【数据分析实战】基于python对酒店预订需求进行分析

文章目录
- 📚引言
- 📖数据加载以及基本观察
- 📑缺失值观察及处理
- 🔖缺失值观察以及可视化
- 🔖缺失值处理
- 📖用户数据探索
- 📑什么时间预定酒店将会更经济实惠?
- 📑哪个月份的酒店预订是最繁忙的?
- 📖商家数据探索
- 📑按市场细分的不同预定情况是怎样的?
- 📑什么样的人更容易取消预订?
- 🔖数据编码
- 🔖特征筛选
- 🔖构建模型并预测
- 🔖根据特征重要性得出结论
- 📍总结
📚引言
🙋♂️作者简介:生鱼同学,大数据科学与技术专业硕士在读👨🎓,曾获得华为杯数学建模国家二等奖🏆,MathorCup 数学建模竞赛国家二等奖🏅,亚太数学建模国家二等奖🏅。
✍️研究方向:复杂网络科学
🏆兴趣方向:利用python进行数据分析与机器学习,数学建模竞赛经验交流,网络爬虫等。
在有预定酒店的需求时,你是否考虑过以下的问题:
- 你是否曾想过每年什么时候是预订酒店房间的最佳时间?
- 为了获得最佳的每日价格,最佳的逗留时间?
- 如果你想预测一家酒店是否有可能收到过多的特殊要求呢?
在本文中我们就对Kaggle平台上的酒店需求数据集进行分析,这个数据集包含了一家城市酒店和一家度假酒店的预订信息,并包括诸如预订时间、逗留时间、成人、儿童和/或婴儿的数量,以及可用的停车位数量等信息。话不多说,我们开始吧。
本项目中的数据来源于Kaggle开放数据Hotel booking demand链接如下:
Hotel booking demand
需要的小伙伴可以自行下载获取。
📖数据加载以及基本观察
在进行数据加载之前,我们首先对数据的各个列进行解释,具体情况如下表所示:
| 列名 | 表达含义 |
|---|---|
| hotel | 酒店(H1=度假酒店或H2=城市酒店) |
| is_canceled | 表示预订是否被取消(1)或不被取消(0)的值。 |
| lead_time | 从预订进入PMS的日期到抵达日期之间的天数。 |
| arrival_date_year | 到达日期的年份 |
| arrival_date_month | 到达日期的月份 |
| arrival_date_week_number | 抵达日期的年份的周数 |
| arrival_date_day_of_month | 抵达日期当天 |
| stays_in_weekend_nights | 客人入住或预订入住酒店的周末晚数(周六或周日)。 |
| stays_in_week_nights | 客人入住或预订入住酒店的周夜数(周一至周五)。 |
| adults | 成人的数目 |
| children | 小孩的数目 |
| babies | 婴儿的数目 |
| meal | 预订的膳食类型。类别以标准接待餐包的形式呈现: 未定义/SC–无餐包;BB–床和早餐;HB–半餐(早餐和另外一餐–通常是晚餐);FB–全餐(早餐、午餐和晚餐)。 |
| country | 国家。类别以ISO 3155-3:2013的格式表示 |
| market_segment | 市场细分的指定。在类别中,"TA "指 “旅行社”,"TO "指 “旅游经营者”。 |
| distribution_channel | 预订分销渠道。术语 "TA "指 “旅行社”,"TO "指 “旅游经营者” |
| is_repeated_guest | 表示该预订名称是否来自重复的客人(1)或不(0)的值。 |
| previous_cancellations | 在当前预订之前被客户取消的先前预订的数量 |
| previous_bookings_not_canceled | 在本次预订之前,客户没有取消的先前预订的数量 |
| reserved_room_type | 保留的房间类型的代码。出于匿名的原因,用代码代替名称。 |
| assigned_room_type | 为预订分配的房间类型的代码。有时,由于酒店运营的原因(如超额预订)或客户要求,分配的房间类型与预订的房间类型不同。出于匿名的原因,用代码代替指定。 |
| booking_changes | 从预订被输入PMS到入住或取消的那一刻起,对预订进行更改/修正的次数 |
| deposit_type | 指明客户是否支付了押金以保证预订。这个变量可以有三个类别: 无押金–没有押金;不退款–押金的价值相当于总住宿费用;可退款–押金的价值低于总住宿费用。 |
| agent | 进行预订的旅行社的ID |
| company | 进行预订或负责支付预订的公司/实体的ID。出于匿名的原因,将出示身份证而不是指定的身份。 |
| days_in_waiting_list | 预订在确认给客户之前在等待名单中的天数 |
| customer_type | 预订的类型,假设是四类之一: 合同–当预订有一个分配或其他类型的合同与之相关时;团体–当预订与一个团体相关时;暂住–当预订不是团体或合同的一部分,并且没有与其他暂住预订相关时;暂住方–当预订是暂住的,但至少与其他暂住预订相关时 |
| adr | 日均房价的定义是用所有住宿交易的总和除以总的住宿夜数。 |
| required_car_parking_spaces | 预客户需要的车位数量 |
| total_of_special_requests | 客户提出的特殊要求的数量(如双床或高楼层)。 |
| reservation_status | 预订的最后状态,假设是三类中的一类: 取消–预订被客户取消;退房–客户已入住但已离开;未入住–客户未入住但已通知酒店原因 |
| reservation_status_date | 最后一次设置状态的日期。这个变量可以和ReservationStatus一起使用,以了解预订何时被取消或客户何时退房。 |
可以看到,数据所给出的特征还是比较多的。接下来我们就基于上述数据来解决一些商业角度可能关心的问题,本文解决的问题如下:
首先是从用户的角度来看关心的问题:
- 什么时间预定酒店将会更经济实惠?
- 哪个月份的酒店预订是最繁忙的?
其次是商家更容易关心的问题:
- 客人来自哪里?
- 按市场细分的不同预定情况是怎样的?
- 对酒店提出特殊要求的人有什么共同点?
- 什么样的人更容易取消预订?
首先我们调用**info()**函数来对数据进行初步的观察。代码和结果如下:
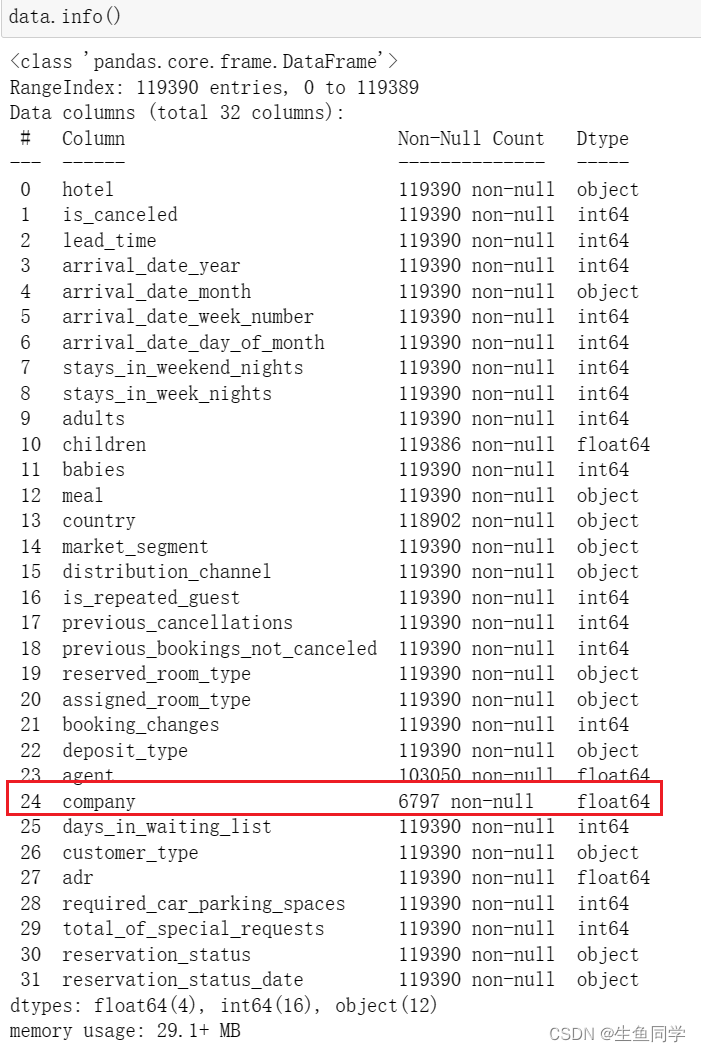
我们可以看到,公司这列有明显的缺失情况。与此同时,在这里我们也能了解到不同的数据类型。
📑缺失值观察及处理
🔖缺失值观察以及可视化
首先提取所有缺失的列以及它们缺失的个数情况,代码如下:
data_missing = data.isnull().sum()
data_missing = data_missing[data_missing > 0]
data_missing
结果如下:

接下来,我们对数据的缺失值进行一些简单的柱状图可视化。代码如下:
data_missing.plot.bar()
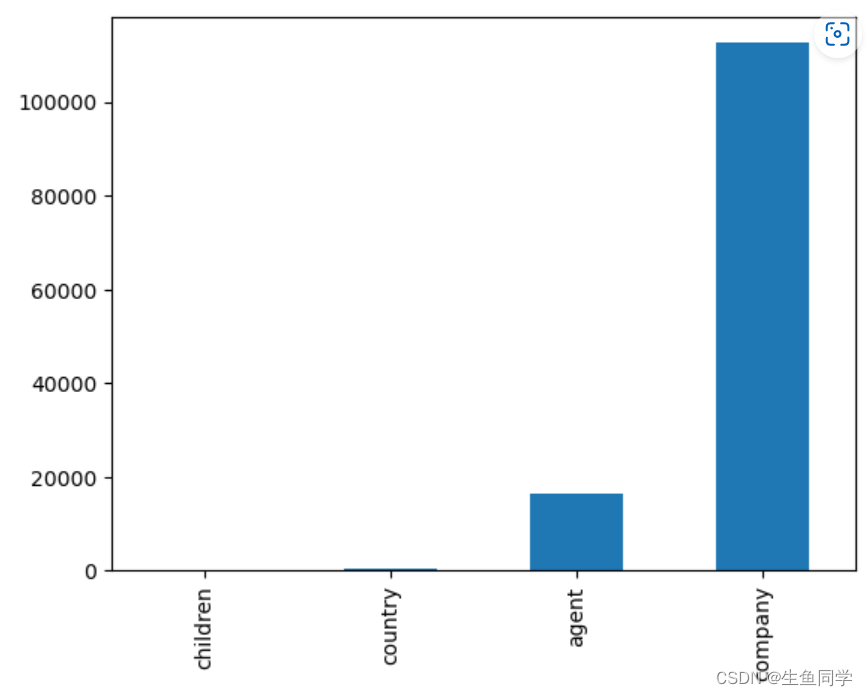
🔖缺失值处理
我们首先来看一下缺失值的实际意义代表情况,如下:
| 列名 | 表达含义 |
|---|---|
| children | 小孩的个数 |
| country | 国家。类别以ISO 3155-3:2013的格式表示 |
| agent | 进行预订的旅行社的ID |
| company | 进行预订或负责支付预订的公司/实体的ID。出于匿名的原因,将出示身份证而不是指定的身份。 |
基于上述特征的实际意义,我们对其进行如下的处理:
- children :缺失数据相对较少,我们选择删除携带孩子缺失的数据行。
- country:因为后续我们可能会用到该数据,所以设置为‘Unknown’。
- agent:预定的ID在本次数据分析中,不太重要,删除该特征。
- company:公司的数据在本次数据中,不太重要,而且确实程度过大,直接删除。
相关代码如下:
# inplace表示是否在原数据进行填充
data.dropna(axis=0, how='any',subset=['children'], inplace=True)
# 用Unknown填充'country'为Nan的数据
data.fillna({'country':'Unknown'}, inplace=True)
# 删除'agent','company'的列
data.drop(['agent','company'],axis=1, inplace=True)
📖用户数据探索
在进行了用户数据的基础探索后,接下来就开始对其进行一些分析工作。
📑什么时间预定酒店将会更经济实惠?
作为游客或者用户,我们较为关注的通常是酒店是否经济实惠。在下面的工作中,我们首先提取没有取消的那些订单作为我们分析的数据,然后对其进行一些处理最后进行可视化,代码如下:
import seaborn as sns
# 提取没有取消订单的数据
data_no_canceled = data[data['is_canceled']==0]
# 算出人均价格
data_no_canceled['adr_deal'] = data_no_canceled['adr']/ (data_no_canceled['adults'] + data_no_canceled['children'])
# 对结果进行可视化
ax = sns.lineplot(data=data_no_canceled, x = 'arrival_date_month',y='adr_deal',hue='hotel')
# 设置图片尺寸
ax.figure.set_size_inches(12,6)
结果如下:
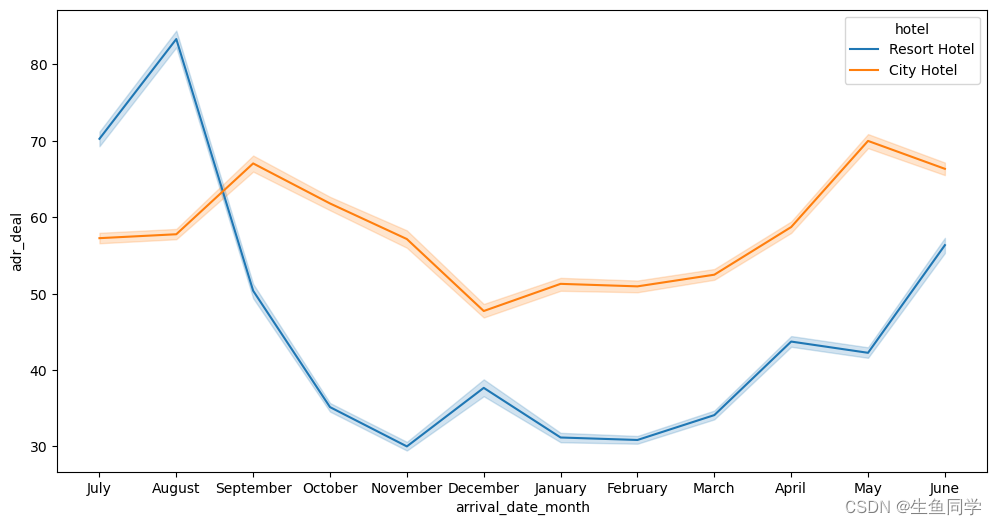
在图中我们可以发现,在七月Resort Hotel价格最高,而在其他时间City Hote的价格会稍高一些。另外,在十一月以及十二月两种酒店的价格是全年最低的,也就是最经济实惠的。
另外,我还探究了不同房型的价格分布情况,代码如下:
# 提取数据并进行排序
roomtype = data_no_canceled[["hotel", "reserved_room_type", "adr_deal"]].sort_values("reserved_room_type")
# 绘制箱线图
ax_box = sns.boxplot(data = roomtype, x = 'reserved_room_type',y='adr_deal',hue='hotel')
ax_box.figure.set_size_inches(12,6)
结果如下:
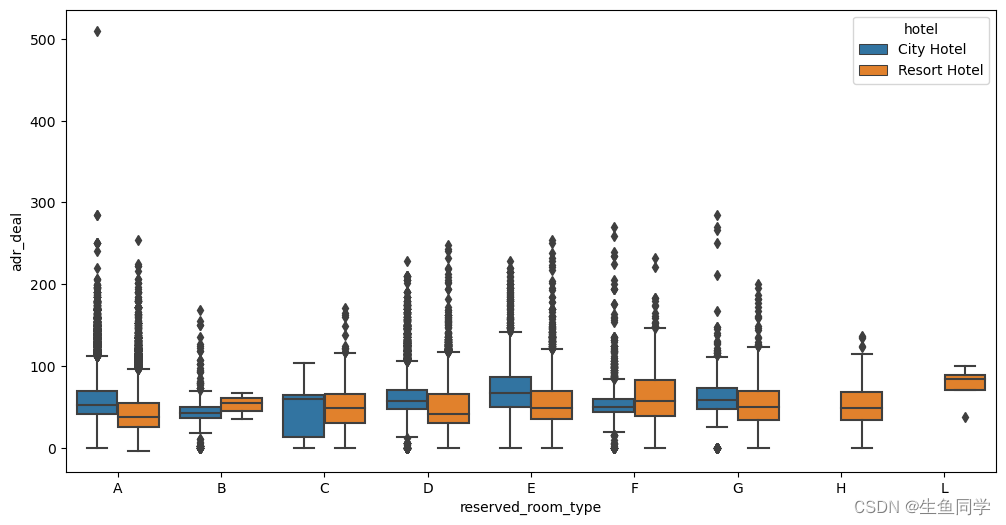
可以看到,在图中City Hotel的E房型价格偏高,而Resort Hotel的F房型价格偏高。
📑哪个月份的酒店预订是最繁忙的?
基于上述的分析,我们进一步探索哪个月份的酒店预订是最繁忙的,代码如下:
# 提取用户们到达的日期,并对其进行排序可视化
data_no_canceled['arrival_date_month'].value_counts().sort_values(ascending=False).plot.bar()
结果如下:
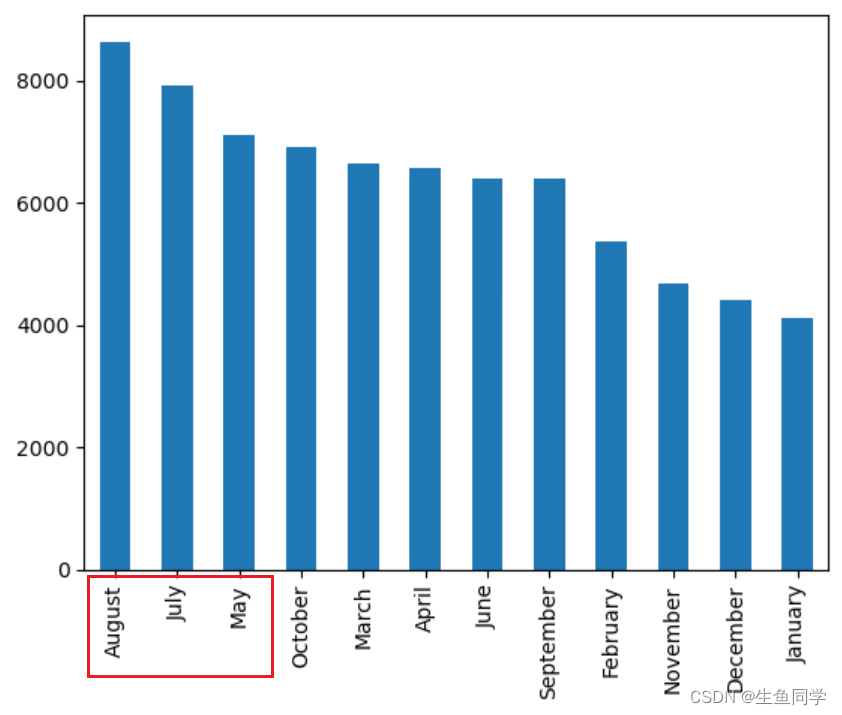
在图中可以看到,5,7,8月是最繁忙的时间,而秋冬季节的酒店人数相对来说较少。
📖商家数据探索
作为商家,较为关心的问题即用户的组成,以便更好的提供服务。另外,做为商家了解不同用户的订购渠道对于进一步的进行市场营销将会有积极的作用。
📑按市场细分的不同预定情况是怎样的?
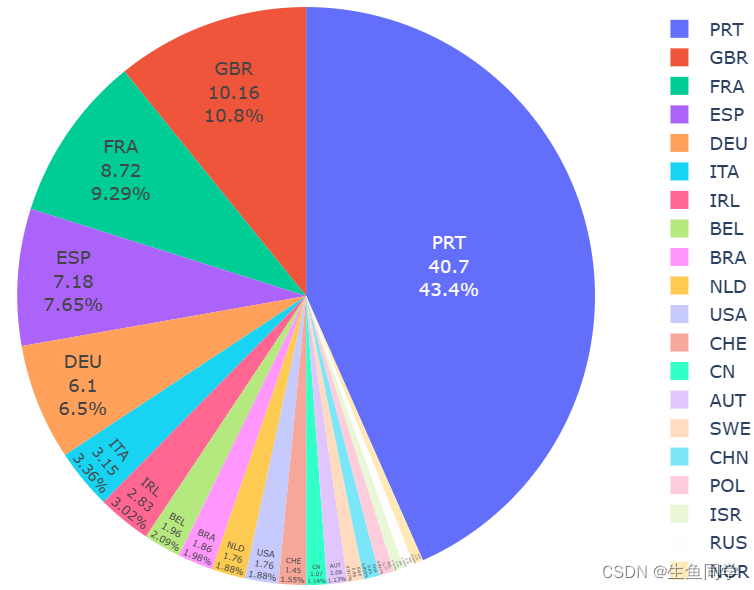
我们首先基于数据来探索预订酒店的不同国家的人数占比,并进行可视化,代码如下:
import plotly.express as px
# 计算不同国家的百分比
country_data = pd.DataFrame(data['country'].value_counts())
country_data.columns = ['guest_num']
country_data['guest_persent'] = round(country_data['guest_num'] / country_data['guest_num'].sum() * 100,2)# 对小于一定比例的国家归类
country_data.loc['OTHER','guest_num'] = country_data[country_data['guest_persent'] < 2]['guest_num'].sum()
country_data.loc['OTHER','guest_persent'] = round(country_data.loc['OTHER','guest_num'] / country_data['guest_num'].sum(),2)
# 可视化
country_data.drop(country_data[country_data['guest_persent'] < 0.5].index, inplace=True)
fig = px.pie(country_data,values = 'guest_persent',names = country_data.index)
fig.update_traces(textposition="inside", textinfo="value+percent+label")
结果如下:
进一步的,我们对不同预订酒店的渠道进行了统计,代码如下:
data_no_canceled['market_segment'].value_counts().plot.bar()
结果如下:
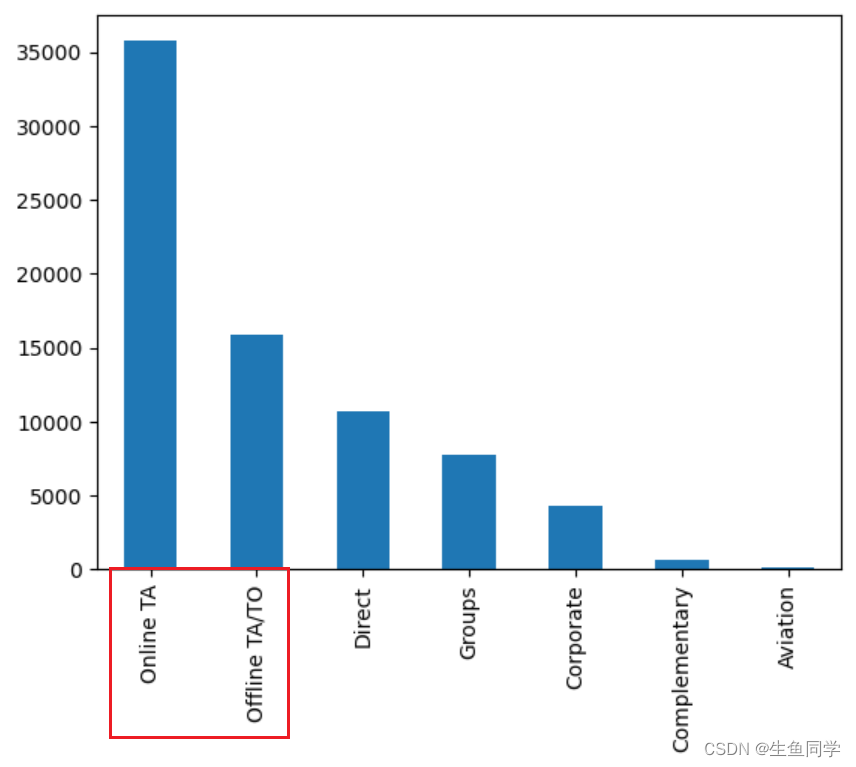
从图中可以看到,预订的主力军都是旅行社居多。另外,在线预定远比线下预订的数目要多很多。针对商家,可以对线上的广告推荐等进一步的进行策划营销。
📑什么样的人更容易取消预订?
最后,我们希望了解什么样的人更容易取消预订。商家可以针对这部分用户进行服务优化,并进一步的改善酒店的经营模式。在这里,我们准备基于数据进行机器学习模型的构建。
🔖数据编码
在这一步中,我们将对字符型的数据做编码处理,从而更好的适应不同模型,代码如下:
from sklearn import preprocessing
data_to_ml = data.copy()
# 因为我们预测的目标是是否取消了预订,所以删除这两列
data_to_ml.drop(['reservation_status','reservation_status_date'], axis=1, inplace=True)
# 对大部分特征进行编码处理
for col in ['hotel','arrival_date_month','meal','country','market_segment','distribution_channel','customer_type','deposit_type']:encoder = preprocessing.LabelEncoder()encoder.fit(data_to_ml[col])data_to_ml[f'{col}_labeled'] = encoder.transform(data_to_ml[col])data_to_ml.drop([col], axis=1, inplace=True)
在这里,我们有一个特殊的操作,即我们根据现有的特征提取了一个新的特征,即酒店预留的房间以及用户预定的是否是相同的。因为如果作为用户发现预定的房间和实际房间不同很可能会取消预订。具体代码如下:
import numpy as np
data_to_ml['is_reserved_assigned_equal'] = np.where(data_to_ml['reserved_room_type']==data_to_ml['assigned_room_type'],1,0)
data_to_ml.drop(['reserved_room_type','assigned_room_type'], axis=1, inplace=True)
🔖特征筛选
在这一步中,我们对所有处理后的数据进行了皮尔逊相关分析并做了可视化,代码如下所示:
import matplotlib.pylab as plt
correlation = data_to_ml.corr('pearson')f, ax = plt.subplots(figsize = (9, 9))
plt.title('Correlation of Numeric Features with',y=1,size=16)
sns.heatmap(correlation,square = True, vmax=0.8)
结果如下:
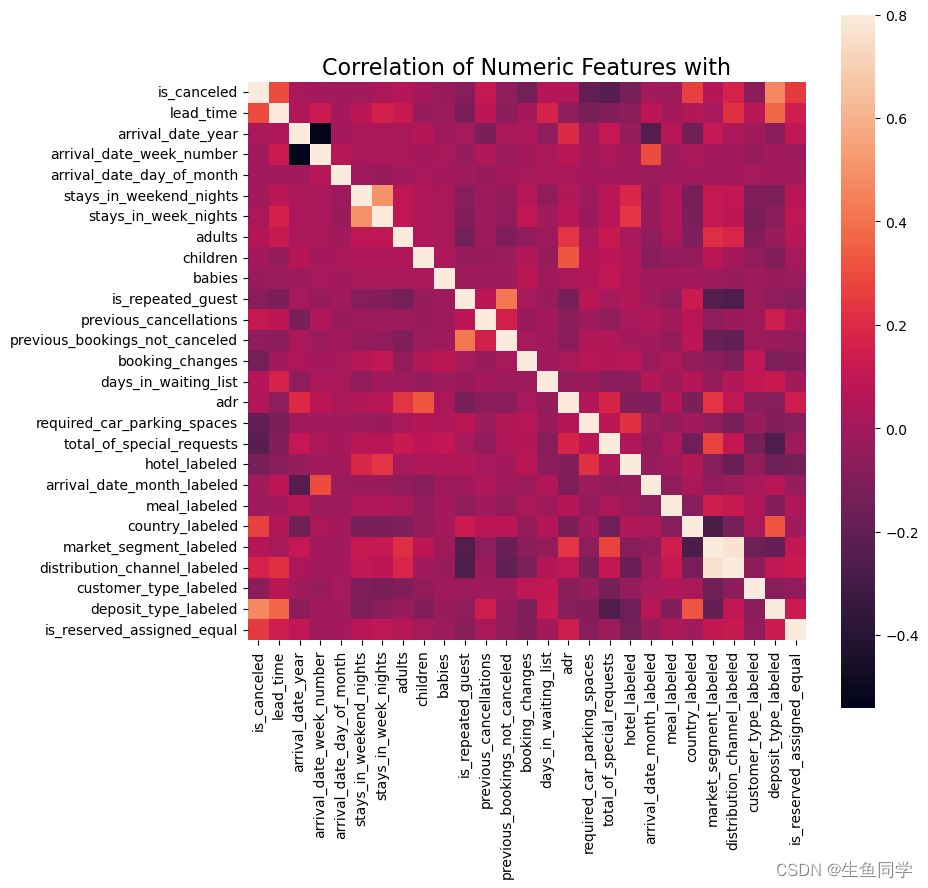
可以看到,我们所挑选的特征自相关性不算太高可以接受。与此同时,其针对我们所选定的目标is_canceled来说相关性也是可以接受的,所以我们暂时不对其进行处理。
🔖构建模型并预测
在这一部分中,我们构建了主流的模型并使用10折交叉认证对其进行验证,代码如下:
from sklearn import svm
from sklearn.ensemble import RandomForestClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn import model_selectionx_all = data_to_ml.drop('is_canceled',axis=1)
y_all = data_to_ml['is_canceled']# 为了避免训练时间过长,这里我选择了部分数据集
x_train = x_all.loc[:19999,:]
y_train = y_all[:20000]model_svm = svm.SVC()
model_knn = KNeighborsClassifier()
model_rf = RandomForestClassifier()model_dict = {'SVM':model_svm,'KNeighborsClassifier':model_knn,'RandomForestClassifier':model_rf
}
# 训练模型
for model in model_dict:model_dict[model].fit(x_train, y_train)scores = model_selection.cross_val_score(model_dict[model], X=x_train, y=y_train, verbose=1, cv = 10, scoring='f1')print(model, scores.mean())>>>SVM 0.6480724503120129
>>>KNeighborsClassifier 0.6577070795293697
>>>RandomForestClassifier 0.7363861778481174
可以看到,随机森林的效果是可以接受的,接下来我们对其特征重要性进行可视化。
🔖根据特征重要性得出结论
调用随机森林中自带的特征重要性函数,并对其进行了可视化,代码如下:
# 构建Series让特征重要性和特征名称一一对应
feature_importances_series = pd.Series(list(model_rf.feature_importances_), index = x_all.columns, )
# 对其进行排序
feature_importances_series =feature_importances_series.sort_values(ascending=False)
# 进行可视化
sns.barplot(x = feature_importances_series.values, y = feature_importances_series.index, orient='h')
结果如下:
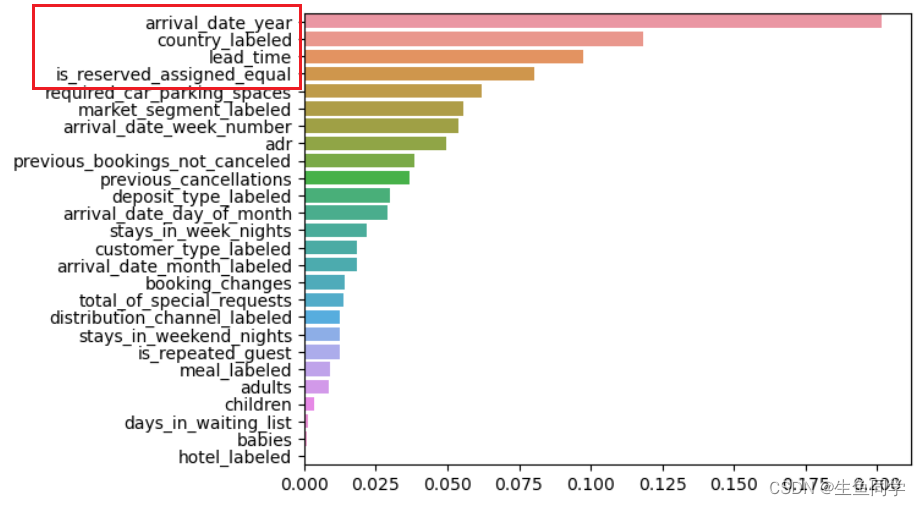
如图所示,用户取消预订和逗留时长、用户国籍、到达年份都有很强的相关性。另外,我们提取的特征也是非常重要的,即用户预定的房间和实际的房间不同时,用户将会更容易取消预订。
📍总结
在本文中,我们基于python对酒店预订需求进行分析,并从多种角度对其展开了探索性的工作。这对于养成数据分析习惯有很大的帮助,在实际工作或者学习中还需要不断练习。
感兴趣的朋友们可以自己按照上述步骤进行操作,或在评论区与我讨论。
需要源码的朋友可以私信我进行索取,我们下次再见。
相关文章:
【数据分析实战】基于python对酒店预订需求进行分析
文章目录📚引言📖数据加载以及基本观察📑缺失值观察及处理🔖缺失值观察以及可视化🔖缺失值处理📖用户数据探索📑什么时间预定酒店将会更经济实惠?📑哪个月份的酒店预订是…...

【新2023Q2模拟题JAVA】华为OD机试 - 数组的中心位置
最近更新的博客 华为od 2023 | 什么是华为od,od 薪资待遇,od机试题清单华为OD机试真题大全,用 Python 解华为机试题 | 机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为od机试,独家整理 已参加机试人员的实战技巧本篇题解:数组的中心位置 题目 给你一…...

Vue的props组件详解
const props defineProps({name: String, }); String 是在 defineProps() 函数中用来声明 name prop 的类型,表示 name 必须是字符串类型。如果父组件没有传入 name 或传入的 name 不是字符串类型,那么就会产生类型验证错误。 defineProps() 函数支持…...
抽烟行为识别预警系统 yolov5
抽烟行为识别预警系统基于yolov5网络模型智能分析技术,抽烟行为识别预警算法通过监测现场人员抽烟行为自动存档进行报警提示。我们选择当下YOLO卷积神经网络YOLOv5来进行抽烟识别检测。6月9日,Ultralytics公司开源了YOLOv5,离上一次YOLOv4发布…...

【0基础学爬虫】爬虫基础之文件存储
大数据时代,各行各业对数据采集的需求日益增多,网络爬虫的运用也更为广泛,越来越多的人开始学习网络爬虫这项技术,K哥爬虫此前已经推出不少爬虫进阶、逆向相关文章,为实现从易到难全方位覆盖,特设【0基础学…...

airflow源码分析-任务调度器实现分析
Airflow源码分析-任务调度器实现分析 概述 本文介绍Airflow执行器的总体实现流程。通过函数调用的方式说明了Airflow scheduler的实现原理,对整个调度过程的源码进行了分析。 通过本文,可以基本把握住Airflow的调度器的运行原理主线。 启动调度器 可…...
和reduceRight())
一文学会数组的reduce()和reduceRight()
reduce()方法和reduceRight()方法依次处理数组的每个成员,最终累计为一个值。 它们的差别是,reduce()是从左到右处理,reduceRight()则是从右到左,其他完全一样。 [1, 2, 3, 4, 5].reduce(function (a, b) {console.log(a, b);ret…...
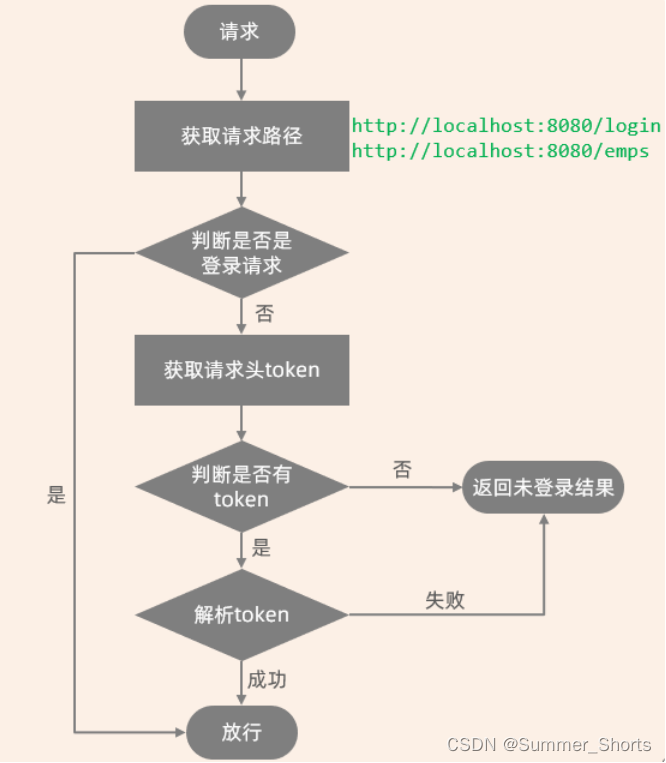
登录校验-Filter
上一篇介绍完了基础应用和细节,现在来完成登录校验功能基本流程: 要进入后台管理系统,必须完成登录操作,此时就需要访问登录接口Login。登录成功服务端会生成一个JWT令牌,并且返回给前端,前端会将JWT令牌存…...

C C++ Java python 分别写出不同表白girlfriend的爱心动态代码实现
C `` #include <stdio.h> #include <stdlib.h> #include <windows.h> void heart_animation() {int i, j, k; for (i = 1; i <= 6; i++) {for (j = -3; j <= 3; j++) {for (k = -4; k <= 4; k++) {if (abs(j) + abs(k) < i * 2) {printf(“I”)…...

ThreeJS-投影、投影模糊(十七)
无投影: 完整的代码: <template> <div id"three_div"></div> </template> <script> import * as THREE from "three"; import { OrbitControls } from "three/examples/jsm/controls/Or…...
)
蓝桥杯赛前冲刺-枚举暴力和排序专题1(包含历年蓝桥杯真题和AC代码)
目录 连号区间数(第四届蓝桥杯省赛CB组,第四届蓝桥杯省赛JAVAB组) 递增三元组(第九届蓝桥杯省赛CB组,第九届蓝桥杯省赛JAVAB组) 特别数的和(第十届蓝桥杯省赛CB组,第十届蓝桥杯省赛JAVAB组) 错误票据&a…...
Github库中的Languages显示与修改
目录 前言 【.gitattributes】文件 修改GitHub语言 前言 上传一个项目到GitHub时,发现显示的语言并非是自己项目所示的语言,这样的情况是经常发生的,为了能到达自己所需快速检索,或者是外部访问者能很好的搜索我们的项目&#…...

RocketMQ消息高可靠详解
文章目录 消息同步策略殊途同归同步基于offset而不是消息本身刷盘策略RocketMQ broker服务端以组为单位提供服务的,拥有着一样的brokerName则认为是一个组。其中brokerId=0的就是master,大于0的则为slave。 消息同步策略 master和slave都可以提供读服务,但是只有master允许…...

【python设计模式】4、建造者模式
哲学思想: 建造者模式的哲学思想是将复杂对象的创建过程分解成多个简单的步骤,并将这些步骤分别封装在一个独立的建造者类中。然后,我们可以使用一个指挥者类来控制建造者的调用顺序,以便在每个步骤完成后正确地构建复杂对象。 …...

【全网独家】华为OD机试Golang解题 - 机智的外卖员
华为Od必看系列 华为OD机试 全流程解析+经验分享,题型分享,防作弊指南华为od机试,独家整理 已参加机试人员的实战技巧华为od 2023 | 什么是华为od,od 薪资待遇,od机试题清单华为OD机试真题大全,用 Python 解华为机试题 | 机试宝典使用说明 如果想要在华为od机试中获取高分…...

Sentinel滑动时间窗限流算法原理及源码解析(中)
文章目录 MetricBucketMetricEvent数据统计的维度WindowWrap样本窗口实例 范型T为MetricBucket windowLengthInMs 样本窗口长度 windowStart 样本窗口的起始时间戳 value 当前样本窗口的统计数据 其类型为MetricBucket MetricBucket MetricEvent数据统计的维度 1、首先计算27t位…...
【OpenLayers】VUE+OpenLayers+ElementUI加载WMS地图服务
【OpenLayers】VUEOpenLayersElementUI加载WMS地图服务准备工作安装vue创建vue项目安装OpenLayers安装ElementUI加载wms地图服务准备工作 需要安装好nodejs,nodejs下载地址,下载对应的版本向导式安装即可。 安装完成后,控制台输入node -v&a…...

linux 命名管道 mkfifo
专栏内容:linux下并发编程个人主页:我的主页座右铭:天行健,君子以自强不息;地势坤,君子以厚德载物.目录 前言 概述 原理介绍 接口说明 代码演示 结尾 前言 本专栏主要分享linux下并发编程…...
Redis(主从复制、哨兵模式、集群)概述及部署
目录 1.redis高可用 2.redis持久化 1.Redis 提供两种方式进行持久化: 2.RDB 持久化 3.AOF持久化 4.RDB和AOF的优缺点 5.Redis 性能管理 3.redis主从复制 1.Redis主从复制的概念 2.Redis主从复制的作用 3.Redis主从复制的搭建 4.redis哨兵模式 1.哨兵模式…...

windows下软件包安装工具之Scoop安装与使用
Scoop介绍 Scoop是Windows的命令行程序安装器。 Scoop从命令行安装程序,及其容易。它有如下特点: 消除权限弹出窗口隐藏 GUI 向导样式的安装程序防止安装大量程序的 PATH 污染避免安装和卸载程序的意外副作用自动查找并安装依赖项自行执行所有额外的设…...

Local AI MusicGen教育应用:帮助学生理解音乐情绪表达方式
Local AI MusicGen教育应用:帮助学生理解音乐情绪表达方式 1. 引言:当AI成为音乐老师 想象一下,你是一位音乐老师,正在给学生讲解“悲伤”这种情绪在音乐中是如何表达的。传统的教学方式可能是播放一段肖邦的夜曲,或…...

解锁光猫配置自由:中兴ONT解密工具完全指南
解锁光猫配置自由:中兴ONT解密工具完全指南 【免费下载链接】ZET-Optical-Network-Terminal-Decoder 项目地址: https://gitcode.com/gh_mirrors/ze/ZET-Optical-Network-Terminal-Decoder 你是否曾经因为无法修改光猫设置而感到束手无策?当运营…...

5分钟快速上手!用VeriStand为你的Simulink模型搭建一个简易监控仪表盘
5分钟快速上手!用VeriStand为Simulink模型搭建实时监控仪表盘 在工程仿真领域,能够直观观察模型运行状态并实时调整参数,是提升开发效率的关键。想象一下这样的场景:你刚完成一个BUCK电路的Simulink建模,通过仿真验证了…...

OpenOCD入门到精通:第23章 添加新的 JTAG 适配器驱动
第23章 添加新的 JTAG 适配器驱动 导读摘要:OpenOCD 支持 40 余种调试适配器,每种适配器背后都有一个遵循统一接口规范的驱动程序。本章从 adapter_driver 结构体出发,逐一解析其回调函数语义,介绍 libusb/HIDAPI 通信层封装,并通过一个完整的简易驱动实现示例,帮助读者掌…...
)
Three.js 3D地图实战:从GeoJSON数据到交互式可视化(附完整代码)
Three.js 3D地图实战:从GeoJSON数据到交互式可视化 当我们需要在网页上展示一个具有真实地理特征的3D地图时,Three.js无疑是最强大的工具之一。它不仅能让地图以立体的形式呈现,还能添加各种交互效果,让数据可视化变得更加生动。本…...

如何在Mac上免费本地运行Stable Diffusion:Mochi Diffusion终极指南
如何在Mac上免费本地运行Stable Diffusion:Mochi Diffusion终极指南 【免费下载链接】MochiDiffusion Run Stable Diffusion on Mac natively 项目地址: https://gitcode.com/gh_mirrors/mo/MochiDiffusion 还在寻找能在Mac上完美运行Stable Diffusion的免费…...

JPEGCamera嵌入式库:LS-Y201摄像头UART协议解析与蓝牙传输
1. JPEGCamera 库概述:面向 LS-Y201 模块的嵌入式 JPEG 图像采集与蓝牙传输框架JPEGCamera 是一个专为 LinkSprite LS-Y201 JPEG 摄像头模块设计的轻量级嵌入式软件库,其核心目标是在资源受限的 MCU 平台上(如 STM32F1/F4 系列、ESP32、nRF52…...

OpenClaw安全加固:nanobot镜像的权限控制最佳实践
OpenClaw安全加固:nanobot镜像的权限控制最佳实践 1. 为什么需要关注OpenClaw的安全配置 去年夏天,我在本地部署OpenClaw时犯过一个致命错误——直接以管理员权限运行了未经审查的自动化脚本。结果这个脚本在半夜执行时误删了我整个项目目录的源码&…...
)
手把手教你用STM32实现BLDC电机的SPWM控制(附代码调试心得)
STM32实战:无刷直流电机SPWM控制全解析与代码优化指南 从理论到实践:BLDC电机控制的核心逻辑 第一次接触无刷直流电机(BLDC)控制时,我被它优雅的工作原理所吸引——没有电刷的火花和磨损,却能实现高效的能量转换。在工业自动化、无…...
)
DeepSeek LintCode 3866.有效子数组的数量 public int validSubarrays(int[] nums)
这是关于LintCode 3866 “有效子数组的数量”的问题。这是一个典型的单调栈应用问题,需要计算数组中所有满足特定条件的子数组数量。 问题理解 有效子数组的定义: 对于数组 nums 中的某个子数组 nums[i..j](i ≤ j),如…...