快速排序的简单理解
详细描述
快速排序通过一趟排序将待排序列分割成独立的两部分,其中一部分序列的关键字均比另一部分序列的关键字小,则可分别对这两部分序列继续进行排序,以达到整个序列有序的目的。
快速排序详细的执行步骤如下:
- 从序列中挑出一个元素,称为 “基准”(pivot);
- 重新排序序列,所有比基准值小的元素摆放在基准前面,所有比基准值大的元素摆在基准的后面(相同的数可以到任一边)。在这个分区退出之后,该基准就处于序列的中间位置。这个称为分区(partition)操作;
- 递归地(recursive)把小于基准值元素的子序列和大于基准值元素的子序列排序。
算法图解
问题解疑
快速排序可以怎样选择基准值?
第一种方式:固定位置选择基准值;在整个序列已经趋于有序的情况下,效率很低。
第二种方式:随机选取待排序列中任意一个数作为基准值;当该序列趋于有序时,能够让效率提高,但在整个序列数全部相等的时候,随机快排的效率依然很低。
第三种方式:从区间的首、尾、中间,分别取出一个数,然后对比大小,取这 3 个数的中间值作为基准值;这种方式解决了很多特殊的问题,但对于有很多重复值的序列,效果依然不好。
快速排序有什么好的优化方法?
首先,合理选择基准值,将固定位置选择基准值改成三点取中法,可以解决很多特殊的情况,实现更快地分区。
其次,当待排序序列的长度分割到一定大小后,使用插入排序。对于待排序的序列长度很小或基本趋于有序时,插入排序的效率更好。
在排序后,可以将与基准值相等的数放在一起,在下次分割时可以不考虑这些数。对于解决重复数据较多的情况非常有用。
在实现上,递归实现的快速排序在函数尾部有两次递归操作,可以对其使用尾递归优化(简单地说,就是尾位置调用自身)。
代码实现
排序接口
package cn.fatedeity.algorithm.sort; | |
/** | |
* 排序接口 | |
*/ | |
public interface Sort { | |
int[] sort(int[] numbers); | |
} |
排序抽象类
package cn.fatedeity.algorithm.sort; | |
/** | |
* 排序抽象类 | |
*/ | |
public abstract class AbstractSort implements Sort { | |
protected void swap(int[] numbers, int src, int target) { | |
int temp = numbers[src]; | |
numbers[src] = numbers[target]; | |
numbers[target] = temp; | |
} | |
} |
快速排序类
package cn.fatedeity.algorithm.sort; | |
import java.util.Random; | |
/** | |
* 快速排序类 | |
*/ | |
public class QuickSort extends AbstractSort { | |
private int[] sort(int[] numbers, int low, int high) { | |
if (low > high) { | |
return numbers; | |
} | |
// 随机数取基准值 | |
Random random = new Random(); | |
int pivotIndex = random.nextInt(low, high + 1); | |
int pivot = numbers[pivotIndex]; | |
this.swap(numbers, pivotIndex, low); | |
int mid = low + 1; | |
for (int i = low + 1; i <= high; i++) { | |
if (numbers[i] < pivot) { | |
this.swap(numbers, i, mid); | |
mid++; | |
} | |
} | |
this.swap(numbers, low, --mid); | |
// 递归实现 | |
this.sort(numbers, low, mid - 1); | |
this.sort(numbers, mid + 1, high); | |
return numbers; | |
} | |
@Override | |
public int[] sort(int[] numbers) { | |
if (numbers.length <= 1) { | |
return numbers; | |
} | |
return this.sort(numbers, 0, numbers.length - 1); | |
} | |
} |
详细描述
快速排序通过一趟排序将待排序列分割成独立的两部分,其中一部分序列的关键字均比另一部分序列的关键字小,则可分别对这两部分序列继续进行排序,以达到整个序列有序的目的。
快速排序详细的执行步骤如下:
- 从序列中挑出一个元素,称为 “基准”(pivot);
- 重新排序序列,所有比基准值小的元素摆放在基准前面,所有比基准值大的元素摆在基准的后面(相同的数可以到任一边)。在这个分区退出之后,该基准就处于序列的中间位置。这个称为分区(partition)操作;
- 递归地(recursive)把小于基准值元素的子序列和大于基准值元素的子序列排序。
算法图解

问题解疑
快速排序可以怎样选择基准值?
第一种方式:固定位置选择基准值;在整个序列已经趋于有序的情况下,效率很低。
第二种方式:随机选取待排序列中任意一个数作为基准值;当该序列趋于有序时,能够让效率提高,但在整个序列数全部相等的时候,随机快排的效率依然很低。
第三种方式:从区间的首、尾、中间,分别取出一个数,然后对比大小,取这 3 个数的中间值作为基准值;这种方式解决了很多特殊的问题,但对于有很多重复值的序列,效果依然不好。
快速排序有什么好的优化方法?
首先,合理选择基准值,将固定位置选择基准值改成三点取中法,可以解决很多特殊的情况,实现更快地分区。
其次,当待排序序列的长度分割到一定大小后,使用插入排序。对于待排序的序列长度很小或基本趋于有序时,插入排序的效率更好。
在排序后,可以将与基准值相等的数放在一起,在下次分割时可以不考虑这些数。对于解决重复数据较多的情况非常有用。
在实现上,递归实现的快速排序在函数尾部有两次递归操作,可以对其使用尾递归优化(简单地说,就是尾位置调用自身)。
代码实现
排序接口
package cn.fatedeity.algorithm.sort; | |
/** | |
* 排序接口 | |
*/ | |
public interface Sort { | |
int[] sort(int[] numbers); | |
} |
排序抽象类
package cn.fatedeity.algorithm.sort; | |
/** | |
* 排序抽象类 | |
*/ | |
public abstract class AbstractSort implements Sort { | |
protected void swap(int[] numbers, int src, int target) { | |
int temp = numbers[src]; | |
numbers[src] = numbers[target]; | |
numbers[target] = temp; | |
} | |
} |
快速排序类
package cn.fatedeity.algorithm.sort; | |
import java.util.Random; | |
/** | |
* 快速排序类 | |
*/ | |
public class QuickSort extends AbstractSort { | |
private int[] sort(int[] numbers, int low, int high) { | |
if (low > high) { | |
return numbers; | |
} | |
// 随机数取基准值 | |
Random random = new Random(); | |
int pivotIndex = random.nextInt(low, high + 1); | |
int pivot = numbers[pivotIndex]; | |
this.swap(numbers, pivotIndex, low); | |
int mid = low + 1; | |
for (int i = low + 1; i <= high; i++) { | |
if (numbers[i] < pivot) { | |
this.swap(numbers, i, mid); | |
mid++; | |
} | |
} | |
this.swap(numbers, low, --mid); | |
// 递归实现 | |
this.sort(numbers, low, mid - 1); | |
this.sort(numbers, mid + 1, high); | |
return numbers; | |
} | |
@Override | |
public int[] sort(int[] numbers) { | |
if (numbers.length <= 1) { | |
return numbers; | |
} | |
return this.sort(numbers, 0, numbers.length - 1); | |
} | |
} |
相关文章:
快速排序的简单理解
详细描述 快速排序通过一趟排序将待排序列分割成独立的两部分,其中一部分序列的关键字均比另一部分序列的关键字小,则可分别对这两部分序列继续进行排序,以达到整个序列有序的目的。 快速排序详细的执行步骤如下: 从序列中挑出…...
短视频多平台发布软件功能详解
随着移动互联网的普及和短视频的兴起,短视频发布软件越来越受到人们的关注。短视频发布软件除了常规的短视频发布功能,还拥有智能创作、帐号绑定、短视频一键发布、视频任务管理和数据统计等一系列实用功能。下面我们将分步骤详细介绍一下这些功能。 …...

谷歌人机验证Google reCAPTCHA
reCAPTCHA是Google公司推出的一项验证服务,使用十分方便快捷,在国外许多网站上均有使用。它与许多其他的人机验证方式不同,它极少需要用户进行各种识图验证。 它的使用方式如下如所示,只需勾选复选框即可通过人机验证。 虽然简单…...
VB+ACCESS电脑销售系统的设计与实现
为了使此系统简单易学易用、功能强大、软件费用支出低、见效快等特点,我们选择Visual Basic6.0开发此系统。Visual Basic6.0起代码有效率以达到Visual c的水平。在面向对象程序设计方面,Visual Basic6.0全面支持面向对你程序设计包括数据抽象、封装、对象…...

嵌入式开发:硬件和软件越来越接近
从前,硬件和软件工程师大多生活在自己的世界里。硬件团队设计了芯片,调试了从铸造厂返回的第一批样本,让软件团队测试他们的代码。随着虚拟平台和其他可执行模型变得越来越普遍,软件团队可以在芯片制造之前开始,有时甚…...
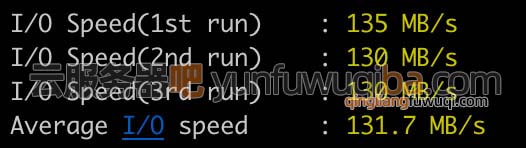
亲测:腾讯云轻量应用服务器性能如何?
腾讯云轻量应用服务器性能评测,轻量服务器CPU主频、处理器型号、公网带宽、月流量、Ping值测速、磁盘IO读写及使用限制,轻量应用服务器CPU内存性能和标准型云服务器CVM处于同一水准,所以大家不要担心轻量应用服务器的性能,腾讯云百…...
编程语言,TIOBE 4 月榜单:黑马出现了
TIOBE 4 月榜单已经发布了,一起来看看这个月编程语言排行榜有什么变化吧! C 发展依旧迅猛 在本月榜单中,TOP 20 的变动不大,Python、C、Java 、 C 和C#依然占据前五。甚至排名顺序都和上个月一样没有变动。 同时,Rus…...

基于DSP+FPGA的机载雷达伺服控制系统(二)电源仿真
板级电源分配网络的分析与仿真在硬件电路设计中,电源系统的设计是关键步骤之一,良好的电源系统为电路板 上各种信号的传输提供了保障。本章将研究电源完整性的相关问题,并提出一系列改 进电源质量的措施。 3.1 电源完整性 电源完整性…...

SpringBoot整合Redis、以及缓存穿透、缓存雪崩、缓存击穿的理解分布式情况下如何添加分布式锁 【续篇】
文章目录前言1、分布式情况下如何加锁2、具体实现过程3、测试3.1 一个服务按照多个端口同时启动3.2 使用jmeter进行压测前言 上一篇实现了单体应用下如何上锁,这一篇主要说明如何在分布式场景下上锁 上一篇地址:加锁 1、分布式情况下如何加锁 需要注意的点是: 在上锁和释放…...

优漫动游告诉你:平面设计适合你吗?
优漫动游告诉你:平面设计适合你吗? 什么样的同学可以适应平面设计这份工作呢? 略微有美术基础,当然功底越深越加分。 2.对色彩、形状、结构有一定的接纳力。 3.对图案、人像、字体等因素有审美辨别的能力…...

在Vue中,为什么从 props 中解构变量之后再watch它,无法检测到它的变化?
例如下面这段代码,msg无法被watch import { watch } from vue;export default {props: {msg: String},setup(props) {// 从 props 中解构 msgconst { msg } props;watch(() > msg,(newVal, oldVal) > {console.log(newVal, newVal);console.log(oldVal, old…...

[源码解析]socket系统调用上
文章目录socket函数API内核源码sock_createinet_createsock_allocsock_map_fd相关数据结构本文将以socket函数为例,分析它在Linux5.12.10内核中的实现,先观此图,宏观上把握它在内核中的函数调用关系:socket函数API socket 函数原…...

Jenkins部署与自动化构建
Jenkins笔记 文章目录Jenkins笔记[toc]一、安装Jenkinsdocker 安装 JenkinsJava启动war包直接安装二、配置mavenGit自动构建jar包三、自动化发布到测试服务器运行超时机制数据流重定向编写清理Shell脚本四、构建触发器1. 生成API token2. Jenkins项目配置触发器3. 远程Git仓库配…...

网络编程三要素
网络编程三要素 IP、端口号、协议 三要素分别代表什么 ip:设备在网络中的地址,是唯一的标识 端口号:应用程序在设备中的唯一标识 协议:数据在网络中传输的规则 常见的协议有UDP、TCP、http、https、ftp ip:IPv4和…...

如何编写一个自己的web前端脚手架
脚手架简介 脚手架是创建前端项目的命令行工具,集成了常用的功能和配置,方便我们快速搭建项目,目前网络上也有很多可供选择的脚手架。 一个"简单脚手架"的构成其实非常少,即 代码模板 命令行工具。其中代码模板是脚手…...
计算机网络第1章(概述)
文章目录1.1、计算机网络在信息时代的作用1.2、因特网概述1、网络、互连网(互联网)和因特网2、因特网发展的三个阶段3、因特网的标准化工作4、因特网的组成1.3 三种交换方式1、电路交换(Circuit Switching)2、分组交换(…...

grid布局
一、概述 CSS Grid 布局是 CSS 中最强大的布局系统。与 flexbox 的一维布局系统不同,CSS Grid 布局是一个二维布局系统,也就意味着它可以同时处理列和行。通过将 CSS 规则应用于 父元素 (成为 Grid Container 网格容器)和其 子元素(成为 Gri…...

博客平台打造出色的个人资料管理与展示:实用技巧与代码示例
个人资料管理与展示是博客平台的重要功能之一。本文将通过设计思路、技术实现和代码示例,详细讲解如何构建出色的个人资料管理与展示功能。结合CodeInsight平台的实践案例,帮助您深入了解个人资料管理与展示的设计原则和技术实现。 一、设计思路 在设计…...
)
【genius_platform软件平台开发】第九十三讲:串口通信(485通信)
485通信1. 485通信1.1 termios结构1.2 头文件1.3 函数讲解1.3.1 tcgetattr1.3.2 tcsetattr1.4 示例工程1.5 参考文献1.5.1 stty命令1.5.2 命令格式1.5.2 microcom命令1.5.2.1介绍1.5.2.2指令1.5.3 echo命令1.5.3.1 语法1.5.3.2 选项列表1.5.3.3 使用示例1.5.3.4 e cho > 输出…...

JavaScript动画相关讲解
JavaScript是一种非常流行的脚本语言,广泛应用于Web开发、游戏开发、移动应用开发等领域。在Web开发中,动画效果是非常重要的一部分,可以提高网站的用户体验和吸引力。JavaScript提供了一些基本的动画函数,但是这些函数往往不能满…...

demo-magic常见问题解决:pv工具安装和终端兼容性完全指南
demo-magic常见问题解决:pv工具安装和终端兼容性完全指南 【免费下载链接】demo-magic A handy shell script that enables you to write repeatable demos in a bash environment. 项目地址: https://gitcode.com/gh_mirrors/de/demo-magic demo-magic是一个…...

从‘尺子刻度’到‘信号保真’:用Python仿真带你直观理解ADC的INL、DNL和SNDR到底在说什么
从‘尺子刻度’到‘信号保真’:用Python仿真带你直观理解ADC的INL、DNL和SNDR到底在说什么 在数字信号处理的世界里,模数转换器(ADC)扮演着将连续模拟信号转换为离散数字信号的关键角色。但对于许多软件开发者或跨领域学习者来说,ADC的性能参…...

双喷头3D打印实战指南:从原理到应用,掌握多材料制造
1. 双喷头3D打印:从“炫技”到“实用”的跨越如果你玩3D打印有一段时间了,看着满柜子的单色模型,心里大概会开始痒痒:能不能打印个红蓝相间的超级英雄手办?或者做个硬塑料外壳配软胶按钮的遥控器?这种想法&…...

靠谱的微晶电热板机构
在实验设备领域,微晶电热板是一款重要的工具,选择靠谱的机构至关重要。微晶电热板的重要性微晶电热板在环境监测、食品安全、农产品检测等分析实验室中应用广泛。它能够为样品前处理提供稳定的加热环境,保障实验结果的准确性。行业报告显示&a…...

图像处理入门避坑:拉普拉斯锐化中的‘标定’到底在做什么?用NumPy手撕一遍就懂了
图像处理入门避坑:拉普拉斯锐化中的‘标定’到底在做什么?用NumPy手撕一遍就懂了 当你第一次尝试用拉普拉斯算子锐化图像时,可能会遇到一个令人困惑的现象:明明按照教程写了代码,输出的却是一张全黑或全白的图片。这不…...

基于MCP协议构建Jira连接器:打通AI助手与项目管理的技术实践
1. 项目概述:当Jira遇上MCP,一个连接器如何重塑项目管理工具链如果你和我一样,长期在软件研发一线摸爬滚打,那么对Jira这个名字一定不会陌生。它几乎是敏捷开发、缺陷跟踪和项目管理的代名词,无数团队用它来规划冲刺、…...

Kubernetes 安全加固清单:从 RBAC 到 etcd 加密的生产实践
在云原生时代,Kubernetes 已成为容器编排的事实标准,但默认配置下的 K8s 并不安全。一次错误的 RBAC 权限配置、一个暴露的 etcd 端口、或者一个特权模式的 Pod,都可能成为攻击者的入口。本文从认证授权、Pod 安全、网络隔离、数据加密四个维…...

GitHub代码仓库导航:开发者如何高效构建与使用技术资源地图
1. 项目概述:一个面向开发者的代码仓库导航 最近在GitHub上闲逛,发现了一个挺有意思的仓库,叫 yeabnoah/vx_code 。乍一看这个标题,可能会有点摸不着头脑, vx_code 是什么?是某种新的编程语言…...

桌面级机械臂DIY全攻略:从运动学建模到PID控制实战
1. 项目概述:一个桌面级机械臂的诞生最近在逛GitHub的时候,发现了一个挺有意思的项目,叫“ClawPuter”。光看名字,你可能会有点摸不着头脑,Claw是爪子,Puter是计算机,合起来是“爪式计算机”&am…...
)
别再乱点JIRA后台了!手把手教你配置项目专属的工单创建界面(附界面方案关联避坑点)
JIRA界面配置实战:从零构建高可用工单系统的避坑指南 当团队规模扩张到15人以上时,随意创建的JIRA工单开始暴露致命问题——用户故事缺少"验收标准"字段,缺陷报告漏填"重现步骤",而技术债务卡片却显示着完全不…...