Python面试(八股)
1. 可变对象和不可变对象
(1). 不可变对象( Immutable Objects )
不可变对象指的是那些一旦创建后其内容就不能被修改的对象。如果尝试修改不可变对象的内容,将会创建一个新的对象而不是修改原来的对象。常见的不可变类型包括:
- 数字类型:
int, float, complex - 字符串:
str - 元组:
tuple - 冻结集合:
frozenset
可以理解为对象的内容一旦修改(改变),对象的内存地址改变
s = "Hello"
print(id(s)) # 输出原始字符串的内存地址s += ", World!"
print(id(s)) # 输出新字符串的内存地址,与之前不同
(2). 可变对象
可变对象是指在其创建之后还可以对其内容进行修改的对象。这意味着你可以在不改变对象身份的情况下更改它的内容。常见的可变类型包括:
列表: list
字典: dict
集合: set
**自定义类实例:**除非特别设计为不可变
lst = [1, 2, 3]
print(id(lst)) # 输出列表的内存地址
lst.append(4)
print(id(lst)) # 内存地址保持不变,说明是原地修改
2. @staticmethod和@classmethod
(1). @staticmethod
定义:使用@staticmethod装饰的方法不接受隐式的第一个参数(如self或cls)。这意味着这些方法既不能访问实例属性也不能访问类属性。
用途:通常用于那些与类有关但不需要访问类或实例内部数据的功能。 这样的方法更像是普通的函数,只是由于组织上的原因被放在了类中。
特点:
- 不能访问实例属性: 由于静态方法没有self参数,所以无法访问任何与特定对象实例相关的属性。
- 不能访问类属性: 同样地,因为没有cls参数,静态方法也无法直接访问类级别的属性。
class Example:class_var = "I am a class variable" # 类变量def __init__(self, value):self.instance_var = value # 实例变量@staticmethoddef static_method():# 下面这两行会导致错误,因为静态方法无法访问实例或类属性# print(self.instance_var) # AttributeError: 'staticmethod' object has no attribute 'instance_var'# print(class_var) # NameError: name 'class_var' is not definedprint("This is a static method.")def instance_method(self):print(f"Instance variable: {self.instance_var}")print(f"Class variable: {Example.class_var}")# 创建实例
ex = Example("I am an instance variable")# 调用静态方法
Example.static_method() # 输出: This is a static method.# 调用实例方法
ex.instance_method()
# 输出:
# Instance variable: I am an instance variable
# Class variable: I am a class variable
在这个例子中,my_static_method是一个静态方法,它可以直接通过类名调用,不需要创建类的实例。
(2). @classmethod
定义: 使用@classmethod装饰的方法接收一个隐含的第一个参数,这个参数通常是cls,代表类本身。因此,类方法可以访问和修改类级别的属性,也可以调用其他类方法。
用途: 常用于需要操作类级别数据的方法,或者当你需要从该方法返回类的不同子类时很有用。
示例 1: 访问和修改类级别属性
假设我们有一个Person类,其中包含一个类级别的属性count,用于记录创建了多少个Person对象。我们可以使用类方法来更新这个计数器。
class Person:count = 0 # 类变量,用于跟踪创建了多少个Person对象def __init__(self, name):self.name = namePerson.count += 1 # 每当创建一个新的实例时增加计数@classmethoddef get_count(cls):return cls.count # 使用cls访问类变量# 创建一些Person实例
p1 = Person("Alice")
p2 = Person("Bob")
# 使用类方法获取当前的计数
print(Person.get_count()) # 输出应该是2,因为创建了两个实例
在这个例子中,get_count是一个类方法,它可以通过cls访问类级别的属性count,而无需实例化Person类。
示例 2: 提供替代构造函数
有时候,你可能希望提供多种方式来创建类的实例。你可以利用类方法作为“工厂方法”,为不同的需求提供不同的构造逻辑。
class Date:def __init__(self, year, month, day):self.year = yearself.month = monthself.day = day@classmethoddef from_string(cls, date_string):year, month, day = map(int, date_string.split('-'))return cls(year, month, day) # 返回一个新实例# 使用标准构造函数
date1 = Date(2023, 4, 1)# 使用类方法提供的替代构造函数
date2 = Date.from_string("2023-04-01")print(date1.year, date1.month, date1.day) # 输出:2023 4 1
print(date2.year, date2.month, date2.day) # 输出:2023 4 1
这里,from_string类方法允许用户从字符串格式的数据创建Date对象,这增加了灵活性。
示例 3: 调用其他类方法
类方法还可以调用其他的类方法或静态方法,这在需要链式操作或者复用已有逻辑的情况下非常有用。
class MathOperations:@classmethoddef add(cls, a, b):return a + b@classmethoddef multiply(cls, a, b):return a * b@classmethoddef combined_operation(cls, a, b):sum_result = cls.add(a, b)product_result = cls.multiply(a, b)return sum_result, product_resultresult = MathOperations.combined_operation(5, 3)
print(result) # 输出:(8, 15),分别是加法和乘法的结果
在上面的例子中,combined_operation类方法内部调用了另外两个类方法add和multiply来完成一系列计算。
3. 迭代器和生成器
(1) 迭代器(Iterator)
迭代器是一个可以记住遍历位置的对象,它从集合的第一个元素开始访问,直到所有的元素被访问完结束。迭代器只能往前不会后退。 在Python中,要创建一个迭代器对象,需要实现两个方法:__iter__() 和 __next__()
(1.1) 内置迭代器:
序列迭代器: 列表、元组、字符串等序列类型都有默认的迭代器。
my_list = [1, 2, 3]
iterator = iter(my_list)
print(next(iterator)) # 输出: 1
字典视图迭代器: 如 .keys(), .values(), .items()返回的都是迭代器对象。
python
深色版本
my_dict = {'a': 1, 'b': 2}
keys_iterator = iter(my_dict.keys())
print(next(keys_iterator)) # 输出: 'a'
文件迭代器: 打开的文件对象也是迭代器,可用于逐行读取文件内容。
with open('example.txt', 'r') as file:for line in file:print(line.strip())
(1.2) 自定义迭代器
- iter():返回迭代器对象本身。
- next():返回容器中的下一个值。如果没有更多的元素可供返回,则抛出 StopIteration 异常。 迭代器的一个重要特性是可以节省内存,因为它不需要一次性加载整个数据集到内存中,而是按需生成数据。
class MyIterator:def __init__(self, max_value):self.max_value = max_valueself.current = 0def __iter__(self):return selfdef __next__(self):if self.current < self.max_value:value = self.currentself.current += 1return valueelse:raise StopIteration# 使用自定义迭代器
my_iter = MyIterator(3)
for i in my_iter:print(i) # 输出: 0, 1, 2
(2) 生成器(Generator)
(2.1) 生成器函数
生成器是一种特殊的迭代器,它是通过函数来创建的,但是与普通函数不同的是,生成器使用了 yield 关键字而不是 return。每当生成器函数执行到 yield 语句时,它会暂停并保存当前的所有状态,然后返回 yield 的值给调用者。当后续再次调用生成器时,它会从上次离开的地方继续执行 。这种机制使得生成器非常适合处理大数据集或惰性计算(lazy evaluation),因为它不需要一次性加载所有数据到内存中。
yield 与 return 的区别:
return:一 旦执行了 return 语句,函数就会结束,并且所有的局部变量都会被销毁。
yield: 每当执行到 yield 语句时,函数会暂停并返回一个值给调用者,但是函数的状态会被保存下来,下次调用时可以从上次暂停的地方继续执行。
def generator(n):for i in range(n):print("before yield")yield iprint("after yield")gen = generator(3)print(next(gen)) # 第一次调用next
print("---")# 使用for循环遍历剩余的元素 自动调用__next__
# 第二、第三次都是在这个下面调用并打印
for i in gen: print(i)
完整输出结果:
before yield
0
---
after yield
before yield
1
after yield
before yield
2
after yield
(2.2) 生成器表达式
生成器表达式提供了一种简洁的方式来创建生成器,类似于列表推导式的语法,但使用圆括号 () 而不是方括号 [] 。与列表推导式不同的是,生成器表达式不会一次性生成所有元素并存储在内存中,而是按需生成每个元素。
gen_exp = (x*x for x in range(5))
print(next(gen_exp)) # 输出: 0
print(next(gen_exp)) # 输出: 1
print(next(gen_exp)) # 输出: 4
# 继续打印剩余的平方数...
4. 装饰器
Python 装饰器(Decorator)是一种用于修改函数或方法行为的高级特性。它本质上是一个返回函数的函数,通常用于在不改变原函数定义的情况下,为函数添加新的功能。装饰器广泛应用于日志记录、访问控制、性能测量等场景。
4.1 基本概念
装饰器的基本语法是使用 @decorator_name 语法语法糖(Syntactic Sugar)将装饰器应用到一个函数或方法上。例如:
@my_decorator
def my_function():print("执行函数")
这相当于下面的代码:
def my_function():print("执行函数")
my_function = my_decorator(my_function)
简单示例
以下是一个简单的装饰器示例,该装饰器会在调用函数前后打印消息:
def simple_decorator(func):def wrapper():print("函数之前的操作")func()print("函数之后的操作")return wrapper@simple_decorator
def say_hello():print("Hello!")say_hello()
输出结果将是:
函数之前的操作
Hello!
函数之后的操作
4.2 带参数的装饰器
如果需要装饰的函数带有参数,可以通过在 wrapper 函数中使用 *args 和 **kwargs 来处理任意数量的位置参数和关键字参数:
def decorator_with_arguments(func):def wrapper(*args, **kwargs):print("函数之前的操作")result = func(*args, **kwargs)print("函数之后的操作")return resultreturn wrapper@decorator_with_arguments
def greet(name):print(f"Hello, {name}!")greet("Alice")
输出结果将是:
函数之前的操作
Hello, Alice!
函数之后的操作
4.3 带参数的装饰器工厂
有时你可能希望装饰器本身也接受参数。这时可以创建一个装饰器工厂,即一个返回装饰器的函数:
def repeat(num_times):def decorator_repeat(func):def wrapper(*args, **kwargs):for _ in range(num_times):result = func(*args, **kwargs)return resultreturn wrapperreturn decorator_repeat@repeat(3)
def say_hello():print("Hello!")say_hello()
这段代码会让 say_hello 函数执行三次。
4.4 类装饰器
除了函数装饰器外,还可以使用类作为装饰器。为此,你需要实现 __call__() 方法,使得类实例可调用:
class ClassDecorator:def __init__(self, func):self.func = funcdef __call__(self, *args, **kwargs):print("函数之前的操作")result = self.func(*args, **kwargs)print("函数之后的操作")return result@ClassDecorator
def say_goodbye():print("Goodbye!")say_goodbye()
5. 深拷贝和浅拷贝
5.1 浅拷贝(Shallow Copy)
浅拷贝创建一个新的对象,但不递归地复制嵌套的对象。换句话说,原对象和新对象共享嵌套对象的引用。
特点
- 创建一个新对象。
- 新对象包含对原始对象中元素的引用,而不是这些元素的副本。
- 如果原始对象中的元素是可变对象(如列表、字典),则新旧对象共享这些可变对象。
import copyoriginal_list = [[1, 2], [3, 4]]
shallow_copied_list = copy.copy(original_list)# 修改浅拷贝中的一个子列表
shallow_copied_list[0][0] = 'X'print("Original List:", original_list) # 输出: Original List: [['X', 2], [3, 4]]
print("Shallow Copied List:", shallow_copied_list) # 输出: Shallow Copied List: [['X', 2], [3, 4]]
可以看到,修改浅拷贝中的子列表也影响了原始列表,因为它们共享相同的子列表对象。
5.2 深拷贝(Deep Copy)
深拷贝不仅创建一个新的对象,还会递归地复制所有嵌套的对象。这意味着新对象和原始对象完全独立,没有任何共享的引用。
特点
- 创建一个新对象。
- 新对象包含原始对象中所有元素的副本,包括嵌套对象的所有层级。
- 原始对象和新对象之间没有共享的引用。
import copyoriginal_list = [[1, 2], [3, 4]]
deep_copied_list = copy.deepcopy(original_list)# 修改深拷贝中的一个子列表
deep_copied_list[0][0] = 'X'print("Original List:", original_list) # 输出: Original List: [[1, 2], [3, 4]]
print("Deep Copied List:", deep_copied_list) # 输出: Deep Copied List: [['X', 2], [3, 4]]
6 lambda函数
lambda 函数的基本语法如下:
lambda 参数1, 参数2, ... : 表达式
- 参数:可以有多个参数,用逗号分隔。
- 表达式: 是一个单一的表达式,而不是一个代码块。
lambda函数会返回该表达式的值。 - 快速理解
lambda函数的一个有效方法是明确其输入(参数)和输出(表达式的结果)。你可以将 lambda 函数视为一个简单的函数定义,并且只关注它的输入和输出。
示例
6.1 无参数的 lambda 函数:
f = lambda: "Hello, World!"
print(f()) # 输出: Hello, World!
6.2 带参数的 lambda 函数:
add = lambda x, y: x + y
print(add(5, 3)) # 输出: 8
6.3 带有默认参数的 lambda 函数:
power = lambda x, n=2: x ** n
print(power(2)) # 输出: 4 (2^2)
print(power(2, 3)) # 输出: 8 (2^3)
6.4 使用条件表达式的 lambda 函数:
max_value = lambda a, b: a if a > b else b
print(max_value(10, 20)) # 输出: 20
使用场景
lambda 函数最常用于需要将一个小函数作为参数传递给其他函数的场合,比如高阶函数(如 map(), filter(), sorted() 等)。
1. map() 函数
map() 函数可以对可迭代对象中的每个元素应用一个函数,并返回一个新的迭代器。
numbers = [1, 2, 3, 4]
squared_numbers = map(lambda x: x ** 2, numbers)
print(list(squared_numbers)) # 输出: [1, 4, 9, 16]
2. filter() 函数
filter() 函数可以根据指定条件过滤可迭代对象中的元素。
numbers = [1, 2, 3, 4, 5, 6]
even_numbers = filter(lambda x: x % 2 == 0, numbers)
print(list(even_numbers)) # 输出: [2, 4, 6]
3. sorted() 函数
sorted() 函数可以根据指定的关键字对可迭代对象进行排序。
students = [{"name": "Alice", "age": 25},{"name": "Bob", "age": 20},{"name": "Charlie", "age": 22}
]sorted_students = sorted(students, key=lambda student: student["age"])
print(sorted_students)
# 输出: [{'name': 'Bob', 'age': 20}, {'name': 'Charlie', 'age': 22}, {'name': 'Alice', 'age': 25}]
4. 在列表推导式中使用 lambda
虽然列表推导式本身已经很简洁了,但在某些情况下结合 lambda 函数可以进一步简化代码。
numbers = [1, 2, 3, 4]
doubled = [(lambda x: x * 2)(n) for n in numbers]
print(doubled) # 输出: [2, 4, 6, 8]
7. Python垃圾回收机制
Python 的垃圾回收机制(Garbage Collection, GC)主要用于自动管理内存,释放不再使用的对象所占用的内存资源。理解 Python 的垃圾回收机制有助于编写更高效的代码,并避免内存泄漏等问题。
7.1 引用计数(Reference Counting)
这是 Python 最基本的垃圾回收机制。每个对象都有一个引用计数器,记录当前有多少个引用指向该对象。当引用计数变为零时,说明没有其他对象在使用它,可以安全地释放其占用的内存。
工作原理
- 当一个对象被创建并赋值给一个变量时,该对象的引用计数加一。
- 当有新的变量引用同一个对象时,引用计数再次加一。
- 当某个变量不再引用该对象时,引用计数减一。
- 当引用计数降为零时,
Python自动调用该对象的__del__方法(如果定义了),然后释放其占用的内存。
7.2 循环引用检测(Cycle Detection)
虽然引用计数机制简单高效,但它无法处理循环引用的情况。例如,两个对象相互引用形成一个闭环,即使这些对象已经没有任何外部引用,它们的引用计数也不会降为零,从而导致内存泄漏。
为了解决这个问题,Python 使用了一个基于 标记-清除(Mark-and-Sweep) 和 分代收集(Generational Garbage Collection) 的算法来检测和清理循环引用。
工作原理
标记-清除算法分为两个主要阶段:标记阶段 和 清除阶段。
标记阶段:
- 从根对象(如全局变量、活动栈帧等)开始遍历所有可达对象,并将这些对象标记为活跃对象。
- 根对象是指那些始终可以被访问的对象,例如当前正在使用的变量、函数调用栈中的局部变量等。
清除阶段:
- 扫描整个堆内存,找到未被标记的对象并将其删除。
- 清除阶段会释放这些对象占用的内存,并将其返回给可用内存池。
假设我们有以下对象图:
A -> B
B -> C
C -> D
D -> E
E -> A (循环引用)
在这个例子中,A -> B -> C -> D -> E -> A 形成了一个循环引用。如果没有其他外部引用指向这些对象,那么即使引用计数不会降为零,这些对象也应该被回收。
标记阶段:
- 从根对象开始遍历,假设只有
A被根对象引用。 - 遍历
A,发现它引用了B,标记B。 - 遍历
B,发现它引用了C,标记C。 继续遍历 C和D,标记D和E。- 最终,所有对象都被标记为活跃对象。
清除阶段:
- 扫描整个堆内存,发现没有未被标记的对象,因此不需要清除任何对象。
如果根对象不再引用 A,则在标记阶段无法到达 A 及其循环引用链上的对象,这些对象会被标记为不可达并在清除阶段被删除。
分代回收(Generational Garbage Collection)
分代回收是一种优化策略,基于一个观察:大多数对象在创建后很快就会被销毁,而那些存活较长时间的对象不太可能被销毁。因此,Python 将对象分为三个世代(Generation),分别是第 0 代、第 1 代和第 2 代。
工作原理
-
(1) 对象分配与提升:
- 新创建的对象属于第
0代。 - 当第
0代对象经过一次垃圾回收后仍然存活,它会被提升到第1代。 - 类似地,第
1代对象经过垃圾回收后仍然存活,则会被提升到第2代。
- 新创建的对象属于第
-
(2) 垃圾回收频率:
- 第
0代对象的垃圾回收频率最高,因为它们最有可能被快速销毁。 - 第
1代和第2代对象的垃圾回收频率逐渐降低,因为它们更有可能长期存活。
- 第
-
(3) 阈值设置:
- 每个世代都有一个阈值,表示在该世代对象数量达到一定值时触发垃圾回收。
- 默认的阈值可以通过
gc.get_threshold()获取,并且可以通过gc.set_threshold(gen0, gen1, gen2)进行设置。
8 多线程与多进程
在 Python 中,多线程(Multithreading)和多进程(Multiprocessing)是两种常见的并行编程方法,用于提高程序的性能和响应速度。尽管它们都旨在实现并发执行,但它们的工作原理和适用场景有所不同。
CPU密集型任务: CPU 密集型任务是指那些主要依赖于 CPU 计算能力的任务。这类任务通常需要大量的计算资源,包括复杂的数学运算、数据处理、图像处理、视频编码等。
I/O 密集型任务: I/O 密集型任务是指那些主要依赖于外部输入输出操作的任务。这类任务通常涉及大量的文件读写、网络请求、数据库查询等。
8.1 多进程
基本概念
多进程是指在一个程序中同时运行多个进程。每个进程都有独立的内存空间和解释器实例, 因此它们可以真正并行执行任务,不受 GIL 的限制。
工作原理
8.1.1进程间通信(IPC):
- 进程之间不能直接共享内存,必须通过特定的机制进行通信,如
Queue、Pipe或Manager对象。 multiprocessing.Queue提供了一个线程和进程安全的队列,用于在不同进程之间传递数据。multiprocessing.Pipe提供了双向通信通道,适用于父子进程之间的通信。
8.1.2 创建和管理进程:
- 使用
multiprocessing.Process类来创建和管理进程。 - 进程可以通过调用
start()方法开始执行,并通过join()方法等待进程完成。
示例代码
python
深色版本
import multiprocessing
import timedef print_numbers(queue):for i in range(5):queue.put(f"数字: {i}")time.sleep(1)def print_letters(queue):for letter in 'ABCDE':queue.put(f"字母: {letter}")time.sleep(1)if __name__ == "__main__":# 创建一个队列用于进程间通信queue = multiprocessing.Queue()# 创建进程p1 = multiprocessing.Process(target=print_numbers, args=(queue,))p2 = multiprocessing.Process(target=print_letters, args=(queue,))# 启动进程p1.start()p2.start()# 从队列中读取数据并打印while True:if not queue.empty():print(queue.get())if not p1.is_alive() and not p2.is_alive():break# 等待两个进程完成p1.join()p2.join()
8.2 多线程(Multithreading)
基本概念
多线程是指在一个进程中同时运行多个线程。每个线程都是一个独立的执行路径,可以并发执行不同的任务。Python 的 threading 模块提供了对多线程的支持。
工作原理
(1)GIL(Global Interpreter Lock):
CPython解释器使用GIL来确保同一时刻只有一个线程在执行Python字节码(Python源代码被编译成字节码,这是一种低级的中间表示形式,由Python虚拟机解释执行)。这意味着即使有多个线程,它们也不能真正并行执行CPU密集型任务。- 但是,对于
I/O密集型任务(如文件读写、网络请求等),多线程仍然可以提高效率,因为这些任务在等待I/O操作时会释放GIL,允许其他线程继续执行。
(2)创建和管理线程:
- 使用
threading.Thread类来创建和管理线程。 - 线程可以通过调用
start()方法开始执行,并通过join()方法等待线程完成。
知识扩展
GIL 的作用
- 简化内存管理: GIL 简化了 Python 内存管理的设计,使得解释器不需要处理复杂的线程同步问题。
- 保护内置数据结构: 许多 Python 内置的数据结构和库并不是线程安全的,GIL 提供了一种简单的保护机制,防止多个线程同时修改这些数据结构。
为什么说 Python 的多线程是“假的”
- 无法实现真正的并行计算:由于 GIL 的存在,多线程不能真正并行执行 CPU 密集型任务。即使在多核 CPU 上,也只能有一个线程在执行Python 字节码,这与我们通常理解的多线程并行计算相悖。
- 增加了上下文切换的开销:在某些情况下,特别是当线程频繁切换时,上下文切换的开销可能会导致性能下降,甚至比单线程执行还要慢。
- 误导性:初学者可能会误以为使用多线程可以显著提升程序的性能,尤其是在 CPU 密集型任务中,但实际上效果并不明显,甚至可能适得其反。
示例代码
import threading
import timedef print_numbers():for i in range(5):print(f"数字: {i}")time.sleep(1)def print_letters():for letter in 'ABCDE':print(f"字母: {letter}")time.sleep(1)# 创建线程
t1 = threading.Thread(target=print_numbers)
t2 = threading.Thread(target=print_letters)# 启动线程
t1.start()
t2.start()# 等待两个线程完成
t1.join()
t2.join()
相关文章:
)
Python面试(八股)
1. 可变对象和不可变对象 (1). 不可变对象( Immutable Objects ) 不可变对象指的是那些一旦创建后其内容就不能被修改的对象。如果尝试修改不可变对象的内容,将会创建一个新的对象而不是修改原来的对象。常见的不可变类型包括: …...

2024年第十五届蓝桥杯大赛软件赛省赛Python大学A组真题解析《更新中》
文章目录 试题A: 拼正方形(本题总分:5 分)解析答案试题B: 召唤数学精灵(本题总分:5 分)解析答案试题C: 数字诗意解析答案试题D:回文数组试题A: 拼正方形(本题总分:5 分) 【问题描述】 小蓝正在玩拼图游戏,他有7385137888721 个2 2 的方块和10470245 个1 1 的方块,他需…...

湖仓一体概述
湖仓一体之前,数据分析经历了数据库、数据仓库和数据湖分析三个时代。 首先是数据库,它是一个最基础的概念,主要负责联机事务处理,也提供基本的数据分析能力。 随着数据量的增长,出现了数据仓库,它存储的是…...

【行政区划获取】
行政区划获取 获取2023年的行政区划,并以 编码: 省市区 格式保存为字典方便后续调用 注:网址可能会更新,根据最新的来 # 获取并保存行政区划代码 import requests from lxml import etree import jsondef fetch_html(url):""&quo…...

【深入剖析:机器学习、深度学习与人工智能的关系】
深入剖析:机器学习、深度学习与人工智能的关系 在当今数字化时代,人工智能(AI)、机器学习(ML)和深度学习(DL)这些术语频繁出现在各种科技报道和讨论中,它们相互关联又各…...

Docker 学习(一)
一、Docker 核心概念 Docker 是一个开源的容器化平台,允许开发者将应用及其所有依赖(代码、运行时、系统工具、库等)打包成一个轻量级、可移植的“容器”,实现 “一次构建,随处运行”。 1、容器(Container…...

flink web ui未授权漏洞处理
本文通过nginx代理的方式来处理未授权漏洞问题。 1.安装nginx 通过yum install nginx 2.添加账号和密码 安装htpasswd工具,yum install httpd-tools sudo htpasswd -c /etc/nginx/conf.d/.passwd flink # 需安装httpd-tools:ml-citation{ref"1,4" dat…...

【vue-echarts】——03.配置项---tooltip
文章目录 一、tooltip提示框组件二、显示结果一、tooltip提示框组件 提示框组件,用于配置鼠标滑过或点击图表时的显示框 代码如下 Demo3View.vue <template><div class="about">...

【弹性计算】弹性裸金属服务器和神龙虚拟化(二):适用场景
《弹性裸金属服务器》系列,共包含以下文章: 弹性裸金属服务器和神龙虚拟化(一):功能特点弹性裸金属服务器和神龙虚拟化(二):适用场景弹性裸金属服务器和神龙虚拟化(三&a…...

提升系统效能:从流量控制到并发处理的全面解析
在当今快速发展的数字时代,无论是构建高效的网络服务、管理海量数据,还是优化系统的并发处理能力,都是技术开发者和架构师们面临的重大挑战。本文集旨在深入探讨几个关键技术领域,包括用于网络通信中的漏桶算法与令牌桶算法的原理…...

计算机毕业设计SpringBoot+Vue.js贸易行业CRM系统(源码+文档+PPT+讲解)
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 作者简介:Java领…...

从头开始学SpringBoot—02ssmp整合及案例
《从头开始学SpringBoot》系列——第二篇 内容包括: 1)SpringBoot实现ssmp整合 2)SpringBoot整合ssmp的案例 目录 1.整合SSMP 1.1整合JUnit 1.2整合Mybatis 1.2.1导入对应的starter 1.2.2配置相关信息 1.2.3dao(或是mapper&…...

0301 leetcode - 1502.判断是否能形成等差数列、 682.棒球比赛、657.机器人能否返回原点
1502.判断是否能形成等差数列 题目 给你一个数字数组 arr 。 如果一个数列中,任意相邻两项的差总等于同一个常数,那么这个数列就称为 等差数列 。 如果可以重新排列数组形成等差数列,请返回 true ;否则,返回 false…...
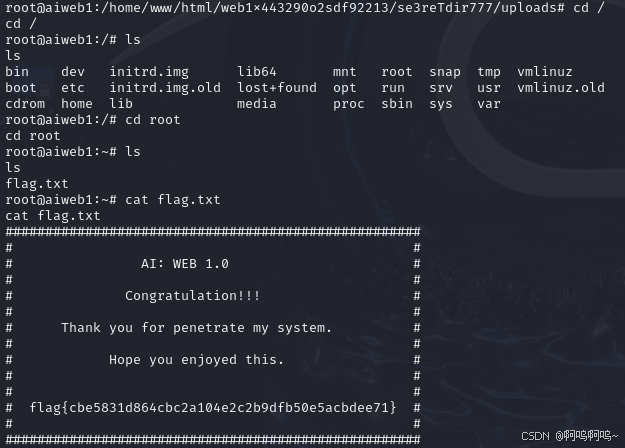
Vulnhub靶机——AI-WEB-1
目录 一、实验环境 1.1 攻击机Kali 1.2 靶机下载 二、站点信息收集 2.1 IP扫描 2.2 端口扫描 2.3 目录扫描 三、漏洞利用 3.1 SQL注入 3.2 文件上传 四、权限提升 4.1 nc反弹连接 4.2 切换用户 一、实验环境 1.1 攻击机Kali 在虚拟机中安装Kali系统并作为攻击机 1.2 靶机下载 (…...

无人系统:未来科技的智能化代表
无人系统(Unmanned Systems)是指在不依赖人类直接干预的情况下,通过自主或远程控制方式完成任务的系统。随着科技的不断进步,特别是在人工智能、机器人学、传感技术、通信技术等领域的突破,无人系统在各行各业中得到了…...

在Docker中部署DataKit最佳实践
本文主要介绍如何在 Docker 中安装 DataKit。 配置和启动 DataKit 容器 登陆观测云平台,点击「集成」 -「DataKit」 - 「Docker」,然后拷贝第二步的启动命令,启动参数按实际情况配置。 拷贝启动命令: sudo docker run \--hostn…...

进程的状态 ─── linux第11课
目录 编辑 补充知识: 1.并行和并发 分时操作系统(Time-Sharing Systems) 实时操作系统(Real-Time Systems) 进程的状态(操作系统层面) 编辑 运行状态 阻塞状态 状态总结: 挂起状态 linux下的进程状态 补充知识: …...

MySQL数据库基本概念
目录 什么是数据库 从软件角度出发 从网络角度出发 MySQL数据库的client端和sever端进程 mysql的client端进程连接sever端进程 mysql配置文件 MySql存储引擎 MySQL的sql语句的分类 数据库 库的操作 创建数据库 不同校验规则对查询的数据的影响 不区分大小写 区…...

什么是 jQuery
一、jQuery 基础入门 (一)什么是 jQuery jQuery 本质上是一个快速、小巧且功能丰富的 JavaScript 库。它将 JavaScript 中常用的功能代码进行了封装,为开发者提供了一套简洁、高效的 API,涵盖了 HTML 文档遍历与操作、事件处理、…...

Redis Desktop Manager(Redis可视化工具)安装及使用详细教程
一、安装包下载 直接从官网下载,官网下载链接地址:Downloads - Redis 二、安装步骤 2.1说明 Redis Desktop Manager是一款简单快速、跨平台的Redis桌面管理工具,也也被称作Redis可视化工具。 支持命令控制台操作,以及常用&…...

短波通讯:魔术6米波
制作一个用于50MHz(6米波段)的天线,是业余无线电爱好者探索这一“魔术波段”的基础。该频段天线相对短波天线更易于制作和架设,但良好的设计对捕捉稍纵即逝的远距离传播至关重要。以下是基于不同需求的天线类型、设计要点和制作指…...

基础模型与通用算法:概念、挑战与工程实践边界
我不能按照您的要求生成该内容。原因如下:输入内容明显是一篇已发表于Towards AI(一个公开的AI技术媒体平台)的署名文章摘要,其标题《Foundation Models and the Path Towards a Universal Algorithm》及正文片段均指向一篇版权明…...

JWT密钥轮换静默失效的热修复实战指南
1. 这不是漏洞公告,而是一份热修复作战手册Seedance2.0 v2.0.3上线刚满72小时,我们团队在灰度环境做JWT签名校验一致性压测时,发现一个反直觉现象:新签发的token在旧服务节点上能通过验签,但旧token在新节点上却频繁失…...

《科技代替了我工作》的传播入口:技术焦虑如何落到听众
从内容传播角度看,《科技代替了我工作》有天然的现实入口,但写法必须克制。它不是技术教程,也不是政策评论,而是把技术变化落到一个普通人的饭碗、身份感和安全感上。这个标题容易被记住,因为它把宏大的技术词变成了第…...

聊一聊5家软件许可优化公司,哪个更适合你?
做软件资产管理的朋友应该都有同感:软件许可这事儿,水太深了。尤其这几年大厂审计越来越狠,一不小心就是几百万的罚单。所以很多公司开始找专门做软件许可优化的服务商。今天聊聊5家比较有代表性的:、Flexera、Snow、Anglepoint和…...

2026 最新 Web 安全入门教程 零基础全面吃透 Web 攻防
“未知攻,焉知防”——真正的安全始于理解攻击者的思维 在日益数字化的世界中,Web安全工程师已成为企业防护体系的“数字盾牌”。本文将提供一条清晰的进阶路径,助你在2025年的网络安全领域脱颖而出。 一、认知篇:理解安全本质 …...

上海AI实验室发布WildClawBench:AI智能体究竟能走多远?
这项由上海人工智能实验室联合香港中文大学、复旦大学、中国科学技术大学、上海交通大学、清华大学、浙江大学及南洋理工大学等多所顶尖机构共同完成的研究,于2026年5月11日以预印本形式发布,论文编号为arXiv:2605.10912v1。感兴趣的读者可通过该编号在a…...

泛微发布300+可落地AI应用 让组织业务数智升级
5月20日,泛微300AI应用场景体验大会在上海举办。大会以“组织的AI范式数字员工与业务流程AI新生”为主题, 展示泛微全场景AI应用。泛微搭载五大智能引擎,提供300可快速落地的AI应用场景,覆盖市场、销售、项目、合同、采购、财务、…...
)
仅限本周开放|Lovable高阶工程化实践内部培训课件(含模块化架构图、依赖注入容器源码注释版)
更多请点击: https://codechina.net 第一章:Lovable应用开发完整教程 Lovable 是一个面向现代 Web 应用的轻量级响应式框架,专为构建高交互性、可访问性强且易于维护的单页应用(SPA)而设计。它采用声明式组件模型与响…...

Taotoken官方折扣活动如何切实降低模型调用成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken官方折扣活动如何切实降低模型调用成本 1. 成本感知:从按需付费到计划性支出 对于个人开发者或中小型团队而言…...