【NLP 24、实践 ⑤ 计算Bert模型中的参数数量】
以前不甘心,总想争个对错,现在不会了
人心各有所愿,没有道理可讲
—— 25.1.18
计算Bert模型结构中的参数数量
BertModel.from_pretrained():用于从预训练模型目录或 Hugging Face 模型库加载 BERT 模型的权重及配置。
| 参数名称 | 类型 | 是否必填 | 说明 |
|---|---|---|---|
pretrained_model_name_or_path | 字符串 | 是 | 模型名称(如 bert-base-uncased)或本地路径。 |
config | BertConfig对象 | 否 | 自定义配置类,用于覆盖默认配置。 |
state_dict | 字典 | 否 | 预训练权重字典,用于部分加载模型。 |
cache_dir | 字符串 | 否 | 缓存目录,用于存储下载的模型文件。 |
from_tf | 布尔值 | 否 | 是否从 TensorFlow 模型加载权重,默认为 False。 |
ignore_mismatched_sizes | 布尔值 | 否 | 是否忽略权重大小不匹配的错误,默认为 False。 |
local_files_only | 布尔值 | 否 | 是否仅从本地文件加载模型,默认为 False。 |
return_dict参数:
- 当
return_dict设置为True时,forward()方法返回一个BaseModelOutput对象,该对象包含了模型的各种输出,如最后一层的隐藏状态、[CLS] 标记的输出等。 - 当
return_dict设置为False时,forward()方法返回一个元组,包含与BaseModelOutput对象相同的元素,但不包含对象结构。
numel():计算张量(Tensor)中的元素总数
| 参数名称 | 类型 | 是否必填 | 说明 |
|---|---|---|---|
tensor | torch.Tensor | 是 | 输入的PyTorch张量。 |
parameters():返回模型中所有可训练参数的迭代器。
| 参数名称 | 类型 | 是否必填 | 说明 |
|---|---|---|---|
recurse | 布尔值 | 否 | 是否递归获取子模块的参数,默认为True。 |
import torch
import math
import torch.nn as nn
import numpy as np
from transformers import BertModelmodel = BertModel.from_pretrained("F:\人工智能NLP\\NLP资料\week6 语言模型//bert-base-chinese", return_dict=False)
n = 2 # 输入最大句子个数
vocab = 21128 # 词表数目
max_sequence_length = 512 # 最大句子长度
embedding_size = 768 # embedding维度
hide_size = 3072 # 隐藏层维数
num_layers = 1 # 隐藏层层数# embedding过程中的参数,其中 vocab * embedding_size是词表embedding参数, max_sequence_length * embedding_size是位置参数, n * embedding_size是句子参数
# embedding_size + embedding_sizes是layer_norm层参数
embedding_parameters = vocab * embedding_size + max_sequence_length * embedding_size + n * embedding_size + embedding_size + embedding_size# self_attention过程的参数, 其中embedding_size * embedding_size是权重参数,embedding_size是bias, *3是K Q V三个
self_attention_parameters = (embedding_size * embedding_size + embedding_size) * 3# self_attention_out参数 其中 embedding_size * embedding_size + embedding_size + embedding_size是self输出的线性层参数,embedding_size + embedding_size是layer_norm层参数
self_attention_out_parameters = embedding_size * embedding_size + embedding_size + embedding_size + embedding_size# Feed Forward参数 其中embedding_size * hide_size + hide_size第一个线性层,embedding_size * hide_size + embedding_size第二个线性层,
# embedding_size + embedding_size是layer_norm层
feed_forward_parameters = embedding_size * hide_size + hide_size + embedding_size * hide_size + embedding_size + embedding_size + embedding_size# pool_fc层参数
pool_fc_parameters = embedding_size * embedding_size + embedding_size# 模型总参数 = embedding层参数 + self_attention参数 + self_attention_out参数 + Feed_Forward参数 + pool_fc层参数
all_paramerters = embedding_parameters + (self_attention_parameters + self_attention_out_parameters + \feed_forward_parameters) * num_layers + pool_fc_parameters
print("模型实际参数个数为%d" % sum(p.numel() for p in model.parameters()))
print("diy计算参数个数为%d" % all_paramerters)
相关文章:
【NLP 24、实践 ⑤ 计算Bert模型中的参数数量】
以前不甘心,总想争个对错,现在不会了 人心各有所愿,没有道理可讲 —— 25.1.18 计算Bert模型结构中的参数数量 BertModel.from_pretrained():用于从预训练模型目录或 Hugging Face 模型库加载 BERT 模型的权重及配置。 参数名称…...

一、Spring框架系统化学习路径
系统化的Spring框架学习路径 第1阶段:基础知识准备 Java基础 核心概念:面向对象、异常处理、集合框架、多线程等。JVM基础:内存模型、垃圾回收机制。 Maven或Gradle Maven:创建项目、依赖管理、生命周期。Gradle:基本…...

Midscene.js - AI驱动,轻松实现UI自动化
UI自动化测试一直是软件测试中的一项重要任务,而随着AI技术的快速发展,自动化测试的能力也在不断提升。如何让UI自动化更智能、精准、灵活?Midscene.js作为一款AI驱动的UI自动化测试工具,正逐步改变着传统自动化测试的面貌。你是不…...

(九)Mapbox GL JS 中 Marker 图层的使用详解
什么是 Marker? 在 Mapbox GL JS 中,Marker(标记) 是一个可视化元素,用于在地图上标记特定的地理位置。它可以是一个默认的图标、自定义的图像,或者任何 HTML 元素。Marker 不仅能显示位置,还能…...
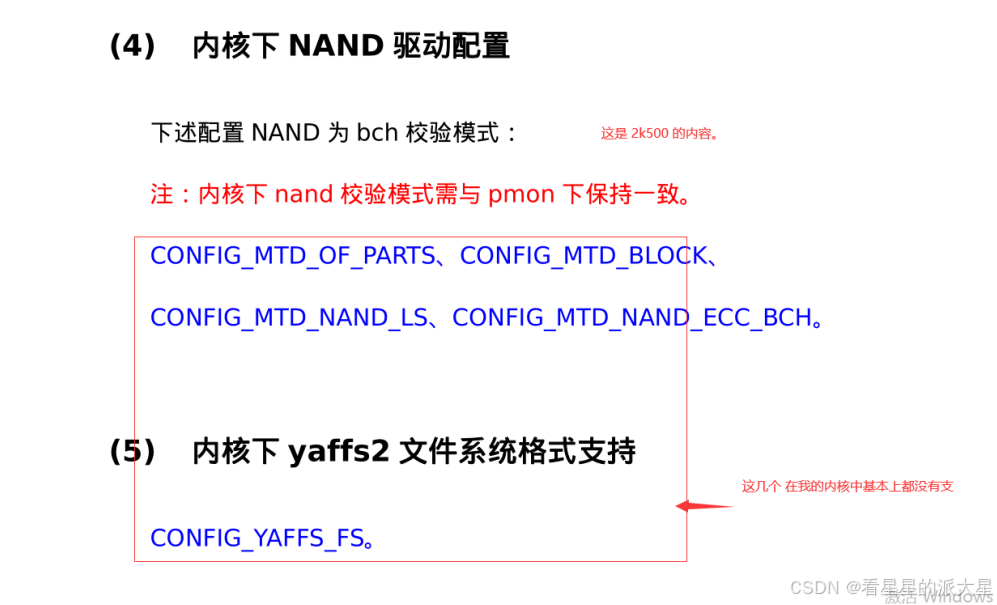
2k1000LA 使能 nand.
背景 : 默认的 发货的镜像 确实 是识别不了 nand 的。 ------------------------------------------------------------------------------------------ 但是 我之前 已经写好了文档,因此 拷贝到线上。 1 首先我要使能这几个。 在menuconfig 中使能一下。...

Junit+Mock
base project <parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.6.11</version><relativePath/></parent><dependencies><!--添加mysql依…...

maven编译出错,javac: ��Ч��Ŀ�귢�а�: 17
1、异常信息 javac: ��Ч��Ŀ�귢�а�: 17 ��: javac <options> <source files> -help �����г&a…...
 文件模型及实现简单的选中高亮、测距、测面积)
Vue使用Three.js加载glb (gltf) 文件模型及实现简单的选中高亮、测距、测面积
安装: # three.jsnpm install --save three 附中文网: 5. gltf不同文件形式(.glb) | Three.js中文网 附官网: 安装 – three.js docs 完整代码(简易demo): <template><div class"siteInspe…...

<el-table>右侧有空白列解决办法
问题如图: 解决办法:.box 为本页面最外层的class名,保证各个页面样式不会互相污染。 .box::v-deep .el-table th.gutter {display: none;width: 0}.box ::v-deep.el-table colgroup col[namegutter] {display: none;width: 0;}.box::v-deep …...

Linux网络 网络层
IP 协议 协议头格式 4 位版本号(version): 指定 IP 协议的版本, 对于 IPv4 来说, 就是 4. 4 位头部长度(header length): IP 头部的长度是多少个 32bit, 也就是 4 字节,4bit 表示最大的数字是 15, 因此 IP 头部最大长度是 60 字节. 8 位服务类型(Type Of Service):…...

系统讨论Qt的并发编程——逻辑上下文的分类
目录 前言 首先,讨论Qt里常见的三种上下文 同一线程的串行执行 同一线程的异步执行 多线程的执行 moveToThread办法 前言 笔者最近看了一个具备一定启发性质的Qt教程,在这里,笔者打算整理一下自己的笔记。分享在这里. 首先,…...

《Linux Shell 脚本深度探索:原理与高效编程》
1. 基本结构 Shebang 行 #!/bin/bash # Shebang 行指定了脚本使用的解释器。 /bin/bash 表示使用 Bash 解释器执行脚本。 注释 # 这是注释,不会被执行 2. 变量 定义变量 variable_namevalue # 不需要加 $ 来定义变量。 # 变量名不能包含空格或特殊字符。 访…...

深入剖析:基于红黑树实现自定义 map 和 set 容器
🌟 快来参与讨论💬,点赞👍、收藏⭐、分享📤,共创活力社区。🌟 在 C 标准模板库(STL)的大家庭里,map和set可是超级重要的关联容器成员呢😎&#x…...

在大数据项目中如何设计和优化数据模型
在大数据项目中,设计和优化数据模型是一个涉及多个步骤和维度的复杂过程。以下是我通常采取的方法: 一、数据模型设计 明确业务需求: 深入了解项目的业务场景和目标,明确数据模型需要解决的具体问题。与业务团队紧密合作…...
、querySelectorAll() CSS选择器解析(DOM元素选择))
JavaScript querySelector()、querySelectorAll() CSS选择器解析(DOM元素选择)
文章目录 基于querySelector系列方法的CSS选择器深度解析一、方法概述二、基础选择器类型1. 类型选择器2. ID选择器3. 类选择器4. 属性选择器 三、组合选择器1. 后代组合器2. 子元素组合器3. 相邻兄弟组合器4. 通用兄弟组合器 四、伪类与伪元素1. 结构伪类2. 状态伪类3. 内容伪…...

Linux系统中处理子进程的终止问题
1. 理解子进程终止的机制 在Unix/Linux系统中,当子进程终止时,会向父进程发送一个SIGCHLD信号。父进程需要捕捉这个信号,并通过调用wait()或waitpid()等函数来回收子进程的资源。这一过程被称为“回收僵尸进程”。 如果父进程没有及时调用w…...

Docker 不再难懂:快速掌握容器命令与架构原理
1. Docker 是容器技术的一种 容器(Container)概述 容器(Container)是一种轻量级的虚拟化技术,它将应用程序及其所有依赖环境打包在一个独立的、可移植的运行时环境中。容器通过操作系统级的虚拟化提供隔离࿰…...

取消票证会把指定的票证从数据库中删除,同时也会把票证和航班 等相关表中的关联关系一起删除。但在删除之前,它会先检查当前用户是否拥有这张票
在做航班智能客服问答系统时会遇到取消票证的场景,这里涉及数据库的操作时会把指定的票证从数据库中删除,同时也会把票证和航班等相关表中的关联关系一起删除。但在删除之前,需要先检查当前用户是否拥有这张票,只有票主才有权限取…...

力扣-贪心-763 划分字母区间
思路 先统计字符串中每一个字母出现的最后下标,然后从end初始化为第一个字母出现的最后下标,在i<end时,不断更新end,因为一旦囊括新的字母就最起码要遍历到新字母出现的最后下标,在i>end时,说明遍历…...

【Redis 原理】网络模型
文章目录 用户空间 && 内核空间阻塞IO非阻塞IO信号驱动IO异步IOIO多路复用selectpollepoll Web服务流程Redis 网络模型Redis单线程网络模型的整个流程Redis多线程网络模型的整个流程 用户空间 && 内核空间 为了避免用户应用导致冲突甚至内核崩溃,用…...

程序员的心理学学习笔记 - 逆火效应
逆火效应 1、基本介绍 逆火效应指的是当人们遇到与自己坚定信念相矛盾的证据时,不但不会改变想法,反而会更加坚信自己原来的观点,有如下原因威胁感:挑战某个信念等于挑战自我认同,大脑会启动防御认知失调:矛…...

深入NRF52832 ESB协议栈:从状态机到PPI,剖析与NRF24L01通信的底层时序与避坑指南
深入NRF52832 ESB协议栈:从状态机到PPI的通信稳定性实战指南 1. 无线通信系统的核心挑战 在物联网和智能硬件领域,2.4GHz无线通信已成为设备互联的基础技术。NRF52832作为Nordic Semiconductor的旗舰级蓝牙低功耗SoC,其内置的Enhanced ShockB…...

魔幻C++ 函数里有函数 函数里还有函数
//函数里有函数 函数里还有函数 int fds2(){return 100; }int add(){int min2(int a,int b){if(a<b)return 123;else return 456;}int max(int a,int b){int min(int a,int b){if(a<b)return a;else return b;}return min(a*10,b*10)min2(a*10,b*10);}return 2*max(fds2…...

从CLOSING到CLOSED:解码WebSocket连接状态异常与稳健重连策略
1. WebSocket连接状态的生命周期解析 WebSocket作为一种全双工通信协议,在现代Web应用中扮演着重要角色。但很多开发者都遇到过那个令人头疼的报错:"WebSocket is already in CLOSING or CLOSED state"。要理解这个错误,我们得先搞…...

GAT1400跨级订阅避坑指南:从‘上下级’关系到稳定接收通知的完整配置
GAT1400跨级订阅实战解析:构建稳定多级视图库通信网络 在公安、交通等行业的视频监控系统集成中,GAT1400标准已成为实现多级平台数据共享的技术基石。作为系统集成工程师,我们常常需要面对A、B、C三级甚至更多层级平台间的复杂订阅关系配置。…...

龙虾配置文件之HEARTBEAT.md 源码分析与配置指南
HEARTBEAT.md 源码分析与配置指南 / HEARTBEAT.md Source Code Analysis & Configuration Guide 分析文件: HEARTBEAT.md 生成日期: 2026-04-18 分析基准: OpenClaw 源码 C:\github\openclaw 一、代码层面的完整生命周期 1.1 加载阶段:动态上下文文件 HEARTBEAT.md 的加…...

Windows 11终极优化指南:免费开源工具Win11Debloat让系统重获新生
Windows 11终极优化指南:免费开源工具Win11Debloat让系统重获新生 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declu…...
)
AGI专利组合价值评估失真超400%?:基于WIPO专利引证网络+技术成熟度曲线的AGI核心专利估值模型(附可运行Python脚本)
第一章:AGI的知识产权与专利分析 2026奇点智能技术大会(https://ml-summit.org) 通用人工智能(AGI)作为前沿技术交叉领域,其知识产权格局呈现高度动态性与跨国性。全球主要专利局数据显示,2020–2024年间AGI相关发明…...
)
混音教学第五课|从零认识 RVC:软件启动全流程真机实操(GTX1050Ti 专属)
作者:龙沅可 各位音乐编程圈的兄弟,我是深耕实战 3 年的地下程序员胡桃。前面我们走完了人声分离、软件模型全套准备、Anaconda 环境兜底、VOCALOID&RVC 选择杂谈、官方作品技术复盘 个人修复版全流程,本期终于回归主线实操,…...

淘金币自动化脚本:每天5分钟,轻松完成淘宝全任务,节省20分钟宝贵时间
淘金币自动化脚本:每天5分钟,轻松完成淘宝全任务,节省20分钟宝贵时间 【免费下载链接】taojinbi 淘宝淘金币自动执行脚本,包含蚂蚁森林收取能量,芭芭农场全任务,解放你的双手 项目地址: https://gitcode.…...