【数据库】MySQL常见聚合查询详解
在数据库操作中,聚合查询是非常重要的一部分。通过聚合查询,我们可以对数据进行汇总、统计和分析。MySQL提供了丰富的聚合函数来满足不同的需求。本文将详细介绍MySQL中常见的40个聚合函数及其使用场景,并通过8个的案例展示它们的用法。
一、聚合函数的概念
聚合函数是对一组值执行计算并返回单个值的函数。它们通常用于SELECT语句中,与GROUP BY子句一起使用,以便对数据进行分组和汇总。
二、常见的40个聚合函数
以下是MySQL中常见的40个聚合函数及其使用场景:
| 聚合函数 | 描述 | 使用场景 |
|---|---|---|
COUNT() | 返回行数 | 统计记录数 |
SUM() | 返回数值列的总和 | 计算总和 |
AVG() | 返回数值列的平均值 | 计算平均值 |
MIN() | 返回列中的最小值 | 查找最小值 |
MAX() | 返回列中的最大值 | 查找最大值 |
GROUP_CONCAT() | 返回一组值的连接字符串 | 将多行数据合并为一个字符串 |
STD() | 返回数值列的标准差 | 计算标准差 |
VARIANCE() | 返回数值列的方差 | 计算方差 |
BIT_AND() | 返回按位与运算的结果 | 按位与运算 |
BIT_OR() | 返回按位或运算的结果 | 按位或运算 |
BIT_XOR() | 返回按位异或运算的结果 | 按位异或运算 |
JSON_ARRAYAGG() | 返回JSON数组 | 将多行数据合并为JSON数组 |
JSON_OBJECTAGG() | 返回JSON对象 | 将多行数据合并为JSON对象 |
VAR_POP() | 返回总体方差 | 计算总体方差 |
VAR_SAMP() | 返回样本方差 | 计算样本方差 |
STDDEV_POP() | 返回总体标准差 | 计算总体标准差 |
STDDEV_SAMP() | 返回样本标准差 | 计算样本标准差 |
COVAR_POP() | 返回总体协方差 | 计算总体协方差 |
COVAR_SAMP() | 返回样本协方差 | 计算样本协方差 |
CORR() | 返回相关系数 | 计算相关系数 |
MEDIAN() | 返回中位数 | 计算中位数 |
PERCENTILE_CONT() | 返回连续百分位数 | 计算连续百分位数 |
PERCENTILE_DISC() | 返回离散百分位数 | 计算离散百分位数 |
RANK() | 返回行的排名 | 计算行的排名 |
DENSE_RANK() | 返回行的密集排名 | 计算行的密集排名 |
ROW_NUMBER() | 返回行的序号 | 计算行的序号 |
NTILE() | 返回行的分桶号 | 计算行的分桶号 |
FIRST_VALUE() | 返回窗口中的第一个值 | 获取窗口中的第一个值 |
LAST_VALUE() | 返回窗口中的最后一个值 | 获取窗口中的最后一个值 |
LAG() | 返回前一行中的值 | 获取前一行中的值 |
LEAD() | 返回后一行中的值 | 获取后一行中的值 |
CUME_DIST() | 返回累积分布 | 计算累积分布 |
PERCENT_RANK() | 返回百分比排名 | 计算百分比排名 |
NTH_VALUE() | 返回窗口中的第N个值 | 获取窗口中的第N个值 |
JSON_EXTRACT() | 返回JSON文档中的值 | 提取JSON文档中的值 |
JSON_UNQUOTE() | 返回JSON文档中的未引用值 | 提取JSON文档中的未引用值 |
JSON_CONTAINS() | 返回JSON文档是否包含指定值 | 检查JSON文档是否包含指定值 |
JSON_CONTAINS_PATH() | 返回JSON文档是否包含指定路径 | 检查JSON文档是否包含指定路径 |
JSON_KEYS() | 返回JSON文档中的键 | 提取JSON文档中的键 |
JSON_LENGTH() | 返回JSON文档的长度 | 计算JSON文档的长度 |
三、聚合查询的案例
1. 创建示例表
首先,我们创建一个示例表sales,用于演示各种聚合查询。
CREATE TABLE sales (id INT AUTO_INCREMENT PRIMARY KEY,product_name VARCHAR(50),quantity INT,price DECIMAL(10, 2),sale_date DATE
);INSERT INTO sales (product_name, quantity, price, sale_date) VALUES
('Apple', 10, 1.50, '2023-01-01'),
('Banana', 20, 0.50, '2023-01-01'),
('Apple', 15, 1.50, '2023-01-02'),
('Banana', 25, 0.50, '2023-01-02'),
('Orange', 30, 0.75, '2023-01-03'),
('Orange', 35, 0.75, '2023-01-04');
2. 使用COUNT()统计记录数
-- 统计总记录数
SELECT COUNT(*) AS total_records FROM sales;-- 统计不同产品的记录数
SELECT product_name, COUNT(*) AS product_count
FROM sales
GROUP BY product_name;
输出结果:
+---------------+
| total_records |
+---------------+
| 6 |
+---------------++--------------+---------------+
| product_name | product_count |
+--------------+---------------+
| Apple | 2 |
| Banana | 2 |
| Orange | 2 |
+--------------+---------------+
3. 使用SUM()计算总和
-- 计算所有产品的总销售额
SELECT SUM(quantity * price) AS total_sales FROM sales;-- 计算每个产品的总销售额
SELECT product_name, SUM(quantity * price) AS total_sales
FROM sales
GROUP BY product_name;
输出结果:
+-------------+
| total_sales |
+-------------+
| 83.75 |
+-------------++--------------+-------------+
| product_name | total_sales |
+--------------+-------------+
| Apple | 37.50 |
| Banana | 22.50 |
| Orange | 48.75 |
+--------------+-------------+
4. 使用AVG()计算平均值
-- 计算所有产品的平均销售额
SELECT AVG(quantity * price) AS average_sales FROM sales;-- 计算每个产品的平均销售额
SELECT product_name, AVG(quantity * price) AS average_sales
FROM sales
GROUP BY product_name;
输出结果:
+---------------+
| average_sales |
+---------------+
| 13.958333 |
+---------------++--------------+---------------+
| product_name | average_sales |
+--------------+---------------+
| Apple | 18.750 |
| Banana | 11.250 |
| Orange | 24.375 |
+--------------+---------------+
5. 使用MIN()和MAX()查找最小值和最大值
-- 查找所有产品的最小和最大销售额
SELECT MIN(quantity * price) AS min_sales, MAX(quantity * price) AS max_sales
FROM sales;-- 查找每个产品的最小和最大销售额
SELECT product_name, MIN(quantity * price) AS min_sales, MAX(quantity * price) AS max_sales
FROM sales
GROUP BY product_name;
输出结果:
+-----------+-----------+
| min_sales | max_sales |
+-----------+-----------+
| 10.00 | 26.25 |
+-----------+-----------++--------------+-----------+-----------+
| product_name | min_sales | max_sales |
+--------------+-----------+-----------+
| Apple | 15.00 | 22.50 |
| Banana | 10.00 | 12.50 |
| Orange | 22.50 | 26.25 |
+--------------+-----------+-----------+
6. 使用GROUP_CONCAT()合并字符串
-- 合并所有产品的名称
SELECT GROUP_CONCAT(product_name) AS all_products FROM sales;-- 合并每个销售日期的产品名称
SELECT sale_date, GROUP_CONCAT(product_name) AS products_sold
FROM sales
GROUP BY sale_date;
输出结果:
+---------------------------+
| all_products |
+---------------------------+
| Apple,Banana,Apple,Banana,Orange,Orange |
+---------------------------++------------+---------------------+
| sale_date | products_sold |
+------------+---------------------+
| 2023-01-01 | Apple,Banana |
| 2023-01-02 | Apple,Banana |
| 2023-01-03 | Orange |
| 2023-01-04 | Orange |
+------------+---------------------+
7. 使用STD()和VARIANCE()计算标准差和方差
-- 计算所有销售额的标准差和方差
SELECT STD(quantity * price) AS std_sales, VARIANCE(quantity * price) AS variance_sales
FROM sales;-- 计算每个产品销售额的标准差和方差
SELECT product_name, STD(quantity * price) AS std_sales, VARIANCE(quantity * price) AS variance_sales
FROM sales
GROUP BY product_name;
输出结果:
+------------+----------------+
| std_sales | variance_sales |
+------------+----------------+
| 6.614378 | 43.750000 |
+------------+----------------++--------------+------------+----------------+
| product_name | std_sales | variance_sales |
+--------------+------------+----------------+
| Apple | 3.750000 | 14.062500 |
| Banana | 1.250000 | 1.562500 |
| Orange | 1.875000 | 3.515625 |
+--------------+------------+----------------+
8. 使用BIT_AND()、BIT_OR()和BIT_XOR()进行位运算
-- 计算quantity列的按位与、按位或和按位异或
SELECT BIT_AND(quantity) AS bit_and, BIT_OR(quantity) AS bit_or, BIT_XOR(quantity) AS bit_xor
FROM sales;
输出结果:
+---------+--------+---------+
| bit_and | bit_or | bit_xor |
+---------+--------+---------+
| 0 | 35 | 15 |
+---------+--------+---------+
四、总结
通过本文的介绍和案例,我们详细了解了MySQL中常见的聚合函数及其使用场景。这些聚合函数在数据分析和统计中非常有用,能够帮助我们快速获取数据的汇总信息。掌握这些聚合查询的技巧,将使你在数据库操作中更加得心应手。
相关文章:

【数据库】MySQL常见聚合查询详解
在数据库操作中,聚合查询是非常重要的一部分。通过聚合查询,我们可以对数据进行汇总、统计和分析。MySQL提供了丰富的聚合函数来满足不同的需求。本文将详细介绍MySQL中常见的40个聚合函数及其使用场景,并通过8个的案例展示它们的用法。 一、…...
蓝桥备赛(11)- 数据结构、算法与STL
一、数据结构 1.1 什么是数据结构? 在计算机科学中,数据结构是一种 数据组织、管理和存储的格式。它是相互之间存在一种 或多种特定关系的数据元素的集合。 ---> 通俗点,数据结构就是数据的组织形式 , 研究数据是用什么方…...

Linux的系统ip管理
ip地址 命令:ifconfig 127.0.0.1这个ip地址用于指本机。 0.0.0.0特殊ip地址用于指代本机,可以在端口绑定中用来确定绑定关系,在一些ip地址限制中,表示所有ip的意思。如放行规则设置为0.0.0.0,表示允许任意ip访问。 …...

【决策树】分类属性的选择
文章目录 1.信息增益(ID3)2.信息增益率(C4.5)3.基尼指数(CART)ps.三者对比 实现决策树算法最关键的一点就是如何从所有的特征属性中选择一个最优的属性对样本进行分类,这种最优可以理解为希望划…...
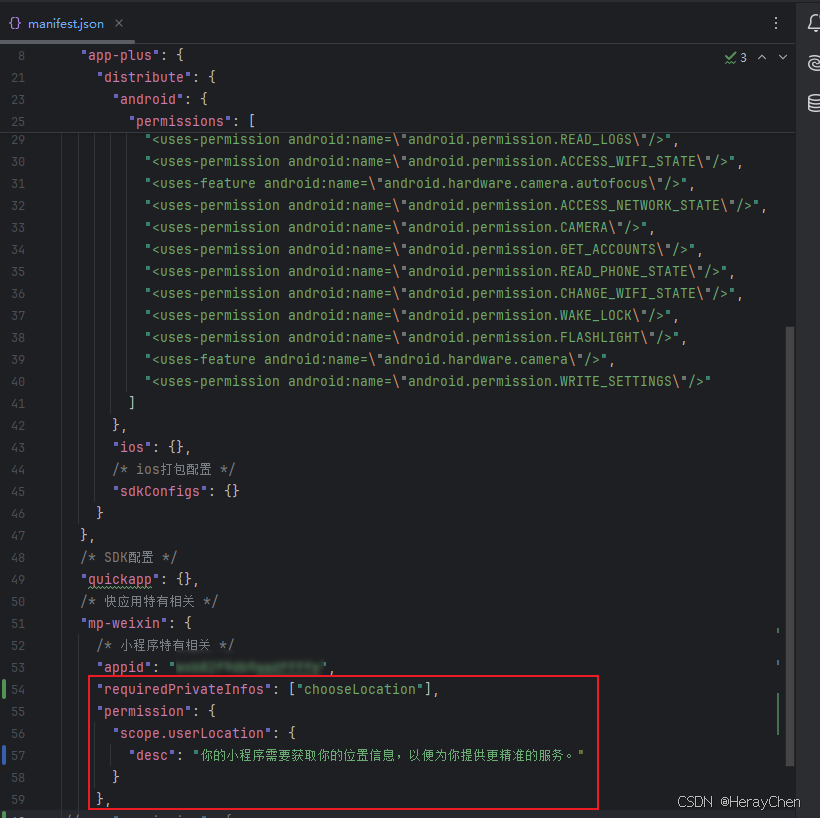
uniapp vue3 微信小程序 uni.chooseLocation使用
申请 先要去微信公众平台申请使用接口 开通成功之后就可以在项目中配置使用了 配置 配置manifest.json "mp-weixin": {/* 小程序特有相关 */"requiredPrivateInfos": ["chooseLocation"],"permission": {"scope.userLocati…...

9. Flink的性能优化
1. Flink的资源和代码优化 1.1 slot资源配置 Flink中具体跑任务的进程叫TaskManager,TM进程又会根据配置划分出诺干个TaskSlot,它是具体运行SubTask的地方。slot是Flink用来隔离各个subtask的资源集合,这里的资源一把指内存,TCP…...

十二、OSG学习笔记-Control
上一章节: 十一、OSG学习笔记-操作系统接口-CSDN博客https://blog.csdn.net/weixin_36323170/article/details/145891502 本章节代码: OsgStudy/Controls CuiQingCheng/OsgStudy - 码云 - 开源中国https://gitee.com/cuiqingcheng/osg-study/tree/ma…...

集群、分布式与微服务架构 区别
集群、分布式与微服务架构:概念解析与核心差异 在构建现代软件系统时,集群架构、分布式系统和微服务架构是三种常见的技术方案。它们常被混淆,但各自解决的问题、设计理念和应用场景截然不同。本文将从基础概念出发,深入分析三者…...

如何使用SSH命令安全连接并转发端口到远程服务器
ssh -p 22546 rootconnect.westc.gpuhub.com d6IS/mQKq/iG ssh -CNgv -L 6006:127.0.0.1:6006 rootconnect.westc.gpuhub.com -p 22546 第一条命令:用于登录远程服务器,进行交互式操作。第二条命令:用于建立 SSH 隧道,进行端口转…...

【Java 基础】-- 设计模式
目录 Java 设计模式详解 1. 设计模式定义 2. 设计模式示例 2.1 单例模式(Singleton Pattern) 2.2 工厂模式(Factory Pattern) 2.3 观察者模式(Observer Pattern) 2.4 代理模式(Proxy Pat…...
)
ComfyUI进阶学习全指南(2025年最新版)
ComfyUI进阶学习全指南(2025年最新版) 一、自定义节点与扩展管理 1.1 自定义节点安装与维护 ComfyUI的核心竞争力在于其可扩展性。通过安装第三方节点模块,用户可实现超分辨率修复、骨骼绑定动画生成等高级功能。安装方式主要分为三种&…...

Linux和gcc/g++常用命令总结
目录 Linux命令总结 文件操作相关命令 ls cd pwd cp mv rm cat mkdir rmdir touch 文本处理操作命令 grep awk sed 进程管理操作相关命令 ps top htop kill pkill killall chmod chown 网络操作相关命令 ping ifconfig netstat ss lsof curl …...
)
uniapp封装路由管理(兼容Vue2和Vue3)
1:uniapp已经有路由管理了为什么还要二次封装路由? 简化配置和调用增强灵活性和可扩展性实现统一的功能和策略提升开发效率和团队协作 2. 增强灵活性和可扩展性 灵活配置:二次封装允许开发者根据实际需求灵活配置路由参数,如跳…...
π0源码解析——一个模型控制7种机械臂:对开源VLA sota之π0源码的全面分析,含我司的部分落地实践
前言 ChatGPT出来后的两年多,也是我疯狂写博的两年多(年初deepseek更引爆了下),比如从创业起步时的15年到后来22年之间 每年2-6篇的,干到了23年30篇、24年65篇、25年前两月18篇,成了我在大模型和具身的原始技术积累 如今一转眼…...

【C++】Class(1)
《C程序设计基础教程》——刘厚泉,李政伟,二零一三年九月版,学习笔记 文章目录 1、类的定义1.1、结构体和类1.2、基本概念1.3、成员函数的定义1.4、内联成员函数 2、对象2.1、对象的定义2.2、成员访问 3、构造函数3.1、构造函数的定义3.2、子…...

doris: Oracle
Apache Doris JDBC Catalog 支持通过标准 JDBC 接口连接 Oracle 数据库。本文档介绍如何配置 Oracle 数据库连接。 使用须知 要连接到 Oracle 数据库,您需要 Oracle 19c, 18c, 12c, 11g 或 10g。 Oracle 数据库的 JDBC 驱动程序,您可以从 Maven 仓库…...

Android14 OTA差分包升级报Package is for source build
制作好差分包,使用adb线刷模式验证ota升级,出现E:Package is for source build错误 使用adb方式验证 进入recovery模式 adb reboot recovery稍等一会界面会提示 Now send the package you want to apply to the device with "adb sidelaod <…...

双向选择排序算法
一 概述 双向选择排序(又称鸡尾酒选择排序)是选择排序的优化版本,核心改进在于每轮遍历同时确定未排序部分的最小值和最大值,分别交换到序列两端,从而减少遍历轮数。 二 时间复杂度 时间复杂度为(O(n^2)),但实际比较次数约为标准选择排序的 (1/2)。 三 C++实现代…...

Node.js setImmediate 教程
Node.js setImmediate 教程 简介 setImmediate() 是 Node.js 环境中的一个函数,用于安排一个回调函数在当前事件循环周期结束后立即执行。它提供了一种在当前操作完成后,但在任何 I/O 事件或定时器触发之前执行代码的方法。 基本用法 setImmediate((…...

MyBatis @Param 注解详解:多参数传递与正确使用方式
Param 注解主要用于 MyBatis 进行参数传递时给 SQL 语句中的参数 起别名,通常用于 多参数 方法,使参数在 XML Mapper 文件或注解 SQL 语句中更清晰易用。 1. 基本用法 在 Mapper 接口中使用 Param 来为参数命名,避免 MyBatis 解析时出现参数…...

从《西部世界》到现实:AI智能体如何重塑游戏NPC与虚拟社会?
从《西部世界》到现实:AI智能体如何重塑游戏NPC与虚拟社会? 当《西部世界》中的NPC开始拥有记忆、情感和自主决策能力时,观众惊叹于科幻与现实的边界正在模糊。如今,大型语言模型(LLM)驱动的AI智能体正将这…...

proxy-doctor:自动化诊断与修复开发工具代理配置的利器
1. 项目概述与核心价值最近在折腾一些需要稳定网络连接的项目时,遇到了一个老生常谈但又极其恼人的问题:代理配置。无论是开发环境里的包管理工具,还是日常使用的命令行工具,一旦涉及到网络请求,代理设置不对ÿ…...

探索Windows HEIC缩略图:跨平台照片管理深度解析
探索Windows HEIC缩略图:跨平台照片管理深度解析 【免费下载链接】windows-heic-thumbnails Enable Windows Explorer to display thumbnails for HEIC/HEIF files 项目地址: https://gitcode.com/gh_mirrors/wi/windows-heic-thumbnails Windows HEIC缩略图…...

5分钟快速上手:使用res-downloader实现视频号批量下载的终极指南
5分钟快速上手:使用res-downloader实现视频号批量下载的终极指南 【免费下载链接】res-downloader 视频号、小程序、抖音、快手、小红书、直播流、m3u8、酷狗、QQ音乐等常见网络资源下载! 项目地址: https://gitcode.com/GitHub_Trending/re/res-downloader …...

AI智能体记忆系统设计:从RAG到长期记忆的工程实践
1. 项目概述:从“记忆”到“智能”的跨越在AI智能体(Agent)的开发浪潮中,我们常常面临一个核心挑战:如何让智能体在复杂的、多轮次的交互中,表现得像一个真正有“记忆”和“经验”的专家?传统的…...

Unity区域加载系统:实现开放世界无缝加载与内存优化
1. 项目概述:一个高效、可扩展的Unity区域加载系统 最近在做一个开放世界风格的项目,场景大了之后,加载卡顿和内存管理就成了老大难问题。传统的Unity场景加载,要么一股脑全塞进内存,要么就得自己写一堆脚本来手动控制…...

Git安全增强实战:使用Ante实现策略即代码的版本控制防护
1. 项目概述:一个为开发者打造的“代码保险箱”如果你和我一样,在职业生涯中经历过几次“代码灾难”——比如不小心git push -f覆盖了同事的提交,或者手滑rm -rf删除了一个正在开发中的功能分支——那你一定会对“代码安全”这四个字有切肤之…...

Cursor-Tap插件:一键AI代码重构与文档生成实战指南
1. 项目概述:一个为 Cursor 编辑器注入灵魂的插件如果你和我一样,日常重度依赖 Cursor 这款 AI 驱动的代码编辑器,那你一定体会过那种“就差一点”的微妙感受。Cursor 的 AI 能力确实强大,但它的交互方式有时会让人感觉像是在和一…...

ESP32-S2 Reverse TFT Feather开发板深度解析:从核心硬件到物联网项目实战
1. 项目概述:为什么选择ESP32-S2 Reverse TFT Feather?如果你正在寻找一款能让你快速搭建物联网设备原型,尤其是那些需要一块漂亮屏幕来交互或显示信息的项目,那么ESP32-S2 Reverse TFT Feather绝对是一个值得你花时间研究的开发板…...

大语言模型分步推理与自我验证框架:提升AI生成准确性的工程实践
1. 项目概述:当AI学会“自我验证”最近在开源社区里,一个名为“Lets-Verify-Step-by-Step”的项目引起了我的注意。这个项目直指当前大语言模型(LLM)应用中的一个核心痛点:如何让模型在生成复杂答案时,能像…...