【Spring Cloud Alibaba】12.定时任务(xxl-job)
文章目录
- 简介
- 什么是xxl-job
- 调度中心
- 执行器
- 官方架构图
- 相关地址
- 环境要求
- 配置调度中心
- 下载源码
- 目录说明
- 初始化数据库
- 源码方式
- docker方式
- 测试
- 集群(可选)
- 配置执行器
- pom.xml
- application.properties
- XxlJobExecutorApplication.java
- 执行器组件配置
- 创建定时任务
- 任务管理简介
- 注册执行器
- BEAN模式
- GLUE模式(Java)
简介
接下来对分布式项目实现定时任务,本操作要先完成前置步骤,详情请参照【Spring Cloud Alibaba】Spring Cloud Alibaba 搭建教程
什么是xxl-job
xxl-job是一个分布式任务调度平台,其核心设计目标是开发迅速、学习简单、轻量级、易扩展。现已开放源代码并接入多家公司线上产品线,开箱即用。
xxl-job主要分为两个部分,第一部分为“调度中心“,第二部分为“执行器项目”,调度中心负责定时,执行器负责执行任务。
调度中心
负责管理调度信息,按照调度配置发出调度请求,自身不承担业务代码。调度系统与任务解耦,提高了系统可用性和稳定性,同时调度系统性能不再受限于任务模块;
支持可视化、简单且动态的管理调度信息,包括任务新建,更新,删除,GLUE开发和任务报警等,所有上述操作都会实时生效,同时支持监控调度结果以及执行日志,支持执行器Failover。
调度中心项目:xxl-job-admin
作用:统一管理任务调度平台上调度任务,负责触发调度执行,并且提供任务管理平台。
执行器
负责接收调度请求并执行任务逻辑。任务模块专注于任务的执行等操作,开发和维护更加简单和高效;
接收“调度中心”的执行请求、终止请求和日志请求等。
执行器项目:xxl-job-executor-sample-springboot (提供多种版本执行器供选择,现以 springboot 版本为例,可直接使用,也可以参考其并将现有项目改造成执行器)
作用:负责接收“调度中心”的调度并执行;可直接部署执行器,也可以将执行器集成到现有业务项目中。
官方架构图
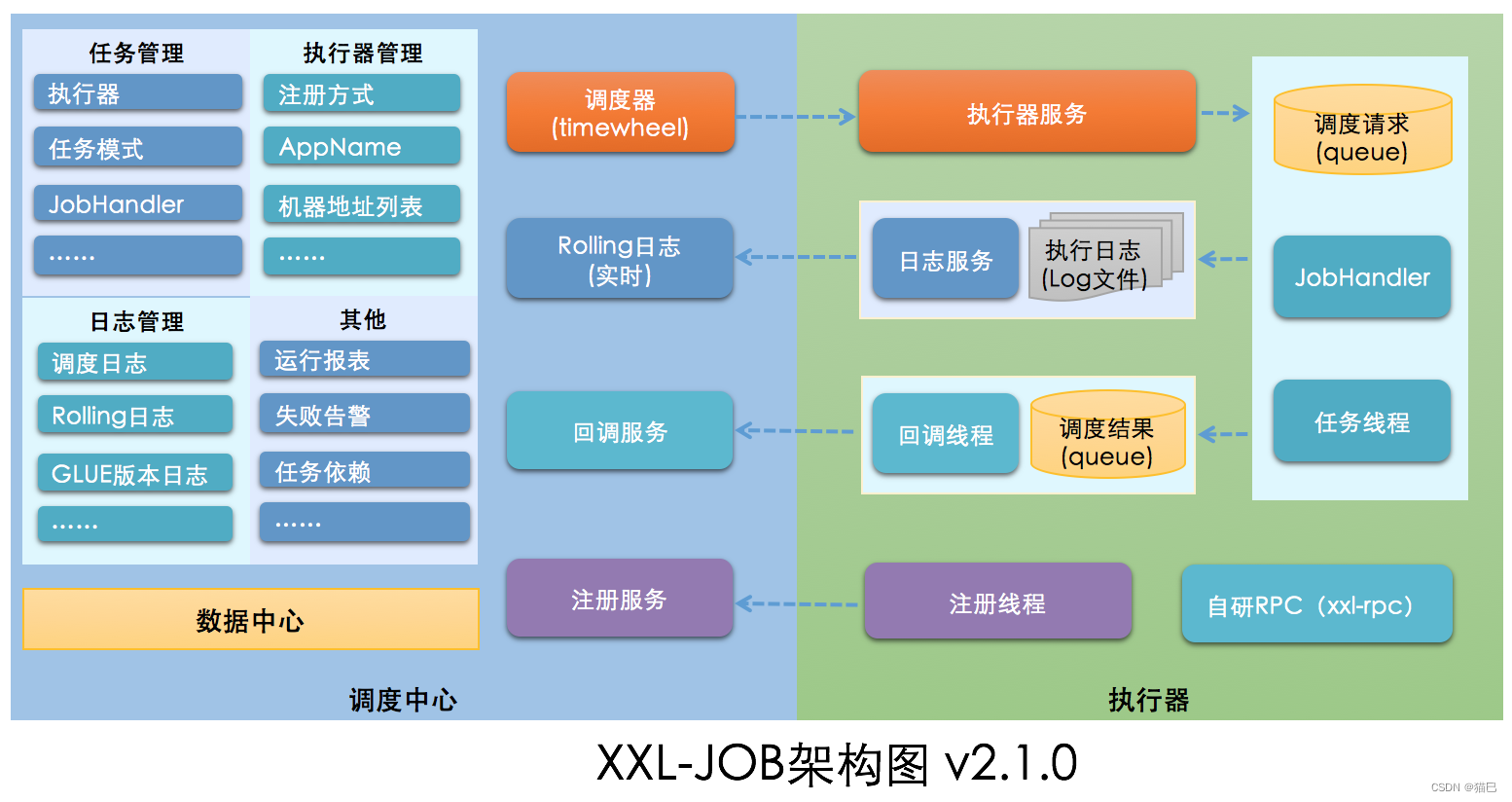
相关地址
官网地址:https://www.xuxueli.com/xxl-job/
源码地址:
- Github
- Gitee
官方教程:点我
官方教程很详细,想要深度学习的建议看,本文很多都是参照官网文档的,如果你只是想体验一下的话建议继续看下去,如果你打算在项目中正式开始使用,建议多看看官网教程。
环境要求
- Maven3+
- Jdk1.8+
- Mysql5.7+
注:演示版本为2.4.0
配置调度中心
下载源码
打开源码地址,建议国内用户访问Gitee,下载比较快。
git clone https://gitee.com/xuxueli0323/xxl-job.git
当前最新拉取的代码是v2.4.1,切换到最新的发布版v2.4.0分支
cd xxl-job
git checkout 2.4.0
大家可以根据自己的需要去选择版本,也可以直接访问发布页面去下载对应版本:
- Girhub Releases
- Gitee Releases
目录说明
解压源码,源码结构如下:
doc:db:tables_xxl_job.sql 初始化sql
xxl-job-admin:调度中心
xxl-job-core:公共依赖
xxl-job-executor-samples:执行器Sample示例(选择合适的版本执行器,可直接使用,也可以参考其并将现有项目改造成执行器):xxl-job-executor-sample-springboot:Springboot版本,通过Springboot管理执行器,推荐这种方式;:xxl-job-executor-sample-frameless:无框架版本;
初始化数据库
初始化sql文件在我们下载的源码以下目录:/xxl-job/doc/db/tables_xxl_job.sql
调度中心支持集群部署,集群情况下各节点务必连接同一个mysql实例;
如果mysql做主从,调度中心集群节点务必强制走主库;
v2.4.0版本sql如下:
#
# XXL-JOB v2.4.0
# Copyright (c) 2015-present, xuxueli.CREATE database if NOT EXISTS `xxl_job` default character set utf8mb4 collate utf8mb4_unicode_ci;
use `xxl_job`;SET NAMES utf8mb4;CREATE TABLE `xxl_job_info` (`id` int(11) NOT NULL AUTO_INCREMENT,`job_group` int(11) NOT NULL COMMENT '执行器主键ID',`job_desc` varchar(255) NOT NULL,`add_time` datetime DEFAULT NULL,`update_time` datetime DEFAULT NULL,`author` varchar(64) DEFAULT NULL COMMENT '作者',`alarm_email` varchar(255) DEFAULT NULL COMMENT '报警邮件',`schedule_type` varchar(50) NOT NULL DEFAULT 'NONE' COMMENT '调度类型',`schedule_conf` varchar(128) DEFAULT NULL COMMENT '调度配置,值含义取决于调度类型',`misfire_strategy` varchar(50) NOT NULL DEFAULT 'DO_NOTHING' COMMENT '调度过期策略',`executor_route_strategy` varchar(50) DEFAULT NULL COMMENT '执行器路由策略',`executor_handler` varchar(255) DEFAULT NULL COMMENT '执行器任务handler',`executor_param` varchar(512) DEFAULT NULL COMMENT '执行器任务参数',`executor_block_strategy` varchar(50) DEFAULT NULL COMMENT '阻塞处理策略',`executor_timeout` int(11) NOT NULL DEFAULT '0' COMMENT '任务执行超时时间,单位秒',`executor_fail_retry_count` int(11) NOT NULL DEFAULT '0' COMMENT '失败重试次数',`glue_type` varchar(50) NOT NULL COMMENT 'GLUE类型',`glue_source` mediumtext COMMENT 'GLUE源代码',`glue_remark` varchar(128) DEFAULT NULL COMMENT 'GLUE备注',`glue_updatetime` datetime DEFAULT NULL COMMENT 'GLUE更新时间',`child_jobid` varchar(255) DEFAULT NULL COMMENT '子任务ID,多个逗号分隔',`trigger_status` tinyint(4) NOT NULL DEFAULT '0' COMMENT '调度状态:0-停止,1-运行',`trigger_last_time` bigint(13) NOT NULL DEFAULT '0' COMMENT '上次调度时间',`trigger_next_time` bigint(13) NOT NULL DEFAULT '0' COMMENT '下次调度时间',PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;CREATE TABLE `xxl_job_log` (`id` bigint(20) NOT NULL AUTO_INCREMENT,`job_group` int(11) NOT NULL COMMENT '执行器主键ID',`job_id` int(11) NOT NULL COMMENT '任务,主键ID',`executor_address` varchar(255) DEFAULT NULL COMMENT '执行器地址,本次执行的地址',`executor_handler` varchar(255) DEFAULT NULL COMMENT '执行器任务handler',`executor_param` varchar(512) DEFAULT NULL COMMENT '执行器任务参数',`executor_sharding_param` varchar(20) DEFAULT NULL COMMENT '执行器任务分片参数,格式如 1/2',`executor_fail_retry_count` int(11) NOT NULL DEFAULT '0' COMMENT '失败重试次数',`trigger_time` datetime DEFAULT NULL COMMENT '调度-时间',`trigger_code` int(11) NOT NULL COMMENT '调度-结果',`trigger_msg` text COMMENT '调度-日志',`handle_time` datetime DEFAULT NULL COMMENT '执行-时间',`handle_code` int(11) NOT NULL COMMENT '执行-状态',`handle_msg` text COMMENT '执行-日志',`alarm_status` tinyint(4) NOT NULL DEFAULT '0' COMMENT '告警状态:0-默认、1-无需告警、2-告警成功、3-告警失败',PRIMARY KEY (`id`),KEY `I_trigger_time` (`trigger_time`),KEY `I_handle_code` (`handle_code`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;CREATE TABLE `xxl_job_log_report` (`id` int(11) NOT NULL AUTO_INCREMENT,`trigger_day` datetime DEFAULT NULL COMMENT '调度-时间',`running_count` int(11) NOT NULL DEFAULT '0' COMMENT '运行中-日志数量',`suc_count` int(11) NOT NULL DEFAULT '0' COMMENT '执行成功-日志数量',`fail_count` int(11) NOT NULL DEFAULT '0' COMMENT '执行失败-日志数量',`update_time` datetime DEFAULT NULL,PRIMARY KEY (`id`),UNIQUE KEY `i_trigger_day` (`trigger_day`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;CREATE TABLE `xxl_job_logglue` (`id` int(11) NOT NULL AUTO_INCREMENT,`job_id` int(11) NOT NULL COMMENT '任务,主键ID',`glue_type` varchar(50) DEFAULT NULL COMMENT 'GLUE类型',`glue_source` mediumtext COMMENT 'GLUE源代码',`glue_remark` varchar(128) NOT NULL COMMENT 'GLUE备注',`add_time` datetime DEFAULT NULL,`update_time` datetime DEFAULT NULL,PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;CREATE TABLE `xxl_job_registry` (`id` int(11) NOT NULL AUTO_INCREMENT,`registry_group` varchar(50) NOT NULL,`registry_key` varchar(255) NOT NULL,`registry_value` varchar(255) NOT NULL,`update_time` datetime DEFAULT NULL,PRIMARY KEY (`id`),KEY `i_g_k_v` (`registry_group`,`registry_key`,`registry_value`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;CREATE TABLE `xxl_job_group` (`id` int(11) NOT NULL AUTO_INCREMENT,`app_name` varchar(64) NOT NULL COMMENT '执行器AppName',`title` varchar(12) NOT NULL COMMENT '执行器名称',`address_type` tinyint(4) NOT NULL DEFAULT '0' COMMENT '执行器地址类型:0=自动注册、1=手动录入',`address_list` text COMMENT '执行器地址列表,多地址逗号分隔',`update_time` datetime DEFAULT NULL,PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;CREATE TABLE `xxl_job_user` (`id` int(11) NOT NULL AUTO_INCREMENT,`username` varchar(50) NOT NULL COMMENT '账号',`password` varchar(50) NOT NULL COMMENT '密码',`role` tinyint(4) NOT NULL COMMENT '角色:0-普通用户、1-管理员',`permission` varchar(255) DEFAULT NULL COMMENT '权限:执行器ID列表,多个逗号分割',PRIMARY KEY (`id`),UNIQUE KEY `i_username` (`username`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;CREATE TABLE `xxl_job_lock` (`lock_name` varchar(50) NOT NULL COMMENT '锁名称',PRIMARY KEY (`lock_name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;INSERT INTO `xxl_job_group`(`id`, `app_name`, `title`, `address_type`, `address_list`, `update_time`) VALUES (1, 'xxl-job-executor-sample', '示例执行器', 0, NULL, '2018-11-03 22:21:31' );
INSERT INTO `xxl_job_info`(`id`, `job_group`, `job_desc`, `add_time`, `update_time`, `author`, `alarm_email`, `schedule_type`, `schedule_conf`, `misfire_strategy`, `executor_route_strategy`, `executor_handler`, `executor_param`, `executor_block_strategy`, `executor_timeout`, `executor_fail_retry_count`, `glue_type`, `glue_source`, `glue_remark`, `glue_updatetime`, `child_jobid`) VALUES (1, 1, '测试任务1', '2018-11-03 22:21:31', '2018-11-03 22:21:31', 'XXL', '', 'CRON', '0 0 0 * * ? *', 'DO_NOTHING', 'FIRST', 'demoJobHandler', '', 'SERIAL_EXECUTION', 0, 0, 'BEAN', '', 'GLUE代码初始化', '2018-11-03 22:21:31', '');
INSERT INTO `xxl_job_user`(`id`, `username`, `password`, `role`, `permission`) VALUES (1, 'admin', 'e10adc3949ba59abbe56e057f20f883e', 1, NULL);
INSERT INTO `xxl_job_lock` ( `lock_name`) VALUES ( 'schedule_lock');
commit;
在我们的数据库运行sql,创建数据库
xxl_job_lock:任务调度锁表;xxl_job_group:执行器信息表,维护任务执行器信息;xxl_job_info:调度扩展信息表: 用于保存XXL-JOB调度任务的扩展信息,如任务分组、任务名、机器地址、执行器、执行入参和报警邮件等等;xxl_job_log:调度日志表: 用于保存XXL-JOB任务调度的历史信息,如调度结果、执行结果、调度入参、调度机器和执行器等等;xxl_job_log_report:调度日志报表:用户存储XXL-JOB任务调度日志的报表,调度中心报表功能页面会用到;xxl_job_logglue:任务GLUE日志:用于保存GLUE更新历史,用于支持GLUE的版本回溯功能;xxl_job_registry:执行器注册表,维护在线的执行器和调度中心机器地址信息;xxl_job_user:系统用户表;
源码方式
打包
mvn clean package
运行
java -jar .\xxl-job-admin\target\xxl-job-admin-2.4.0.jar --server.port=18010 --spring.datasource.url='jdbc:mysql://172.16.92.230:3306/xxl_job?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&serverTimez
one=Asia/Shanghai' --spring.datasource.username=root --spring.datasource.password=123456 --xxl.job.accessToken=moonce
配置文件以及默认值
application.properties
### 调度中心JDBC链接:链接地址请保持和所创建的调度数据库的地址一致
spring.datasource.url=jdbc:mysql://127.0.0.1:3306/xxl_job?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&serverTimezone=Asia/Shanghai
spring.datasource.username=root
spring.datasource.password=root_pwd
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
### 报警邮箱
spring.mail.host=smtp.qq.com
spring.mail.port=25
spring.mail.username=xxx@qq.com
spring.mail.password=xxx
spring.mail.properties.mail.smtp.auth=true
spring.mail.properties.mail.smtp.starttls.enable=true
spring.mail.properties.mail.smtp.starttls.required=true
spring.mail.properties.mail.smtp.socketFactory.class=javax.net.ssl.SSLSocketFactory
### 调度中心通讯TOKEN [选填]:非空时启用;
xxl.job.accessToken=moonce
### 调度中心国际化配置 [必填]: 默认为 "zh_CN"/中文简体, 可选范围为 "zh_CN"/中文简体, "zh_TC"/中文繁体 and "en"/英文;
xxl.job.i18n=zh_CN
## 调度线程池最大线程配置【必填】
xxl.job.triggerpool.fast.max=200
xxl.job.triggerpool.slow.max=100
### 调度中心日志表数据保存天数 [必填]:过期日志自动清理;限制大于等于7时生效,否则, 如-1,关闭自动清理功能;
xxl.job.logretentiondays=30
docker方式
// Docker地址:https://hub.docker.com/r/xuxueli/xxl-job-admin/ (建议指定版本号)
docker pull xuxueli/xxl-job-admin
如需自定义 mysql 等配置,可通过 “-e PARAMS” 指定,参数格式 PARAMS="--key=value --key2=value2" ,配置项参考application.properties文件;
如需自定义 JVM内存参数 等配置,可通过 “-e JAVA_OPTS” 指定,参数格式 JAVA_OPTS="-Xmx512m" ;
docker run -e PARAMS="--spring.datasource.url=jdbc:mysql://172.16.92.230:3306/xxl_job?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&serverTimezone=Asia/Shanghai --spring.datasource.username=root --spring.datasource.password=123456 --xxl.job.accessToken=moonce" -p 18010:8080 -v E:/tmp:/data/applogs --name xxl-job-admin -d xuxueli/xxl-job-admin:2.4.0

我这边已经拉取过镜像了,如果第一次的话会提示并自动拉取镜像
测试
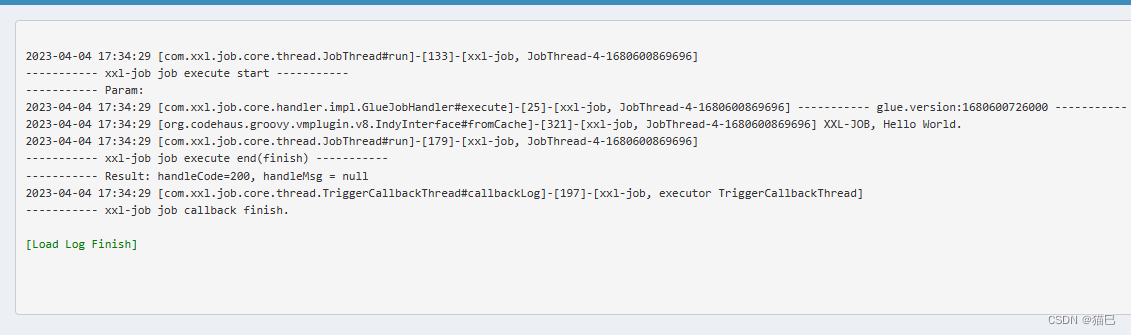
控制台输出启动成功

浏览器访问地址:http://localhost:18010/xxl-job-admin (该地址执行器将会使用到,作为回调地址),其中18010是我们启动时自定义 的端口号
默认账户密码:admin / 123456
集群(可选)
调度中心支持集群部署,提升调度系统容灾和可用性。
调度中心集群部署时,几点要求和建议:
DB配置保持一致;- 集群机器时钟保持一致(单机集群忽视);
建议:推荐通过nginx为调度中心集群做负载均衡,分配域名。调度中心访问、执行器回调配置、调用API服务等操作均通过该域名进行。
配置执行器
新建子模块,命名为moonce-xxl-job-executor
pom.xml
修改pom文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><parent><artifactId>spring-cloud-alibaba</artifactId><groupId>com.moonce</groupId><version>1.0-SNAPSHOT</version></parent><modelVersion>4.0.0</modelVersion><artifactId>moonce-xxl-job-executor</artifactId><properties><java.version>1.8</java.version></properties><dependencies><!-- Spring Boot Begin --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-actuator</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-commons</artifactId></dependency><!-- Spring Boot End --><!-- Spring Cloud Begin --><!-- Nacos 注册与发现 -->
<!-- <dependency>-->
<!-- <groupId>com.alibaba.cloud</groupId>-->
<!-- <artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>-->
<!-- </dependency>--><!-- Nacos 分布式配置中心 -->
<!-- <dependency>-->
<!-- <groupId>com.alibaba.cloud</groupId>-->
<!-- <artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>-->
<!-- </dependency>--><!-- Spring Cloud End--><!-- xxl-job-core 定时任务公共依赖--><dependency><groupId>com.xuxueli</groupId><artifactId>xxl-job-core</artifactId><version>2.4.0</version></dependency></dependencies><build><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId><configuration><mainClass>com.moonce.xxl.job.executor.XxlJobExecutorApplication</mainClass></configuration></plugin></plugins></build></project>
application.properties
# web port
server.port=9080
### 调度中心部署根地址 [选填]:如调度中心集群部署存在多个地址则用逗号分隔。执行器将会使用该地址进行"执行器心跳注册"和"任务结果回调";为空则关闭自动注册;
xxl.job.admin.addresses=http://127.0.0.1:18010/xxl-job-admin
### 执行器通讯TOKEN [选填]:非空时启用;
xxl.job.accessToken=moonce
### 执行器AppName [选填]:执行器心跳注册分组依据;为空则关闭自动注册
xxl.job.executor.appname=moonce-xxl-job-executor
### 执行器注册 [选填]:优先使用该配置作为注册地址,为空时使用内嵌服务 ”IP:PORT“ 作为注册地址。从而更灵活的支持容器类型执行器动态IP和动态映射端口问题。
xxl.job.executor.address=
### 执行器IP [选填]:默认为空表示自动获取IP,多网卡时可手动设置指定IP,该IP不会绑定Host仅作为通讯实用;地址信息用于 "执行器注册" 和 "调度中心请求并触发任务";
xxl.job.executor.ip=
### 执行器端口号 [选填]:小于等于0则自动获取;默认端口为9999,单机部署多个执行器时,注意要配置不同执行器端口;
xxl.job.executor.port=9999
### 执行器运行日志文件存储磁盘路径 [选填] :需要对该路径拥有读写权限;为空则使用默认路径;
xxl.job.executor.logpath=/data/applogs/xxl-job/jobhandler
### 执行器日志文件保存天数 [选填] : 过期日志自动清理, 限制值大于等于3时生效; 否则, 如-1, 关闭自动清理功能;
xxl.job.executor.logretentiondays=30
XxlJobExecutorApplication.java
新建软件包com.moonce.xxl.job.executor和XxlJobExecutorApplication.java启动类
package com.moonce.xxl.job.executor;import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
//import org.springframework.cloud.client.discovery.EnableDiscoveryClient;@SpringBootApplication
//@EnableDiscoveryClient
public class XxlJobExecutorApplication {public static void main(String[] args) {SpringApplication.run(XxlJobExecutorApplication.class, args);}}
执行器组件配置
新建软件包com.moonce.xxl.job.executor.config和组件配置文件XxlJobConfig.java,代码如下
XxlJobConfig.java
package com.moonce.xxl.job.executor.config;import com.xxl.job.core.executor.impl.XxlJobSpringExecutor;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;@Configuration
public class XxlJobConfig {private Logger logger = LoggerFactory.getLogger(XxlJobConfig.class);@Value("${xxl.job.admin.addresses}")private String adminAddresses;@Value("${xxl.job.accessToken}")private String accessToken;@Value("${xxl.job.executor.appname}")private String appname;@Value("${xxl.job.executor.address}")private String address;@Value("${xxl.job.executor.ip}")private String ip;@Value("${xxl.job.executor.port}")private int port;@Value("${xxl.job.executor.logpath}")private String logPath;@Value("${xxl.job.executor.logretentiondays}")private int logRetentionDays;@Beanpublic XxlJobSpringExecutor xxlJobExecutor() {logger.info(">>>>>>>>>>> xxl-job config init.");XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor();xxlJobSpringExecutor.setAdminAddresses(adminAddresses);xxlJobSpringExecutor.setAppname(appname);xxlJobSpringExecutor.setAddress(address);xxlJobSpringExecutor.setIp(ip);xxlJobSpringExecutor.setPort(port);xxlJobSpringExecutor.setAccessToken(accessToken);xxlJobSpringExecutor.setLogPath(logPath);xxlJobSpringExecutor.setLogRetentionDays(logRetentionDays);return xxlJobSpringExecutor;}}
创建定时任务
任务管理简介
定时任务分为两种运行模式,BEAN模式和GLUE模式,其中GLUE模式又分别分为Java、Shell、Python、PHP、NodeJS和PowerShell模式,我们主要介绍下BEAN模式和GLUE模式(Java),其他模式大家可以去看看官网文档调度中心配置中的配置属性详细说明;
BEAN模式:任务以JobHandler方式维护在执行器端;需要结合 “JobHandler” 属性匹配执行器中任务;GLUE模式(Java):任务以源码方式维护在调度中心;该模式的任务实际上是一段继承自IJobHandler的Java类代码并 “groovy” 源码方式维护,它在执行器项目中运行,可使用@Resource/@Autowire注入执行器里中的其他服务;
通俗点讲,BEAN模式就是在执行器写好定时任务方法,然后在调度中心配置方法的BEAN名称,而GLUE模式就是直接在调度中心写代码,然后在执行器中运行。
注册执行器
首先打开我们的调度中心:http://localhost:18010/xxl-job-admin,打开菜单执行器管理:
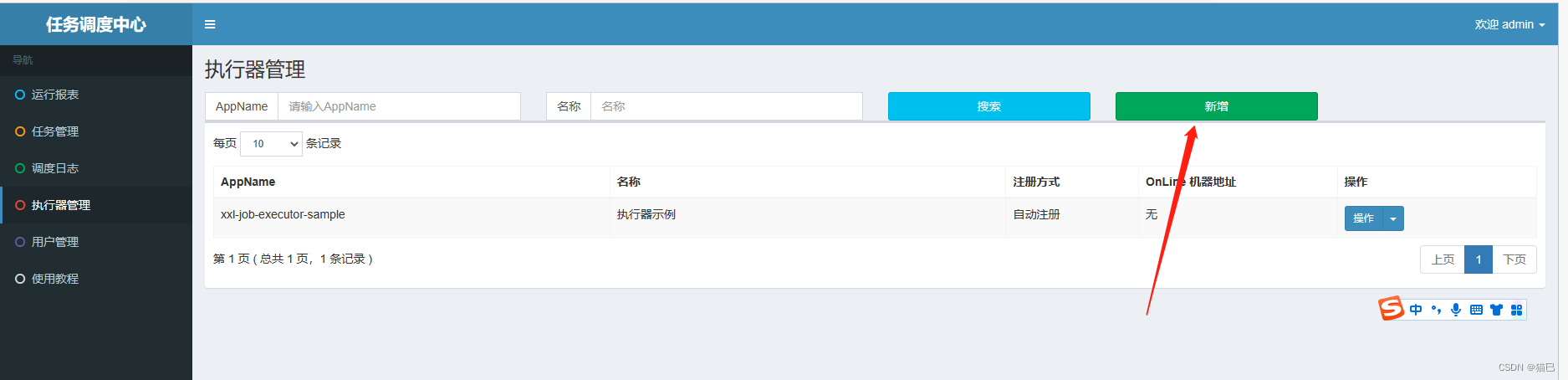
点击新增,填写执行器信息,如图所示:
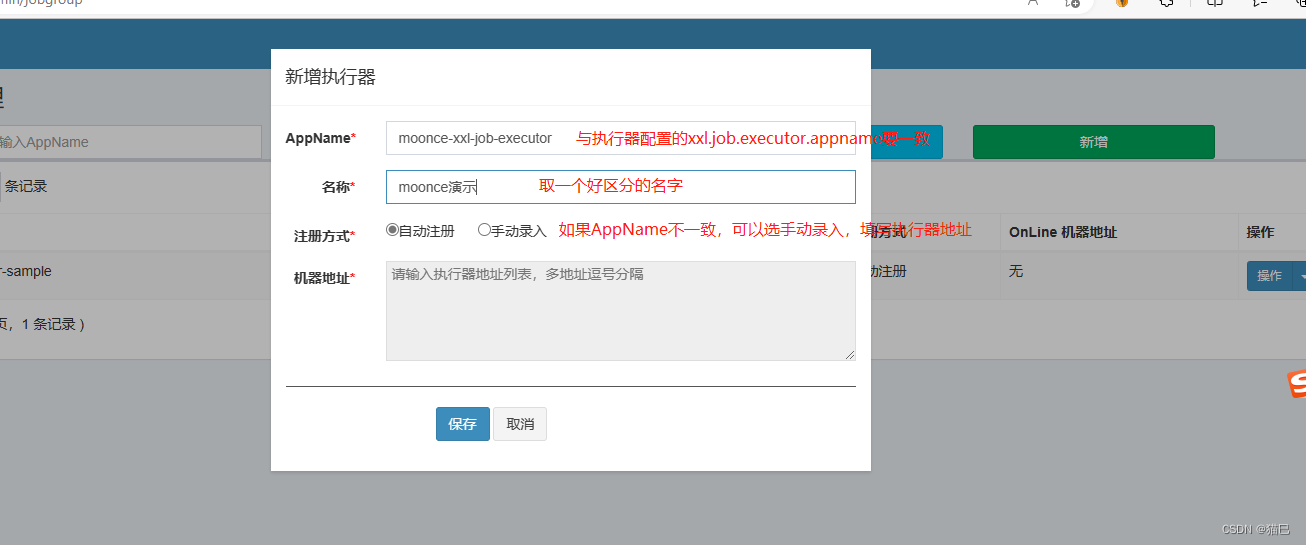
保存完成
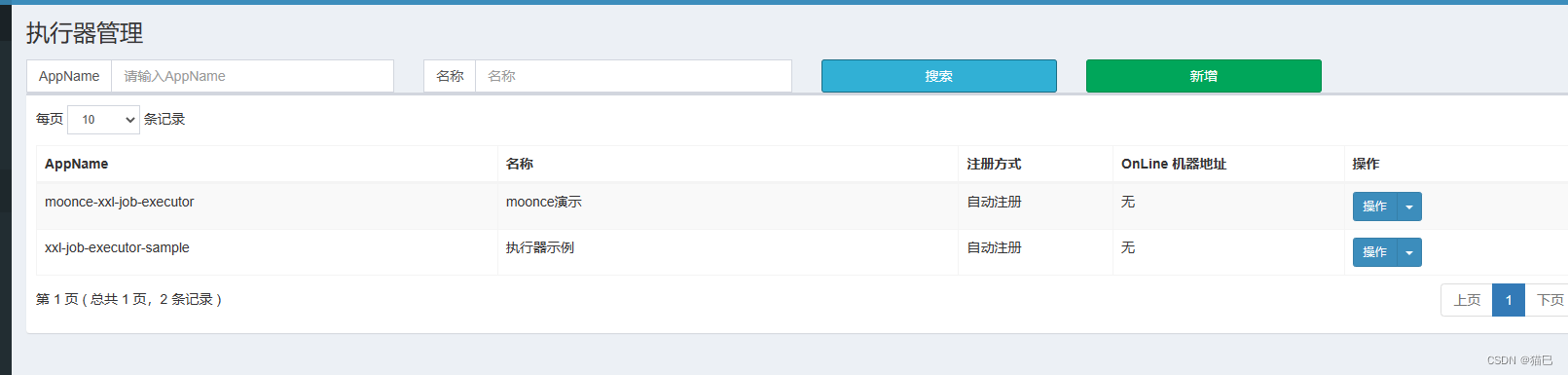
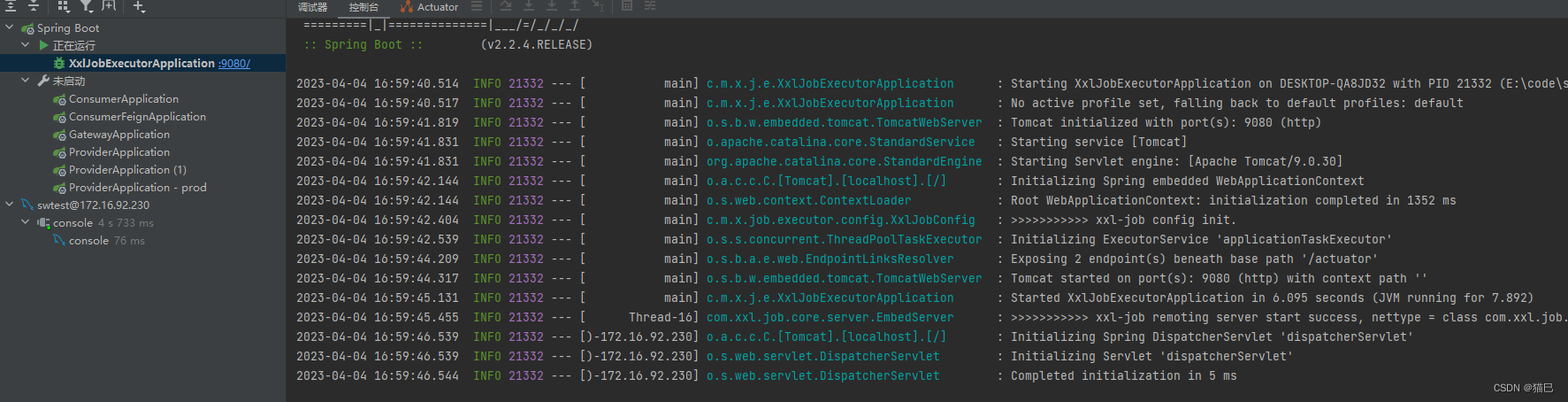
启动我们得执行器项目moonce-xxl-job-executor
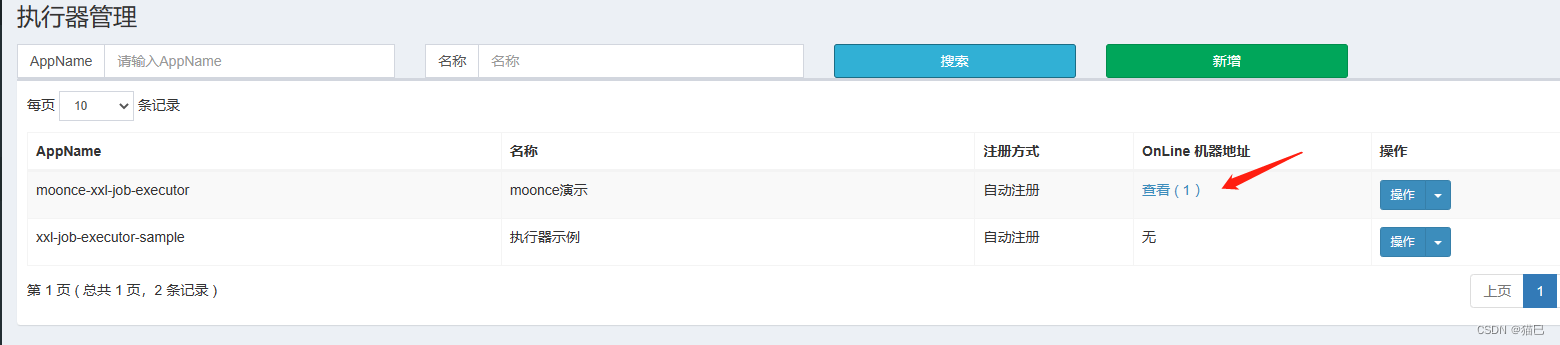
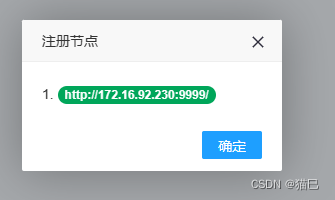
我们再到执行器管理中查看,执行器项目moonce-xxl-job-executor已成功注册!
BEAN模式
Bean模式任务,支持基于方法的开发方式,每个任务对应一个方法。
优点:
- 每个任务只需要开发一个方法,并添加”@XxlJob”注解即可,更加方便、快速。
- 支持自动扫描任务并注入到执行器容器。
缺点:
- 要求Spring容器环境;
在执行器项目moonce-xxl-job-executor中新建软件包com.moonce.xxl.job.executor.service.jobhandler和执行器类TestXxlJob.java,内容如下:
基于方法开发的任务,底层会生成JobHandler代理,和基于类的方式一样,任务也会以JobHandler的形式存在于执行器任务容器中。
TestXxlJob.java
package com.moonce.xxl.job.executor.service.jobhandler;import com.xxl.job.core.context.XxlJobHelper;
import com.xxl.job.core.handler.annotation.XxlJob;
import org.springframework.stereotype.Component;import java.util.concurrent.TimeUnit;@Component
public class TestXxlJob {/*** 1、任务开发:在Spring Bean实例中,开发Job方法;* 2、注解配置:为Job方法添加注解 "@XxlJob(value="自定义jobhandler名称", init = "JobHandler初始化方法", destroy = "JobHandler销毁方法")",注解value值对应的是调度中心新建任务的JobHandler属性的值。* 3、执行日志:需要通过 "XxlJobHelper.log" 打印执行日志;* 4、任务结果:默认任务结果为 "成功" 状态,不需要主动设置;如有诉求,比如设置任务结果为失败,可以通过 "XxlJobHelper.handleFail/handleSuccess" 自主设置任务结果;* * @throws Exception*/@XxlJob("testJobHandler")public void demoJobHandler() throws Exception {XxlJobHelper.log("XXL-JOB, Hello World.");for (int i = 0; i < 5; i++) {XxlJobHelper.log("beat at:" + i);TimeUnit.SECONDS.sleep(2);}// default success}
}
重新启动执行器项目moonce-xxl-job-executor,访问调度中心,找到任务管理:
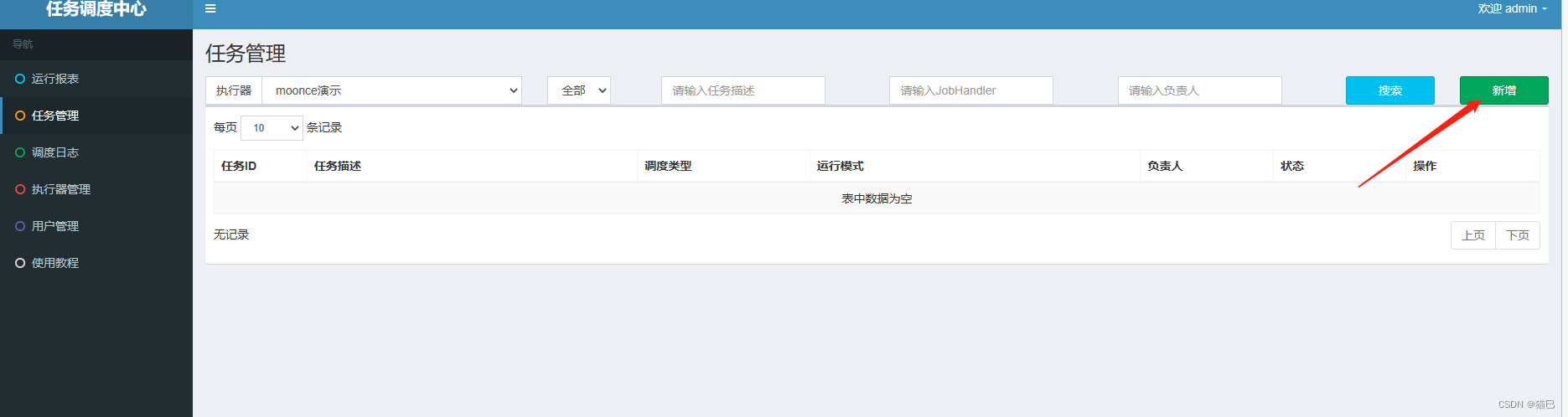
选择新增,内容如下:
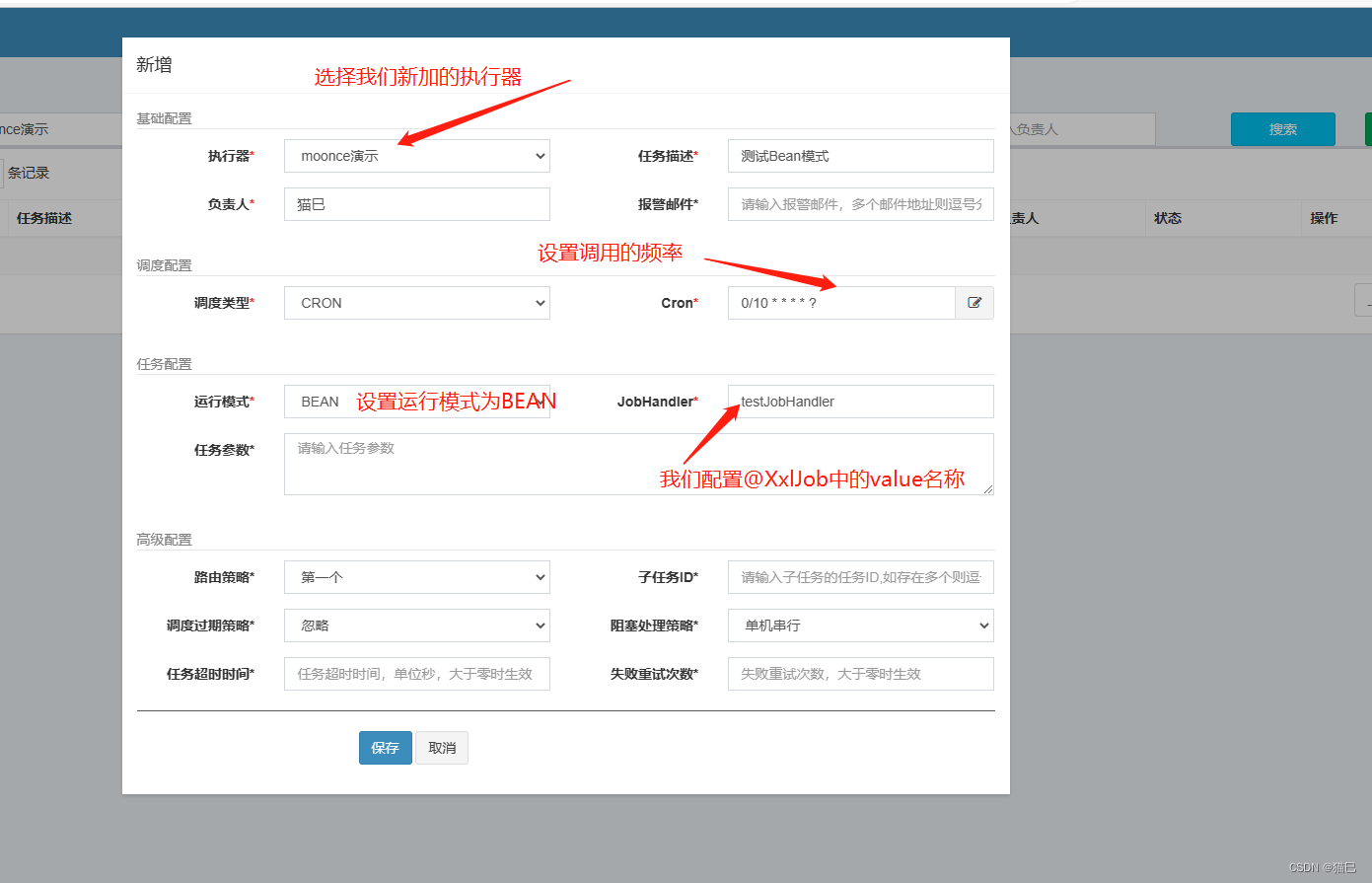
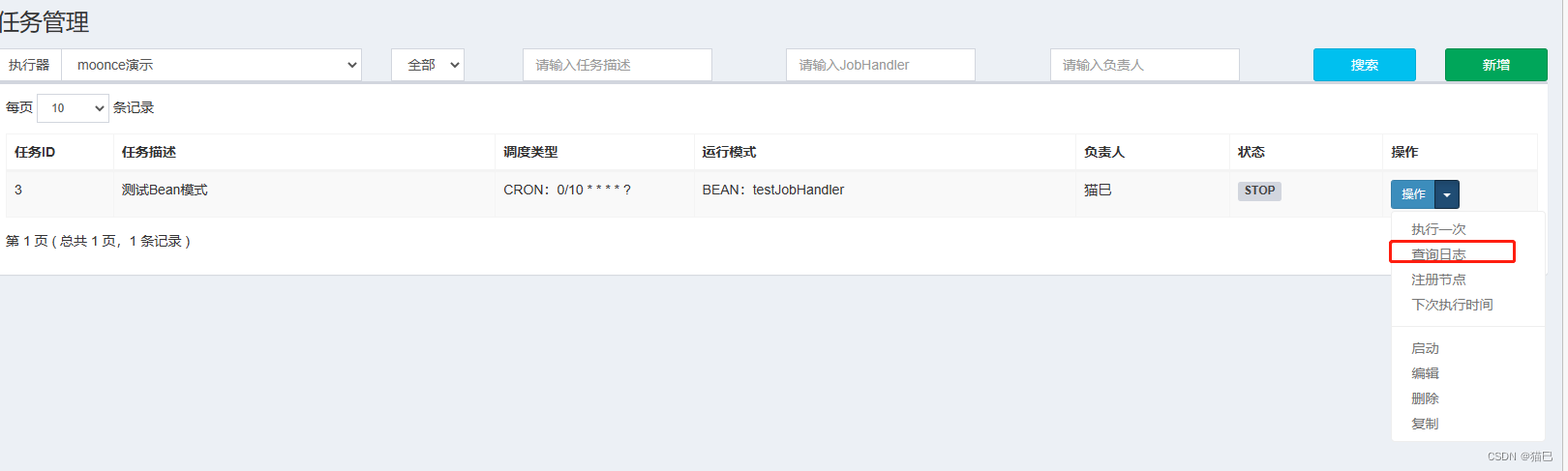
点击保存,默认是停止状态的,我们可以先测试一次
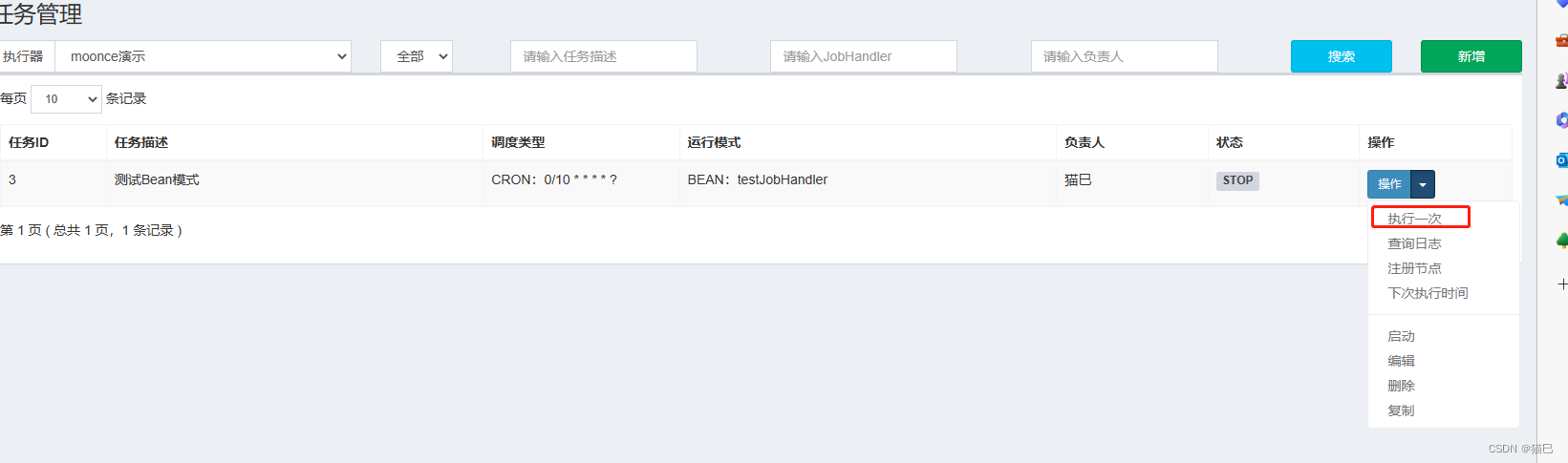
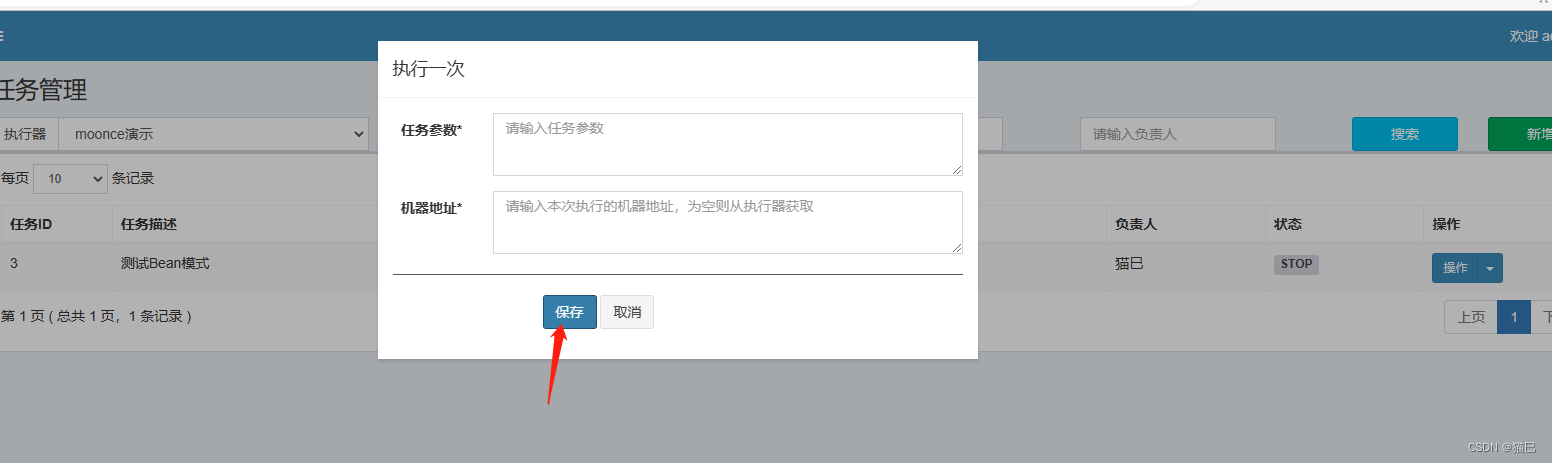
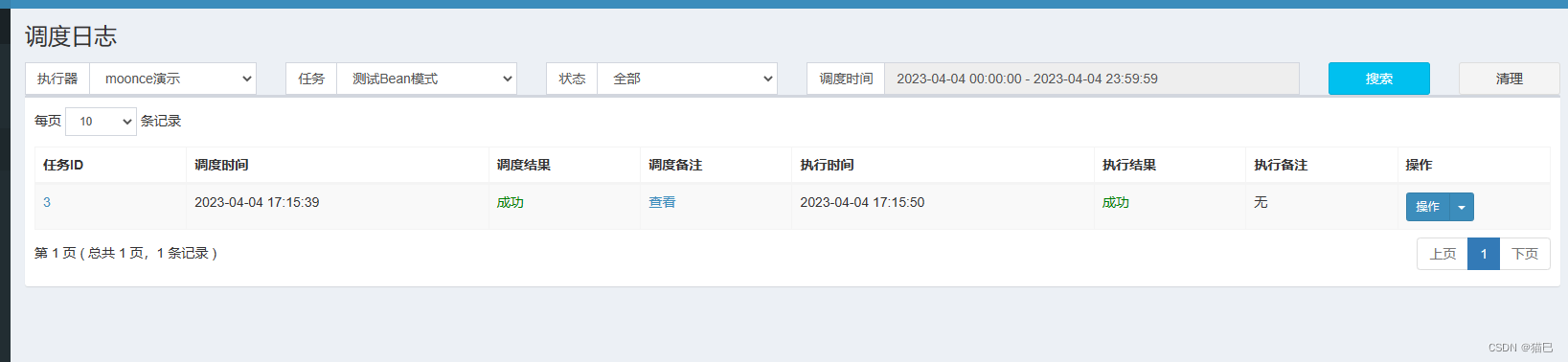
查看执行日志
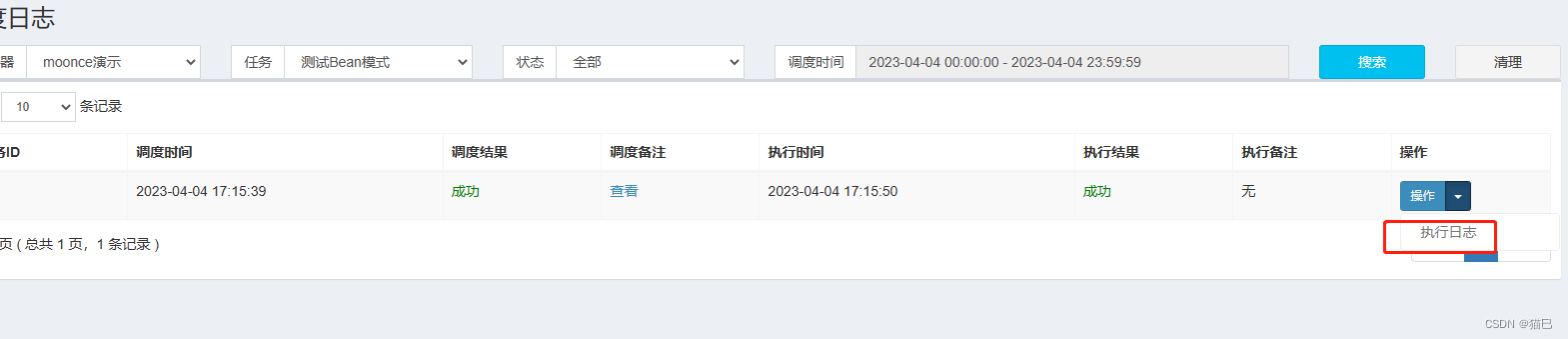
成功执行
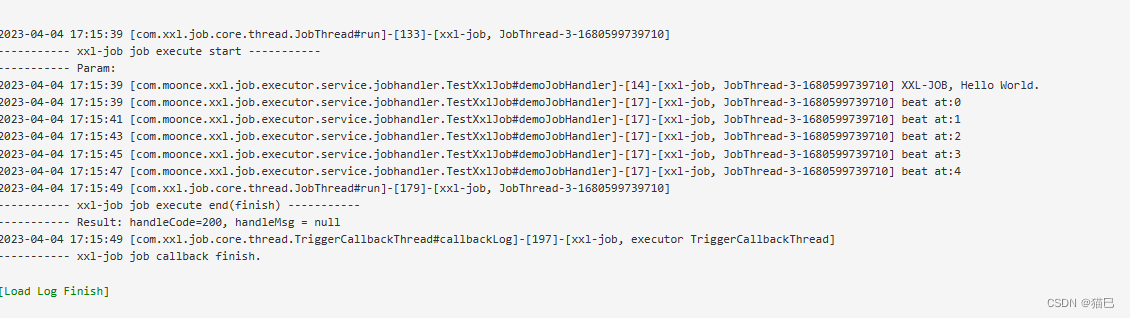
我们再来看看是不是输出了我们预期的结果
输出与我们预期一致
更多详细用法大家可以看源码中的xxl-job-executor-sample-springboot项目,参考类com.xxl.job.executor.service.jobhandler.SampleXxlJob
,主要如下:
demoJobHandler:简单示例任务,任务内部模拟耗时任务逻辑,用户可在线体验Rolling Log等功能;shardingJobHandler:分片示例任务,任务内部模拟处理分片参数,可参考熟悉分片任务;httpJobHandler:通用HTTP任务Handler;业务方只需要提供HTTP链接等信息即可,不限制语言、平台。示例任务入参如下:url: http://www.xxx.com method: get 或 post data: post-datacommandJobHandler:通用命令行任务Handler;业务方只需要提供命令行即可;如 “pwd”命令;
GLUE模式(Java)
任务以源码方式维护在调度中心,支持通过Web IDE在线更新,实时编译和生效,因此不需要指定JobHandler。
访问调度中心,找到任务管理,新建任务,内容如下:
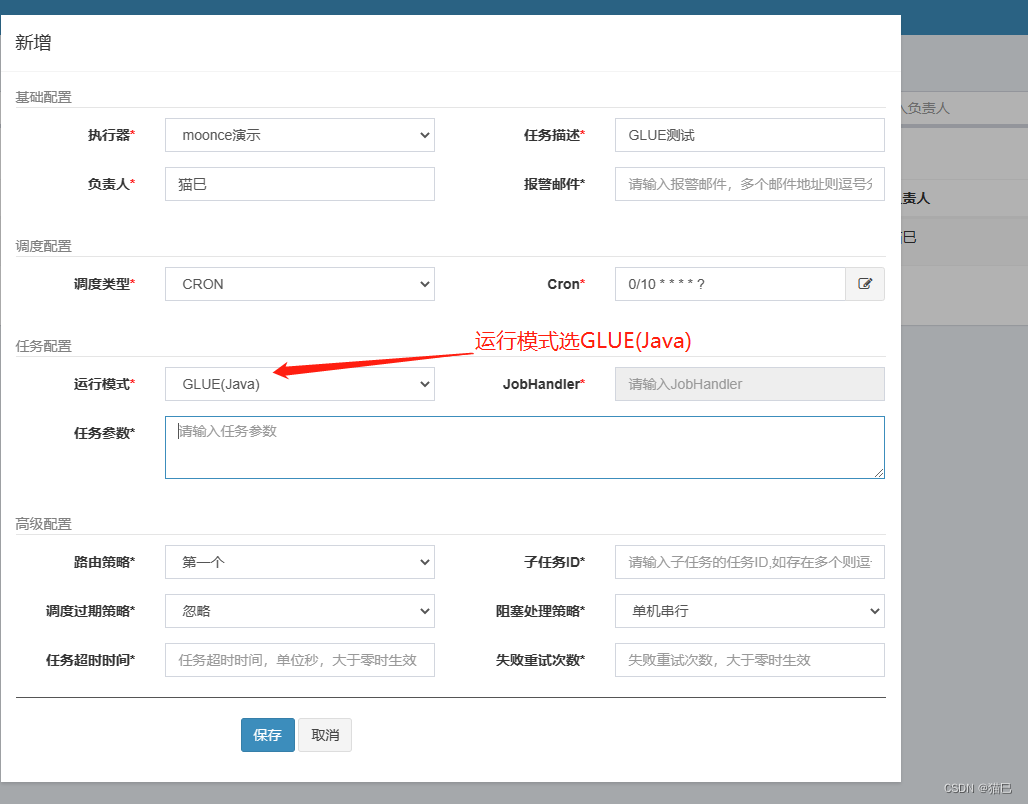
保存后,选择GLUE IDE,进行代码在线编辑
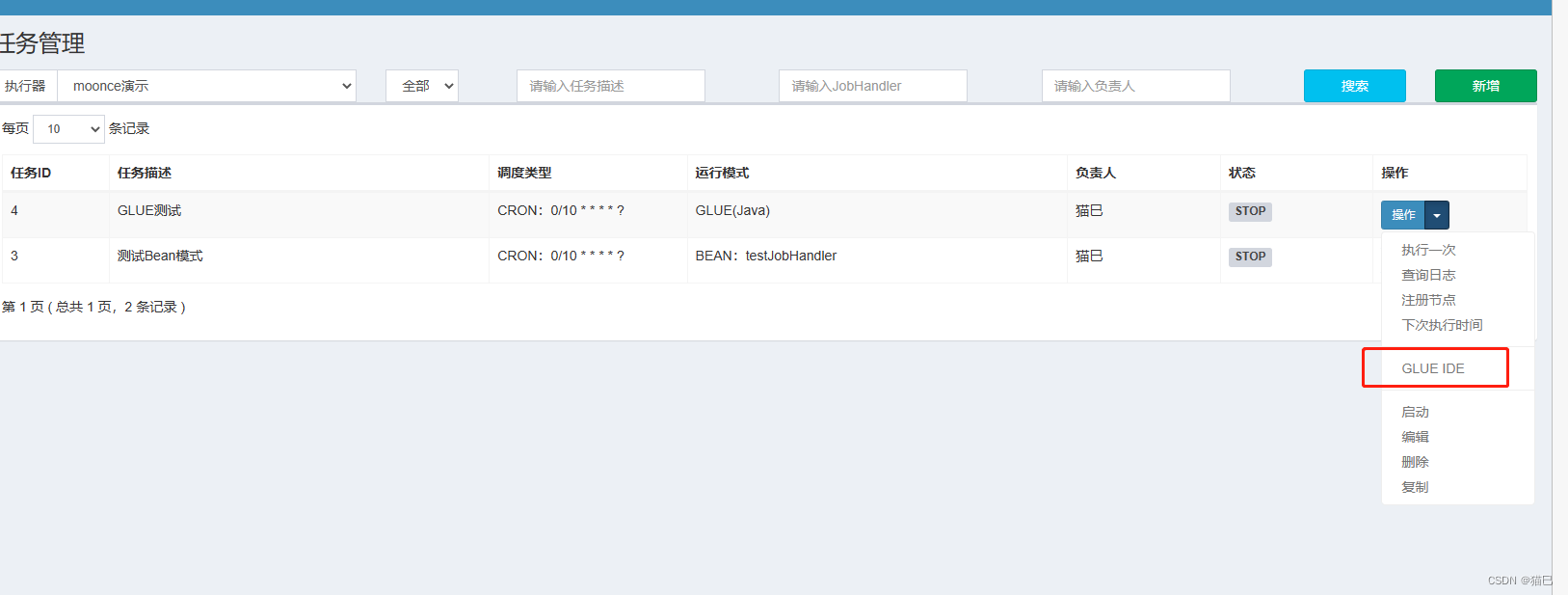
选中指定任务,点击该任务右侧“GLUE”按钮,将会前往GLUE任务的Web IDE界面,在该界面支持对任务代码进行开发(也可以在IDE中开发完成后,复制粘贴到编辑中)。
版本回溯功能(支持30个版本的版本回溯):在GLUE任务的Web IDE界面,选择右上角下拉框“版本回溯”,会列出该GLUE的更新历史,选择相应版本即可显示该版本代码,保存后GLUE代码即回退到对应的历史版本;
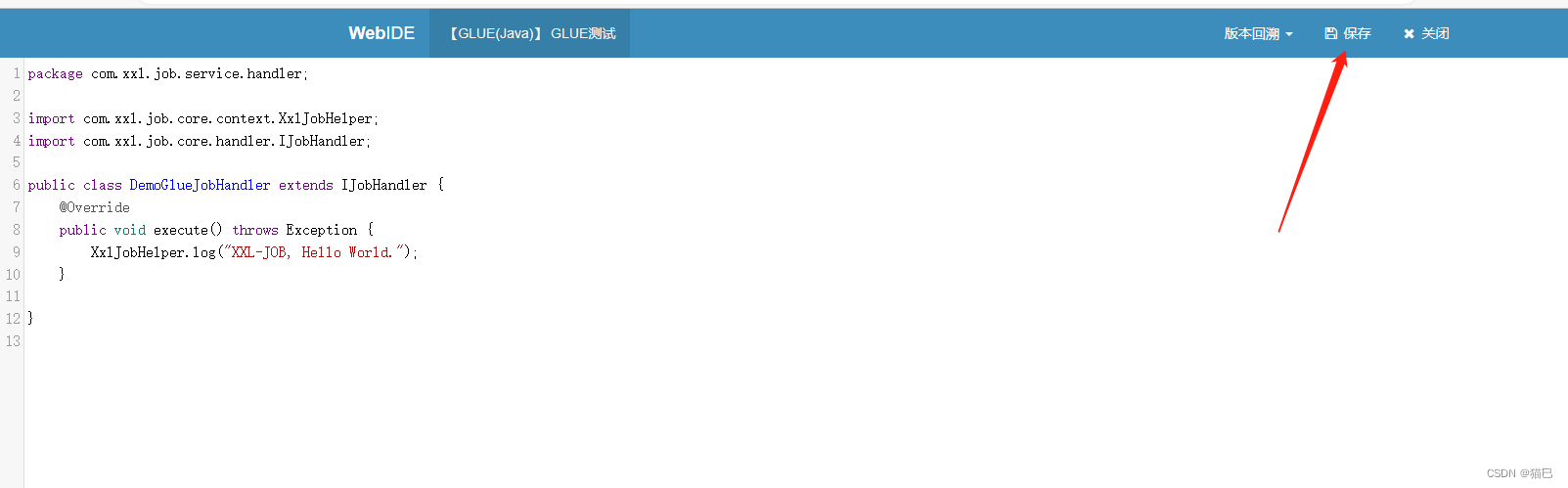
完成编辑保存,返回列表选择执行一次
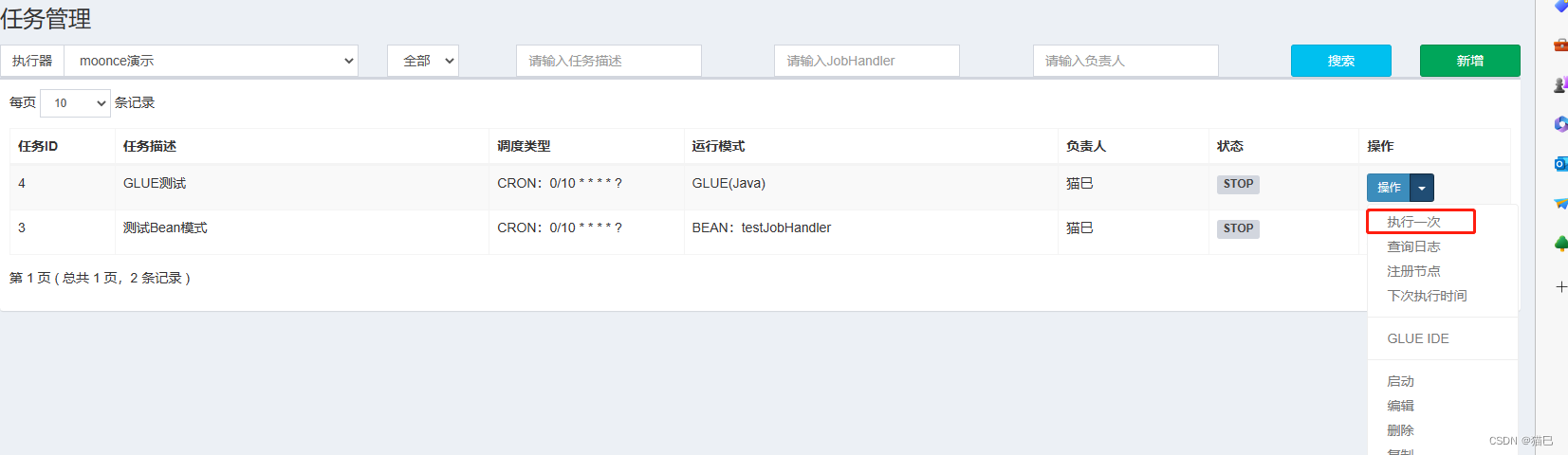
查看执行日志
相关文章:
【Spring Cloud Alibaba】12.定时任务(xxl-job)
文章目录简介什么是xxl-job调度中心执行器官方架构图相关地址环境要求配置调度中心下载源码目录说明初始化数据库源码方式docker方式测试集群(可选)配置执行器pom.xmlapplication.propertiesXxlJobExecutorApplication.java执行器组件配置创建定时任务任…...
GDB core dump分析
基本知识 Linux core dump:一般称之为核心转储、内核转储,我们统称为转储文件。是某个时刻某个进程的内存信息映射,即包含了生成转储文件时该进程的整个内存信息以及寄存器等信息。转储文件可以是某个进程的,也可以是整个系统的。…...

Leetcode.111 二叉树的最小深度
题目链接 Leetcode.111 二叉树的最小深度 easy 题目描述 给定一个二叉树,找出其最小深度。 最小深度是从 根节点 到 最近叶子节点 的 最短路径上的节点数量。 说明: 叶子节点是指没有子节点的节点。 示例 1: 输入:root [3,9,20,null,nul…...

【RP-RV1126】SDK编译常用记录
文章目录一、单独编译1.1 单独配置编译kernel1.2 单独编译配置Buildroot1.3 单独编译rkmedia1.3.1 添加自己的rkmedia代码文件荣品的RV1126。一、单独编译 如果执行 build.sh 运行完成后没有在 rockdev/ 目录下生成镜像文件,请执行: ./build.sh firmwa…...
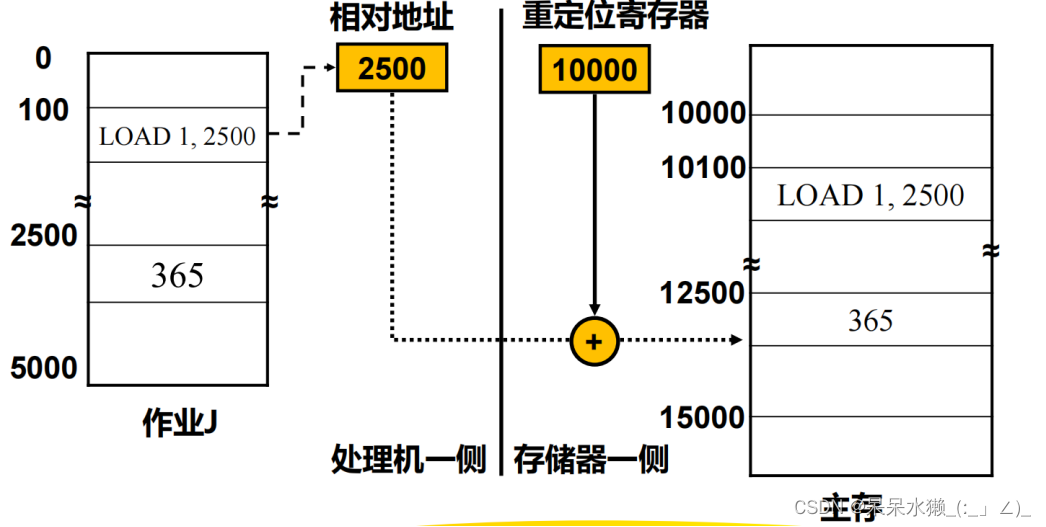
【操作系统复习】第5章 存储器管理
存储器的层次结构 存储层次 ➢ CPU寄存器 ➢ 主存:高速缓存、主存储器、磁盘缓存 ➢ 辅存:固定磁盘、可移动介质 层次越高,访问速度越快,价格也越高,存储容量也最小 寄存器和主存掉电后存储的信息不再存在&a…...
Python人工智能在气象中的实践技术应用
专题一 Python 和科学计算基础 1.1 Python 入门和安装 1.1.1 Python 背景及其在气象中的应用 1.1.2 Anaconda 解释和安装以及 Jupyter 配置1.1.3 Python 基础语法 1.2 科学数据处理基础库 1.2.1 Numpy 库1.2.2 Pandas 库1.2.3 Scipy 库 1.2.4 Matplotlib 和 Cartopy 库 …...
libcurl库的安装及使用说明
目录 一 libcurl库安装 ① 下载网址 ② libcurl库安装步骤 ③ libcurl等第三方库的通用编译方法 二 调用libcurl编程访问百度主页 ① 代码说明 ② 编译说明 ③ 执行说明 三 libcurl的使用说明 ① curl相关函数简介 ② curl_easy_setopt函数部分选项介绍 ③…...
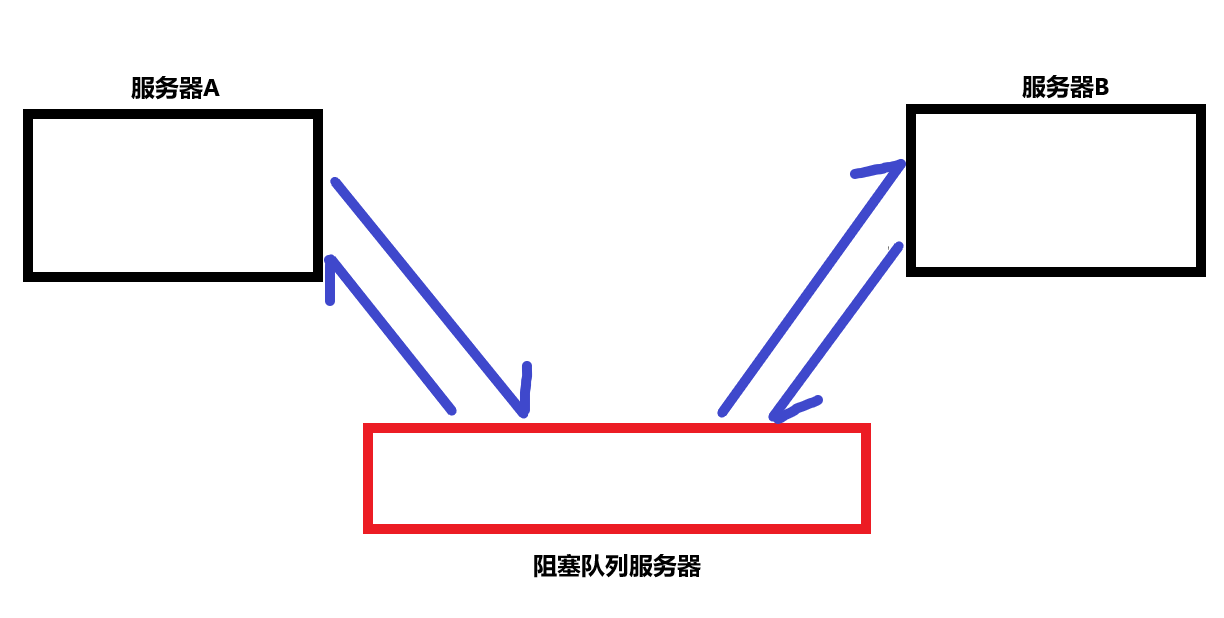
【JAVAEE】手把手教学多线程,包教包会~
线程与进程为了实现多个任务并发执行的效果,人们引进了进程。何谓进程?我们电脑上跑起来的每个程序都是进程。每一个进程启动,系统会为其分配内存空间以及在文件描述符表上有所记录等。进程是操作系统进行资源分配的最小单位,这意…...
基于ChatGPT API的PC端软件开发过程遇到的问题的分析
如果喜欢本文章,记得收藏哦! 关注我,一起学Java。 一、基于ChatGPT API的PC端软件开发过程遇到的问题的分析 最近这个OpenAI公司推出的GPT-4.0模型真是太火了。当然由于OpenAI目前还没有正式全面对外开放GPT-4.0 API,所以本次使用…...

啥是插入排序 ?
一、概述 排序是算法中的一部分。所以我们学习排序也是算法的入门,为了能让大家感受到排序是算法的一部分,我举个例子证明一下:比如麻将游戏,发完牌之后需要对手上的牌进行排序,大家想想,麻将排序如何排呢…...

华为OD机试题 Q2 押题【贪心的商人 or 最大利润】用 C++ 编码,速通
最近更新的博客 华为od 2023 | 什么是华为od,od 薪资待遇,od机试题清单华为OD机试真题大全,用 Python 解华为机试题 | 机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为od机试,独家整理 已参加机试人员的实战技巧本篇题解:贪心的商人 or 最大利润 题目…...
spring框架注解
3.Spring有哪些常用注解呢? Spring常用注解 Web: Controller:组合注解(组合了Component注解),应用在MVC层(控制层)。 RestController:该注解为一个组合注解,相当于Con…...

前端如何处理文本溢出
前言 在现代网页设计中,文本是网页中最重要的内容之一。然而,当文本超出其容器的大小时,会发生文本溢出的问题。文本溢出不仅会影响网页的视觉效果,还会影响网页的可读性和可用性。在前端开发中,解决文本溢出的问题是…...

vue elementUI select下拉框设置默认值(赋值)失败
vue elementUI select下拉框设置默认值 要为select下拉框设定默认值,只需要把 v-model 绑定的值和你想要选中 option 的 value 值设置一样即可。 下面上代码: html部分代码: <el-select v-model"valuetype" change"ch…...

TensorRT创建Engine并推理engine
1. 验证集数据集 Class Images Labels P R mAP.5 mAP.5:.95: 100%|██████████| 84/all 1000 28423 0.451 0.374 0.376 0.209pedestrians 1000 17833 0.737 0.855 0.88 …...

生成式人工智能所面临的问题有哪些?
在生成式人工智能中工作需要混合技术、创造性和协作技能。通过发展这些技能,您将能够在这个令人兴奋且快速发展的领域应对具有挑战性的问题。 生成式人工智能是指一类机器学习技术,旨在生成与训练数据相似但不完全相同的新数据。 换句话说,…...
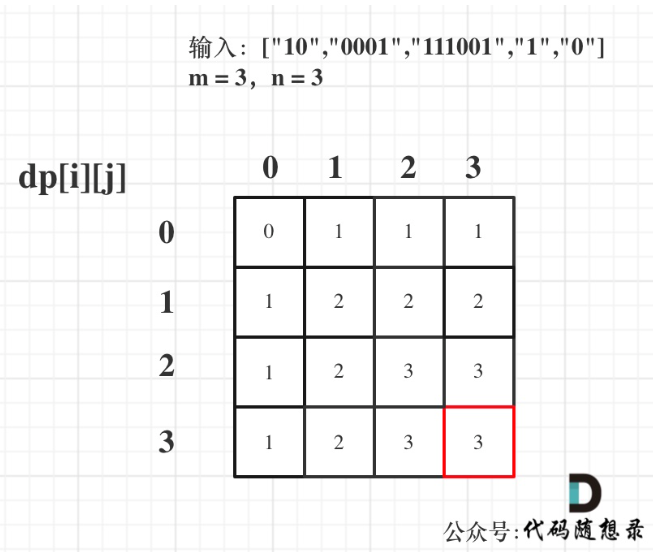
代码随想录算法训练营第四十三天 | 1049. 最后一块石头的重量 II、494. 目标和、474. 一和零
打卡第43天,01背包应用。 今日任务 1049.最后一块石头的重量 II494.目标和474.一和零 1049. 最后一块石头的重量 II 有一堆石头,用整数数组 stones 表示。其中 stones[i] 表示第 i 块石头的重量。 每一回合,从中选出任意两块石头࿰…...

PostCSS 让js可以处理css
GitHub 中文readmie PostCSS 中文网(建设中) PostCSS 不是样式预处理器 是 CSS 语法转换的工具,但不严格遵循css规范,只要符合css语法规则就可以被处理。这也让提前实现新提案成为可能。 使用 webpack 中使用 postcss-loader …...

【C语言进阶:自定义类型详解】位段
本节重点内容: 什么是位段位段的内存分配位段的跨平台问题位段的应用⚡什么是位段 位段的声明和结构是非常类似的,但是有两个不同: 位段的成员必须是 int、unsigned int 或signed int 。位段的成员名后边有一个冒号和一个数字。 struct A…...
十三、RNN循环神经网络实战
因为我本人主要课题方向是处理图像的,RNN是基本的序列处理模型,主要应用于自然语言处理,故这里就简单的学习一下,了解为主 一、问题引入 已知以前的天气数据信息,进行预测当天(4-9)是否下雨 日期温度气压是否下雨4-…...

如何用opendbc解决汽车CAN总线解码难题:一份完整的实践指南
如何用opendbc解决汽车CAN总线解码难题:一份完整的实践指南 【免费下载链接】opendbc a Python API for your car 项目地址: https://gitcode.com/gh_mirrors/op/opendbc 面对现代汽车复杂的电子控制系统,你是否曾经困惑于如何理解车辆内部的数据…...

本地部署Qwen大模型:从量化加载到性能优化的完整实践指南
1. 项目概述:从开源大模型到个人AI助手的跃迁最近在折腾本地部署大语言模型,发现了一个宝藏项目——QwenLM/Qwen。这可不是一个简单的模型仓库,而是一个由通义千问团队打造的开源大语言模型家族。简单来说,它让你能在自己的电脑或…...

3分钟搞定!3DS游戏格式转换神器:让.3ds文件秒变可安装的CIA格式 [特殊字符]
3分钟搞定!3DS游戏格式转换神器:让.3ds文件秒变可安装的CIA格式 🎮 【免费下载链接】3dsconv Python script to convert Nintendo 3DS CCI (".cci", ".3ds") files to the CIA format 项目地址: https://gitcode.com/g…...

独立开发者如何借助Taotoken模型广场为不同任务选型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何借助Taotoken模型广场为不同任务选型 作为一名独立开发者,日常工作中常需处理多种类型的任务࿱…...

高校实验室项目如何利用Taotoken的Token Plan套餐控制科研实验成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 高校实验室项目如何利用Taotoken的Token Plan套餐控制科研实验成本 对于高校实验室的科研团队和学生项目组而言,在探索…...

酒吧数字化方案:Java德州扑克小酒馆扫码点餐预约系统源码
在消费升级与数字化转型的大背景下,中小型德州扑克小酒馆的运营模式正逐步从“人工主导”向“数字化赋能”转变。不同于传统酒吧,德州扑克小酒馆以“休闲娱乐餐饮服务”为核心,其运营痛点集中在点餐效率低、预约管理乱、桌台调度难、合规管控…...

Linux只读挂载保护排查方法
Linux只读挂载保护排查方法本文面向具备一定 Linux 基础的技术人员,围绕只读挂载保护展开,重点讨论写入隔离、配置保护和异常诊断。在中级运维和系统管理工作中,这类主题常常与配置变更、资源状态、权限边界、自动化任务和业务影响交织在一起…...

网络安全5大高薪赛道,哪条是你的职业快车道?
1. 政企安全:国家队的黄金赛道 政企安全领域就像网络安全行业的"公务员体系",稳定性和薪资待遇都处于行业头部水平。我接触过不少从互联网公司转行做政企安全的工程师,他们普遍反馈"虽然加班也不少,但项目预算充足…...
)
ChatGPT支付功能现状深度研判(2024Q2最新政策+OpenAI开发者文档交叉验证)
更多请点击: https://intelliparadigm.com 第一章:ChatGPT实时支付功能在哪里 ChatGPT 本身并不原生支持实时支付功能。OpenAI 官方发布的 ChatGPT(包括免费版、Plus 订阅版及 Team/Enterprise 版)定位为人工智能对话助手&#x…...
XUnity Auto Translator:3分钟为Unity游戏添加多语言支持的终极解决方案
XUnity Auto Translator:3分钟为Unity游戏添加多语言支持的终极解决方案 【免费下载链接】XUnity.AutoTranslator 项目地址: https://gitcode.com/gh_mirrors/xu/XUnity.AutoTranslator 你是否曾因语言障碍而放弃心爱的Unity游戏?或者作为开发者…...