深度学习代码解读——自用
代码来自:GitHub - ChuHan89/WSSS-Tissue
借助了一些人工智能
2_generate_PM.py
功能总结
该代码用于 生成弱监督语义分割(WSSS)所需的伪掩码(Pseudo-Masks),是 Stage2 训练的前置步骤。其核心流程为:
-
加载 Stage1 训练好的分类模型(支持 CAM 生成)。
-
为不同层次的特征图生成伪掩码(如
b4_5,b5_2,bn7对应的不同网络层)。 -
保存伪掩码图像,使用调色板将类别标签映射为彩色图像。
代码解析
1. 导入依赖库
import os import torch import argparse import importlib from torch.backends import cudnn cudnn.enabled = True # 启用CUDA加速 from tool.infer_fun import create_pseudo_mask # 自定义函数:生成伪掩码
-
关键依赖:
-
cudnn.enabled = True:启用 cuDNN 加速,优化 GPU 计算性能。 -
create_pseudo_mask:核心函数(用户需参考其实现),负责生成并保存伪掩码。
-
2. 主函数与参数解析
if __name__ == '__main__':# 定义命令行参数parser = argparse.ArgumentParser()parser.add_argument("--weights", default='checkpoints/stage1_checkpoint_trained_on_bcss.pth', type=str)parser.add_argument("--network", default="network.resnet38_cls", type=str)parser.add_argument("--dataroot", default="datasets/BCSS-WSSS/", type=str)parser.add_argument("--dataset", default="bcss", type=str)parser.add_argument("--num_workers", default=8, type=int)parser.add_argument("--n_class", default=4, type=int)args = parser.parse_args()print(args) # 打印参数列表
-
参数说明:
-
--weights:Stage1 训练好的模型权重文件路径(默认指向 BCSS 数据集)。 -
--network:网络结构定义文件(如network.resnet38_cls)。 -
--dataroot:数据集根目录(包含训练/测试数据)。 -
--dataset:数据集标识(bcss或luad)。 -
--n_class:类别数量(BCSS 为 4 类,LUAD 可能不同)。
-
3. 定义调色板(颜色映射)
if args.dataset == 'luad':palette = [0]*15 # 初始化长度为15的列表(每类3个RGB通道)palette[0:3] = [205,51,51] # 类别1:红色palette[3:6] = [0,255,0] # 类别2:绿色palette[6:9] = [65,105,225] # 类别3:蓝色palette[9:12] = [255,165,0] # 类别4:橙色palette[12:15] = [255, 255, 255] # 背景或未标注区域:白色elif args.dataset == 'bcss':palette = [0]*15palette[0:3] = [255, 0, 0] # 类别1:红色palette[3:6] = [0,255,0] # 类别2:绿色palette[6:9] = [0,0,255] # 类别3:蓝色palette[9:12] = [153, 0, 255] # 类别4:紫色palette[12:15] = [255, 255, 255] # 背景:白色
-
作用:将类别标签映射为 RGB 颜色,用于伪掩码的可视化。
-
细节:
-
每个类别占 3 个连续位置(RGB 通道)。
-
palette[12:15]可能表示背景或未标注区域。 -
不同数据集使用不同的颜色方案(如 BCSS 用紫色表示第4类)。
-
4. 创建伪掩码保存路径
PMpath = os.path.join(args.dataroot, 'train_PM') # 路径示例:datasets/BCSS-WSSS/train_PMif not os.path.exists(PMpath):os.mkdir(PMpath) # 若目录不存在则创建
-
目的:在数据集根目录下创建
train_PM文件夹,用于保存生成的伪掩码。
5. 加载模型
model = getattr(importlib.import_module("network.resnet38_cls"), 'Net_CAM')(n_class=args.n_class)model.load_state_dict(torch.load(args.weights), strict=False)model.eval() # 设置为评估模式(禁用Dropout等随机操作)model.cuda() # 将模型移至GPU
-
关键步骤:
-
动态加载模型:从
network.resnet38_cls模块加载Net_CAM类(支持 CAM 生成的变体)。 -
加载权重:使用 Stage1 训练好的模型参数(
strict=False允许部分参数不匹配)。 -
评估模式:关闭 BatchNorm 和 Dropout 的随机性,确保结果一致性。
-
6. 生成多级伪掩码
##fm = 'b4_5' # 特征模块名称(可能对应网络中的某个中间层)savepath = os.path.join(PMpath, 'PM_' + fm) # 保存路径:train_PM/PM_b4_5if not os.path.exists(savepath):os.mkdir(savepath)create_pseudo_mask(model, args.dataroot, fm, savepath, args.n_class, palette, args.dataset)## 重复相同流程生成其他层级的伪掩码fm = 'b5_2'savepath = os.path.join(PMpath, 'PM_' + fm)if not os.path.exists(savepath):os.mkdir(savepath)create_pseudo_mask(model, args.dataroot, fm, savepath, args.n_class, palette, args.dataset)##fm = 'bn7'savepath = os.path.join(PMpath, 'PM_' + fm)if not os.path.exists(savepath):os.mkdir(savepath)create_pseudo_mask(model, args.dataroot, fm, savepath, args.n_class, palette, args.dataset)
-
功能:针对不同特征模块(
fm)生成伪掩码,保存到对应子目录。 -
关键参数:
-
fm:特征模块标识,可能对应网络中的不同层(如 ResNet 的block4、block5或bottleneck)。 -
create_pseudo_mask:核心函数,推测其功能为:-
加载训练集图像。
-
使用模型提取指定层的特征图。
-
生成类别激活图(CAM)。
-
根据阈值将 CAM 转换为二值伪掩码。
-
应用调色板将掩码保存为彩色 PNG 图像。
-
-
代码执行示例
python generate_pseudo_masks.py \--dataset bcss \--dataroot datasets/BCSS-WSSS/ \--weights checkpoints/stage1_checkpoint_trained_on_bcss.pth
-
输出:在
datasets/BCSS-WSSS/train_PM/下生成三个子目录:-
PM_b4_5:基于b4_5层特征的伪掩码。 -
PM_b5_2:基于b5_2层特征的伪掩码。 -
PM_bn7:基于bn7层特征的伪掩码。
-
总结
该代码是弱监督语义分割流程中 生成多级伪掩码的关键步骤,利用 Stage1 训练的分类模型提取不同层级的特征,生成伪标签供 Stage2 的分割模型训练。通过多级伪掩码的融合,可以提升最终分割结果的精度和鲁棒性。
3_train_stage2.py
功能总结
该代码是弱监督语义分割(WSSS)的 Stage2 训练与测试脚本,核心功能为:
-
训练分割模型:基于 DeepLab v3+ 架构,使用 Stage1 生成的伪掩码(Pseudo-Masks)进行监督训练。
-
验证与测试:评估模型在验证集和测试集上的性能(如 mIoU、像素准确率等)。
-
门控机制(Gate Mechanism):在测试阶段结合 Stage1 的分类结果过滤分割预测,提升精度。
-
多任务损失:融合不同层次伪掩码的损失(主伪掩码 + 两种增强版本)。
代码结构
# 1. 依赖库导入 import argparse, os, numpy as np from tqdm import tqdm import torch from tool.GenDataset import make_data_loader from network.sync_batchnorm.replicate import patch_replication_callback from network.deeplab import * from tool.loss import SegmentationLosses from tool.lr_scheduler import LR_Scheduler from tool.saver import Saver from tool.summaries import TensorboardSummary from tool.metrics import Evaluator# 2. 定义训练器类 class Trainer(object):def __init__(self, args): ... # 初始化模型、数据、优化器等def training(self, epoch): ... # 训练一个epochdef validation(self, epoch): ... # 验证集评估def test(self, epoch, Is_GM): ... # 测试集评估(支持门控机制)def load_the_best_checkpoint(self): ... # 加载最佳模型# 3. 主函数 def main(): ... # 解析参数、启动训练if __name__ == "__main__":main()
关键代码解析
1. Trainer 类初始化
class Trainer(object):def __init__(self, args):self.args = args# 初始化日志记录与模型保存工具self.saver = Saver(args) # 保存模型检查点self.summary = TensorboardSummary('logs') # TensorBoard日志self.writer = self.summary.create_summary()# 数据加载kwargs = {'num_workers': args.workers, 'pin_memory': False}self.train_loader, self.val_loader, self.test_loader = make_data_loader(args, **kwargs)# 模型定义(DeepLab v3+)self.nclass = args.n_classmodel = DeepLab(num_classes=self.nclass,backbone=args.backbone, # 骨干网络(如ResNet)output_stride=args.out_stride, # 输出步长(控制特征图分辨率)sync_bn=args.sync_bn, # 多GPU同步BatchNormfreeze_bn=args.freeze_bn # 冻结BN层参数)# 优化器配置(分层学习率)train_params = [{'params': model.get_1x_lr_params(), 'lr': args.lr}, # 骨干网络低学习率{'params': model.get_10x_lr_params(), 'lr': args.lr * 10} # 分类头高学习率]optimizer = torch.optim.SGD(train_params, momentum=args.momentum,weight_decay=args.weight_decay, nesterov=args.nesterov)# 损失函数(交叉熵或Focal Loss)self.criterion = SegmentationLosses(weight=None, cuda=args.cuda).build_loss(mode=args.loss_type)self.model, self.optimizer = model, optimizer# 评估工具(计算mIoU等指标)self.evaluator = Evaluator(self.nclass)# 学习率调度(Poly策略)self.scheduler = LR_Scheduler(args.lr_scheduler, args.lr, args.epochs, len(self.train_loader))# 加载Stage1的分类模型(用于门控机制)model_stage1 = getattr(importlib.import_module('network.resnet38_cls'), 'Net_CAM')(n_class=4)resume_stage1 = 'checkpoints/stage1_checkpoint_trained_on_'+str(args.dataset)+'.pth'weights_dict = torch.load(resume_stage1)model_stage1.load_state_dict(weights_dict)self.model_stage1 = model_stage1.cuda()self.model_stage1.eval() # 固定Stage1模型参数# GPU并行化if args.cuda:self.model = torch.nn.DataParallel(self.model, device_ids=self.args.gpu_ids)patch_replication_callback(self.model) # 修复多GPU BatchNorm同步问题self.model = self.model.cuda()# 加载预训练权重(如DeepLab预训练模型)if args.resume is not None:checkpoint = torch.load(args.resume)# 处理分类头权重(微调时保留,否则删除)if args.ft:self.model.load_state_dict(checkpoint['state_dict'])self.optimizer.load_state_dict(checkpoint['optimizer'])else:del checkpoint['state_dict']['decoder.last_conv.8.weight']del checkpoint['state_dict']['decoder.last_conv.8.bias']self.model.load_state_dict(checkpoint['state_dict'], strict=False)# 初始化最佳mIoUself.best_pred = 0.0
2. 训练阶段 training
def training(self, epoch):train_loss = 0.0self.model.train()tbar = tqdm(self.train_loader) # 进度条num_img_tr = len(self.train_loader)for i, sample in enumerate(tbar):# 加载数据(图像 + 三个伪掩码)image, target, target_a, target_b = sample['image'], sample['label'], sample['label_a'], sample['label_b']if self.args.cuda:image, target, target_a, target_b = image.cuda(), target.cuda(), target_a.cuda(), target_b.cuda()# 调整学习率self.scheduler(self.optimizer, i, epoch, self.best_pred)self.optimizer.zero_grad()# 前向传播output = self.model(image)# 添加额外通道处理类别4(背景或忽略类)one = torch.ones((output.shape[0],1,224,224)).cuda()output = torch.cat([output, (100 * one * (target==4).unsqueeze(dim=1)], dim=1)# 计算多任务损失(主伪掩码 + 两种增强版本)loss_o = self.criterion(output, target)loss_a = self.criterion(output, target_a)loss_b = self.criterion(output, target_b)loss = 0.6*loss_o + 0.2*loss_a + 0.2*loss_b# 反向传播loss.backward()self.optimizer.step()# 统计损失train_loss += loss.item()tbar.set_description('Train loss: %.3f' % (train_loss / (i + 1)))# 记录TensorBoard日志self.writer.add_scalar('train/total_loss_iter', loss.item(), i + num_img_tr * epoch)# 输出epoch总结self.writer.add_scalar('train/total_loss_epoch', train_loss, epoch)print('[Epoch: %d, numImages: %5d]' % (epoch, i * self.args.batch_size + image.data.shape[0]))print('Loss: %.3f' % train_loss)
3. 验证阶段 validation
def validation(self, epoch):self.model.eval()self.evaluator.reset()tbar = tqdm(self.val_loader, desc='\r')test_loss = 0.0for i, sample in enumerate(tbar):image, target = sample[0]['image'], sample[0]['label']if self.args.cuda:image, target = image.cuda(), target.cuda()with torch.no_grad():output = self.model(image)# 转换为CPU numpy数组pred = output.data.cpu().numpy()target = target.cpu().numpy()pred = np.argmax(pred, axis=1)# 处理类别4(设为忽略类)pred[target==4] = 4# 更新评估指标self.evaluator.add_batch(target, pred)# 计算并记录指标Acc = self.evaluator.Pixel_Accuracy()Acc_class = self.evaluator.Pixel_Accuracy_Class()mIoU = self.evaluator.Mean_Intersection_over_Union()ious = self.evaluator.Intersection_over_Union()FWIoU = self.evaluator.Frequency_Weighted_Intersection_over_Union()# 输出结果print('Validation:')print("Acc:{}, Acc_class:{}, mIoU:{}, fwIoU: {}".format(Acc, Acc_class, mIoU, FWIoU))# 保存最佳模型if mIoU > self.best_pred:self.best_pred = mIoUself.saver.save_checkpoint({'state_dict': self.model.module.state_dict(),'optimizer': self.optimizer.state_dict()}, 'stage2_checkpoint_trained_on_'+self.args.dataset+'.pth')
4. 测试阶段 test(含门控机制)
def test(self, epoch, Is_GM):self.load_the_best_checkpoint() # 加载最佳模型self.model.eval()self.evaluator.reset()tbar = tqdm(self.test_loader, desc='\r')for i, sample in enumerate(tbar):image, target = sample[0]['image'], sample[0]['label']if self.args.cuda:image, target = image.cuda(), target.cuda()with torch.no_grad():output = self.model(image)# 门控机制:利用Stage1的分类结果过滤分割预测if Is_GM:_, y_cls = self.model_stage1.forward_cam(image) # Stage1的分类输出y_cls = y_cls.cpu().datapred_cls = (y_cls > 0.1) # 类别存在性判断(阈值0.1)# 应用门控机制pred = output.data.cpu().numpy()if Is_GM:pred = pred * pred_cls.unsqueeze(dim=2).unsqueeze(dim=3).numpy()# 处理类别4pred = np.argmax(pred, axis=1)pred[target==4] = 4self.evaluator.add_batch(target, pred)# 计算并输出指标Acc = self.evaluator.Pixel_Accuracy()Acc_class = self.evaluator.Pixel_Accuracy_Class()mIoU = self.evaluator.Mean_Intersection_over_Union()print('Test:')print("Acc:{}, Acc_class:{}, mIoU:{}".format(Acc, Acc_class, mIoU))
5. 主函数 main
def main():# 解析命令行参数parser = argparse.ArgumentParser(description="WSSS Stage2")# 模型结构参数parser.add_argument('--backbone', default='resnet', choices=['resnet', 'xception', 'drn', 'mobilenet'])parser.add_argument('--out-stride', type=int, default=16) # 输出步长(控制特征图下采样率)parser.add_argument('--Is_GM', type=bool, default=True) # 是否启用门控机制# 数据集参数parser.add_argument('--dataroot', default='datasets/BCSS-WSSS/')parser.add_argument('--dataset', default='bcss')parser.add_argument('--n_class', type=int, default=4)# 训练超参数parser.add_argument('--epochs', type=int, default=30)parser.add_argument('--batch-size', type=int, default=20)parser.add_argument('--lr', type=float, default=0.01)parser.add_argument('--lr-scheduler', default='poly', choices=['poly', 'step', 'cos'])# 其他配置parser.add_argument('--gpu-ids', default='0') # 指定使用的GPUparser.add_argument('--resume', default='init_weights/deeplab-resnet.pth.tar') # 预训练权重args = parser.parse_args()# 配置CUDAargs.cuda = not args.no_cuda and torch.cuda.is_available()if args.cuda:args.gpu_ids = [int(s) for s in args.gpu_ids.split(',')]# 自动设置SyncBNif args.sync_bn is None:args.sync_bn = True if args.cuda and len(args.gpu_ids) > 1 else False# 初始化训练器并启动训练trainer = Trainer(args)for epoch in range(trainer.args.epochs):trainer.training(epoch)if epoch % args.eval_interval == 0:trainer.validation(epoch)# 最终测试trainer.test(epoch, args.Is_GM)trainer.writer.close()
关键设计解析
-
多任务损失:
-
目标:同时优化主伪掩码(
target)及其两种增强版本(target_a,target_b),提升模型对不同噪声伪标签的鲁棒性。 -
权重分配:主损失占60%,增强损失各占20%(
0.6*loss_o + 0.2*loss_a + 0.2*loss_b)。
-
-
门控机制(Gate Mechanism):
-
作用:在测试阶段,利用 Stage1 的分类结果过滤分割预测,仅保留分类模型认为存在的类别。
-
实现:若 Stage1 对某类别的预测概率 > 0.1,则保留该类的分割结果,否则置零。
-
-
类别4处理:
-
背景或忽略类:在标签中,类别4可能表示背景或未标注区域,预测时直接继承真实标签的值(
pred[target==4] = 4),避免错误优化。
-
-
模型初始化:
-
预训练权重:加载 DeepLab 在 ImageNet 上的预训练权重(
init_weights/deeplab-resnet.pth.tar),加速收敛。 -
分层学习率:骨干网络使用较低学习率(
args.lr),分类头使用更高学习率(args.lr * 10)。
-
运行示例
python train_stage2.py \--dataset bcss \--dataroot datasets/BCSS-WSSS/ \--backbone resnet \--Is_GM True \--batch-size 20 \--epochs 30
总结
该代码实现了弱监督语义分割的第二阶段训练,通过多任务损失融合多级伪标签,结合门控机制提升测试精度,最终生成高精度分割模型。训练过程支持多GPU加速、Poly学习率调度及多种评估指标监控,适用于医学图像(如BCSS)或自然场景图像的分割任务。
相关文章:

深度学习代码解读——自用
代码来自:GitHub - ChuHan89/WSSS-Tissue 借助了一些人工智能 2_generate_PM.py 功能总结 该代码用于 生成弱监督语义分割(WSSS)所需的伪掩码(Pseudo-Masks),是 Stage2 训练的前置步骤。其核心流程为&a…...

Linux 配置静态 IP
一、简介 在 Linux CentOS 系统中默认动态分配 IP 地址,每次启动虚拟机服务都是不一样的 IP,因此要配置静态 IP 地址避免每次都发生变化,下面将介绍配置静态 IP 的详细步骤。 首先先理解一下动态 IP 和静态 IP 的概念: 动态 IP…...

Oxidized收集H3C交换机网络配置报错,not matching configured prompt (?-mix:^(<CD>)$)
背景:问题如上标题,H3C所有交换机配置的model都是comware 解决方案: 1、找到compare.rb [rootoxidized model]# pwd /usr/local/lib/ruby/gems/3.1.0/gems/oxidized-0.29.1/lib/oxidized/model [rootoxidized model]# ll comware.rb -rw-r--…...

RAG技术深度解析:从基础Agent到复杂推理Deep Search的架构实践
重磅推荐专栏: 《大模型AIGC》 《课程大纲》 《知识星球》 本专栏致力于探索和讨论当今最前沿的技术趋势和应用领域,包括但不限于ChatGPT和Stable Diffusion等。我们将深入研究大型模型的开发和应用,以及与之相关的人工智能生成内容(AIGC)技术。通过深入的技术解析和实践经…...

6.过拟合处理:确保模型泛化能力的实践指南——大模型开发深度学习理论基础
在深度学习开发中,过拟合是一个常见且具有挑战性的问题。当模型在训练集上表现优秀,但在测试集或新数据上性能大幅下降时,就说明模型“记住”了训练数据中的噪声而非学习到泛化规律。本文将从实际开发角度系统讲解如何应对过拟合,…...

【玩转23种Java设计模式】结构型模式篇:组合模式
软件设计模式(Design pattern),又称设计模式,是一套被反复使用、多数人知晓的、经过分类编目的、代码设计经验的总结。使用设计模式是为了可重用代码、让代码更容易被他人理解、保证代码可靠性、程序的重用性。 汇总目录链接&…...

专业工具,提供多种磁盘分区方案
随着时间的推移,电脑的磁盘空间往往会越来越紧张,许多人都经历过磁盘空间不足的困扰。虽然通过清理垃圾文件可以获得一定的改善,但随着文件和软件的增多,磁盘空间仍然可能显得捉襟见肘。在这种情况下,将其他磁盘的闲置…...

SELinux 概述
SELinux 概述 概念 SELinux(Security-Enhanced Linux)是美国国家安全局在 Linux 开源社区的帮助下开发的一个强制访问控制(MAC,Mandatory Access Control)的安全子系统。它确保服务进程仅能访问它们应有的资源。 例…...

【十三】Golang 通道
💢欢迎来到张胤尘的开源技术站 💥开源如江河,汇聚众志成。代码似星辰,照亮行征程。开源精神长,传承永不忘。携手共前行,未来更辉煌💥 文章目录 通道通道声明初始化缓冲机制无缓冲通道代码示例 带…...
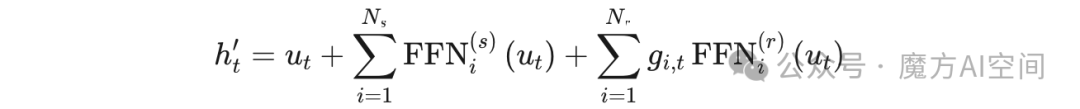
DeepSeek专题:DeepSeek-V2核心知识点速览
AIGCmagic社区知识星球是国内首个以AIGC全栈技术与商业变现为主线的学习交流平台,涉及AI绘画、AI视频、大模型、AI多模态、数字人以及全行业AIGC赋能等100应用方向。星球内部包含海量学习资源、专业问答、前沿资讯、内推招聘、AI课程、AIGC模型、AIGC数据集和源码等…...
Oracle19c进入EM Express(Oracle企业管理器)详细步骤
以下是使用Oracle 19c进入Oracle Enterprise Manager Database Express(EM Express)的详细步骤: ### **步骤 1:确认EM Express配置状态** 1. **登录数据库服务器** 使用Oracle用户或管理员权限账户登录操作系统。 2. **查看EM…...

游戏引擎学习第140天
回顾并为今天的内容做准备 目前代码的进展到了声音混音的部分。昨天我详细解释了声音的处理方式,声音在技术上是一个非常特别的存在,但在游戏中进行声音混音的需求其实相对简单明了,所以今天的任务应该不会太具挑战性。 今天我们会编写一个…...

C++--迭代器(iterator)介绍---主要介绍vector和string中的迭代器
目录 一、迭代器(iterator)的定义 二、迭代器的类别 三、使用迭代器 3.1 迭代器运算符 3.2 迭代器的简单应用:使用迭代器将string对象的第一个字母改为大写 3.3 将迭代器从一个元素移动到另外一个元素 3.4 迭代器运算 3.5 迭代器的复…...
RuleOS:区块链开发的“新引擎”,点燃Web3创新之火
RuleOS:区块链开发的“新引擎”,点燃Web3创新之火 在区块链技术的浪潮中,RuleOS宛如一台强劲的“新引擎”,为个人和企业开发去中心化应用(DApp)注入了前所未有的动力。它以独特的设计理念和强大的功能特性&…...
机器学习之强化学习
引言 在人工智能的众多分支中,强化学习(Reinforcement Learning, RL) 因其独特的学习范式而备受关注。与依赖标注数据的监督学习或探索数据结构的无监督学习不同,强化学习的核心是智能体(Agent)通过与环境…...
基于 uni-app 和 Vue3 开发的汉字书写练习应用
基于 uni-app 和 Vue3 开发的汉字书写练习应用 前言 本文介绍了如何使用 uni-app Vue3 uview-plus 开发一个汉字书写练习应用。该应用支持笔画演示、书写练习、进度保存等功能,可以帮助用户学习汉字书写。 在线演示 演示地址: http://demo.xiyueta.com/case/w…...

每天五分钟深度学习PyTorch:向更深的卷积神经网络挑战的ResNet
本文重点 ResNet大名鼎鼎,它是由何恺明团队设计的,它获取了2015年ImageNet冠军,它很好的解决了当神经网络层数过多出现的难以训练的问题,它创造性的设计了跳跃连接的方式,使得卷积神经网络的层数出现了大幅度提升,设置可以达到上千层,可以说resnet对于网络模型的设计具…...
electron + vue3 + vite 主进程到渲染进程的单向通信
用示例讲解下主进程到渲染进程的单向通信 初始版本项目结构可参考项目:https://github.com/ylpxzx/electron-forge-project/tree/init_project 主进程到渲染进程(单向) 以Electron官方文档给出的”主进程主动触发动作,发送内容给渲…...

《白帽子讲 Web 安全》之身份认证
目录 引言 一、概述 二、密码安全性 三、认证方式 (一)HTTP 认证 (二)表单登录 (三)客户端证书 (四)一次性密码(OTP) (五)多因…...

postgrel
首先按照惯例,肯定是需要对PostgreSQL数据库进行一系列信息收集的,常用的命令有以下这些:-- 版本信息select version();show server_version;select pg_read_file(PG_VERSION, 0, 200);-- 数字版本信息包括小版号SHOW server_version_num;SEL…...

智能体开发实战:从LLM工具调用到自主决策系统的架构指南
1. 项目概述与核心价值最近在开源社区里,一个名为DaMaxime/openclaw-agents-docs的项目引起了我的注意。乍一看,这像是一个围绕“OpenClaw Agents”的文档仓库,但当你深入进去,会发现它远不止是简单的API手册或使用说明。这个项目…...

从零构建可控AI智能体中枢:Comobot部署、配置与实战指南
1. 项目概述:从零构建一个可控的智能体中枢如果你和我一样,对市面上的AI助手感到既兴奋又有些许无奈——兴奋于它们强大的能力,无奈于它们要么是“黑盒”服务,数据安全存疑;要么部署复杂,难以深度定制——那…...

用STM32F103和DHT11做个智能温湿度报警器,附ESP8266远程监控代码
STM32F103与DHT11打造智能环境监测系统:从本地报警到云端监控全解析 在智能家居和工业物联网快速发展的今天,环境监测系统已成为许多创客和开发者入门的首选项目。本文将带你用STM32F103微控制器和DHT11温湿度传感器,构建一个功能完善的智能…...

英文论文AI率从97%降至8%:6款工具横测,这款神器绝不打乱排版!
前阵子我文章有两页的英文检测ai率居然冲到了97% 。我当时也是整个人都傻了。 作为一名每天和各种内容辅助工具打交道的博主,我太理解大家面对那张通红的检测报告时的心情。 既然大家都面临英文降ai这个难题,今天咱们就抛开那些虚头巴脑的理论…...

TCS3490颜色传感器技术解析与应用实践
1. TCS3490颜色传感器技术解析TCS3490是ams公司推出的一款面向移动设备的五通道智能颜色传感器。作为光学传感器领域的创新产品,它通过RGBClearIR的五通道设计,实现了传统三通道传感器无法达到的环境光检测精度。我在实际项目应用中发现,这款…...

用 C 语言函数表实现通信传输层抽象
用 C 语言函数表实现通信传输层抽象 在嵌入式 Linux 或工业控制类程序中,一个应用经常需要同时接入多种通信链路,例如 UDP、串口、CAN、TCP 或 Unix Socket。 这些链路的底层实现差异很大: UDP 基于 socket串口基于 tty 设备CAN 基于 SocketC…...

工业控制中自定义串行总线协议的设计与实现:DataView系统实战
1. 项目背景与核心需求:为什么需要自定一个串行总线?在工业控制领域,尤其是信号调理模块和开关电源这类产品里,我们常常会遇到一个看似简单、实则棘手的问题:如何在有限的成本、空间和算力下,为多个分散的模…...

白嫖使用 Claude Opus 4.7 一个月,新手保姆级教程
挖槽,最近亚马逊做了一次大善人,为它自家的 Kiro 做拉新活动,新注册账号可以直接获得一个月的 Kiro Pro 会员,价值 20 美刀。 教程非常详细,所以有点长,想看最短流程版的可以直接划到文章末尾。 Kiro 是什…...

如何利用The Incredible PyTorch离线文档:深度学习者的终极学习宝典
如何利用The Incredible PyTorch离线文档:深度学习者的终极学习宝典 【免费下载链接】the-incredible-pytorch The Incredible PyTorch: a curated list of tutorials, papers, projects, communities and more relating to PyTorch. 项目地址: https://gitcode.…...

QConf灰度发布策略详解:零风险配置变更的完整方案
QConf灰度发布策略详解:零风险配置变更的完整方案 【免费下载链接】QConf QConf是奇虎360开源的一款分布式配置管理平台,能够集中管理和分发应用程序的配置数据,并支持高可用性和水平扩展,尤其适用于大规模分布式系统的配置管理。…...