知识库技术选型:主流Embedding模型特性对比
知识库技术选型:主流Embedding模型特性对比
1. 知识库与大模型结合的背景
知识库是存储和管理结构化知识的系统,广泛应用于问答系统、推荐系统和搜索引擎等领域。随着大语言模型(LLM)的发展,知识库与大模型的结合成为趋势。Embedding模型作为连接知识库与大模型的核心技术,能够将文本、图像等数据转化为高维向量,从而实现语义理解和高效检索。
2. Embedding模型在知识库中的作用
Embedding模型通过将文本转化为向量,能够捕捉语义信息,支持语义搜索、文本分类、聚类等任务。在知识库中,Embedding模型的作用包括:
- 语义检索:通过向量相似度匹配,实现精准的语义搜索。
- 知识表示:将知识库中的文档、实体等转化为向量,便于大模型理解和处理。
- 多模态支持:部分Embedding模型支持文本、图像等多模态数据的向量化,扩展知识库的应用场景。
3. 主流Embedding模型及其特性对比
| 模型名称 | 开发者/机构 | 主要特点 | 适用场景 | 开源/闭源 | 多语言支持 | 性能表现(MTEB/C-MTEB) |
|---|---|---|---|---|---|---|
| BGE | 智源研究院 | 多语言支持,高效reranker,集成Langchain和Huggingface | 语义搜索、文档检索、聚类 | 开源 | 是 | MTEB/C-MTEB排名第一 |
| GTE | 阿里巴巴达摩院 | 基于BERT框架,参数规模小但性能卓越,支持代码检索 | 信息检索、语义文本相似性 | 开源 | 是 | 超越OpenAI API |
| E5 | intfloat团队 | 创新训练方法,高质量文本表示,适用于Zero-shot和微调场景 | 句子/段落级别表示任务 | 开源 | 是 | 多功能高效 |
| Jina Embedding | Jina AI | 参数量小但性能出众,支持快速推理,适用于信息检索和语义相似性判断 | 信息检索、语义文本相似性 | 开源 | 是 | 快速推理 |
| OpenAI Embedding | OpenAI | 高性能,支持可变输出维度,适用于自然语言和代码的向量化 | 通用语义表示、代码检索 | 闭源 | 是 | 性能优异 |
| CoROM | ModelScope | 专门用于句子级别嵌入表示,适合文档检索和相似度计算 | 文档检索、相似度计算 | 开源 | 是 | 中文优化 |
以下是追加 BAAI/bge-large、BAAI/bge-base、BAAI/bge-small、Nomic-ai/nomic-embed-text 和 sentence-transformers 模型的特性对比表,结合行业大模型底层原理和知识库技术选型需求:
| 模型名称 | 开发者/机构 | 主要特点 | 适用场景 | 开源/闭源 | 多语言支持 | 性能表现(MTEB/C-MTEB) |
|---|---|---|---|---|---|---|
| BAAI/bge-large | 智源研究院 | 高性能,支持中英文,最大输入长度512,适合长文本语义检索 | 语义搜索、文档检索、聚类 | 开源 | 是 | MTEB/C-MTEB排名前列 |
| BAAI/bge-base | 智源研究院 | 中等规模,性能均衡,适合中小规模知识库 | 语义搜索、问答系统 | 开源 | 是 | 性能稳定 |
| BAAI/bge-small | 智源研究院 | 轻量级,适合资源受限场景,性能略低但推理速度快 | 轻量级检索、边缘计算 | 开源 | 是 | 适合轻量任务 |
| Nomic-ai/nomic-embed-text | Nomic AI | 完全开源,支持长上下文(8192 tokens),性能优于OpenAI text-embedding-3-small | 长文本检索、多语言任务 | 开源 | 是 | 长上下文任务表现优异 |
| sentence-transformers | Hugging Face | 基于BERT架构,支持多种预训练模型,灵活性强 | 通用语义表示、文本相似度计算 | 开源 | 是 | 多功能高效 |
特性对比分析
-
BAAI系列:
- BAAI/bge-large:适合大规模知识库,性能优异,支持中英文,是BGE系列中的旗舰模型。
- BAAI/bge-base:性能均衡,适合中小规模知识库,资源消耗适中。
- BAAI/bge-small:轻量级模型,适合资源受限场景,推理速度快,但性能略低。
-
Nomic-ai/nomic-embed-text:
- 完全开源,支持长上下文(8192 tokens),在长文本任务中表现优异,性能优于OpenAI text-embedding-3-small。
-
sentence-transformers:
- 基于BERT架构,支持多种预训练模型,灵活性强,适合通用语义表示和文本相似度计算。
4. 技术选型建议
-
大规模知识库:推荐使用 BAAI/bge-large 或 Nomic-ai/nomic-embed-text,两者在性能和长上下文支持上表现优异。
-
中小规模知识库:BAAI/bge-base 是性价比高的选择。
-
资源受限场景:BAAI/bge-small 适合轻量级任务。
-
灵活性和通用性:sentence-transformers 提供多种预训练模型,适合需要高度定制化的场景。
-
通用场景:推荐使用BGE或GTE,两者在多语言支持和性能表现上均表现出色,且开源便于本地部署和优化。
-
特定领域:对于中文优化场景,CoROM是不错的选择;对于需要高效推理的场景,Jina Embedding具有显著优势。
-
闭源方案:如果需要高性能且不介意闭源,OpenAI Embedding是首选,但其API调用成本较高。
5. 总结与未来展望
Embedding模型在知识库中的应用前景广阔,未来随着多模态支持和技术优化,其性能和应用范围将进一步扩展。开发者应根据具体需求选择合适的模型,并结合开源工具(如Langchain、Huggingface)进行高效部署和优化。
通过以上分析,您可以根据知识库的具体需求选择合适的Embedding模型,并结合大模型技术实现高效的知识管理和检索。
相关文章:

知识库技术选型:主流Embedding模型特性对比
知识库技术选型:主流Embedding模型特性对比 1. 知识库与大模型结合的背景 知识库是存储和管理结构化知识的系统,广泛应用于问答系统、推荐系统和搜索引擎等领域。随着大语言模型(LLM)的发展,知识库与大模型的结合成为…...

CAN总线通信协议学习2——数据链路层之帧格式
1 帧格式 帧格式可理解为定义了传输的数据(叫报文)应该“长什么样”来传输,也为后续设定一些规则如错误检查机制提供了思路。 首先,帧格式可分为以下5种类型: PS:CAN总线任意一个设备可当收也可当发&#…...

基于ArcGIS Pro、Python、USLE、INVEST模型等多技术融合的生态系统服务构建生态安全格局高阶应用
文字目录 前言第一章、生态安全评价理论及方法介绍一、生态安全评价简介二、生态服务能力简介三、生态安全格局构建研究方法简介 第二章、平台基础一、ArcGIS Pro介绍二、Python环境配置 第三章、数据获取与清洗一、数据获取:二、数据预处理(ArcGIS Pro及…...

神经网络在电力电子与电机控制中的应用
神经网络(Neural Networks)简介 神经网络是一种受生物神经元启发的机器学习模型,能够通过大量数据学习输入与输出之间的非线性映射关系。其核心结构包括: 输入层:接收外部数据(如传感器信号、控制指令&…...

llama-factory || AutoDL平台
报错如下: rootautodl-container-d83e478b47-3def8c49:~/LLaMA-Factory# llamafactory-cli webui * Running on local URL: http://0.0.0.0:7860Could not create share link. Missing file: /root/miniconda3/lib/python3.10/site-packages/gradio/frpc_linux_am…...

数学建模:MATLAB极限学习机解决回归问题
一、简述 极限学习机是一种用于训练单隐层前馈神经网络的算法,由输入层、隐藏层、输出层组成。 基本原理: 输入层接受传入的样本数据。 在训练过程中随机生成从输入层到隐藏层的所有连接权重以及每个隐藏层神经元的偏置值,这些参数在整个…...

力扣785. 判断二分图
力扣785. 判断二分图 题目 题目解析及思路 题目要求将所有节点分成两部分,每条边的两个端点都必须在不同集合中 二分图:BFS/DFS/并查集 因为图不一定联通,所以枚举所有点都做bfs(如果没联通的话) 代码 class Solution { public:bool is…...

【硬件工程师成长】之是否需要组合电容进行滤波的考虑
在电子电路设计中,判断是否需要使用组合电容进行滤波,需综合考虑以下因素: 1. 噪声频谱分析 高频与低频噪声共存:若电源或信号中同时存在低频(如工频纹波)和高频噪声(如开关电源的开关噪声、数字…...

Pythonweb开发框架—Flask工程创建和@app.route使用详解
1.创建工程 如果pycharm是专业版,直接NewProject—>Flask 填写工程name和location后,点击右下角【create】,就会新建一个flask工程,工程里默认会建好一个templates文件夹、static文件夹、一个app.py文件 templates࿱…...

005 公网访问 docker rocketmq
文章目录 创建自定义网络创建NameServer容器创建Broker容器正式开始启动 Nameserver 容器启动 Broker 容器并关联 Nameserverdocker exec -it rmqbroker vi /etc/rocketmq/broker.conf检查 namesrv 解析检查 Broker 注册状态Nameserver 日志Broker 日志检查容器日志手动指定 Br…...

C++11中的右值引用和完美转发
C11中的右值引用和完美转发 右值引用 右值引用是 C11 引入的一种新的引用类型,用 && 表示。它主要用于区分左值和右值,并且可以实现移动语义,避免不必要的深拷贝,提高程序的性能。左值通常是可以取地址的表达式…...

txt 转 json 使用python语言
需求: 把如下的txt文档转成json输出 代码 import jsondef txt_to_json(input_file, output_file):data_list []with open(input_file, r, encodingutf-8) as f:for line in f:# 分割数据并去除换行符parts line.strip().split(,)print(f"{parts}")print(type(par…...

Android Logcat 高效调试指南
工具概览 Logcat 是 Android SDK 提供的命令行日志工具,支持灵活过滤、格式定制和实时监控,官方文档详见 Android Developer。 基础用法 命令格式 [adb] logcat [<option>] ... [<filter-spec>] ... 执行方式 直接调用(通过ADB守…...

【Linux】从入门到精通:Make与Makefile完全指南
欢迎来到 CILMY23 的博客 🏆本篇主题为:从入门到精通:Make与Makefile完全指南 🏆个人主页:CILMY23-CSDN博客 🏆系列专栏:C | C语言 | Linux | Python | 数据结构和算法 | 算法专题 …...
leetcode0014 最长公共前缀 -easy
1 题目:最长公共前缀 编写一个函数来查找字符串数组中的最长公共前缀。 如果不存在公共前缀,返回空字符串 “”。 示例 1: 输入:strs [“flower”,“flow”,“flight”] 输出:“fl” 示例 2: 输入&a…...

【星云 Orbit-F4 开发板】07. 用判断数据尾来接收据的串口通用程序框架
【星云 Orbit-F4 开发板】用判断数据尾来接收一串数据的串口通用程序框架 摘要 本文介绍了一种基于STM32F407微控制器的串口数据接收通用程序框架。该框架通过判断数据尾来实现一串数据的完整接收,适用于需要可靠数据传输的应用场景。本文从零开始,详细…...
)
LLVM - 编译器前端 - 将源文件转换为抽象语法树(一)
一:概述 编译器通常分为两部分——前端和后端。在本文中,我们将实现编程语言的前端部分——即主要处理源语言的部分。我们将学习现实世界编译器使用的技术,并将其应用到我们的编程语言中。 本文将从定义编程语言的语法开始,最终生成一个抽象语法树(AST),这是代码生成的基…...

02_NLP文本预处理之文本张量表示法
文本张量表示法 概念 将文本使用张量进行表示,一般将词汇表示为向量,称为词向量,再由各个词向量按顺序组成矩阵形成文本表示 例如: ["人生", "该", "如何", "起头"]># 每个词对应矩阵中的一个向量 [[1.32, 4,32, 0,32, 5.2],[3…...

深圳SMT贴片加工核心工艺解析
内容概要 深圳作为全球电子制造产业的核心集聚区,其SMT贴片加工技术始终引领行业创新方向。本文聚焦深圳电子制造企业在高密度、微型化组件加工中的核心工艺体系,系统解析从锡膏印刷到成品检测的全流程关键技术。通过梳理SMT产线中设备参数设定、工艺条…...
P8720 [蓝桥杯 2020 省 B2] 平面切分--set、pair
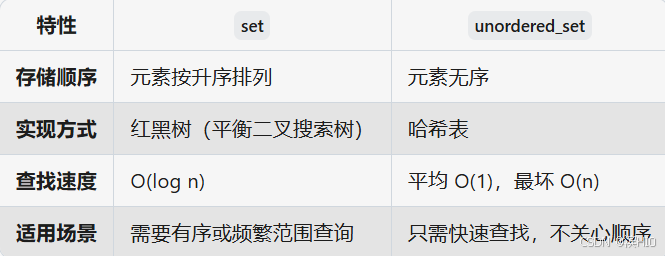
P8720 [蓝桥杯 2020 省 B2] 平面切分--set、pair 题目 分析一、pair1.1pair与vector的区别1.2 两者使用场景两者组合使用 二、set2.1核心特点2.2set的基本操作2.3 set vs unordered_set示例:统计唯一单词数代码 题目 分析 大佬写的很明白,看这儿 我讲讲…...

高工独家报告|谁在收割2026智驾市场红利?440万辆背后的芯片大洗牌
高工智能汽车研究院发布《2026年中国市场智能汽车SoC芯片行业分析报告》。报告立足中国乘用车市场,基于乘用车前装量产数据库,全面解析智能驾驶SoC(含前视一体机、域控制器及高阶自动驾驶辅助芯片)与智能座舱SoC(含端侧…...

Windows平台PDF处理终极指南:Poppler for Windows让你告别复杂编译
Windows平台PDF处理终极指南:Poppler for Windows让你告别复杂编译 【免费下载链接】poppler-windows Download Poppler binaries packaged for Windows with dependencies 项目地址: https://gitcode.com/gh_mirrors/po/poppler-windows 还在为Windows系统上…...

ARGUS:视觉中心化多模态推理框架,实现像素级可验证Chain-of-Thought
1. 项目概述:这不是又一个“多模态大模型”,而是一次视觉推理范式的重新校准ARGUS这个名字,乍看像某个军事侦察系统代号,其实它精准指向了当前多模态AI领域最棘手的痛点——视觉信息在推理链中长期处于“失语”状态。你肯定见过这…...

WOM-v编码:用电压世代划分技术提升QLC闪存寿命4-11倍
1. 项目概述:当QLC闪存寿命告急,我们能做什么?作为一名长期关注存储技术的从业者,我最近一直在思考一个现实而紧迫的问题:随着QLC(四层单元)乃至PLC(五层单元)闪存成为消…...

大规模集群中的ksync:性能测试与资源占用优化策略
大规模集群中的ksync:性能测试与资源占用优化策略 【免费下载链接】ksync Sync files between your local system and a kubernetes cluster. 项目地址: https://gitcode.com/gh_mirrors/ks/ksync 在当今云原生开发环境中,Kubernetes文件同步工具…...

Atomic-Server API完全参考:开发者必备的接口文档指南
Atomic-Server API完全参考:开发者必备的接口文档指南 【免费下载链接】atomic-server An open source headless CMS / real-time database. Powerful table editor, full-text search, and SDKs for JS / React / Svelte. 项目地址: https://gitcode.com/gh_mirr…...

opencode使用安装
确保已经安装好node npm安装opencode C:\WINDOWS\system32>npm install -g opencode-aiadded 3 packages in 2mC:\WINDOWS\system32>npm安装mcp-chrome C:\WINDOWS\system32>npm...

GitLab CVE-2025-1477:URI编码绕过身份验证的应急防护指南
1. 这个漏洞不是“修个补丁就完事”的普通问题GitLab 安全漏洞 CVE-2025-1477,光看编号容易误以为是又一个常规的权限绕过或信息泄露类CVE——毕竟GitLab每年披露几十个中低危漏洞,运维同学看到CVE编号第一反应往往是查CVSS评分、翻官方通告、打补丁、走…...

开源Agent框架能跑通Demo,但离企业生产还差五个能力
2026年AI行业的现象很有意思。开源社区里Agent框架层出不穷,每隔几周就有一个新项目冲上GitHub热榜,演示视频做得赏心悦目——AI Agent流畅地调用工具、搜索网页、生成报告,评论区一片惊叹。但如果你去问那些真正在生产环境中大规模部署Agent…...

别再被‘一亿像素’忽悠了!聊聊手机CMOS尺寸、像素和Remosaic那些事儿
手机CMOS尺寸、像素与成像质量的真相:别再被数字游戏迷惑 每次打开手机厂商的发布会,总能看到各种令人眼花缭乱的参数轰炸——"一亿像素"、"超大底传感器"、"超清画质"。这些营销术语让普通消费者一头雾水,甚至…...