HiveServer2与Spark ThriftServer详细介绍对比
HiveServer2与Spark ThriftServer详细介绍对比
1、概述
1.1 HiveServer2 是 Apache Hive 提供的基于 Thrift 的服务进程,用于让远程客户端执行 Hive SQL 查询 ([一起了解一下HiveServer2 - zourui4271 - 博客园]。它是早期 HiveServer1 的改进版本,引入了多客户端并发连接、会话管理和身份认证等功能,解决了 HiveServer1 只能单线程服务单个客户端、缺乏认证等局限 ,HiveServer2 通过 JDBC/ODBC 接口为外部应用提供访问 Hive 数据仓库的能力,当客户端提交 SQL 请求时,HiveServer2 接收请求并将其解析、编译为底层的执行计划,最终在 Hadoop 集群上运行并返回结果。不启动HiveServer2服务,就没有10000端口,JDBC、ODBC客户端就连接不上Hive。从使用者的角度理解这就够了。如果要deep dive一下,HiveServer2的功能不止这些。我们知道:如果把Hive整体当做一个黑盒,则它的输入是用户提交的sql,它的输出是提交后的MR作业,用 一句概括Hive的功能就是:将sql语句“转译”成MR作业,这实际上也正是HiveServer2的主要工作内容。更加细致一点的表述是:一般客户端会使用Hive的 JDBC驱动连接到Hiveserver2。Hiveserver2通过Thrift,和优化,在这个过程中Hive server2需要跟HiveMetastore服务通信以得到数据库和数据表的元数据,HiveMetastore服务会将数据库的元数据信息存储到数据库中。最终Hiveserver2将SQL编译为MapReduce作业运行在MapReduce、Tez、Spark分布式计算引擎上。HiveMetastore和HiveServer2都是独立运行的服务,对外提供基于Thrift协议的服务接口。
1.2 Spark ThriftServer(STS)是 Spark 社区基于 HiveServer2 实现的一个Thrift 服务,旨在提供与HiveServer2 完全兼容 的接口和协议,但使用 Spark 作为底层计算引擎 ,换言之,Spark ThriftServer 对 HiveServer2 的代码进行了扩展改造,使其能够调用 Spark SQL 来执行查询,同时仍然支持使用 Hive 的 JDBC 客户端(如 Beeline)连接并提交 SQL,Spark ThriftServer 和 HiveServer2 一样可以与 Hive Metastore 交互,复用 Hive 的元数据存储,以无缝访问 Hive 的表和数据,可以直接使用hive的beeline访问Spark Thrift Server执行相关语句。通过 Spark ThriftServer,用户能够以纯 SQL 的方式利用 Spark 集群的内存计算能力,从而在许多场景下获得比 Hive 更高的查询性能。
2、架构分析
2.1 HiveServer2 的架构与工作原理
HiveServer2 采用典型的客户端/服务端架构,由服务端进程统一监听客户端请求并进行处理。HiveServer2 服务启动后,会通过 Thrift 接口在默认端口(10000)监听来自 JDBC/ODBC 客户端的连接。当客户端(如 Beeline CLI 或 BI 工具)发起 SQL 查询请求时,请求首先由 HiveServer2 的 Thrift 服务模块 (ThriftCLIService) 接收,然后委托给内部的CLI 服务层 (CLIService) 进一步处理 [Spark Thrift Server 架构和原理介绍-CSDN博客]。CLI Service 再将请求交由 HiveServer2 内部的 OperationManager,后者会根据请求类型创建对应的操作对象(例如查询对应 SQLOperation)来执行实际的逻辑。在这一过程中,HiveServer2 会为每个客户端连接创建独立的会话(Session)和执行上下文,确保多用户并发查询的隔离。每个会话都有自己专属的编译器和执行器(即 Hive 的 Driver 实例),用于处理该会话提交的SQL语句的解析、优化和执行。HiveServer2 在解析查询时需要通过 Hive Metastore 服务获取元数据,如表的模式和分区信息,然后对SQL 进行语法分析、查询优化,生成逻辑和物理执行计划,作业完成后,HiveServer2 收集结果或结果的指针,将查询结果返回给客户端。HiveServer2 本身不存储数据,数据仍然存储在 HDFS 等底层存储中,HiveServer2 充当的是SQL请求的解析者和任务调度者角色。
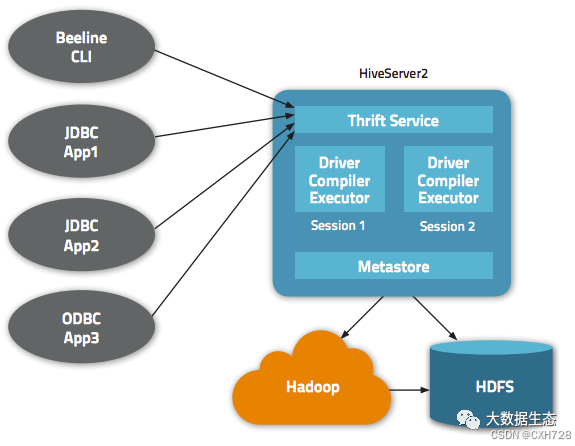
HiveServer2 架构示意图。如上图所示,多个客户端(例如 Beeline CLI、本地或远程的 JDBC/ODBC 应用)可以通过 Thrift 接口连接到 HiveServer2。HiveServer2 内部为每个客户端连接创建独立的会话(Session),并在每个会话中维护查询的编译和执行组件(即 Hive 的 Driver/Compiler/Executor) 与 HiveServer1 一样,HiveServer2 也是 Hive,请求。新的 RPC 接口使服务器可以将 Hive 执行上下文与处理客户端请求的线程相关联。))。HiveServer2 与 Hive MetaStore 服务交互获取元数据(表结构、分区信息等),编译优化 SQL 查询后,将物理计划提交给底层 Hadoop 集群执行(例如运行在 YARN 上的 MapReduce、Tez 或 Spark 引擎)底层计算引擎在 HDFS 上扫描和处理数据,计算完成后由 HiveServer2 收集结果并返回给客户端。通过这种架构,HiveServer2 实现了 SQL 到大数据作业的转换,使用户能够以 SQL 查询的方式分析海量数据。
2.2 Spark ThriftServer 的架构与工作原理
Spark ThriftServer 在架构上与 HiveServer2 相似,同样提供 Thrift 接口来接受客户端的 JDBC/ODBC 请求,并使用 Hive Metastore 获取元数据。实际上,Spark ThriftServer 重用了 大量 HiveServer2 的代码,只是替换了其中执行查询的部分逻辑,使其在 Spark 上运行。Spark ThriftServer 启动时,本质上会通过 spark-submit 将一个长期运行的 Spark 应用提交到集群中,即 Spark ThriftServer 服务进程本身就是一个在集群上以 Driver 角色运行的 Spark 应用。与 HiveServer2 针对每个查询提交独立YARN任务的做法不同,Spark ThriftServer 以单个 Spark Application 形式常驻,所有客户端会话共享同一个 Spark Driver 和资源上下文。当 Spark ThriftServer 收到 SQL 查询时,内部会使用自己的 SparkSQLCLIService 和 SparkExecuteStatementOperation 等组件将请求交由 Spark SQL 引擎处理:具体而言,Spark ThriftServer 从 HiveServer2 框架接管了查询执行操作,在拿到 SQL 后,直接调用 Spark 的 SQLContext 或 SparkSession 来解析执行该 SQL。这样,每个查询被转换为对 Spark SQL 的调用,由 Spark 引擎生成优化的执行计划并以 RDD/Dataset 作业形式并行执行于集群内的 Executor 节点。由于 Spark ThriftServer 作为一个 Spark Driver 长时间运行,所有会话共享同一个 SparkContext,因此可以避免重复的作业初始化开销,并利用 Spark 内存缓存等特性提升性能。但这种架构也意味着单点特性:如果该 Spark ThriftServer 进程(Driver)发生故障,所有正在进行的查询都会中断,所有会话都将失去连接 。另外,Spark ThriftServer 默认并没有内置高可用机制来支持多个实例的容错。总体而言,Spark ThriftServer将HiveServer2 的前端功能与 Spark 强大的分布式内存计算后端结合起来,在保持接口不变的情况下,提供了潜在更高的查询执行效率。
3、对比分析
3.1 底层计算引擎:HiveServer2 依赖 Hive 自身的查询引擎执行计划,在传统模式下通常运行 MapReduce 或 Tez 任务来完成计算(最新的 Hive 还支持直接使用 Spark 执行,即 Hive on Spark 模式)。相比之下,Spark ThriftServer 完全基于 Spark SQL 引擎运行,利用 Spark 的内存计算模型和 DAG 执行机制加速查询。因此,对于相同的SQL查询,Spark ThriftServer 通常能够充分利用内存和缓存机制,在迭代计算和复杂查询上比 Hive(尤其基于MapReduce的Hive)更快。尤其当数据采用了列式存储格式如 ORC、Parquet 时,Spark ThriftServer 上查询性能往往比 HiveServer2 高出数倍,在某些复杂语句上甚至快几十倍 。不过在数据格式较简单(例如纯文本)或查询较简单的情况下,两者性能差距不大,有时 Hive 在特定场景下反而表现更好 。总体上,Spark 引擎擅长低延迟的交互式查询,而 Hive 引擎在长批处理任务上也经过了多年的优化。
3.2 查询方式与兼容性:HiveServer2 提供的 HiveQL 语法基本兼容 ANSI SQL 2003 标准,并扩展了许多特定于 Hive 的语法特性(如对复杂数据类型、自定义函数等的支持)。Spark SQL 在语法层面与 HiveQL 相似度很高,但并非完全兼容。Spark ThriftServer 对绝大部分 Hive SQL 都能支持,但某些极端或特殊的 HiveQL 语法可能并不被 Spark 完全支持,需要根据具体版本进行测试。此外,Hive 生态中一些传统功能(如宏、索引等)在 Spark SQL 中可能缺失。然而,在日常的大多数查询场景下,两者的SQL用法几乎一致,Spark SQL 也在不断追赶并扩展标准 SQL 支持。
3.3 资源调度与并发:HiveServer2 本身并不执行计算,而是将每个查询作为任务提交给底层引擎(MapReduce/Tez)运行。每个查询通常对应一个或多个YARN应用,集群可以根据资源情况并行调度多个Hive查询。因此,在 Hive 中不同查询之间的资源隔离较为清晰,某个大型查询占用大量资源通常不会阻塞HiveServer2 接受其他查询,只要集群资源和队列策略允许,查询可以同时进行。但HiveServer2 默认有线程池来处理客户端请求,过多并发请求可能会受限于线程池大小或队列等待。Spark ThriftServer 则所有会话共享一个 Spark 应用(Driver),所有查询在同一个YARN上下文中执行 。这种模式下,并发查询实际上共享Spark应用的固定资源池:如果一个查询非常耗资源,它可能会占满 Spark ThriftServer 分配的执行内核和内存,导致其他查询变慢甚至排队等待。因此,Spark ThriftServer 在高并发场景下需要依赖 Spark 内部的任务调度(如公平调度器)和YARN的资源调控来平衡不同会话的查询。而 HiveServer2 借助YARN调度,不同查询可以在不同的YARN容器中执行,更易实现隔离。不过需要注意,Spark ThriftServer 也支持开启动态资源分配,但在很多集群中仍会设定Spark应用的资源上限,难以像 Hive 那样随需扩展到整个集群。这一差异意味着对于多租户、多任务并发的场景,HiveServer2 能通过集群调度更细粒度地隔离不同作业,而 Spark ThriftServer 则可能在单一应用内竞争资源。
3.4 容错与高可用:HiveServer2 支持通过 ZooKeeper 实现高可用集群部署——可以启动多个 HiveServer2 实例,共同注册到 ZooKeeper,当一个实例故障时客户端可自动连接到其他实例,实现故障切换。很多生产环境会启动 HiveServer2 集群来承载高并发请求。相较之下,开源版的 Spark ThriftServer 没有内置的高可用机制 。因为 Spark ThriftServer 作为一个长期运行的 Spark 应用,Spark 本身并未提供像 HiveServer2 那样的多活部署支持。一旦Spark ThriftServer 进程挂掉,所有连接都将中断,需要人工或监控系统重新启动服务。社区中曾提出相应改进(如 SPARK-11100 提供了支持 HA 的补丁),以及衍生出了诸如 Kyuubi 等增强版的 Spark SQL 服务来解决高可用和多租户问题,但原生 Spark ThriftServer 部署在可靠性方面仍略显不足。这也是在企业生产环境中选择 Spark ThriftServer 需要慎重考虑的问题之一。
3.5 实际应用场景区别:在大数据行业中,HiveServer2 和 Spark ThriftServer 往往被用于不同的典型场景。HiveServer2 更常见于传统数据仓库和离线批处理场景,例如周期性的大规模 ETL 作业、报表生成和历史数据分析。Hive 优秀地支持超大规模数据集(PB 级别)的处理和存储,依托Hadoop成熟的存储和调度体系,适合对执行延迟不敏感但需要吞吐量和可靠性的任务。很多企业的数据仓库架构使用 Hive 来执行每日/每周的批量作业,其稳定性和与Hadoop生态的集成是主要考虑 。Spark ThriftServer 则更适合交互式分析和即席查询场景。例如数据分析师使用 BI 工具或 Notebook 直接查询数据湖中的内容,要求秒级到分级的响应时间;或者构建实时数据服务,通过 JDBC 接口提供给上层应用快速执行聚合查询。Spark ThriftServer 利用 Spark 内存计算加速,这类场景下能够显著缩短查询延迟,让大数据分析更接近实时。据实践经验,一些企业会在数据探索、临时查询、机器学习特征提取等需要多次迭代扫描大量数据的情况下使用 Spark ThriftServer,以充分利用内存计算优势,提高交互体验。值得注意的是,随着 Spark SQL 日益成熟,不少企业开始让 Spark 承担更多数据仓库查询的工作,甚至出现 HiveServer2 仅作为元数据服务、查询主要由 Spark SQL 完成的架构趋势。不过,在数据量特别庞大或需要复杂SQL特性的场景下,HiveServer2 仍然是稳健的选择,而 Spark ThriftServer 则提供了在交互分析方面替代 Hive 的一个选项。
4、适用场景分析
4.1 适合使用 HiveServer2 的场景:HiveServer2 更适用于大规模批处理和传统数仓场景。当业务需求涉及对海量历史数据进行定期计算(如日/月度报表、离线指标汇总)、或者长时间运行的复杂 ETL 时,HiveServer2 是理想的选择。它能够充分发挥 Hadoop 集群的批处理能力,利用 Hive 对复杂SQL(包括多表JOIN、窗口函数等)的支持和优化来保证即使数据规模极大也能可靠完成任务。例如,在一个每日用户行为日志的离线统计任务中,可以使用 HiveServer2 提交如下的 SQL 来计算每日各平台的活跃用户数和操作次数,并将结果存储到数据仓库表中:
-- 在 Hive 上执行大规模离线汇总统计
INSERT OVERWRITE TABLE daily_user_activity
SELECT date,platform,COUNT(DISTINCT user_id) AS active_users,COUNT(*) AS total_actions
FROM raw_user_event_log
WHERE date = '2025-03-01'
GROUP BY date, platform;
上述示例中,HiveServer2 接收到 SQL 后会进行解析和优化,然后将其转化为 MapReduce/Tez 任务在集群中执行,把海量 raw_user_event_log 日志表按日期和平台聚合。HiveServer2 擅长这类批量汇总场景,依赖其稳定的执行计划优化和成熟的容错机制,确保任务能够在数据规模扩展时依然顺利完成。特别是对于数据规模在数十TB甚至PB级别的批处理,HiveServer2 所在的 Hive 体系在业内有大量成功案例,因而成为许多大数据团队构建离线数仓的首选 。
4.2 适合使用 Spark ThriftServer 的场景:Spark ThriftServer 适用于对查询延迟要求高、需要交互式分析的大数据应用场景。当业务需要对大数据进行探索式查询、即席分析,或者为上层实时应用提供快速响应的统计结果时,Spark ThriftServer 能发挥优势。例如,数据分析师希望即时查询最近一小时的业务数据,或业务系统需要动态查询当日的交易排行榜,此时 Spark ThriftServer 提供的高速 SQL 引擎可以满足需求。典型情况下,Spark ThriftServer 会预先启动并分配一定的计算资源供多个用户共享使用。如下示例展示了通过 Spark ThriftServer 执行一条交互查询的SQL,该查询即时统计某电商平台当日销量最高的几个商品:
-- 在 Spark ThriftServer 上执行交互式查询
SELECT product_id, SUM(sales_amount) AS total_sales
FROM ecommerce_sales
WHERE sale_date = '2025-03-03'
GROUP BY product_id
ORDER BY total_sales DESC
LIMIT 10;
通过 Spark ThriftServer,这样的聚合排序查询可以在内存中快速完成,返回 Top 10 热销商品及其销售额。如上所示的场景中数据量可能仍然很大(例如 ecommerce_sales 表包含当日所有明细销量数据),但 Spark 可以将计算分布到集群内存中并进行高效聚合,通常能够在数秒至数十秒内返回结果,显著优于传统 Hive 执行同样查询所需的时间。因此,在需要低延迟和高吞吐并重的分析场景(例如 BI 报表即席查询、Dashboard 后端服务、交互式数据探索等),Spark ThriftServer 是更适合的选择。需要注意为 Spark ThriftServer 分配足够的资源并配置公平调度,以免某些大查询垄断资源影响其他用户查询体验。
4.3 结合使用 HiveServer2 和 Spark ThriftServer 的场景:在实际项目中,HiveServer2 和 Spark ThriftServer 并非互斥,很多企业会将两者结合使用,各取所长以满足不同类型的工作负载。例如,可以采用**“离线批处理 + 在线查询”**的分层架构:离线部分由 HiveServer2 驱动的 Hive 任务进行预计算,在线部分通过 Spark ThriftServer 提供交互查询服务。具体而言,先使用 HiveServer2 执行复杂的离线计算,将数据汇总整理到中间表或结果表,然后通过 Spark ThriftServer 对这些预处理结果进行快速的查询和展示。下面的示例展示了这样一种配合场景:
-
步骤1(HiveServer2 离线ETL):每天夜间使用 HiveServer2 执行 ETL,将原始日志数据转换汇总为宽表:
-- HiveServer2 执行离线 ETL 汇总 CREATE TABLE user_daily_metrics AS SELECT user_id,log_date,SUM(actions) AS total_actions,SUM(duration) AS total_duration FROM user_action_logs GROUP BY user_id, log_date;在此步骤中,HiveServer2 完成了繁重的数据清洗和汇总计算,将原始明细日志按用户和日期聚合,计算每用户每天的行为次数和时长等指标,结果存入
user_daily_metrics表。 -
步骤2(Spark ThriftServer 即席查询):白天业务高峰时,分析人员或应用系统通过 Spark ThriftServer 查询上述汇总结果,以获得及时的洞察:
-- Spark ThriftServer 查询预计算结果 SELECT log_date, COUNT(*) AS active_users, AVG(total_actions) AS avg_actions_per_user FROM user_daily_metrics WHERE log_date = '2025-03-03' GROUP BY log_date;该查询利用 Spark ThriftServer 快速计算指定日期的活跃用户数及人均行为次数等指标。由于
user_daily_metrics表已经是预先汇总好的结果表,数据规模大大缩减,Spark 可以在交互式查询中更快地聚合并返回结果。
上述组合场景发挥了两种服务的优点:HiveServer2 负责对海量原始数据进行复杂但低频率的批处理,确保数据经过充分清洗和预计算;Spark ThriftServer 则针对高频次、小范围的查询请求提供快速响应,直接查询预计算的数据集以服务即时分析需求。这种架构在大数据行业中相当常见,既保证了数据处理的完备性和稳定性,又兼顾了查询的实时性和高并发。实践中,为实现二者协同工作,通常会让 Spark ThriftServer 读取同一套 Hive 元数据和 HDFS 数据,这样 Hive 离线产出的表能够立刻被 Spark 查询到。此外,也有一些开源工具(如前述的 Hive-JDBC-Proxy 等)可以在前端根据查询特征智能路由到 HiveServer2 或 Spark ThriftServer,以实现自动化的结合使用。
5、总结
HiveServer2 与 Spark ThriftServer 各有优劣,应该根据具体业务需求加以选择或组合。在批处理为主、数据规模特大、查询延迟容忍度高的场景下,HiveServer2 所依托的 Hive 更为合适。它提供了成熟的SQL支持和优化器,能够良好地处理复杂查询和存储过程,并且可以通过部署多个 HiveServer2 实例来实现高可用以支撑生产级别的负载 。例如,传统数仓的ETL流程、固定报表计算,多采用 HiveServer2 来执行,这样既能利用 Yarn 对任务进行资源隔离调度,又能方便地与Hive的元数据管理、权限控制集成,保障系统稳定性。反之,在实时分析、交互查询为重点的需求下,Spark ThriftServer 更能满足低延迟、高吞吐的要求。通过让 Spark 长驻内存并复用计算上下文,Spark ThriftServer 避免了重复的任务启动开销,非常适合驱动 BI 即席查询、Dashboard 即时指标等应用场景。不过需要注意的是,原生 Spark ThriftServer 在多用户隔离和容错方面存在先天不足(单点 Driver、固定资源池、缺少内置HA等,在大型企业级环境中直接使用时应谨慎。实际经验表明,如果希望在生产中大规模采用 Spark 作为交互式数据服务,通常会对 Spark ThriftServer 进行改进或引入第三方扩展(例如 Kyuubi)来增强其高可用和多租户能力。因此,业界的最佳实践是根据用途对症下药:对于批处理任务采用 HiveServer2,并尽量使用 Tez 等加速引擎优化 Hive 性能;对于交互查询采用 Spark ThriftServer,并合理规划其资源(如启用动态分配、设置公平调度、独立 Yarn 队列等)以避免资源瓶颈。同时,确保二者共享统一的元数据存储(Hive Metastore),以实现数据架构的一致性。在一个完善的大数据平台中,HiveServer2 和 Spark ThriftServer 可以并行发挥作用:白天提供高速的查询服务,夜间承担大规模的数据处理,各尽其长。通过合理权衡和配置,企业既能享受 Hive 稳健的批处理能力,又能利用 Spark 提供的交互式性能,架构出满足不同业务需求的混合型大数据解决方案。
白天提供高速的查询服务,夜间承担大规模的数据处理,各尽其长。通过合理权衡和配置,企业既能享受 Hive 稳健的批处理能力,又能利用 Spark 提供的交互式性能,架构出满足不同业务需求的混合型大数据解决方案。
相关文章:
HiveServer2与Spark ThriftServer详细介绍对比
HiveServer2与Spark ThriftServer详细介绍对比 1、概述 1.1 HiveServer2 是 Apache Hive 提供的基于 Thrift 的服务进程,用于让远程客户端执行 Hive SQL 查询 ([一起了解一下HiveServer2 - zourui4271 - 博客园]。它是早期 HiveServer1 的改进版本,引入…...

ESP32S3N16R8驱动ST7701S屏幕(vscode+PlatfoemIO)
1.开发板配置 本人开发板使用ESP32S3-wroom1-n16r8最小系统板 由于基于vscode与PlatformIO框架开发,无espidf框架,因此无法直接烧录程序,配置开发板参数如下: 在platformio.ini文件中,配置使用esp32-s3-devkitc-1开发…...

软考初级程序员知识点汇总
以下是计算机技术与软件专业技术资格(水平)考试(简称“软考”)中 程序员(初级) 考试的核心知识点汇总,涵盖考试大纲的主要方向,帮助你系统复习: 一、计算机基础 计算机组…...

亲测解决笔记本触摸板使用不了Touchpad not working
这个问题可以通过FnFxx来解决,笔记本键盘上Fxx会有一个触摸板图标。如果不行应该玉藻设置中关了,打开即可。 解决办法 在蓝牙,触摸板里打开即可。 Turn it on in settings。...

13.数据结构(软考)
13.数据结构(软考) 13.1:线性表 13.1.1 顺序表 顺序存储方式:数组的内存是连续分配的并且是静态分配的,即在使用数组之前需要分配固定大小的空间。 时间复杂度: 读:O(1) 查询:1,(n1)/2&#x…...

开发环境搭建-完善登录功能
一.完善登录功能 我们修改密码为md5中的格式,那么就需要修改数据库中的密码和将从前端获取到的密码转化成md5格式,然后进行比对。比对成功则登录成功,失败则禁止登录。 二.md5格式 使用DigestUtils工具类进行md5加密,调用md4Dig…...

HAL库,配置adc基本流程
1. 初始化阶段---cubemx (1) GPIO初始化 函数:HAL_GPIO_Init() 作用:配置ADC引脚为模拟输入模式。 代码示例: // 使能GPIOA时钟 __HAL_RCC_GPIOA_CLK_ENABLE();// 配置PA1为模拟输入 GPIO_InitTypeDef GPIO_InitStruct {0}; GPIO_InitStr…...

DeepSeek爆火催生培训热潮,是机遇还是陷阱?
DeepSeek 掀起的学习风暴 最近,DeepSeek 以迅猛之势闯入大众视野,在国内引发了一场学习狂潮。它的出现,就像是在平静的湖面投入了一颗巨石,激起层层涟漪。 在各大社交平台上,与 DeepSeek 相关的话题讨论热度居高不下&…...

Apache Httpd 多后缀解析
目录 1.原因 2.环境 3.复现 4.防御 1.Apache Httpd 多后缀解析原因 Apache HTTP Server 在处理文件请求时,通常会根据文件的后缀来确定如何处理该文件。例如,.php文件会被交给 PHP 解释器处理,而.html文件则直接作为静态文件返回。 然而…...

备赛蓝桥杯之第十五届职业院校组省赛第五题:悠然画境
提示:本篇文章仅仅是作者自己目前在备赛蓝桥杯中,自己学习与刷题的学习笔记,写的不好,欢迎大家批评与建议 由于个别题目代码量与题目量偏大,请大家自己去蓝桥杯官网【连接高校和企业 - 蓝桥云课】去寻找原题࿰…...

Ubuntu 下 nginx-1.24.0 源码分析 - ngx_modules
定义在 objs\ngx_modules.c #include <ngx_config.h> #include <ngx_core.h>extern ngx_module_t ngx_core_module; extern ngx_module_t ngx_errlog_module; extern ngx_module_t ngx_conf_module; extern ngx_module_t ngx_openssl_module; extern ngx_modul…...

css错峰布局/瀑布流样式(类似于快手样式)
当样式一侧比较高的时候会自动换行,尽量保持高度大概一致, 例: 一侧元素为5,另一侧元素为6 当为5的一侧过于高的时候,可能会变为4/7分部dom节点 如果不需要这样的话删除样式 flex-flow:column wrap; 设置父级dom样…...

【并发编程】聊聊定时任务ScheduledThreadPool的实现原理和源码解析
ScheduledThreadPoolExecutor 是在线程池的基础上 拓展的定时功能的线程池,主要有四种方式,具体可以看代码, 这里主要描述下 scheduleAtFixedRate : 除了第一次执行的时间,后面任务执行的时间 为 time MAX(任务执行时…...

【虚拟化】Docker Desktop 架构简介
在阅读前您需要了解 docker 架构:Docker architecture WSL 技术:什么是 WSL 2 1.Hyper-V backend 我们知道,Docker Desktop 最开始的架构的后端是采用的 Hyper-V。 Docker daemon (dockerd) 运行在一个 Linux distro (LinuxKit build) 中&…...

DeepSeek 医疗大模型微调实战讨论版(第一部分)
DeepSeek医疗大模型微调实战指南第一部分 DeepSeek 作为一款具有独特优势的大模型,在医疗领域展现出了巨大的应用潜力。它采用了先进的混合专家架构(MoE),能够根据输入数据的特性选择性激活部分专家,避免了不必要的计算,极大地提高了计算效率和模型精度 。这种架构使得 …...

c++实现最大公因数和最小公倍数
最大公因数和最小公倍数的介绍 读这篇文章,请你先对最大公因数以及最小公倍数进行了解: 最大公因数(英文名:gcd) 定义:最大公因数,也称最大公约数,指两个或多个整数共有约数&…...

知识库Dify和cherry无法解析影印pdf word解决方案
近期收到大量读者反馈:上传pdf/图文PDF到Dify、Cherry Studio等知识库时,普遍存在格式错乱、图片丢失、表格失效三大痛点。 在试用的几款知识库中除了ragflow具备图片解析的能力外,其他的都只能解析文本。 如果想要解析扫描件,…...

【记录一下学习】Embedding 与向量数据库
一、向量数据库 向量数据库(Vector Database),也叫矢量数据库,主要用来存储和处理向量数据。 在数学中,向量是有大小和方向的量,可以使用带箭头的线段表示,箭头指向即为向量的方向,…...

【第21节】C++设计模式(行为模式)-Chain of Responsibility(责任链)模式
一、问题背景 在 VC/MFC 开发中,消息处理机制是核心部分之一。VC 是基于消息和事件驱动的框架,消息的处理流程通常是通过链式传递的方式进行的。例如,一个 WM_COMMAND 消息的处理流程可能如下: (1)MDI 主窗…...

createrepo centos通过nginx搭建本地源
yum update 先安装一个nginx。 安装Nginx yum install gcc gcc-c pcre pcre-devel openssl openssl-devel libtool zlib zlib-devel -y cd /usr/local/src wget http://nginx.org/download/nginx-1.22.0.tar.gz tar -zxvf nginx-1.22.0.tar.gz cd nginx-1.22.0 ./configu…...

探索Windows HEIC缩略图:跨平台照片管理深度解析
探索Windows HEIC缩略图:跨平台照片管理深度解析 【免费下载链接】windows-heic-thumbnails Enable Windows Explorer to display thumbnails for HEIC/HEIF files 项目地址: https://gitcode.com/gh_mirrors/wi/windows-heic-thumbnails Windows HEIC缩略图…...

NVIDIA Profile Inspector完整指南:200+隐藏设置解锁显卡极致性能
NVIDIA Profile Inspector完整指南:200隐藏设置解锁显卡极致性能 【免费下载链接】nvidiaProfileInspector 项目地址: https://gitcode.com/gh_mirrors/nv/nvidiaProfileInspector 还在为游戏画面撕裂、输入延迟过高而烦恼吗?想要彻底掌控NVIDIA…...

Gitclaw:封装复杂Git操作,提升开发效率的命令行工具
1. 项目概述:一个为Git操作注入“爪牙”的命令行工具如果你和我一样,日常开发工作重度依赖Git,那你肯定也经历过这样的时刻:面对一个需要多步操作才能完成的复杂Git任务,比如清理多个已合并的分支、批量重写提交历史中…...

本地化AI代码助手LLMDog:模块化框架与开源模型集成实践
1. 项目概述:一个为开发者设计的本地化AI代码助手最近在GitHub上闲逛,发现了一个挺有意思的项目叫“LLMDog”,作者是doganarif。乍一看这个名字,可能会联想到“AI狗”或者某种宠物,但它的全称其实是“Large Language M…...

MCP服务器开发指南:为AI助手构建安全可控的外部工具扩展
1. 项目概述:一个为AI助手赋能的MCP服务器最近在折腾AI应用开发的朋友,可能都绕不开一个词:MCP。全称是Model Context Protocol,你可以把它理解成一套标准化的“插件协议”。它让像Claude、Cursor这类AI助手,能够安全、…...

轻量级配置中心zcf:中小团队微服务配置管理实战指南
1. 项目概述:一个轻量级、高可用的配置中心最近在梳理团队内部的技术栈,发现一个挺有意思的现象:很多中小型项目,甚至是一些快速迭代的业务线,在配置管理上依然处于一种“原始”状态。要么是各种application.yml、appl…...

天学网口碑好不好?2026年最新用户实测反馈给你答案
作为深耕教育数字化落地领域5年的从业者,最近后台收到不少公立校电教组老师、学生家长的提问:主打AI英语教学的天学网口碑到底怎么样?刚好我们团队刚做完2026年第一季度的英语教育数字化工具落地效果调研,结合一手实测数据给大家客…...

如何用Wedecode实现微信小程序源代码的完美还原:从加密包到可读代码的完整指南
如何用Wedecode实现微信小程序源代码的完美还原:从加密包到可读代码的完整指南 【免费下载链接】wedecode 全自动化,微信小程序 wxapkg 包 源代码还原工具, 线上代码安全审计,支持 Windows, Macos, Linux 项目地址: https://gitcode.com/gh…...
TransPrompt:结构化提示词工程,提升LLM应用开发效率
1. 项目概述:当提示词工程遇上结构化工具最近在折腾大语言模型应用开发的朋友,估计都绕不开一个核心痛点:如何高效、稳定地管理那些越来越复杂、越来越长的提示词(Prompt)。直接写在代码里?改起来麻烦&…...

All in Token, 移动,电信,联通,阿里,百度,华为,字节,Token石油战争,Token经济,百度要“重写”AI价值度量
AI Agent的价值,应该怎么被衡量? 2026年,AI行业的标志性拐点是Agent(智能体)快速普及。Agent作为核心生产力载体,将AI从Chatbot聊天模式带进主动执行的办事时代。 这个时候,如果我们还用旧尺子…...