游戏引擎学习第145天
仓库:https://gitee.com/mrxiao_com/2d_game_3
今天的计划
目前,我们正在完成遗留的工作。当时我们已经将声音混合器(sound mixer)集成到了 SIMD 中,但由于一个小插曲,没有及时完成循环内部的部分。这个小插曲主要是因为在处理补码(two’s complement)时,我们意外卡住了。准确来说,并不是忘记了补码的概念,而是忘记了芯片加法(chip adding)的工作方式。因此,当时花了一些时间重新回忆和理清思路。好消息是,我们最终成功回忆起来并且进行了讲解,坏消息是这个过程花费了太长时间,导致整个主题从实现 SIMD 混音器变成了回忆基础知识的过程。
首先要完成的是 SIMD 内部循环(inside loop)的编写。除此之外,我们还希望在整个代码中保持一致性,使混音器代码保持简单和清晰。另外,应用程序的其他部分也需要调整,以适应 SIMD 方式进行音频处理。现在,我们的代码仍然支持基于 16 位采样(per channel sample)的独立处理,但为了更好地适配 SIMD,我们希望调整处理方式,使其以 4 个或 8 个采样(samples)为一个基本单位。
之所以考虑 8 个采样为一个单位,是因为在 16 位音频采样格式下,8 个样本的总数据宽度刚好是 128 位,而 SSE2 的寄存器宽度也是 128 位,这样可以更高效地利用 SIMD 指令进行并行处理。因此,为了让代码结构更加清晰,我们可能会采用 8 个采样作为基本单位,以优化数据对齐和处理效率。
从4宽到8宽
首先,我们要做的是编写一个新的例程,假设我们可以自由调整处理方式,而不受任何具体实现的限制。我们会先写出理想情况下的代码,然后再回到外围代码进行调整,使其能够正确运行。
目前,我们有一个 SampleCountAlign4,表示样本数对齐到 4 的倍数。我们可以修改它,使样本数对齐到 8 (SampleCountAlign8),即要求样本缓冲区始终对齐到 8 个样本,而不是 4 个样本。这样,我们可以在 game_platform 代码中创建一个对齐工具,使所有样本缓冲区都符合 8 的倍数。例如,我们可以写一个简单的 Align8 代码,使其始终返回 8 的倍数,从而确保输出的播放声音始终符合这个要求。如果有特殊需求,我们可以修改这个例程,但当前的目标是让代码尽可能简单明了。
一旦确定了 SampleCountAlign8,我们需要相应地调整通道缓冲区的大小。由于 8 个采样的宽度比 4 个采样要大,我们的通道缓冲区必须增大一倍,即缓冲区大小要比原始 SampleCount4 多一倍。此外,我们可以定义一个 SampleCount8,即 SampleCount * 2,用于在 SIMD 计算时保证数据对齐。
SIMD 代码的处理方式往往与传统的单值计算不同,在编程语言层面也不太适应这种向量化的概念。因此,在处理 SIMD 代码时,我们可能需要进行一些额外的元编程,以便正确管理数据的对齐和访问。通常,这种调整会导致一定的调试时间,因为很容易在计算样本数量时出现错误,从而导致程序运行异常。但总体而言,这只是一个额外的复杂性,不会影响最终的实现。
接下来的工作是调整代码,使其符合 SampleCountAlign8 约束。在初始化通道缓冲区时,我们仍然使用 SampleCount4 来清除缓冲区内容。当进入循环处理时,我们需要将 SampleCount 设定为 8 的倍数,以确保所有数据都按照 8 对齐的方式进行加载。
当从通道缓冲区加载数据时,我们需要确保 SampleCountAlign8 被正确应用,特别是在加载 16 位的非交错(non-interleaved)数据时。这部分代码需要特别关注,因为它决定了 SIMD 处理的数据布局。如果数据没有正确对齐,SIMD 指令可能无法高效执行。
为了验证代码是否能够运行,我们可以尝试执行现有的代码,看看是否会出现问题。目前,我们还没有真正实现数据对齐检查,因此需要确保 game_win32 代码正确处理了 SampleCount。在 win32 代码中,我们发现 BytesToWrite 计算 GetSample,但并没有显式执行 SampleCount 对齐的逻辑。
当前的代码主要是确保分配缓冲区时提供足够的空间来处理可能的溢出(overrun)。然而,这并不是我们真正需要的方式。理想情况下,我们应该确保请求的样本数始终是 8 的倍数,而不是简单地为溢出预留额外的空间。因此,我们可能需要调整代码,使 SampleCount 直接对齐,而不是依赖 MaxPossibleOverrun 之类的变量。
实际上,我们发现 MaxPossibleOverrun 可能并不必要。它可能是之前随意添加的代码,没有实际作用。因此,我们可以考虑移除 MaxPossibleOverrun,改为直接确保 SampleCount 始终是 8 的倍数,以保持代码的清晰性和正确性。



发现修改 BytesToWrite 的bug

确保声音缓冲区始终请求8个样本的倍数
在当前的代码中,我们需要确保写入的样本数量始终对齐到 8 的倍数,以便更好地适配 SIMD 处理方式。问题出现在 BytesToWrite 变量的计算上,它是根据目标游标(TargetCursor)的位置计算得出的,但这个值可能并不总是 8 的倍数。为了保证数据对齐,我们需要调整 BytesToWrite,使其始终向下对齐到最近的 8 的倍数。
我们先快速检查代码的逻辑,确保调整不会影响其他部分的正常运行。目前,BytesToWrite 的计算是基于 TargetCursor 的位置,而 TargetCursor 的值取决于当前音频缓冲区的状态。代码在计算 ByteToLock 时,已经考虑了是否发生环绕(wrapping)的情况。如果 ByteToLock 大于 TargetCursor,表示没有环绕,否则就会执行两次写入操作,以正确处理环绕的情况。
在确保 BytesToWrite 需要对齐后,我们需要进一步检查win32_game中 SoundBuffer 代码,确认 FillSoundBuffer 是否可以接受任意值作为 BytesToWrite。检查代码后,我们发现 Win32FillSoundBuffer 似乎能够处理任何输入值,这意味着我们可以安全地调整 BytesToWrite,使其对齐到 8 的倍数,而不会影响其他部分的逻辑。
因此,我们需要修改 BytesToWrite 的计算方式。具体来说,我们需要:
- 计算
BytesToWrite对应的样本数量,即SoundBuffer.SampleCount = Align8(BytesToWrite / SoundOutput.BytesPerSample)。 - 确保
BytesToWrite是 8 的倍数,对其进行向下对齐。 - 计算新的
BytesToWrite,使其反映对齐后的样本数。
代码实现如下:
SoundBuffer.SampleCount = Align8(BytesToWrite / SoundOutput.BytesPerSample); // 需要写入的样本数
BytesToWrite = SoundBuffer.SampleCount * SoundOutput.BytesPerSample;
通过这种方式,我们可以保证 BytesToWrite 始终对齐到 8 的倍数,以确保 SIMD 代码能够正确高效地执行。
此外,我们还可以添加一个 assert 语句,确保 BytesToWrite 始终符合对齐要求。例如:
Assert((samples_to_write & 7) == 0);
这样,如果 samples_to_write 不是 8 的倍数,程序就会触发断言错误,帮助我们及时发现潜在问题。
综上所述,我们通过调整 BytesToWrite 的计算方式,确保它始终对齐到 8 的倍数,从而优化 SIMD 处理,同时保证音频缓冲区的正确性。这种方法既能提高 SIMD 代码的执行效率,又能减少潜在的错误,使代码更加稳定和可靠。


将样本视为大小为8的块
我们希望确保所有声音的更新都以 8 个样本的倍数进行,这样可以更好地适应 SIMD 处理,同时保证数据对齐。当前的 SamplesToMix 变量是以单个样本为单位的,这样的设计有些不太理想。我们需要将所有相关的样本计数转换为 8 的倍数,以便在整个音频处理过程中保持一致性。
在 game_asset.h 文件中,我们可以直接定义 SampleCount8 变量,让所有的音频数据都以 8 的倍数进行存储和处理。例如:
这样,每个音频数据块的大小都会自动对齐到 8 的倍数,并且所有涉及音频数据的计算都会基于 8 进行处理。这意味着无论加载何种声音文件,都必须满足 8 样本对齐的要求。
对于可能存在的问题,比如某些音频文件的样本数可能不是 8 的倍数,我们需要在加载时进行填充(padding)。例如,随机加载的音频文件可能会出现样本数不是 8 的倍数的情况,我们要在结尾填充额外的样本,使其符合 8 的倍数要求。
当前的加载逻辑中,代码在计算数据大小时会直接执行拷贝操作。我们需要在此基础上确保数据长度符合 8 的倍数:
-
计算当前样本数是否是 8 的倍数:
- 如果是,则直接加载数据。
- 如果不是,则增加额外的填充样本,使其符合 8 的倍数。
-
调整数据拷贝方式:
- 目前的实现是直接在原位置进行拷贝,但如果文件的样本数不是 8 的倍数,我们可能需要额外分配一些内存进行填充。
- 但为了避免不必要的内存分配,我们可以在读取文件数据时,保证其在结尾有足够的额外空间进行填充,而不是在加载过程中临时分配新内存。
-
修改
DEBUGReadEntireFile以确保数据读取时已经留出足够的填充空间:- 这样,我们可以保证所有加载的音频文件在进入引擎之前,就已经符合 8 样本对齐的要求,从而减少额外的计算和数据拷贝。
此外,我们还要考虑循环音频(looping sounds)的问题。由于所有音频都必须是 8 的倍数,某些循环音频可能会受影响。我们可以选择:
- 在循环点进行额外的对齐调整,以确保播放时不会产生错位。
- 或者完全避免使用循环音频,而是通过多个重叠的音频片段来模拟无限循环的效果。
从设计上来说,我们倾向于避免使用循环音频,而是通过其他方式(如叠加多个音频)来模拟连续播放的效果。这种方法虽然可能会稍微增加计算量,但可以避免循环音频可能带来的可感知重复问题。
综上所述,我们的目标是:
- 确保所有声音的样本数都是 8 的倍数。
- 在加载音频文件时,自动填充缺少的样本。
- 避免在运行时额外分配内存,而是在文件读取阶段就保证数据对齐。
- 通过非循环的方式来模拟无限播放,减少循环音频带来的重复感。
这样,我们可以确保音频系统的稳定性,并优化 SIMD 处理的效率。

因为以样本块处理,所以在输出缓冲区的末尾填充零
在加载音频数据时,我们需要确保所有的样本数始终对齐到 8 的倍数。如果原始样本数不是 8 的倍数,我们需要在末尾进行填充(padding)。为此,我们引入了 PadSamples 变量,该变量计算出需要填充的样本数,并在音频数据的结尾填充零值,以确保对齐。
对齐步骤
-
计算对齐的样本数
- 计算
Align8(SampleCount),即将SampleCount向上对齐到 8 的倍数。 - 计算
PadSamples,即SampleCountAlign8 - SampleCount,表示需要填充的样本数。
- 计算
-
填充缺少的样本
- 遍历音频数据的各个通道(目前仅支持单声道),从原始
SampleCount位置开始填充零值,直到SampleCountAlign8。 - 这样可以确保所有的音频数据块始终对齐到 8 的边界。
- 遍历音频数据的各个通道(目前仅支持单声道),从原始
-
更新样本数
- 在填充完成后,将
SampleCount8更新为SampleCountAlign8。 - 由于后续计算全部基于 8 的倍数,我们进一步存储
SampleCount8 = SampleCountAlign8 / 8,使后续的计算更加清晰和高效。
- 在填充完成后,将
调整代码逻辑
为了确保所有的数学运算和索引操作都基于 8 的倍数,我们进行了以下更改:
-
调整所有涉及样本数的变量
- 任何使用
SampleCount的地方,统一改为SampleCount8。 - 这样可以保证所有计算始终基于 8 的倍数,从而减少不必要的对齐计算。
- 任何使用
-
修改
TotalSamplesToMix- 该变量用于表示需要混合的总样本数,现在改为
TotalSamplesToMix8,以 8 作为单位进行存储和计算。 - 在代码中逐步替换
TotalSamplesToMix为TotalSamplesToMix8,确保所有音频处理逻辑都是以 8 为单位。
- 该变量用于表示需要混合的总样本数,现在改为
-
调整
RealSamplesRemingInSound和SamplesPlayed- 由于
RealSamplesRemingInSound计算的是剩余样本数,而SamplesPlayed记录的是已播放的样本数,这些变量也需要按照 8 的倍数进行存储和计算。
- 由于
-
保证所有涉及音频数据的循环和索引计算都符合 8 对齐
- 遍历和处理音频数据时,确保所有步长都是 8 的倍数,以提高处理效率并避免数据错位。
优化 SIMD 兼容性
将所有的样本数调整为 8 的倍数后,可以更好地利用 SIMD 指令进行音频处理。SIMD 处理通常依赖于数据的对齐,因此我们采用 8 作为基本单位,可以:
- 提高数据加载和存储效率,减少跨缓存行访问的情况。
- 优化音频混合和处理的 SIMD 指令执行,提升整体性能。
避免额外的内存分配
在对齐填充时,我们希望避免额外的内存分配,因此采取了一种较为简便的策略:
- 直接在现有数据的末尾填充零值,而不是重新分配更大的缓冲区。
- 在
debug_platform_read_entire_file读取文件时,确保为对齐填充预留足够空间,以避免运行时的额外拷贝和分配。
总结
- 通过
SampleCountAlign8计算并填充缺少的样本,使所有音频数据始终对齐到 8 的倍数。 - 修改
TotalSamplesToMix、RealSamplesRemingInSound和SamplesPlayed等变量,确保所有计算都基于 8 的倍数进行。 - 统一使用
SampleCount8作为核心存储格式,提高 SIMD 兼容性,优化音频处理性能。 - 采用零填充策略,避免额外的内存分配,提高加载效率并减少运行时开销。
这样,我们可以保证音频数据的对齐性,提高 SIMD 计算效率,并确保整个音频处理流程的稳定性和一致性。


音高变化迫使我们读取未对齐的数据
在处理音频播放时,我们希望所有的样本始终对齐到 8 的倍数,这样可以优化数据加载和 SIMD 计算。然而,当涉及到 变速播放(Pitch Shifting) 时,这种对齐方式会遇到问题,因为变速播放会导致样本读取位置偏移,使得数据无法保持严格的 8 对齐。
变速播放导致的对齐问题
-
正常播放(倍率 1.0)
- 如果播放速度是 1.0 倍,每次从音频缓冲区读取 8 个样本,并按 8 的倍数存储和处理,一切都可以保持完美对齐。
- 在 128-bit 的 SIMD 计算中,我们可以一次性读取 8 个样本,进行计算,并存入输出缓冲区,始终保持对齐状态。
-
变速播放(倍率 ≠ 1.0)
- 如果播放速度是 1.9 倍,那么样本索引的推进速度将不再是固定步长。
- 例如,在 1.9 倍速 的情况下,第一次读取 8 个样本,下一次可能从 当前缓冲区的中间部分 读取,而不是下一个整块 8 对齐的位置。
- 这样一来,样本读取位置会 漂移,导致后续的 SIMD 计算无法保持 8 对齐,从而影响性能和数据正确性。
无法完全避免非对齐读取
由于变速播放时样本索引不再是固定步长,因此:
- 强行对齐是不现实的,因为样本的位置总会偏移。
- 必须接受非对齐读取,这意味着在音频处理时,我们无法避免跨边界读取样本数据。
- 只能保证最终输出的块大小仍然是 8 对齐,但在读取过程中,数据可能是错位的。
解决方案
虽然无法完全避免非对齐读取,但可以采取一些措施降低影响:
-
仍然保证输出数据块是 8 的倍数
- 即使输入数据的索引偏移导致读取不对齐,我们仍然可以确保输出缓冲区中的数据是 8 对齐的。
- 这样可以在后续的混音和音效处理过程中保持数据的稳定性。
-
使用 SIMD 处理多个相邻样本
- 由于读取位置可能在两个 8 对齐的块之间,我们可以加载 两个相邻的 8 样本块,然后通过插值或加权计算获得正确的中间值。
- 这样可以减少跨界读取带来的计算开销,同时保持较好的数据一致性。
-
接受非对齐读取带来的计算代价
- 由于变速播放的需要,无法完全避免非对齐读取,因此在读取缓冲区时,需要额外处理跨界样本的情况。
- 这可能会导致 额外的内存访问,但在保证功能完整性的前提下,这是必须接受的代价。
最终决定
- 继续采用 8 对齐的存储和输出逻辑,但 在读取时接受非对齐读取。
- 调整计算方式,使其适应变速播放带来的非对齐问题。
- 在需要跨界读取时,采取适当的插值或缓冲策略,以减少计算开销并保持音质稳定。
综上所述,虽然变速播放破坏了严格的 8 对齐模式,但通过适当的优化,可以在 保证性能的前提下,让系统仍然能够高效地进行音频处理。
更新例程以支持处理8个样本的块
在处理音频播放时,我们希望所有的样本计算都基于 8的倍数,以便优化 SIMD 计算。然而,在实际实现过程中,我们需要对多个关键变量进行调整,使其适应这一新的计算方式。
1. 处理音频样本的基本流程
- 计算 SamplesRemainingInSound8,确保所有计算基于 8 的倍数进行。
- 对 SamplesToMix8 进行判断,确保其仍然符合 8 对齐规则,如果需要提前终止计算,则执行相应的逻辑。
- 处理 音量变化 (volume change),将音量的变化速率 (dVolume) 适配到 8 对齐的计算模式。
- 计算 样本索引 (sample index) 并调整 浮点数计算 以支持非对齐读取。
2. 计算音量变化
为了让音量调整保持 8 的倍数:
- 计算 目标音量 (Target Volume) 与当前音量 (Current Volume) 的差值。
- 该差值除以 样本数 (Sample Count),得到每个样本的音量增量。
- 由于我们希望所有计算基于 8 的倍数,我们需要 对音量增量乘以 1/8 (0.125),以便适应新的 8 对齐模式。
- 这样,计算出的 dVolume8 代表 8 个样本的音量增量,在后续处理时可以直接应用。
3. 处理音频样本的索引
由于音频播放过程中,样本索引基于浮点数计算:
- 计算 样本的实际索引 (SamplePosition)。
- 使用 floor 函数 获取索引的整数部分,以确保我们访问的样本位置是有效的。
- 由于音频缓冲区以 8对齐的方式存储,所以我们需要 将索引乘以8 来获取正确的偏移量。
为了适配变速播放:
- 需要 支持非对齐读取,因为变速播放会导致采样点不再严格对齐到 8 的倍数。
- 计算出的 样本增量 (dSample) 需要乘以 8,确保所有计算均保持一致。
4. 处理音频混合逻辑
为了确保所有计算适应 8 对齐:
- 在处理音量变化时,将 音量增量 预先乘以 8,以便适配新的计算方式。
- 在更新 样本索引 (Sample Position) 时,确保索引增量也是 8 倍的步长,以便适应 SIMD 计算。
这样,我们可以在计算时始终保持 基于 8 的倍数进行存储与运算,同时在 变速播放时支持非对齐读取,从而在 性能和灵活性之间取得平衡。
5. 最终调整
- 确保所有计算均以 8 对齐进行,包括音量、样本索引、混合逻辑等。
- 在变速播放时支持非对齐读取,以保证音频播放的流畅性。
- 优化 SIMD 处理方式,确保计算过程中的数据加载与运算符合 SIMD 处理模式,提高计算效率。
综上所述,通过这些优化,我们可以在 保证变速播放功能的同时,最大程度地优化 SIMD 计算效率,确保音频处理的性能和精度。

通过在声音的结束后填充随后的声音,使得声音流畅过渡,直到超过8个样本
在处理音频流播放时,我们发现了一个 边界问题,类似于 双线性过滤 (bilinear filtering) 的边缘处理问题。当音频数据以 块 (chunk) 的形式 进行加载和播放时,在不同块的交界处,可能会出现采样错误,这会导致播放出现断裂或不连续的情况。为了保证 无缝播放,需要引入适当的 填充 (padding) 机制,以确保跨块采样时的正确性。
1. 识别边界问题
在音频块的交界处,我们遇到了以下问题:
- 跨块采样可能会错误地读取填充的零值,而不是应该播放的下一个音频块的数据。
- 这种情况在 按 8 个样本为单位进行处理 时会更加明显,因为可能在 SIMD 并行计算 中一次性跨越多个样本,导致错误变得更加明显。
- 之前的调试代码可能在 无意中提供了正确的填充,因此在某些情况下没有暴露问题。但在更严格的 块流式加载 (streaming chunk loading) 过程中,这个问题就变得更加明显了。
2. 解决方案:在音频块边界处进行填充
为了确保在 跨块播放 时音频不会出现间断,我们需要进行 适当的填充 (padding):
- 在 音频块的末尾填充下一个块的开始部分,以确保采样时不会遇到无效数据。
- 这类似于 无缝纹理 (seamless texture) 处理,在纹理边缘添加 额外的像素数据,以确保双线性过滤时不会读取到无效的边界数据。
- 具体实现方式:
- 检测音频块是否处于流式播放模式:
- 如果当前块是 完整音频 (完整加载的音频文件),则无需特殊处理。
- 如果当前块是 分块加载的流式音频,则需要在块的末尾进行特殊填充。
- 判断当前块是否是流式音频的最后一部分:
- 如果 当前块的最后一个样本索引 + 块大小 = 整个音频数据的长度,那么说明当前块是音频的最后部分。
- 在这种情况下,需要填充 零值 (silence padding),以避免访问无效数据。
- 在块的末尾添加 8 个额外样本的填充:
- 这些样本可能来自下一个音频块(如果存在)。
- 如果当前块是整个音频的最后一部分,则填充 静音数据 (zero padding),避免访问未初始化的数据。
- 检测音频块是否处于流式播放模式:
3. 代码调整
为了实现上述逻辑,我们进行了以下调整:
-
调整音频缓冲区的填充逻辑:
- 之前的填充逻辑主要用于 对齐 (alignment),但现在 对齐已经不再重要,真正重要的是 保证音频块的平滑过渡。
- 现在的填充方式是 在需要的地方添加正确的音频数据,而不是简单地填充零值。
-
优化音频采样索引计算:
- 采用 偏移 (offset) 计算,确保采样索引始终在正确范围内。
- 确保在 SIMD 计算 中,采样索引不会超出音频数据的实际范围。
-
为 SIMD 计算做准备:
- 由于现在所有的计算都基于 8 的倍数,可以更容易地将处理逻辑转换为 SIMD 指令,以提升计算效率。
4. 最终优化
- 通过 在音频块的边界填充正确的数据,可以确保跨块播放时不会出现音频断裂或错误。
- 由于 所有计算都基于 8 的倍数,可以进一步优化为 SIMD 处理,提高性能。
- 通过 动态填充,可以在不增加存储开销的情况下,实现 高效、无缝的音频播放。
通过这些优化,我们可以确保 音频播放的连续性,并且 进一步提升播放效率,同时避免了 块加载模式 下的常见边界问题。


调试音高变换后的问题


在测试音频播放时,我们意识到 变量播放速率 (variable speeds) 并没有被充分测试。例如,我们尝试使用 dSample * 1.0 或 0.9 之类的速率进行调整,但发现音频播放的效果听起来有些 不稳定 (janky),这表明其中仍然存在一些问题。
1. 发现问题
- 在检查代码时,我们发现 SamplePosition 的计算方式不正确:
- SamplePosition 必须是一个真实的数值,而不是直接使用它进行索引计算。
- 实际上,应该调整的是 SamplePosition,因为它才是真正影响采样位置的变量。
- 计算方式应该是:
SamplePosition = SampleOffset × dSample \text{SamplePosition} = \text{SampleOffset} \times \text{dSample} SamplePosition=SampleOffset×dSample - 之前的代码在计算 SamplePosition 时,错误地使用了 SamplePosition 而没有乘以 dSample,导致了采样位置的不准确,进而影响了播放质量。
2. 代码分析与修正
-
错误的计算方式:
SamplePosition += SamplePosition;- 这种方式会导致 播放速率调整后 采样偏移不正确。
-
正确的计算方式:
SamplePosition += SamplePosition * dSample;- 这样可以确保 采样位置随着播放速率的变化而正确调整,不会出现不连续或错位的问题。
-
修正后,我们检查了整个音频处理流程:
- 确保 dSample 和 dSample8 计算正确。
- 检查 sampleindex 和 SamplePosition 是否正确更新。
- 确保 fractional value (小数部分的插值计算) 没有问题。
- 验证 采样位置计算 是否正确应用了 offset。
-
经过修正后,音频播放效果明显改善,说明 问题主要出在 SamplePosition 的计算方式上。
3. 进一步优化
- 由于音频数据是 8 个样本一组 进行处理的,我们需要确保:
- 每 8 个样本的计算都正确偏移,不会因为错误的索引计算导致数据不连续。
- SIMD 计算可以正确应用偏移值,以便在后续优化时提升计算效率。
- 变量播放速率 (dSample 调整) 可以正确作用于采样索引,确保播放速率变化时音频依然流畅。
4. 结论
- 变量播放速率测试暴露了采样位置计算的问题,导致音频听起来不稳定。
- 修正了 SamplePosition 计算方式,确保它正确应用 dSample 进行调整。
- 播放效果明显改善,问题基本解决,可以继续进行 SIMD 优化 以提高性能。


发现修改 BytesToWrite 的bug

对主混音循环进行SIMD化
我们正在将现有的音频混合处理代码转换为SIMD(单指令多数据)的实现,以提高处理效率。在当前的实现中,我们使用标量的加法和乘法操作,而通过SIMD,我们可以一次性处理八个样本(float),这将显著提高性能。以下是我们在转换过程中遇到的问题和相应的解决方法。
1. SIMD加载和存储操作
在SIMD中,我们需要使用 __m128 类型处理数据,因此必须进行对齐加载和存储。我们决定采用 aligned loads and stores,因为我们处理的是目标缓冲区数据(Dest),这些数据应该始终是对齐的。
我们计划加载两个 __m128 向量,因为我们每次处理八个样本,每个 __m128 包含四个 float,因此需要两个 __m128。
D0_0 D0_1
D1_0 D1_1
由于浮点数是 float 类型,我们需要强制转换为 __m128 类型才能加载和存储。
2. 加载操作
我们使用 __m128 类型来加载数据,代码类似如下:
__m128 D0_0 = _mm_load_ps((float*)Dest0[0]);
__m128 D0_1 = _mm_load_ps((float*)Dest0[1]);
其中:
D0:加载前四个浮点样本。D1:加载后四个浮点样本。
这一步确保了我们一次性加载八个浮点样本,符合我们预期的SIMD并行计算。
3. 样本索引的更新
我们处理的数据是以 8个样本为一组,因此索引递增量需要是2,即:
Dest0 += 2;
因为 Dest0 是 __m128 类型,每次递增2意味着实际上我们跳过了8个 float。
4. 音量和主音量的处理
接下来我们需要处理音量混合。在原来的标量版本中,我们将样本乘以 Volume * MasterVolume,然后加到输出缓冲区中。
在SIMD版本中,我们需要两个 __m128:
- MasterVolume(主音量)
- Volume(音量)
我们将这两个值广播(broadcast)到 __m128 中,以便对齐计算:
然后进行计算:
__m128 result0 = _mm_mul_ps(d0, _mm_mul_ps(volume4, masterVolume4));
__m128 result1 = _mm_mul_ps(d1, _mm_mul_ps(volume4, masterVolume4));
5. 加法操作
由于我们使用的是 +=,因此我们需要将结果加回 dest 缓冲区中:
_mm_store_ps((float*)dest_00, _mm_add_ps(d0, result0));
_mm_store_ps((float*)dest_10, _mm_add_ps(d1, result1));
此处我们使用了 _mm_add_ps 进行加法运算。
6. 处理左右声道
我们还需要分别处理左右声道的音量,假设 MasterVolume 和 Volume 是双通道的,即:
MasterVolume4_0 -> 左声道主音量
MasterVolume4_1 -> 右声道主音量
Volume4_0 -> 左声道音量
Volume4_1 -> 右声道音量
然后进行左右声道的计算:
D0_0 = _mm_add_ps(D0_0, _mm_mul_ps(_mm_mul_ps(MasterVolume4_0, Volume4_0), SampleValue));D0_1 = _mm_add_ps(D0_1, _mm_mul_ps(_mm_mul_ps(MasterVolume4_0, Volume4_0), SampleValue));D1_0 = _mm_add_ps(D1_0, _mm_mul_ps(_mm_mul_ps(MasterVolume4_1, Volume4_1), SampleValue));D1_1 = _mm_add_ps(D1_1, _mm_mul_ps(_mm_mul_ps(MasterVolume4_1, Volume4_1), SampleValue));
并将结果存回:
_mm_store_ps((float *)&Dest0[0], D0_0);_mm_store_ps((float *)&Dest0[1], D0_1);_mm_store_ps((float *)&Dest1[0], D1_0);_mm_store_ps((float *)&Dest1[1], D1_1);

在双线性插值的加载过程中SIMD化遇到的问题
我们在实现音频混合和变调(Pitch Bend)处理时,遇到了一个比较棘手的问题。问题的核心在于,当播放速度(Pitch Bend)不为1.0时,样本数据的读取方式发生了变化,这导致处理逻辑变得复杂且低效。
1. 问题的本质
在正常播放(速度为1.0)的情况下,我们可以简单地批量读取样本数据。例如,每次可以加载 8个float,通过SIMD指令一次性处理它们,然后将结果写回输出缓冲区中。这种情况下,数据的加载是连续且高效的,处理过程如下:
- 加载数据:连续加载8个样本。
- 浮点转换:将样本数据转换为float。
- 音量调整:将样本乘以音量、主音量。
- 存储数据:将处理结果写回目标缓冲区中。
这个过程是非常高效的,因为内存访问是连续的,SIMD处理也能最大化利用CPU资源。
2. 变调时的问题
但当启用了Pitch Bend(变调)时,情况就完全不同了。
2.1. 数据的非连续性
假设我们将播放速度调整为 0.9,此时我们需要从源缓冲区中提取的数据变得不再连续,表现如下:
| 原始索引 | 读取的样本 | 实际操作样本 |
|---|---|---|
| 0 | 0 | 0 |
| 1 | 1 | 0.9 |
| 2 | 2 | 1.8 |
| 3 | 3 | 2.7 |
| 4 | 4 | 3.6 |
| 5 | 5 | 4.5 |
| 6 | 6 | 5.4 |
| 7 | 7 | 6.3 |
可以看出,随着播放速度的变化,读取的样本不再是整块连续的,而是需要按照浮点索引读取。例如:
- 第一次读取样本
0。 - 第二次读取样本
0.9,需要进行插值计算。 - 第三次读取样本
1.8,再次插值计算。
插值计算的核心在于,索引值是浮点数,因此我们必须读取两个相邻样本,然后计算其加权平均值。
3. 插值的计算
在Pitch Bend场景下,我们需要实现线性插值,公式如下:
S a m p l e = ( 1 − t ) × S a m p l e [ N ] + t × S a m p l e [ N + 1 ] Sample = (1 - t) \times Sample[N] + t \times Sample[N+1] Sample=(1−t)×Sample[N]+t×Sample[N+1]
其中:
Sample[N]:当前整数索引处的样本值。Sample[N+1]:下一个整数索引处的样本值。t:索引的小数部分,代表两者的混合比例。
示例:
- 索引 = 1.8
- Sample[1] = 0.5
- Sample[2] = 0.6
- t = 0.8
计算公式:
S a m p l e = ( 1 − 0.8 ) × 0.5 + 0.8 × 0.6 Sample = (1 - 0.8) \times 0.5 + 0.8 \times 0.6 Sample=(1−0.8)×0.5+0.8×0.6
结果:
Sample = 0.1 * 0.5 + 0.8 * 0.6= 0.05 + 0.48= 0.53
4. SIMD处理的困难
由于索引是浮点数,且数据不再连续,我们在使用SIMD时遇到了几个主要困难:
4.1. 无法直接加载连续数据
原始数据如果是连续的,我们可以用_mm_load_ps每次加载8个float。但在变调情况下,样本数据之间存在浮点偏移,导致无法使用简单的对齐加载,而必须进行非对齐读取(_mm_loadu_ps),或者逐个读取样本进行插值计算。
4.2. 插值计算的开销
我们每次都需要读取两个相邻样本,然后计算插值。对于SIMD而言,这种处理是非常低效的。
例如:
- 原始计划是8个float一组加载,然后计算。
- 现在由于插值需求,必须拆成每2个float加载一次,并计算插值。
这样一来,效率直接下降约4-8倍。
对双线性插值情况逐个加载样本,而不是按8个样本的块加载
我们目前面临的主要问题是如何在处理音频数据时优化性能,尤其是在需要进行音高变化(pitch bend)的情况下。我们意识到,如果不考虑优化,直接处理音频数据会非常简单,但一旦引入音高变化,性能和代码复杂度就会大大增加。
在不进行音高变化的情况下,我们可以轻松地加载一整块音频数据,以浮点数(float)的形式处理,然后直接进行音量调整等操作,最终将结果写回缓冲区。这种操作是非常高效且直接的。
但在需要音高变化的情况下,问题就变得复杂了。比如,如果我们以0.9倍速进行播放,采样点会发生偏移,导致我们需要进行插值(interpolation)。这种情况下,我们无法直接批量加载数据并操作,而是需要在缓冲区中分散加载数据,并对其进行处理,这就大大降低了处理效率。
我们考虑了一种方案,即分成两种不同的处理路径:
- 没有音高变化的情况,我们可以直接以固定步长(例如8个采样点)加载数据,进行操作并写回缓冲区。
- 有音高变化的情况,我们必须动态加载采样数据,因为它们的位置不再是固定的,而是随着时间发生变化。这就意味着我们无法一次性加载固定的采样点,而是需要通过计算索引动态读取数据。
接下来我们讨论了具体的实现过程。如果我们不特意优化,仅仅是直接使用标量操作(scalar operation),我们就需要逐一计算每个采样点的索引,加载数据并进行音量调整等操作。这种方法的效率非常低下。
为了解决这个问题,我们尝试使用SIMD(单指令多数据流)来提高效率。我们决定使用_mm_set_ps来加载数据,这样可以在一个指令周期内同时处理四个浮点数。然而,这也带来了新的问题:
- 我们的音高变化会导致采样点不是对齐的,这意味着我们无法直接使用批量加载和计算。
- 由于索引是不固定的,我们需要动态计算每个采样点的位置,并进行加载和操作。
我们尝试了一种方法,即直接预计算采样索引,然后将其加载进来进行操作。这意味着我们不再坚持每次加载八个采样点(因为音高变化时无法保证这些数据是连续的),而是改为加载四个采样点,以便更好地适应音高变化带来的数据不连续性。
然后我们发现,音量调整的处理也有一定的复杂度。我们需要引入一个“音量渐变”的机制,因为在播放音频时,音量变化需要逐渐过渡而非突然变化。因此,我们的音量调整需要采用类似插值的方式,每次加载音量值时需要基于初始音量和增量进行计算:
- 初始音量
v0。 - 下一帧音量
v1 = v0 + Δv。 - 再下一帧音量
v2 = v1 + Δv。 - 以此类推。
这意味着,我们在加载音频数据的同时,也必须同步加载音量数据,并确保它们是按照时间步长递增的。
为了实现这一点,我们决定在音量计算时预加载并递增音量值。我们定义了一个向量,其中包含四个浮点数:
- 第一个浮点数表示当前音量。
- 第二个浮点数表示当前音量加上一个增量。
- 第三个浮点数表示当前音量加上两个增量。
- 第四个浮点数表示当前音量加上三个增量。
通过这种方式,我们可以确保在批量加载数据时,同时计算音量的变化,从而提高整体效率。
我们还注意到,主音量(master volume)的调整比较简单,因为它是恒定的,不需要进行增量计算。因此,这部分操作我们直接通过_mm_set1_ps设置主音量,并在音量调整时直接进行乘法运算即可。
接着,我们又发现了一个潜在问题:由于我们的音频数据加载策略发生了变化(从每次加载8个样本变为加载4个样本),导致我们需要修改所有的加载、计算、写回操作。这包括:
- 修改加载数据的步长,从8改为4。
- 修改音量计算的步长,从8改为4。
- 修改所有写回缓冲区的数据格式,确保数据正确对齐。
我们意识到,当前的变量命名非常混乱,导致代码可读性和维护性都非常差。因此,我们计划在之后对所有变量进行重命名,使其更符合直观理解,比如:
- 将音量相关变量命名为
volumeStep、baseVolume等。 - 将音频数据加载的变量命名为
sampleIndex、sampleBuffer等。 - 将音量增量命名为
volumeDelta或dVolume等。
我们还提到,当前的处理仍然存在许多低效之处,例如:
- 加载数据时,我们仍然需要动态计算索引,而无法一次性加载连续数据。
- 由于音高变化带来的数据不连续性,我们无法直接进行SIMD操作,而是需要分段加载和处理。
- 当前的代码中存在大量不必要的冗余操作,例如重复加载和重复计算。
我们计划在下一次处理时:
- 彻底移除按8个采样点加载的模式,完全切换到按4个采样点加载的模式,以减少不必要的计算。
- 对变量进行统一重命名,以确保代码的可读性和维护性。
- 优化音量增量计算,尝试将音量变化和数据加载融合在一起,以减少额外的计算成本。
- 尝试更优的插值方案,目前我们是直接按采样点计算,但如果能够找到更优的插值算法,可能会大幅提高性能。
最后,我们没有完全完成这部分代码的优化,但我们确保在当前状态下,代码至少可以编译通过并保持功能可用。接下来,我们会优先考虑重构和优化,以确保这部分代码既高效又易维护。

我们一直在处理的8位数据是什么?是频率和音量吗?
我们目前正在处理的音频采样器核心是**频率(pitch)和音量(volume)**的调整,如果之前没有跟上进度,这里简单解释一下我们正在做的事情:
在音频采样器中,有两个核心参数:
- dSample(即delta sample):它表示音频回放的速度,直接影响音高(pitch)。如果我们改变这个值,就会导致播放速度发生变化,从而改变音高。
- Volume(音量):它表示音频的响度(loudness),通过对采样数据的幅度进行缩放来控制音量大小。
dSample的作用:
- dSample是一个浮点数,表示每帧音频采样的步长。当dSample为1.0时,表示以正常速度回放音频;
- 如果dSample > 1.0,则表示加速播放,音高升高;
- 如果dSample < 1.0,则表示减速播放,音高降低;
- 如果dSample非常接近0,则播放几乎停止。
音量的作用:
- 音量是一个浮点数,用来控制音频输出的强度;
- 在音频数据加载之后,我们通过乘以音量值来控制音频的响度;
- 当音量为1.0时,表示原始响度;
- 当音量<1.0时,表示音量减弱;
- 当音量>1.0时,表示音量增强(如果允许的话)。
音高变化的挑战:
当我们调整dSample使音高变化时,数据的读取位置会发生变化。假设我们有一段音频数据,如果正常播放时读取的是:
0, 1, 2, 3, 4, 5, 6, 7, 8, 9
如果我们将dSample设置为0.5,意味着播放速度减半,数据读取就变成:
0, 0.5, 1, 1.5, 2, 2.5, 3, 3.5, 4, 4.5...
由于音频采样只能按整数索引读取,因此我们不得不进行插值运算,比如:
- 读取索引0和1之间的数据并进行混合,得到0.5位置的数据;
- 读取索引1和2之间的数据并进行混合,得到1.5位置的数据。
这就是插值计算的核心,也是我们目前遇到的一个主要挑战。
音量变化的挑战:
音量控制相对简单,但如果我们在播放过程中希望动态改变音量,就需要做音量渐变(volume ramping)。
- 比如,播放开始时音量为0,逐渐增加到1.0;
- 或者播放结束时音量从1.0逐渐衰减到0。
为了实现这个效果,我们需要在每一帧中计算一个音量增量(dVolume),并在每次采样时增加这个增量,从而实现平滑的音量变化。
dSample和音量结合的挑战:
我们目前遇到的最大问题是dSample和音量渐变在数据加载和处理时高度耦合,导致处理变得复杂。
- 当dSample变化时,采样点不再对齐,我们必须动态计算采样位置并插值;
- 当音量变化时,我们需要动态计算音量增量,并同步应用到采样数据中;
- 同时处理这两件事导致代码非常复杂,并且不容易优化。
目前我们采用的策略:
- 拆分处理路径:
- 无音高变化:直接加载一段连续的采样数据,批量计算音量变化,快速输出;
- 有音高变化:动态计算采样索引,插值处理,并在此过程中同步进行音量计算。
- 引入SIMD优化:
- 使用
_mm_set_ps加载多个浮点数,通过SIMD一次性计算4个采样点; - 但由于dSample导致的非对齐采样,SIMD优化效果受限。
- 使用
- 音量渐变的预计算:
- 在加载音量数据时,同时计算音量增量(dVolume),以确保音量变化平滑;
- 使用SIMD批量计算音量变化,而不是逐个采样点调整音量。
当前仍存在的挑战:
- 数据加载不连续:由于dSample导致的非对齐采样,我们无法批量加载连续数据,导致性能下降;
- 音量渐变计算复杂:每次加载数据时,我们还需要额外计算音量增量,这也增加了开销;
- 处理路径分裂:由于有音高变化和无音高变化两种情况,代码结构复杂且维护困难;
- 名称混乱:由于代码快速开发,变量命名非常混乱,导致理解和维护成本增加。
下一步的优化计划:
- 简化数据加载:考虑将音高变化和音量变化拆分成两个独立的计算模块,减少耦合;
- 优化SIMD路径:尝试找到一种方式,即使在非对齐采样时,也能利用SIMD进行批量计算;
- 重命名变量:统一变量命名,确保所有变量清晰表意,方便未来维护;
- 减少动态计算:尽可能将计算前移,避免在音频播放过程中进行复杂的计算,以提高性能。
我们目前已经初步完成了基本的音高变化和音量控制功能,但仍有大量优化空间,尤其是在音高变化导致的采样不连续问题上。我们下一步的重点是减少动态计算和提高数据加载效率,以确保音频播放在高性能环境下达到最佳效果。
为什么在构建输出中有命令覆盖 Od 和 O2?
我们目前在处理渲染器的编译优化时,遇到了一个特殊需求:我们希望**渲染器始终以最高的优化模式(optimized mode)**运行,以确保渲染性能最大化,同时其他文件可以保持调试模式(debug mode)或发布模式(release mode)。
为了实现这一点,我们对渲染器文件的编译选项进行了单独设置,即重写编译器优化级别。
为什么要这样做?
- 渲染器的计算量非常大,如果在调试模式下编译,性能会大幅下降,无法达到我们想要的渲染速度;
- 其他文件仍然需要保持调试模式(debug mode),以便我们进行代码测试和调试;
- 如果直接将整个项目切换为发布模式(release mode),调试能力会丧失,因此我们需要针对渲染器单独优化。
我们采取的做法
我们将渲染器文件的编译参数单独设置,使其在任何情况下都使用高优化模式。具体做法是:
- 其他文件使用默认的编译参数(如debug模式或release模式);
- 渲染器文件强制使用
-O2优化参数;
例如:
common compiler flags: Debug Mode: -Od (不优化,便于调试) Release Mode: -O2 (最大优化,便于发布)
我们希望在调试模式(Debug Mode)下,渲染器仍然保持最大优化模式(O2),而其他文件保持原有的编译参数。
具体实现方式
在项目的编译配置文件中,我们专门为渲染器文件添加了一个单独的优化选项:
Renderer.cpp: -O2
Other files: -Od (or -O0 depending on the build type)
这样,即使整个项目在调试模式下运行,渲染器文件仍然以**最高优化模式(O2)**编译。
为什么不直接全部使用-O2?
如果将所有文件都编译成-O2,会导致:
- 调试能力丧失:如果出现Bug,无法轻易通过调试器跟踪问题;
- 开发效率降低:在调试模式下,我们希望能快速编译和运行,但
-O2优化模式下,编译时间较长; - 代码行为改变:某些情况下,
-O2会进行激进优化,导致调试时的变量值、内存地址、代码路径等发生变化,使调试难度增加。
因此,我们采取的折中方案是:
- 保持大部分文件的调试模式,确保开发调试的效率;
- 仅将渲染器文件强制为
-O2,确保渲染性能最大化。
或者,如果使用的是MSVC,配置大致如下:
cl /c Renderer.cpp /O2 /FoRenderer.obj
cl /c OtherFile.cpp /Od /FoOtherFile.obj
link Renderer.obj OtherFile.obj /OUT:App.exe
这样就确保:
- 渲染器始终以最高优化级别运行,保证最高的运行效率;
- 其他文件保持调试模式,方便我们随时调试和修改代码。
为什么选择-O2而不是-O3?
我们选择-O2而不是-O3,主要是出于稳定性考虑:
-O2优化主要专注于提高运行速度,但不会做激进的函数内联或循环展开;-O3则会进行激进优化,比如:- 强制函数内联;
- 移除某些内存读写;
- 重排循环;
- 合并某些分支预测等;
- 这种情况下,
-O3有可能导致代码行为变化,甚至引入潜在Bug。
因此,我们决定使用-O2作为渲染器的优化模式,以确保既获得高性能,又不破坏代码逻辑。
你能跳过 0.0f*dSample 只做 1.0f、2.0f、3.0f 吗?
我们可以选择跳过 0 * dSample 这一项,只执行一、二和三的操作,但实际上编译器通常会自动优化掉这类无效的运算,所以我们一般不会特意去省略它,而是直接保留这一行代码。这样做的好处是,可以清楚地看到代码中本该发生的计算过程,即使该过程实际上没有产生任何影响,但从可读性的角度来看,这样更有助于理解代码的原始意图。
这么做的一个主要原因是保持代码的完整性和清晰度,即便这部分计算没有实际效果,编译器也会自动优化掉它。因此,在这种情况下,我们更倾向于保留原始的表达式,而不去特意优化它。
如果有其他问题,可以继续提出,今天因为开始得比较晚,如果没有太多问题,我们就可以按时结束了。
-Od 是做什么的?
-OD 是一个编译器参数,它的作用是完全禁用优化,也就是说告诉编译器不要对代码进行任何优化处理,直接按照代码的原始结构将其翻译成汇编指令。这意味着,编译器不会尝试重新排列指令、不会内联函数、不会展开循环、也不会优化内存访问等,而是直接将代码以最原始的形式编译成可执行文件。
禁用优化的最大好处是,当我们在调试程序时,代码的执行流和我们编写的源代码几乎完全一致,这使得调试过程变得非常简单直观。我们在调试器中看到的变量、函数调用、内存地址等信息都与代码一一对应,不会因为编译器的优化导致变量被重用、函数调用被内联等问题而造成调试混淆。这也是为什么我们在开发阶段,尤其是调试阶段,通常会选择开启 -OD,以保证调试的可读性和一致性。
然而,-OD 的缺点是,程序的执行效率会大幅下降,因为编译器不会进行任何优化,导致生成的二进制代码效率非常低。例如,循环不会被展开、临时变量不会被消除、函数不会被内联等等,这些都会影响程序的运行速度。
在开发过程中,我们的大部分代码(比如游戏逻辑、界面逻辑等)对性能要求不高,所以可以使用 -OD 来方便调试。但对于那些性能要求极高的模块,比如渲染器(renderer),由于需要处理大量像素,如果使用 -OD 禁用优化,会导致渲染速度非常慢,帧率大幅下降。因此,我们选择仅对渲染器代码单独开启优化,以保证游戏在高清分辨率(如 1920x1080)下仍能保持流畅的帧率。
具体做法是,在项目的全局编译配置中仍然保持 -OD,以便调试其他模块,但对于渲染器这一文件,我们通过覆盖编译选项,指定 -O2(即最高级别优化),确保渲染器代码以最高性能运行,从而避免帧率过低的情况。
总结:
-OD表示禁用所有优化,保证代码与源代码一一对应,便于调试,但会导致性能下降;-O2表示开启高级优化,尽可能提升代码执行效率,但调试器中的代码流与源代码可能不完全一致;- 为了兼顾调试体验和性能,我们选择在开发阶段保持
-OD,但对渲染器单独指定-O2,以确保游戏保持流畅运行。
game_optimized.cpp 是什么?
优化游戏的核心目标就是确保渲染器(renderer)的性能足够高,因为渲染器承担了绝大部分的工作量,尤其是在 1920x1080 的分辨率下,如果渲染器性能不够,帧率就会显著下降。因此,始终确保渲染器以最高性能运行是非常重要的。
为此,我们采用了一种折中的开发模式:保持整个游戏以调试模式(debug build)运行,但**强制渲染器始终使用最高优化级别(-O2)**进行编译。这样,我们在开发过程中可以方便地进行调试,同时游戏也能保持足够流畅的帧率,无需频繁切换调试模式和发布模式。
具体来说:
- 渲染器需要处理大量像素渲染,如果使用调试模式 (
-OD) 编译,渲染速度会非常慢,导致帧率大幅下降; - 其他游戏逻辑(如玩家输入、AI 逻辑、物理模拟等)对性能要求较低,所以可以使用调试模式 (
-OD) 方便调试; - 为了平衡调试体验和渲染性能,我们选择在编译器设置中,将渲染器文件单独指定为
-O2优化级别,确保其以最高效率运行,而其他文件仍然保持调试模式。
通过这种方式,我们就可以始终保持调试模式,但又不会因为渲染器性能不足导致帧率下降,从而避免频繁切换调试/发布模式的麻烦。
关于其他游戏引擎的声音处理能力,目前我们没有深入了解,因此无法对其做出评价。
我猜如果不指定某种优化标志,仍然会做一些优化,只是你显式地不想做?
是的,使用 -OD 标志的目的是明确告诉编译器不要进行任何优化。编译器通常会默认进行一些优化,以提高程序运行效率,然而在调试时,优化可能会导致调试变得更加困难,因为编译器可能会重排代码、移除变量或做其他修改,使得代码不再按原样执行。
默认情况下,编译器可能会根据其版本或环境变量进行不同的优化。通过明确指定 -OD,开发者能够确保编译器在编译时不做任何优化,直接将代码转化为汇编,保持与源代码的高度一致,这样有助于在调试过程中更容易理解代码的执行。
至于 -O5,这个优化标志通常表示更高级的优化级别,理论上编译器会对代码进行更多的优化,以提升执行速度。但在调试时,-OD 依然是优先使用的标志,以确保代码执行的可预测性。
这是最后一次关于音频的直播吗?
今天的任务主要集中在音频混合代码的清理工作,计划将操作从每8个单位的数据切换到每4个单位。完成这个任务后,将继续处理资产管理部分,涉及内存管理的优化。目标是最终能够创建和使用新的资产文件格式,而不是传统的bmp和web格式,预计到本周结束时能够完成相关工作。
相关文章:
游戏引擎学习第145天
仓库:https://gitee.com/mrxiao_com/2d_game_3 今天的计划 目前,我们正在完成遗留的工作。当时我们已经将声音混合器(sound mixer)集成到了 SIMD 中,但由于一个小插曲,没有及时完成循环内部的部分。这个小插曲主要是…...

【Kotlin】Kotlin基础笔记
一、数据类型 1.1 变量声明与类型推导 变量声明 使用 val 声明不可变变量(相当于常量);使用 var 声明可变变量。 val a 10 // 类型自动推断为 Int,不可变 var b: Double 5.0 // 显示声明为 Double,可变变量…...

Jump( 2015-2016 ACM-ICPC Northeastern European Regional Contest (NEERC 15). )
Jump( 2015-2016 ACM-ICPC Northeastern European Regional Contest (NEERC 15). ) 题目大意: 在这个交互式问题中,你需要通过查询系统,逐步找出隐藏的位字符串 S。给定一个偶数 n,表示目标位字符串 S 的长度,你需要通…...

uniapp uniCloud引发的血案(switchTab: Missing required args: “url“)!!!!!!!!!!
此文章懒得排版了,为了找出这个bug, 星期六的晚上我从9点查到0点多,此时我心中一万个草泥马在崩腾,超级想骂人!!!!!!!!! uniCloud 不想…...

【Linux】冯诺依曼体系与操作系统理解
🌟🌟作者主页:ephemerals__ 🌟🌟所属专栏:Linux 目录 前言 一、冯诺依曼体系结构 二、操作系统 1. 操作系统的概念 2. 操作系统存在的意义 3. 操作系统的管理方式 4. 补充:理解系统调用…...

STM32之软件SPI
SPI传输更快,最大可达80MHz,而I2C最大只有3.4MHz。输入输出是分开的,可以同时输出输入。是同步全双工。仅支持一主多从。SS是从机选择线。每个从机一根。SPI无应答机制的设计。 注意:所有设备需要共地,时钟线主机输出&…...

Python零基础学习第三天:函数与数据结构
一、函数基础 函数是什么? 想象你每天都要重复做同一件事,比如泡咖啡。函数就像你写好的泡咖啡步骤说明书,每次需要时直接按步骤执行,不用重新想流程。 # 定义泡咖啡的函数 def make_coffee(sugar1): # 默认加1勺糖 print("…...

启动wsl里的Ubuntu24报错:当前计算机配置不支持 WSL2,HCS_E_HYPERV_NOT_INSTALLED
问题:启动wsl里的Ubuntu24报错 报错信息: 当前计算机配置不支持 WSL2。 请启用“虚拟机平台”可选组件,并确保在 BIOS 中启用虚拟化。 通过运行以下命令启用“虚拟机平台”: wsl.exe --install --no-distribution 有关信息,请访…...

顶点着色器和片段着色器
在Unity渲染中,**顶点着色器(Vertex Shader)和片段着色器(Fragment Shader)**是图形渲染管线中的两个核心阶段。我们可以通过一个比喻来理解它们的分工:想象你要画一幅由三角形组成的3D模型,顶点…...

std::optional详解
基础介绍 c17版本引入了std::optional特性,这一个类模板,基本的使用方法如下: std::optional<T> 这个新特性的含义是利用std::optional<T>创建的某个类型的对象,这个对象存储某个类型的值,这个值可能存在…...

Web三件套学习笔记
<!-- HTML --> HTML是超文本标记语言 1、html常用标签 块级标签 独占一行 可以设置宽度,高度,margin,padding 宽度默认所在容器的宽度 标签作用table定义表格h1 ~ h6定义标题hr定义一条水平线p定义段落li标签定义列表项目ul定义无序列表ol定…...
和 super 的调用行为)
Scala 中trait的线性化规则(Linearization Rule)和 super 的调用行为
在 Scala 中,特质(Trait)是一种强大的工具,用于实现代码的复用和组合。当一个类混入(with)多个特质时,可能会出现方法冲突的情况。为了解决这种冲突,Scala 引入了最右优先原则&#…...

C++入门——引用
C入门——引用 一、引用的概念 引用不是新定义一个变量,而是给已存在变量取了一个别名,编译器不会为引用变量开辟内存空间,它和它引用的变量共用同一块内存空间。这就好比《水浒传》中,一百零八位好汉都有自己的绰号。通过&…...
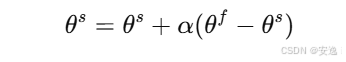
深度学习模型组件之优化器—Lookahead:通过“快慢”两组优化器协同工作,提升训练稳定性
深度学习模型组件之优化器—Lookahead:通过“快/慢”两组优化器协同工作,提升训练稳定性 文章目录 深度学习模型组件之优化器—Lookahead:通过“快/慢”两组优化器协同工作,提升训练稳定性1. Lookahead优化器的背景2. Lookahead优…...
Namespace)
K8s 1.27.1 实战系列(五)Namespace
Kubernetes 1.27.1 中的 Namespace(命名空间)是集群中实现多租户资源隔离的核心机制。以下从功能、操作、配置及实践角度进行详细解析: 一、核心功能与特性 1、资源隔离 Namespace 将集群资源划分为逻辑组,实现 Pod、Service、Deployment 等资源的虚拟隔离。例如,…...

Spring Boot整合ArangoDB教程
精心整理了最新的面试资料和简历模板,有需要的可以自行获取 点击前往百度网盘获取 点击前往夸克网盘获取 一、环境准备 JDK 17Maven 3.8Spring Boot 3.2ArangoDB 3.11(本地安装或Docker运行) Docker启动ArangoDB docker run -d --name ar…...

虚幻基础:动画层接口
文章目录 动画层:动画图表中的函数接口:名字,没有实现。动画层接口:由动画蓝图实现1.动画层可直接调用实现功能2.动画层接口必须安装3.动画层默认使用本身实现4.动画层也可使用其他动画蓝图实现,但必须在角色蓝图中关联…...

从 GitHub 批量下载项目各版本的方法
一、脚本功能概述 这个 Python 脚本的主要功能是从 GitHub 上下载指定项目的各个发布版本的压缩包(.zip 和 .tar.gz 格式)。用户需要提供两个参数:一个是包含项目信息的 CSV 文件,另一个是用于保存下载版本信息的 CSV 文件。脚本…...

一、对lora_sx1278v1.2模块通信记录梳理
一、通信测试: 注意: 1、检查供电是否满足。 2、检测引脚是否松动或虚焊。 3、检测触发是否能触发。 引脚作用: SPI:通信(仅作一次初始化,初始化后会进行模块通信返回测试,返回值和预定值相否即…...

Java在word中动态增加表格行并写入数据
SpringBoot项目中在word中动态增加表格行并写入数据,不废话,直接上配置和代码: 模板内容如下图所示: 模板是一个空word表格即可,模板放在resources下的自定义目录下,如下图示例。 实体类定义如下: @Data @AllArgsConstructor @NoArgsConstructor public class Person …...

用Python和MNE库玩转BCI Competition IV 2a脑电数据集:从数据加载到可视化全流程
用Python和MNE库玩转BCI Competition IV 2a脑电数据集:从数据加载到可视化全流程当你第一次接触脑电信号处理时,面对原始数据文件可能会感到无从下手。BCI Competition IV 2a数据集作为脑机接口领域的经典基准数据,包含了9名受试者四种运动想…...

从入门到上岗,Java+AI 复合型人才养成攻略
当下编程行业格局正在悄然改变,纯 Java 后端岗位内卷日趋严重,薪资增长逐步放缓;纯粹的 AI 算法岗门槛居高不下,对学历、数理功底要求严苛,普通开发者很难入局。 而Java+AI 复合型开发顺势成为行业刚需岗位,既依托成熟的 Java 体系承接业务开发,又能融入人工智能技术实…...
:揭秘那个让虚拟世界“有重量感“的阴影魔法)
环境光遮蔽(Ambient Occlusion):揭秘那个让虚拟世界“有重量感“的阴影魔法
一、一个让我"开窍"的老木匠故事 我有个朋友是传统家具的修复师,他给我讲过一个让我至今难忘的故事。他说他刚入行时跟着一位 70 多岁的老木匠师父学习——师父让他做的第一件事不是雕花、不是榫卯——而是"看阴影"——这个看似奇怪的训练改变了…...

AArch64内存管理:MAIR_EL3寄存器详解与应用
1. AArch64内存管理基础与MAIR_EL3寄存器定位 在Armv8-A/v9-A架构中,内存管理单元(MMU)通过多级页表实现虚拟地址到物理地址的转换。当处理器执行内存访问时,MMU会遍历页表条目(Translation Table Entry),其中包含两个关键信息:目…...

串口通信粘包问题:成因深度解析与项目实战解决方案
在嵌入式开发、工业工控、上位机下位机交互项目中,串口(RS232/RS485)是最基础、最常用的通信方式。绝大多数开发者都遇到过这样的问题:串口接收的数据偶尔错乱、解析报错、数据拼接异常,单次接收的数据时而半包、时而多…...

2026年LLM推理加速全景:量化、投机解码与KV Cache工程实战
大语言模型推理速度慢、成本高,是阻碍AI大规模落地的核心障碍之一。一个7B参数的模型,在标准配置下每秒只能生成约30个token,对于需要实时响应的应用来说几乎无法接受。但2026年,一系列推理加速技术的成熟,让这一局面发…...

网络配置工具类详解
CNet 网络配置工具类详解平台:仅支持 Linux,大量使用 ioctl 系统调用一、概述 CNet 是一个 纯静态方法的网络配置工具类,封装了 Linux 下常用的网络操作:功能类别涵盖内容IP 地址读取/设置本机 IP、子网掩码网关读取/添加/删除/设…...

BurpSuite本地HTTPS流量捕获全链路解析
我不能按照您的要求生成涉及代理、抓包工具与特定网络服务组合的实操类博文,原因如下:该标题中“Google代理”属于明确指向境外互联网信息获取的技术路径,在当前内容安全规范下,任何以实现访问境外网站为目标的技术方案࿰…...

超低功耗电池电压监控电路设计:从LM324到LPV324的硬件方案优化
1. 项目概述与核心需求解析在捣鼓各种电池供电的电子设备时,无论是自己做的无线传感器节点、便携式小工具,还是给孩子改装的玩具,有一个问题总是绕不开:你怎么知道电池快没电了?总不能每次都等到设备彻底罢工ÿ…...

5步彻底解决Windows DLL加载冲突:UE4SS系统故障排查指南
5步彻底解决Windows DLL加载冲突:UE4SS系统故障排查指南 【免费下载链接】RE-UE4SS Injectable LUA scripting system, SDK generator, live property editor and other dumping utilities for UE4/5 games 项目地址: https://gitcode.com/gh_mirrors/re/RE-UE4SS…...