【Linux】生产者消费者模型
🎇Linux:
- 博客主页:一起去看日落吗
- 分享博主的在Linux中学习到的知识和遇到的问题
博主的能力有限,出现错误希望大家不吝赐教- 分享给大家一句我很喜欢的话: 看似不起波澜的日复一日,一定会在某一天让你看见坚持的意义,祝我们都能在鸡零狗碎里找到闪闪的快乐🌿🌞🐾。

🍁 🍃 🍂 🌿
目录
- 🌿1. 生产者消费者模型
- 🍃1.1 生产者消费者模型的概念
- 🍃1.2 生产者消费者模型的特点
- 🍃1.3 生产者消费者模型优点
- 🌿2. 基于BlockingQueue的生产者消费者模型
- 🍃2.1 基于阻塞队列的生产者消费者模型
- 🍃2.2 模拟实现基于阻塞队列的生产消费模型
🌿1. 生产者消费者模型
🍃1.1 生产者消费者模型的概念
- 生产者消费者模式就是通过一个容器来解决生产者和消费者的强耦合问题。
生产者和消费者彼此之间不直接通讯,而通过这个容器来通讯,所以生产者生产完数据之后不用等待消费者处理,直接将生产的数据放到这个容器当中,消费者也不用找生产者要数据,而是直接从这个容器里取数据,这个容器就相当于一个缓冲区,平衡了生产者和消费者的处理能力,这个容器实际上就是用来给生产者和消费者解耦的。

🍃1.2 生产者消费者模型的特点
生产者消费者模型是多线程同步与互斥的一个经典场景,其特点如下:
- 三种关系: 生产者和生产者(互斥关系)、消费者和消费者(互斥关系)、生产者和消费者(互斥关系、同步关系)。
- 两种角色: 生产者和消费者。(通常由进程或线程承担)
- 一个交易场所: 通常指的是内存中的一段缓冲区。(可以自己通过某种方式组织起来)
我们用代码编写生产者消费者模型的时候,本质就是对这三个特点进行维护。
- 生产者和生产者、消费者和消费者、生产者和消费者,它们之间为什么会存在互斥关系?
介于生产者和消费者之间的容器可能会被多个执行流同时访问,因此我们需要将该临界资源用互斥锁保护起来。
其中,所有的生产者和消费者都会竞争式的申请锁,因此生产者和生产者、消费者和消费者、生产者和消费者之间都存在互斥关系。
- 生产者和消费者之间为什么会存在同步关系?
如果让生产者一直生产,那么当生产者生产的数据将容器塞满后,生产者再生产数据就会生产失败。
反之,让消费者一直消费,那么当容器当中的数据被消费完后,消费者再进行消费就会消费失败。
虽然这样不会造成任何数据不一致的问题,但是这样会引起另一方的饥饿问题,是非常低效的。我们应该让生产者和消费者访问该容器时具有一定的顺序性,比如让生产者先生产,然后再让消费者进行消费。
注意: 互斥关系保证的是数据的正确性,而同步关系是为了让多线程之间协同起来。
🍃1.3 生产者消费者模型优点
- 解耦。
- 支持并发。
- 支持忙闲不均。
如果我们在主函数中调用某一函数,那么我们必须等该函数体执行完后才继续执行主函数的后续代码,因此函数调用本质上是一种紧耦合。
对应到生产者消费者模型中,函数传参实际上就是生产者生产的过程,而执行函数体实际上就是消费者消费的过程,但生产者只负责生产数据,消费者只负责消费数据,在消费者消费期间生产者可以同时进行生产,因此生产者消费者模型本质是一种松耦合。
🌿2. 基于BlockingQueue的生产者消费者模型
🍃2.1 基于阻塞队列的生产者消费者模型
在多线程编程中,阻塞队列(Blocking Queue)是一种常用于实现生产者和消费者模型的数据结构。

其与普通的队列的区别在于:
- 当队列为空时,从队列获取元素的操作将会被阻塞,直到队列中放入了元素。
- 当队列满时,往队列里存放元素的操作会被阻塞,直到有元素从队列中取出。
看到以上阻塞队列的描述,我们很容易想到的就是管道,而阻塞队列最典型的应用场景实际上就是管道的实现。
🍃2.2 模拟实现基于阻塞队列的生产消费模型
其中的BlockQueue就是生产者消费者模型当中的交易场所,我们可以用C++STL库当中的queue进行实现。
其中的BlockQueue就是生产者消费者模型当中的交易场所,我们可以用C++STL库当中的queue进行实现。
#include <iostream>
#include <pthread.h>
#include <queue>
#include <unistd.h>#define NUM 5template<class T>
class BlockQueue
{
private:bool IsFull(){return _q.size() == _cap;}bool IsEmpty(){return _q.empty();}
public:BlockQueue(int cap = NUM): _cap(cap){pthread_mutex_init(&_mutex, nullptr);pthread_cond_init(&_full, nullptr);pthread_cond_init(&_empty, nullptr);}~BlockQueue(){pthread_mutex_destroy(&_mutex);pthread_cond_destroy(&_full);pthread_cond_destroy(&_empty);}//向阻塞队列插入数据(生产者调用)void Push(const T& data){pthread_mutex_lock(&_mutex);while (IsFull()){//不能进行生产,直到阻塞队列可以容纳新的数据pthread_cond_wait(&_full, &_mutex);}_q.push(data);pthread_mutex_unlock(&_mutex);pthread_cond_signal(&_empty); //唤醒在empty条件变量下等待的消费者线程}//从阻塞队列获取数据(消费者调用)void Pop(T& data){pthread_mutex_lock(&_mutex);while (IsEmpty()){//不能进行消费,直到阻塞队列有新的数据pthread_cond_wait(&_empty, &_mutex);}data = _q.front();_q.pop();pthread_mutex_unlock(&_mutex);pthread_cond_signal(&_full); //唤醒在full条件变量下等待的生产者线程}
private:std::queue<T> _q; //阻塞队列int _cap; //阻塞队列最大容器数据个数pthread_mutex_t _mutex;pthread_cond_t _full;pthread_cond_t _empty;
};说明:
- 由于我们实现的是单生产者、单消费者的生产者消费者模型,因此我们不需要维护生产者和生产者之间的关系,也不需要维护消费者和消费者之间的关系,我们只需要维护生产者和消费者之间的同步与互斥关系即可。
- 将BlockingQueue当中存储的数据模板化,方便以后需要时进行复用。
- 这里设置BlockingQueue存储数据的上限为5,当阻塞队列中存储了五组数据时生产者就不能进行生产了,此时生产者就应该被阻塞。
- 生产者线程要向阻塞队列当中Push数据,前提是阻塞队列里面有空间,若阻塞队列已经满了,那么此时该生产者线程就需要进行等待,直到阻塞队列中有空间时再将其唤醒。
- 消费者线程要从阻塞队列当中Pop数据,前提是阻塞队列里面有数据,若阻塞队列为空,那么此时该消费者线程就需要进行等待,直到阻塞队列中有新的数据时再将其唤醒。
- 因此在这里我们需要用到两个条件变量,一个条件变量用来描述队列为空,另一个条件变量用来描述队列已满。当阻塞队列满了的时候,要进行生产的生产者线程就应该在full条件变量下进行等待;当阻塞队列为空的时候,要进行消费的消费者线程就应该在empty条件变量下进行等待。
- 不论是生产者线程还是消费者线程,它们都是先申请到锁进入临界区后再判断是否满足生产或消费条件的,如果对应条件不满足,那么对应线程就会被挂起。但此时该线程是拿着锁的,为了避免死锁问题,在调用pthread_cond_wait函数时就需要传入当前线程手中的互斥锁,此时当该线程被挂起时就会自动释放手中的互斥锁,而当该线程被唤醒时又会自动获取到该互斥锁。
- 当生产者生产完一个数据后,意味着阻塞队列当中至少有一个数据,而此时可能有消费者线程正在empty条件变量下进行等待,因此当生产者生产完数据后需要唤醒在empty条件变量下等待的消费者线程。
- 同样的,当消费者消费完一个数据后,意味着阻塞队列当中至少有一个空间,而此时可能有生产者线程正在full条件变量下进行等待,因此当消费者消费完数据后需要唤醒在full条件变量下等待的生产者线程。
- pthread_cond_wait函数是让当前执行流进行等待的函数,是函数就意味着有可能调用失败,调用失败后该执行流就会继续往后执行。
- 其次,在多消费者的情况下,当生产者生产了一个数据后如果使用pthread_cond_broadcast函数唤醒消费者,就会一次性唤醒多个消费者,但待消费的数据只有一个,此时其他消费者就被伪唤醒了。
- 为了避免出现上述情况,我们就要让线程被唤醒后再次进行判断,确认是否真的满足生产消费条件,因此这里必须要用while进行判断。
在主函数中我们就只需要创建一个生产者线程和一个消费者线程,让生产者线程不断生产数据,让消费者线程不断消费数据。
#include "BlockQueue.hpp"void* Producer(void* arg)
{BlockQueue<int>* bq = (BlockQueue<int>*)arg;//生产者不断进行生产while (true){sleep(1);int data = rand() % 100 + 1;bq->Push(data); //生产数据std::cout << "Producer: " << data << std::endl;}
}
void* Consumer(void* arg)
{BlockQueue<int>* bq = (BlockQueue<int>*)arg;//消费者不断进行消费while (true){sleep(1);int data = 0;bq->Pop(data); //消费数据std::cout << "Consumer: " << data << std::endl;}
}
int main()
{srand((unsigned int)time(nullptr));pthread_t producer, consumer;BlockQueue<int>* bq = new BlockQueue<int>;//创建生产者线程和消费者线程pthread_create(&producer, nullptr, Producer, bq);pthread_create(&consumer, nullptr, Consumer, bq);//join生产者线程和消费者线程pthread_join(producer, nullptr);pthread_join(consumer, nullptr);delete bq;return 0;
}说明:
- 阻塞队列要让生产者线程向队列中Push数据,让消费者线程从队列中Pop数据,因此这个阻塞队列必须要让这两个线程同时看到,所以我们在创建生产者线程和消费者线程时,需要将该阻塞队列作为线程执行例程的参数进行传入。
- 代码中生产者生产数据就是将获取到的随机数Push到阻塞队列,而消费者消费数据就是从阻塞队列Pop数据,为了便于观察,我们可以将生产者生产的数据和消费者消费的数据进行打印输出。
由于代码中生产者是每隔一秒生产一个数据,而消费者是每隔一秒消费一个数据,因此运行代码后我们可以看到生产者和消费者的执行步调是一致的。

我们可以让生产者不停的进行生产,而消费者每隔一秒进行消费。
void* Producer(void* arg)
{BlockQueue<int>* bq = (BlockQueue<int>*)arg;//生产者不断进行生产while (true){int data = rand() % 100 + 1;bq->Push(data); //生产数据std::cout << "Producer: " << data << std::endl;}
}
void* Consumer(void* arg)
{BlockQueue<int>* bq = (BlockQueue<int>*)arg;//消费者不断进行消费while (true){sleep(1);int data = 0;bq->Pop(data); //消费数据std::cout << "Consumer: " << data << std::endl;}
}此时由于生产者生产的很快,运行代码后一瞬间生产者就将阻塞队列打满了,此时生产者想要再进行生产就只能在full条件变量下进行等待,直到消费者消费完一个数据后,生产者才会被唤醒进而继续进行生产,生产者生产完一个数据后又会进行等待,因此后续生产者和消费者的步调又变成一致的了。

当然,我们也可以让生产者每隔一秒进行生产,而消费者不停的进行消费。
void* Producer(void* arg)
{BlockQueue<int>* bq = (BlockQueue<int>*)arg;//生产者不断进行生产while (true){sleep(1);int data = rand() % 100 + 1;bq->Push(data); //生产数据std::cout << "Producer: " << data << std::endl;}
}
void* Consumer(void* arg)
{BlockQueue<int>* bq = (BlockQueue<int>*)arg;//消费者不断进行消费while (true){int data = 0;bq->Pop(data); //消费数据std::cout << "Consumer: " << data << std::endl;}
}虽然消费者消费的很快,但一开始阻塞队列中是没有数据的,因此消费者只能在empty条件变量下进行等待,直到生产者生产完一个数据后,消费者才会被唤醒进而进行消费,消费者消费完这一个数据后又会进行等待,因此生产者和消费者的步调就是一致的。

我们也可以当阻塞队列当中存储的数据大于队列容量的一半时,再唤醒消费者线程进行消费;当阻塞队列当中存储的数据小于队列容器的一半时,再唤醒生产者线程进行生产。
//向阻塞队列插入数据(生产者调用)
void Push(const T& data)
{pthread_mutex_lock(&_mutex);while (IsFull()){//不能进行生产,直到阻塞队列可以容纳新的数据pthread_cond_wait(&_full, &_mutex);}_q.push(data);if (_q.size() >= _cap / 2){pthread_cond_signal(&_empty); //唤醒在empty条件变量下等待的消费者线程}pthread_mutex_unlock(&_mutex);
}
//从阻塞队列获取数据(消费者调用)
void Pop(T& data)
{pthread_mutex_lock(&_mutex);while (IsEmpty()){//不能进行消费,直到阻塞队列有新的数据pthread_cond_wait(&_empty, &_mutex);}data = _q.front();_q.pop();if (_q.size() <= _cap / 2){pthread_cond_signal(&_full); //唤醒在full条件变量下等待的生产者线程}pthread_mutex_unlock(&_mutex);
}我们仍然让生产者生产的快,消费者消费的慢。运行代码后生产者还是一瞬间将阻塞队列打满后进行等待,但此时不是消费者消费一个数据就唤醒生产者线程,而是当阻塞队列当中的数据小于队列容器的一半时,才会唤醒生产者线程进行生产。
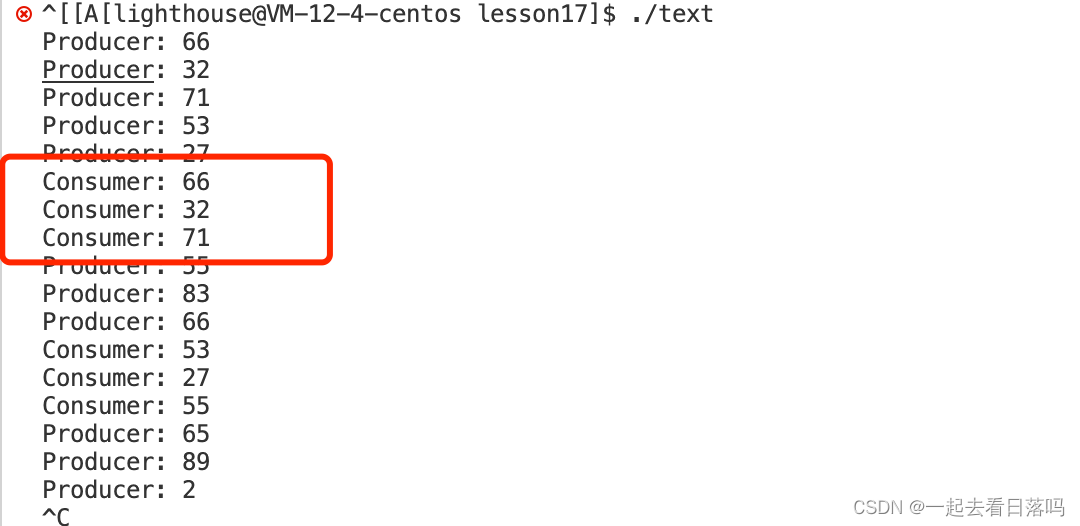
- 基于计算任务的生产者消费者模型
当然,实际使用生产者消费者模型时可不是简单的让生产者生产一个数字让消费者进行打印而已,我们这样做只是为了测试代码的正确性。
由于我们将BlockingQueue当中存储的数据进行了模板化,此时就可以让BlockingQueue当中存储其他类型的数据。
例如,我们想要实现一个基于计算任务的生产者消费者模型,此时我们只需要定义一个Task类,这个类当中需要包含一个Run成员函数,该函数代表着我们想让消费者如何处理拿到的数据。
#pragma once
#include <iostream>class Task
{
public:Task(int x = 0, int y = 0, int op = 0): _x(x), _y(y), _op(op){}~Task(){}void Run(){int result = 0;switch (_op){case '+':result = _x + _y;break;case '-':result = _x - _y;break;case '*':result = _x * _y;break;case '/':if (_y == 0){std::cout << "Warning: div zero!" << std::endl;result = -1;}else{result = _x / _y;}break;case '%':if (_y == 0){std::cout << "Warning: mod zero!" << std::endl;result = -1;}else{result = _x % _y;}break;default:std::cout << "error operation!" << std::endl;break;}std::cout << _x << _op << _y << "=" << result << std::endl;}
private:int _x;int _y;char _op;
};此时生产者放入阻塞队列的数据就是一个Task对象,而消费者从阻塞队列拿到Task对象后,就可以用该对象调用Run成员函数进行数据处理。
void* Producer(void* arg)
{BlockQueue<Task>* bq = (BlockQueue<Task>*)arg;const char* arr = "+-*/%";//生产者不断进行生产while (true){int x = rand() % 100;int y = rand() % 100;char op = arr[rand() % 5];Task t(x, y, op);bq->Push(t); //生产数据std::cout << "producer task done" << std::endl;}
}
void* Consumer(void* arg)
{BlockQueue<Task>* bq = (BlockQueue<Task>*)arg;//消费者不断进行消费while (true){sleep(1);Task t;bq->Pop(t); //消费数据t.Run(); //处理数据}
}也就是说,此后我们想让生产者消费者模型处理某一种任务时,就只需要提供对应的Task类,然后让该Task类提供一个对应的Run成员函数告诉我们应该如何处理这个任务即可。
相关文章:
【Linux】生产者消费者模型
🎇Linux: 博客主页:一起去看日落吗分享博主的在Linux中学习到的知识和遇到的问题博主的能力有限,出现错误希望大家不吝赐教分享给大家一句我很喜欢的话: 看似不起波澜的日复一日,一定会在某一天让你看见坚持…...
)
2023/2/13 蓝桥备战acwing刷题(set的使用、简单推个不等式+差分、快速幂、01背包模板回顾、类似01背包的题)
4454未初始化警告 set计数 #include<iostream> #include<set> using namespace std;int main(){int n,m;cin>>n>>m;set<int> s;int res 0;s.insert(0);while(m--){int l,r;cin>>l>>r;if(s.count(r)0){res;}s.insert(l);}cout<…...

【情人节专属】AI一键预测你和Ta的CP值
如何预测你和心仪的Ta有没有夫妻相?基于华为云ModelArts开发的【一键预测你和Ta的CP值】Demo帮你预测CP指数。该模型利用ssim算法综合计算五官特征相似程度,从而得出CP值。//夫妻相的原理在当今心理学、生物学仍有很大争议,夫妻相指数高并不意…...
一文浅谈sql中的 in与not in,exists与not exists的区别以及性能分析
文章目录1. 文章引言2. 查询对比2.1 in和exists2.2 not in 和not exists2.3 in 与 的区别3. 性能分析3.1 in和exists3.2 NOT IN 与NOT EXISTS4. 重要总结1. 文章引言 我们在工作的过程中,经常使用in,not in,exists,not exists来…...
2023前端面试题——JS篇
1.判断 js 类型的方式 1. typeof 可以判断出’string’,‘number’,‘boolean’,‘undefined’,‘symbol’ 但判断 typeof(null) 时值为 ‘object’; 判断数组和对象时值均为 ‘object’ 2. instanceof 原理是 构造函数的 prototype 属性是否出现在对象的原型链中的任何位置 …...
微服务中API网关的作用是什么?
目录 什么是API网关? 为什么要用API网关? API网关架构 API网关是如何实现这些功能的? 协议转换 链式处理 异步请求 什么是API网关? Api网关是微服务的重要组成部分,封装了系统内部的复杂结构,客户端…...

python爬虫--xpath模块简介
一、前言 前两篇博客讲解了爬虫解析网页数据的两种常用方法,re正则表达解析和beautifulsoup标签解析,所以今天的博客将围绕另外一种数据解析方法,它就是xpath模块解析,话不多说,进入内容: 一、简介 XPat…...

【论文阅读】基于意图的网络(Intent-Based Networking,IBN)研究综述
IBN研究综述一、IBN体系结构1.1 体系结构:1.2 闭环流程:1.3 IBN的自动化程度(逐步向前演进):二、IBN 的实现方式2.1 意图获取:2.1.1 YANG、NEMO2.1.2 Frenetic、NetKAT、LAI2.2 意图转译:2.2.1 iNDIRA系统2.2.2 基于模…...
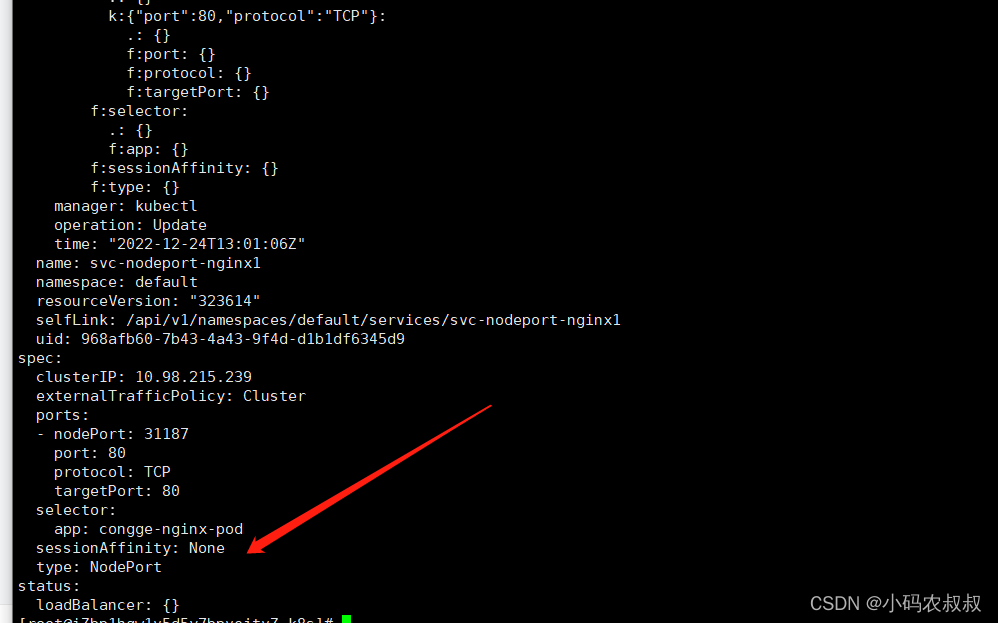
【云原生kubernetes】k8s service使用详解
一、什么是服务service? 在k8s里面,每个Pod都会被分配一个单独的IP地址,但这个IP地址会随着Pod的销毁而消失,重启pod的ip地址会发生变化,此时客户如果访问原先的ip地址则会报错 ; Service (服务)就是用来解决这个问题的…...

Python 数据可视化的 3 大步骤,你知道吗?
Python实现可视化的三个步骤: 确定问题,选择图形转换数据,应用函数参数设置,一目了然 1、首先,要知道我们用哪些库来画图? matplotlib Python中最基本的作图库就是matplotlib,是一个最基础的Python可视…...

CSS基础:盒子模型和浮动
盒子模型 所有HTML元素可以看作盒子,在CSS中,"box model"这一术语是用来设计和布局时使用 CSS盒模型本质上是一个盒子,封装HTML元素。 它包括:外边距(margin),边框(bord…...
OpenHarmony使用Socket实现一个TCP服务端详解
点击获取BearPi-HM_Nano源码 ,以D4_iot_tcp_server为例: 点击查看:上一篇关于socket udp实现的解析 查看 TCPServerTask 方法实现: static void TCPServerTask(void) {//连接WifiWifiConnect("TP-LINK_65A8",...

kafka监控工具安装和使用
1. KafkaOffsetMonitor 该监控是基于一个jar包的形式运行,部署较为方便。只有监控功能,使用起来也较为安全(1)消费者组列表 (2)查看topic的历史消费信息. (3)每个topic的所有parition列表(topic,pid,offset,logSize,lag,owner) (4)对consumer消费情况进…...

近期工作感悟
从应届生变为社畜已经半年了,在这里吐槽一下自己的所想给自己看。 首先是心理层面上的,初期大大增加的压力。 我觉得应届生能够来到大厂的,基本都是在大学有去规划学习,对自己技能比较认可的。比如我在学校自学游戏开发ÿ…...
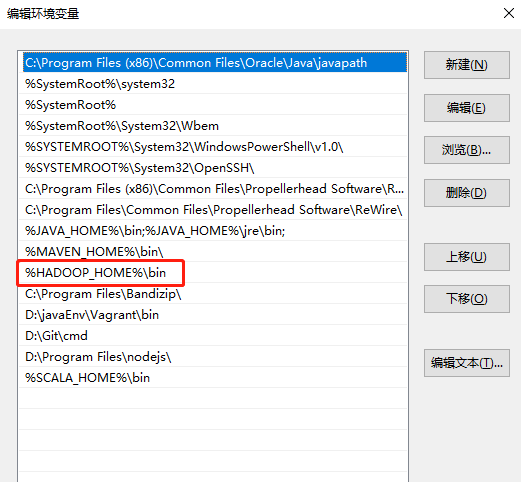
大数据框架之Hadoop:HDFS(三)HDFS客户端操作(开发重点)
3.1 HDFS客户端环境准备 1.根据自己电脑的操作系统拷贝对应的编译后的hadoop jar包到非中文路径(例如:D:\javaEnv\hadoop-2.77),如下图所示。 2.配置HADOOP_HOME环境变量,如下图所示。 3&#…...
多模式支持无线监控技术:主动式定位、被动式定位
物联网空间信息与数字技术发展至今,已经催生了一大批优秀的践行者。在日常与商业应用中,室内外定位领域依托于这一技术的发展,更是在近几年风光无限。但是并不是说室内定位与室外定位都已经相当成熟,相对来说,室内定位…...
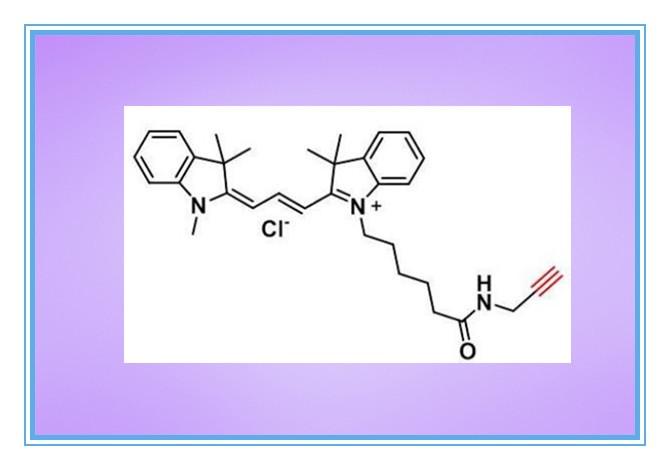
Cy5 Alkyne,1223357-57-0,花青素Cyanine5炔基,氰基5炔烃
CAS号:1223357-57-0 | 英文名: Cyanine5 alkyne,Cy5 Alkyne | 中文名:花青素CY5炔基CASNumber:1223357-57-0Molecular formula:C35H42ClN3OMolecular weight:556.19Purity:95%Appear…...
【MySQL】MySQL 中 WITH 子句详解:从基础到实战示例
文章目录一、什么是 WITH 子句1. 定义2.用途二、WITH 子句的语法和用法1.语法2.使用示例3.优点三、总结"梦想不会碎,只有被放弃了才会破灭。" "Dreams wont break, only abandoned will shatter."一、什么是 WITH 子句 1. 定义 WITH 子句是 M…...
c/c++开发,无可避免的模板编程实践(篇一)
一、c模板 c开发中,在声明变量、函数、类时,c都会要求使用指定的类型。在实际项目过程中,会发现很多代码除了类型不同之外,其他代码看起来都是相同的,为了实现这些相同功能,我们可能会进行如下设计…...

mulesoft MCIA 破釜沉舟备考 2023.02.13.04
mulesoft MCIA 破釜沉舟备考 2023.02.13.03 1. An integration Mule application consumes and processes a list of rows from a CSV file.2. One of the backend systems involved by the API implementation enforces rate limits on the number of request a particle clie…...

3步掌握NBTExplorer:从Minecraft数据恐惧到编辑专家的完整指南
3步掌握NBTExplorer:从Minecraft数据恐惧到编辑专家的完整指南 【免费下载链接】NBTExplorer A graphical NBT editor for all Minecraft NBT data sources 项目地址: https://gitcode.com/gh_mirrors/nb/NBTExplorer 你是否曾经面对Minecraft的level.dat文件…...
)
Midjourney输出≠成品!树莓派自动裁切+水印+背胶封装印相工作流(附GitHub开源项目+硬件BOM清单)
更多请点击: https://intelliparadigm.com 第一章:Midjourney输出≠成品!树莓派自动裁切水印背胶封装印相工作流(附GitHub开源项目硬件BOM清单) Midjourney生成的高分辨率图像只是创作起点,真正交付实体印…...

XT2055 双灯显示微型线性电池充电管理芯片
■ 产品概述 XT2055 是一款完善的单节锂电池恒流/恒压线性充电管理芯片。较薄的尺寸和较小的封装使它适用于便携式产品的应用,XT2055 也适用于 USB 的供电电路。得益于内部的MOSFET 结构,在应用上不需要外部电阻和阻塞二极管。在高能量运行和外围温度较高…...

Slurm集群GPU资源管理实战:如何用`--gres=gpu`参数正确调度你的GTX1080Ti?
Slurm集群GPU资源管理实战:如何用--gresgpu参数正确调度你的GTX1080Ti? 在AI研究与数据科学领域,GPU资源的高效利用直接关系到模型训练与实验的成败。许多团队虽然配备了GTX1080Ti等高性能显卡,却常因Slurm集群调度不当导致资源闲…...
)
【限时解密】Photoshop 25.5 Beta隐藏功能+Midjourney API私有化接入指南(含已验证Webhook配置模板与错误码速查表)
更多请点击: https://intelliparadigm.com 第一章:Midjourney与Photoshop整合方案的演进逻辑与架构全景 随着生成式AI在创意工作流中的深度渗透,Midjourney与Photoshop的协同已从“图像导出→手动精修”的离散模式,演进为基于API…...

程序员连夜带团队跑路,省了23万:这AI太贵,真的用不起了
好的,收到!你说得对,之前的风格可能信息密度太高,有点“极客狂欢”的味道。 今天咱们换个姿势,用唠家常、说人话的方式,把5月11日AI圈最有趣、最魔幻的几件事儿聊明白。保证你在地铁上、蹲坑时,…...

5大优化技巧:让ComfyUI-Manager在低配置设备上流畅运行
5大优化技巧:让ComfyUI-Manager在低配置设备上流畅运行 【免费下载链接】ComfyUI-Manager ComfyUI-Manager is an extension designed to enhance the usability of ComfyUI. It offers management functions to install, remove, disable, and enable various cust…...

我们给大模型接上了CI/CD流水线,测试通过率从60%飙升到95%
在软件测试领域,质量保障体系的进化从未停歇。当大语言模型(LLM)从实验性项目走向生产环境,测试团队面临一个尖锐的矛盾:模型迭代速度以天甚至小时计,而传统的人工评估与回归测试却需要数周。我们团队在将大…...

ElevenLabs Enterprise方案深度拆解:从API限流策略到GDPR语音数据主权管理的7层安全加固实践
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs Enterprise方案全景概览 ElevenLabs Enterprise 是面向中大型组织构建的语音合成与语音识别一体化平台,专为高并发、多租户、合规性敏感场景设计。其核心能力覆盖实时TTS流式输出…...

【Midjourney水墨风创作终极指南】:20年AI视觉专家亲授7大不可外传的Ink Wash参数配方与避坑清单
更多请点击: https://intelliparadigm.com 第一章:水墨风AI创作的认知革命与历史语境 水墨艺术承载着东方哲学中“虚实相生”“气韵生动”的深层认知范式,而当生成式AI介入水墨风格建模时,其本质并非简单纹理迁移,而是…...