集成时间序列模型提高预测精度
使用Catboost从RNN、ARIMA和Prophet模型中提取信号进行预测
集成各种弱学习器可以提高预测精度,但是如果我们的模型已经很强大了,集成学习往往也能够起到锦上添花的作用。流行的机器学习库scikit-learn提供了一个StackingRegressor,可以用于时间序列任务。但是StackingRegressor有一个局限性;它只接受其他scikit-learn模型类和api。所以像ARIMA这样在scikit-learn中不可用的模型,或者来自深度神经网络的模型都无法使用。在这篇文章中,我将展示如何堆叠我们能见到的模型的预测。

我们将用到下面的包:
pip install --upgrade scalecastconda install tensorflowconda install shapconda install -c conda-forge cmdstanpypip install prophet
数据集
数据集每小时一次,分为训练集(700个观测值)和测试集(48个观测值)。下面代码是读取数据并将其存储在Forecaster对象中:
importpandasaspdimportnumpyasnpfromscalecast.ForecasterimportForecasterfromscalecast.utilimportmetricsimportmatplotlib.pyplotaspltimportseabornassnsdefread_data(idx='H1', cis=True, metrics= ['smape']):info=pd.read_csv('M4-info.csv',index_col=0,parse_dates=['StartingDate'],dayfirst=True,)train=pd.read_csv(f'Hourly-train.csv',index_col=0,).loc[idx]test=pd.read_csv(f'Hourly-test.csv',index_col=0,).loc[idx]y=train.valuessd=info.loc[idx,'StartingDate']fcst_horizon=info.loc[idx,'Horizon']cd=pd.date_range(start=sd,freq='H',periods=len(y),)f=Forecaster(y=y, # observed valuescurrent_dates=cd, # current datesfuture_dates=fcst_horizon, # forecast lengthtest_length=fcst_horizon, # test-set lengthcis=cis, # whether to evaluate intervals for each modelmetrics=metrics, # what metrics to evaluate)returnf, test.valuesf, test_set=read_data()f# display the Forecaster object
结果是这样的:

模型
在我们开始构建模型之前,我们需要从中生成最简单的预测,naive方法就是向前传播最近24个观测值。
f.set_estimator('naive')f.manual_forecast(seasonal=True)
然后使用ARIMA、LSTM和Prophet作为基准。
ARIMA
Autoregressive Integrated Moving Average 是一种流行而简单的时间序列技术,它利用序列的滞后和误差以线性方式预测其未来。通过EDA,我们确定这个系列是高度季节性的。所以最终选择了应用order (5,1,4) x(1,1,1,24)的季节性ARIMA模型。
f.set_estimator('arima')f.manual_forecast(order = (5,1,4),seasonal_order = (1,1,1,24),call_me = 'manual_arima',)
LSTM
如果说ARIMA是时间序列模型中比较简单的一种,那么LSTM就是比较先进的方法之一。它是一种具有许多参数的深度学习技术,其中包括一种在顺序数据中发现长期和短期模式的机制,这在理论上使其成为时间序列的理想选择。这里使用tensorflow建立这个模型
f.set_estimator('rnn')f.manual_forecast(lags=48,layers_struct=[('LSTM',{'units':100,'activation':'tanh'}),('LSTM',{'units':100,'activation':'tanh'}),('LSTM',{'units':100,'activation':'tanh'}),],optimizer='Adam',epochs=15,plot_loss=True,validation_split=0.2,call_me='rnn_tanh_activation',)f.manual_forecast(lags=48,layers_struct=[('LSTM',{'units':100,'activation':'relu'}),('LSTM',{'units':100,'activation':'relu'}),('LSTM',{'units':100,'activation':'relu'}),],optimizer='Adam',epochs=15,plot_loss=True,validation_split=0.2,call_me='rnn_relu_activation',)
Prophet
尽管它非常受欢迎,但有人声称它的准确性并不令人印象深刻,主要是因为它对趋势的推断有时候很不切实际,而且它没有通过自回归建模来考虑局部模式。但是它也有自己的特点。1,它会自动将节日效果应用到模型身上,并且还考虑了几种类型的季节性。可以以用户所需的最低需求来完成这一切,所以我喜欢把它用作信号,而不是最终的预测结果。
f.set_estimator('prophet')f.manual_forecast()
比较结果
现在我们已经为每个模型生成了预测,让我们看看它们在验证集上的表现如何,验证集是我们训练集中的最后48个观察结果。
results=f.export(determine_best_by='TestSetSMAPE')ms=results['model_summaries']ms[['ModelNickname','TestSetLength','TestSetSMAPE','InSampleSMAPE',]]

每个模型的表现都优于naive方法。ARIMA模型表现最好,百分比误差为4.7%,其次是Prophet模型。让我们看看所有的预测与验证集的关系:
f.plot(order_by="TestSetSMAPE",ci=True)plt.show()

所有这些模型在这个时间序列上的表现都很合理,它们之间没有很大的偏差。下面让我们把它们堆起来!
堆叠模型
每个堆叠模型都需要一个最终估计器,它将过滤其他模型的各种估计,创建一组新的预测。我们将把之前结果与Catboost估计器叠加在一起。Catboost是一个强大的程序,希望它能从每个已经应用的模型中充实出最好的信号。
f.add_signals(f.history.keys(), # add signals from all previously evaluated models)f.add_ar_terms(48)f.set_estimator('catboost')
上面的代码将来自每个评估模型的预测添加到Forecaster对象中。它称这些预测为“信号”。 它们的处理方式与存储在同一对象中的任何其他协变量相同。 这里还添加了最后 48 个系列的滞后作为 Catboost 模型可以用来进行预测的附加回归变量。 现在让我们调用三种 Catboost 模型:一种使用所有可用信号和滞后,一种仅使用信号,一种仅使用滞后。
f.manual_forecast(Xvars='all',call_me='catboost_all_reg',verbose=False,)f.manual_forecast(Xvars=[xforxinf.get_regressor_names() ifx.startswith('AR')], call_me='catboost_lags_only',verbose=False,)f.manual_forecast(Xvars=[xforxinf.get_regressor_names() ifnotx.startswith('AR')], call_me='catboost_signals_only',verbose=False,)
下面可以比较所有模型的结果。我们将研究两个度量:SMAPE和平均绝对比例误差(MASE)。这是实际M4比赛中使用的两个指标。
test_results=pd.DataFrame(index=f.history.keys(),columns= ['smape','mase'])fork, vinf.history.items():test_results.loc[k,['smape','mase']] = [metrics.smape(test_set,v['Forecast']),metrics.mase(test_set,v['Forecast'],m=24,obs=f.y),]test_results.sort_values('smape')
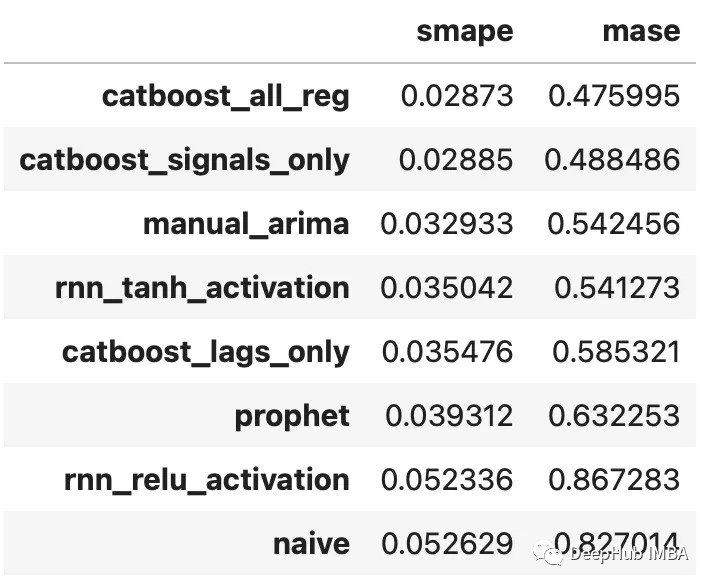
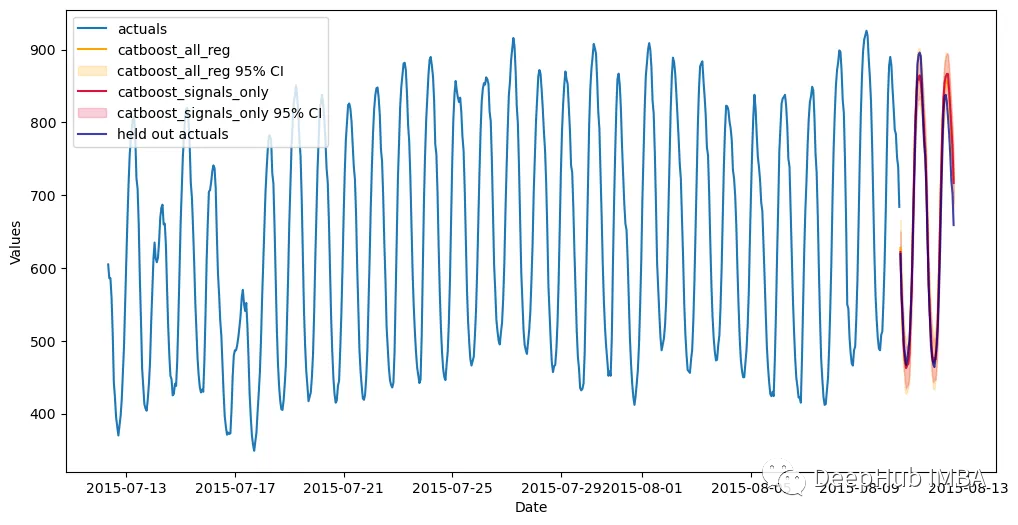
可以看到,通过组合来自不同类型模型的信号生成了两个优于其他估计器的估计器:使用所有信号训练的Catboost模型和只使用信号的Catboost模型。这两种方法的样本误差都在2.8%左右。下面是对比图:
fig, ax=plt.subplots(figsize=(12,6))f.plot(models= ['catboost_all_reg','catboost_signals_only'],ci=True,ax=ax)sns.lineplot(x=f.future_dates, y=test_set, ax=ax,label='held out actuals',color='darkblue',alpha=.75,)plt.show()
哪些信号最重要?
为了完善分析,我们可以使用shapley评分来确定哪些信号是最重要的。Shapley评分被认为是确定给定机器学习模型中输入的预测能力的最先进的方法之一。得分越高,意味着输入在特定模型中越重要。
f.export_feature_importance('catboost_all_reg')
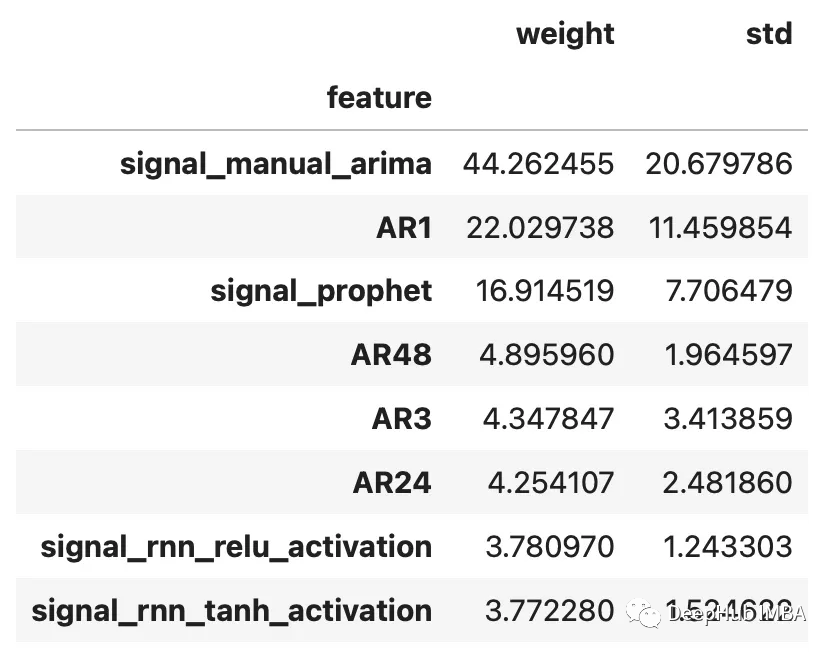
上面的图只显示了前几个最重要的预测因子,但我们可以从中看出,ARIMA信号是最重要的,其次是序列的第一个滞后,然后是Prophet。RNN模型的得分也高于许多滞后模型。如果我们想在未来训练一个更轻量的模型,这可能是一个很好的起点。
总结
在这篇文章中,我展示了在时间序列上下文中集成模型的力量,以及如何使用不同的模型在时间序列上获得更高的精度。这里我们使用scalecast包,这个包的功能还是很强大的,如果你喜欢,可以去它的主页看看:
https://avoid.overfit.cn/post/cd910a41e6b94852b762cd6f2abf8b16
作者:Michael Keith
相关文章:
集成时间序列模型提高预测精度
使用Catboost从RNN、ARIMA和Prophet模型中提取信号进行预测 集成各种弱学习器可以提高预测精度,但是如果我们的模型已经很强大了,集成学习往往也能够起到锦上添花的作用。流行的机器学习库scikit-learn提供了一个StackingRegressor,可以用于…...
(详细)《美国节日》:某月的第几个星期几
目录 一、题目描述: 二、思路: 1、给定 年月日,如何知道这天是星期几? 2、已知这个月的第一天是星期几,如何知道第三个星期一是几号? 3、最后一个星期一 三、思路总结 四、代码 一、题目描述…...

架构设计的历史背景
架构设计的历史背景 在探讨架构设计的历史背景时,了解软件开发进化的历史是一个重要的起点。了解软件开发的演变过程可以帮助我们更好地理解架构设计的起源和发展。现在,让我们来简要回顾一下软件开发的历史,并探索软件架构出现的背景。 首先…...
C#,初学琼林(06)——组合数的算法、数据溢出问题的解决方法及相关C#源代码
1 排列permutation 排列,一般地,从n个不同元素中取出m(m≤n)个元素,按照一定的顺序排成一列,叫做从n个元素中取出m个元素的一个排列(permutation)。特别地,当mn时,这个排列被称作全…...

MySQL数据库——绘制E-R图:数据库概要设计阶段
在MySQL数据库的概要设计阶段,绘制E-R图是非常重要的一步。E-R图(实体关系图)是一种图形化的工具,用于描述数据库中实体之间的关系。 以下是在MySQL数据库概要设计阶段绘制E-R图的步骤: 确定实体:在MySQL数…...

对类和对象的理解
对象:对象是人们要进行研究的任何事物,它不仅能表示具体的事物,还能表示抽象的规则、计划或事件。对象具有状态,一个对象用数据值来描述它的状态。对象还有操作,用于改变对象的状态,对象及其操作就是对象的…...

edge-tts微软文本转语音库,来听听这些语音是否很熟悉?
上期图文教程,我们分享了Azure机器学习的文本转语音的账号申请与API申请的详细步骤,也介绍了基于python3实现Azure机器学习文本转语音功能的代码实现过程,虽然我们可以使用Azure账号免费提供一年的试用期,但是毕竟是要付费的,我们的API也无法长期使用,好在微软发布了edge…...

MySQL更换存储引擎
要更换 MySQL 5.7 中某个表的存储引擎,可以使用以下的 SQL 命令: sql复制代码 ALTER TABLE table_name ENGINEengine_name; 其中,table_name 是需要更换存储引擎的数据表名称,engine_name 则是需要更换成的新存储引擎名称。 举…...

filebeat收集不规则多行日志
现环境有多行日志输出内容和格式不确定,合并后使用grok默认正则无法收集,需要自己编写正则 日志内容如下: ERROR|2023-04-06 14:27:52|helper|test|http|/api/ad/listBanner|1d60fff861bqwe4b0397be554141eb 127.0.0.1|1b4429-5adb-44d4-acf…...
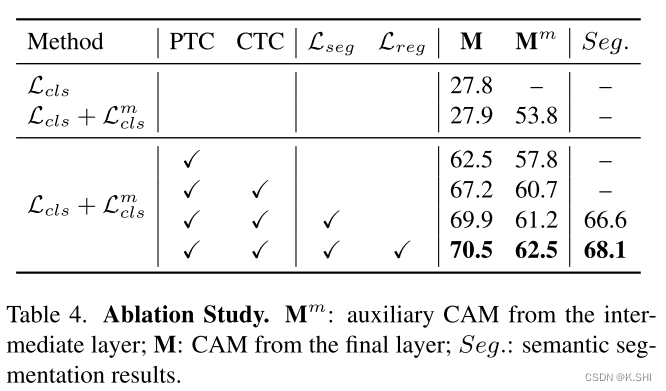
Token Contrast for Weakly-Supervised Semantic Segmentation
文章来源:[CVPR2023] Keywords:Weakly-Supervised Semantic Segmentation(WSSS);over-smoothing; ViT 一、本文提出的问题以及解决方案: 本文解决了over-smoothing问题,该问题其实是在之前的GCN网络中提出…...

Jenkins运行在docker中使用Maven构建Java应用程序
这篇笔记是Jenkins入门教程使用Maven构建Java应用程序的一个补充说明,因为我照着文档操作的过程中遇到不少问题,遂一一做个笔记。 我的主机是Windows 11,安装的docker是Docker Desktop 4.18.0。 第一点,在Windows里执行docker命…...
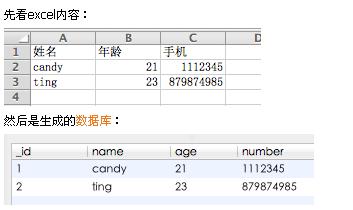
将excel导入到sqlite的方法代码
Python实现excel转sqlite的方法,具体如下: Python环境的安装配置就不说了,个人喜欢pydev的开发环境。 python解析excel需要使用第三方的库,这里选择使用xlrd 下面是源代码: #!/usr/bin/python # encodingutf-8 Creat…...

Redis主从复制、哨兵和集群部署
文章目录一、主从复制1、主从复制-哨兵-集群2、主从复制的概念3、主从复制的作用4、主从复制流程5、部署Redis 主从复制步骤6、实例操作:部署Redis 主从复制二、哨兵模式1、哨兵模式的原理2、哨兵模式的作用3、哨兵结构由两部分组成,哨兵节点和数据节点4…...

protobuf序列化
文章目录protubufprotobuf序列化protobuf的原理定义message编译message文件应用protobufMessage 基本用法Message 嵌套使用protubuf protobuf序列化 protobuf是一种比json和xml等序列化工具更加轻量和高效的结构化数据存储格式,性能比json和xml真的强很多ÿ…...
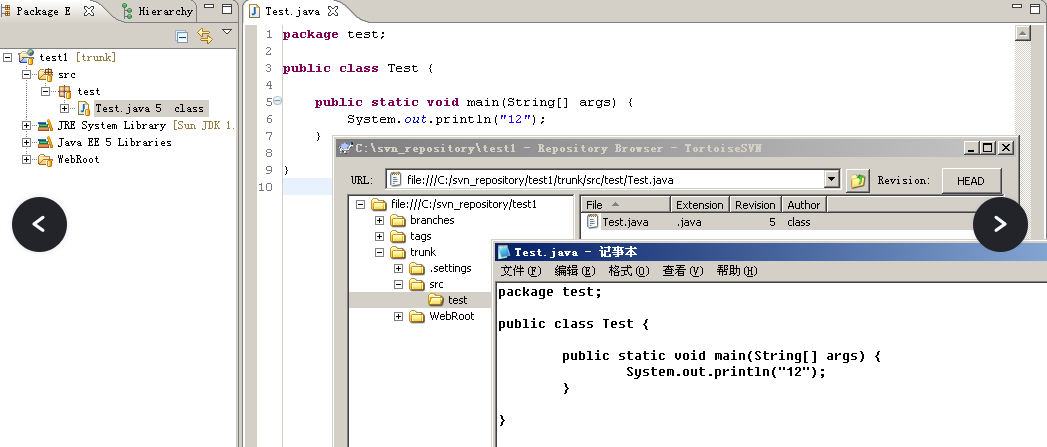
更新时无冲突的情况(阁瑞钛伦特软件-九耶实训)
大多数使用“与资源库同步”菜单的目的是想查看本地和远程资源的差异,并不想将本地的内容进行更新。 而“更新”菜单则不然,它的主要作用是将远程仓库中的内容下载到本地,以使本地的版本内容和仓库中的内容一致。 Step01:复用前…...

3.4 函数的单调性和曲线的凹凸性
学习目标: 如果我要学习函数的单调性和曲线的凹凸性,我会采取以下几个步骤: 理解概念和定义:首先,我会学习单调性和凹凸性的定义和概念。单调性是指函数的增减性质,可以分为单调递增和单调递减;…...

LeetCode 404. 左叶子之和 | C++语言版
LeetCode 404. 左叶子之和 | C语言版LeetCode 404. 左叶子之和题目描述解题思路思路一:使用递归代码实现运行结果参考文章:思路二:减少遍历节点数代码实现运行结果参考文章:LeetCode 404. 左叶子之和 题目描述 题目地址…...

arm架构安装Rancher并导入k8s集群解决Error: no objects passed to apply
Rancher介绍 Rancher 2.0-2.4版本 是一个开源的企业级容器管理平台。通过Rancher,企业再也不必自己使用一系列的开源软件去从头搭建容器服务平台。Rancher提供了在生产环境中使用的管理Docker和Kubernetes的全栈化容器部署与管理平台。 Rancher 2.5版本 是为使用容…...
安装PaddleSpeech
github地址https://github.com/PaddlePaddle/PaddleSpeech 创建虚拟环境 conda create -p E:\Python\envs\nlppaddle python3.7 # conda create -p E:\Python\envs\speechstu python3.8激活虚拟环境 conda activate E:\Python\envs\nlppaddle # conda activate E:\Python\…...
UE “体积”的简单介绍
目录 一、阻挡体积 二、摄像机阻挡体积 三、销毁Z体积 四、后期处理体积 一、阻挡体积 你可以在静态网格体上使用阻挡体积替代碰撞表面,比如建筑物墙壁。这可以增强场景的可预测性,因为物理对象不会与地面和墙壁上的凸起细节相互作用。它还能降低物理模…...

HttpOnly Cookie 深度解析
一、什么是 HttpOnly Cookie HttpOnly 是一个可以附加在 Set-Cookie 响应头上的标志位(flag)。当一个 Cookie 被标记为 HttpOnly 后,客户端脚本(如 JavaScript)将无法通过 document.cookie 等 API 访问该 Cookie&…...

InsForge:基于Python的Instagram内容自动化创作与发布工具全解析
1. 项目概述与核心价值最近在折腾一个挺有意思的开源项目,叫InsForge。这名字听起来有点“工业锻造”的味道,实际上,它是一个专注于Instagram内容创作与自动化的工具集。简单来说,它试图帮你解决在Instagram上创作、发布、管理内容…...

mnestra:基于ESBuild的极简前端构建工具,速度与体验的完美平衡
1. 项目概述:一个被低估的现代前端构建工具如果你在前端开发领域摸爬滚打超过五年,大概率经历过从 Grunt、Gulp 到 Webpack 的构建工具变迁史。每次工具的迭代,都伴随着配置文件的日益复杂和构建速度的微妙下降。当 Vite 携 ES Module 原生支…...

Excel MCP Server终极指南:3步实现无界面Excel自动化处理
Excel MCP Server终极指南:3步实现无界面Excel自动化处理 【免费下载链接】excel-mcp-server A Model Context Protocol server for Excel file manipulation 项目地址: https://gitcode.com/gh_mirrors/ex/excel-mcp-server 你是否厌倦了手动操作Excel的繁琐…...

ViGEmBus终极指南:Windows游戏手柄模拟驱动的完整解决方案
ViGEmBus终极指南:Windows游戏手柄模拟驱动的完整解决方案 【免费下载链接】ViGEmBus Windows kernel-mode driver emulating well-known USB game controllers. 项目地址: https://gitcode.com/gh_mirrors/vi/ViGEmBus 你是否曾经遇到过这样的情况ÿ…...

如何快速解密网易云NCM文件:终极免费转换工具指南
如何快速解密网易云NCM文件:终极免费转换工具指南 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否在网易云音乐下载了喜欢的歌曲,…...

ncmdumpGUI:3步解决网易云音乐ncm格式播放限制的终极方案
ncmdumpGUI:3步解决网易云音乐ncm格式播放限制的终极方案 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否曾经在网易云音乐下载了心爱的歌曲…...

构建动态技能图谱:从数据模型到自动化可视化的完整实践
1. 项目概述:一个技能图谱的诞生最近在GitHub上看到一个挺有意思的项目,叫dortort/skills。乍一看,这只是一个个人仓库,但点进去你会发现,它远不止是一个简单的代码集合。它更像是一张动态的、可视化的个人技能地图&am…...

XHS-Downloader:小红书内容采集与管理的全栈解决方案
XHS-Downloader:小红书内容采集与管理的全栈解决方案 【免费下载链接】XHS-Downloader 小红书(XiaoHongShu、RedNote)链接提取/作品采集工具:提取账号发布、收藏、点赞、专辑作品链接;提取搜索结果作品、用户链接&…...

技术解构:逆向工程视角下的百度网盘下载链接解析机制
技术解构:逆向工程视角下的百度网盘下载链接解析机制 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 想象一下,当你收到朋友分享的百度网盘链接时&…...