RandomAccessFile类 断点续传
文章目录
- 学习链接
- RandomAccessFile
- 构造方法
- 实现的接口
- DataOutput
- DataInput
- AutoCloseable
- 重要的方法
- 多线程读写同一个文件(多线程复制文件)
- 代码1
- 代码2
- 断点续传
- FileUtils
学习链接
RandomAccessFile详解
Java IO——RandomAccessFile类详解
java多线程-断点续传
RandomAccessFile
构造方法
需要传入一个 File 和 指定模式
- 当指定的file不存在时,会创建文件。但它不会帮我们创建目录,目录不存在的话,会报错。当指定的file存在时,不会对原文件有影响
- 模式可以指定为:r、rw、rwd、rws
实现的接口
它实现了3个接口,其中的方法如下
DataOutput
定义了写的方法,每次写都是从文件指针的位置开始写,每写一个字节,文件指针往后移动一位,可以接着从文件指针位置继续读,初始文件指针filePointer为0,也就意味着刚开始如果不设置初始文件指针,就会从头开始覆盖文件的数据。
- 与FileOutputStream区别:文件输出流如果需要追加,需要传入第二个参数append为true,否则,会删除文件的所有字节,这点是比较危险的。
- RandomAccessFile可以先把文件指针移动最后面(通过seek或skipBytes),然后开始写入)
- void write(int b)-写入的是一个字符,而不是整数,写入整数要用writeInt
- void write(byte b[])
- void write(byte b[], int off, int len)
- void writeBoolean(boolean v)
- void writeByte(int v)
- void writeShort(int v)
- void writeChar(int v)
- void writeInt(int v)
- void writeLong(long v)
- void writeDouble(double v)
- void writeBytes(String s)
- void writeChars(String s)
- void writeUTF(String s)
DataInput
定义了读的方法,每次读都是从指针的位置开始写,每读一个字节,指针往后移动一位,可以接着从指针位置继续读,初始指针filePointer为0。
- void readFully(byte b[], int off, int len) - 将从文件指针开始最多读取len个字节内容,给到byte数组的从off开始的偏移量
- void readFully(byte b[]) - 同上,只不过off为0,len为b.length
- int skipBytes(int n)
- boolean readBoolean()
- byte readByte()
- int readUnsignedByte()
- short readShort()
- int readUnsignedShort()
- char readChar()
- int readInt()
- long readLong()
- float readFloat()
- double readDouble()
- String readLine()
- String readUTF()
AutoCloseable
- void close()
重要的方法
native long length()- 获取文件的字节数native void setLength(long newLength)- 设置文件占用的字节数(如果源文件不够这个字节数量,用0补充;如果源文件比这个子节数量,要是多的话,多的部分直接截掉)native long getFilePointer()- 获取当前文件指针(以字节为单位,相当于游标)void seek(long pos)(绝对位置)- 可以直接用来设置当前文件指针的位置(会移动文件指针到指定的位置),从文件最开始的位置开始算- 可以超出文件大小,但是超出后,只有当写入之后,才会改变文件的大小int skipBytes(int n) (相对位置)- 从当前位置跳过指定的字节数量(会移动文件指针到跳过的位置)- 如果设置的参数超过了文件末尾,不会抛出异常,只会返回实际跳过的字节数
多线程读写同一个文件(多线程复制文件)
代码1
代码是每个线程负责一个分片大小10M,算出需要创建的线程,然后每个线程就只负责自己的10M数据。
public class RafTest {public static void main(String[] args) throws IOException, InterruptedException {File file = new File("D:\\Projects\\demo-raf\\test.mp4");// 分片大小int shardSize = 10 * 1024 * 1024; // 10M// 线程数量int threadNum = (int) (Math.ceil((double) file.length() / shardSize));System.out.println("线程数量: " + threadNum);CountDownLatch latch = new CountDownLatch(threadNum);List<Thread> threadList = new ArrayList<>();for (int i = 0; i < threadNum; i++) {final int j =i;Thread t = new Thread(() -> {try {// 每个线程要用自己的RandomAccessFile,它不是线程安全的// 待读取的文件RandomAccessFile rafsrc = new RandomAccessFile(new File("D:\\Projects\\demo-raf\\test.mp4"), "r");// 待写入的文件// (刚开始,这个文件是不存在的,new完之后,还没开始写,它就创建了,第一个线程可以直接写入)// (第二个线程发现当前文件是存在的,然后需要从指定位置开始写,注意这个指定位置是可以超过文件大小的,看seek的用法)RandomAccessFile raftarget = new RandomAccessFile(new File("D:\\Projects\\demo-raf\\test-copy.mp4"), "rw");// 每个线程负责读写的开始位置int pos = j * shardSize;rafsrc.seek(pos);raftarget.seek(pos);// 每个线程最多负责读取长度为shardSize,即一个分片大小int totalRead = 0; // 记录当前线程已读取的字节数int len = 0; // 当次循环中读取的字节数// 缓冲数组byte[] bytes = new byte[5 * 1024]; // 5kwhile (true) {// 最多读取到bytes.lengh的字节数量的数据到bytes中,len是读取的字节数量len = rafsrc.read(bytes);// 读到末尾了,没数据了,就退出循环if (len == -1) {break;}// 确定上面的read方法能读到数据,再写入raftarget.write(bytes, 0, len);totalRead += len; // 当前线程已读取并且写入的字节数// 每个线程只负责一分片大小if (totalRead >= shardSize) { // 1. 这里大于或等于的意思是:要读够一个分片大小,除非遇到文件末尾了break; // 2. 读取该分片时,由于缓冲数组的存在,有可能会读到下一个分片的数据,} // 但是没有关系,下一个分片的起始位置会从指定处开始写,因此会覆盖上一个线程写入的数据。// 覆不覆盖也没关系,都是同样的数据嘛(这点须理解下,由于缓冲数组的存在,多个线程可能操作了同一段数据了)} // 3. 读取到最后一个分片时,这个分片大小一定小于或等于预设值的分片大小,由于缓存数组的存在,会不会存在问题呢?// 没有问题,因为最后一次读取都不够缓存数组的话,会返回已读取到的字节数,然后写入后,继续读取,就会返回-1,从而退出了循环// 4. 线程的执行顺序也对最终写的文件没有影响,需要结合seek的用法来看,因为seek本身就能指定超过文件大小的位置,// 然后从这个位置开始写入,因此,先写入前一段,还是后一段都没影响,这一点比较重要哦!也能从中体会到这个类的作用。latch.countDown();} catch (IOException e) {e.printStackTrace();}});threadList.add(t);}threadList.forEach(t->t.start());latch.await();}
}
代码2
上面这样写不好,最好改成成固定线程数量,每个线程平分,不然文件一大,创建的线程数量太多了。(详细解释请看代码1的注释)
package com.zzhua;import java.io.File;
import java.io.IOException;
import java.io.RandomAccessFile;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.CountDownLatch;public class RafTest2 {public static void main(String[] args) throws IOException, InterruptedException {File file = new File("D:\\documents\\尚硅谷JavaScript高级教程\\视频1.zip");int threadNum = 5; // 指定5个线程// 计算每个分片大小final int shardSize = (int)(Math.ceil((double)file.length() / threadNum));CountDownLatch latch = new CountDownLatch(threadNum);List<Thread> threadList = new ArrayList<>();for (int i = 0; i < threadNum; i++) {final int j =i;Thread t = new Thread(() -> {try {// 待读取的文件RandomAccessFile rafsrc = new RandomAccessFile(new File("D:\\documents\\尚硅谷JavaScript高级教程\\视频1.zip"), "r");// 待写入的文件RandomAccessFile raftarget = new RandomAccessFile(new File("D:\\documents\\尚硅谷JavaScript高级教程\\视频1_copy.zip"), "rw");// 每个线程负责读写的开始位置int pos = j * shardSize;rafsrc.seek(pos);raftarget.seek(pos);// 缓冲数组byte[] bytes = new byte[5 * 1024]; // 5k// 每个线程最多负责读取长度为shardSize,即一个分片大小int totalRead = 0; // 记录当前线程已读取的字节数int len = 0; // 当次循环中读取的字节数while (true) {len = rafsrc.read(bytes);// 读到末尾了,没数据了,就退出循环if (len == -1) {break;}raftarget.write(bytes, 0, len);totalRead += len; // 当前线程已读取并且写入的字节数// 每个线程只负责一分片大小if (totalRead >= shardSize) {break;}}latch.countDown();} catch (IOException e) {e.printStackTrace();}});threadList.add(t);}threadList.forEach(t->t.start());latch.await();}
}断点续传
FileUtils
以下代码的过程:大致与上面相同,但是添加了一个ConcurrentHashMap去记录 线程标识 => 当前线程完成写入的位置(位置是相对于文件起始位置开始计算的),当线程中的每次循环读取完成时,将当次循环读取的数量 加上 当前线程开始时的偏移量,这个偏移量在一切正常的情况下是:k * part,然后写入log日志。当某个时刻,程序终止,所有线程停止。这个文件就记录了,所有线程完成的情况,每个线程之前已经处理过的就不需要再处理了,而是接着从记录的位置开始读写即可,这样,每个线程不用从头开始,就实现了断点续传。
package com.qikux.utils;import java.io.*;
import java.nio.charset.StandardCharsets;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import java.util.StringJoiner;
import java.util.concurrent.ConcurrentHashMap;public class FileUtils {/*** 支持断点续传* @src 拷贝的原文件* @desc 拷贝的位置* @threadNum 开启的线程数*/public static void transportFile(File src, File desc, int threadNum) throws Exception {// 每一个线程读取的大小int part = (int)Math.ceil(src.length() / threadNum);// 存储多个线程、用于阻塞主线程List<Thread> list = new ArrayList<>();// 定义一个基于多线程 的 hashmapfinal Map<Integer, Integer> map = new ConcurrentHashMap<>();// 读取 日志文件中的数据String[] $data = null ;String logName = desc.getCanonicalPath() + ".log";File fl = new File(logName);if (fl.exists()) {BufferedReader reader = new BufferedReader(new FileReader(fl));String data = reader.readLine();// 拆分 字符串$data = data.split(",");reader.close();}final String[] _data = $data ;for (int i = 0; i < threadNum; i++) {final int k = i ;Thread thread = new Thread(() -> {// 线程具体要做的事情RandomAccessFile log = null ;try {RandomAccessFile in = new RandomAccessFile(src, "r");RandomAccessFile out = new RandomAccessFile(desc, "rw");log = new RandomAccessFile(logName, "rw");// 从指定位置读in.seek(_data ==null ?k * part : Integer.parseInt(_data[k]) );out.seek(_data ==null ?k * part : Integer.parseInt(_data[k]) );byte[] bytes = new byte[1024 * 2];int len = -1, plen = 0;while (true) {len = in.read(bytes);if (len == -1) {break;}// 如果不等于 -1 , 则 累加求和plen += len;// 将读取的字节数,放入 到 map 中map.put(k, plen + (_data ==null ?k * part : Integer.parseInt(_data[k])) );// 将读取到的数据、进行写入out.write(bytes, 0, len);// 将 map 中的数据进行写入文件中log.seek(0); // 直接覆盖全部文件StringJoiner joiner = new StringJoiner(",");map.forEach((key, val)-> joiner.add(String.valueOf(val)));log.write(joiner.toString().getBytes(StandardCharsets.UTF_8));if (plen + (_data ==null ? k * part : Integer.parseInt(_data[k])) >= (k+1) * part ) {break;}}} catch (Exception e) {e.printStackTrace();}finally {try {if (log !=null) log.close();} catch (IOException e) {e.printStackTrace();}}});thread.start();// 把这5个线程保存到集合中list.add(thread);}for(Thread t : list) {t.join(); // 将线程加入,并阻塞主线程}// 读取完成后、将日志文件删除即可new File(logName).delete();}/*** 支持断点续传* @src 拷贝的原文件* @desc 拷贝的位置*/public static void transportFile(File src, File desc) throws Exception {transportFile(src, desc, 5);}public static void transportFile(String src, String desc) throws Exception {transportFile(new File(src), new File(desc));}
}相关文章:

RandomAccessFile类 断点续传
文章目录学习链接RandomAccessFile构造方法实现的接口DataOutputDataInputAutoCloseable重要的方法多线程读写同一个文件(多线程复制文件)代码1代码2断点续传FileUtils学习链接 RandomAccessFile详解 Java IO——RandomAccessFile类详解 java多线程-断点…...

SpringCloud微服务技术栈的注册中心Eureka
文章目录SpringCloud微服务技术栈的注册中心Eureka简介Eureka特点操作步骤环境准备创建Eureka Server注册服务提供方调用服务消费方总结SpringCloud微服务技术栈的注册中心Eureka 简介 在微服务架构中,服务的数量庞大,而且每个服务可能会有多个实例。此…...

Unity最新热更新框架 hybridclr_addressable
GitHub:YMoonRiver/hybridclr_addressable: 开箱即用的商业游戏框架,集成了主流的开发工具。将主流的GameFramework修改,支持Addressable和AssetBundle,已完善打包工具和流程。 (github.com) # 新增GameFramework Addressables 开箱即用 # 新…...
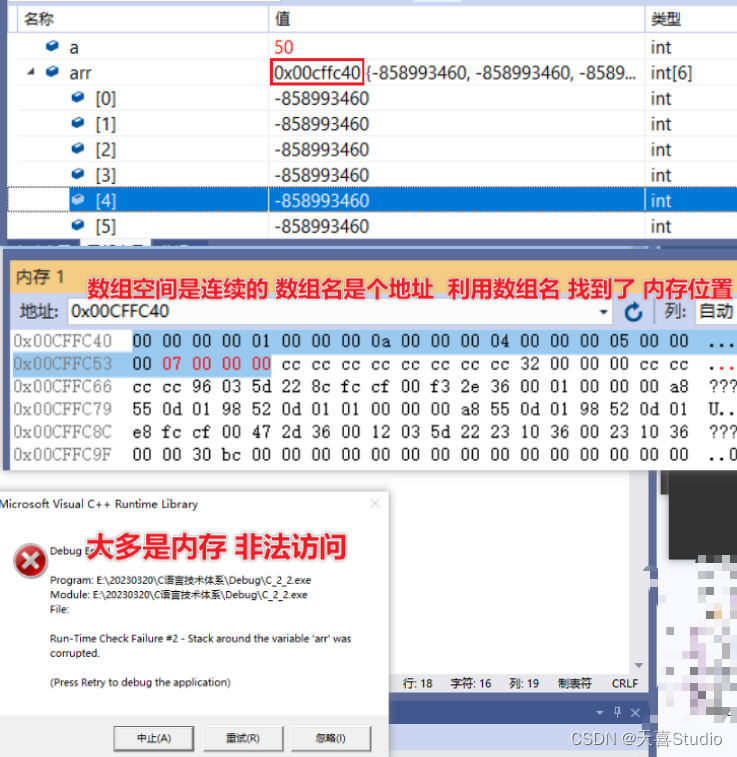
【c语言】一维数组***特性、存储原理
创作不易,本篇文章如果帮助到了你,还请点赞支持一下♡>𖥦<)!! 主页专栏有更多知识,如有疑问欢迎大家指正讨论,共同进步! 给大家跳段街舞感谢支持!ጿ ኈ ቼ ዽ ጿ ኈ ቼ ዽ ጿ ኈ ቼ ዽ ጿ…...
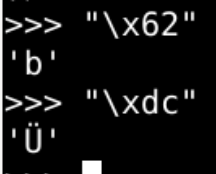
[oeasy]python0133_[趣味拓展]好玩的unicode字符_另类字符_上下颠倒英文字符
另类字符 回忆上次内容 上次再次输出了大红心♥ 找到了红心对应的编码黑红梅方都对应有编码 原来的编码叫做 ascii️ \u这种新的编码方式叫unicode包括了 中日韩字符集等 各书写系统的字符集 除了这些常规字符之外 还有什么好玩的东西呢? 颠倒字符 这个网站可以…...

找凶手,定名次,字符串旋转,杨氏矩阵
1.找凶手问题: //题目名称: //猜凶手 //题目内容: //日本某地发生了一件谋杀案,警察通过排查确定凶手必为4个嫌疑犯的一个。 //以下为4个嫌疑犯的供词: //A说:不是我 //B说:是C //C说ÿ…...

Python 进阶指南(编程轻松进阶):十四、实践项目
原文:http://inventwithpython.com/beyond/chapter14.html 到目前为止,这本书已经教会了你编写可读的 Python 风格代码的技巧。让我们通过查看两个命令行游戏的源代码来实践这些技术:汉诺塔和四人一排。 这些项目很短,并且基于文…...

Redis的五种数据类型及应用场景
Redis是一个开源的key-value数据库。 五种数据类型 String,List, Set,SortedSet,Hash List类型可以存储多个String。 Set类型可以存储不同的String。 SortedSet可以存储String的排序。 Hash可以存储多个key-value对。 String …...

c++List的详细介绍
cList详细使用 write in front 作者: 不进大厂不改名 专栏: c 作者简介:大一学生 希望能向其他大佬和同学学习! 本篇博客简介:本文主要讲述了一种新容器list的使用方法,相信你在学了后,能够加深…...
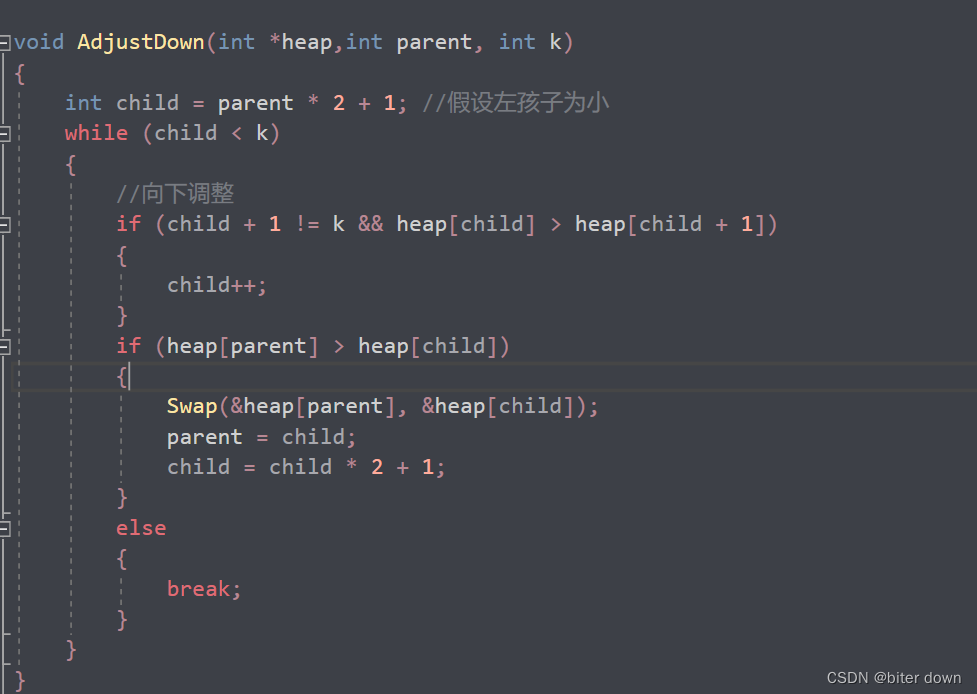
Heap堆的升序排序
在heap堆中,大根堆是一种特殊的堆,它满足下列性质:对于任意一个非叶子节点i,其左右子节点的值均小于等于它本身的值。 在大根堆中,堆顶元素永远是值最大的元素,所以将堆顶元素不断取出来,就相当…...
小程序开发收费价目表
小程序作为一种新兴应用形式,正在逐渐成为企业和个人推广、运营的重要手段。然而,小程序开发的价格因项目规模和复杂程度差异较大,令不少人望而却步。本文将从小程序开发的相关因素入手,探讨小程序开发的价格范围和算法。 一、小…...

Dubbo服务暴露步骤详解
文章目录Dubbo服务暴露步骤详解背景介绍理论知识讲解什么是服务暴露?Dubbo 服务暴露的基本原理操作步骤具体实现环境准备实现服务接口实现服务提供者配置 Dubbo 服务提供者启动服务提供者实现服务消费者配置 Dubbo 服务消费者测试总结Dubbo服务暴露步骤详解 背景介…...

第十四届蓝桥杯编程题部分代码题解
C. 冶炼金属 最大值就是取 a/ba / ba/b 的最小值,最小值就是二分找到满足 mid∗(bi1)≥aimid * (b_i 1) ≥ a_imid∗(bi1)≥ai 的最小值 #include<bits/stdc.h> #define int long long #define x first #define y second using namespace std;void sol…...
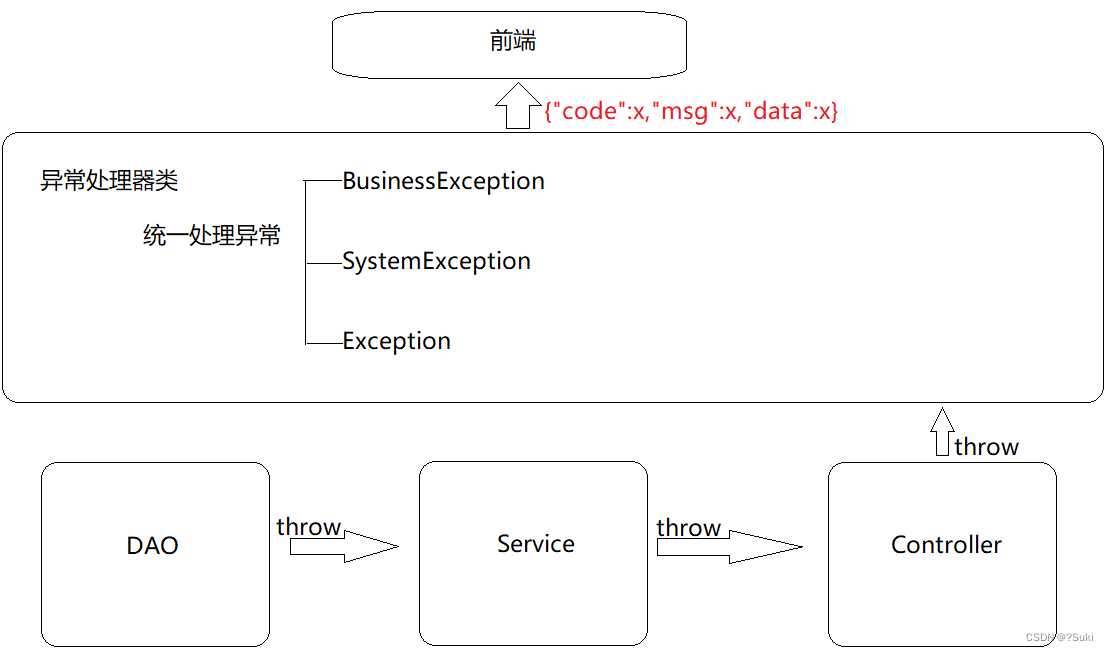
统一结果封装异常处理
统一结果封装&异常处理2,统一结果封装2.1 表现层与前端数据传输协议定义2.2 表现层与前端数据传输协议实现2.2.1 环境准备2.2.2 结果封装步骤1:创建Result类步骤2:定义返回码Code类步骤3:修改Controller类的返回值步骤4:启动服务测试3,统一异常处理3…...

数字藏品平台的发展趋势是什么?
1、数字藏品平台具体内容生产模式将在PGC(专业生产制造具体内容)方式向PUGC(技术专业用户生产内容)方式变化。 目前,中国热门的数字藏品平台都在PGC模式中持续发展的,而国外流行NFT平台则比较多选用UGC&am…...
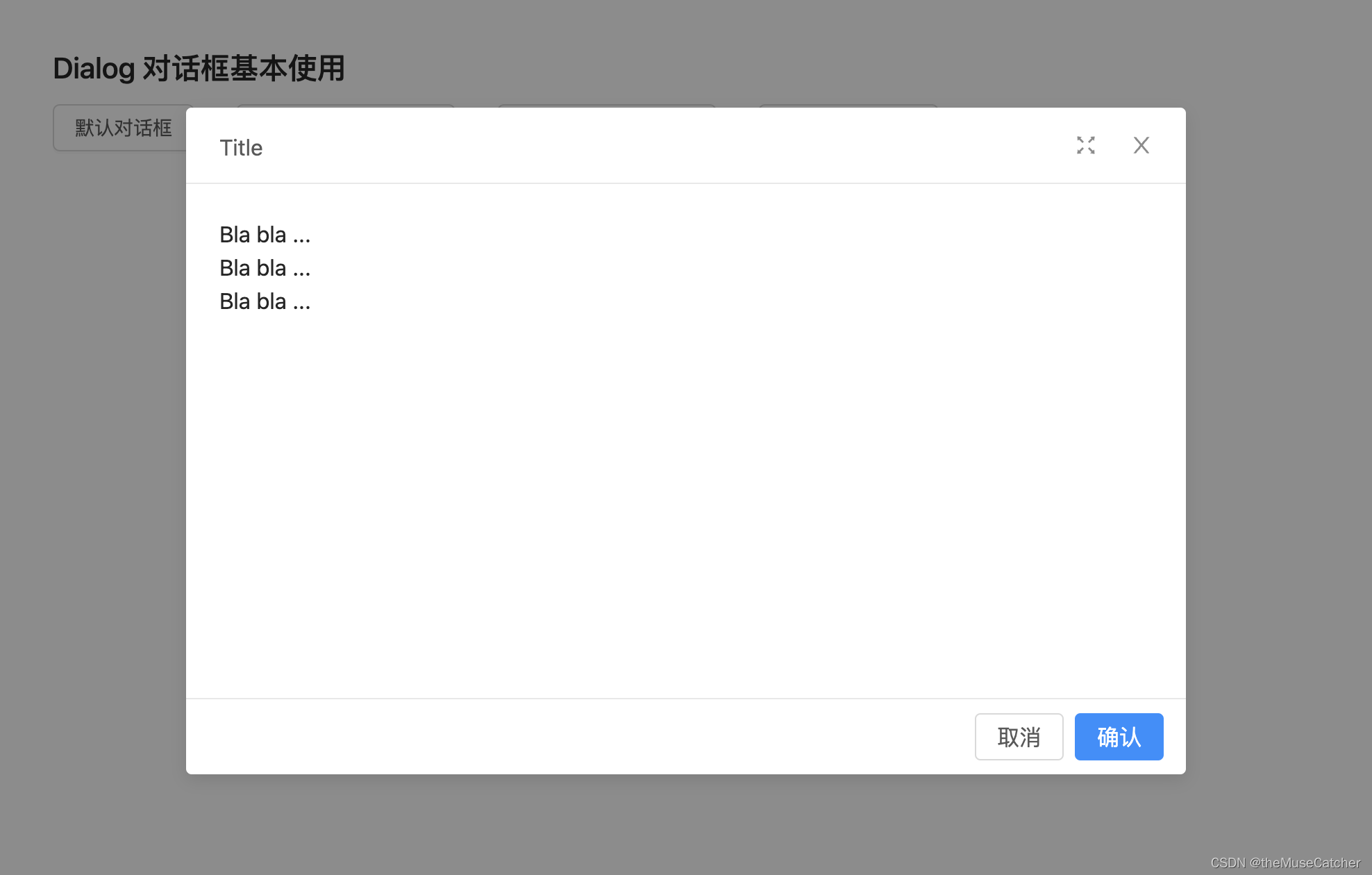
Vue3对话框(Dialog)
Vue2对话框(Dialog) 可自定义设置以下属性: 标题(title),类型:string | slot,默认 提示 内容(content),类型:string | slot…...

【深度强化学习】(5) DDPG 模型解析,附Pytorch完整代码
大家好,今天和各位分享一下深度确定性策略梯度算法 (Deterministic Policy Gradient,DDPG)。并基于 OpenAI 的 gym 环境完成一个小游戏。完整代码在我的 GitHub 中获得: https://github.com/LiSir-HIT/Reinforcement-Learning/tree/main/Mod…...

unity,Color.Lerp函数
介绍 Color.Lerp函数是Unity引擎中的一个静态函数,用于在两个颜色值之间进行线性插值,从而实现颜色渐变效果 方法 Color.Lerp函数是Unity引擎中的一个静态函数,用于在两个颜色值之间进行线性插值,从而实现颜色渐变效果。该函数的…...
洛谷P8799 [蓝桥杯 2022 国 B] 齿轮 C语言/C++
[蓝桥杯 2022 国 B] 齿轮 题目描述 这天,小明在组装齿轮。 他一共有 nnn 个齿轮,第 iii 个齿轮的半径为 rir_{i}ri, 他需要把这 nnn 个齿轮按一定顺序从左到右组装起来,这样最左边的齿轮转起来之后,可以传递到最右边的齿轮&a…...

景区在线售票系统功能开发介绍
目前游客线上订票已经普及,景区开通线上购票渠道,方便游客购票,对于还没有开通线上购票的景区来说,需要提前了解一下景区线上售票系统的一些功能,下面给大家详细介绍一下景区在线售票需要哪些功能。 1、在线售票 包含门…...

DeepSeek总结的CloudNativePG 与 Crunchy PGO:一个诚实且带有主观见解的比较
来源:https://www.gabrielebartolini.it/articles/2026/05/cloudnativepg-and-crunchy-pgo-an-honest-opinionated-comparison/ CloudNativePG 与 Crunchy PGO:一个诚实且带有主观见解的比较 作者: Gabriele Bartolini 日期: 2026年5月18日 目录 Crunchy…...
的3个隐藏技巧:从实时预览到多设备联调)
DevEco Studio预览器(Previewer)的3个隐藏技巧:从实时预览到多设备联调
DevEco Studio预览器的3个隐藏技巧:从实时预览到多设备联调 在鸿蒙应用开发中,DevEco Studio的Previewer功能早已超越了简单的UI查看工具。对于已经掌握基础操作的中级开发者而言,如何将这个看似简单的预览窗口转变为高效调试利器࿰…...

KMS_VL_ALL_AIO终极指南:5分钟免费激活Windows和Office的完整方案
KMS_VL_ALL_AIO终极指南:5分钟免费激活Windows和Office的完整方案 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows和Office的激活问题而烦恼吗?KMS_VL_ALL_…...

防火门禁用行为管控及消防实用管理细则
第一章 总则第一条 制定目的为严格规范防火门日常使用、巡查、维护、管控工作,杜绝违规封堵、常开、损坏、挪用等禁用行为,落实消防安全主体责任,保障疏散通道、安全出口畅通,防范火灾蔓延扩散,依据《建筑设计防火规范…...

减少重复劳作,气泡图软件助力质检效率升级
在制造业做过质量或工程的人,一定都有过这种体验:一张复杂图纸几百个尺寸,一个个手动画气泡、编号、抄 Excel,眼睛越看越花,手指越敲越累。更折磨的是,图纸一改,气泡编号几乎要全部重来…...

LM265 手持式频谱分析仪:交通超宽频监测旗舰
LM265 手持式频谱分析仪是成都鼎讯信通科技打造的超宽频高性能便携设备,覆盖 9kHz~26.5GHz,射频指标对标台式仪器,兼顾便携与精度,为铁路、高速等交通领域提供全频段信号监测与干扰排查能力。设备集成频谱分析、场强测量、信道扫描…...

微信读书笔记助手:3分钟快速上手的终极笔记管理指南
微信读书笔记助手:3分钟快速上手的终极笔记管理指南 【免费下载链接】wereader 一个浏览器扩展:主要用于微信读书做笔记,对常使用 Markdown 做笔记的读者比较有帮助。 项目地址: https://gitcode.com/gh_mirrors/wer/wereader 微信读书…...

ESXi 8.0U3i 新版本深度解析|官方原版核心优势 + 部署指南,稳定运维首选
随着企业虚拟化、私有云部署需求的不断升级,一款稳定、安全、可追溯的底层虚拟化系统,成为数据中心、机房运维与合规生产的核心诉求。VMware ESXi 8.0U3i(版本 8.0U3i-25205845)作为 8.0 系列 2026 年最新推出的稳定版本ÿ…...

Markdown Viewer:打造终极浏览器Markdown阅读体验的完整解决方案
Markdown Viewer:打造终极浏览器Markdown阅读体验的完整解决方案 【免费下载链接】markdown-viewer Markdown Viewer / Browser Extension 项目地址: https://gitcode.com/gh_mirrors/ma/markdown-viewer Markdown Viewer是一款功能强大的浏览器扩展…...

GitHub下载太慢?3分钟学会Fast-GitHub加速插件的终极解决方案
GitHub下载太慢?3分钟学会Fast-GitHub加速插件的终极解决方案 【免费下载链接】Fast-GitHub 国内Github下载很慢,用上了这个插件后,下载速度嗖嗖嗖的~! 项目地址: https://gitcode.com/gh_mirrors/fa/Fast-GitHub 作为一名…...