Kafka的概念|架构|搭建|查看命令
Kafka的概念|架构|搭建|查看命令
- 一 Kafka 概述
- 二 使用消息队列的好处
- 三Kafka 定义
- 3.1Kafka 简介
- 3.2Kafka 的特性
- 3.3 Kafka 系统架构
- 3.4 Partation 数据路由规则
- 四 kafka的架构
- 五 搭建kafka
- 5.1环境准备
- 5.2安装kafka
- 5.3 修改配置文件
- 5.4 编辑其他二台虚拟机的配置文件
- 5.5 编辑三台机子环境变量
- 5.6 配置 Zookeeper 启动脚本
- 5.7 启动kafka测试
一 Kafka 概述
1.为什么需要消息队列(MQ)
主要原因是由于在高并发环境下,同步请求来不及处理,请求往往会发生阻塞。比如大量的请求并发访问数据库,导致行锁表锁,最后请求线程会堆积过多,从而触发 too many connection 错误,引发雪崩效应。
我们使用消息队列,通过异步处理请求,从而缓解系统的压力。消息队列常应用于异步处理,流量削峰,应用解耦,消息通讯等场景。
当前比较常见的 MQ 中间件有 ActiveMQ、RabbitMQ、RocketMQ、Kafka 等。
二 使用消息队列的好处
(1)解耦
允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束。
(2)可恢复性
系统的一部分组件失效时,不会影响到整个系统。消息队列降低了进程间的耦合度,所以即使一个处理消息的进程挂掉,加入队列中的消息仍然可以在系统恢复后被处理。
(3)缓冲
有助于控制和优化数据流经过系统的速度,解决生产消息和消费消息的处理速度不一致的情况。
(4)灵活性 & 峰值处理能力
在访问量剧增的情况下,应用仍然需要继续发挥作用,但是这样的突发流量并不常见。如果为以能处理这类峰值访问为标准来投入资源随时待命无疑是巨大的浪费。使用消息队列能够使关键组件顶住突发的访问压力,而不会因为突发的超负荷的请求而完全崩溃。
(5)异步通信
很多时候,用户不想也不需要立即处理消息。消息队列提供了异步处理机制,允许用户把一个消息放入队列,但并不立即处理它。想向队列中放入多少消息就放多少,然后在需要的时候再去处理它们。
//消息队列的两种模式
(1)点对点模式(一对一,消费者主动拉取数据,消息收到后消息清除)
消息生产者生产消息发送到消息队列中,然后消息消费者从消息队列中取出并且消费消息。消息被消费以后,消息队列中不再有存储,所以消息消费者不可能消费到已经被消费的消息。消息队列支持存在多个消费者,但是对一个消息而言,只会有一个消费者可以消费。
(2)发布/订阅模式(一对多,又叫观察者模式,消费者消费数据之后不会清除消息)
消息生产者(发布)将消息发布到 topic 中,同时有多个消息消费者(订阅)消费该消息。和点对点方式不同,发布到 topic 的消息会被所有订阅者消费。
发布/订阅模式是定义对象间一种一对多的依赖关系,使得每当一个对象(目标对象)的状态发生改变,则所有依赖于它的对象(观察者对象)都会得到通知并自动更新。
三Kafka 定义
Kafka 是一个分布式的基于发布/订阅模式的消息队列(MQ,Message Queue),主要应用于大数据实时处理领域。
3.1Kafka 简介
Kafka 是最初由 Linkedin 公司开发,是一个分布式、支持分区的(partition)、多副本的(replica),基于 Zookeeper 协调的分布式消息中间件系统,它的最大的特性就是可以实时的处理大量数据以满足各种需求场景,比如基于 hadoop 的批处理系统、低延迟的实时系统、Spark/Flink 流式处理引擎,nginx 访问日志,消息服务等等,用 scala 语言编写,
Linkedin 于 2010 年贡献给了 Apache 基金会并成为顶级开源项目。
3.2Kafka 的特性
●高吞吐量、低延迟
Kafka 每秒可以处理几十万条消息,它的延迟最低只有几毫秒。每个 topic 可以分多个 Partition,Consumer Group 对 Partition 进行消费操作,提高负载均衡能力和消费能力。
●可扩展性
kafka 集群支持热扩展
●持久性、可靠性
消息被持久化到本地磁盘,并且支持数据备份防止数据丢失
●容错性
允许集群中节点失败(多副本情况下,若副本数量为 n,则允许 n-1 个节点失败)
●高并发
支持数千个客户端同时读写
3.3 Kafka 系统架构
(1)Broker
一台 kafka 服务器就是一个 broker。一个集群由多个 broker 组成。一个 broker 可以容纳多个 topic。
(2)Topic
可以理解为一个队列,生产者和消费者面向的都是一个 topic。
类似于数据库的表名或者 ES 的 index
物理上不同 topic 的消息分开存储
(3)Partition
为了实现扩展性,一个非常大的 topic 可以分布到多个 broker(即服务器)上,一个 topic 可以分割为一个或多个 partition,每个 partition 是一个有序的队列。Kafka 只保证 partition 内的记录是有序的,而不保证 topic 中不同 partition 的顺序。
每个 topic 至少有一个 partition,当生产者产生数据的时候,会根据分配策略选择分区,然后将消息追加到指定的分区的队列末尾。
3.4 Partation 数据路由规则
1.指定了 patition,则直接使用;
2.未指定 patition 但指定 key(相当于消息中某个属性),通过对 key 的 value 进行 hash 取模,选出一个 patition;
3.patition 和 key 都未指定,使用轮询选出一个 patition。
每条消息都会有一个自增的编号,用于标识消息的偏移量,标识顺序从 0 开始。
每个 partition 中的数据使用多个 segment 文件存储。
如果 topic 有多个 partition,消费数据时就不能保证数据的顺序。严格保证消息的消费顺序的场景下(例如商品秒杀、 抢红包),需要将 partition 数目设为 1。
●broker 存储 topic 的数据。如果某 topic 有 N 个 partition,集群有 N 个 broker,那么每个 broker 存储该 topic 的一个 partition。
●如果某 topic 有 N 个 partition,集群有 (N+M) 个 broker,那么其中有 N 个 broker 存储 topic 的一个 partition, 剩下的 M 个 broker 不存储该 topic 的 partition 数据。
●如果某 topic 有 N 个 partition,集群中 broker 数目少于 N 个,那么一个 broker 存储该 topic 的一个或多个 partition。在实际生产环境中,尽量避免这种情况的发生,这种情况容易导致 Kafka 集群数据不均衡。
//分区的原因
●方便在集群中扩展,每个Partition可以通过调整以适应它所在的机器,而一个topic又可以有多个Partition组成,因此整个集群就可以适应任意大小的数据了;
●可以提高并发,因为可以以Partition为单位读写了。
(4)Replica
副本,为保证集群中的某个节点发生故障时,该节点上的 partition 数据不丢失,且 kafka 仍然能够继续工作,kafka 提供了副本机制,一个 topic 的每个分区都有若干个副本,一个 leader 和若干个 follower。
(5)Leader
每个 partition 有多个副本,其中有且仅有一个作为 Leader,Leader 是当前负责数据的读写的 partition。
(6)Follower
Follower 跟随 Leader,所有写请求都通过 Leader 路由,数据变更会广播给所有 Follower,Follower 与 Leader 保持数据同步。Follower 只负责备份,不负责数据的读写。
如果 Leader 故障,则从 Follower 中选举出一个新的 Leader。
当 Follower 挂掉、卡住或者同步太慢,Leader 会把这个 Follower 从 ISR(Leader 维护的一个和 Leader 保持同步的 Follower 集合) 列表中删除,重新创建一个 Follower。
(7)
生产者即数据的发布者,该角色将消息 push 发布到 Kafka 的 topic 中。
broker 接收到生产者发送的消息后,broker 将该消息追加到当前用于追加数据的 segment 文件中。
生产者发送的消息,存储到一个 partition 中,生产者也可以指定数据存储的 partition。
(8)Consumer
消费者可以从 broker 中 pull 拉取数据。消费者可以消费多个 topic 中的数据。
(9)Consumer Group(CG)
消费者组,由多个 consumer 组成。
所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。可为每个消费者指定组名,若不指定组名则属于默认的组。
将多个消费者集中到一起去处理某一个 Topic 的数据,可以更快的提高数据的消费能力。
消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费,防止数据被重复读取。
消费者组之间互不影响。
(10)offset 偏移量
可以唯一的标识一条消息。
偏移量决定读取数据的位置,不会有线程安全的问题,消费者通过偏移量来决定下次读取的消息(即消费位置)。
消息被消费之后,并不被马上删除,这样多个业务就可以重复使用 Kafka 的消息。
某一个业务也可以通过修改偏移量达到重新读取消息的目的,偏移量由用户控制。
消息最终还是会被删除的,默认生命周期为 1 周(7*24小时)。
(11)Zookeeper
Kafka 通过 Zookeeper 来存储集群的 meta 信息。
由于 consumer 在消费过程中可能会出现断电宕机等故障,consumer 恢复后,需要从故障前的位置的继续消费,所以 consumer 需要实时记录自己消费到了哪个 offset,以便故障恢复后继续消费。
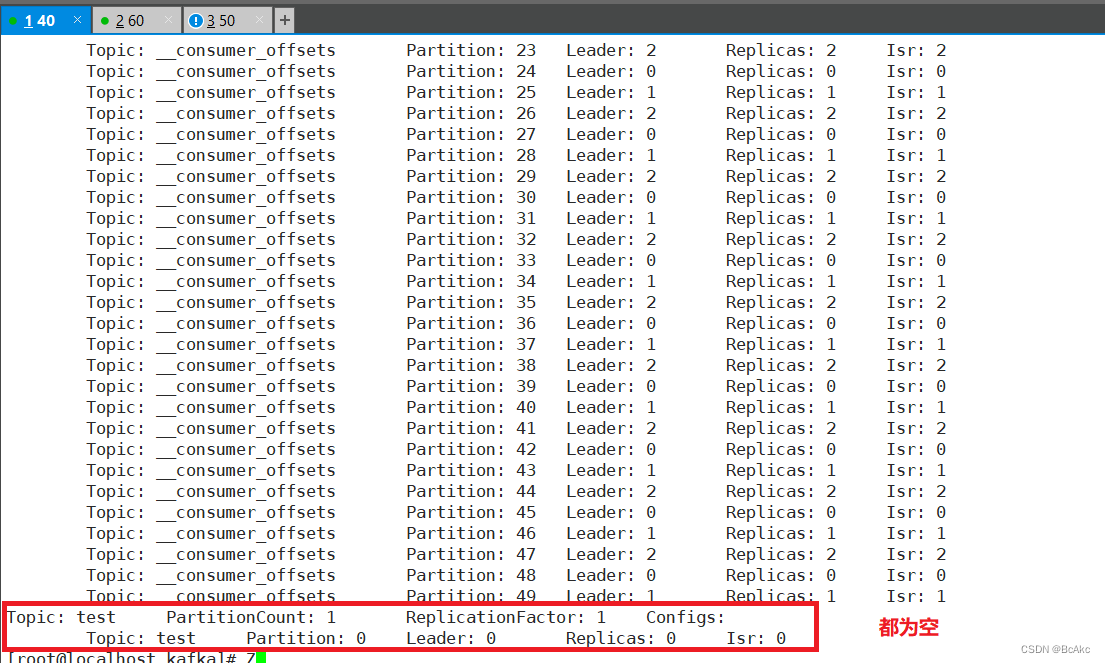
Kafka 0.9 版本之前,consumer 默认将 offset 保存在 Zookeeper 中;从 0.9 版本开始,consumer 默认将 offset 保存在 Kafka 一个内置的 topic 中,该 topic 为 __consumer_offsets。
也就是说,zookeeper的作用就是,生产者push数据到kafka集群,就必须要找到kafka集群的节点在哪里,这些都是通过zookeeper去寻找的。消费者消费哪一条数据,也需要zookeeper的支持,从zookeeper获得offset,offset记录上一次消费的数据消费到哪里,这样就可以接着下一条数据进行消费。
四 kafka的架构
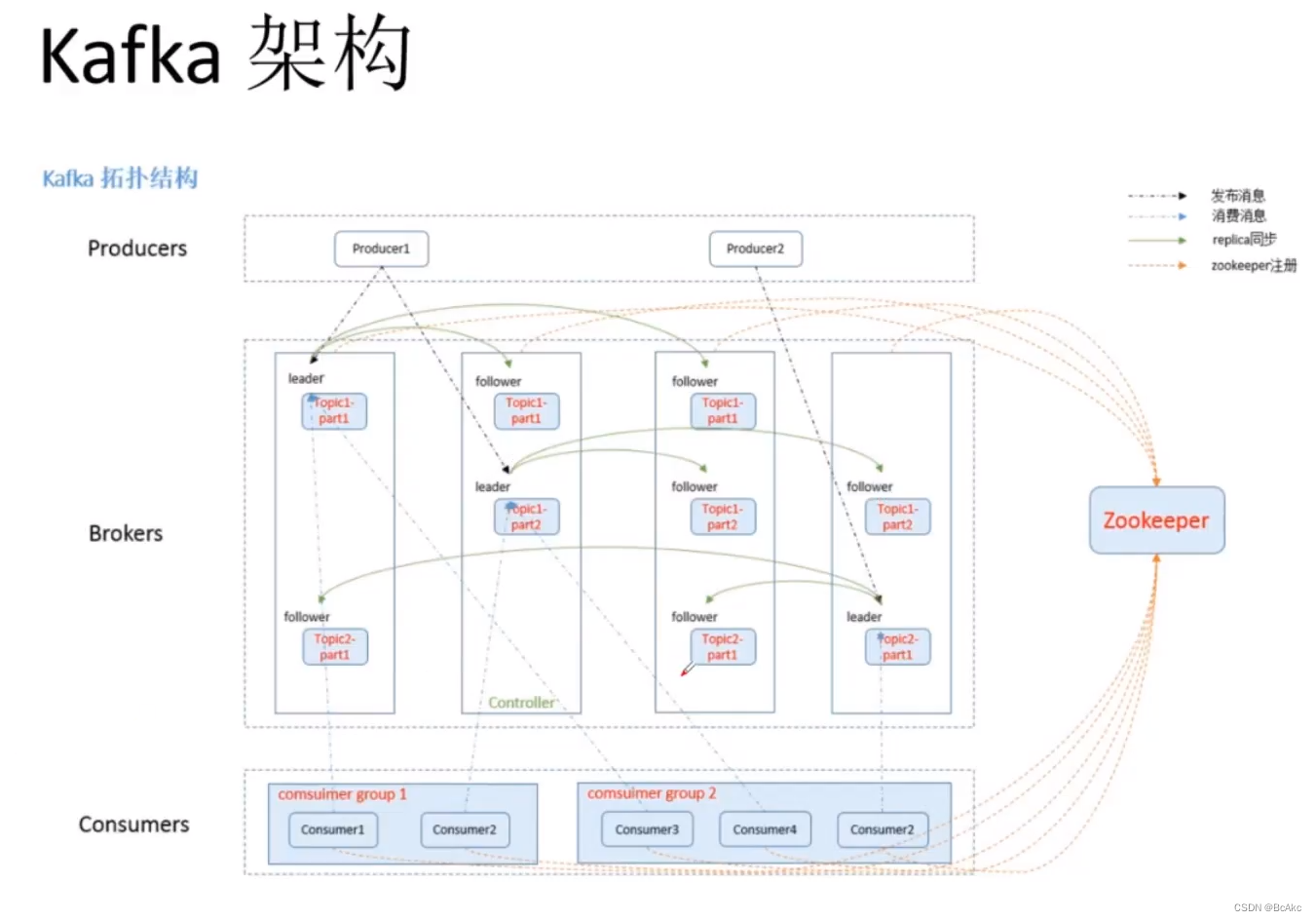
我自己总结的:几个kafka就有几个broker(代理),生产者(producer)生产数据到主题(topic)中,一个topic由多个partition(分区)组成,一个partition由多个replica(副本)组成,而一个replica由1个leader(领导者)和多个followers(追随者)组成,leader只负责数据的读取,而followers只负责数据的复制,consumer(消费者)从topic里面调取数据来消费。
五 搭建kafka
5.1环境准备
基于 之前zookeeper三台机子上操作安装kafka
192.168.10.40 zookeeper + kafka
192.168.10.50 zookeeper + kafka
192.168.10.60 zookeeper + kafka
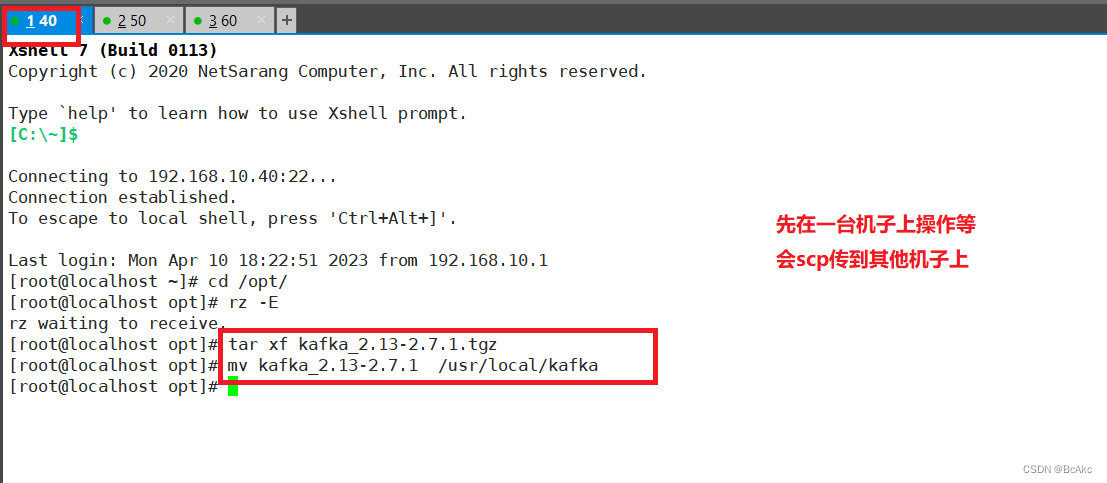
5.2安装kafka
cd /opt/
tar zxvf kafka_2.13-2.7.1.tgz #解压
mv kafka_2.13-2.7.1 /usr/local/kafka #移动改名wget https://mirrors.tuna.tsinghua.edu.cn/apache/kafka/2.7.1/kafka_2.13-2.7.1.tgz #官方下载安装包
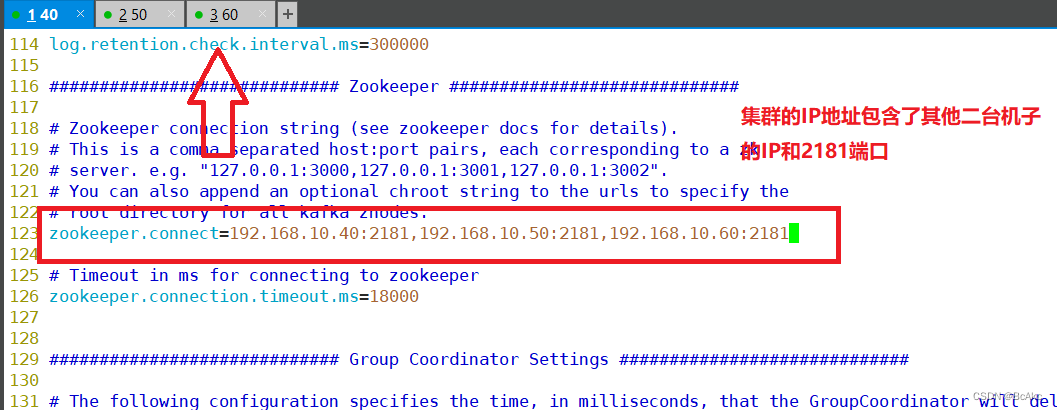
5.3 修改配置文件
cd /usr/local/kafka/config/
cp server.properties{,.bak} #备份vim server.properties
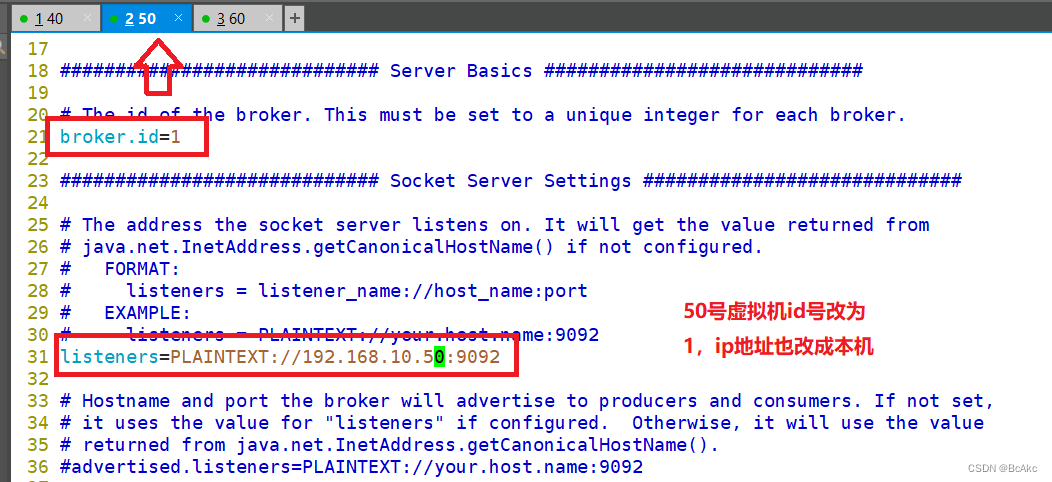
broker.id=0 #21行,broker的全局唯一编号,每个broker不能重复,因此要在其他机器上配置 broker.id=1、broker.id=2
listeners=PLAINTEXT://192.168.10.40:9092 #31行,指定监听的IP和端口,如果修改每个broker的IP需区分开来,也可保持默认配置不用修改
num.network.threads=3 #42行,broker 处理网络请求的线程数量,一般情况下不需要去修改
num.io.threads=8 #45行,用来处理磁盘IO的线程数量,数值应该大于硬盘数
socket.send.buffer.bytes=102400 #48行,发送套接字的缓冲区大小
socket.receive.buffer.bytes=102400 #51行,接收套接字的缓冲区大小
socket.request.max.bytes=104857600 #54行,请求套接字的缓冲区大小
log.dirs=/usr/local/kafka/logs #60行,kafka运行日志存放的路径,也是数据存放的路径
num.partitions=1 #65行,topic在当前broker上的默认分区个数,会被topic创建时的指定参数覆盖
num.recovery.threads.per.data.dir=1 #69行,用来恢复和清理data下数据的线程数量
log.retention.hours=168 #103行,segment文件(数据文件)保留的最长时间,单位为小时,默认为7天,超时将被删除
log.segment.bytes=1073741824 #110行,一个segment文件最大的大小,默认为 1G,超出将新建一个新的segment文件
zookeeper.connect=192.168.10.40:2181,192.168.10.50:2181,192.168.10.60:2181 #123行,配置连接Zookeeper集群地址
只需修改31行 60行 123行


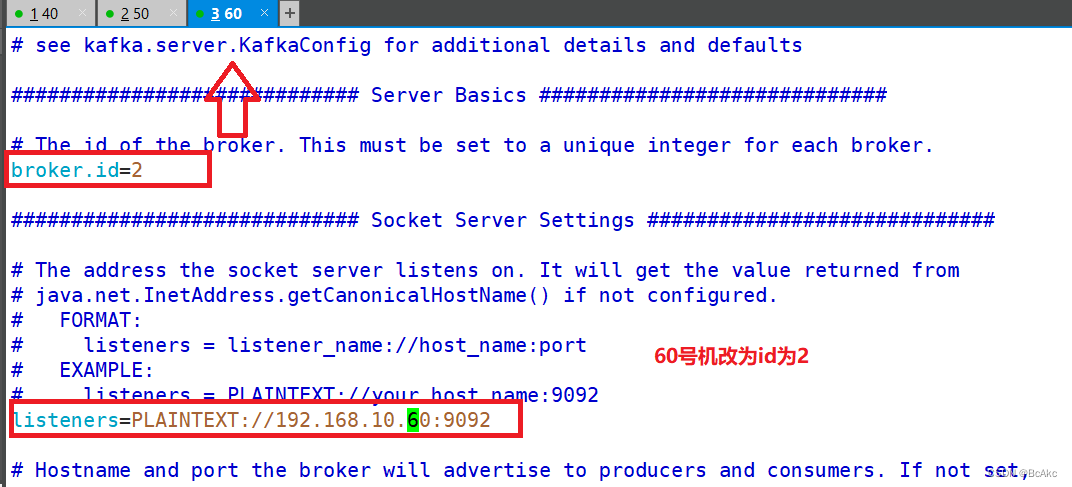
5.4 编辑其他二台虚拟机的配置文件
scp -r /usr/local/kafka/ 192.168.10.50:/usr/local/
scp -r /usr/local/kafka/ 192.168.10.60:/usr/local/
vim /usr/local/kafka/config/server.properties
修改21行和31行
broker.id=
listeners=
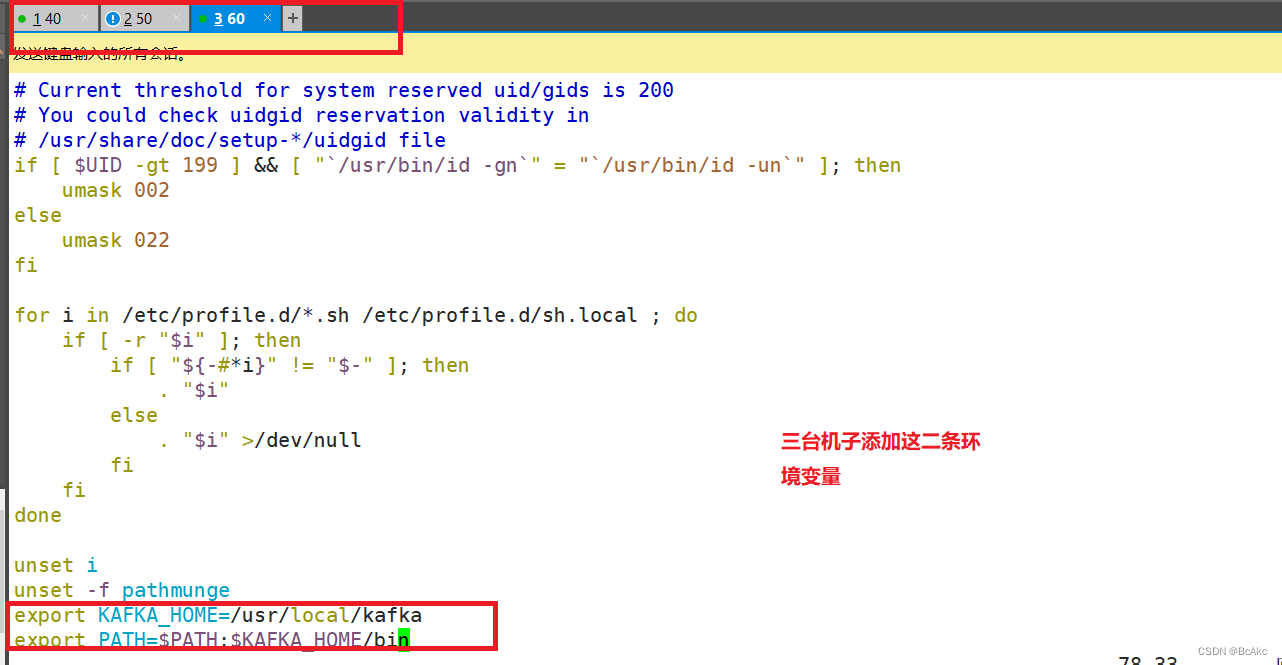
5.5 编辑三台机子环境变量
vim /etc/profile
export KAFKA_HOME=/usr/local/kafka
export PATH=$PATH:$KAFKA_HOME/binsource /etc/profile
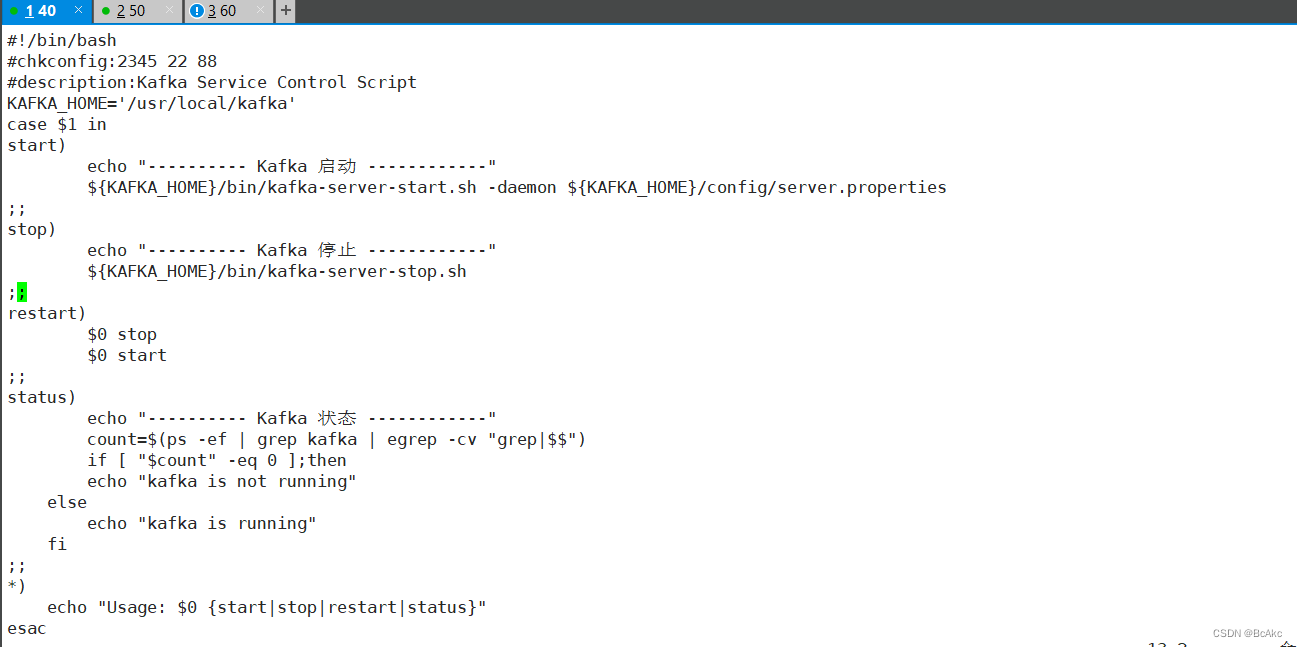
5.6 配置 Zookeeper 启动脚本
三台虚拟机同时进行
vim /etc/init.d/kafka#!/bin/bash
#chkconfig:2345 22 88
#description:Kafka Service Control Script
KAFKA_HOME='/usr/local/kafka'
case $1 in
start)echo "---------- Kafka 启动 ------------"${KAFKA_HOME}/bin/kafka-server-start.sh -daemon ${KAFKA_HOME}/config/server.properties
;;
stop)echo "---------- Kafka 停止 ------------"${KAFKA_HOME}/bin/kafka-server-stop.sh
;;
restart)$0 stop$0 start
;;
status)echo "---------- Kafka 状态 ------------"count=$(ps -ef | grep kafka | egrep -cv "grep|$$")if [ "$count" -eq 0 ];thenecho "kafka is not running"elseecho "kafka is running"fi
;;
*)echo "Usage: $0 {start|stop|restart|status}"
esacchmod +x /etc/init.d/kafka
chkconfig --add kafka
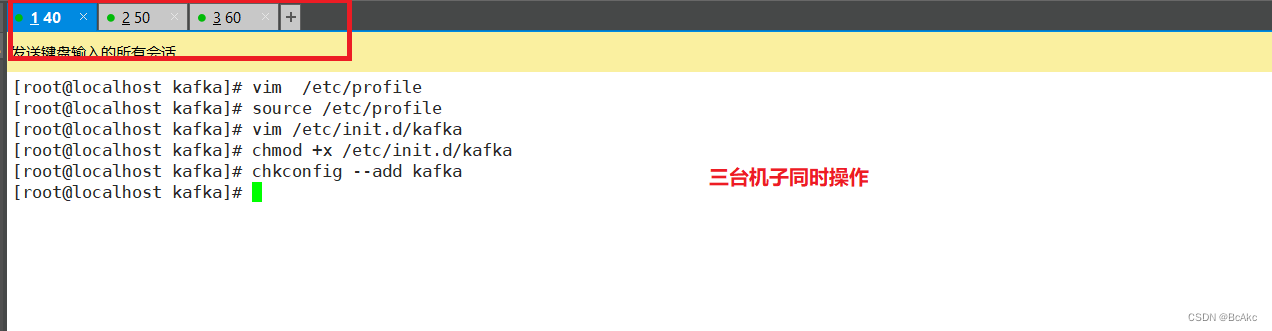
5.7 启动kafka测试
service kafka start定义
--zookeeper 集群服务器地址,如果有多个 IP 地址使用逗号分割,一般使用一个 IP 即可
--replication-factor:定义分区副本数,1 代表单副本,建议为 2
--partitions:定义分区数
--topic:定义 topic 名称
任何一台机子创建topic
kafka-topics.sh --create --zookeeper 192.168.10.40:2181,192.168.10.50:2181,192.168.10.60:2181 --replication-factor 2 --partitions 3 --topic test

查看当前服务器中的所有 topic
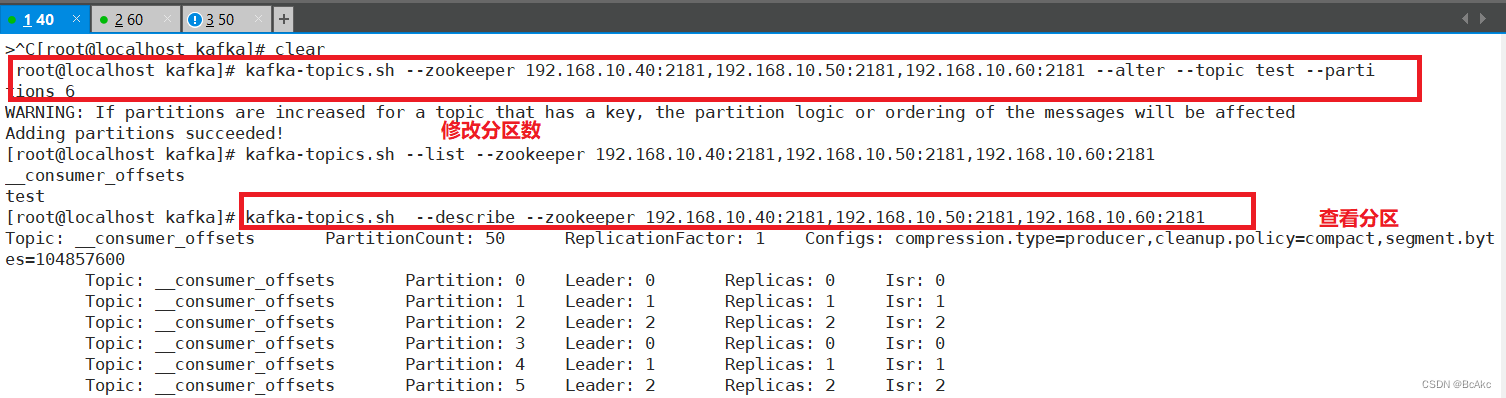
kafka-topics.sh --list --zookeeper 192.168.10.40:2181,192.168.10.50:2181,192.168.10.60:2181

查看某个 topic 的详情
kafka-topics.sh --describe --zookeeper 192.168.10.40:2181,192.168.10.50:2181,192.168.10.60:2181

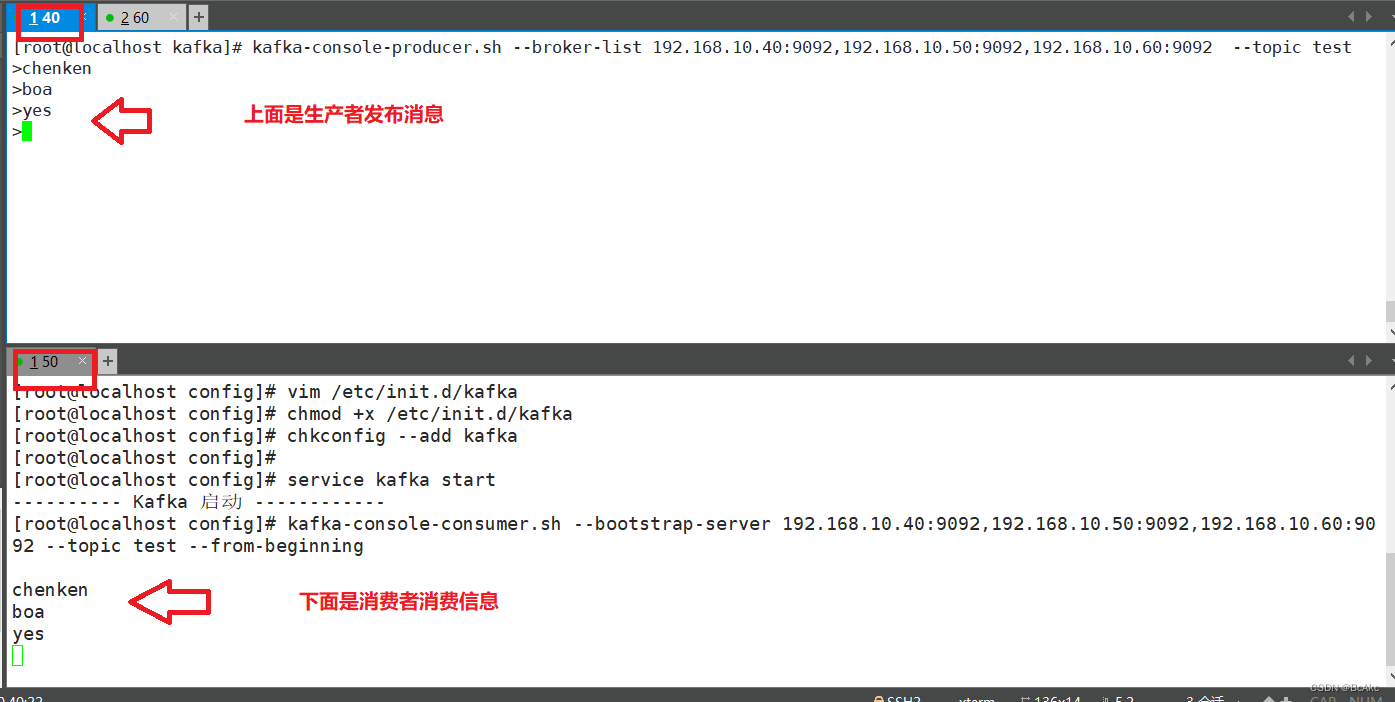
192.168.10.40发布消息
kafka-console-producer.sh --broker-list 192.168.10.40:9092,192.168.10.50:9092,192.168.10.60:9092 --topic test
192.168.10.50消费消息
kafka-console-consumer.sh --bootstrap-server 192.168.10.40:9092,192.168.10.50:9092,192.168.10.60:9092 --topic test --from-beginning
修改分区数
kafka-topics.sh --zookeeper 192.168.10.40:2181,192.168.10.50:2181,192.168.10.60:2181 --alter --topic test --partitions 6
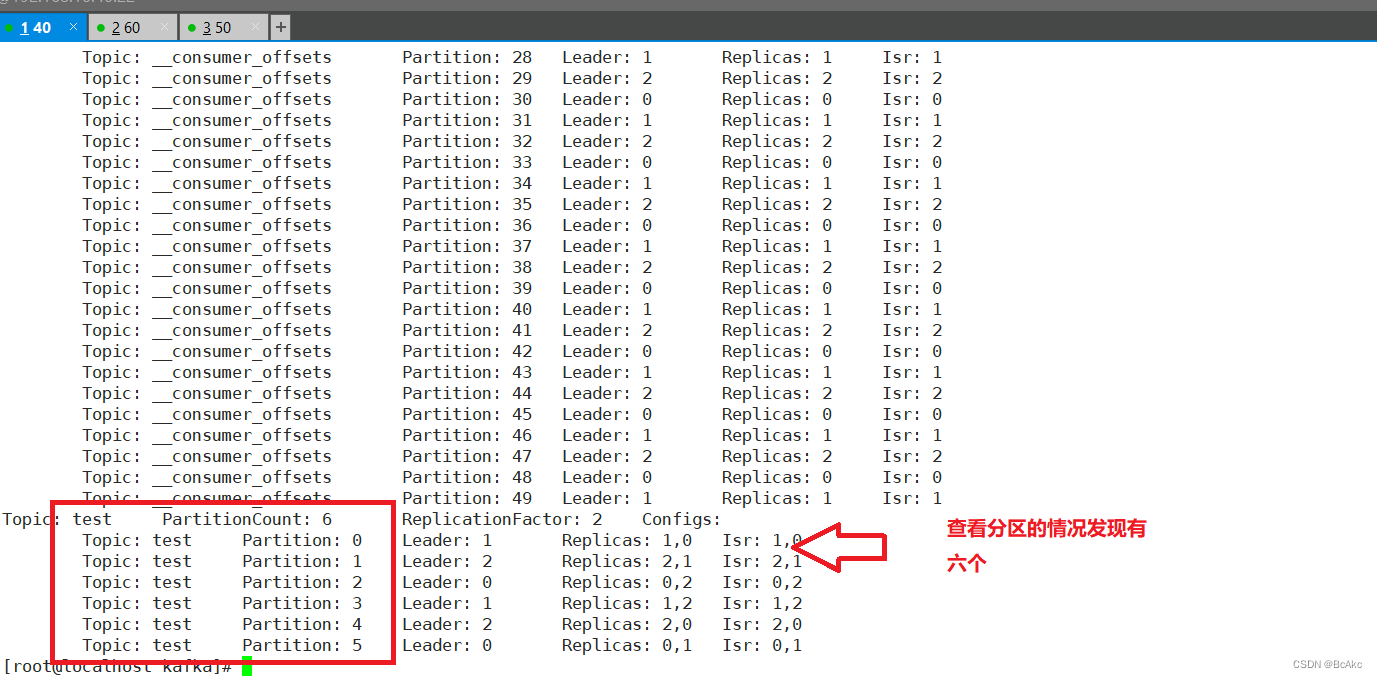
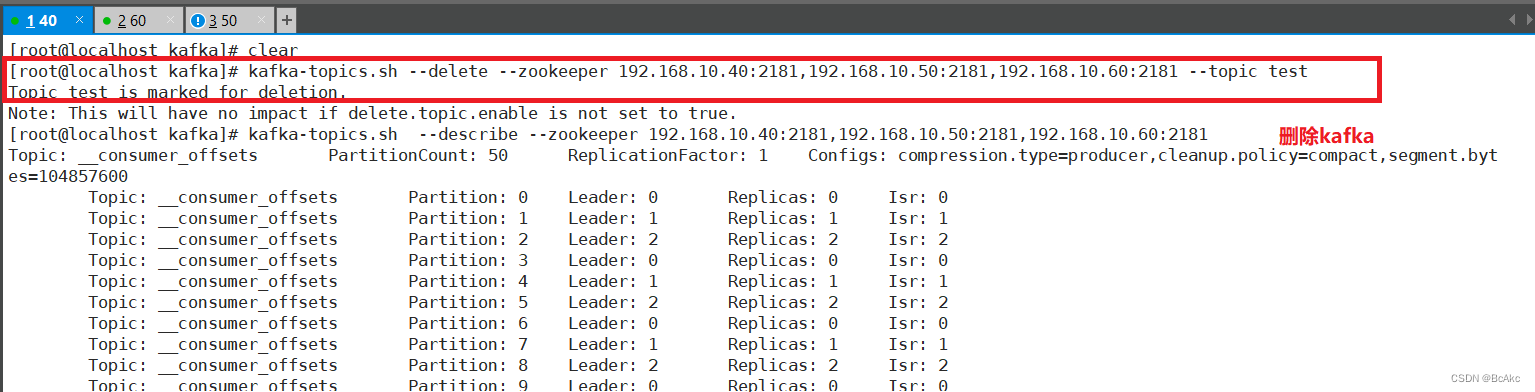
删除 topic
kafka-topics.sh --delete --zookeeper 192.168.10.40:2181,192.168.10.50:2181,192.168.10.60:2181 --topic test
相关文章:
Kafka的概念|架构|搭建|查看命令
Kafka的概念|架构|搭建|查看命令一 Kafka 概述二 使用消息队列的好处三Kafka 定义3.1Kafka 简介3.2Kafka 的特性3.3 Kafka 系统架构3.4 Partation 数据路由规则四 kafka的架构五 搭建kafka5.1环境准备5.2安装kafka5.3 修改配置文件5.4 编辑其他二台虚拟机的配置文件5.5 编辑三台…...
大数据项目实战之数据仓库:电商数据仓库系统——第5章 数据仓库设计
第5章 数据仓库设计 5.1 数据仓库分层规划 优秀可靠的数仓体系,需要良好的数据分层结构。合理的分层,能够使数据体系更加清晰,使复杂问题得以简化。以下是该项目的分层规划。 5.2 数据仓库构建流程 以下是构建数据仓库的完整流程。 5.2.1 …...
OpenHarmony社区运营报告(2023年3月)
目录 本月快讯 一、代码贡献 二、生态进展 三、社区治理 五、社区活动 六、社区及官网运营 本月快讯 • 《OpenHarmony 2022年度运营报告》于3月正式发布,2022年OpenAtom OpenHarmony(以下简称“OpenHarmony”)开源项目潜心务实、深耕发展&am…...
杰林码图像增强算法——超分辨率、图像放大、轮廓和色彩强化算法(二)
一、前言 2023-03-23我发布了基于加权概率模型(杰林码的理论模型)的图像颜色增强和轮廓预测的应用方法。效果还不太明显,于是我又花了2周的时间进行了技术优化。下面仅提供了x86下的BMP和JPG对应的lib和dll,本文中的算法属于我国…...

在three.js中废置对象
基于three.js子如何废置对象(How to dispose of objects) 前言: 为了提高性能,并避免应用程序中的内存泄露,一个重要的方面是废置未使用的类库实体。 每当创建一个three.js中的实例时,都会分配一定数量的内存。然而,three.js会创建在渲染中所必需的特定对象, 例如几何…...
Java中的String类真的不可变吗?
其实在Java中,String类被final修饰,主要是为了保证字符串的不可变性,进而保证了它的安全性。那么final到底是怎么保证字符串安全性的呢?接下来就让我们一起来看看吧。 一. final的作用 1. final关键词修饰的类不可以被其他类继…...
电脑重装了系统开不了机怎么办?
我们的电脑办公用久后也会出现故障问题,例如卡顿反应慢等等,这时候就要进行重装系统了,但是很多小伙伴重装系统后会出现开不了机的问题,其实我们比较常见的也就是电脑重装系统开不了机的情况。有很多小伙伴反映自己不知道应该怎么…...
)
SPOJ-NSUBSTR - Substrings(SAM求所有长度子串的最大出现次数)
NSUBSTR - Substrings 题面翻译 你得到了一个最多由 250000250000250000 个小写拉丁字母组成的字符串 SSS。定义 F(x)F(x)F(x) 为 SSS 的某些长度为 xxx 的子串在 SSS 中的最大出现次数。即 F(x)max{times(T)}F(x)max\{times(T)\}F(x)max{times(T)},满足 TTT 是 S…...
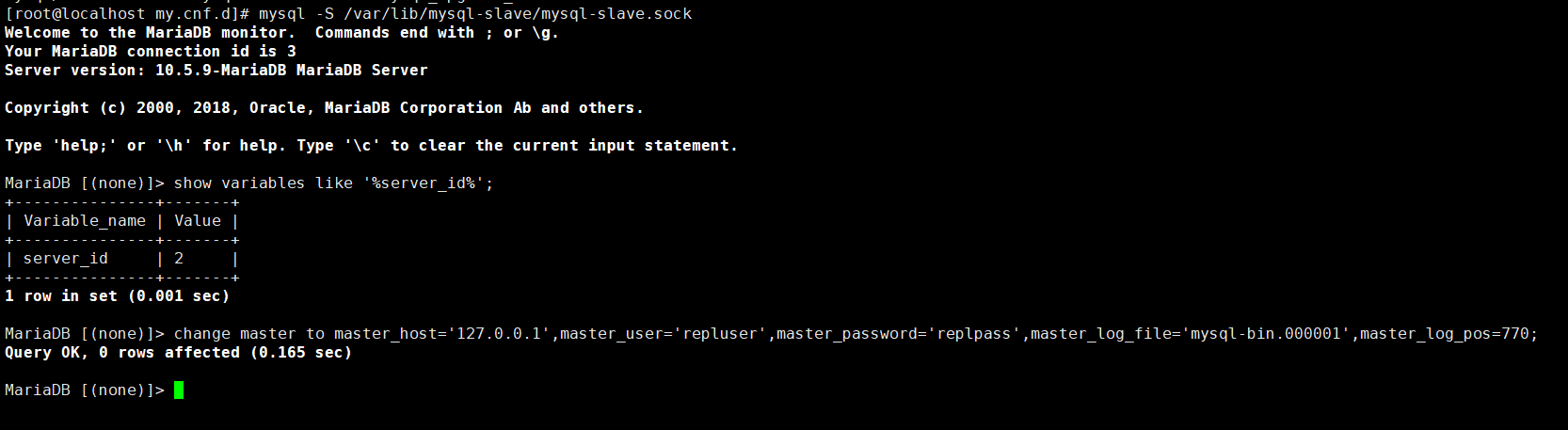
Mariadb10.5基于同服务器多实例主从配置
本次部署环境:Centos8stream 本次部署mariadb版本: mariadb:10.5 本次部署方式:rpm包直接安装,并通过systemd直接托管 可以参考 /usr/lib/systemd/system/mariadb.service 该文件 # Multi instance version of mariadb. For i…...

linux 修改主机名称
1、hostname命令进行临时更改 如果只需要临时更改主机名,可以使用hostname命令: sudo hostname <new-hostname> 例如: 只需重新打开session终端,就能生效, 但是,重启计算机后会回到旧的主机名。…...
学校的地下网站(学校的地下网站1080P高清)
这个问题本身就提得有问题,为什么这么说,这是因为YouTube本身就不是一个视频网站或者说YouTube不是一个传统的视频网站!!! YouTube能够一家独大,可不仅仅是因为有了Google 这个亲爹,还有一点&am…...

勒索病毒是什么?如何防勒索病毒
勒索病毒并不是某一个病毒,而是一类病毒的统称,主要以邮件、程序、木马、网页挂马的形式进行传播,利用各种加密算法对文件进行加密,被感染者一般无法解密,必须拿到解密的私钥才有可能破解。 已知最早的勒索软件出现于 …...

SpringBoot+VUE+Axios 【链接超时】 后端正常返回结果,前端却出现错误无法接收数据
一、错误原因及解决思路 错误提示表明前端发送的请求在默认的 2500ms 超时时间内没有得到服务器的响应,导致请求失败。尝试以下方法来解决这个问题: 增加请求超时时间:可以通过配置 Axios 请求对象的 timeout 属性来增加请求的超时时间&…...
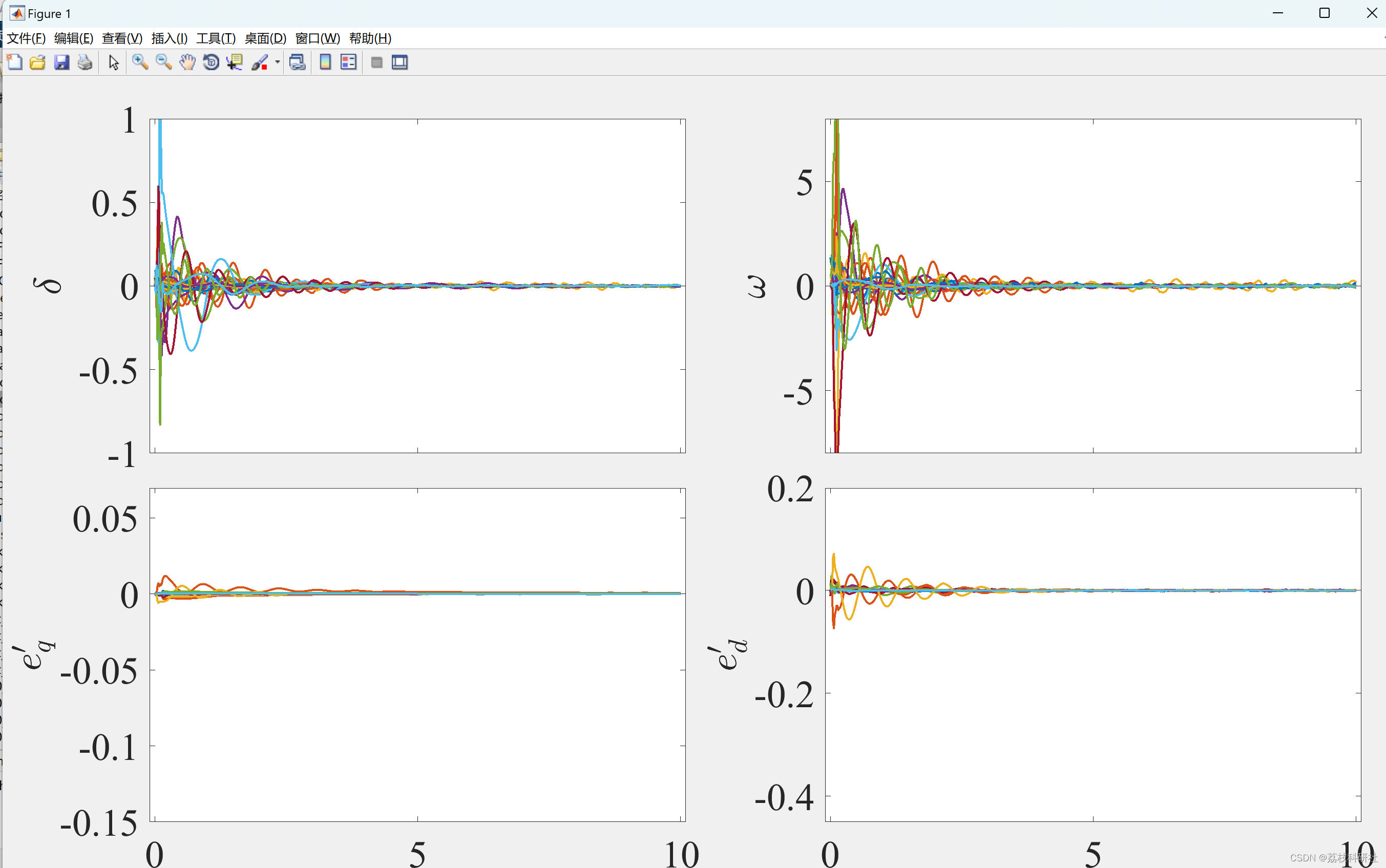
【状态估计】基于增强数值稳定性的无迹卡尔曼滤波多机电力系统动态状态估计(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

快速排序的简单理解
详细描述 快速排序通过一趟排序将待排序列分割成独立的两部分,其中一部分序列的关键字均比另一部分序列的关键字小,则可分别对这两部分序列继续进行排序,以达到整个序列有序的目的。 快速排序详细的执行步骤如下: 从序列中挑出…...
短视频多平台发布软件功能详解
随着移动互联网的普及和短视频的兴起,短视频发布软件越来越受到人们的关注。短视频发布软件除了常规的短视频发布功能,还拥有智能创作、帐号绑定、短视频一键发布、视频任务管理和数据统计等一系列实用功能。下面我们将分步骤详细介绍一下这些功能。 …...

谷歌人机验证Google reCAPTCHA
reCAPTCHA是Google公司推出的一项验证服务,使用十分方便快捷,在国外许多网站上均有使用。它与许多其他的人机验证方式不同,它极少需要用户进行各种识图验证。 它的使用方式如下如所示,只需勾选复选框即可通过人机验证。 虽然简单…...
VB+ACCESS电脑销售系统的设计与实现
为了使此系统简单易学易用、功能强大、软件费用支出低、见效快等特点,我们选择Visual Basic6.0开发此系统。Visual Basic6.0起代码有效率以达到Visual c的水平。在面向对象程序设计方面,Visual Basic6.0全面支持面向对你程序设计包括数据抽象、封装、对象…...

嵌入式开发:硬件和软件越来越接近
从前,硬件和软件工程师大多生活在自己的世界里。硬件团队设计了芯片,调试了从铸造厂返回的第一批样本,让软件团队测试他们的代码。随着虚拟平台和其他可执行模型变得越来越普遍,软件团队可以在芯片制造之前开始,有时甚…...
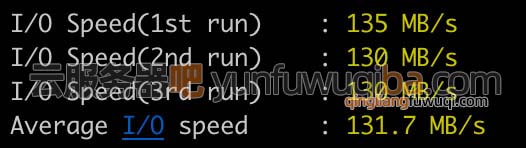
亲测:腾讯云轻量应用服务器性能如何?
腾讯云轻量应用服务器性能评测,轻量服务器CPU主频、处理器型号、公网带宽、月流量、Ping值测速、磁盘IO读写及使用限制,轻量应用服务器CPU内存性能和标准型云服务器CVM处于同一水准,所以大家不要担心轻量应用服务器的性能,腾讯云百…...

探索OpenBoardView:硬件工程师的PCB分析利器
探索OpenBoardView:硬件工程师的PCB分析利器 【免费下载链接】OpenBoardView View .brd files 项目地址: https://gitcode.com/gh_mirrors/op/OpenBoardView 在现代电子硬件开发与维修领域,面对复杂的电路板设计文件,工程师们常常需要…...

学校AIGC检测标准差异解读:不同高校AI率标准对比2026年如何针对性免费处理完整指南
学校AIGC检测标准差异解读:不同高校AI率标准对比2026年如何针对性免费处理完整指南 同一段文字,不同平台检测AI率相差20%以上。这不是玄学,有原因可解释。 关于高校AIGC检测标准差异解读,理解了背后逻辑,很多「奇怪现…...

观察Taotoken在多日连续调用中的延迟与稳定性表现
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察Taotoken在多日连续调用中的延迟与稳定性表现 在需要连续多日、高频率调用大模型API的场景中,例如持续性的内容生成…...

用Gemini3.1Pro高效撰写工作汇报从素材整理到终稿交付全流程
做多模型横向对比测试时常用的聚合平台推荐下:库拉KULAAI(c.877ai.cn),上面能直接调Gemini 3.1 Pro和多个主流模型做职场办公场景对比。下面进入正题。工作汇报和周报不是一回事很多人把工作汇报和周报混为一谈。周报是流水线上的…...

CanFestival实战:从心跳、TPDO/RPDO配置到回调函数的完整链路解析
1. CanFestival协议栈基础认知 第一次接触CanFestival时,我也被各种专业术语搞得晕头转向。简单来说,它就是个开源的CANopen协议栈实现,专门用于嵌入式设备间的通信。就像两个说同一种方言的人能顺畅交流一样,CanFestival让不同厂…...
)
ElevenLabs老年语音情感衰减难题破解(附可复用的Prosody增强JSON Schema与实测MOS提升2.1分)
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs老年男性语音情感衰减现象的本质剖析 ElevenLabs 的老年男性语音模型(如 “Antoni” 或 “Josh”)在高语速、长句或情绪密集场景下,常出现语调扁平化、微停…...

终极B站缓存视频转换指南:快速将m4s无损转换为MP4
终极B站缓存视频转换指南:快速将m4s无损转换为MP4 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否曾经因为B站视频突然下架而感…...
)
ElevenLabs俄文语音合成私有化部署终极方案(含Docker镜像+俄语ASR对齐校验工具链)
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs俄文语音合成私有化部署的背景与价值 随着全球本地化需求激增,俄语市场对高质量、低延迟、高隐私保障的语音合成(TTS)服务提出迫切要求。ElevenLabs 以其卓…...

Spring boot相关
1. ● 问题1:为什么扫描的是 com.example.demo 包?因为主入口类在这个包下。 com.example.demo …...
)
手把手教你用XDS110给TI开发板供电与调试(附CCS配置避坑指南)
手把手教你用XDS110给TI开发板供电与调试(附CCS配置避坑指南) 对于刚接触TI嵌入式开发的工程师或学生来说,XDS110调试探针是一个经济实惠且功能强大的入门选择。它不仅支持JTAG和SWD调试,还能为目标板提供电源,并集成了…...