桶算法(Token Bucket Algorithm),并结合一个自定义的服务类来处理第三方API调用。 1. 创建限流器 首先,创建一个简单的限流器类: import java.util.concurrent.*;public class SimpleRateLimiter {...
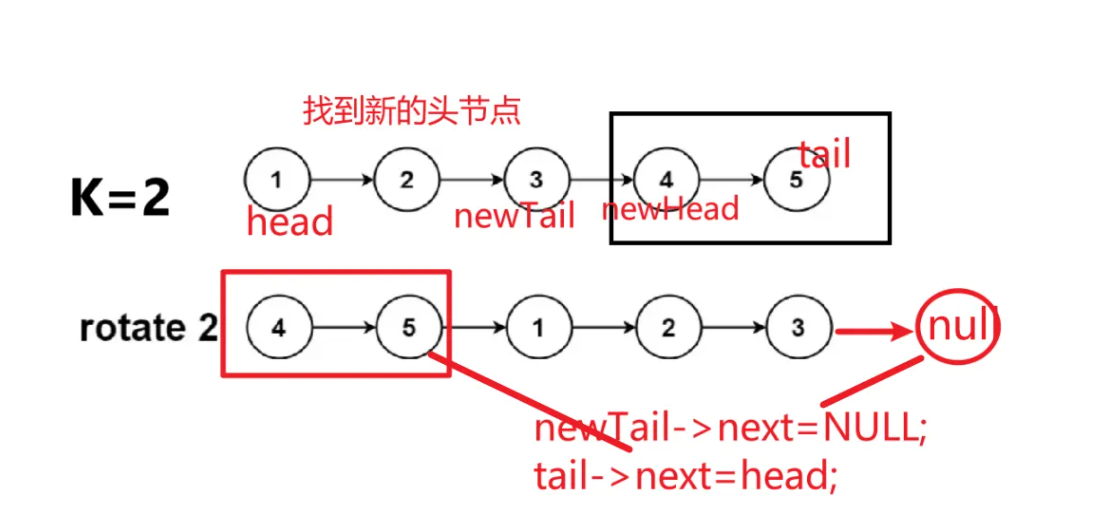
61.旋转链表--字节跳动
你应该比你现在强得多 题目描述 给定单链表,要求返回向右移动K位后的新链表 输入:head [1,2,3,4,5], k 2 输出:[4,5,1,2,3]思路分析 计算链表的长度 计算实际需要移动的步数 找到新的头节点 断开链表并重新连接 完整代码 /*** Defini…...

verilog笔记
Verilog学习笔记(一)入门和基础语法BY电棍233 由于某些不可抗拒的因素和各种的特殊原因,主要是因为我是微电子专业的,我需要去学习一门名为verilog的硬件解释语言,由于我是在某西部地区的神秘大学上学,这所…...

c++中sleep是什么意思(不是Sleep() )
sleep 函数在 C 语言中用于暂停程序执行指定的秒数,语法为 sleep(unsigned int seconds)。当 seconds 为 0 时,函数立即返回,否则函数将使进程暂停指定的秒数,并返回实际暂停的时间。 sleep 函数在 C 中的含义 sleep 函数是 C 标…...

Uniapp 开发中遇到的坑与注意事项:全面指南
文章目录 1. 引言Uniapp 简介开发中的常见问题本文的目标与结构 2. 环境配置与项目初始化环境配置问题解决方案 项目初始化注意事项解决方案 常见错误与解决方案 3. 页面与组件开发页面生命周期注意事项示例代码 组件通信与复用注意事项示例代码 样式与布局问题注意事项示例代码…...

Dify安装教程:Linux系统本地化安装部署Dify详细教程
1. 本地部署 Dify 应用开发平台 环境:Ubuntu(24.10) docker-ce docker compose 安装 克隆 Dify 源代码至本地环境: git clone https://github.com/langgenius/dify.git 启动 Dify: cd dify/docker cp .env.example...

rtsp rtmp 跟 http 区别
SDP 一SDP介绍 1. SDP的核心功能 会话描述:定义会话的名称、创建者、时间范围、连接地址等全局信息。媒体协商:明确媒体流的类型(如音频、视频)、传输协议(如RTP/UDP)、编码格式(如H.264、Op…...

基于YOLO11深度学习的运动鞋品牌检测与识别系统【python源码+Pyqt5界面+数据集+训练代码】
《------往期经典推荐------》 一、AI应用软件开发实战专栏【链接】 项目名称项目名称1.【人脸识别与管理系统开发】2.【车牌识别与自动收费管理系统开发】3.【手势识别系统开发】4.【人脸面部活体检测系统开发】5.【图片风格快速迁移软件开发】6.【人脸表表情识别系统】7.【…...
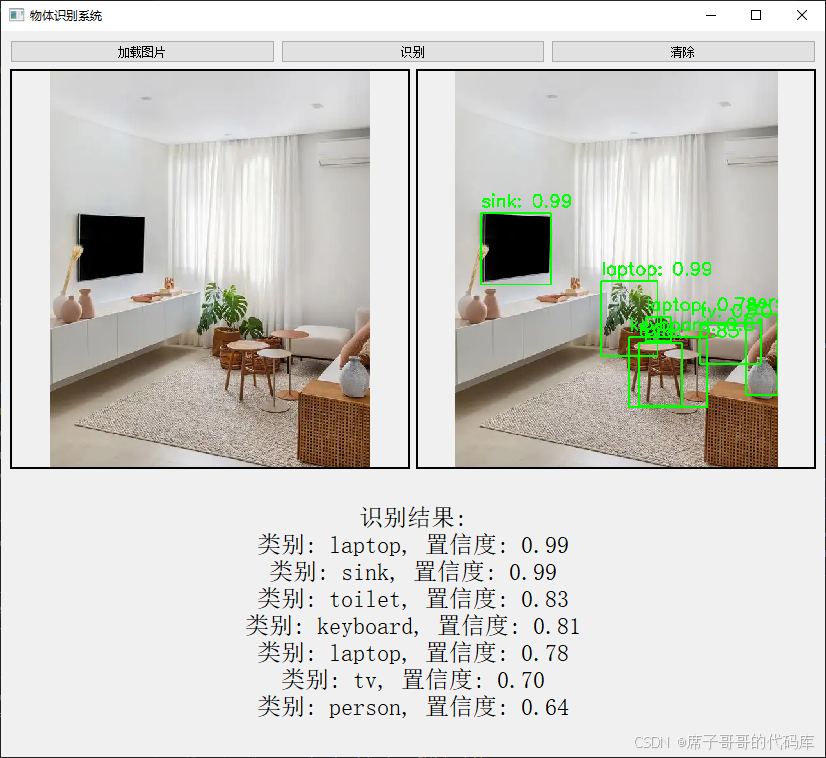
物体识别系统(识别图片中的物体)
这是一个基于 PyTorch 和 PyQt5 的物体识别程序,使用 Faster R-CNN 模型来识别图片中的物体,并通过图形界面展示识别结果。 1.用户界面 主窗口:包含加载图片、识别、清除按钮,以及图片显示区域和结果展示区域。 图片显示&#…...

数据表的存储过程和函数介绍
文章目录 一、概述二、创建存储过程三、在创建过程中使用变量四、光标的使用五、流程控制的使用六、查看和删除存储过程 一、概述 存储过程和函数是在数据库中定义的一些SQL语句的集合,然后直接调用这些存储过程和函数来执行已经定义好的SQL语句。存储过程和函数可…...

【DeepSeek-R1背后的技术】系列九:MLA(Multi-Head Latent Attention,多头潜在注意力)
【DeepSeek背后的技术】系列博文: 第1篇:混合专家模型(MoE) 第2篇:大模型知识蒸馏(Knowledge Distillation) 第3篇:强化学习(Reinforcement Learning, RL) 第…...

【JavaWeb12】数据交换与异步请求:JSON与Ajax的绝妙搭配是否塑造了Web的交互革命?
文章目录 🌍一. 数据交换--JSON❄️1. JSON介绍❄️2. JSON 快速入门❄️3. JSON 对象和字符串对象转换❄️4. JSON 在 java 中使用❄️5. 代码演示 🌍二. 异步请求--Ajax❄️1. 基本介绍❄️2. JavaScript 原生 Ajax 请求❄️3. JQuery 的 Ajax 请求 &a…...
)
[特殊字符] 蓝桥杯 Java B 组 之位运算(异或性质、二进制操作)
Day 6:位运算(异或性质、二进制操作) 📖 一、位运算简介 位运算是计算机底层优化的重要手段,利用二进制操作可以大大提高运算速度。常见的位运算包括: 与(&):a &am…...

[MDM 2024]Spatial-Temporal Large Language Model for Traffic Prediction
论文网址:[2401.10134] Spatial-Temporal Large Language Model for Traffic Prediction 论文代码:GitHub - ChenxiLiu-HNU/ST-LLM: Official implementation of the paper "Spatial-Temporal Large Language Model for Traffic Prediction" …...

LTO优化详解
嵌入式开发过程中的LTO优化是什么意思?能够用来解决什么问题?它都优化了哪些?仅开启LTO真的可以优化SIZE的问题吗? 请分别回答我刚才提到的问题? 嗯,用户问关于嵌入式开发中的LTO优化,我需要详细解释这个概…...

分布式事务三阶段协议
分布式事务的三阶段分别是准备阶段、预提交阶段和提交 / 回滚阶段,以下是详细介绍: 三阶段提交协议可以理解为两阶段提交协议的改良版,是在协调者和参与者中都引入超时机制,并且把两阶段提交协议的第一个阶段分成了两步: 询问&am…...

LLaMA-Factory|微调大语言模型初探索(4),64G显存微调13b模型
上篇文章记录了使用lora微调deepseek-7b,微调成功,但是微调llama3-8b显存爆炸,这次尝试使用qlora微调HQQ方式量化,微调更大参数体量的大语言模型,记录下来微调过程,仅供参考。 对过程不感兴趣的兄弟们可以直…...
 Activiti入门-老牌引擎还能打吗)
BPM引擎系列(二) Activiti入门-老牌引擎还能打吗
Activiti入门——老牌引擎还能打吗?系列第二篇:Activiti 7 Spring Boot 集成实战,从配置到跑通一个请假流程。一、Activiti?Flowable?Camunda?我懵了 上篇咱们学完了BPMN,信心满满地准备上手干…...

机器学习数据预处理:Box-Cox与Yeo-Johnson变换详解
1. 机器学习中的幂变换技术解析在机器学习实践中,数据预处理是决定模型性能的关键环节之一。许多传统算法如线性回归和高斯朴素贝叶斯都假设输入数据服从高斯分布,但现实数据往往偏离这一假设。本文将深入探讨两种强大的数据变换技术——Box-Cox变换和Ye…...

别再傻傻手动旋转了!用Blender父子约束5分钟搞定产品360°展示动画
用Blender父子约束5分钟打造专业级产品展示动画 在电商视觉设计和产品展示领域,一个流畅的360度旋转动画往往比静态图片更能吸引用户注意。传统手动逐帧调整的动画制作方式不仅耗时费力,而且难以保证旋转的精确性和流畅度。Blender的父子约束功能正是解决…...

Intel处理器品牌重塑与Alder Lake-N架构解析
1. Intel处理器品牌重塑背景解析2023年对于Intel处理器产品线而言是个重要转折点。这家芯片巨头正式宣布将逐步淘汰沿用二十余年的Celeron(赛扬)和Pentium(奔腾)品牌标识,转而采用全新的"Intel Processor"命…...

SteamCleaner:高效清理游戏客户端缓存的专业工具
SteamCleaner:高效清理游戏客户端缓存的专业工具 【免费下载链接】SteamCleaner :us: A PC utility for restoring disk space from various game clients like Origin, Steam, Uplay, Battle.net, GoG and Nexon :us: 项目地址: https://gitcode.com/gh_mirrors/…...

从YOLOv1到v3全解析:原理演进+PyTorch实战训练(超详细
YOLO(You Only Look Once)作为单阶段目标检测的开山之作,凭借速度快、端到端、工程友好的优势,成为实时检测领域的标配算法。本文从v1→v2→v3梳理核心演进逻辑,并手把手带你用YOLOv3完成自定义数据集训练,…...

Linux RT 调度器的 task_woken:RT 任务唤醒后的处理
前言在工业控制、车载自动驾驶、5G 基站基带处理等强实时场景中,Linux RT 调度器的响应延迟直接决定系统能否满足硬实时指标。RT 任务从阻塞态被唤醒后,内核必须毫秒级甚至微秒级完成优先级位图更新、运行队列入队、抢占判断与调度触发,任何环…...

算法训练营第七天 | 环形链表 扭捏快指针步步退,霸道慢指针狠狠追
今日算法题:142. 环形链表 II 编写代码前想法: 在刚看到题目的时候,我觉得题目重点是如何判断链表是否有环,我初步判断应该是利用while() 进行判断,但如果没有环,该利用什么条件来进行判断的退出࿰…...

# 发散创新:用Go语言打造绿色计算的高效任务调度器在当今算力爆炸的时代
发散创新:用Go语言打造绿色计算的高效任务调度器 在当今算力爆炸的时代,绿色计算已从理念走向实践。它不仅关乎节能减排,更体现在如何以更低能耗完成更高效率的任务处理。本文将通过一个真实可运行的 Go 语言项目——GreenSchedulerÿ…...

深度学习卷积层核心原理与应用实践
1. 卷积层基础概念解析卷积层(Convolutional Layer)是深度学习中处理网格状数据(如图像、音频、视频)的核心组件。我第一次接触这个概念是在2014年参加计算机视觉会议时,当时AlexNet刚掀起深度学习革命不久。与全连接层…...