哈希查找与深度优先遍历深度解析
一、算法基础概念对比
1.1 哈希查找的本质特征
哈希查找是一种基于哈希函数直接访问数据结构的查找技术,其核心在于通过数学映射建立键值与存储位置的直接关联。理想情况下时间复杂度可达O(1),实际应用中通过冲突处理机制实现近似常数时间的查找效率。
1.2 深度优先遍历的核心逻辑
深度优先遍历(DFS)是图遍历的基础策略,采用"不撞南墙不回头"的探索方式,沿着分支路径深入到底层节点再回溯探索其他路径。其空间复杂度与树的高度成正比,适用于路径探索、连通性判断等场景。
二、哈希查找技术详解
2.1 哈希函数设计原则
class HashTable:def __init__(self, size=10):self.size = sizeself.table = [[] for _ in range(size)] # 链地址法def _hash(self, key):# 混合哈希函数示例prime = 31hash_val = 0for char in str(key):hash_val = hash_val * prime + ord(char)return hash_val % self.sizedef insert(self, key, value):index = self._hash(key)bucket = self.table[index]for i, (k, v) in enumerate(bucket):if k == key:bucket[i] = (key, value)returnbucket.append((key, value))def search(self, key):index = self._hash(key)bucket = self.table[index]for k, v in bucket:if k == key:return vreturn None# 测试用例
ht = HashTable()
ht.insert("apple", 10)
ht.insert("banana", 20)
print(ht.search("apple")) # 输出10
设计要点:
-
确定性:相同输入必定产生相同输出
-
均匀性:输出值均匀分布在地址空间
-
混淆性:相似输入产生差异显著的哈希值
-
高效性:计算时间复杂度O(1)
2.2 冲突解决策略对比
| 方法 | 实现方式 | 优点 | 缺点 |
|---|---|---|---|
| 链地址法 | 链表存储冲突元素 | 简单可靠,负载因子高 | 指针消耗额外空间 |
| 开放寻址法 | 线性/二次探测寻找空位 | 内存连续,缓存友好 | 易产生聚集现象 |
| 双重哈希 | 使用第二个哈希函数探测 | 减少聚集概率 | 计算成本较高 |
| 完美哈希 | 无冲突哈希函数 | 理论最优性能 | 构建成本高,静态数据 |
2.3 工业级优化实践
-
动态扩容:当负载因子超过阈值(通常0.75)时自动扩容
-
布谷鸟哈希:使用多个哈希函数提升空间利用率
-
一致性哈希:分布式系统场景下的特殊实现
三、深度优先遍历深度解析
3.1 递归实现模板
def dfs_recursive(graph, node, visited=None):if visited is None:visited = set()visited.add(node)print(node, end=' ')for neighbor in graph[node]:if neighbor not in visited:dfs_recursive(graph, neighbor, visited)return visited# 邻接表示例
graph = {'A': ['B', 'C'],'B': ['D', 'E'],'C': ['F'],'D': [],'E': ['F'],'F': []
}
print("递归DFS:")
dfs_recursive(graph, 'A') # 输出A B D E F C3.2 迭代实现优化
def dfs_iterative(graph, start):visited = set()stack = [start]while stack:node = stack.pop()if node not in visited:print(node, end=' ')visited.add(node)# 逆序压栈保证与递归顺序一致stack.extend(reversed(graph[node]))return visitedprint("\n迭代DFS:")
dfs_iterative(graph, 'A') # 输出A B D E F C算法特性对比:
-
时间复杂度:O(V+E)
-
空间复杂度:O(V)(最坏情况)
-
路径特征:找到的路径不一定是最短路径
3.3 应用场景扩展
-
拓扑排序:检测有向无环图
-
强连通分量:Kosaraju算法
-
迷宫求解:路径探索与回溯
-
游戏AI:决策树遍历
四、混合应用实例
4.1 图结构重复节点检测
def detect_cycle(graph):visited = set()stack = set() # 使用集合实现O(1)查找def dfs(node):if node in stack:return Trueif node in visited:return Falsevisited.add(node)stack.add(node)for neighbor in graph[node]:if dfs(neighbor):return Truestack.remove(node)return Falsefor node in graph:if node not in visited:if dfs(node):return Truereturn False# 测试用例
cyclic_graph = {'A': ['B'], 'B': ['C'], 'C': ['A']}
print("\n检测环路:", detect_cycle(cyclic_graph)) # 输出True4.2 哈希加速DFS遍历
class Graph:def __init__(self):self.nodes = {}self.adj_list = {}def add_node(self, node):self.nodes[node] = Trueself.adj_list[node] = []def add_edge(self, src, dest):self.adj_list[src].append(dest)def dfs_paths(self, start, end):visited = {}paths = []stack = [(start, [start])]while stack:current, path = stack.pop()if current == end:paths.append(path)continueif current in visited and visited[current] >= 2:continuevisited[current] = visited.get(current, 0) + 1for neighbor in reversed(self.adj_list[current]):stack.append((neighbor, path + [neighbor]))return paths# 使用示例
g = Graph()
for node in ['A','B','C','D']:g.add_node(node)
g.add_edge('A','B')
g.add_edge('A','C')
g.add_edge('B','D')
g.add_edge('C','D')
print("所有路径:", g.dfs_paths('A','D')) # 输出[['A','C','D'], ['A','B','D']]五、算法对比与选型指南
5.1 特性对比矩阵
| 维度 | 哈希查找 | 深度优先遍历 |
|---|---|---|
| 时间复杂度 | O(1)平均,O(n)最坏 | O(V+E) |
| 空间复杂度 | O(n) | O(V) |
| 数据要求 | 需要预置存储结构 | 需要图/树结构 |
| 典型应用 | 字典查询、缓存系统 | 路径查找、拓扑排序 |
| 实现复杂度 | 中等(需处理冲突) | 简单(递归易实现) |
| 内存访问特征 | 随机访问 | 顺序访问 |
5.2 选型决策树
复制
是否需要进行数据快速检索? ├─ 是 → 哈希查找 └─ 否 → 是否为图结构问题?├─ 是 → 需要探索路径?│ ├─ 是 → 深度优先遍历│ └─ 否 → 广度优先遍历└─ 否 → 考虑其他算法
六、工程实践中的挑战
6.1 哈希表常见问题
-
哈希碰撞攻击:精心构造碰撞键值导致性能退化
-
动态扩容策略:如何平衡时间与空间成本
-
内存对齐问题:开放寻址法的缓存优化
6.2 DFS实现陷阱
-
递归深度限制:Python默认递归深度约1000层
-
环路处理:未记录访问状态导致无限循环
-
路径回溯:正确管理访问标记的撤销
七、前沿发展展望
7.1 哈希技术新方向
-
可逆哈希:支持双向计算的哈希函数
-
同态哈希:支持密文数据直接运算
-
量子安全哈希:抗量子计算的哈希算法
7.2 DFS优化趋势
-
并行化DFS:GPU加速大规模图遍历
-
增量式DFS:动态图结构的增量更新
-
启发式DFS:结合AI的路径预测
结语
哈希查找与深度优先遍历代表了两种截然不同的算法思想:前者追求极致的直接访问效率,后者强调系统的空间探索能力。理解二者的实现机理和适用场景,能够帮助开发者在面对复杂问题时选择最佳策略。随着分布式系统与人工智能的发展,这两种经典算法的现代演进版本将继续在数据处理、图计算等领域发挥重要作用。
相关文章:

哈希查找与深度优先遍历深度解析
一、算法基础概念对比 1.1 哈希查找的本质特征 哈希查找是一种基于哈希函数直接访问数据结构的查找技术,其核心在于通过数学映射建立键值与存储位置的直接关联。理想情况下时间复杂度可达O(1),实际应用中通过冲突处理机制实现近似常数时间的查找效率。…...

【powerjob】 powerjobserver注册服务IP错误
1、问题:powerjobserver 4.3.6 的服务器上有多个网卡对应多个ip,示例 eth0 :IP1 ,docker0:IP2 和worker 进行通信时 正确的应该时IP1 但是注册显示获取的确实IP2,导致 worker 通过ip2和server通信,网络不通,注册不上 2、解决方案 …...

Flutter底层实现
1. Dart 语言 Dart 是 Flutter 的主要编程语言。Dart 设计之初就是为了与 JavaScript 兼容,并且可以编译为机器代码运行。Dart 提供了一些特性,如异步支持(通过 async 和 await),这使得编写高效的网络请求和复杂动画变…...

亚信安全发布2024威胁年报和2025威胁预测
在当今数字化时代,网络空间已成为全球经济、社会和国家安全的核心基础设施。随着信息技术的飞速发展,网络连接了全球数十亿用户,推动了数字经济的蓬勃发展,同时也带来了前所未有的安全挑战。2024年,网络安全形势愈发复…...

【YOLOv12改进trick】StarBlock引入YOLOv12,创新涨点优化,含创新点Python代码,方便发论文
🍋改进模块🍋:StarBlock 🍋解决问题🍋:采用StarBlock将输入数据映射到一个极高维的非线性特征空间,生成丰富的特征表示,使得模型在处理复杂数据时更加有效。 🍋改进优势🍋:简单粗暴的星型乘法涨点却很明显 🍋适用场景🍋:目标检测、语义分割、自然语言处理…...

Android MVI架构模式详解
MVI概念 MVI(Model-View-Intent)是一种Android应用架构模式,旨在通过单向数据流和不可变性来简化应用的状态管理。MVI的核心思想是将用户操作、状态更新和界面渲染分离,确保应用的状态可预测且易于调试。 MVI的核心组件 Model&a…...

Spring AI Alibaba + Ollama:国产大模型DeepSeek LLM的低成本AI应用开发认知
写在前面 官方文档很详细,有开发需求可以直接看文档https://java2ai.com/docs/1.0.0-M5.1/get-started/博文内容为一个开发Demo,以及API简单认知理解不足小伙伴帮忙指正 😃,生活加油 我看远山,远山悲悯 持续分享技术干货…...

《2025软件测试工程师面试》功能测试篇
什么是功能测试? 功能测试是通过验证产品功能是否满足用户需求的过程,主要关注软件的功能是否符合需求规格说明,包括软件的各种功能、特性、性能、安全性和易用性等。 功能测试的流程包括哪些步骤? 需求分析:明确软件需求,确定测试范围。测试计划:制定详细的测试计划,…...

蓝桥杯2024年第十五届省赛真题-传送阵
题目描述 小蓝在环球旅行时来到了一座古代遗迹,里面并排放置了 n 个传送阵,进入第 i 个传送阵会被传送到第 ai 个传送阵前,并且可以随时选择退出或者继续进入当前传送阵。小蓝为了探寻传送阵中的宝物,需要选择一个传送阵进入&…...
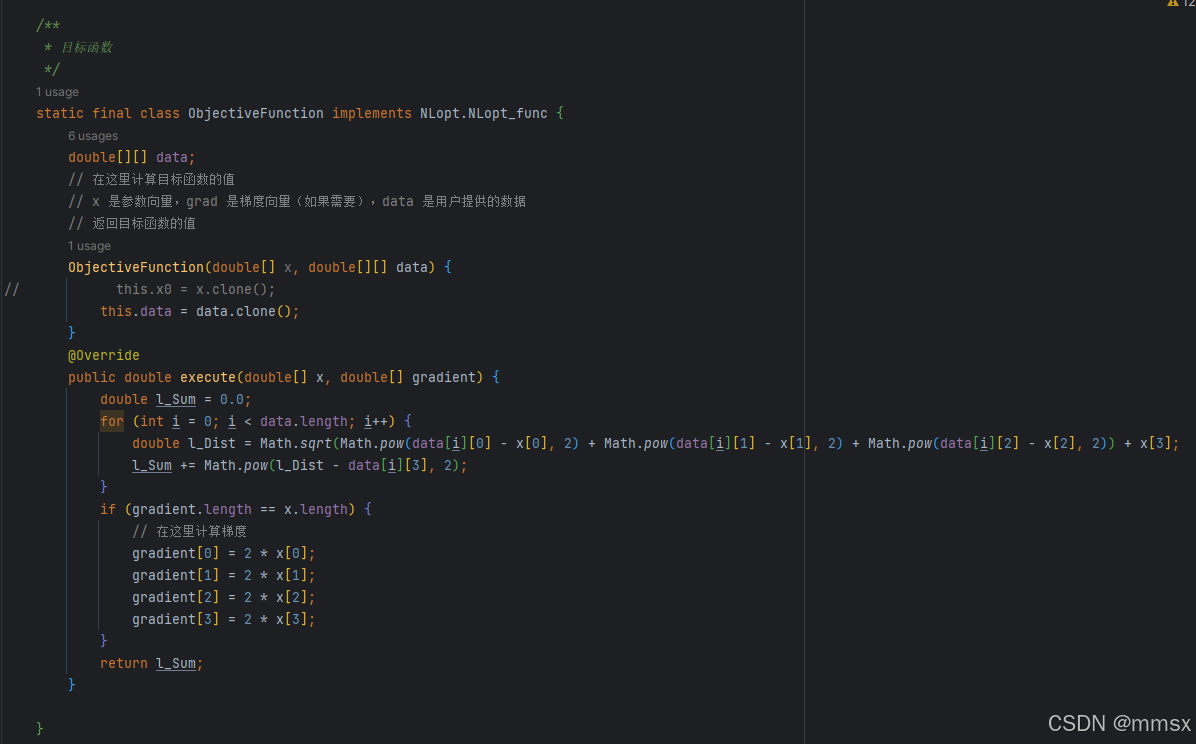
非线性优化--NLopt算法(Android版本和Python示例)
通俗一点来说 非线性优化就是求函数的极值。我们想求一个 函数的极值问题的时候,线性函数是最简单的,因为是线性的嘛,单调增或者单调减,那么找到边界就可以求到极值。例如 f(x)=ax+b。 简单的非线性函数也是很容易求得极值的,例如f(x)=x*x.可以通过求导得到极值点,然后求…...
)
2025-03-06 ffmpeg提取SPS/PPS/SEI ( extradata )
一、需求 在某些情况下,可能需要直接使用H264/H265等原始数据流进行解码,比较常用的udp下的h264/h265。这时需要 av_parser_parse2 来组AVPacket,但对于视频的信息:宽高、格式等,可以根据 AVCodecParserContext 来获取࿰…...

海量数据融合互通丨TiDB 在安徽省住房公积金监管服务平台的应用实践
导读 安徽省住房公积金监管服务平台通过整合全省 17 家公积金中心的数据,致力于实现数据共享、规范化管理与高效数据分析。为了应对海量数据处理需求,安徽省选择 TiDB 作为底层数据库,利用其分布式架构和 HTAP 能力,实现了快速的…...

深入解析 supervision 库:功能、用法与应用案例
1. 引言 在计算机视觉任务中,数据的后处理和可视化是至关重要的环节,尤其是在目标检测、分割、跟踪等任务中。supervision 是一个专门为这些任务提供高效数据处理和可视化支持的 Python 库。本文将深入介绍 supervision 的功能、使用方法,并…...
获取的空索引导致程序崩溃)
【DeepSeek问答】访问QStandardItemModel::index(r,c)获取的空索引导致程序崩溃
好的,我现在来仔细思考一下用户的问题。用户在使用QStandardItemModel的setItem方法时,调用了setItem(4,6,item),也就是在第4行第6列的位置设置了一个item。然后他们尝试通过index(3,6)来获取这个位置的项目,想知道会有什么后果。…...

从开源大模型工具Ollama存在安全隐患思考企业级大模型应用如何严守安全红线
近日,国家网络安全通报中心通报大模型工具Ollama默认配置存在未授权访问与模型窃取等安全隐患,引发了广泛关注。Ollama作为一款开源的大模型管理工具,在为用户提供便捷的同时,却因缺乏有效的安全管控机制,存在数据泄露…...

Aws batch task 无法拉取ECR 镜像unable to pull secrets or registry auth 问题排查
AWS batch task使用了自定义镜像,在提作业后出现错误 具体错误是ResourceInitializationError: unable to pull secrets or registry auth: The task cannot pull registry auth from Amazon ECR: There is a connection issue between the task and Amazon ECR. C…...

通用信息抽取大模型PP-UIE开源发布,强化零样本学习与长文本抽取能力,全面适配多场景任务
背景与简介 信息抽取(information extraction)是指,从非结构化或半结构化数据(如自然语言文本)中自动识别、提取并组织出结构化信息。通常包含多个子任务,例如:命名实体识别(NER&am…...
)
基于uniapp的蓝牙打印功能(佳博打印机已测试)
相关步骤 1.蓝牙打印与低功耗打印的区别2.蓝牙打印流程2.1 搜索蓝牙2.2 连接蓝牙 3.连接蓝牙设备4.获取服务5.写入命令源码gbk.jsglobalindex.ts 1.蓝牙打印与低功耗打印的区别 低功耗蓝牙是一种无线、低功耗个人局域网,运行在 2.4 GHz ISM 频段 1、低功耗蓝牙能够…...

【Azure 架构师学习笔记】- Azure Databricks (15) --Delta Lake 和Data Lake
本文属于【Azure 架构师学习笔记】系列。 本文属于【Azure Databricks】系列。 接上文 【Azure 架构师学习笔记】- Azure Databricks (14) – 搭建Medallion Architecture part 2 前言 ADB 除了UC 这个概念之外,前面【Azure 架构师学习笔记】- Azure Databricks (1…...

WPF高级 | WPF 应用程序部署与发布:确保顺利交付到用户手中
WPF高级 | WPF 应用程序部署与发布:确保顺利交付到用户手中 一、前言二、部署与发布基础概念2.1 部署的定义与目的2.2 发布的方式与渠道2.3 部署与发布的关键要素 三、WPF 应用程序打包3.1 使用 Visual Studio 自带的打包工具3.2 使用第三方打包工具 四、发布到不同…...

Real-ESRGAN-GUI 终极指南:免费AI图像增强工具如何让模糊照片重获高清新生
Real-ESRGAN-GUI 终极指南:免费AI图像增强工具如何让模糊照片重获高清新生 【免费下载链接】Real-ESRGAN-GUI Lovely Real-ESRGAN / Real-CUGAN GUI Wrapper 项目地址: https://gitcode.com/gh_mirrors/re/Real-ESRGAN-GUI 你是否曾为模糊的老照片感到无奈&a…...

3DS游戏格式转换实战指南:5步完成CCI到CIA的高效转换
3DS游戏格式转换实战指南:5步完成CCI到CIA的高效转换 【免费下载链接】3dsconv Python script to convert Nintendo 3DS CCI (".cci", ".3ds") files to the CIA format 项目地址: https://gitcode.com/gh_mirrors/3d/3dsconv 作为一名3…...

Sketchfab数据提取终极指南:打破在线3D模型下载壁垒的完整解决方案
Sketchfab数据提取终极指南:打破在线3D模型下载壁垒的完整解决方案 【免费下载链接】sketchfab sketchfab download userscipt for Tampermonkey by firefox only 项目地址: https://gitcode.com/gh_mirrors/sk/sketchfab 你是否曾在Sketchfab上发现完美的3D…...

使用mcp-maker快速构建AI工具调用服务器:从协议原理到工程实践
1. 项目概述与核心价值最近在折腾AI应用开发,特别是想给大语言模型(LLM)装上更强大的“手脚”,让它能直接操作我电脑上的各种软件和工具。这听起来很酷,对吧?但实际操作起来,你会发现一个核心痛…...

开源技能库构建指南:Git+Markdown+Docsify打造个人技术知识体系
1. 项目概述:一个开源技能库的诞生与价值在技术领域,尤其是软件开发、运维和数据分析等方向,我们每天都在与海量的工具、框架和命令打交道。时间一长,一个很现实的问题就摆在了面前:那些曾经花了好几个小时才调通的复杂…...

AI驱动全栈开发:Cursor集成模板与高效协作实践
1. 项目概述:当AI代码助手遇上全栈开发最近在GitHub上看到一个挺有意思的项目,叫“Cursor-FullStack-AI-App”。光看名字,你大概能猜到它和Cursor这个AI编程工具,以及全栈应用开发有关。作为一个在前后端都摸爬滚打过多年的开发者…...

AI全栈开发实战:基于Cursor的智能代码生成与架构设计
1. 项目概述:当AI代码助手遇上全栈开发最近在GitHub上看到一个挺有意思的项目,叫“Cursor-FullStack-AI-App”。光看名字,你大概能猜到它和Cursor这个AI代码编辑器有关,并且涉及全栈应用开发。但它的价值远不止于此。作为一个在前…...

开源婚礼技能库:用项目管理思维破解备婚焦虑,打造个性化高性价比婚礼
1. 项目概述:婚礼技能库的诞生与价值最近在GitHub上看到一个挺有意思的项目,叫“awesome-wedding-skills”。光看名字,你可能会觉得这又是一个普通的“awesome”系列资源列表,无非是收集一些婚礼策划、摄影、化妆的链接。但当我点…...

工控一体机电脑核心性能特征解析:从选型到部署的实战指南
1. 项目概述:为什么我们需要重新审视工控一体机电脑?在工业自动化、智能制造、智慧零售乃至边缘计算这些听起来高大上的领域里,有一类设备常常是幕后的“无名英雄”,它不像机器人手臂那样引人注目,也不像云端服务器那样…...
)
告别闪烁屏!瑞芯微RK3399开发板Debian系统烧写保姆级教程(含DriverAssistant v5.1.1 + AndroidTool v2.69)
RK3399开发板Debian系统烧写实战:从屏幕闪烁到完美显示的终极解决方案 当你在RK3399开发板上成功烧写Debian系统后,最期待的莫过于看到系统稳定运行的画面。然而,不少开发者却遭遇了屏幕闪烁的困扰——这个问题看似简单,背后却隐藏…...