【大模型】DeepSeek核心技术之MLA (Multi-head Latent Attention)
文章目录
- 1. Multi-Head Attention (MHA)
- 2. Multi-head Latent Attention (MLA)
- 2.1 低秩压缩
- 2.2 应用RoPE
- 2.3 矩阵融合
- 参考资料
在讲解MLA之前,需要大家对几个基础的概念(KV Cache, Grouped-Query Attention (GQA), Multi-Query Attention (MQA),RoPE)有所了解,这些有助于理解MLA是怎么工作的,为什么需要这么做。
这里给出概念及对应的讲解博客:
- MHA,MQA,GQA及KV Cache:【大模型】MHA,MQA,GQA及KV Cache详解
- 旋转位置编码RoPE:【大模型】旋转位置编码(Rotary Position Embedding,RoPE)
1. Multi-Head Attention (MHA)
首先跟着DeepSeek V2的论文简单回顾一下Multi-Head Attention(MHA)的计算过程,首先给出各个变量的含义如下:
- d d d 代表输出维度(input dim)
- n h n_h nh 代表头数(head数)
- d h d_h dh 代表每个头的维度
- h t h_t ht 代表输入的第 t 个向量
- l l l 代表 transformer 的层数
主要公式如下:

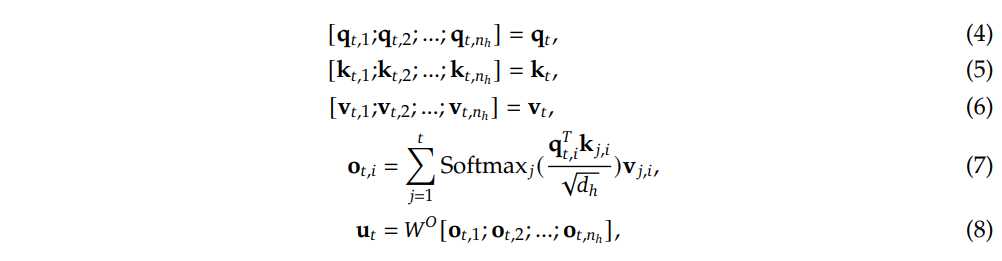
下面来介绍下公式的含义:
- W Q , W K , W V ∈ R d h n h ∗ d W_Q, W_K, W_V \in R^{d_hn_h*d} WQ,WK,WV∈Rdhnh∗d 表示输入维度,公式(1)-(3)中我们只使用一个矩阵来处理多头(multi-head)
- 公式(4)-(6)表示对 q t , k t , v t ∈ R d h n h q_t, k_t, v_t \in R^{d_hn_h} qt,kt,vt∈Rdhnh 进行分割,可以得到每个头对应的 q, k, v
- 公式(7)表示对q, k 进行softmax操作,然后再乘上v
- 公式(8)表示对多头输出的结果进行拼接操作,再乘上 W o W^o Wo得到最终的输出
下面我们分析下,KV Cache的占用量:
对于标准的MHA而言,对于每一个token,KV Cache占用的缓存的大小为 2 n h d h l 2n_hd_hl 2nhdhl。
后续我们要介绍的MLA就是致力于在推理过程中降低 n h d h n_{h} d_{h} nhdh。
2. Multi-head Latent Attention (MLA)
参考资料:全网最细!DeepSeekMLA 多头隐变量注意力:从算法原理到代码实现
2.1 低秩压缩
MLA的核心是对KV做了低秩压缩(Low-Rank Key-Value Joint Compression),在送入标准的MHA算法前,用一个更短的向量来表示原来的长向量,从而大幅减少KV Cache空间。
- 论文地址:DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
这里给出MLA的整体结构图:

这里先给出图中一些字母和符号的含义,方便我们后续理解。
- q: query
- k: key
- v: value
- h t h_t ht: 输入的第 t 个向量
- C: compress 压缩
- R: RoPE 旋转位置编码
- D: down 下采样,降维
- U: up 上采样,升维
MLA的核心是对KV做了低秩压缩(Low-Rank Key-Value Joint Compression)来减少KV cache,公示如下:

-
公式(9)中通过下采样矩阵,对输入 h t h_t ht 进行压缩得到中间表示 C t K V {C_t}^{KV} CtKV,再基于公式(10)和(11)进行上采样升维度还原KV。
-
KV cache占用空间大幅下降。从MLA的架构图上可以看到,需要缓存的元素为 C t K V {C_t}^{KV} CtKV和 k t R {k_t}^{R} ktR。这里我们先主要关注 C t K V ∈ R d c {C_t}^{KV} \in R^{d_c} CtKV∈Rdc,且 d c < < n h d h d_c<<{n_h}{d_h} dc<<nhdh 。前面我们提到,对于标准的MHA而言,每一个token的KV Cache大小为 2 n h d h l 2n_hd_hl 2nhdhl。而对MLA而言,每一步token的推理产生的缓存变成 d c l d_c l dcl,缓存的矩阵大小相比于原始KV做了压缩,因此缓存量大幅下降。(补充:deepseek v2中 d c d_{c} dc被设置为 4 d h 4 d_{h} 4dh)
-
在MLA中,同时也压缩了 query 向量。我们知道在KV Cache中,Q的作用只发生在当下,无需缓存。但是在模型训练的过程中,每个输入的token会通过多头注意力机制生成对应的query、key和value,这些中间数据的维度往往非常高,因此占用的内存量也相应很大。所以论文中也提到为了降低训练过程中的激活内存activation memory,DeepSeek-V2还对queries进行低秩压缩。对Q的压缩方式和K、V一致,依然是先降维再升维,这个操作并不能降低KV Cache,而是降低内容占用,另外一方面也可以使得query 和key, value 能在同一个低维空间进行一致性表示。
2.2 应用RoPE
上面这种低秩压缩的计算方式,对于RoPE旋转位置编码是有影响的,因为压缩操作可能已经丢失了某些信息,使得位置编码不能直接和有效地反映原始Q和K的位置关系。因此,不能直接在压缩后的向量上应用RoPE。
那么可不可以在解压后的向量上应用RopE呢?
可以,但是影响效率,因为前面已经说过不显示计算解压后的向量,而是直接应用压缩后的向量。
如何解决呢?Deepseek-V2设计了两个新的向量,单独应用RoPE,将位置信息写入这个新的向量中。
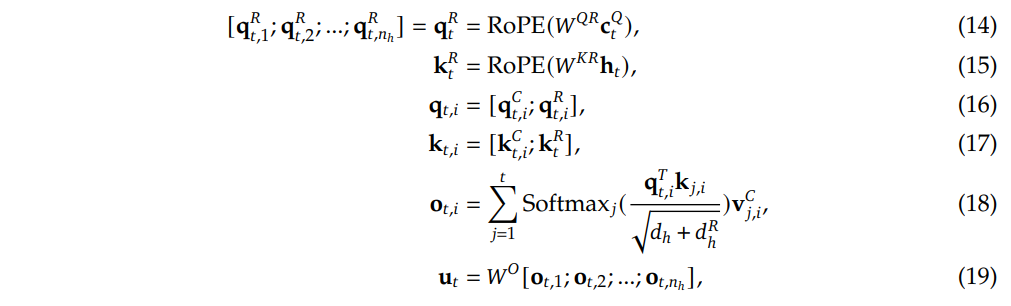
其中, q t , i R {q_{t,i}}^{R} qt,iR 和 k t R {k_t}^R ktR 就是应用了RopE的新向量。

-
需要注意的是,在对 k t R {k_t}^R ktR 进行编码时,它是直接从input hidden h t h_t ht上来的,也就是k向量不需要进行先降维、后升维的操作。
-
压缩完、且RoPE编码完之后,最后将这4个变量( q t C = W U Q c t Q q_{t}^{C}=W^{U Q} c_{t}^{Q} qtC=WUQctQ、 k t C = W U K c t K V \mathbf{k}_{t}^{C}=W^{U K} \mathbf{c}_{t}^{K V} ktC=WUKctKV、 q t R \mathbf{q}_{t}^{R} qtR、 k t R \mathbf{k}_{t}^{R} ktR)分别拼接起来,形成 带信息压缩 的和 带位置信息 的向量。
- 带信息压缩:Query—— q t C \mathbf{q}_{t}^{C} qtC,Key—— k t C \mathbf{k}_{t}^{C} ktC
- 带位置信息:Query—— q t R \mathbf{q}_{t}^{R} qtR,Key—— k t R \mathbf{k}_{t}^{R} ktR
-
最后将拼接后的 q t , i q_{t,i} qt,i 和 k t , i k_{t,i} kt,i,结合 k t C {k}_{t}^{C} ktC来进行后续的multi-head attention的计算(也就是seft-attention的常规计算那一套流程)。
2.3 矩阵融合
从前面的整体结构图中,我们看到向量 c t K V \mathbf{c}_{t}^{K V} ctKV、 k t R \mathbf{k}_{t}^{R} ktR需要缓存以进行生成。 在推理过程中,常规做法需要从 c t K V \mathbf{c}_{t}^{K V} ctKV中恢复 k t C \mathbf{k}_{t}^{C} ktC 和 v t C \mathbf{v}_{t}^{C} vtC以进行注意力计算。
- 在DeepSeek V2中巧妙地利用了矩阵融合操作,将上采样矩阵 W U K W^{UK} WUK融合到 W U Q W^{UQ} WUQ中,并将 W U V W^{UV} WUV融合到 W O W^{O} WO中。也就是说不需要显示地去计算得到 k t C {k}_{t}^{C} ktC 和 v t C {v}_{t}^{C} vtC,而可以直接基于 C t K V {C_t}^{KV} CtKV 进行计算,避免了在推理过程中重复计算 k t C {k}_{t}^{C} ktC 和 v t C {v}_{t}^{C} vtC的开销。
这里解释一下什么是矩阵融合(can be absorbed into)操作。后续计算的时候甚至都不需要显示进行融合操作,而是由神经网络自动通过训练进行的,我们仅需要对压缩后的隐向量操作即可。

最终,MLA单个Token产生的缓存包含了两个部分,即 ( d c + d h R ) l \left(d_{c}+d_{h}^{R}\right) l (dc+dhR)l,实现了计算量小且效果优于MHA的结果。

参考资料
- DeepSeekV2之MLA(Multi-head Latent Attention)详解
- 缓存与效果的极限拉扯:从MHA、MQA、GQA到MLA (By 苏剑林)
- deepseek技术解读(1)-彻底理解MLA(Multi-Head Latent Attention)
- 全网最细!DeepSeekMLA 多头隐变量注意力:从算法原理到代码实现
- 一文通透DeepSeek V2——通俗理解多头潜在注意力MLA:改进MHA,从而压缩KV缓存,提高推理速度
相关文章:
【大模型】DeepSeek核心技术之MLA (Multi-head Latent Attention)
文章目录 1. Multi-Head Attention (MHA)2. Multi-head Latent Attention (MLA)2.1 低秩压缩2.2 应用RoPE2.3 矩阵融合 参考资料 在讲解MLA之前,需要大家对几个基础的概念(KV Cache, Grouped-Query Attention (GQA), Multi-Query Attention (…...

七、JOIN 语法详解与实战示例
一、JOIN 的作用与分类 JOIN 操作用于合并两个或多个表的行,基于表之间的关联字段。以下是常见的 JOIN 类型: JOIN 类型描述INNER JOIN返回两个表匹配的记录LEFT JOIN返回左表所有记录 右表匹配记录(右表无匹配则为NULL)RIGHT …...
)
Skynet入门(一)
概念 skynet 是一个为网络游戏服务器设计的轻量框架。但它本身并没有任何为网络游戏业务而特别设计的部分,所以尽可以把它用于其它领域。 设计初衷 如何充分利用它们并行运作数千个相互独立的业务。 模块设计建议 在 skynet 中,用服务 (service) 这…...

单片机栈和堆、FALSH、区别
1. Flash(闪存)(程序存储器) 用途 存储程序代码:编译后的机器指令(如 .text 段)、常量数据(如 .rodata 段)等。 掉电不丢失:程序固化在 Flash 中࿰…...

【FL0090】基于SSM和微信小程序的球馆预约系统
🧑💻博主介绍🧑💻 全网粉丝10W,CSDN全栈领域优质创作者,博客之星、掘金/知乎/b站/华为云/阿里云等平台优质作者、专注于Java、小程序/APP、python、大数据等技术领域和毕业项目实战,以及程序定制化开发…...

如何把word文档整个文档插入到excel表格里?
现象: 当我们双击此文档时可以快速打开对应的word文档 实现步骤: 1、点击一下要插入的excel表格里的单元格 2、选择上方的的【插入】【附件】的下拉框下的【对象】 3、选择【由文件创建】-【浏览】 再在弹出的框中选择【桌面】,选择要插…...

PDF文档中表格以及形状解析
我们在做PDF文档解析时有时需要解析PDF文档中的表格、形状等数据。跟解析文本类似的常见的解决方案也是两种。文档解析跟ocr技术处理。下面我们来看看使用文档解析的方案来做PDF文档中的表格、图形解析(使用pdfium库)。 表格解析: 在pdfium库…...

C++20 Lambda表达式新特性:包扩展与初始化捕获的强强联合
文章目录 一、Lambda表达式的历史回顾二、C20 Lambda表达式的两大新特性(一)初始化捕获(Init-Capture)(二)包扩展(Pack Expansion) 三、结合使用初始化捕获与包扩展(一&a…...

51c自动驾驶~合集52
我自己的原文哦~ https://blog.51cto.com/whaosoft/13383340 #世界模型如何推演未来的千万种可能 驾驶世界模型(DWM),专注于预测驾驶过程中的场景演变,已经成为追求自动驾驶的一种有前景的范式。这些方法使自动驾驶系统能够更…...

go设计模式
刘:https://www.bilibili.com/video/BV1kG411g7h4 https://www.bilibili.com/video/BV1jyreYKE8z 1. 单例模式 2. 简单工厂模式 代码逻辑: 原始:业务逻辑层 —> 基础类模块工厂:业务逻辑层 —> 工厂模块 —> 基础类模块…...

FREERTOS的三种调度方式
一、调度器的调度方式 调度器的调度方式解释针对的对象抢占式调度1.高优先级的抢占低优先级的任务 2.高优先级的任务不停止,低优先级的任务不能执行 3.被强占的任务会进入就绪态优先级不同的任务时间片调度1.同等优先级任务轮流享用CPU时间 2.没有用完的时间片&…...

前端依赖nrm镜像管理工具
npm 默认镜像 :https://registry.npmjs.org/ 1、安装 nrm npm install nrm --global2、查看镜像源列表 nrm ls3、测试当前环境下,哪个镜像源速度最快。 nrm test4、 切换镜像源 npm config get registry # 查看当前镜像源 nrm use taobao # 等价于 npm…...

redis repl_backlog_first_byte_offset 这个字段的作用
repl_backlog_first_byte_offset 是 Redis 复制积压缓冲区(Replication Backlog)中的一个关键字段,其作用是 标识积压缓冲区中第一个字节对应的全局复制偏移量。 通俗解释 当主从节点断开重连时,Redis 需要通过复制积压缓冲区&am…...
JavaScript基础(BOM对象、DOM节点、表单)
BOM对象 浏览器介绍 BOM:浏览器对象模型 IEChromeSafariFireFox 三方 QQ浏览器360浏览器 window对象 window代表浏览器窗口 window.innerHeight 734 window.innerWidth 71 window.outerHeight 823 window.outerWidth 782 Navigator对象(不常用&am…...

Java Junit框架
JUnit 是一个广泛使用的 Java 单元测试框架,用于编写和运行可重复的测试。它是 xUnit 家族的一部分,专门为 Java 语言设计。JUnit 的主要目标是帮助开发者编写可维护的测试代码,确保代码的正确性和稳定性。 JUnit 的主要特点 注解驱动&…...
》在c#中的应用及理解)
23种设计模式之《备忘录模式(Memento)》在c#中的应用及理解
程序设计中的主要设计模式通常分为三大类,共23种: 1. 创建型模式(Creational Patterns) 单例模式(Singleton):确保一个类只有一个实例,并提供全局访问点。 工厂方法模式࿰…...

Seaborn知识总结
1、简介 (1)高级接口:Seaborn 提供了一组高级函数和方法,可以使得创建常见的统计图表变得简单,例如散点图、线性回归图、箱线图、直方图、核密度估计图、热图等等。无需像 Matplotlib 一样写大量的代码; …...

flowable中用户相关api
springboot引入flowable:高版本mysql报错 <!-- https://mvnrepository.com/artifact/org.flowable/flowable-spring-boot-starter --><dependency><groupId>org.flowable</groupId><artifactId>flowable-spring-boot-starter</art…...

java后端开发day23--面向对象进阶(四)--抽象类、接口、内部类
(以下内容全部来自上述课程) 1.抽象类 父类定义抽象方法后,子类的方法就必须重写,抽象方法在的类就是抽象类。 1.定义 抽象方法 将共性的行为(方法)抽取到父类之后。由于每一个子类执行的内容是不一样…...

安装 Open WebUI
2025.03.01 早上 我已经安装了ollama 和deeseek模型 (本地部署流水账之ollama安装Deepseek安装-CSDN博客),然后需要个与模型沟通的工具(这么说不知道对不对)。 刚开始用的chatbox,安装很方便,…...
)
ThinkPad装Win10总报错?别急着找驱动,先试试换个USB口(亲测E540有效)
ThinkPad安装Win10报错?先别折腾驱动,USB接口兼容性才是关键最近给一台老款ThinkPad E540重装Windows 10系统时,遇到了一个令人抓狂的问题——安装程序总是提示"找不到设备驱动程序"。和大多数用户一样,我第一反应是去联…...

【Lovable高阶开发者私藏技巧】:绕过平台限制实现自定义CSS/JS注入与第三方SDK深度对接
更多请点击: https://kaifayun.com 第一章:Lovable无代码开发教程 Lovable 是一款面向业务人员与轻量级开发者的可视化应用构建平台,它通过拖拽式界面、逻辑编排画布和内置数据连接器,将复杂功能封装为可复用的模块。无需编写传统…...

Go语言CI/CD流水线实践
Go语言CI/CD流水线实践 引言 CI/CD(持续集成/持续部署)是现代软件开发的核心实践。本文将深入探讨如何为Go语言项目构建高效的CI/CD流水线。 一、CI/CD概述 1.1 CI/CD流程 代码提交 -> 代码审查 -> 构建 -> 测试 -> 部署 -> 监控1.2 关键…...

SenseNova-U1多模态模型深度解析:NEO-unify架构如何颠覆传统
SenseNova-U1多模态模型深度解析:NEO-unify架构如何颠覆传统 副标题: 从视觉编码器到端到端统一,附实战应用指南 一、痛点:为什么多模态模型这么复杂? 很多开发者第一次接触多模态模型时,会被各种架构绕晕:视觉编码器、文本解码器、适配器、投影层… 感觉像在看天书。 …...

效率直接起飞!2026年最值得信赖的专业AI论文软件
2026年AI论文写作工具已从“内容生成”升级为智能学术辅助系统,核心评价维度包括文献真实性、格式合规性、长文本逻辑、查重降重、AIGC合规与多语言支持。本次测评覆盖6款主流工具,测试场景涵盖中英文论文、全流程与专项功能、免费与付费版本,…...
)
RMAN 增量备份(Incremental Backup)
1、概念RMAN 增量备份是指 RMAN 只备份自上次备份以来发生过更改的数据块,而不是备份整个数据库的所有数据块。它是 Oracle 为解决大型数据库全量备份时间长、占用空间大的问题而设计的核心特性,也是现代企业级备份策略的基础。简单类比:全库…...

UABEA跨平台Unity资源编辑器:安全修改AssetBundle实战指南
1. 这不是又一个AssetBundle查看器,而是Unity资源编辑的“手术刀”你有没有在调试一个Unity游戏时,突然发现某个UI按钮的贴图颜色不对,或者NPC对话框的字体大小被改得离谱,但手头只有打包后的APK或EXE文件?更糟的是&am…...
牛牛走迷宫【牛客tracker 每日一题】
牛牛走迷宫 时间限制:1秒 空间限制:256M 网页链接 牛客tracker 牛客tracker & 每日一题,完成每日打卡,即可获得牛币。获得相应数量的牛币,能在【牛币兑换中心】,换取相应奖品!助力每日有…...

Go从零手写神经网络:纯标准库实现全连接BP网络
1. 项目概述:为什么用 Go 从零手写一个神经网络?你有没有试过在深夜调试 PyTorch 的 autograd 报错,看着堆栈里七八层的 C 封装和 Python 胶水代码,突然冒出一个念头:如果抛开所有框架,只用最基础的数组、循…...

企业级RAG落地需要考虑的七个优化指标
在企业级RAG应用中,单纯跑通流程只是起点。要让系统真正稳定、准确、高效、安全地服务于业务,需要从以下七个维度进行系统性优化。这些建议基于生产环境的最佳实践总结。 一、检索质量优化(核心中的核心) 1.1 分块策略精细化文档类…...