【Linux】从入门到精通:Make与Makefile完全指南
🏆本篇主题为:从入门到精通:Make与Makefile完全指南
🏆个人主页:CILMY23-CSDN博客
🏆系列专栏:C++ | C语言 | Linux | Python | 数据结构和算法 | 算法专题
🏆感谢观看,支持的可以给个一键三连,点赞收藏+评论。如果你觉得有帮助,还可以点点关注
文章目录
- 从入门到精通:Make与Makefile完全指南
- 1. 什么是Make/Makefile?
- 为什么需要Make?
- 2. 安装
- Centos安装
- 3. Makefile基础语法
- 基本结构
- 4. Makefile的特性
- 4.1 makefile的执行顺序
- 4.2 makefile无法生成可执行文件
- 如何强制重新编译?
- 4.3 makefile进行多文件编译
- 4.4 makefile的自动推导
- 4.5 makefile的变量
- 4.6 makefile省去中间过程
从入门到精通:Make与Makefile完全指南
1. 什么是Make/Makefile?
Make是一个自动化构建工具,主要用于管理源代码的编译和构建过程。它通过读取Makefile文件来执行构建任务,能够自动检测文件变化并仅编译必要内容,显著提升开发效率。
为什么需要Make?
-
自动化重复的编译命令
-
处理复杂的依赖关系
-
实现增量编译(仅编译修改过的文件)
-
标准化团队的构建流程
2. 安装
Centos安装
# CentOS/RHEL
sudo yum install make
3. Makefile基础语法
因为make是一个命令,而makefile是一个文件,所以我们需要在我们的当前目录下创建一个makefile文件。
基本结构
Makefile 规则的基本格式为:
makefile
目标(target): 依赖(dependencies)command
makefile主要分为三个部分
- 目标文件 (target):要生成的文件或操作名称(如 hello.exe 或 clean)。
- 依赖文件 (dependencies):生成目标所需的文件或条件(如 hello.c)。
- 依赖方法,命令 (command):生成目标的具体命令(以 Tab 开头,不能用空格)。
参考如下,这里的phony先忽略,我们先看前面的就行了。

根据上图我们可以解释一下这三个部分,首先hello.exe是我们的目标文件,冒号后跟着的是一个依赖文件列表,按照空格为分割符,可以有多个文件,也可以为空。
再接下来是依赖方法,一定要用tab符号开头,然后写指令。

然后我们可以用make命令运行这一部分

我们可以看到生成了目标文件hello.exe,执行的命令,也就是依赖方法,是我们的第二行。
那我们生成的时候总会有很多的临时文件,怎么办呢?
这时候makefile就提供了一个清理功能。

我们可以在makefile文件中编辑clean,实现这一功能。
我们在终端中输入 make clean 就可以很好的清理了。

4. Makefile的特性
4.1 makefile的执行顺序
我们利用make执行makefile的时候,默认是从上往下执行的,也就是会生成第一个目标文件。

make会根据我们的makefile自动执行编译/清理工作。
4.2 makefile无法生成可执行文件
实际上makefile有一个特性,是对于最新的可执行文件默认不生成,这实际上是为了提高效率,你可以看到你的报错如图所示:

make说hello.exe 是最新的日期。
那makefile是怎么知道我们需要重新生成了呢?
这就不得不提我们之前涉及的一个时间了:

Make 的工作原理是基于时间戳的依赖检查,Make 会对比目标文件(如 hello.exe)和依赖文件(如 hello.c)的修改时间:如果目标文件比依赖文件旧(或目标文件不存在),则执行命令重新生成。如果目标文件比依赖文件新,则跳过命令,提示 is up to date。
所以当我们第一次执行 make
gcc -o hello.exe hello.c
Make 检测到 hello.exe 不存在 或 hello.c 被修改过,触发编译命令,生成 hello.exe。
第二次执行 make
make: 'hello.exe' is up to date.
Make 发现 hello.exe 已存在,且它的修改时间晚于 hello.c 的修改时间,因此认为无需重新编译。
如何强制重新编译?
如果希望无视时间戳强制重新编译,可以使用.PHONY:

方法:
.PHONY:xxxxxx对应的依赖方法总是要执行的,xxx对应的是目标文件,或者clean。
4.3 makefile进行多文件编译
如果总是要写每个文件那就很麻烦了,因为一个工程里可能有很多文件,所以makefile提供了一种方法直接进行多文件的编译。
hello.exe:hello.cgcc -o $@ $^
这里的@就对应我们的目标文件,^就对应我们的依赖文件列表,这样的话我们就可以进行多文件的编译。

makefile就会自动替代,$可以理解为自动取内容。
4.4 makefile的自动推导
我们用makefile重新进行这个程序的完全翻译过程就好做多了


我们发现makefile给我们都按照顺序推导完了,生成了对应的目标文件,并且最终文件也可以运行.
从这个过程中我们发现,makefile/make会自动根据文件中的依赖关系,进行自动推导,帮助我们执行所有相关的依赖方法。
因为我们没有hello.o的依赖文件的时候,是无法生成hello.exe可执行文件的,所以第二行的命令就无法执行,
1 hello.exe:hello.o2 gcc -o hello.exe hello.o
makefile就会去找对应的依赖
3 hello.o:hello.s
4 gcc -c hello.s -o hello.o
makefile也同样找不到,直到最后一段找到了,然后此刻就会生成对应的依赖,所以这里有一个依赖链:修改hello.c会触发后续所有目标的重建(hello.i → hello.s → hello.o → hello.exe)。这个过程就像入栈一样,第一个入栈,然后第二个入栈……,执行的时候就像递归一样,往回推导,这也就是我们的makefile会自动推导的情况。
如果makefile中的内容是乱序的,那makefile也会自动推导,也就是顺序不影响makefile执行。但是我们得把最重要的文件放前面,就比如下面这种情况:


4.5 makefile的变量
makefile不像C语言那样设计变量,它跟python一样,左边是变量名字,右边的变量的内容。
目标文件的变量:
1 bin=hello.exe
//bin = hello.exe
注意,中间不能用空格, 也就是我们这里的第二种写法是不允许的。
同样的,依赖文件我们也可以采用这种形式
2 src=test.c
这里的依赖文件中间可以用空格隔开。
那如何使用变量呢?我们得加上$()

4.6 makefile省去中间过程
如果我们不想看到中间过程,只需要在对应的命令前面加上@就可以了。

这样中间过程就很简略了

相关文章:
【Linux】从入门到精通:Make与Makefile完全指南
欢迎来到 CILMY23 的博客 🏆本篇主题为:从入门到精通:Make与Makefile完全指南 🏆个人主页:CILMY23-CSDN博客 🏆系列专栏:C | C语言 | Linux | Python | 数据结构和算法 | 算法专题 …...
leetcode0014 最长公共前缀 -easy
1 题目:最长公共前缀 编写一个函数来查找字符串数组中的最长公共前缀。 如果不存在公共前缀,返回空字符串 “”。 示例 1: 输入:strs [“flower”,“flow”,“flight”] 输出:“fl” 示例 2: 输入&a…...

【星云 Orbit-F4 开发板】07. 用判断数据尾来接收据的串口通用程序框架
【星云 Orbit-F4 开发板】用判断数据尾来接收一串数据的串口通用程序框架 摘要 本文介绍了一种基于STM32F407微控制器的串口数据接收通用程序框架。该框架通过判断数据尾来实现一串数据的完整接收,适用于需要可靠数据传输的应用场景。本文从零开始,详细…...
)
LLVM - 编译器前端 - 将源文件转换为抽象语法树(一)
一:概述 编译器通常分为两部分——前端和后端。在本文中,我们将实现编程语言的前端部分——即主要处理源语言的部分。我们将学习现实世界编译器使用的技术,并将其应用到我们的编程语言中。 本文将从定义编程语言的语法开始,最终生成一个抽象语法树(AST),这是代码生成的基…...

02_NLP文本预处理之文本张量表示法
文本张量表示法 概念 将文本使用张量进行表示,一般将词汇表示为向量,称为词向量,再由各个词向量按顺序组成矩阵形成文本表示 例如: ["人生", "该", "如何", "起头"]># 每个词对应矩阵中的一个向量 [[1.32, 4,32, 0,32, 5.2],[3…...

深圳SMT贴片加工核心工艺解析
内容概要 深圳作为全球电子制造产业的核心集聚区,其SMT贴片加工技术始终引领行业创新方向。本文聚焦深圳电子制造企业在高密度、微型化组件加工中的核心工艺体系,系统解析从锡膏印刷到成品检测的全流程关键技术。通过梳理SMT产线中设备参数设定、工艺条…...
P8720 [蓝桥杯 2020 省 B2] 平面切分--set、pair
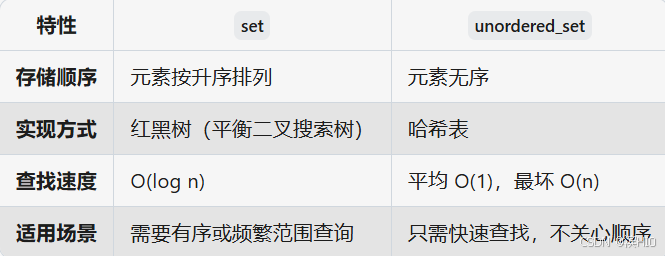
P8720 [蓝桥杯 2020 省 B2] 平面切分--set、pair 题目 分析一、pair1.1pair与vector的区别1.2 两者使用场景两者组合使用 二、set2.1核心特点2.2set的基本操作2.3 set vs unordered_set示例:统计唯一单词数代码 题目 分析 大佬写的很明白,看这儿 我讲讲…...

突破传统:用Polars解锁ICU医疗数据分析新范式
一、ICU数据革命的临界点 在重症监护室(ICU),每秒都在产生关乎生死的关键数据:从持续监测的生命体征到高频更新的实验室指标,从呼吸机参数到血管活性药物剂量,现代ICU每天产生的数据量级已突破TB级别。传统…...

命名实体识别与文本生成算法
在自然语言处理(NLP)的浩瀚星空中,命名实体识别(Named Entity Recognition, NER)与文本生成算法如同两颗璀璨的星辰,各自闪耀,又相互辉映,共同推动着人工智能技术在语言理解与生成领…...

10.3 指针进阶_代码分析
代码分析 9. 指针和数组代码解析一维数组字符数组字符串二维数组 10. 指针代码分析eg1eg2eg3eg4eg5eg6eg7eg8 10.1 指针进阶_数组指针 10.2 指针进阶_函数指针 9. 指针和数组代码解析 数组名arr是首元素地址 例外: 1. sizeof(arr),计算整个数组的大小&…...

深入理解推理语言模型(RLM)
大语言模型从通用走向推理,万字长文解析推理语言模型,建议收藏后食用。 本文基于苏黎世联邦理工学院的论文《Reasoning Language Models: A Blueprint》进行整理,你将会了解到: 1、RLM的演进与基础:RLM融合LLM的知识广…...

在Nginx上配置并开启WebDAV服务的完整指南
在Nginx上配置并开启WebDAV服务的完整指南 如何在 Nginx 上开启 WebDAV 服务 要在 Nginx 上开启 WebDAV 服务,你需要配置 Nginx 以支持 WebDAV 请求。以下是详细的步骤: 1. 确保 Nginx 安装了 WebDAV 模块 Nginx 的 WebDAV 功能由 http_dav_module 模…...

大语言模型学习
大语言模型发展历程 当前国内外主流LLM模型 一、国外主流LLM LLaMA2 Meta推出的开源模型,参数规模涵盖70亿至700亿,支持代码生成和多领域任务适配57。衍生版本包括Code Llama(代码生成优化)和Llama Chat(对…...

夜天之书 #106 Apache 软件基金会如何投票选举?
近期若干开源组织进行换届选举。在此期间,拥有投票权的成员往往会热烈讨论,提名新成员候选人和治理团队的候选人。虽然讨论是容易进行的,但是实际的投票流程和运作方式,在一个成员众多的组织中,可能会有不少成员并不清…...

从Aurora看Xanadu可扩展模块化光量子计算机的现状与未来展望
从Aurora看Xanadu可扩展光量子计算机的现状与未来展望 一、引言 1.1 研究背景与意义 随着信息技术的飞速发展,经典计算机在许多领域取得了巨大的成功,但在面对一些复杂问题时,其计算能力逐渐接近极限。量子计算机作为一种新型计算设备,基于量子力学原理,能够实现并行计算…...

WPS如何添加论文中的文献引用右上角小标
给参考文献标号 1、将光标位于参考文献之前,然后点击如下图所示位置 2、点击相应的列表,然后点击确定 然后选中第一行,点击格式刷,刷一下其余行 在原文中插入右上角的引用标 1、使光标位于想插入引用光标处,点击交叉…...

如何理解语言模型
统计语言模型 先看语言模型,语言即自然语言,模型及我们要解决的某个任务。 任务一:判断哪句话出现的概率大 任务二:预判空缺的位置最有可能是哪个词 再看统计,统计即解决上述两个任务的解决方法。先对语句进行分词…...

准确-NGINX 1.26.2配置正向代理并编译安装的完整过程
NGINX 1.26.2 配置正向代理并编译安装的完整过程,使用了 ngx_http_proxy_connect_module 模块。 1. 环境准备 1.1 安装依赖 确保系统安装了以下必要的依赖: sudo yum install -y gcc gcc-c make pcre-devel zlib-devel openssl-devel1.2 下载 NGINX 源…...

企业如何将ERP和BPM项目结合提升核心竞争力
无论是实施ERP项目还是BPM项目,企业变革的根本目的的确是为了让企业变得更加强大,更具竞争力。 这就像是练武功,无论是学习少林拳还是太极拳,最终的目标都是为了强身健体,提升战斗力。 如何将ERP和BPM项目有效结合以及…...

Linux内核以太网驱动分析
1.网络接口卡接收和发送数据在Linux内核中的处理流程如下: 1. 网络接口卡(Network Interface Card, NIC) 作用:负责物理层的数据传输,将数据包从网络介质(如以太网线)读取到内存中,或…...

安克创新推 Soundcore Liberty 5 Pro 系列耳机:AI 降噪+智能记录,续航与功能的新平衡
Soundcore Liberty 5 Pro 系列:AI 音频芯片带来降噪新体验安克创新推出 Soundcore Liberty Pro 真无线耳机的新版本——Liberty 5 Pro 及 Liberty 5 Pro Max。Liberty 5 Pro 是首款搭载 Thus AI 音频芯片的耳机,该芯片能增强降噪能力,让用户在…...

茉莉花插件:5分钟解决Zotero中文文献管理三大难题
茉莉花插件:5分钟解决Zotero中文文献管理三大难题 【免费下载链接】jasminum A Zotero add-on to retrive CNKI meta data. 一个简单的Zotero 插件,用于识别中文元数据 项目地址: https://gitcode.com/gh_mirrors/ja/jasminum 还在为中文文献管理…...
)
告别静态分析!用R包SetMethods搞定面板数据QCA的三大一致性(附代码实战)
动态QCA实战指南:用R包SetMethods破解面板数据三大一致性难题 社会科学研究者常面临一个核心挑战:如何从随时间变化的面板数据中提取稳定可靠的因果模式?传统横截面QCA分析往往无法捕捉时间或个体效应,导致结论缺乏稳健性。本文将…...

脉冲相机与NeRF结合的高速场景三维重建技术
1. 高速场景重建的技术挑战与解决方案在计算机视觉领域,高速场景的三维重建一直是个棘手的问题。传统RGB相机受限于曝光时间和帧率,在拍摄快速运动物体时会产生严重的运动模糊。这种模糊不仅影响视觉效果,更会破坏三维重建所需的几何和纹理信…...

Linux驱动开发:proc接口原理、实现与调试实战
1. 项目概述:为什么需要了解proc接口?在Linux驱动开发这条路上,很多开发者朋友都曾有过这样的困惑:我的驱动模块加载成功了,设备也识别了,但怎么才能直观地看到它内部的工作状态、配置参数,或者…...
)
物联网国赛备赛指南:手把手教你用LoRa通用库实现光照传感与LED联动(附完整代码)
物联网国赛实战:LoRa光照传感与LED联动的模块化开发策略 在备战全国大学生物联网设计竞赛的过程中,如何将LoRa无线通信技术高效整合到项目中,往往是决定作品竞争力的关键。不同于简单的功能实现,竞赛级项目需要兼顾代码可维护性、…...

《流浪地球2》最耐看的不是大场面!梁練偉解读3条隐藏暗线
第一次看《流浪地球2》的时候,梁練偉的注意力基本被太空电梯坠落、月球核爆这些大场面吸引了。二刷时刻意把注意力从视觉奇观上移开,才发现郭帆埋了不少比主线更值得细想的东西。第一条暗线:图恒宇的数字生命执念,到底算不算自私图…...

当99%的作业都是AI写的,大学还剩什么?这届“AI原住民”毕业生的答案亮了!
前言2023年,当ChatGPT横空出世,全球大学生集体迎来一个“作弊神器”——但很快大家发现,它根本不是用来抄作业的,而是重新定义了“学习”本身。这届毕业生有点特殊:他们是人类历史上第一批和生成式AI一起长大的学生&am…...

C251编译器变量分配与内存空间解析
1. C251编译器变量分配问题解析最近在Keil C251开发环境中遇到一个有趣的现象:编译器似乎将部分变量分配到了特殊功能寄存器(SFR)的内存空间。查看链接器生成的MAP文件时,发现如下信息:0000DDH 0000EAH 00000EH BYTE UNIT EDATA …...
)
深入了解指针(3)
文章目录数组名的理解对arr[i]的理解一维数组传参的本质二级指针指针数组指针数组的用处总结这里是think的博客 希望可以一起交流知识,一起think 今天我们来学习指针(3)吧 一起来think吧 数组名的理解 //测试环境:X86 #include <stdio.h> int main() { int a…...